在云服务器ECS上用Python写一个搜索引擎
在云服务器ECS上用Python写一个搜索引擎
- 一、场景介绍
- 二、搜索引擎的组成
- 2.1 网页的爬取及排序
- 2.2 用户使用搜索引擎进行搜索
- 三、操作步骤
- 3.1 环境准备
- 3.2 安装Anaconda
- 3.3 安装Streamlit
- 3.4 下载搜索引擎代码
- 3.5 运行搜索引擎
- 四、常见问题
- 4.1 运行setup.py时可能的问题
- 4.2 如何使搜索引擎一直在线
一、场景介绍
一台阿里云ECS云服务器就是一台带有公网IP地址的计算机。用户可以通过远程登录使用这台计算机;同时,由于带有公网IP,用户在ECS云服务器上部署的网站、APP、小程序等,可以被其他人通过互联网访问。
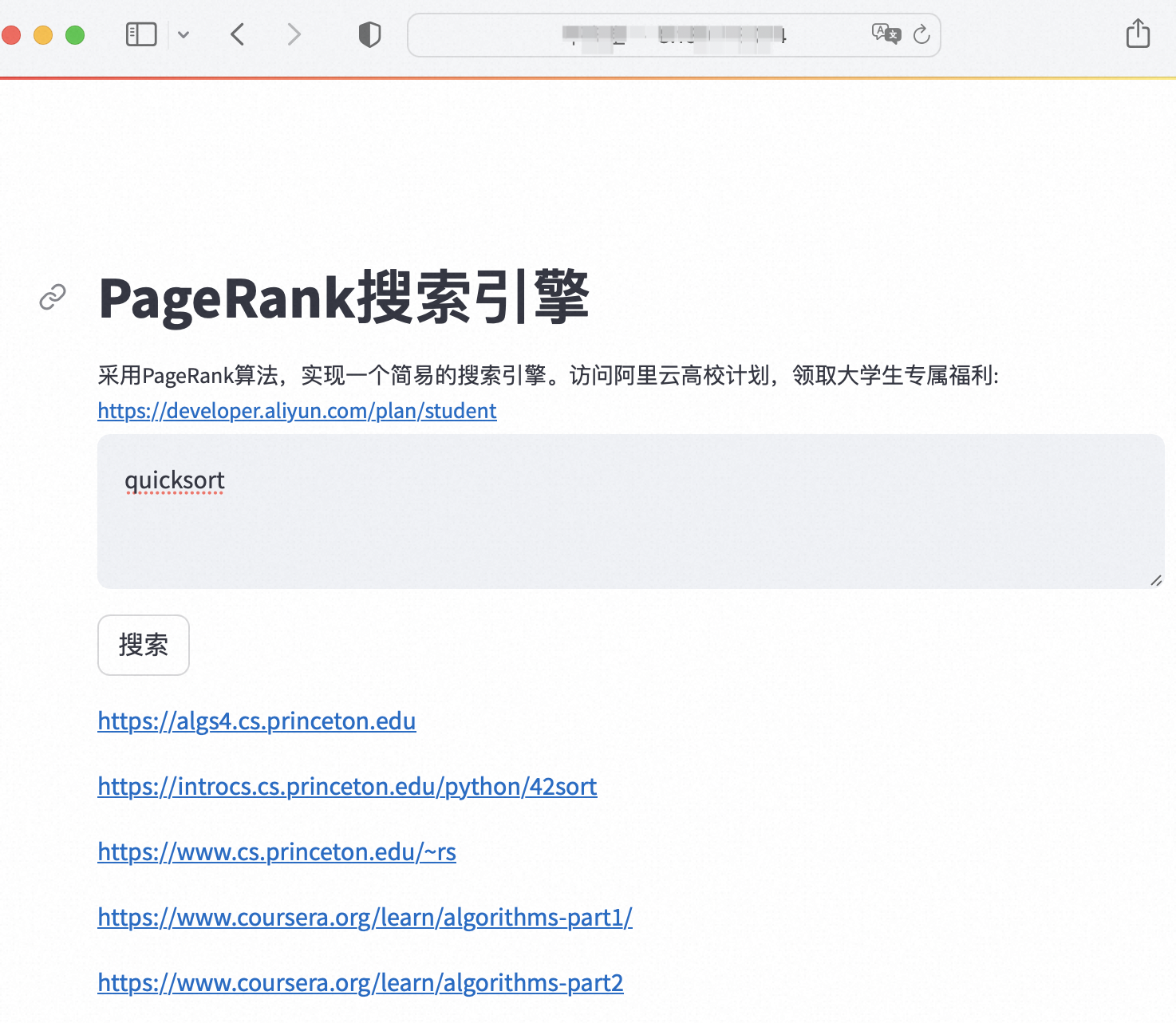
本实验应用PageRank算法,使用Python,在一台ECS云服务器上搭建了一个简易版的搜索引擎。可以用单个英文词语作为搜索词,搜索相关的网页。实现的效果如下图所示。在搜索框中,输入搜索词,例如"universe",单击搜索,搜索引擎即会按相关度从高到低,列出相关的网页。
二、搜索引擎的组成
本案例中的搜索引擎由两部分组成:网页的爬取及排序,以及用户使用搜索引擎进行搜索。
2.1 网页的爬取及排序
首先,搜索引擎需要从互联网上爬取网页。爬取到网页后,做两方面的工作:
-
获取网页间的超链接关系,使用PageRank算法对网页进行排序。PageRank算法的基本原理是,被引用越多的网页(即获取的超链接越多),重要性越高,类似于被引用次数越多的学术论文重要性越高的原理。对算法的说明可参考下面这本书:Google’s PageRank and Beyond: The Science of Search Engine Rankings。
-
编制搜索词的索引。从网页中提取词语,分析这些词语出现在哪些网页。
2.2 用户使用搜索引擎进行搜索
用户搜索某个词(例如 computer)时,搜索引擎首先从搜索词的索引中,找到这个词出现在哪些网页。然后,获取这些网页的PageRank值,按照值的大小,由高至低排序,呈现给用户。
本案例中,数据存储做了简化处理,采用了txt文档存储数据,没有使用数据库。Web页面采用Streamlit生成。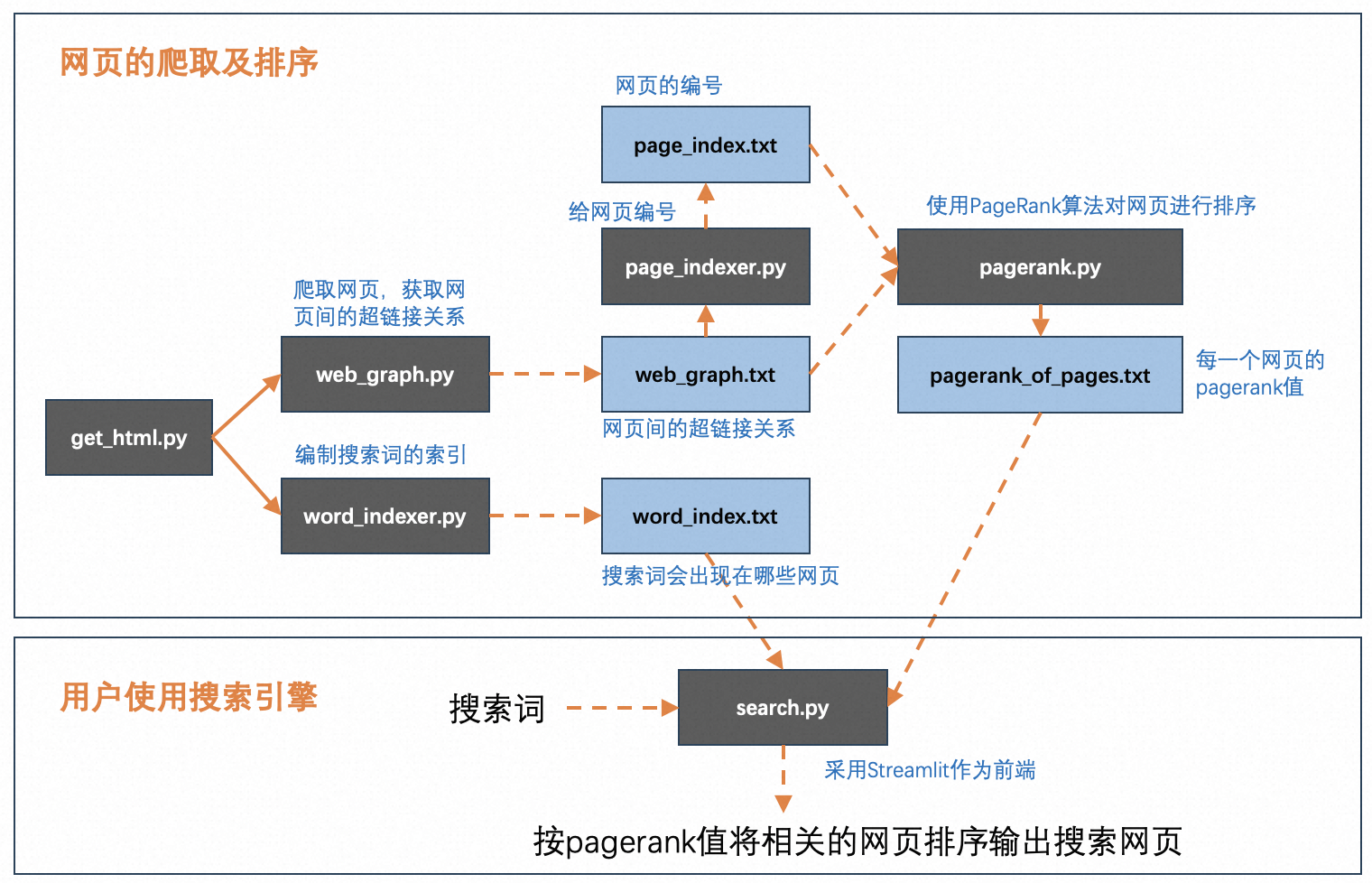
三、操作步骤
3.1 环境准备
-
创建用于运行搜索引擎的ECS实例。ECS实例建议配置如下:
-
实例规格:选择2vCPU 2 GiB的实例规格
-
系统盘:40 GiB
-
公网IP:选中分配公网 IPv4 地址并选择1M。
-
镜像:选择Linux系统的镜像,本实验中选取Alibaba Cloud Linux,版本为Alibaba Cloud Linux 3.2104 LTS 64位。当您选择其他Linux系统时,运行命令与本文有所不同。
-
-
