19- CNN进行Fashion-MNIST分类 (tensorflow系列) (项目十九)
项目要点
- Fashion-MNIST总共有十个类别的图像。
- 代码运行位置 CPU: cpu=tf.config.set_visible_devices(tf.config.list_physical_devices("CPU"))
- fashion_mnist = keras.datasets.fashion_mnist # fashion_mnist 数据导入
- 训练数据和测试数据拆分: x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
- x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(55000, -1)).reshape( -1, 28, 28, 1) 标准化处理数据 # scaler = StandardScaler() 标准化处理只能处理一维数据
- 创建模型: model = keras.models.Sequential()
- model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', activation = 'relu', input_shape = (28, 28, 1))) 添加输入层
- 池化, 常用最大值池化: model.add(keras.layers.MaxPool2D())
- model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3, padding = 'same',activation = 'relu')) # 添加卷积层
- 维度变化, 卷积完后为四维, 自动变二维: model.add(keras.layers.Flatten())
- model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784))) # 重新调整形状
- 添加卷积层: model.add(keras.layers.Dense(256, activation = 'relu'))
- 添加输出层: model.add(keras.layers.Dense(10, activation = 'softmax'))
- 查看模型: model.summary()
- 模型配置:
model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])- histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid)) 模型训练
- 模型评估: model.evaluate(x_test_scaled, y_test)
- 画图大小设置: pd.DateFrame(history.history).plot(figsize = (8, 5))
- 网格线显示: plt.grid(True)
- y轴设置: plt.gca().set_ylim(0, 1) # plt.gca() 坐标轴设置
- plt.show() 显示图像
一 Fashion-MNIST分类
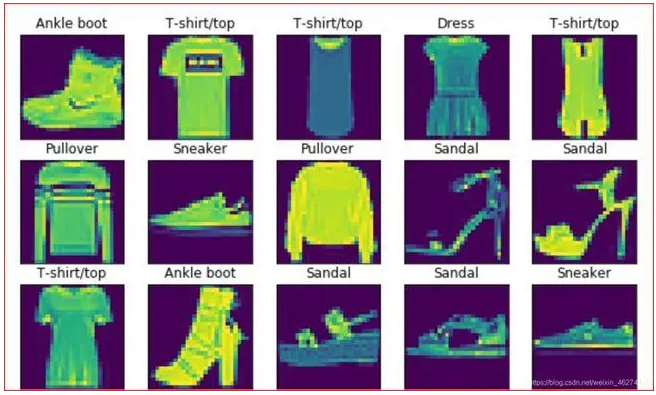
Fashion-MNIST总共有十个类别的图像。每一个类别由训练数据集6000张图像和测试数据集1000张图像。所以训练集和测试集分别包含60000张和10000张。测试训练集用于评估模型的性能。
每一个输入图像的高度和宽度均为28像素。数据集由灰度图像组成。Fashion-MNIST,中包含十个类别,分别是t-shirt,trouser,pillover,dress,coat,sandal,shirt,sneaker,bag,ankle boot。
1.1 导包
import numpy as np
from tensorflow import keras
import tensorflow as tf
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScalercpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())1.2 数据导入
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]1.3 标准化
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(55000, -1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(5000, -1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(10000, -1)).reshape(-1, 28, 28, 1)1.4 创建模型
model = keras.models.Sequential()
# filters 过滤器
# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu',# batch_size, height, width, channels(通道数)input_shape = (28, 28, 1))) # (28, 28, 32)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)# 卷积
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)# 卷积
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (7, 7, 128)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (4, 4, 128)
# 维度变化, 卷积完后为四维, 自动变二维
model.add(keras.layers.Flatten())model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784, )))
model.add(keras.layers.Dense(256, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = 'softmax'))model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])
1.5 训练模型
histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid))
1.6 模型评估
model.evaluate(x_test_scaled, y_test) # [0.32453039288520813, 0.906000018119812]二 增加卷积
2.1 创建模型
model = keras.models.Sequential()
# filters 过滤器
# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu',# batch_size, height, width, channels(通道数)input_shape = (28, 28, 1))) # (28, 28, 32)
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)# 卷积
model.add(keras.layers.Conv2D(filters = 128,kernel_size = 3,padding = 'same',activation = 'relu')) # (7, 7, 128)
model.add(keras.layers.Conv2D(filters = 128,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (4, 4, 128)
# 维度变化, 卷积完后为四维, 自动变二维
model.add(keras.layers.Flatten())model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784, )))
model.add(keras.layers.Dense(256, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = 'softmax'))model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])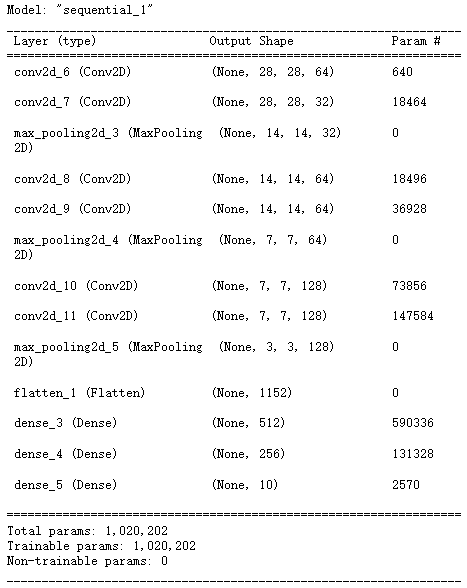
2.2 训练模型
histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid))
2.3 评估模型
model.evaluate(x_test_scaled, y_test) # [0.3228122293949127, 0.9052000045776367]相关文章:
19- CNN进行Fashion-MNIST分类 (tensorflow系列) (项目十九)
项目要点 Fashion-MNIST总共有十个类别的图像。代码运行位置 CPU: cputf.config.set_visible_devices(tf.config.list_physical_devices("CPU"))fashion_mnist keras.datasets.fashion_mnist # fashion_mnist 数据导入训练数据和测试数据拆分: x_valid, x_train…...
【正点原子FPGA连载】第二十二章IP封装与接口定义实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第二十二章IP封装…...

