机器学习-基于Word2vec搜狐新闻文本分类实验
机器学习-基于Word2vec搜狐新闻文本分类实验
实验介绍
Word2vec是一群用来产生词向量的相关模型,由Google公司在2013年开放。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应用研究提供了新的工具。
Word2vec模型为浅而双层的神经网络,网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
实验要求
本实验主要基于Word2vec来实现对搜狐新闻文本分类,大致步骤如下。
1.数据准备
数据集下载地址 密码: hq5v
训练集共有24000条样本,12个分类,每个分类2000条样本。
测试集共有12000条样本,12个分类,每个分类1000条样本。
2.word2vec模型(可以使用Word2Vec原代码库)
完成此步骤需要先安装gensim库,安装命令:pip install gensim
3.特征工程
对于每一篇文章,获取文章的每一个分词在word2vec模型的相关性向量。然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量。
实验代码及结果展示
import pandas as pd
import jieba
import time
from gensim.models import Word2Vec
import warnings
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()
for name, group in train_df.groupby(0):print(name,len(group))test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):print(name, len(group))train_df.columns = ['分类', '文章']
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
for article in train_df['文章']:cutWords = [k for k in jieba.cut(article) if k not in stopword_list]i += 1if i % 1000 == 0:print('前%d篇文章分词共花费%.2f秒' % (i, time.time() - startTime))cutWords_list.append(cutWords)with open('cutWords_list.txt', 'w') as file:for cutWords in cutWords_list:file.write(' '.join(cutWords) + '\n')with open('cutWords_list.txt') as file:cutWords_list = [k.split() for k in file.readlines()]word2vec_model = Word2Vec(cutWords_list, size=100, iter=10, min_count=20)warnings.filterwarnings('ignore')word2vec_model.wv.most_similar('摄影')word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)word2vec_model.save('word2vec_model.w2v')
import numpy as np
import time def getVector_v1(cutWords, word2vec_model):count = 0article_vector = np.zeros(word2vec_model.layer1_size)for cutWord in cutWords:if cutWord in word2vec_model:article_vector += word2vec_model[cutWord]count += 1return article_vector / countstartTime = time.time()
vector_list = []
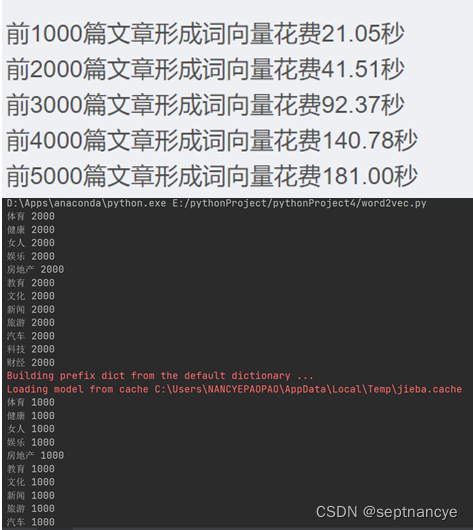
i = 0
for cutWords in cutWords_list[:5000]:i += 1if i % 1000 ==0:print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))vector_list.append(getVector_v1(cutWords, word2vec_model))
X = np.array(vector_list)结果展示
用numpy的mean方法计算
import time
import numpy as npdef getVector_v3(cutWords, word2vec_model):vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]cutWord_vector = np.array(vector_list).mean(axis=0)return cutWord_vectorstartTime = time.time()
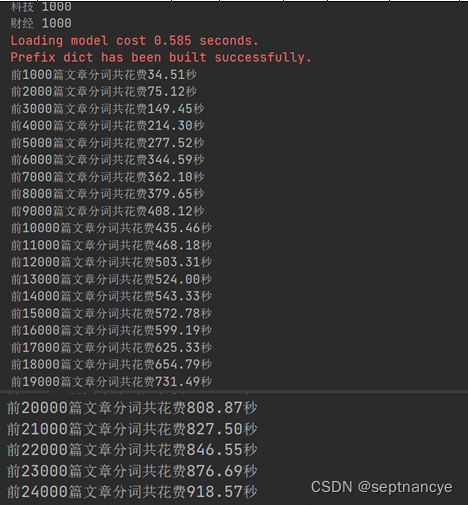
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:i += 1if i % 1000 ==0:print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))vector_list.append(getVector_v3(cutWords, word2vec_model))
X = np.array(vector_list)结果展示