实例安全组的入方向规则,放行22、80、443、8501端口(Streamlit默认使用8501端口)。
3.2 安装Anaconda
Anaconda中包含了Python、NumPy等本项目中需要的依赖项。
-
远程连接ECS实例。
-
更新操作系统。
sudo yum update -y sudo yum upgrade -y -
下载Anaconda安装包。
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh -
安装Anaconda。
bash Anaconda3-2023.09-0-Linux-x86_64.sh-
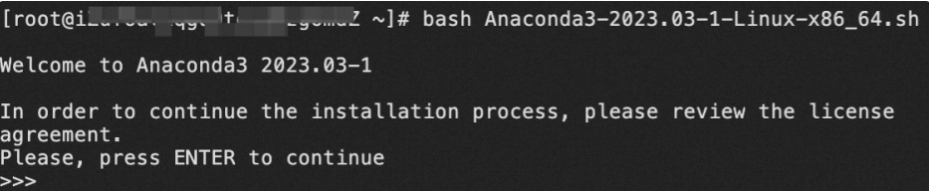
当出现下图所示信息时,单击Enter,继续安装过程。
-
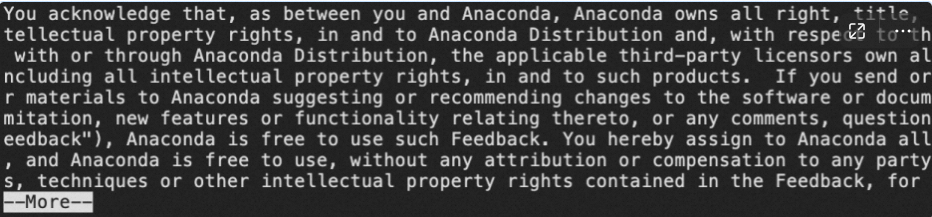
出现下面的界面后,连续多次单击Enter。**在这里需要注意,此处安装软件是在显示它的授权协议,让用户阅读。不要一直按住Enter,而是建议一下一下地点击Enter,后续会出现****Do you accept the license terms?**的提示(紧接着一个步骤)。默认的选项是no,如果一直按住Enter,安装过程会中止。
-
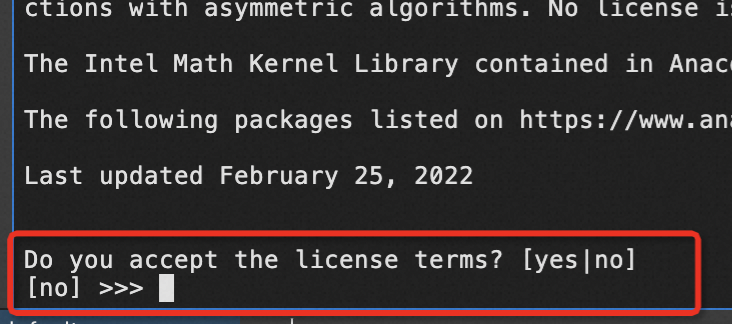
出现Do you accept the license terms? [yes|no]时,输入yes,单击Enter继续安装。
-
出现如下提示,单击Enter继续,等待Anaconda完成安装。
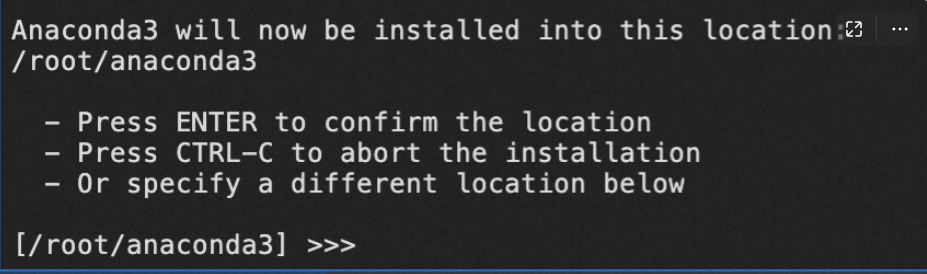
-
出现如下提示时,输入yes,单击Enter继续安装。
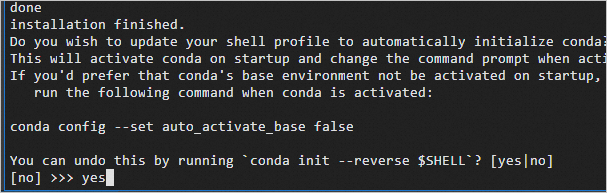
出现如下图所示信息时,说明Anaconda已安装完成。
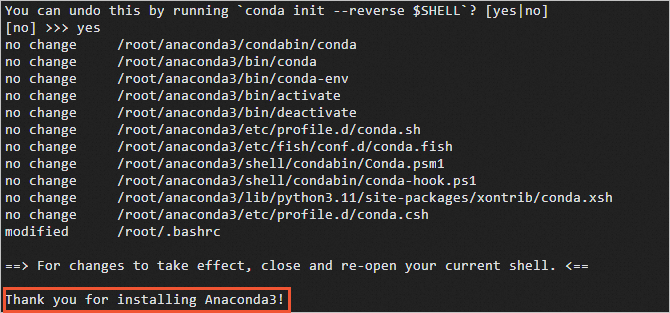
-
-
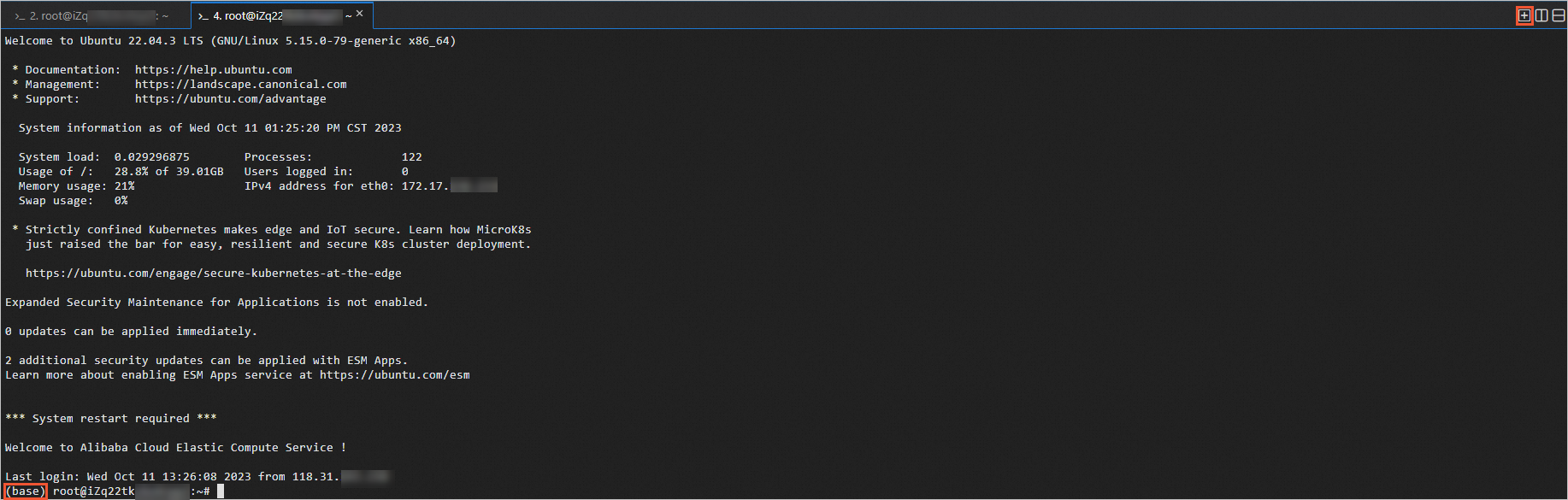
单击页面右上角的
 图标,打开一个新终端。
图标,打开一个新终端。当出现(base)字样,表示Anaconda已启动。
说明
在实际开发过程中,通常需要通过conda安装虚拟环境,在虚拟环境中继续后续操作。本实验中略去此步骤。
3.3 安装Streamlit
Streamlit用于展示Web页面。
pip install streamlit
3.4 下载搜索引擎代码
搜索引擎能搜索到哪些网页,取决于搜索引擎通过爬虫获得了哪些网页。本实验中,以Introduction to Programming in Python网页为起始网页,爬取了总计322个网页。因此,搜索的结果限于这322个网页。用户可以通过在web_graph.py中添加新的起始网页,爬取新的网页。
-
