实战Flink Java api消费kafka实时数据落盘HDFS
文章目录
- 1 需求分析
- 2 实验过程
- 2.1 启动服务程序
- 2.2 启动kafka生产
- 3 Java API 开发
- 3.1 依赖
- 3.2 代码部分
- 4 实验验证
- STEP1
- STEP2
- STEP3
- 5 时间窗口
1 需求分析
在Java api中,使用flink本地模式,消费kafka主题,并直接将数据存入hdfs中。
flink版本1.13
kafka版本0.8
hadoop版本3.1.4
2 实验过程
2.1 启动服务程序
为了完成 Flink 从 Kafka 消费数据并实时写入 HDFS 的需求,通常需要启动以下组件:
[root@hadoop10 ~]# jps
3073 SecondaryNameNode
2851 DataNode
2708 NameNode
12854 Jps
1975 StandaloneSessionClusterEntrypoint
2391 QuorumPeerMain
2265 TaskManagerRunner
9882 ConsoleProducer
9035 Kafka
3517 NodeManager
3375 ResourceManager
确保 Zookeeper 在运行,因为 Flink 的 Kafka Consumer 需要依赖 Zookeeper。
确保 Kafka Server 在运行,因为 Flink 的 Kafka Consumer 需要连接到 Kafka Broker。
启动 Flink 的 JobManager 和 TaskManager,这是执行 Flink 任务的核心组件。
确保这些组件都在运行,以便 Flink 作业能够正常消费 Kafka 中的数据并将其写入 HDFS。
- 具体的启动命令在此不再赘述。
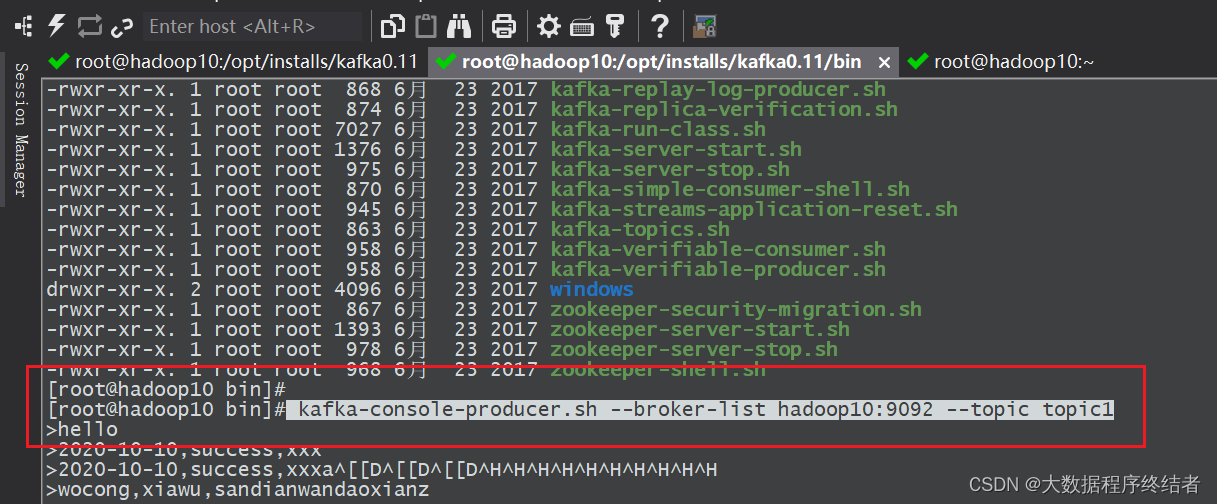
2.2 启动kafka生产
- 当前kafka没有在守护进程后台运行;
- 创建主题,启动该主题的生产者,在kafka的bin目录下执行;
- 此时可以生产数据,从该窗口键入任意数据进行发送。
kafka-topics.sh --zookeeper hadoop10:2181 --create --topic topic1 --partitions 1 --replication-factor 1kafka-console-producer.sh --broker-list hadoop10:9092 --topic topic1