逻辑回归模型
调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
调用sklearn.model_selection库的train_test_split方法划分训练集和测试集。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splittrain_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegression()
logistic_model.fit(train_X, train_y)
logistic_model.score(test_X, test_y)
结果为:0.7825
5.模型测试
import pandas as pd
import numpy as np
from sklearn.externals import joblib
import jieba def getVectorMatrix(article_series):return np.array([getVector_v3(jieba.cut(k), word2vec_model) for k in article_series])logistic_model = joblib.load('logistic.model')
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
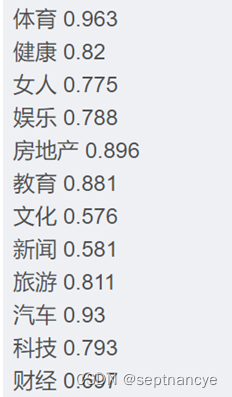
for name, group in test_df.groupby('分类'):featureMatrix = getVectorMatrix(group['文章'])target = labelEncoder.transform(group['分类'])
print(name, logistic_model.score(featureMatrix, target))结果展示
相关文章:
机器学习-基于Word2vec搜狐新闻文本分类实验
机器学习-基于Word2vec搜狐新闻文本分类实验 实验介绍 Word2vec是一群用来产生词向量的相关模型,由Google公司在2013年开放。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应…...
5.vue学习笔记(数组变化的侦测+计算属性+Class绑定)
文章目录 1.数组变化的侦测1.1.变更方法1.2.替换一个数组 2.计算属性计算属性缓存vs方法 3.Class绑定3.1.绑定对象3.2.多个对象的绑定形式3.3.绑定数组3.4.数组与对象 1.数组变化的侦测 1.1.变更方法 vue能够侦听响应式数组的变更方法,并在它们被调用时出发相关的…...

Java十种经典排序算法详解与应用
数组的排序 前言 排序概念 排序是将一组数据,依据指定的顺序进行排列的过程。 排序是算法中的一部分,也叫排序算法。算法处理数据,而数据的处理最好是要找到他们的规律,这个规律中有很大一部分就是要进行排序,所以需…...

git常用命令及概念对比
查看日志 git config --list 查看git的配置 git status 查看暂存区和工作区的变化内容(查看工作区和暂存区有哪些修改) git log 查看当前分支的commit 记录 git log -p commitID详细查看commitID的具体内容 git log -L :funcName:fileName 查看file…...