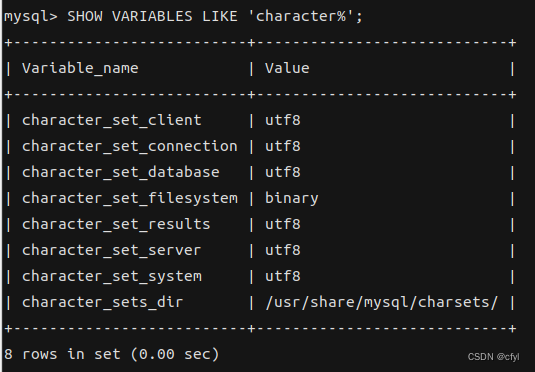
【ElasticSearch8.X】学习笔记(二)
【ElasticSearch8.X】学习笔记四、基础操作4.1、索引操作4.1.1、创建索引4.1.2、查询指定索引4.1.3、查询所有索引4.1.4、 删除索引4.2、文档操作4.2.1、创建文档4.2.2、查询文档4.2.3、修改文档4.2.4、删除文档4.2.5、查询所有文档4.3、数据搜索4.3.1、匹配查询文档4.3.2、匹配…...
Ubuntu22.04安装、配置、美化、软件安装、配置开发环境
Ubuntu22.04安装、配置、美化、软件安装、配置开发环境 一、Ubuntu、Windows11(10)双系统安装 因为ubuntu的安装网上的教程特别多了,所以这里不做赘述,推荐使用小破站这个up主的教程:Windows 和 Ubuntu 双系统从安装到…...

