简单易懂的理解 PyTorch 中 Transformer 组件
目录
torch.nn子模块transformer详解
nn.Transformer
Transformer 类描述
Transformer 类的功能和作用
Transformer 类的参数
forward 方法
参数
输出
示例代码
注意事项
nn.TransformerEncoder
TransformerEncoder 类描述
TransformerEncoder 类的功能和作用
TransformerEncoder 类的参数
forward 方法
参数
返回类型
形状
示例代码
nn.TransformerDecoder
TransformerDecoder 类描述
TransformerDecoder 类的功能和作用
TransformerDecoder 类的参数
forward 方法
参数
返回类型
形状
示例代码
nn.TransformerEncoderLayer
TransformerEncoderLayer 类描述
TransformerEncoderLayer 类的功能和作用
TransformerEncoderLayer 类的参数
forward 方法
参数
返回类型
形状
示例代码
nn.TransformerDecoderLayer
TransformerDecoderLayer 类描述
TransformerDecoderLayer 类的功能和作用
TransformerDecoderLayer 类的参数
forward 方法
参数
返回类型
形状
示例代码
总结
torch.nn子模块transformer详解
nn.Transformer
Transformer 类描述
torch.nn.Transformer 类是 PyTorch 中实现 Transformer 模型的核心类。基于 2017 年的论文 “Attention Is All You Need”,该类提供了构建 Transformer 模型的完整功能,包括编码器(Encoder)和解码器(Decoder)部分。用户可以根据需要调整各种属性。
Transformer 类的功能和作用
- 多头注意力: Transformer 使用多头自注意力机制,允许模型同时关注输入序列的不同位置。
- 编码器和解码器: 包含多个编码器和解码器层,每层都有自注意力和前馈神经网络。
- 适用范围广泛: 被广泛用于各种 NLP 任务,如语言翻译、文本生成等。
Transformer 类的参数
- d_model (int): 编码器/解码器输入的特征数(默认值为512)。
- nhead (int): 多头注意力模型中的头数(默认值为8)。
- num_encoder_layers (int): 编码器中子层的数量(默认值为6)。
- num_decoder_layers (int): 解码器中子层的数量(默认值为6)。
- dim_feedforward (int): 前馈网络模型的维度(默认值为2048)。
- dropout (float): Dropout 值(默认值为0.1)。
- activation (str 或 Callable): 编码器/解码器中间层的激活函数,默认为 ReLU。
- custom_encoder/decoder (可选): 自定义的编码器或解码器(默认值为None)。
- layer_norm_eps (float): 层归一化组件中的 eps 值(默认值为1e-5)。
- batch_first (bool): 如果为 True,则输入和输出张量的格式为 (batch, seq, feature)(默认值为False)。
- norm_first (bool): 如果为 True,则在其他注意力和前馈操作之前进行层归一化(默认值为False)。
- bias (bool): 如果设置为 False,则线性和层归一化层将不学习附加偏置(默认值为True)。
forward 方法
forward 方法用于处理带掩码的源/目标序列。
参数
- src (Tensor): 编码器的输入序列。
- tgt (Tensor): 解码器的输入序列。
- src/tgt/memory_mask (可选): 序列掩码。
- src/tgt/memory_key_padding_mask (可选): 键填充掩码。
- src/tgt/memory_is_causal (可选): 指定是否应用因果掩码。
输出
- 输出 Tensor 的形状为
(T, N, E)或(N, T, E)(如果batch_first=True),其中T是目标序列长度,N是批次大小,E是特征数。
示例代码
import torch
import torch.nn as nn# 创建 Transformer 实例
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)# 输入数据
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))# 前向传播
out = transformer_model(src, tgt)
这段代码展示了如何创建并使用 Transformer 模型。在这个例子中,src 和 tgt 分别是随机生成的编码器和解码器的输入张量。输出 out 是模型的最终输出。
注意事项
- 掩码生成: 可以使用
