Python高性能编程
一、进程池和线程池
1.串行
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
2.多进程
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
3.进程池(1)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
3.进程池(2)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
2019-03-06 補充
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
4.多线程
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
5.线程池
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
二、异步非阻塞
| 1 2 3 4 5 6 7 |
|
1.asyncio示例1
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
2.asyncio示例2
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
3.asyncio示例3
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
4.asyncio+aiohttp示例1
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
或者
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
5.asyncio+requests示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
补充:
| 1 2 3 4 5 |
|
6.gevent+requests示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
使用gevent协程并获取返回值示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
7.Twisted示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
8.Tornado示例
以上均是Python内置以及第三方模块提供异步IO请求模块,使用简便大大提高效率;
而对于异步IO请求的本质则是【非阻塞Socket】+【IO多路复用】
三、自定义异步非阻塞模块
1.简单示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
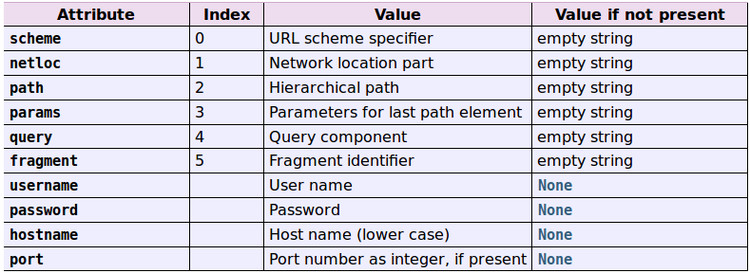
2.自定义异步非阻塞模块
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
|
3.牛逼的异步IO模块
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
|
相关文章:
Python高性能编程
一、进程池和线程池 1.串行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import time import requests url_lists [ http://www.baidu.com, http://fanyi.baidu.com, http://map.baidu.com, http://music.baidu.com/, http://tieba.baid…...

MVVM模式下如何正确【视图绑定+数据】
概述 我如何(不在后面的代码中使用代码)自动绑定到我想要的视图?据我了解,如果正确完成,这就是模式应该如何工作。我可以使用主窗口 xaml 中的代码实现这一切,我甚至正确创建了一个资源字典(因…...

外包测试3年,离职后成功入职华为,拿到offer的那天我泪目了....
一提及外包测试,大部分人的第一印象就是:工作强度大,技术含量低,没有归属感!外包工作三年总体感受就是这份工作缺乏归属感,心里总有一种落差,进步空间不大,接触不到核心技术…...

Qt Study
按钮->点击->窗口->关闭窗口 connect(信号的发送者,发送具体信号,信号的接收者,信号的处理); 信号处理函数称为槽 信号槽的优点,松散耦合,信号发送端和接收端本身是没有关联的,通过connect连接…...