企业电子招投标采购系统之系统的首页设计
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为…...
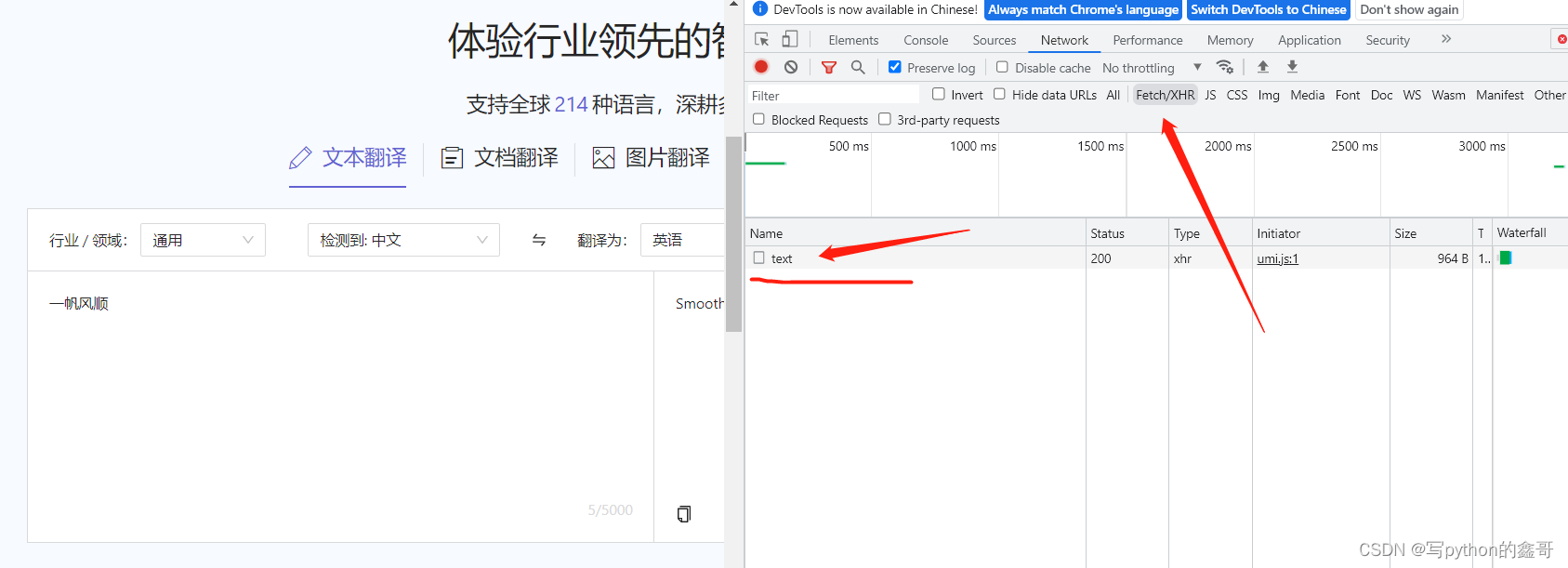
Python爬虫-阿里翻译_csrf
前言 本文是该专栏的第37篇,后面会持续分享python爬虫干货知识,记得关注。 笔者在前面有介绍过百度翻译的案例,感兴趣的同学,可往前翻阅查看(JS逆向-百度翻译sign)。而本文,笔者要介绍的是阿里翻译,相对于百度翻译的参数被逆向需要花点时间,阿里相对于易上手。 下面…...

C语言实现三子棋【详解+全部源码】
大家好,我是你们熟悉的恒川 今天我们用C语言来实现三子棋 实现的过程很难,但我们一定要不放弃 三子棋1. 配置运行环境2. 三子棋游戏的初步实现2.1 建立三子棋分布模块2.2 创建一个名为board的二维数组并进行初始化2.3 搭建棋盘3. 接下来该讨论的事情3.1 …...
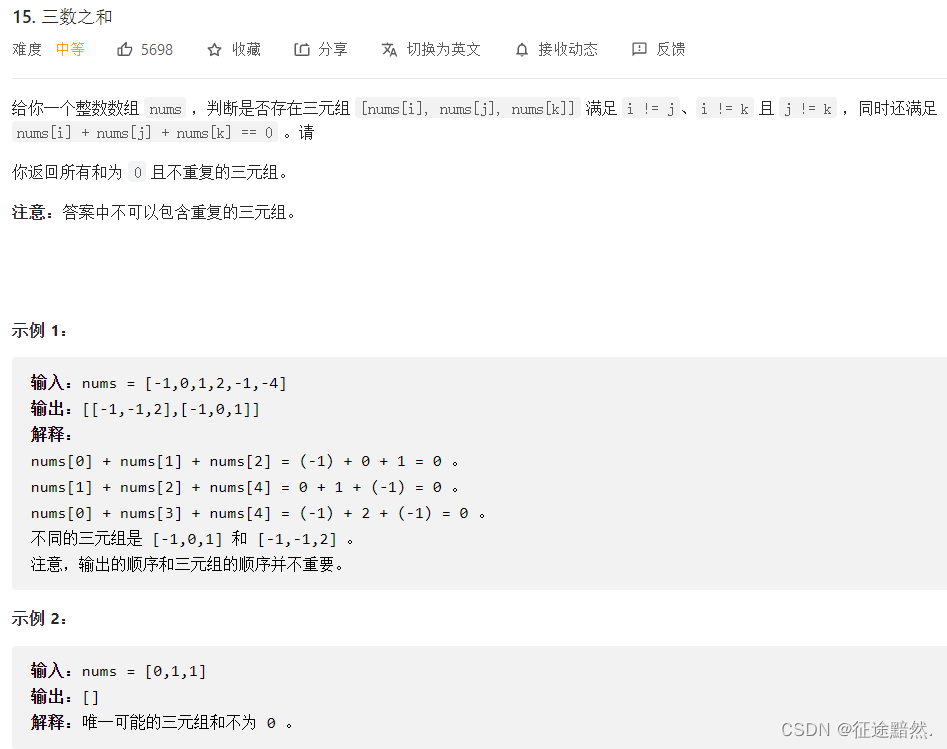
双指针法将时间复杂度从 O(n^2) 优化到 O(n)
[1] 什么是双指针法 双指针法(Two Pointers)是一种常见的算法技巧,常用于数组和链表等数据结构中。 双指针法的基本思想是维护两个指针,分别指向不同的位置,通过它们的移动来解决问题。在某些情况下,使用双…...