3 Java API 开发
3.1 依赖
此为项目的所有依赖,包括flink、spark、hbase、ck等,实际本需求无需全部依赖,均可在阿里云或者maven开源镜像站下载。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>flink-test</artifactId><version>1.0-SNAPSHOT</version><properties><flink.version>1.13.6</flink.version><hbase.version>2.4.0</hbase.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version><!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><!--<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.11</artifactId><version>1.14.6</version></dependency>--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.1.0</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version><exclusions><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion><exclusion><artifactId>log4j</artifactId><groupId>log4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version><exclusions><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.4.2</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.32</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hbase-2.2_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.20</version></dependency></dependencies><build><extensions><extension><groupId>org.apache.maven.wagon</groupId><artifactId>wagon-ssh</artifactId><version>2.8</version></extension></extensions><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>wagon-maven-plugin</artifactId><version>1.0</version><configuration><!--上传的本地jar的位置--><fromFile>target/${project.build.finalName}.jar</fromFile><!--远程拷贝的地址--><url>scp://root:root@hadoop10:/opt/app</url></configuration></plugin></plugins></build></project>- 依赖参考
3.2 代码部分
- 请注意kafka和hdfs的部分需要配置服务器地址,域名映射。
- 此代码的功能是消费
topic1主题,将数据直接写入hdfs中。
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class Test9_kafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "hadoop10:9092");properties.setProperty("group.id", "test");// 使用FlinkKafkaConsumer作为数据源DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));String outputPath = "hdfs://hadoop10:8020/out240102";// 使用StreamingFileSink将数据写入HDFSStreamingFileSink<String> sink = StreamingFileSink.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")).build();// 添加Sink,将Kafka数据直接写入HDFSds1.addSink(sink);ds1.print();env.execute("Flink Kafka HDFS");}