JS混淆技术探究及解密方法分析
随着Web技术的快速发展,JavaScript被广泛应用于网页开发、移动应用开发等领域。然而,JavaScript代码很容易被反编译、解密,这给保护网站和应用程序的安全性带来了严重的挑战。为了解决这个问题,JS混淆技术应运而生。JS混淆就是将J…...
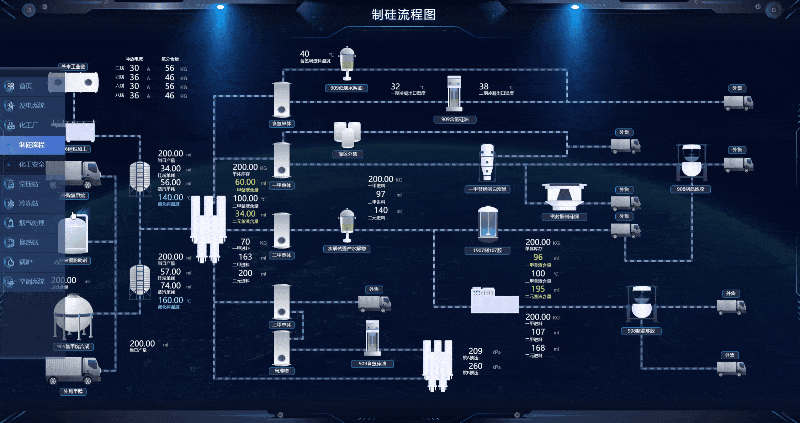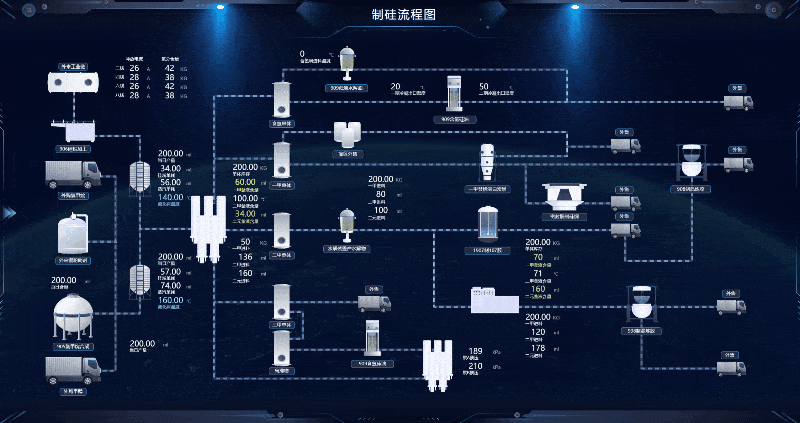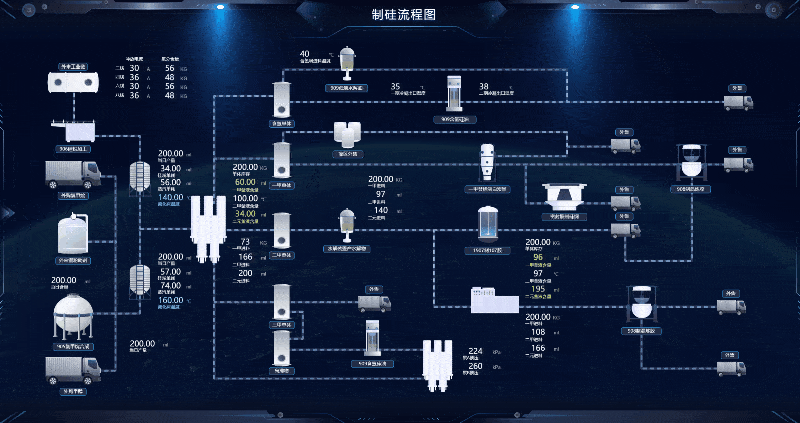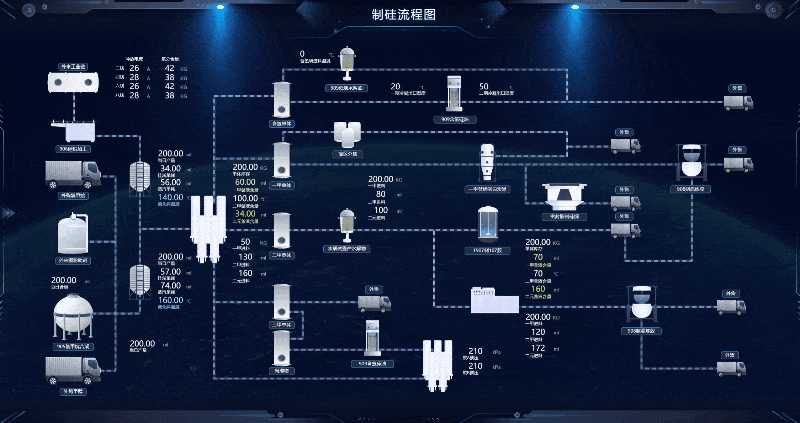
智慧制硅厂 Web SCADA 生产线
我国目前是全球最大的工业硅生产国、消费国和贸易国,且未来该产业的主要增量也将来源于我国。绿色低碳发展已成为全球大趋势和国际社会的共识,随着我国“双碳”目标的推进,光伏产业链快速发展,在光伏装机需求的带动下,…...
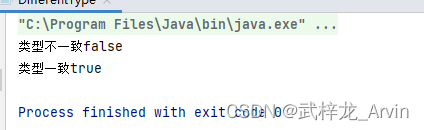