【SpringBoot系列】 Spring中自定义Session管理,Spring Session源码解析
系列文章:Spring Boot学习大纲,可以留言自己想了解的技术点 目录 系列文章:Spring Boot学习大纲,可以留言自己想了解的技术...
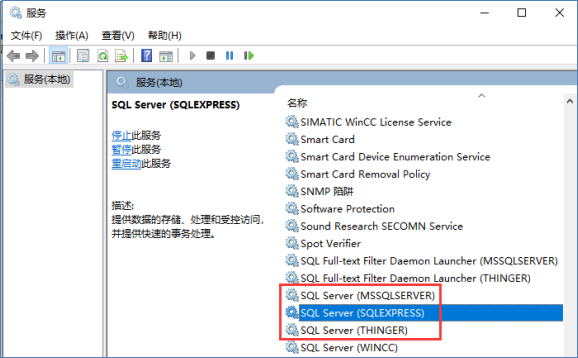
【上位机入门常见问题】SQLServer2019 安装指导
SQLServer2019 安装指导 这里要说一下SQLServer的版本问题,首先说纵向的高低版本,如果大家跟我学习,我教给大家的是T-SQL编程的方法,而不是直接操作菜单的方法,所以,我们学习中只要使用SQLServer2012或以上…...
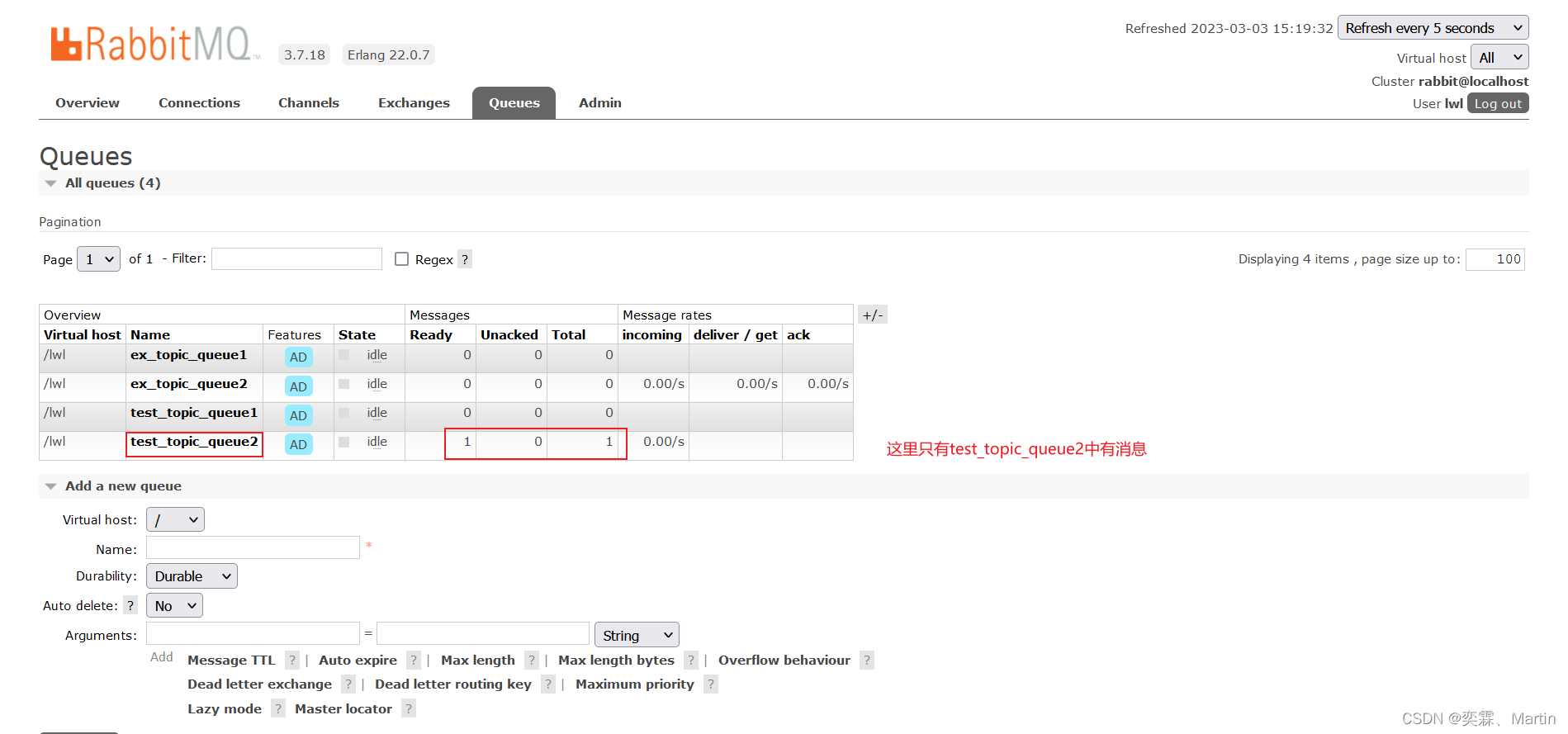
RabbitMQ第一讲
目录 一、RabbitMQ-01 1.1 MQ概述 1.2 MQ的优势和劣势 1.2.1 优势 1.2.2 劣势 1.2.3 MQ应用场景 1.2.4 常用的MQ产品 1.3 RabbitMQ的基本介绍 1.3.1 AMQP介绍 1.3.2 RabbitMQ基础架构 1.3.3 RabbitMQ的6种工作模式 编辑 1.4 AMQP和JMS 1.4.1 AMQP 1.4.2 JMS …...
华为机试题:HJ100 等差数列(python)
文章目录(1)题目描述(2)Python3实现(3)知识点详解1、input():获取控制台(任意形式)的输入。输出均为字符串类型。1.1、input() 与 list(input()) 的区别、及其相互转换方…...