57、python 环境搭建[for 计算机视觉从入门到调优项目]
从本节开始,进入到代码实战部分,在开始之前,先简单进行一下说明。 代码实战部分,我会默认大家有一定的编程基础,不需要对编程很精通,但是至少要会 python 的基础语法、python 环境搭建、pip 的使用;C++ 要熟悉基础知识和基础语法,会根据文章中的步骤完成 C++ 的环境搭…...
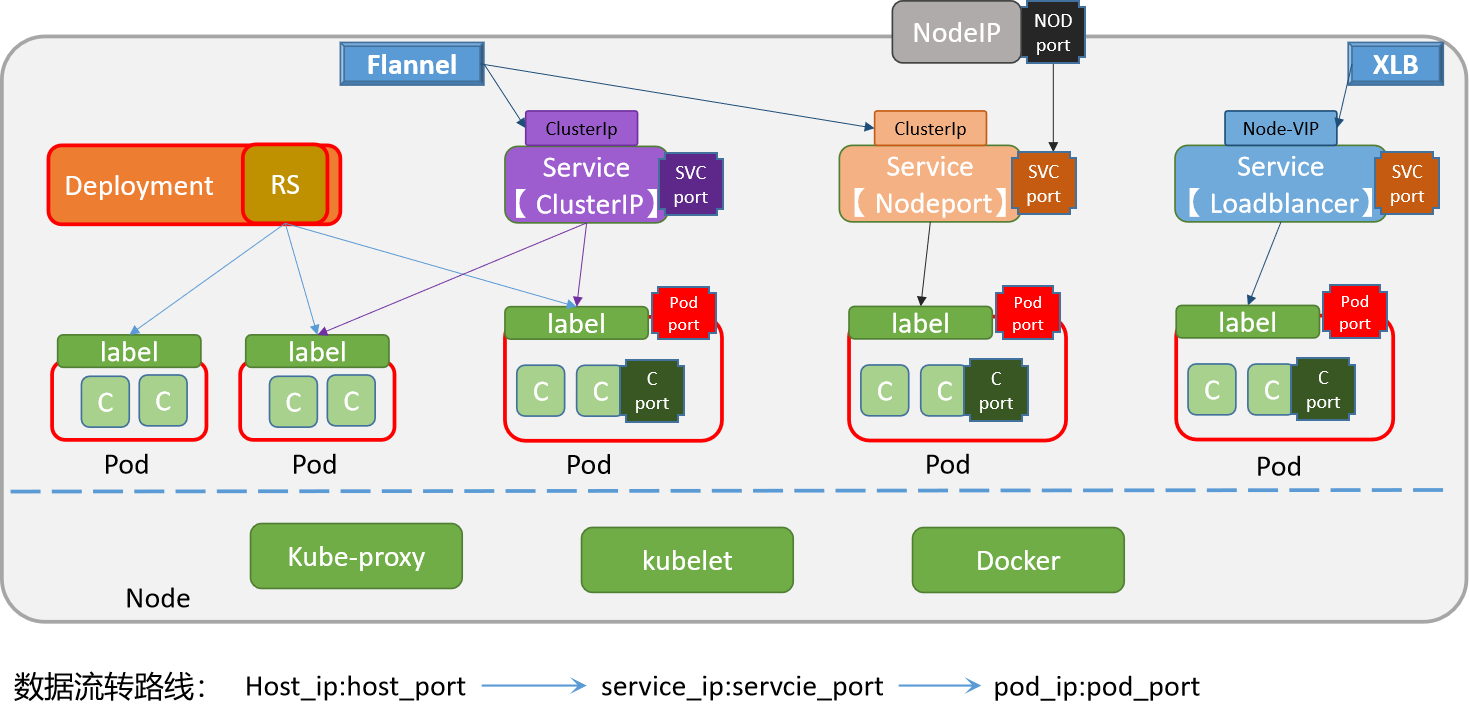
K8S-应用访问
1 service对象定位 2 Service 实践 手工创建Service 根据应用部署资源对象,创建SVC对象 kubectl expose deployment nginx --port80 --typeNodePortyaml方式创建Service nginx-web的service资源清单文件 apiVersion: v1 kind: Service metadata:name: sswang-ngi…...
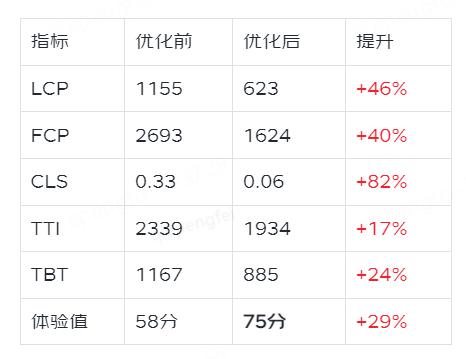
商智C店H5性能优化实战
前言 商智C店,是依托移动低码能力搭建的一个应用,产品面向B端商家。随着应用体量持续增大,考虑产品定位及用户体验,我们针对性能较差页面做了一次优化,并取得了不错的效果,用户体验值(UEI&…...