案例09-数据类型不一致导致equals判断为false
一:背景介绍 在判断课程id和班级id的时候如果一致就像课程信息进行更新,如果不一致就插入一条新的数据。其实两个变量的值是一致的但是类型是不一致的。这就导致数据库中已经有一条这样的数据了,在判断的时候结果为false,就有插入…...
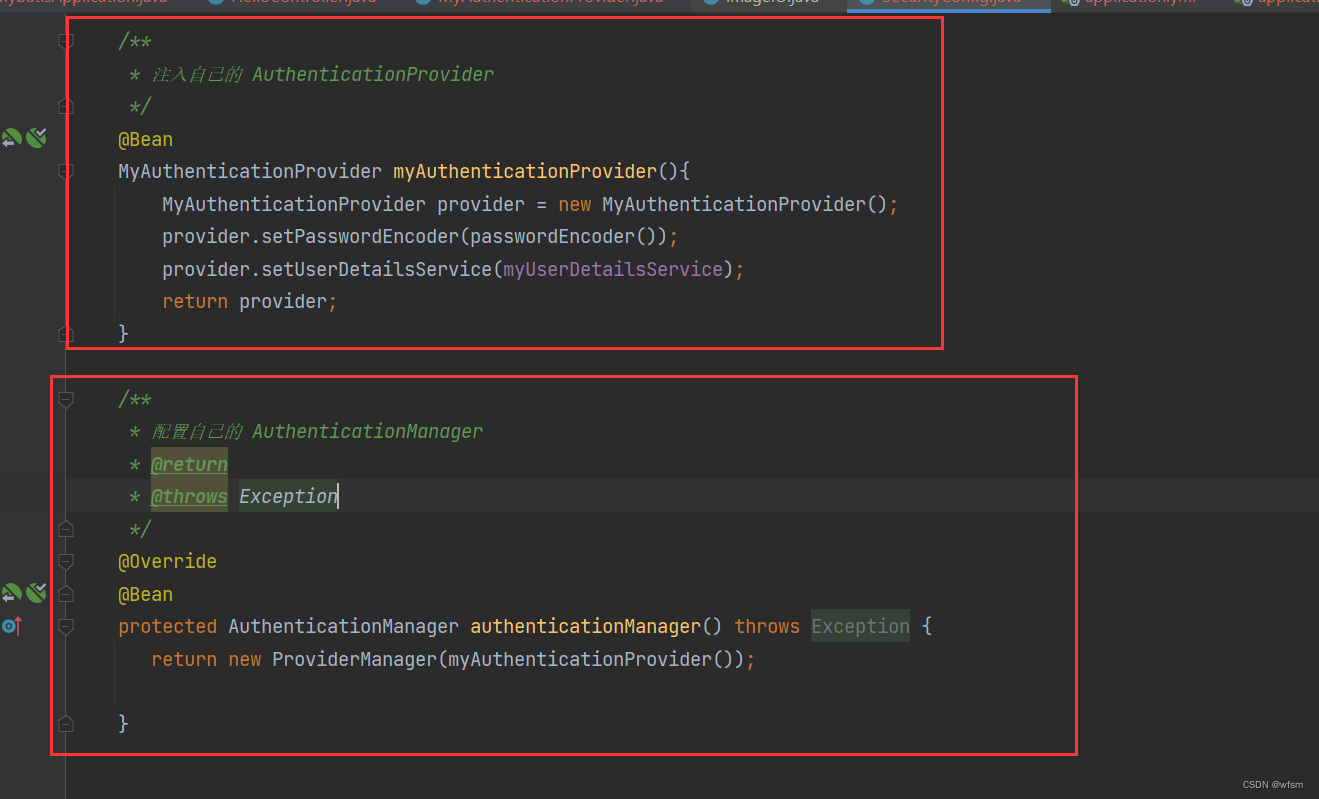
springsecurity中的类
Authentication AuthenticationProvider 每一个AuthenticationProvider对应一个Authentication 很多个AuthenticationProvider 由一个 ProviderManager管理 ProviderManager implements AuthenticationManager 一个ProviderManager有很多个 AuthenticationProvider Usern…...

