LLM之RAG实战(十三)| 利用MongoDB矢量搜索实现RAG高级检索
想象一下,你是一名侦探,身处庞大的信息世界,试图在堆积如山的数据中找到隐藏的一条重要线索,这就是检索增强生成(RAG)发挥作用的地方,它就像你在人工智能和语言模型世界中的可靠助手。但即使是最好的助理也有其局限性,因此,让我们开始探索RAG的高级方法,重点关注大规模文档检索中的精度和上下文。
一、基本RAG
想象一下,有一本和地平线一样宽百科全书。基本的RAG试图将这些丰富的知识提炼成一个单一的“嵌入”——本质上是一个数字。但是,当你在一个特定的主题上寻求智慧时,比如神秘的百慕大三角,基本的RAG的粗笔画会覆盖更多细节,给你留下一幅不完整的画面。这种限制就像试图用一张只显示大陆的地图来寻找隐藏的宝藏,而不是通往标有“X”的地点的复杂路径。
另一方面,如果我们只拥有带有嵌入的单个页面,我们可能会找出具体的事实,但当它们交织在一起时,我们就会失去它们所讲述的故事。如果没有叙事,大型语言模型(LLM)很难找到一个能抓住我们探究的真正本质的答案。
基本RAG,虽然是一个值得称赞的里程碑,但没有做的更好。基本RAG只是一个基础,需要跨越通用知识和精确见解之间的距离,我们需要做更细致的优化工作。
二、路径的细化:父子文档关系
我们不是对整个百科全书进行单一的总结,而是为每一页(子文档)进行简洁的概述,注意包含的章节(父文档)。该方法在我之前的LLM之RAG实战(五)| 高级RAG 01:使用小块检索,小块所属的大块喂给LLM,可以提高RAG性能博客中有所介绍,这里略过。
2.1 步骤1:父子文档关系
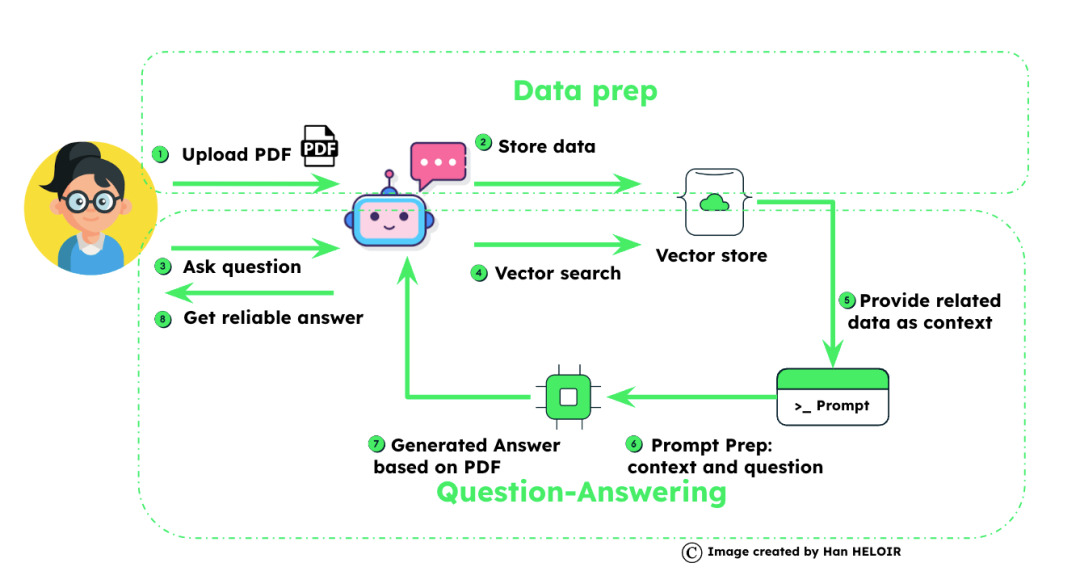
想象一下,你有一本又大又笨重的书——一本关于所有电器的用户手册。现在,有人问了一个特定的问题:“为什么我的洗衣机显示错误代码2?”,对于基本的RAG,我们要么得到缺乏上下文的小块,要么得到搜索不够准确的大块。然而,高级RAG采用了更聪明的方法。
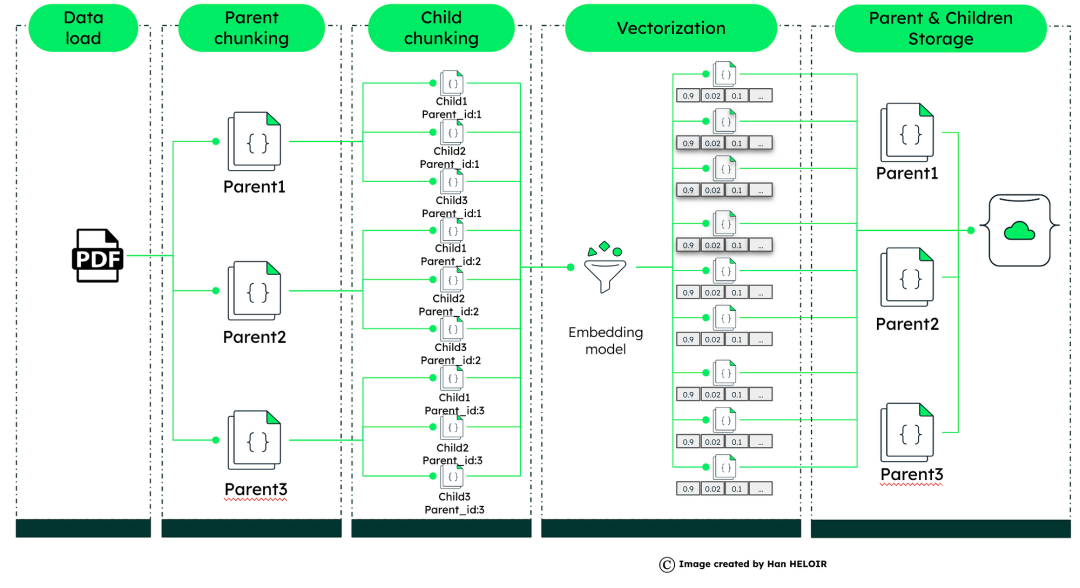
首先,手册被分解成大块——这些是我们的“父”文档。每一节都涉及更大的信息。在这些部分中,我们拆分了涵盖特定问题的“子”文档,如洗衣机的错误代码。
现在,来看看矢量化的魔力。每个子文档都通过嵌入模型进行处理,该模型分析文本并将其转换为向量——一系列表示文本本质的数字。这就像为每一小段信息创建一个DNA图谱。
每个子文档的文本都被提取到一个向量中,然后将其存储在向量存储中,其父文档也存储在这个向量存储中——这也是一个通用数据库。这使我们不仅可以快速检索最相关的小信息,还可以保留父文档提供的上下文。
2.2 步骤二:问答
当关于洗衣机的问题出现时,它就变成了一个“嵌入”——把它想象成一个独特的数字签名。然后使用矢量搜索将这些嵌入与类似的子文档进行匹配。如果它与“洗衣机”部分的子文档嵌入紧密对齐,我们就找到了匹配项。
有了我们的矢量存储和准备,当出现问题时,我们可以迅速找到最相关的子文档。但是,我们没有提供狭义的回应,而是引入了母文档,它提供了更多的背景和上下文。这个准备好的提示富含特定信息和广泛的上下文,然后被输入到大型语言模型(LLM)中,该模型生成精确的上下文感知答案。
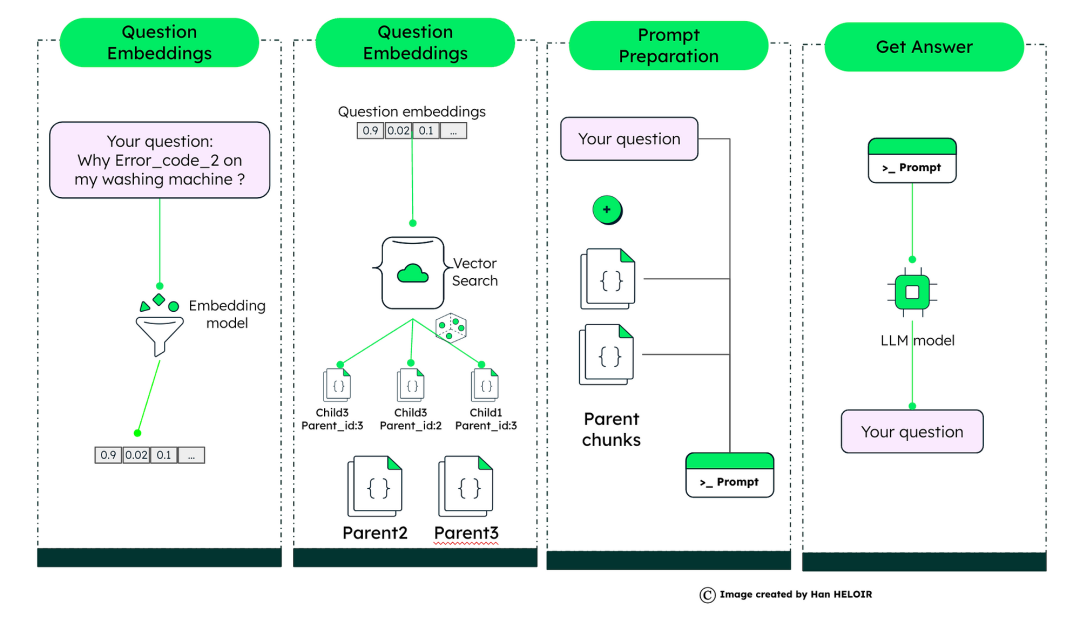
如图所示,这种先进的RAG过程确保LLM具有生成准确响应所需的所有上下文,就像侦探拼凑线索来解开谜团一样。借助MongoDB矢量搜索的强大功能,我们可以以超级计算机的速度和精度浏览这一过程,确保每个问题都得到尽可能好的答案。
三、MongoDB矢量搜索:高级RAG背后的动力
从父子关系和矢量化的复杂关系中走出来,我们直接进入了MongoDB的矢量搜索领域,该引擎为我们的高级RAG过程提供了动力。让我们深入研究一下MongoDB矢量搜索是如何将筛选堆积如山的数据这一艰巨任务转变为一个精简高效的过程的。
3.1 矢量搜索:快速寻找答案
MongoDB中的矢量搜索就像在浩瀚的数据海洋中拥有一盏高功率探照灯。当我们的洗衣机爱好者询问那个令人讨厌的错误代码时,矢量搜索不仅仅是梳理数据,它还可以精确定位信息的确切位置,这要归功于我们早些时候创建的独特的“数字签名”。最棒的部分?它以惊人的速度做到了这一点,使得搜索答案的速度就像翻阅一个组织良好的文件柜一样快。
3.2 结构与速度想结合
MongoDB的矢量搜索将结构和速度和谐地结合在一起。父文档和子文档的存储,以及它们的矢量化本质,使MongoDB能够快速识别最相关的数据片段,而不会被不太相关的信息所困扰。这是一位一丝不苟的图书管理员和一位侦探大师的完美结合,确保了没有遗漏任何线索,每个答案都切中要害。
3.3 语境丰富性:增加的层次
在这里,事情变得更加有趣。一旦矢量搜索精确定位了相关的子文档,它就不会止步于此。通过检索父文档,它确保了上下文的丰富性不会丢失。这意味着我们的LLM不仅了解“什么”,还了解“为什么”和“如何”,提供了超出表面水平的答案。
3.4 MongoDB:不仅仅是一个数据库
MongoDB不仅仅是一个存储数据的地方;这是一个动态的生态系统,支持先进的RAG过程的每一步。它可以轻松管理复杂的父文档和子文档网络,并促进快速矢量搜索,使高级RAG功能强大。使用MongoDB,我们不仅仅是在寻找答案;我们正在制定既能提供信息又能与上下文相关的回应。