Unity 使用 Plastic 同步后,正常工程出现错误
class Newtonsoft.Json.Linq.JToken e CS0433:类型"JToken"同时存在于"Newtonsoft.Json.Net20,Version3.5.0.0,Cultureneutral,,PublicKeyToken30ad4fe6b2a6aeed"和"Newtonsoft.Json, Version12.0.0.0,Cultureneutral,PublicKeyToken30ad4fe6b2a6aeed…...

详细设计文档该怎么写
详细设计文档是软件开发过程中的一个关键阶段,它为每个软件模块的实现提供了详细说明。这份文档通常在概要设计阶段之后编写,目的是指导开发人员如何具体实现软件的功能。以下是撰写详细设计文档的步骤和一些示例: 步骤和组成部分 引言 目的…...
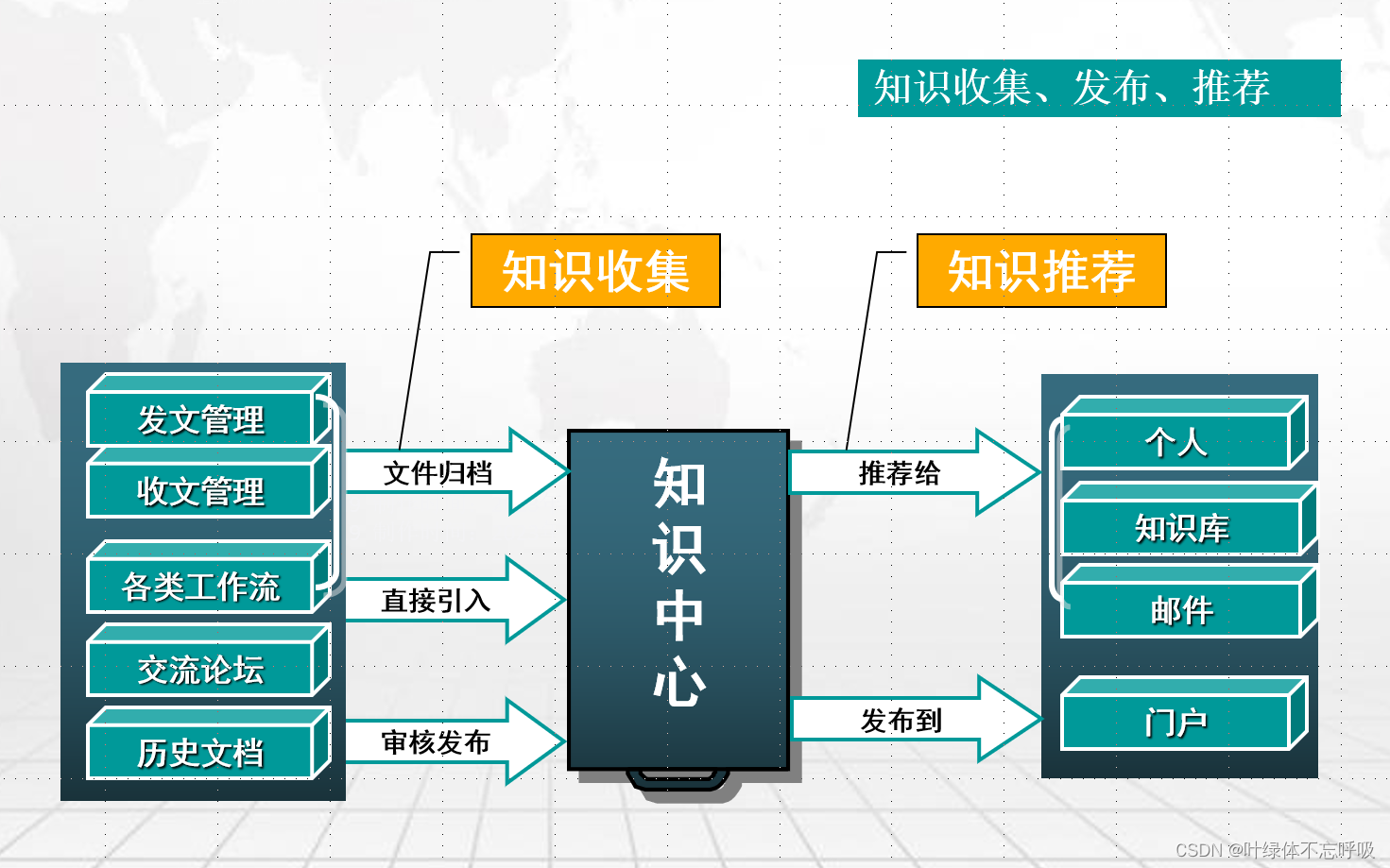
集团企业OA办公协同平台建设方案
一、企业对协同应用的需求分析 实现OA最核心、最基础的应用 业务流转:收/发文、汇报、合同等各种审批事项的业务协作与办理 信息共享:规章制度、业务资料、共享信息资源集中存储、统一管理 沟通管理:电子邮件、手机短信、通讯录、会议协作等…...