k8s配置管理
一、configmap 1.1 configmap概述 Configmap 是 k8s 中的资源对象,用于保存非机密性的配置的,数据可以用 key/value 键值对的形式保存,也可通过文件的形式保存。 1.2 configmap作用 我们在部署服务的时候,每个服务都有自己的配置…...
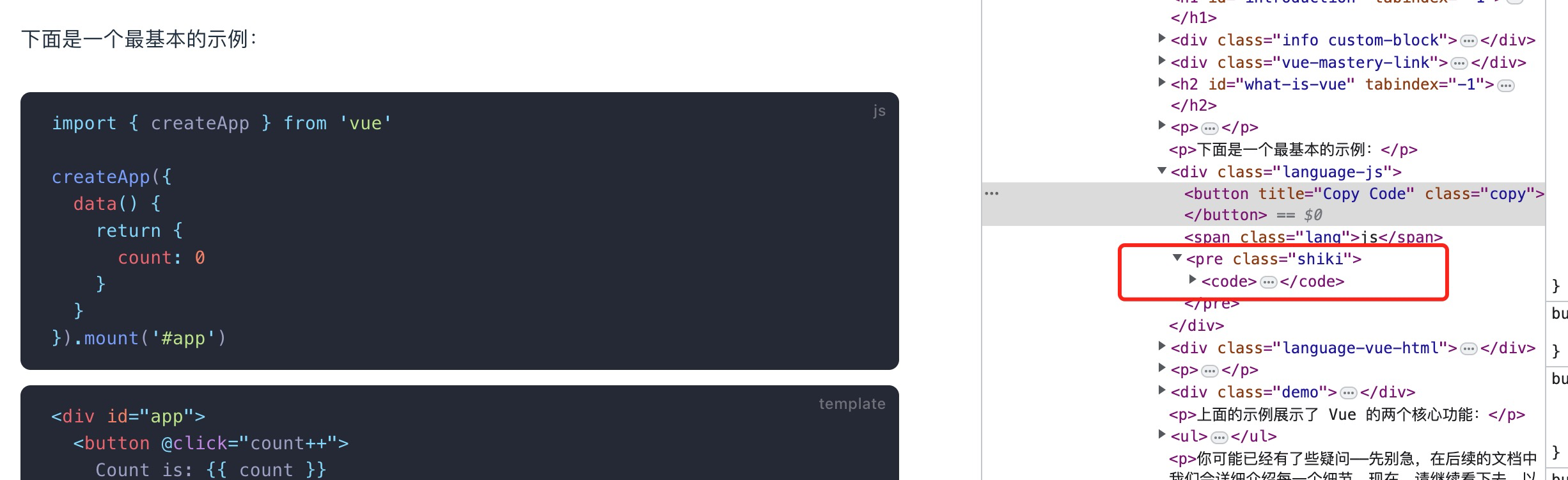
技术官方文档中的代码是用什么展示的?代码高亮插件总结
****内容预警****菜鸟教程***大佬绕道我们经常看到各种技术官方文档,有很多代码展示的区域,用于我们复制粘贴代码,比如vue 的官网当我们需要自己实现这么一个网站的时候,我就开始手忙脚乱,这到底是咋实现的?…...
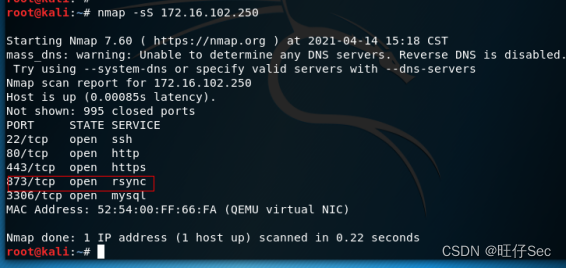
2023年中职组网络安全竞赛——综合渗透测试解析
综合渗透测试 题目如下: PS:需求环境可私信博主,求个三连吧! 解析如下: 通过本地PC中的渗透测试平台KALI2020对服务器场景进行渗透攻击,获取到RSYNC服务所开放的端口,将RSYNC服务开放的端口数值进行MD5加密后作为FLAG提交(如MD5加密前:812);...
)
【全网最细PAT题解】【PAT乙】1044 火星数字(测试点2,测试点4详细解释)
题目链接 1044 火星数字 题目描述 火星人是以 13 进制计数的:地球人的 0 被火星人称为 tret。 地球人数字 1 到 12 的火星文分别为:jan, feb, mar, apr, may, jun, jly, aug, sep, oct, nov, dec。 火星人将进位以后的 12 个高位数字分别称为:…...
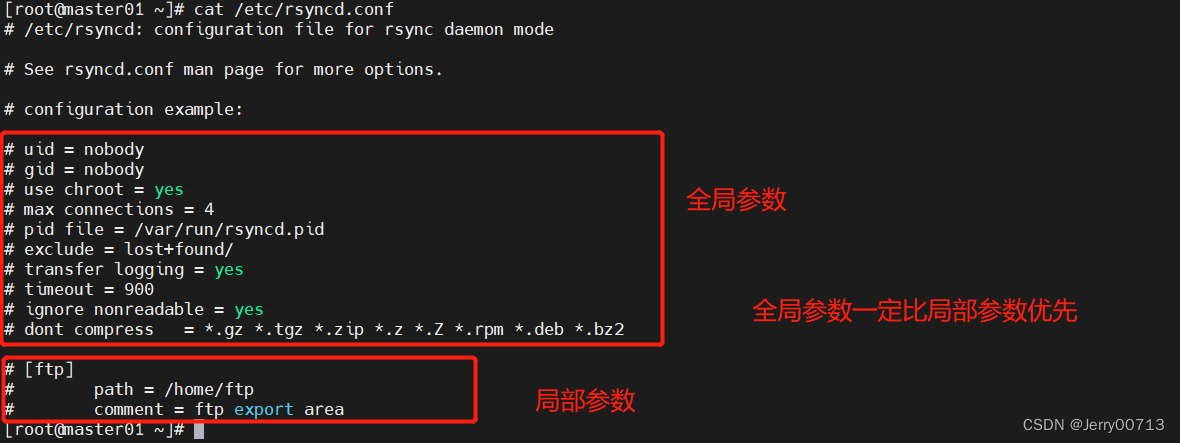
rsync+xinetd+inotify+sersync
一、介绍 1.1、rsync 对比 scp 相同: 都有拷贝的功能不同: rsync:具有增量复制,每次复制的时候,会扫描对端是否在同路径下有我要发送的一样的文件或者目录,如果,如果存在,则不进行复制。边复制&…...