3.5 结果:知情、准确的回答
由于高级RAG和MongoDB矢量搜索之间的强大协作,生成的响应不仅准确,而且信息丰富。当我们的用户询问洗衣机上的错误代码时,他们会收到一个既准确又充满有用上下文的回复,类似于为他们量身定制的全面指南。
MongoDB矢量搜索是这一高级RAG过程的支柱,提供了在复杂的数据检索环境中导航所需的速度和精度。在下一节中,我们将探索这一过程的实际实施,展示如何将先进的RAG系统应用到生活中,为用户提供人工智能所能提供的最佳答案。请继续关注我们将理论转化为实践,并充分发挥先进RAG的潜力。
四、用MongoDB矢量搜索实现高级RAG
将Advanced RAG与MongoDB Vector Search集成到我们的系统中,首先是几个技术组件的和数据处理流程。下面看一下具体步骤:
4.1 步骤1:设置和初始化
我们通过设置环境和建立必要的联系来启动工作,这包括加载环境变量,初始化OpenAI和MongoDB客户端,以及定义我们的数据库和集合名称。
import osfrom dotenv import load_dotenvfrom pymongo import MongoClientfrom langchain.embeddings import OpenAIEmbeddings# Load environment variables from .env fileload_dotenv(override=True)# Set up MongoDB connection detailsOPENAI_API_KEY = os.environ["OPENAI_API_KEY"]MONGO_URI = os.environ["MONGO_URI"]DB_NAME = "pdfchatbot"COLLECTION_NAME = "advancedRAGParentChild"# Initialize OpenAIEmbeddings with the API keyembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)# Connect to MongoDBclient = MongoClient(MONGO_URI)db = client[DB_NAME]collection = db[COLLECTION_NAME]
4.2 步骤2:数据加载和分块
接下来,我们将重点处理作为数据源的PDF文档。文档被加载并拆分为“父”和“子”块,以准备嵌入和向量化。
from langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitter# Initialize the text splitters for parent and child documentsparent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)# Function to process PDF document and split it into chunksdef process_pdf(file):loader = PyPDFLoader(file.name)docs = loader.load()parent_docs = parent_splitter.split_documents(docs)# Process parent documentsfor parent_doc in parent_docs:parent_doc_content = parent_doc.page_content.replace('\n', ' ')parent_id = collection.insert_one({'document_type': 'parent','content': parent_doc_content}).inserted_id# Process child documentschild_docs = child_splitter.split_documents([parent_doc])for child_doc in child_docs:child_doc_content = child_doc.page_content.replace('\n', ' ')child_embedding = embeddings.embed_documents([child_doc_content])[0]collection.insert_one({'document_type': 'child','content': child_doc_content,'embedding': child_embedding,'parent_ref': parent_id})return "PDF processing complete"
4.3 步骤3:查询嵌入和矢量搜索
当提交查询时,我们将其转换为嵌入,并执行向量搜索以找到最相关的子文档,链接回它们的父文档以获取上下文。