下载搜索引擎代码压缩包。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/en-US/20231011/uhsy/search_engine_demo_aliyun.zip -
解压缩搜索引擎代码压缩包。
yum install unzip unzip search_engine_demo_aliyun.zip -
切换到
search_engine_demo_aliyun目录。cd search_engine_demo_aliyunsearch_engine_demo_aliyun目录下的文件结构如下所示:
-
**search.py:**运行该程序,可以启动搜索引擎网页,供用户使用。
-
pageranking:包含爬取网页、计算PageRank值、生成词的索引所需要的程序。
-
web_graph.py:爬取网页,生成网页间的关系图(graph);
-
page_indexer.py:对使用web_graph.py爬取到的网页做编号,以方便使用PageRank算法时做矩阵运算;
-
pagerank.py:使用PageRank算法计算网页的重要性;
-
word_indexer.py:对爬取到的网页中的词进行分析,确定每一个词分别出现在了哪些网页;
-
get_html.py:获取网页的hmtl内容,web_graph.py和word_indexer.py都会调用这个程序;
-
setup.py:用于同时运行web_graph.py, page_indexer.py, pagerank.py, word_indexer.py,并存储数据。
-
-
**data:**用于存储运行./pageranking/setup.py后生成的数据。
-
web_graph.txt: 用于存储网页间的关联关系,本质上是一个有向图。采用字典的方式存储数据,key为一个网页,value为这个网页上超链接指向的网页组成的数组;
-
page_indexer.txt: 爬取到的网页的编号。这里的网页经过了去重。采用字典的方式存储数据,key为一个网页,value为网页的编号;
-
pagerank_of_pages.txt:采用PageRank算法计算出的各个网页的PageRank值,即重要性。采用字典的方式存储数据,key为一个网页,value为这个网页的PageRank值;
-
word_index.txt:词的索引,即词会出现在哪些网页。采用字典的方式存储数据,key为一个词,value为出现了这个词的网页的数组。
-
-
3.5 运行搜索引擎
-
启动搜索引擎。
streamlit run search.py当显示如下信息时,说明Streamlit已启动。
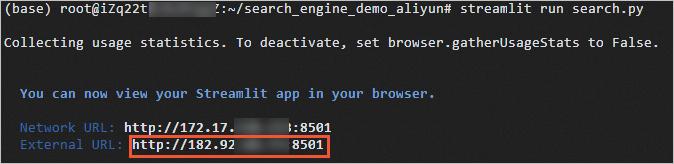
-
复制External URL显示的公网IP地址输入到浏览器,就可以访问并使用搜索引擎。
-
修改网页的爬取及排序。