CSS - 扫盲
文章目录1. 前言2. CSS2.1 css 的引入方式2.2 选择器2.3 CSS 常用属性2.3.1 字体属性2.3.2 文本属性2.3.3 背景属性2.4 圆角矩形2.5 元素的显示模式2.6 盒子模型2.7 弹性布局1. 前言 上文我们简单 将 HTML 过了一遍 , 知道了 HTML 知识表示页面的结构和内容 &#x…...

ChatGPT能完全取代软件开发吗,看看它怎么回答?
最近网上一直疯传,ChatGPT 最可能取代的 10 种工作。具体包括①、技术类工作:程序员、软件工程师、数据分析师②、媒体类工作:广告、内容创作、技术写作、新闻③、法律类工作:法律或律师助理④、市场研究分析师⑤、教师⑥、金融类…...

Vue3学习笔记
一、Ref ref, isRef, shallowRef, triggerRef, customRef ref返回的是es6的一个class类,取值和修改都要加上.valueref 和 shallowRef不能一起写,会引起shallowRef的视图更新ref shallowRef triggerRef <template><div class"home&quo…...

【React】pro-mobile
1.项目介绍 实现react移动端项目 2.目标: 能够应用CRAReactMobxAntd-mobile开发C端项目掌握基于React的C端项目开发流程学会如何应用next优化项目 3.使用技术栈 脚手架:cra dva-cliumi 脚本:ts react版本:react v18 2022年更…...
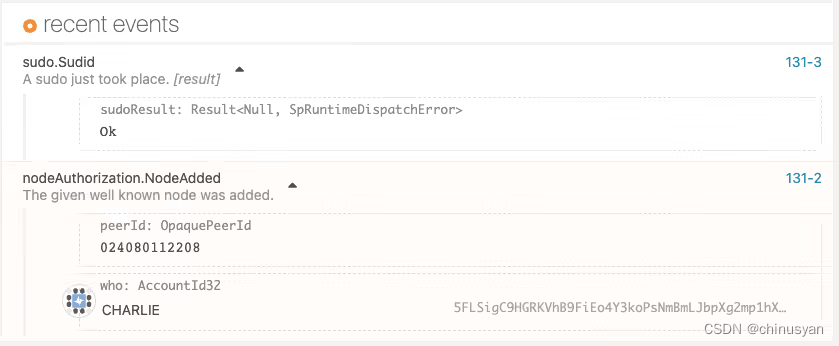
Substrate 基础教程(Tutorials) -- 授权特定节点
五、授权特定节点 在添加可信节点中,您看到了如何使用一组已知的验证器节点构建一个简单的网络。该教程演示了一个简化版的许可网络(permissioned network)。在一个被许可的网络中,只有被授权的节点(authorized nodes…...

使用qemu-img转换镜像格式
qemu功能强大,详细了解其功能请到官网查看 https://www.qemu.org/docs/master/system/images.html qemu-img能将RAW、qcow2、VMDK、VDI、VHD(vpc)、VHDX、qcow1或QED格式的镜像转换成VHD格式,也可以实现RAW和VHD格式的互相转换。 …...

Springboot怎么集成Thymeleaf模板引擎?
Thymeleaf介绍Thymeleaf,是一个XML/XHTML/HTML模板引擎,开源的java库,可以用于SpingMVC项目中,用于代替JSP、FreeMarker或者其他的模板引擎;页面与数据分离,提高了开发效率,让代码重用更容易。S…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...