# Function to embed a query and perform a vector searchdef query_and_display(query):query_embedding = embeddings.embed_documents([query])[0]# Retrieve relevant child documents based on querychild_docs = collection.aggregate([{"$vectorSearch": {"index": "vector_index","path": "embedding","queryVector": query_embedding,"numCandidates": 10}}])# Fetch corresponding parent documents for additional contextparent_docs = [collection.find_one({"_id": doc['parent_ref']}) for doc in child_docs]return parent_docs, child_docs
4.4 步骤4:通过上下文感知生成响应
在识别出相关文档后,我们为LLM创建一个提示,其中包括用户的查询和匹配文档中的内容。这确保了响应具有信息性和上下文相关性。
from langchain.llms import OpenAI# Initialize the OpenAI clientopenai_client = OpenAI(api_key=OPENAI_API_KEY)# Function to generate a response from the LLMdef generate_response(query, parent_docs, child_docs):response_content = " ".join([doc['content'] for doc in parent_docs if doc])chat_completion = openai_client.chat.completions.create(messages=[{"role": "user", "content": query}],model="gpt-3.5-turbo")return chat_completion.choices[0].message.content
4.5 第五步:串联所有组件
最后,我们将这些元素组合成一个连贯的界面,用户可以在其中上传文档并提出问题。这是使用Gradio实现的,它提供了一种用户友好的方式来与我们先进的RAG系统交互。
with gr.Blocks(css=".gradio-container {background-color: AliceBlue}") as demo:gr.Markdown("Generative AI Chatbot - Upload your file and Ask questions")with gr.Tab("Upload PDF"):with gr.Row():pdf_input = gr.File()pdf_output = gr.Textbox()pdf_button = gr.Button("Upload PDF")with gr.Tab("Ask question"):question_input = gr.Textbox(label="Your Question")answer_output = gr.Textbox(label="LLM Response and Retrieved Documents", interactive=False)question_button = gr.Button("Ask")question_button.click(query_and_display, inputs=[question_input], outputs=answer_output)pdf_button.click(process_pdf, inputs=pdf_input, outputs=pdf_output)demo.launch()
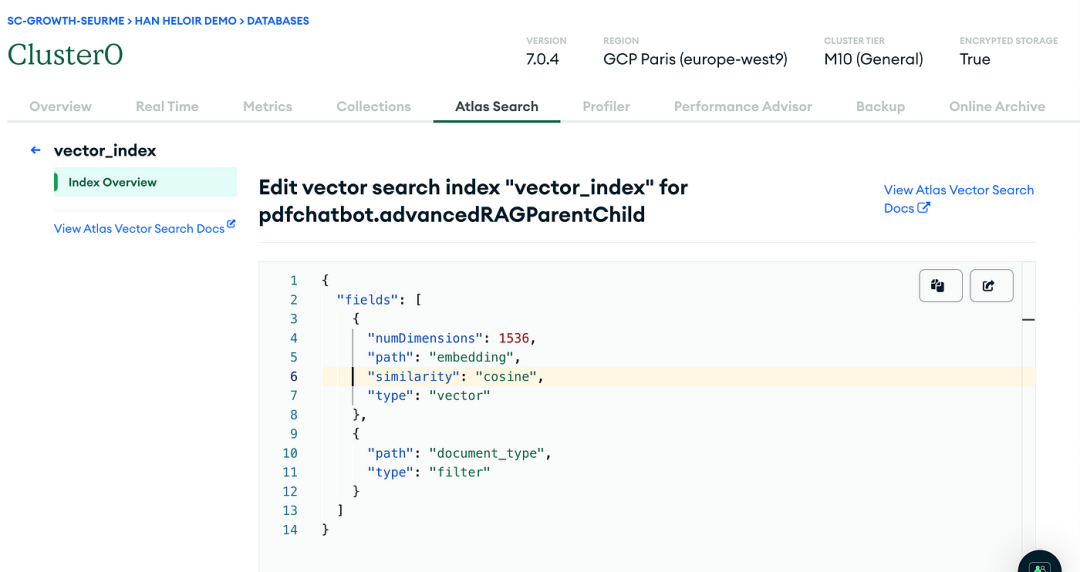
4.6 步骤6:在MongoDB Atlas上创建索引
{"fields": [{"numDimensions": 1536,"path": "embedding","similarity": "cosine","type": "vector"},{"path": "document_type","type": "filter"}]}
参考文献:
[1] https://ai.gopubby.com/byebye-basic-rag-embracing-advanced-retrieval-with-mongodb-vector-search-47b550be2c59
相关文章:
LLM之RAG实战(十三)| 利用MongoDB矢量搜索实现RAG高级检索
想象一下,你是一名侦探,身处庞大的信息世界,试图在堆积如山的数据中找到隐藏的一条重要线索,这就是检索增强生成(RAG)发挥作用的地方,它就像你在人工智能和语言模型世界中的可靠助手。但即使是最…...