Spring Security之认证
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 Spring Security之认证 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、什么是Spring…...

智能语音机器人NXCallbot
受出海公司业务全球化的影响,智能客服逐渐从便捷应用变为市场刚需。新基建七大领域中,人工智能及场景应用的基础建设是最核心的领域,而智能客服作为商业化实际应用的核心场景之一,能提升企业运营效率,为行业客户赋能。…...

Vue 3中toRaw和markRaw的使用
Vue 3的响应性系统 在Vue 3中,响应性系统是构建动态Web应用程序的关键部分。Vue使用响应性系统来跟踪依赖关系,使数据更改能够自动更新视图。这使得Vue应用程序在数据变化时能够高效地更新DOM。Vue 3引入了新的Proxy对象来替代Vue 2中的Object.definePro…...

移动神器RAX3000M路由器不刷固件变身家庭云之三:外网访问家庭云
本系列文章: 移动神器RAX3000M路由器变身家庭云之一:开通SSH,安装新软件包 移动神器RAX3000M路由器变身家庭云之二:安装vsftpd 移动神器RAX3000M路由器变身家庭云之三:外网访问家庭云 移动神器RAX3000M路由器变身家庭云…...
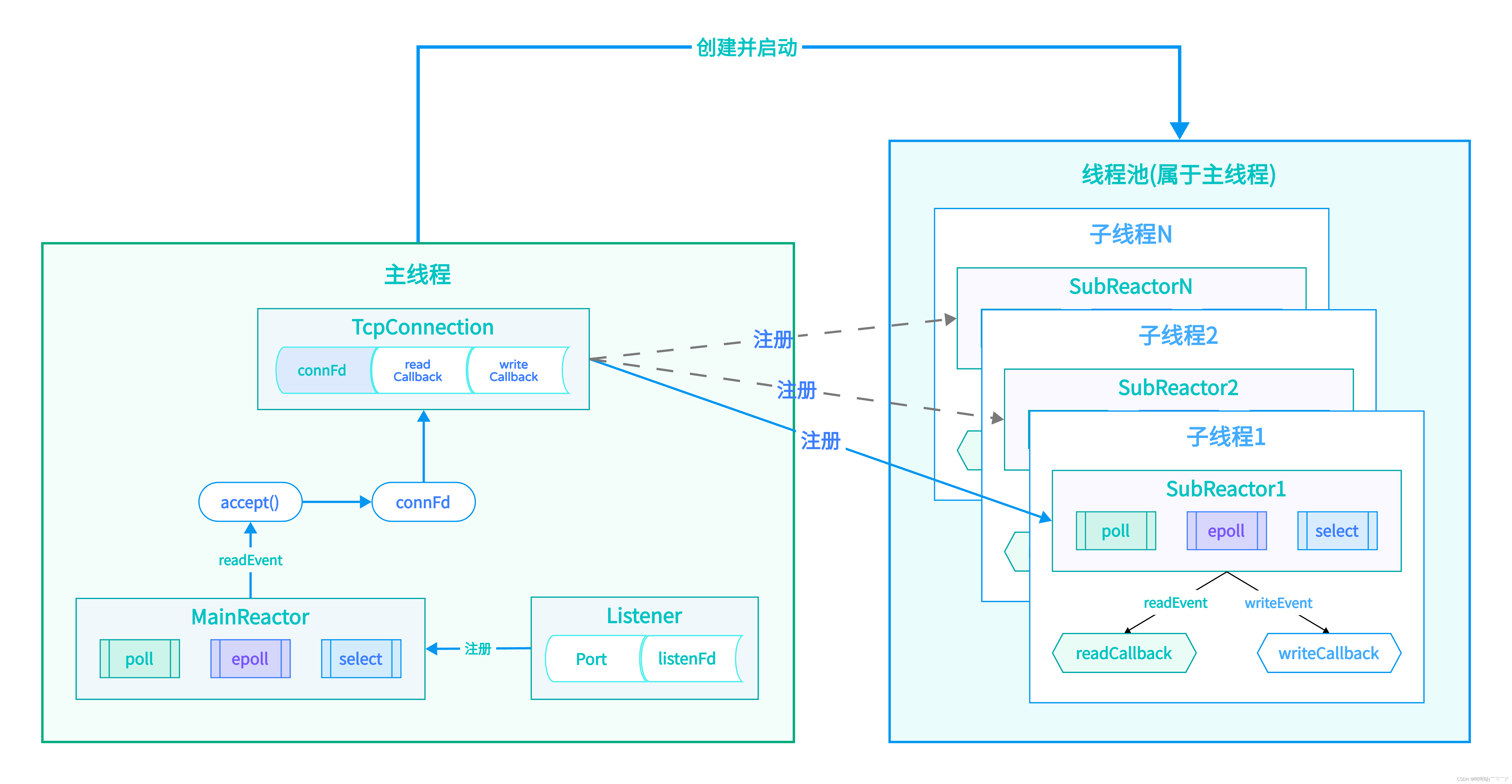
基于多反应堆的高并发服务器【C/C++/Reactor】(中)线程池的启动和从线程池中取出一个反应堆实例
一、线程池的启动 (主线程) // 启动线程池 (主线程) void threadPoolRun(struct ThreadPool* pool) {/*线程池被创建出来之后,接下来就需要让线程池运行起来,其实就是让线程池里的若干个子线程运行起来*//…...