本实验中,以Introduction to Programming in Python这个网页为起始网页,爬取了总计322个网页。因此,搜索的结果限于这322个网页。
您可以通过在web_graph.py中添加新的起始网页,爬取新的网页。例如,如果要增加以Algorithms这个网页为起始网页,做爬虫,让搜索引擎能搜到更多的网页。可以按如下步骤操作:
-
切换到pageranking目录。
cd /root/search_engine_demo_aliyun/pageranking -
打开web_graph.py文件。
vim web_graph.py -
按
i键进入编辑模式。 -
在seed_urls数组中,增加
https://algs4.cs.princeton.edu/home/。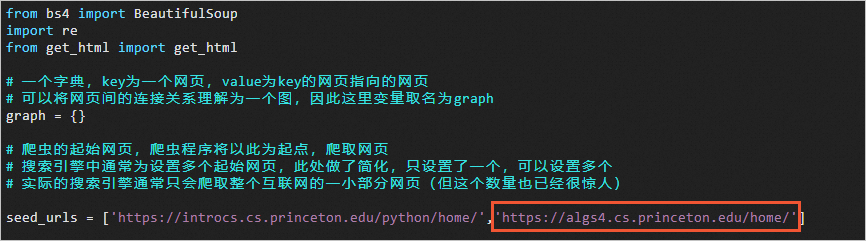
-
按Esc键,输入**:wq**,按Enter键,输入并保存文件。
-
-
执行如下命令,开始更新data文件夹中的数据。
其中,web_graph.txt、word_index.txt的生成需要较长的时间(约10分钟)。运行完毕后,搜索引擎即可覆盖更多的网页。
python setup.py
四、常见问题
4.1 运行setup.py时可能的问题
运行python setup.py做新的爬虫任务时,耗时较长,任务可能被中断。如果被中断,可以尝试重新运行。
4.2 如何使搜索引擎一直在线
在云服务器ECS上运行搜索引擎时,如果远程连接中断,search.py文件也会中止运行,导致搜索引擎无法使用。可以采用screen命令,解决这个问题。
-
执行
ctrl+z终止search.py程序。 -
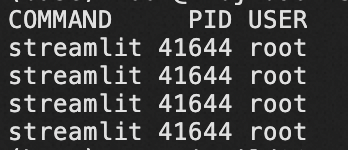
查看占用8501端口的进程。
lsof -i:8501例如,占用该端口的PID位41644,输入下列命令中止该进程,释放8501端口。
kill -9 41644 -
执行以下命令,使用screen新建一个窗口。
screen -S search
-
在新生成的窗口里,运行下列命令,启动搜索引擎。
streamlit run search.py -
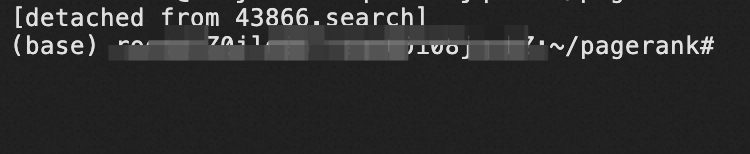
按住ctrl+A,再按D,出现下列提示(detached from …)后,说明detach成功。
这样,即使远程连接中断、退出登录ECS实例,搜索引擎仍然将正常工作。
相关文章:
在云服务器ECS上用Python写一个搜索引擎
在云服务器ECS上用Python写一个搜索引擎 一、场景介绍二、搜索引擎的组成2.1 网页的爬取及排序2.2 用户使用搜索引擎进行搜索 三、操作步骤3.1 环境准备3.2 安装Anaconda3.3 安装Streamlit3.4 下载搜索引擎代码3.5 运行搜索引擎 四、常见问题4.1 运行setup.py时可能的问题4.2 如…...