UI动效设计师通往高薪之路,AE设计从基础到进阶教学
一、教程描述 UI动效设计,顾名思义即动态效果的设计,用户界面上所有运动的效果,也可以视其为界面设计与动态设计的交集,或者可以简单理解为UI设计中的动画效果,是UI设计中不可或缺的组成部分。现在UI设计的要求越来越…...

APK多渠道加固打包笔记之360加固宝
知识储备 首先需要知道V1,V2,V3签名的区别,可以参考之前的文章:AndroidV1,V2,V3签名原理详解 前言:一般开发者会指定使用自己创建的证书,如果没有指定,则会默认使用系统的证书,该默认的证书存储在C:\Users…...

编程天赋和努力哪个更重要?
编程天赋和努力在编程中都非常重要,但它们的侧重点不同。 编程天赋通常指的是与生俱来的、在逻辑思维、抽象思维、创造力等方面的能力,这些能力可以帮助程序员更快地理解问题、更高效地设计和实现解决方案。天赋的确可以帮助程序员更容易地入门和更快地掌…...
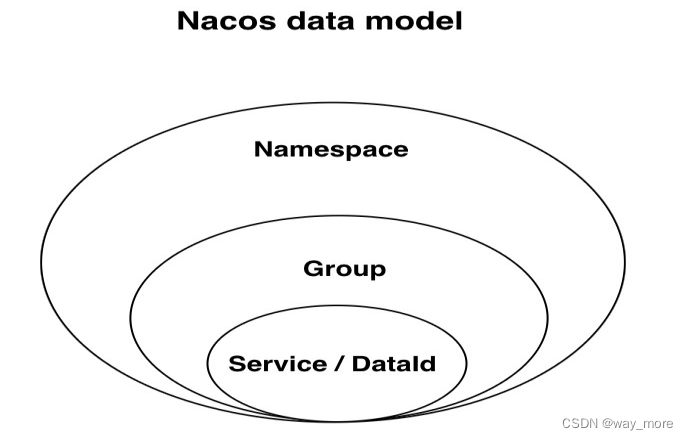
SpringCloud Alibaba之Nacos配置中心配置详解
目录 Nacos配置中心数据模型Nacos配置文件加载Nacos配置 Nacos配置中心数据模型 Nacos 数据模型 Key 由三元组唯一确定,三元组分别是Namespace、Group、DataId,Namespace默认是公共命名空间(public),分组默认是 DEFAUL…...