}
4 实验验证
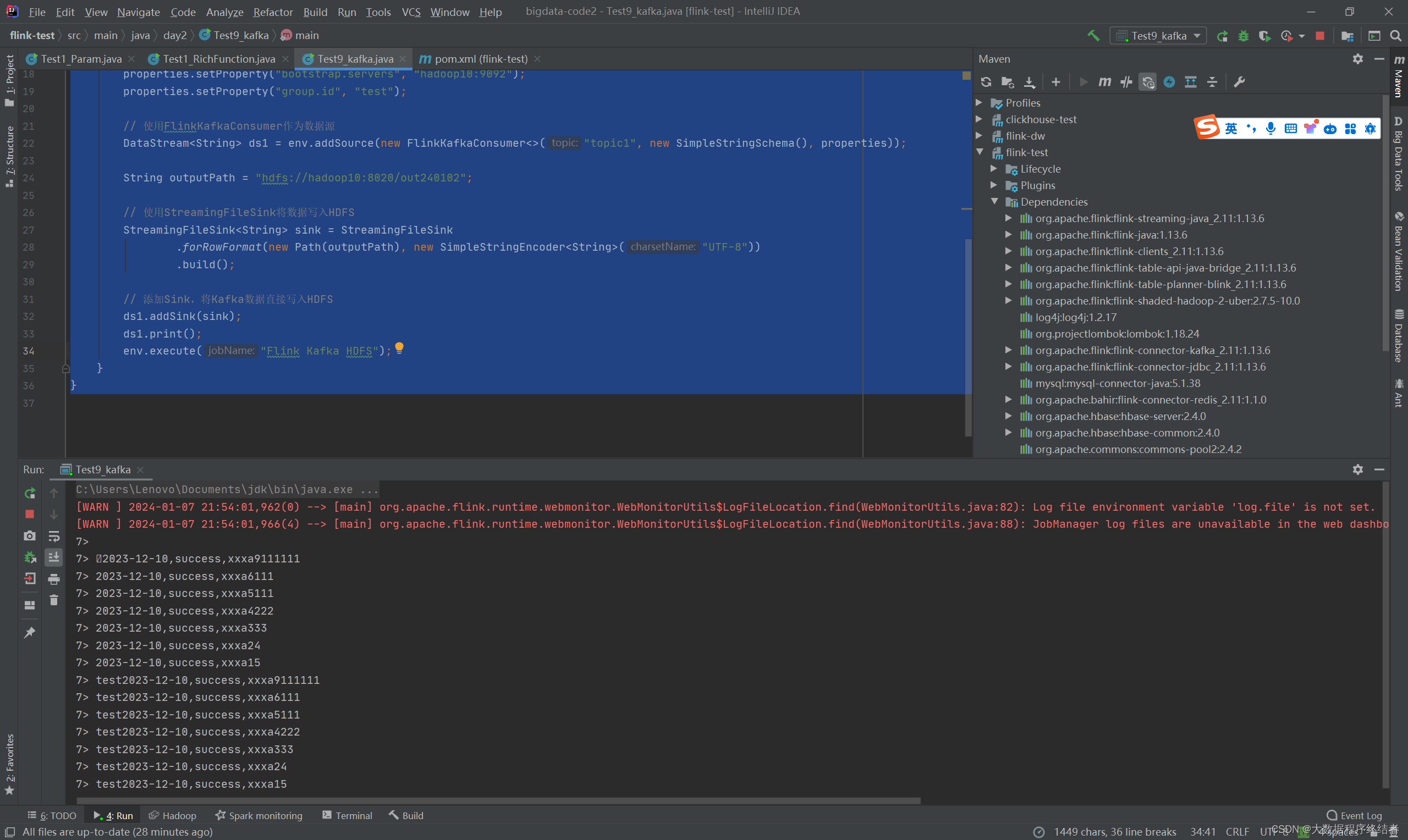
STEP1
运行idea代码,程序开始执行,控制台除了日志外为空。下图是已经接收到生产者的数据后,消费在控制台的截图。
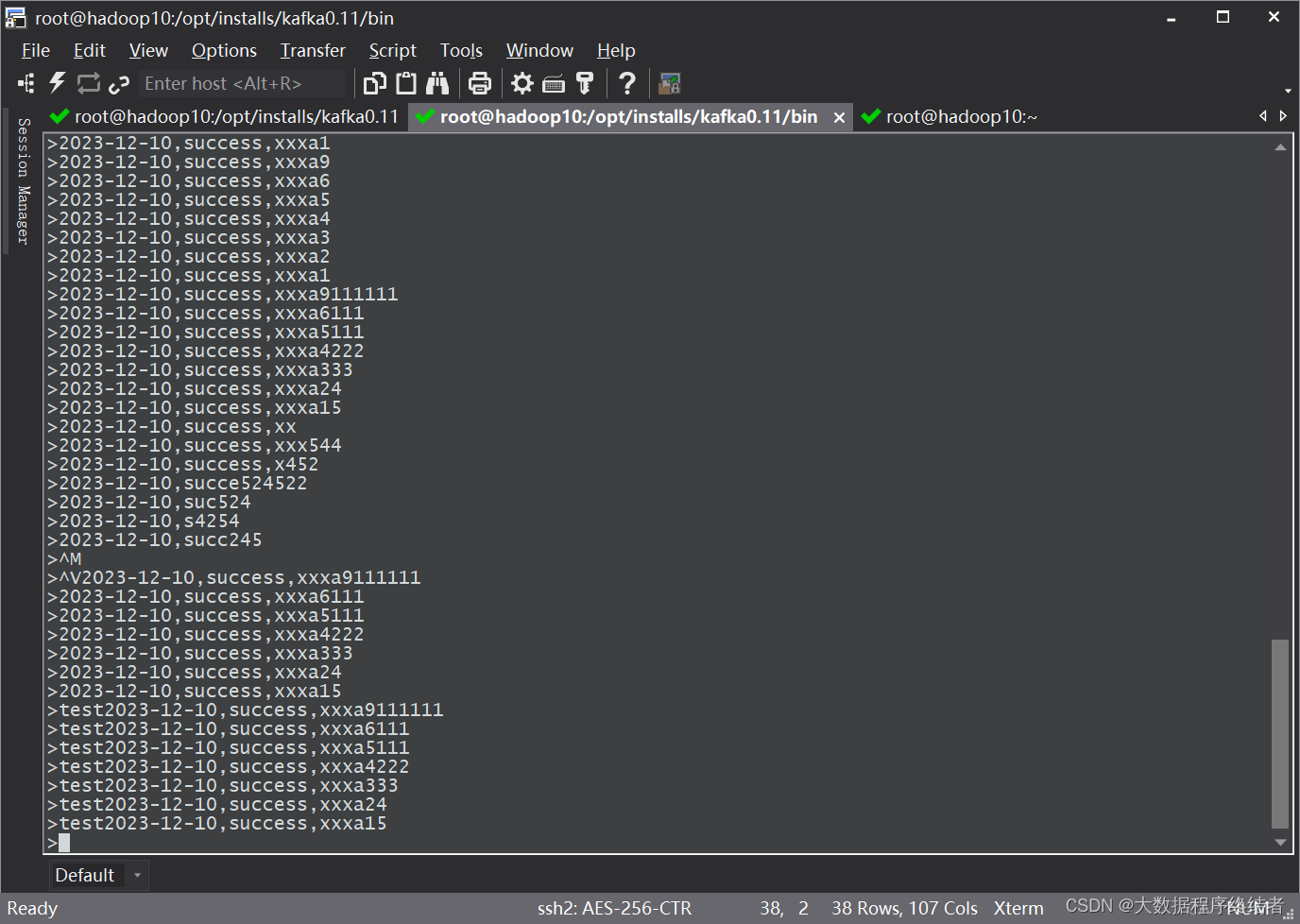
STEP2
启动生产者,将数据写入,数据无格式限制,随意填写。此时发送的数据,是可以在STEP1中的控制台中看到屏幕打印结果的。
STEP3
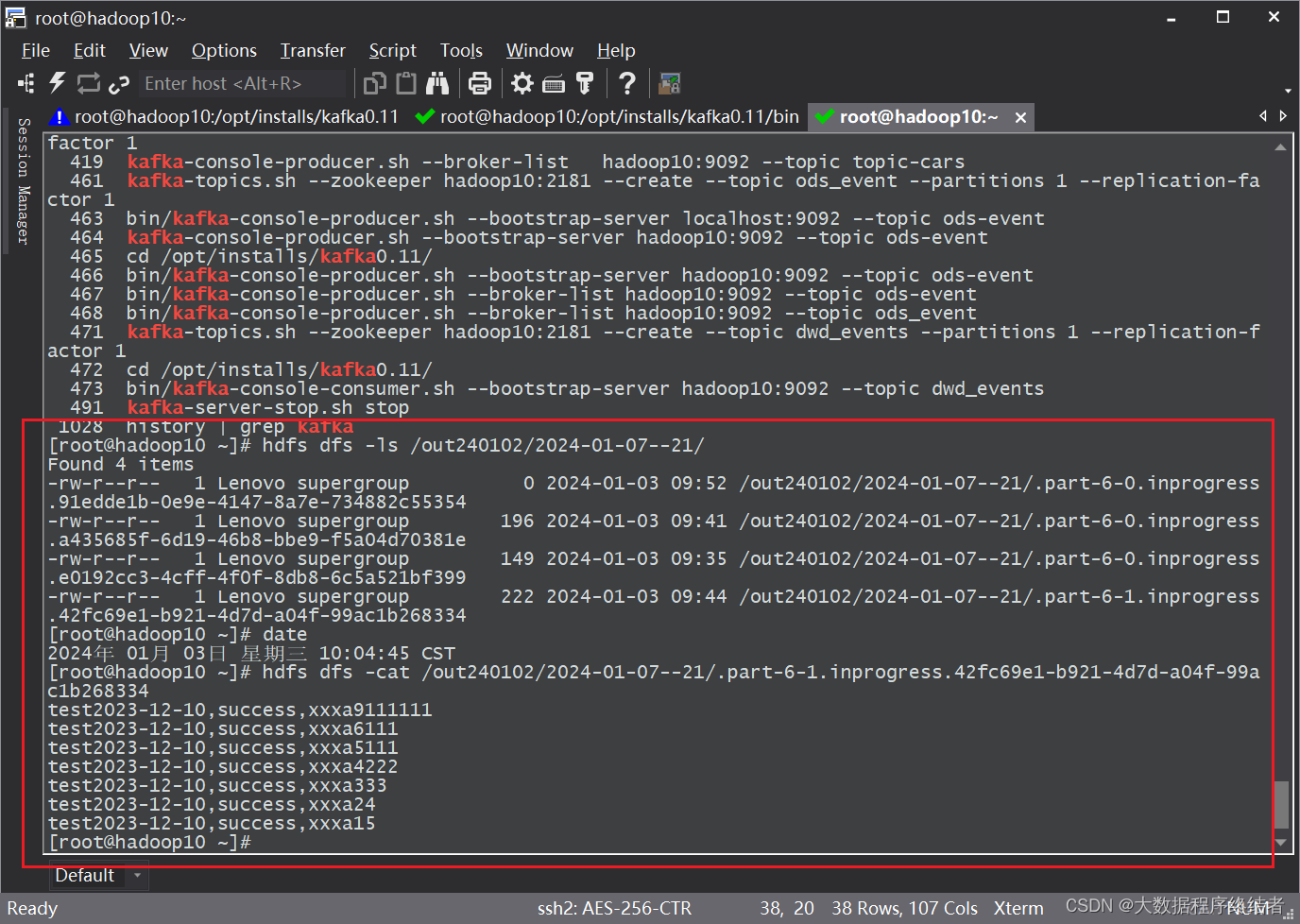
在HDFS中查看对应的目录,可以看到数据已经写入完成。
我这里生成了多个inprogress文件,是因为我测试了多次,断码运行了多次。ide打印在屏幕后,到hdfs落盘写入,中间有一定时间,需要等待,在HDFS中刷新数据,可以看到文件大小从0到被写入数据的过程。
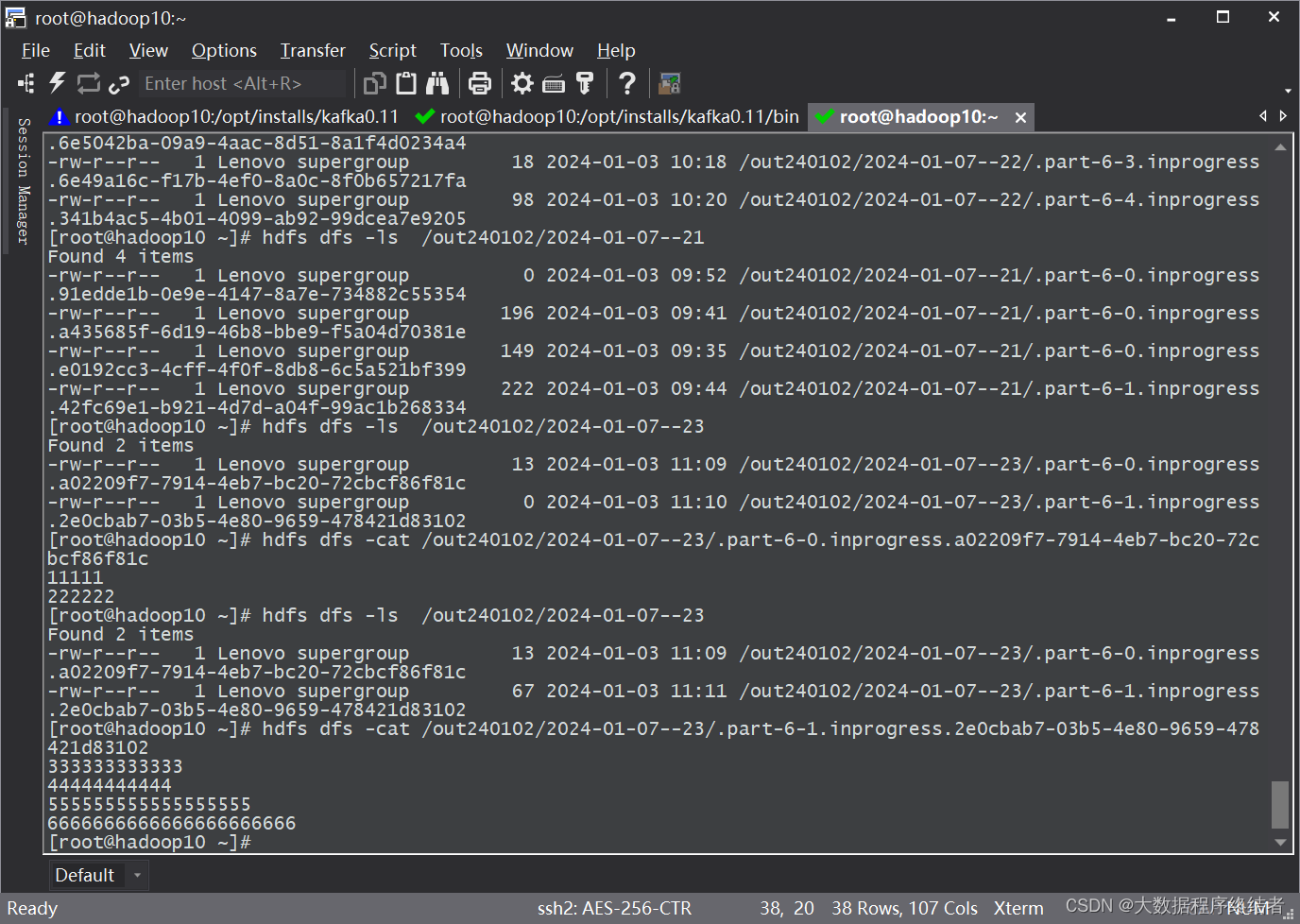
5 时间窗口
- 使用另一种思路实现,以时间窗口的形式,将数据实时写入HDFS,实验方法同上。截图为发送数据消费,并且在HDFS中查看到数据。
package day2;import day2.CustomProcessFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
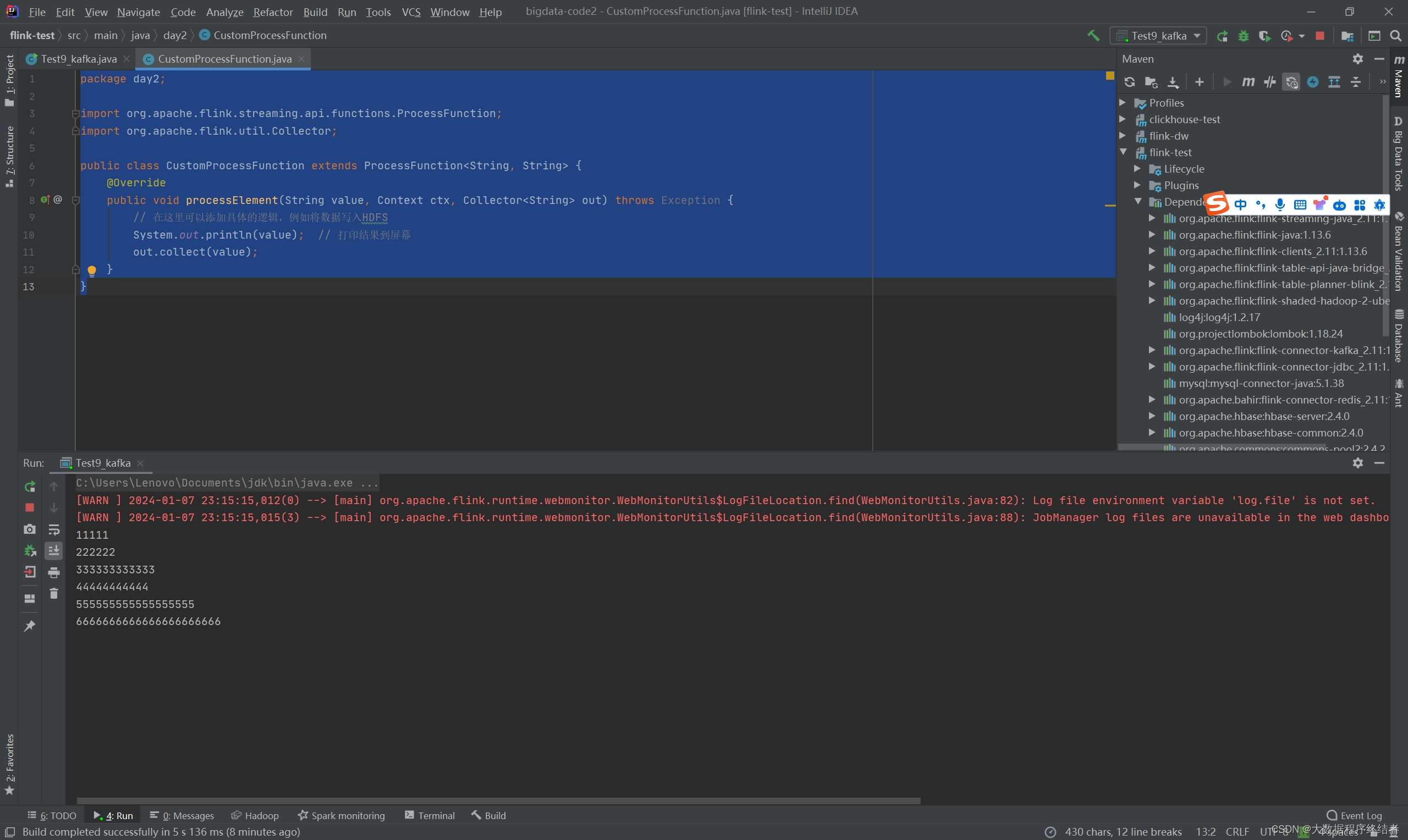
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class Test9_kafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "hadoop10:9092");properties.setProperty("group.id", "test");// 使用FlinkKafkaConsumer作为数据源DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));String outputPath = "hdfs://hadoop10:8020/out240102";// 使用StreamingFileSink将数据写入HDFSStreamingFileSink<String> sink = StreamingFileSink.