Python在智能手机芯片研发
Python在智能手机芯片研发中扮演着重要的角色。以下是几个方面的重要性: 快速原型设计:Python具有简洁易读的语法和丰富的第三方库,使工程师能够快速构建原型和进行快速迭代。这对于芯片研发来说,可以加快开发速度,减少…...
-K8S中的informa机制)
K8S学习指南(70)-K8S中的informa机制
引言 在 Kubernetes 集群中,Informer 是一种重要的机制,用于监控和处理集群中资源对象的变化。它是基于观察者模式设计的,允许开发者注册对某类资源对象的关注,并在对象发生变化时得到通知。本文将深入介绍 Kubernetes 中的 Info…...

「MCU」SD NAND芯片之国产新选择优秀
文章目录 前言 传统SD卡和可贴片SD卡 传统SD卡 可贴片SD卡 实际使用 总结 前言 随着目前时代的快速发展,即使是使用MCU的项目上也经常有大数据存储的需求。可以看到经常有小伙伴这样提问: 大家好,请问有没有SD卡芯片,可以…...

【QML COOK】- 002-添加一个图片
1. 编辑main.qml import QtQuickWindow {width: 800height: 800visible: truetitle: qsTr("Hello World")Image {anchors.fill: parentsource: "qrc:/Resources/Images/arrow.png"} }将Window的width和height都改成800,因为我们要添加的图片大…...