个人实际开发心得感悟及学习方法
前言 我的学习路线应该和大多数人的学习路线差不多,快速的学习完html和css,很多东西都没有记住的情况下就进入了js的学习,js学的懵懵懂懂就进入了node.js的基础学习和webpack的了解式学习,然后就跨度到了vue和react框架的学习。 节奏很快,学习的基础也极其不扎实。正如同那句…...
光速爱购--靠谱的SpringBoot项目
简介 这是一个靠谱的SpringBoot项目实战,名字叫光速爱购。从零开发项目,视频加文档,十天就能学会开发JavaWeb项目。 教程路线是:搭建环境> 安装软件> 创建项目> 添加依赖和配置> 通过表生成代码> 编写Java代码&g…...
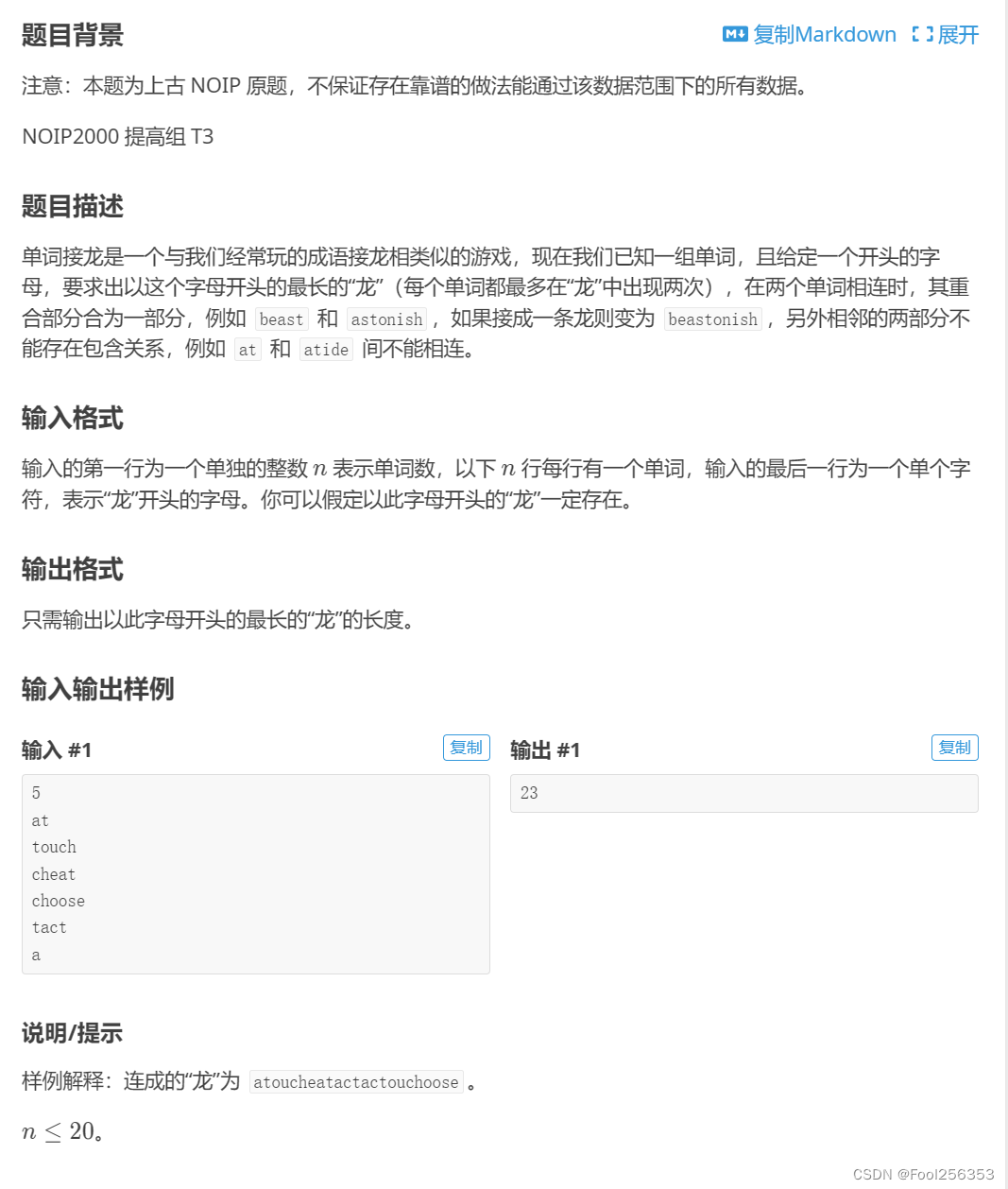
P1019 [NOIP2000 提高组] 单词接龙