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")).build();// 在一个时间窗口内将数据写入HDFSds1.process(new CustomProcessFunction()) // 使用自定义 ProcessFunction.addSink(sink);// 执行程序env.execute("Flink Kafka HDFS");}
}
package day2;import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;public class CustomProcessFunction extends ProcessFunction<String, String> {@Overridepublic void processElement(String value, Context ctx, Collector<String> out) throws Exception {// 在这里可以添加具体的逻辑,例如将数据写入HDFSSystem.out.println(value); // 打印结果到屏幕out.collect(value);}
}
相关文章:
实战Flink Java api消费kafka实时数据落盘HDFS
文章目录 1 需求分析2 实验过程2.1 启动服务程序2.2 启动kafka生产 3 Java API 开发3.1 依赖3.2 代码部分 4 实验验证STEP1STEP2STEP3 5 时间窗口 1 需求分析 在Java api中,使用flink本地模式,消费kafka主题,并直接将数据存入hdfs中。 flin…...
爬虫与反爬-localStorage指纹(某易某盾滑块指纹检测)(Hook案例)
概述:本文将用于了解爬虫中localStorage的检测原理以及讲述一个用于检测localStorage的反爬虫案例,最后对该参数进行Hook断点定位 目录: 一、LocalStorage 二、爬虫中localStorage的案例(以某盾滑块为例) 三、如何…...