数据推荐 | 人体行为识别数据集
人体行为识别任务旨在通过对人体姿态进行分析,识别出人体的具体动作,为人体行为预测、突发事件处理、智能健身、智能看护等领域提供技术支持。 图片 图片 人体行为识别数据标注方式 人体行为数据通用的标注方式包括人体关键点标注和动作标签标注&#…...

667真题分析 | 2023年667真题简要分析和答题思路参考
2023年667真题简要分析和答题思路参考 文章目录 2023年667真题简要分析和答题思路参考前言1. 名词解释2. 简答题3. 分析题3.1 答题框架(套路)3.2 答题框架实战3.2.1 图书情报档案事业如何在文化自信、文化强国中发挥自己的地位和作用3.2.2 高校图书馆如何发挥空间资源的功能和…...

配置 Docker 使用 GPU
准备工作 首先你需要准备一台拥有GPU的实例,在这里我将使用阿里云的竞价实例来做演示,因为它对于短期使用GPU更加划算。 注意,本篇文章将教你手动进行GPU驱动的配置,所以在购买时选择系统的时候不要选择自动安装GPU驱动。 具体关…...

「并发编程实战」常见的限流方案
「并发编程实战」常见的限流方案 文章目录「并发编程实战」常见的限流方案一、概述二、计数器限流方案三、时间窗口限流方案四、令牌桶限流方案五、漏桶限流方案六、高并发限流算法小结文章参考: 追忆四年前:一段关于我被外企CTO用登录注册吊打的不堪往事…...

IO 复习
IO 把电脑硬盘中的数据读到程序中,称为输入,进行数据的read操作 把程序往外部设备写数据,称为输出,进行数据的write操作 File类 一个File对象可以表示计算机硬盘上的一个文件或目录(文件夹) 可以获取文件信息,创建文件,删除文件 但是不能对文件中的数据进行读写操作 一些…...