网址如下:P1019 [NOIP2000 提高组] 单词接龙 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 很怪,不知道该说什么 我试了题目给的第一个测试点的输入,发现输出和测试点的一样,但是还是WA 不是很懂为什么 有没有大佬帮我看一下…...
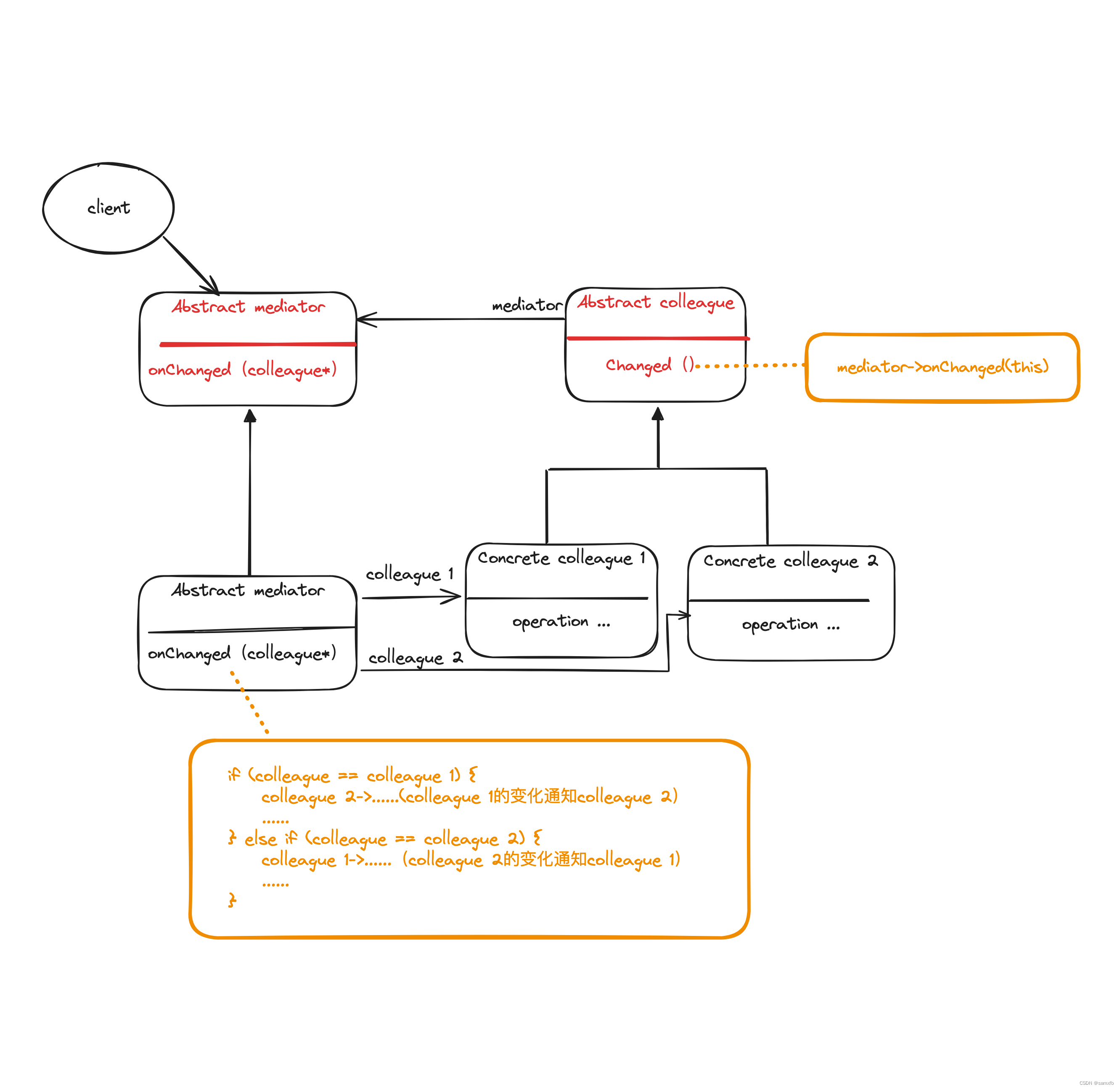
图解设计模式-中介者模式(Mediator)
中介者模式 定义 使用一个中介者对象(mediator)集中封装多个具有依赖/关联关系的对象(colleague,同事对象)之间的交互,使各对象之间不再互相引用,降低对象之间的强耦合程度,对象之…...
)
小程序面试问答(解决方案)
目录 问:uni-app 组件库的解决方案?(xx 分钟) 必答 加分 深入 再深入 参考链接 问:在 uni-app 中,如何进行全局状态管理?请介绍一下你对 Vuex 和 Pinia 的了解。 必答 加…...