generate_square_subsequent_mask方法来生成序列的因果掩码。 - 配置灵活性: 由于 Transformer 类的可配置性,用户可以轻松调整模型结构以适应不同的任务需求。
nn.TransformerEncoder
TransformerEncoder 类描述
torch.nn.TransformerEncoder 类在 PyTorch 中实现了 Transformer 模型的编码器部分。它是一系列编码器层的堆叠,用户可以通过这个类构建类似于 BERT 的模型。
TransformerEncoder 类的功能和作用
- 多层编码器结构: TransformerEncoder 由多个 Transformer 编码器层组成,每一层都包括自注意力机制和前馈网络。
- 适用于各种 NLP 任务: 可用于语言模型、文本分类等多种自然语言处理任务。
- 灵活性和可定制性: 用户可以自定义编码器层的数量和层参数,以适应不同的应用需求。
TransformerEncoder 类的参数
- encoder_layer:
TransformerEncoderLayer实例,表示单个编码器层(必需)。 - num_layers: 编码器中子层的数量(必需)。
- norm: 层归一化组件(可选)。
- enable_nested_tensor: 如果为 True,则输入会自动转换为嵌套张量(在输出时转换回来),当填充率较高时,这可以提高 TransformerEncoder 的整体性能。默认为 True(启用)。
- mask_check: 是否检查掩码。默认为 True。
forward 方法
forward 方法用于顺序通过编码器层处理输入。
参数
- src (Tensor): 编码器的输入序列(必需)。
- mask (可选 Tensor): 源序列的掩码(可选)。
- src_key_padding_mask (可选 Tensor): 批次中源键的掩码(可选)。
- is_causal (可选 bool): 如指定,应用因果掩码。默认为 None;尝试检测因果掩码。
返回类型
- Tensor
形状
- 请参阅 Transformer 类中的文档。
示例代码
import torch
import torch.nn as nn# 创建 TransformerEncoderLayer 实例
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)# 创建 TransformerEncoder 实例
transformer_encoder = nn.TransformeEncoder(encoder_layer, num_layers=6)# 输入数据
src = torch.rand(10, 32, 512) # 随机输入# 前向传播
out = transformer_encoder(src)
这段代码展示了如何创建并使用 TransformerEncoder。在这个例子中,src 是随机生成的输入张量,transformer_encoder 是由 6 层编码器层组成的编码器。输出 out 是编码器的最终输出。
nn.TransformerDecoder
TransformerDecoder 类描述
torch.nn.TransformerDecoder 类实现了 Transformer 模型的解码器部分。它是由多个解码器层堆叠而成,用于处理编码器的输出并生成最终的输出序列。
TransformerDecoder 类的功能和作用
- 多层解码器结构: TransformerDecoder 由多个 Transformer 解码器层组成,每层包括自注意力机制、交叉注意力机制和前馈网络。
- 处理编码器输出: 解码器用于处理编码器的输出,并根据此输出和之前生成的输出序列生成新的输出。
- 应用场景广泛: 适用于各种基于 Transformer 的生成任务,如机器翻译、文本摘要等。
TransformerDecoder 类的参数
- decoder_layer:
TransformerDecoderLayer实例,表示单个解码器层(必需)。 - num_layers: 解码器中子层的数量(必需)。
- norm: 层归一化组件(可选)。
forward 方法
forward 方法用于将输入(及掩码)依次通过解码器层进行处理。
参数
- tgt (Tensor): 解码器的输入序列(必需)。
- memory (Tensor): 编码器的最后一层输出序列(必需)。
- tgt/memory_mask (可选 Tensor): 目标/内存序列的掩码(可选)。
- tgt/memory_key_padding_mask (可选 Tensor): 批次中目标/内存键的掩码(可选)。
- tgt_is_causal/memory_is_causal (可选 bool): 指定是否应用因果掩码。
返回类型
- Tensor
形状
- 请参阅 Transformer 类中的文档。
示例代码
import torch
import torch.nn as nn# 创建 TransformerDecoderLayer 实例
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)# 创建 TransformerDecoder 实例
transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)# 输入数据