什么是项目管理
项目管理(简称PM),就是将知识、技能、工具与技术应用于项目活动,以满足项目的要求。项目管理通过合理运用与整合特定项目所需的项目管理过程得以实现。项目管理使组织能够有效且高效地开展项目 “现代管理,项目就是一切…...

什么是入站营销?如何向合适的受众推销
没有什么比入站营销更有效地优先考虑客户体验了。 入站营销可为您的客户在他们需要的时间和地点准确提供他们想要的东西。它以最有机的方式在您的行业中建立信任、忠诚和权威。 什么是入站营销? 入站营销是一种商业方法,可提供优质内容和量身定制的客户…...

Qt 崩溃 corrupted double-linked list Aborted
文章目录摘要1 使用全局静态变量2 不取第一个和最后一个数3 将数据计算放到同一线程计算4 替换槽函数5 修改传值为const6 神奇的环境因素7 更神奇的板子差异8 另一个细节Aborted最后关键字: Qt、 Aborted、 corrupted、 double、 linked 摘要 额,结论&…...
)
别再硬改CSS了!ElementUI el-table透明背景的3种正确姿势(含Vue2/Vue3避坑指南)
别再硬改CSS了!ElementUI el-table透明背景的3种正确姿势(含Vue2/Vue3避坑指南) 在深色主题或背景融合的现代Web应用中,ElementUI的el-table组件默认的白色背景常常成为视觉设计的绊脚石。许多开发者第一反应是直接修改CSS文件&am…...

基于Vue 3与Express的私有化ChatGPT Web客户端部署指南
1. 项目概述与核心价值最近在折腾一个自用的AI对话工具,核心需求很简单:想在一个自己完全掌控的界面上,方便地使用大语言模型,比如ChatGPT的API。市面上虽然有很多现成的网页应用,但要么功能太臃肿,要么部署…...

逆向实战:从异或表到明文存储,我是如何让Eternium的游戏数据‘裸奔’的
逆向工程实战:解密游戏数据存储的核心逻辑 在数字娱乐时代,游戏安全机制与逆向分析技术之间的博弈从未停止。对于技术爱好者而言,理解游戏如何保护其核心数据不仅是一次智力挑战,更是深入了解计算机系统底层运作的绝佳机会。本文将…...

VisualCppRedist AIO:告别DLL错误,Windows系统必备的一体化运行库解决方案
VisualCppRedist AIO:告别DLL错误,Windows系统必备的一体化运行库解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打…...
实现大数组和GUI缓存)
告别内存焦虑:用STM32+外部SRAM(IS62WV51216)实现大数组和GUI缓存
STM32外部SRAM实战:突破内存限制的工程化解决方案 当你在STM32上开发图形界面或处理音频流时,是否遇到过程序突然崩溃的窘境?那些隐藏在编译通过背后的内存溢出问题,往往在项目后期才暴露出来。最近接手的一个智能家居控制面板项目…...

从零到一:手把手教你搭建MinGW-w64开发环境
1. 为什么需要MinGW-w64开发环境 第一次在Windows上写C代码时,我踩了个大坑:好不容易写完的代码,发现根本没法编译运行。这才意识到Windows不像Linux自带GCC编译器,需要额外搭建开发环境。MinGW-w64就是解决这个问题的神器&#x…...

从微波炉到激光加工:手把手教你用COMSOL搞定4种电磁加热的仿真设置
从微波炉到激光加工:COMSOL电磁加热仿真实战指南 电磁加热技术早已渗透进现代工业与生活的每个角落——从家用微波炉的磁控管震荡,到新能源汽车电池的感应焊接,再到精密医疗器械的激光切割。这些看似迥异的应用背后,都遵循着相同…...

如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南
如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch 还在为DS918…...

Windows掌机游戏体验终极优化指南:HandheldCompanion完全教程
Windows掌机游戏体验终极优化指南:HandheldCompanion完全教程 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否曾经在Windows掌机上玩游戏时,因为缺乏原生控制器支持…...

基于树莓派与ChatGPT打造私有智能音箱:从硬件选型到AI集成全攻略
1. 项目概述:打造一个会思考的智能音箱 如果你和我一样,对智能家居充满热情,但又对市面上那些“大厂”智能音箱的隐私策略和有限的对话能力感到不满,那么这个项目可能就是为你量身定做的。今天要聊的,是一个完全由自己…...