Java10:内部类
7 内部类(了解)7.1 成员内部类7.2 静态内部类7.3 局部内部类7.4 匿名内部类 2.3. 静态内部类2.4. Lambda表达式, 7 内部类(了解) 内部类:就是在一个类的内部再定义一个类。 分类: 成员内部类 静…...

PostgreSQL 支持的字段类型
PostgreSQL 支持多种字段类型,以下是 PostgreSQL 13 版本中支持的所有字段类型: 数值类型: smallint:小整数类型。integer:整数类型。bigint:大整数类型。decimal:精确小数类型。numeric&#x…...
npm报错error:03000086:digital envelope routines::initialization error
可能是因为node版本过高,与现在的项目不符合 这是降低node版本的命令,然后重新运行 npm install npm8.1.2 -g...
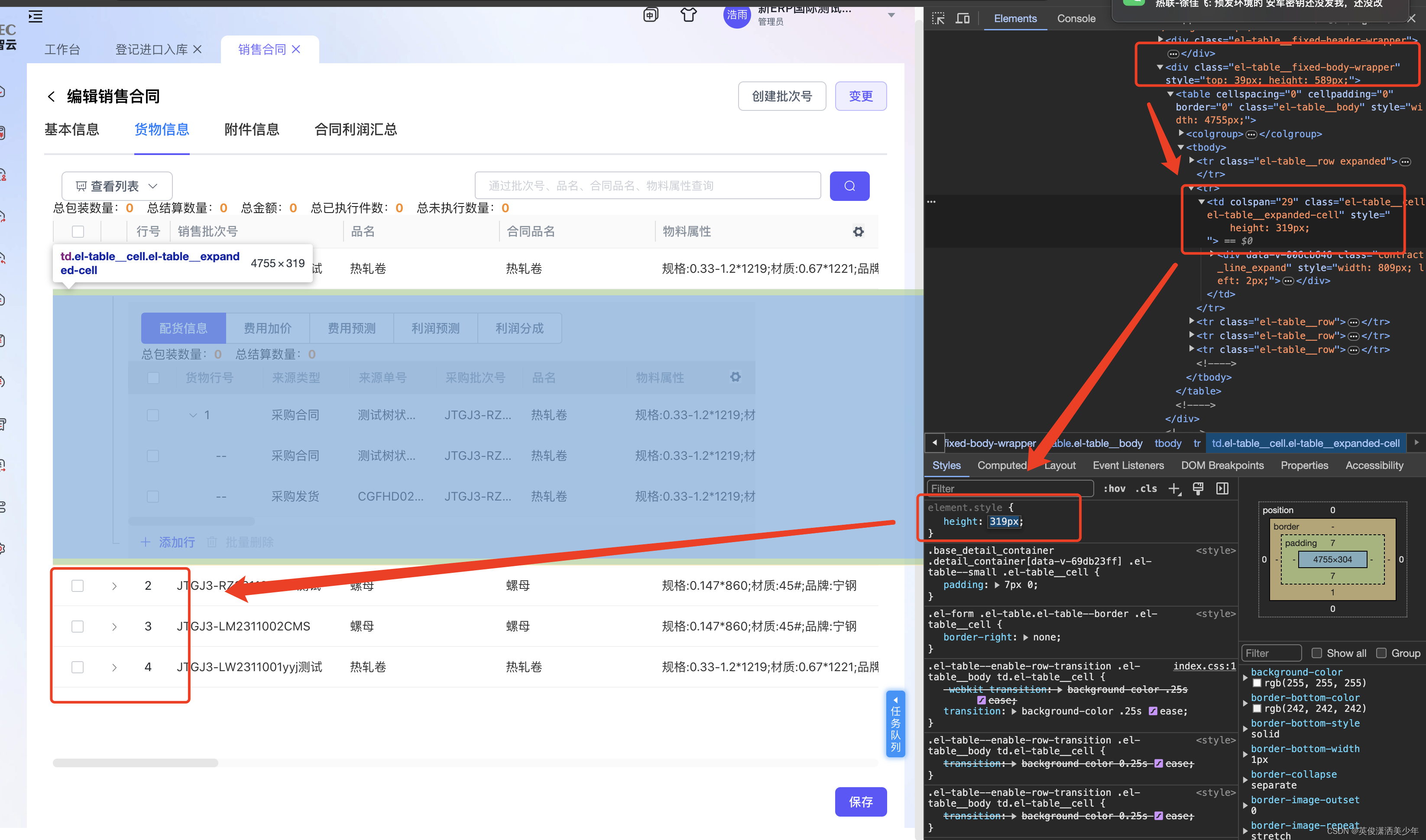
el-table 展开行表格,展开的内容高度可以变化时,导致的固定列错位的问题
问题描述 一个可展开的表格(列设置了type“expand”),并且展开后的内容高度可以变化,会导致后面所有行的固定列错位,图如下,展示行中是一个树形表格,默认不展示子级,点击树形表格的…...