memory = torch.rand(10, 32, 512) # 编码器的输出
tgt = torch.rand(20, 32, 512) # 解码器的输入# 前向传播
out = transformer_decoder(tgt, memory)
这段代码展示了如何创建并使用 TransformerDecoder。在这个例子中,memory 是编码器的输出,tgt 是解码器的输入。输出 out 是解码器的最终输出。
nn.TransformerEncoderLayer
TransformerEncoderLayer 类描述
torch.nn.TransformerEncoderLayer 类构成了 Transformer 编码器的基础单元,每个编码器层包含一个自注意力机制和一个前馈网络。这种标准的编码器层基于论文 "Attention Is All You Need"。
TransformerEncoderLayer 类的功能和作用
- 自注意力机制: 通过自注意力机制,每个编码器层能够捕获输入序列中不同位置间的关系。
- 前馈网络: 为序列中的每个位置提供额外的转换。
- 灵活性和可定制性: 用户可以根据应用需求修改或实现不同的编码器层。
TransformerEncoderLayer 类的参数
- d_model (int): 输入中预期的特征数量(必需)。
- nhead (int): 多头注意力模型中的头数(必需)。
- dim_feedforward (int): 前馈网络模型的维度(默认值=2048)。
- dropout (float): Dropout 值(默认值=0.1)。
- activation (str 或 Callable): 中间层的激活函数,可以是字符串("relu" 或 "gelu")或一元可调用对象。默认值:relu。
- layer_norm_eps (float): 层归一化组件中的 eps 值(默认值=1e-5)。
- batch_first (bool): 如果为 True,则输入和输出张量以 (batch, seq, feature) 的格式提供。默认值:False(seq, batch, feature)。
- norm_first (bool): 如果为 True,则在注意力和前馈操作之前进行层归一化。否则之后进行。默认值:False(之后)。
- bias (bool): 如果设置为 False,则线性和层归一化层将不会学习附加偏置。默认值:True。
forward 方法
forward 方法用于将输入通过编码器层进行处理。
参数
- src (Tensor): 传递给编码器层的序列(必需)。
- src_mask (可选 Tensor): 源序列的掩码(可选)。
- src_key_padding_mask (可选 Tensor): 批次中源键的掩码(可选)。
- is_causal (bool): 如果指定,则应用因果掩码作为源掩码。默认值:False。
返回类型
- Tensor
形状
- 请参阅 Transformer 类中的文档。
示例代码
import torch
import torch.nn as nn# 创建 TransformerEncoderLayer 实例
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)# 输入数据
src = torch.rand(10, 32, 512) # 随机输入# 前向传播
out = encoder_layer(src)
或者在 batch_first=True 的情况下:
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True)
src = torch.rand(32, 10, 512)
out = encoder_layer(src)
这段代码展示了如何创建并使用 TransformerEncoderLayer。在这个例子中,src 是随机生成的输入张量。输出 out 是编码器层的输出。
nn.TransformerDecoderLayer
TransformerDecoderLayer 类描述
torch.nn.TransformerDecoderLayer 类是构成 Transformer 模型解码器的基本单元。这个标准的解码器层基于论文 "Attention Is All You Need"。它由自注意力机制、多头注意力机制和前馈网络组成。
TransformerDecoderLayer 类的功能和作用
- 自注意力和多头注意力机制: 使解码器能够同时关注输入序列的不同部分。
- 前馈网络: 为序列中的每个位置提供额外的转换。
- 灵活性和可定制性: 用户可以根据应用需求修改或实现不同的解码器层。
TransformerDecoderLayer 类的参数
- d_model (int): 输入中预期的特征数量(必需)。
- nhead (int): 多头注意力模型中的头数(必需)。
- dim_feedforward (int): 前馈网络模型的维度(默认值=2048)。
- dropout (float): Dropout 值(默认值=0.1)。
- activation (str 或 Callable): 中间层的激活函数,可以是字符串("relu" 或 "gelu")或一元可调用对象。默认值:relu。
- layer_norm_eps (float): 层归一化组件中的 eps 值(默认值=1e-5)。