聊一聊 webpack 和 vite 的开发服务代理的问题
webpack 和 vite webpackVite重新编辑的问题 changOrigin: true如何定义 /api ? webPack And Vite 都是两个比较好用的打包工具,尤其是 Vite, 几几年流行忘记了,特色就是服务启动极快,实现预加载,感觉 webPack 要比 Vite 要复杂一…...
【鸿蒙4.0】安装DevEcoStudio
1.下载安装包 HUAWEI DevEco Studio和SDK下载和升级 | HarmonyOS开发者华为鸿蒙DevEco Studio是面向全场景的一站式集成开发环境,,在鸿蒙官网下载或升级操作系统开发工具DevEco Studio最新版本,SDK配置和下载,2.1支持Mac、Windows操作系统。…...

[概率论]四小时不挂猴博士
贝叶斯公式是什么 贝叶斯公式是概率论中的一个重要定理,用于计算在已知一些先验信息的情况下,更新对事件发生概率的估计。贝叶斯公式的表达式如下: P(A|B) P(B|A) * P(A) / P(B) 其中,P(A|B)表示在事件B发生的条件下事件A发生的概…...
算法通关村第二十关-黄金挑战图的常见算法
大家好我是苏麟 , 今天聊聊图的常见算法 . 图里的算法是很多的,这里我们介绍一些常见的图算法。这些算法一般都比较复杂,我们这里介绍这些算法的基本含义,适合面试的时候装*,如果手写,那就不用啦。 图分析算法…...