python插入排序
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常使用in-place排序࿰…...
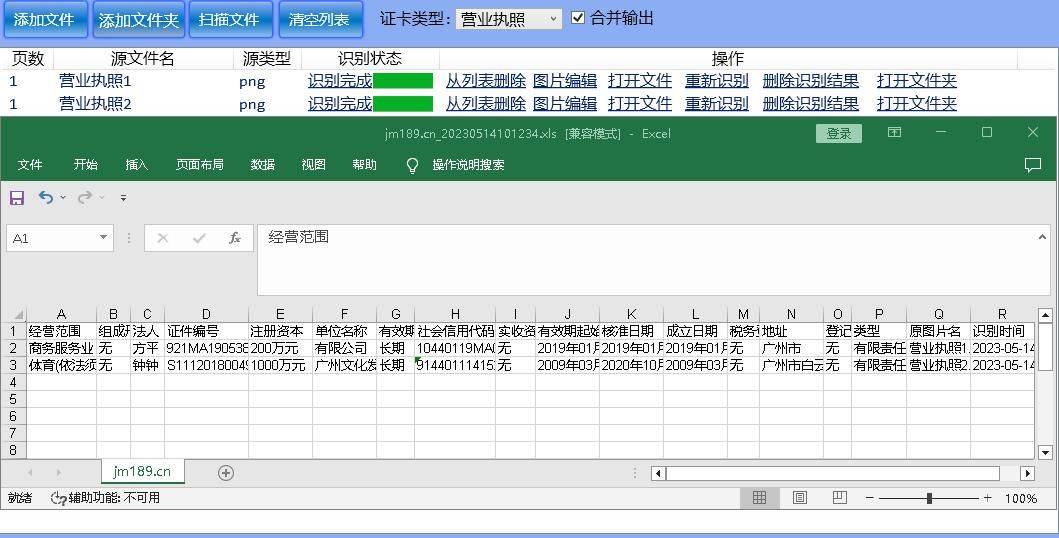
怎么将营业执照图片转为excel表格?(批量合并识别技巧)
一、为何要将营业执照转为excel表格? 1、方便管理:将营业执照转为excel格式,可以方便地进行管理和整理,快速查找需要的信息。 2、数据处理:Excel可以提供丰富的计算和数据分析功能,转化为excel后方便数据…...

关于java数组Arrays类
关于java数组Arrays类 前面的文章中,我们了解了数组创建方法等,我们本篇文章来了解一下数组的方法类Arrays,有了这个类,我们在日常写代码的时候就不不用自己去手动创建方法了😀。 Arrays类 数组的工具类java.util.A…...

LeetCode-58/709
1.最后一个单词的长度(58) 题目描述: 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 思路&…...