qt第三天快速回顾
控件 listWidget 两种添加方式 1QListWidgetItem 2QStringList(链式编程) TreeWidget 核心代码 1设置头的标签 2.Item创建 添加顶层级别的Item 3.创建子Item 挂载到顶层的Item上 QLabelWidget 表格 增加了一个删除和添加 1.设…...

Android 编译过程介绍,Android.mk 和 Android.bp 分析, 在源码中编译 AndroidStudio 构建的 App
Android 编译过程介绍,Android.mk 和 Android.bp 分析, 在源码中编译 AndroidStudio 构建的 App_.mk编译目录所有.bp-CSDN博客...

【C++】几种常用的类型转换
类型转换 c语言中的类型转换C的类型转换static_castreinterpret_castconst_castdynamic_cast c语言中的类型转换 在C语言中我们经常会遇到类型转化的问题,主要分为两种:显式类型转换和隐式类型转换。 显式类型转换:就是程序员使用强制类型转…...
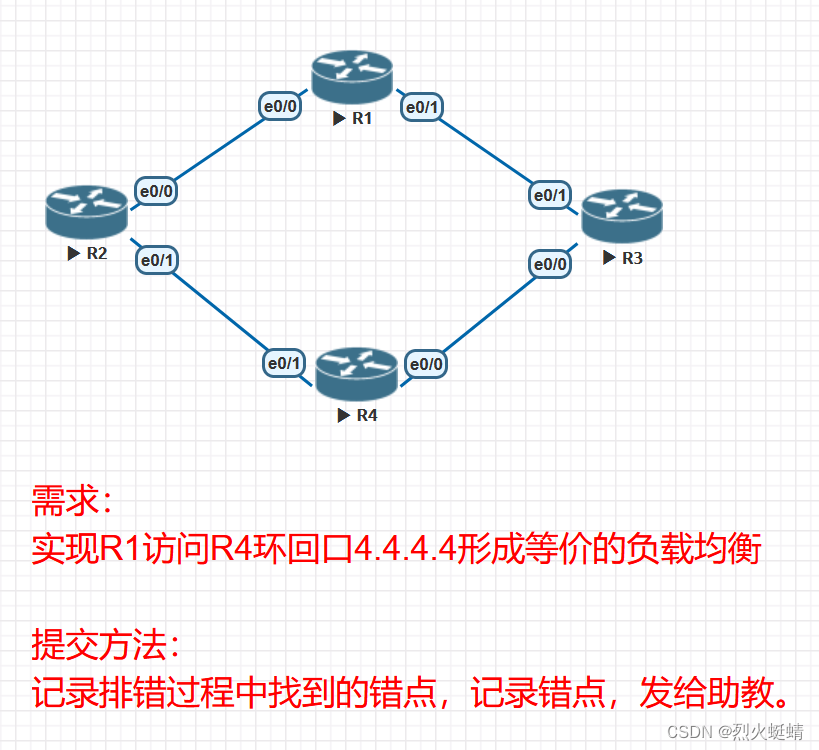
CCNP课程实验-07-OSPF-Trouble-Shooting
目录 实验条件网络拓朴 环境配置开始排错错点1:R1-R2之间认证不匹配错误2:hello包的时间配置不匹配错误3:R2的e0/1接口区域配置不正确错误4:R4的e0/1接口没有配置进OSPF错误5:R2的区域1没有配置成特殊区域错误6&#x…...
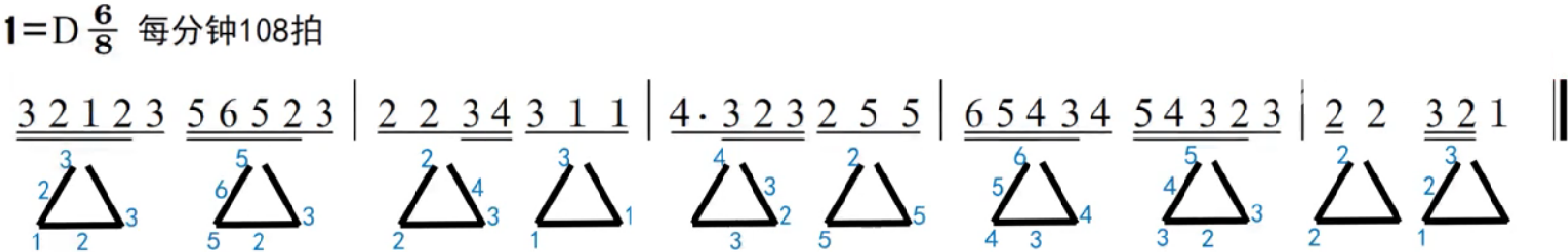
75.乐理基础-打拍子-八三、八六拍的三角形打法
内容来源于:三分钟音乐社 上一个内容:八几拍的V字打法-CSDN博客 在八几拍中几乎只会遇到八三和八六拍,它的V字打法,每个一拍都是一个V字,但是它还有某种程度上更方便的方式去打,按图1 八六拍的三角形&…...
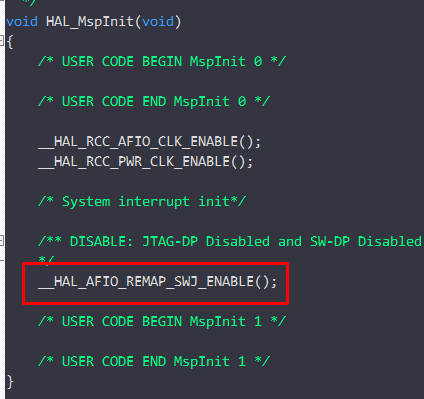
STLink下不了程序的解决办法
目录 1.检查物理接线是否正确 2.检查工程中用的引脚与这两个引脚是否有冲突 3.其次查看HAL_MspInit函数中是否使能SWJ 1.检查物理接线是否正确 2.检查工程中用的引脚与这两个引脚是否有冲突 stm32 swdio和swdclk引脚分别与stm32的PA13,PA14引脚相连 3.其次查看HA…...
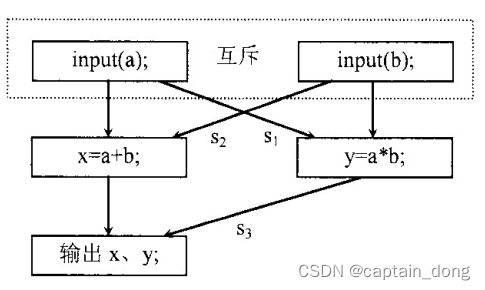
操作系统---期末应用综合题
目录 操作系统---期末应用综合题 操作系统---期末应用综合题 1. 若在一分页存储管理系统中,某作业的页表如表1所示。已知页面大小为1024字节,试将逻辑地址1011,5012(十进制数)转化为相应的物理地址。 表1…...
56K star!一键拥有跨平台 ChatGPT 应用:ChatGPT-Next-Web
前言 现在围绕 openai 的客户端层出不穷,各路开发大神可以说是各出绝招,我也试用过几个国内外的不同客户端。 今天我们推荐的开源项目是目前我用过最好的ChatGPT应用,在GitHub超过56K Star的开源项目:ChatGPT-Next-Web。 ChatGP…...