服务器内存不足怎么办?会有什么影响?
服务器内存,也被称为RAM(Random Access Memory),是一种临时存储设备,用于临时存放正在运行的程序和数据。它是服务器上的超高速存储介质,可以快速读取和写入数据,提供给CPU进行实时计算和操作。…...

GPT实战系列-简单聊聊LangChain
GPT实战系列-简单聊聊LangChain LLM大模型相关文章: GPT实战系列-ChatGLM3本地部署CUDA111080Ti显卡24G实战方案 GPT实战系列-Baichuan2本地化部署实战方案 GPT实战系列-大话LLM大模型训练 GPT实战系列-探究GPT等大模型的文本生成 GPT实战系列-Baichuan2等大模…...

【读书笔记】《白帽子讲web安全》浏览器安全
目录 第二篇 客户端脚本安全 第2章 浏览器安全 2.1同源策略 2.2浏览器沙箱 2.3恶意网址拦截 2.4高速发展的浏览器安全 第二篇 客户端脚本安全 第2章 浏览器安全 近年来随着互联网的发展,人们发现浏览器才是互联网最大的入口,绝大多数用户使用互联…...

海外服务器2核2G/4G/8G和4核8G配置16M公网带宽优惠价格表
腾讯云海外服务器租用优惠价格表,2核2G10M带宽、2核4G12M、2核8G14M、4核8G16M配置可选,可以选择Linux操作系统或Linux系统,相比较Linux服务器价格要更优惠一些,腾讯云服务器网txyfwq.com分享腾讯云国外服务器租用配置报价&#x…...

Linux 编译安装 Nginx
目录 一、前言二、四种安装方式介绍三、本文安装方式:源码安装3.1、安装依赖库3.2、开始安装 Nginx3.3、Nginx 相关操作3.4、把 Nginx 注册成系统服务 四、结尾 一、前言 Nginx 是一款轻量级的 Web 服务器、[反向代理]服务器,由于它的内存占用少…...
Oracle文件自动“减肥”记
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

【csharp】抽象类与接口有哪些不同?什么时候应该使用抽象类?
抽象类与接口有哪些不同? 抽象类和接口是在面向对象编程中两个不同的概念,它们有一些重要的区别。以下是抽象类和接口的主要不同点: 抽象类(Abstract Class): 成员类型: 抽象类可以包含抽象方…...

最新-mybatis-plus 3.5分页插件配置
mybatis-plus 3.5分页插件配置 前提 1.项目不是springboot, 是以前的常规spring项目 2.mp 从3.2升级到3.5,升级后发现原本的分页竟然不起作用了,每次查询都是查出所有 前后配置对比 jar包对比 jsqlparser我这里单独引了包,因为版本太低…...
案例098:基于微信小程序的电子购物系统的设计与实现
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...

亚信安慧AntDB数据库:数字化时代的数据库创新引领者
AntDB数据库以其卓越的创新能力,集中体现在融合统一与实时处理两大关键领域。作为一款服务全国超过10亿用户的分布式数据库,其独特之处在于长期积累的经验、多样性的支持能力、快速响应的数据处理速度以及卓越的系统稳定性。AntDB不仅仅是一个数据库系统…...