go语言gin框架的基本使用
1.首先在linux环境上安装go环境,这个网上搜搜就行 2.初始化一个go mod,网上搜搜怎么初始化 3.下面go代码的网址和端口绑定自己本机的就行 4.与另一篇CSDN一起食用,效果更好哟---> libcurl的get、post的使用-CSDN博客 package mainimpo…...

TypeScript 从入门到进阶之基础篇(六) 类型(断言 、推论、别名)| 联合类型 | 交叉类型
系列文章目录 TypeScript 从入门到进阶系列 TypeScript 从入门到进阶之基础篇(一) ts基础类型篇TypeScript 从入门到进阶之基础篇(二) ts进阶类型篇TypeScript 从入门到进阶之基础篇(三) 元组类型篇TypeScript 从入门到进阶之基础篇(四) symbol类型篇TypeScript 从入门到进阶…...
:文件管理-文件属性命令)
Linux操作系统基础(14):文件管理-文件属性命令
1. 查看文件属性 stat命令用于显示文件的详细信息,包括文件的权限、所有者、大小、修改时间等。 #1.显示文件信息 stat file.txt#2.显示文件系统状态 stat -f file.txt#3.显示以时间戳的形式文件信息 stat -t file.txt2. 修改文件时间戳 touch命令用于创建新的空…...
metaSPAdes,megahit,IDBA-UB:宏基因组装软件安装与使用
metaSPAdes,megahit,IDBA-UB是目前比较主流的宏基因组组装软件 metaSPAdes安装 GitHub - ablab/spades: SPAdes Genome Assembler #3.15.5的预编译版貌似有问题,使用源码安装试试 wget http://cab.spbu.ru/files/release3.15.5/SPAdes-3.15.5.tar.gz tar -xzf SP…...