springMvc向request作用域存储数据的4种方式
文章目录 目录1、springmvc使用ServletAPI向request作用域共享数据(原生态)2、springmvc使用ModelAndView向request作用域共享数据3、springmvc使用Model向request作用域共享数据4、springmvc使用map向request作用域共享数据5、springmvc使用ModelMap向r…...
SolidUI Gitee GVP
感谢Gitee,我是一个典型“吃软不吃硬”的人。奖励可以促使我进步,而批评往往不会得到我的重视。 我对开源有自己独特的视角,我只参与那些在我看来高于自身认知水平的项目。 这么多年来,我就像走台阶一样,一步一步参与…...

TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端
TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾在大屏幕电视前感到手足无措࿱…...

如何处理SQL递归层次结构更新_通过触发器维护父子关系
UPDATE父子路径未更新的主因是触发器中仅修改NEW.path而未递归更新后代path,且AFTER触发器中直接UPDATE同表会报错,需用临时表或存储过程中转,并同步维护level等衍生字段。UPDATE 时父子路径没更新,触发器里忘改 NEW.path递归结构…...

大模型低显存优化实战:量化、KV Cache与动态加载技术解析
1. 项目概述:低显存环境下的OpenClaw模型优化实战最近在GitHub上看到一个挺有意思的项目,标题是“openclaw-lowmem-optimization”。光看名字,就能猜到这大概是在做一件什么事:针对OpenClaw这个模型,进行低显存&#x…...

硬件调试利器:全面掌握AMD Ryzen处理器系统性能优化实战技巧
硬件调试利器:全面掌握AMD Ryzen处理器系统性能优化实战技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

Simulink仿真PMSM时,那个神秘的‘4’和‘30/π’到底怎么来的?手把手带你算清楚
Simulink仿真PMSM时关键参数转换原理与实战解析 在永磁同步电机(PMSM)的Simulink仿真过程中,工程师们常常会遇到几个看似"神秘"的增益系数——特别是30/π和4这两个数值。这些参数并非随意设置,而是深植于电机物理本质与单位系统转换的数学表达…...

基于MCP协议构建专属AI开发助手:从原理到实践
1. 项目概述:一个为开发者定制的MCP服务器最近在折腾AI应用开发,特别是想给Claude、Cursor这类智能助手增加一些“超能力”,让它们能直接操作我本地的开发环境。比如,让AI帮我直接运行单元测试、查看最近的Git提交、或者分析某个目…...

在vscode中快速配置taotoken的claude code插件实现稳定编程助手
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在VSCode中快速配置Taotoken的Claude Code插件实现稳定编程助手 对于使用VSCode的开发者而言,Claude Code插件是一个强…...

ACID [Atomicity, Consistency, Isolation, Durability]
ACID [Atomicity, Consistency, Isolation, Durability] 原子性、一致性、隔离性、持久性package further.zwf.acid;import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException;/*** MySQL 事务示例&am…...

AI智能体在社交约会场景中的架构设计与工程实践
1. 项目概述:当AI遇见约会,一个开源智能体的诞生最近在GitHub上看到一个挺有意思的项目,叫jessastrid/matchclaws-ai_agent_dating。光看名字,就能嗅到一股混合了技术、社交与未来感的独特气息。简单来说,这是一个利用…...

保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练
保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练 在计算机视觉领域,多目标跟踪(MOT)一直是研究热点之一。而VisDrone作为无人机视角下的经典数据集,其丰富的场景和挑战性的标注使其成为MOT研究的理想选择。…...