【MySQL】关于日期转换的方法
力扣题 1、题目地址 1853. 转换日期格式 2、模拟表 表: Days Column NameTypedaydate day 是这个表的主键。 3、要求 给定一个Days表,请你编写SQL查询语句,将Days表中的每一个日期转化为"day_name, month_name day, year"格式的字符串…...
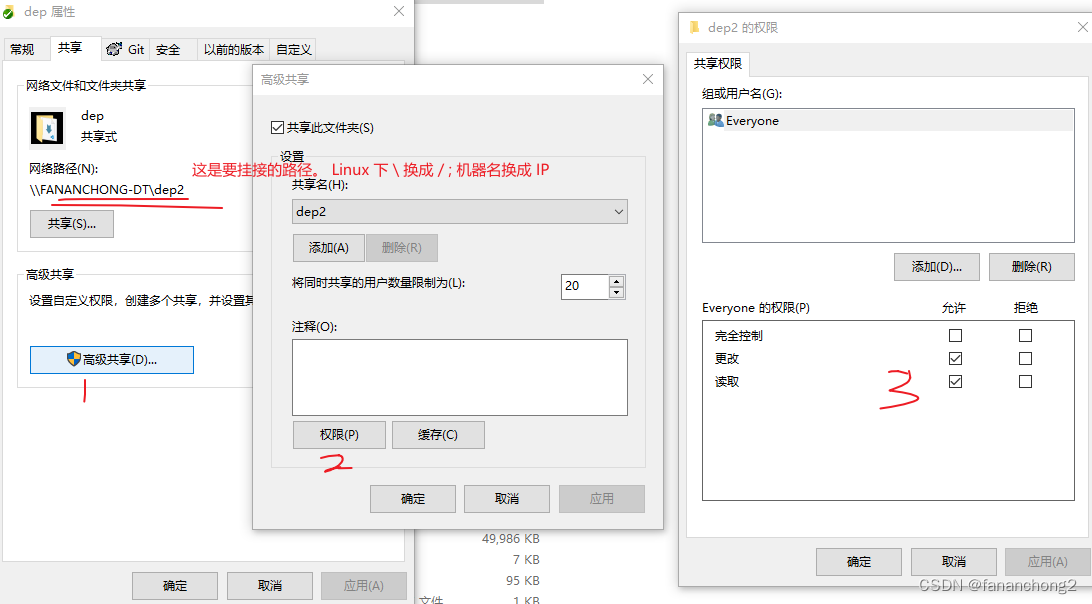
Ubuntu 虚拟机挂接 Windows 目录
Windows 共享目录 首先 Windows 下共享目录 我这里偷懒直接直接 Everyone ,也可以指定用户啥的 Ubuntu 挂接 挂接命令,类似如下: sudo mount -o usernamefananchong,passwordxxxx,uid1000,gid1000,file_mode0644,dir_mode0755,dynperm //…...
机器学习模型可解释性的结果分析
模型的可解释性是机器学习领域的一个重要分支,随着 AI 应用范围的不断扩大,人们越来越不满足于模型的黑盒特性,与此同时,金融、自动驾驶等领域的法律法规也对模型的可解释性提出了更高的要求,在可解释 AI 一文中我们已…...
静态网页设计——环保网(HTML+CSS+JavaScript)(dw、sublime Text、webstorm、HBuilder X)
前言 声明:该文章只是做技术分享,若侵权请联系我删除。!! 感谢大佬的视频: https://www.bilibili.com/video/BV1BC4y1v7ZY/?vd_source5f425e0074a7f92921f53ab87712357b 使用技术:HTMLCSSJS(…...

在多轮对话应用中观察 Taotoken 路由策略对响应速度的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察 Taotoken 路由策略对响应速度的影响 效果展示类,在开发一个需要连续进行多轮对话的聊天应用时&a…...

CF-ISAC技术:无蜂窝网络中的感知通信一体化
1. CF-ISAC技术概述无线通信系统正经历从单纯的信息传输向"感知-通信一体化"的范式转变。集成感知与通信(ISAC)技术通过共享硬件资源和频谱,实现了环境感知与数据传输的深度协同。这种技术突破源于多天线系统(MIMO&…...

OBS多平台直播插件:打破平台限制的5分钟专业解决方案
OBS多平台直播插件:打破平台限制的5分钟专业解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 想象一下这样的场景:你精心准备的游戏直播即将开始…...

光储微网孤岛检测与VSG切换控制【附程序】
✨ 长期致力于光伏-储能系统、微网、孤岛检测、并离网切换、虚拟同步电机研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)经验小波变换与正反馈频率漂…...
ANLI计算结果才准确)
避开这3个坑,你的夜间灯光数据(NPP/VIIRS)ANLI计算结果才准确
避开这3个坑,你的夜间灯光数据(NPP/VIIRS)ANLI计算结果才准确 深夜的城市灯光如同流动的星河,而NPP/VIIRS卫星捕捉的这些光点正成为区域经济研究的"新货币"。但当我第一次用ArcGIS计算昆明各区县的平均灯光指数&#x…...

pkrelay:轻量级端口转发工具的设计原理与生产实践
1. 项目概述:一个轻量级、高可用的端口转发与流量中继工具在分布式系统、微服务架构以及混合云部署的日常运维和开发调试中,我们经常会遇到一个经典问题:如何安全、便捷地将一个网络环境中的服务端口,暴露给另一个网络环境访问&am…...

WechatDecrypt:如何安全解密微信聊天记录的完整技术指南
WechatDecrypt:如何安全解密微信聊天记录的完整技术指南 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 在数字时代,我们的重要对话和回忆往往存储在加密的聊天记录中。当需要迁移…...

构建个人知识记忆桥梁:从数据抽取到智能检索的工程实践
1. 项目概述:一个连接记忆与未来的桥梁最近在开源社区里,我注意到一个挺有意思的项目,叫leninejunior/engrene-memory-bridge。光看这个名字,就透着一股子“连接”和“记忆”的味道。作为一个长期在数据工程和知识管理领域摸爬滚打…...

打破物理限制:如何用ParsecVDisplay创建多达16个虚拟显示器?
打破物理限制:如何用ParsecVDisplay创建多达16个虚拟显示器? 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动…...

链表存储式栈
#include <stdio.h> #include <stdlib.h>#include <stdio.h> #include <stdlib.h> #include <string.h>#include <stdlib.h> typedef struct stack_node{int data;struct stack_node * next; } STstacknode; /*声明一个结构体来存储栈顶&a…...