Apache、MySQL、PHP编译安装LAMP环境
1. 请简要介绍一下LAMP环境。 LAMP环境是一个在Linux操作系统上搭建的服务器环境组合,由Apache、MySQL、PHP三种软件构成。这种环境是开源的,跨平台的,并且由于各组件经常一起使用,因此具有高度的兼容性。 其中,Apac…...

用Circuit Playground Express制作可穿戴互动闪光T恤:零焊接图形化编程入门
1. 项目概述:一件会“跳舞”的闪光T恤几年前,当我第一次把微控制器缝进衣服里时,那感觉既兴奋又麻烦——满桌子的电线、烙铁,还有对洗衣机深深的恐惧。但现在,像Adafruit的Circuit Playground Express(后面…...

神经网络建筑负荷预测与供暖优化【附程序】
✨ 长期致力于BP神经网络、负荷预测、空气源热泵、优化控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于BP神经网络的公共建筑热负荷预测模型&…...

Android Studio中文界面终极指南:3个步骤告别英文开发障碍
Android Studio中文界面终极指南:3个步骤告别英文开发障碍 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Andr…...

Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍
更多请点击: https://intelliparadigm.com 第一章:Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍 该方案通过在 Claude API 请求链路中注入轻量级 RAG 中间件,无需修改业务侧任何模型…...

Word里MathType插件报错?别慌,手把手教你搞定MathPage.wll文件丢失问题
Word里MathType插件报错?三步精准定位MathPage.wll文件问题 当你正全神贯注地在Word中编辑数学公式,突然弹出一个刺眼的错误提示:"无法找到MathPage.wll文件"——这种突如其来的技术故障足以打断任何人的工作节奏。作为科研工作者、…...

嵌入式Linux SPI转CAN-FD扩展实战:基于i.MX8MP与MCP2518FD
1. 项目概述:当开发板的CAN口不够用时在嵌入式产品开发中,尤其是工业控制、汽车电子或机器人领域,CAN总线因其高可靠性和实时性被广泛应用。飞凌嵌入式的OKMX8MP-C开发板基于强大的i.MX8M Plus处理器,原生提供了两路CAN-FD总线&am…...

J-Link V8变砖别慌!手把手教你用SAM-BA 2.14救活AT91SAM7S64芯片
J-Link V8救砖实战:用SAM-BA 2.14拯救AT91SAM7S64芯片全指南 当你的J-Link V8调试器突然"变砖"——LED灯熄灭、电脑无法识别、所有功能瘫痪时,那种感觉就像外科医生在手术台上突然失去所有仪器。但别急着宣布它的"死亡",…...

小红书内容采集神器:XHS-Downloader免费开源工具完全指南
小红书内容采集神器:XHS-Downloader免费开源工具完全指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

c++ 端口扫描程序实现案例
第一、原理端口扫描的原理很简单,就是建立socket通信,切换不通端口,通过connect函数,如果成功则代表端口开发者,否则端口关闭。所有需要多socket程序熟悉,本内容是在window环境下的第二、单线程实现方式123…...

MegSpot视觉对比工具:3个专业级视觉分析难题的终极解决方案
MegSpot视觉对比工具:3个专业级视觉分析难题的终极解决方案 【免费下载链接】MegSpot MegSpot是一款高效、专业、跨平台的图片&视频对比应用 项目地址: https://gitcode.com/gh_mirrors/me/MegSpot 作为一名视觉内容创作者或质量检测人员,你是…...