linux 流量监控
linux 流量监控 Linux 网络流量监控利器 iftop命令详解及实战 https://blog.csdn.net/qq_50247813/article/details/134164093 iftop命令详解 https://www.cnblogs.com/gaoyuechen/p/17300017.html 1 ubuntu如何查看流量监控 Ubuntu是一种非常流行的Linux发行版,…...
)
AUTOSAR从入门到精通-漫谈autosar软件架构(八)
目录 前言 原理 AUTOSAR的方法论 AUTOSAR架构的优点 AUTOSAR 软件架构 1.应用层...
C#设计模式之单例模式
介绍 单例模式(Singleton)保证一个类仅有一个实例,并提供一个访问它的全局访问点。 单例模式的结构图如下所示: 使用单例模式的原因 对一些类来说,只有一个实例是很重要的。如何才能保证一个类只有一个实例并且这个…...
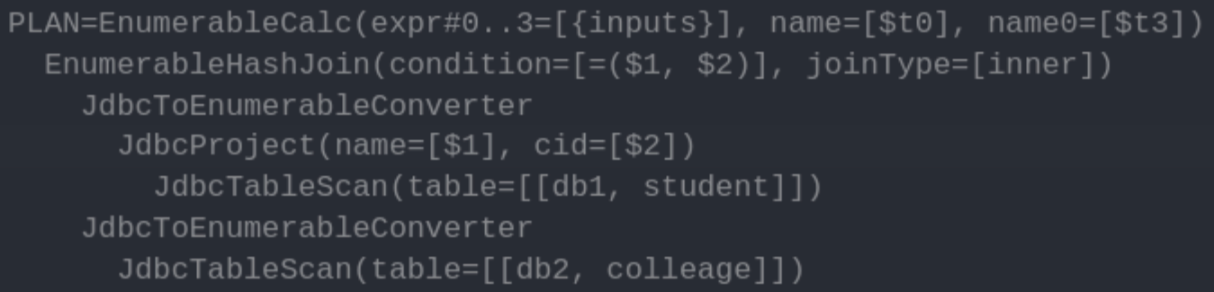
【源码预备】Calcite基础知识与概念:关系代数概念、查询优化、sql关键字执行顺序以及calcite基础概念
文章目录 一. 关系代数的基本知识二. 查询优化三. SQL语句的解析顺序1. FROM2. WHERE3. GROUP BY4. HAVING5. SELECT 四. Apache Calcite中的基本概念1. Adapter2. Calcite中的关系表达式2.1. 关系表达式例子2.2. 源码底层结构 3. Calcite的优化规则4. Calcite的Trait--算子物理…...

【Java 设计模式】23 种设计模式
文章目录 设计模式是什么计算机行业里的设计模式创建型模式(共 5 种)结构型模式(共 7 种)行为型模式(共 11 种) 总结 设计模式是什么 “每一个模式描述了一个在我们周围不断重复发生的问题,以及…...

ElasticSearch深度分页解决方案
一、前言 ElasticSearch是一个基于Lucene的搜索引擎,它支持复杂的全文搜索和实时数据分析。在实际应用中,我们经常需要对大量数据进行分页查询,但是传统的分页方式在处理大量数据时会遇到性能瓶颈。本文将介绍ElasticSearch分页工作原理、深…...

nginx下upstream模块详解
目录 一:介绍 二:特性介绍 一:介绍 Nginx的upstream模块用于定义后端服务器组,以及与这些服务器进行通信的方式。它是Nginx负载均衡功能的核心部分,允许将请求转发到多个后端服务器,并平衡负载。 在upst…...

Tiny AI Client:零依赖、轻量化的AI API调用库设计与实战
1. 项目概述与核心价值最近在折腾AI应用本地化部署和轻量化客户端时,发现了一个挺有意思的项目——piEsposito/tiny-ai-client。这名字起得就很直白,“tiny”意味着小巧,“ai-client”点明了它是一个AI客户端。乍一看,你可能会觉得…...

Cursor AI 编程助手配置优化:一键安装与自定义指南
1. 项目概述:为什么需要一套现成的 Cursor 配置?如果你和我一样,是 Cursor 的重度用户,那么你肯定经历过这样的阶段:刚上手时,觉得这个 AI 驱动的 IDE 简直是神器,但随着项目越来越复杂…...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...

保姆级教程:在Google Colab上用TensorFlow 2.0快速搭建你的第一个ACGAN图像生成器
零门槛实战:用ColabTensorFlow打造你的首个ACGAN数字生成器 想象一下,只需点击几次就能让AI学会生成逼真的手写数字——这不再是实验室里的黑科技。我们将利用Google Colab的免费GPU资源,带你用TensorFlow 2.0快速搭建一个能按需求生成特定数…...

苹果W1芯片如何通过低功耗无线技术重塑TWS耳机体验
1. 无线音频的功耗困局与苹果的破局思路 2016年9月,当苹果在发布会上首次亮出那对剪掉线缆的AirPods时,整个消费电子行业都在问同一个问题:它是怎么做到的?更具体地说,它如何解决了无线耳机领域最核心、也最令人头疼的…...

FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼
FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...

从“抄答案”到“会解题”:我是如何利用头歌实训平台,真正掌握Python数据分析的?
从“抄答案”到“会解题”:我的Python数据分析思维进阶之路 记得第一次打开头歌实训平台的Python数据分析题目时,我像大多数初学者一样,迫不及待地寻找"正确答案"。复制、粘贴、运行——看到绿色通过提示的瞬间,以为自己…...

php artisan serve 在window上执行报错的问题
今天偶发想学习一下Laravel 当执行 php artisan serve 结果一直没法起来 报错信息如下所示: 当前php 环境为 8.2.9 php -v解决办法: php -S localhost:9999 -t public...

【AI原生多任务学习实战白皮书】:SITS 2026官方未公开的5大优化范式与3类典型失效场景复盘
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在 SITS 2026 挑战赛中,AI 原生多任务学习(MTL)不再仅依赖共享特征表示,而是通过任务感知梯…...

八大网盘直链获取开源工具全面指南:如何高效管理你的云端文件下载
八大网盘直链获取开源工具全面指南:如何高效管理你的云端文件下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...