- batch_first (bool): 如果为 True,则输入和输出张量以 (batch, seq, feature) 的格式提供。默认值:False(seq, batch, feature)。
- norm_first (bool): 如果为 True,则在自注意力、多头注意力和前馈操作之前进行层归一化。否则之后进行。默认值:False(之后)。
- bias (bool): 如果设置为 False,则线性和层归一化层将不会学习附加偏置。默认值:True。
forward 方法
forward 方法用于将输入(及掩码)通过解码器层进行处理。
参数
- tgt (Tensor): 解码器层的输入序列(必需)。
- memory (Tensor): 编码器的最后一层输出序列(必需)。
- tgt/memory_mask (可选 Tensor): 目标/内存序列的掩码(可选)。
- tgt/memory_key_padding_mask (可选 Tensor): 批次中目标/内存键的掩码(可选)。
- tgt_is_causal/memory_is_causal (bool): 指定是否应用因果掩码。
返回类型
- Tensor
形状
- 请参阅 Transformer 类中的文档。
示例代码
import torch
import torch.nn as nn# 创建 TransformerDecoderLayer 实例
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)# 输入数据
memory = torch.rand(10, 32, 512) # 编码器的输出
tgt = torch.rand(20, 32, 512) # 解码器的输入# 前向传播
out = decoder_layer(tgt, memory)
或者在 batch_first=True 的情况下:
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8, batch_first=True)
memory = torch.rand(32, 10, 512)
tgt = torch.rand(32, 20, 512)
out = decoder_layer(tgt, memory)
这段代码展示了如何创建并使用 TransformerDecoderLayer。在这个例子中,memory 是编码器的输出,tgt 是解码器的输入。输出 out 是解码器层的输出。
总结
本篇博客深入探讨了 PyTorch 的 torch.nn 子模块中与 Transformer 相关的核心组件。我们详细介绍了 nn.Transformer 及其构成部分 —— 编码器 (nn.TransformerEncoder) 和解码器 (nn.TransformerDecoder),以及它们的基础层 —— nn.TransformerEncoderLayer 和 nn.TransformerDecoderLayer。每个部分的功能、作用、参数配置和实际应用示例都被全面解析。这些组件不仅提供了构建高效、灵活的 NLP 模型的基础,还展示了如何通过自注意力和多头注意力机制来捕捉语言数据中的复杂模式和长期依赖关系。
相关文章:
简单易懂的理解 PyTorch 中 Transformer 组件
目录 torch.nn子模块transformer详解 nn.Transformer Transformer 类描述 Transformer 类的功能和作用 Transformer 类的参数 forward 方法 参数 输出 示例代码 注意事项 nn.TransformerEncoder TransformerEncoder 类描述 TransformerEncoder 类的功能和作用 Tr…...

搭建Eureka服务注册中心
一、前言 我们在别的章节中已经详细讲解过eureka注册中心的作用,本节会简单讲解eureka作用,侧重注册中心的搭建。 Eureka作为服务注册中心可以进行服务注册和服务发现,注册在上面的服务可以到Eureka上进行服务实例的拉取,主要作用…...

【React】react-router-dom中的HashRouter和BrowserRouter实现原理
1. 前言 在之前整理BOM的五个对象时,提到: location.hash发生改变后,会触发hashchange事件,且history栈中会增加一条记录,但页面不会重新加载——实现HashRouter的关键history.pushState(state, , URL)执行后…...

生物信息学中的可重复性研究
科学就其本质而言,是累积渐进的。无论你是使用基于网络的还是基于命令行的工具,在进行研究时都应保证该研究可被其他研究人员重复。这有利于你的工作的累积与进展。在生物信息学领域,这意味着如下内容。 工作流应该有据可查。这可能包括在电脑…...

css-img图像同比缩小
1. HTML 中使图像按比例缩小 CSS 来控制图像的大小,并保持其宽高比 <!DOCTYPE html> <html> <head><style>.image-container {width: 300px; /* 设置容器宽度 */height: auto; /* 让高度自适应 */}.image-container img {width: 100%; /* …...
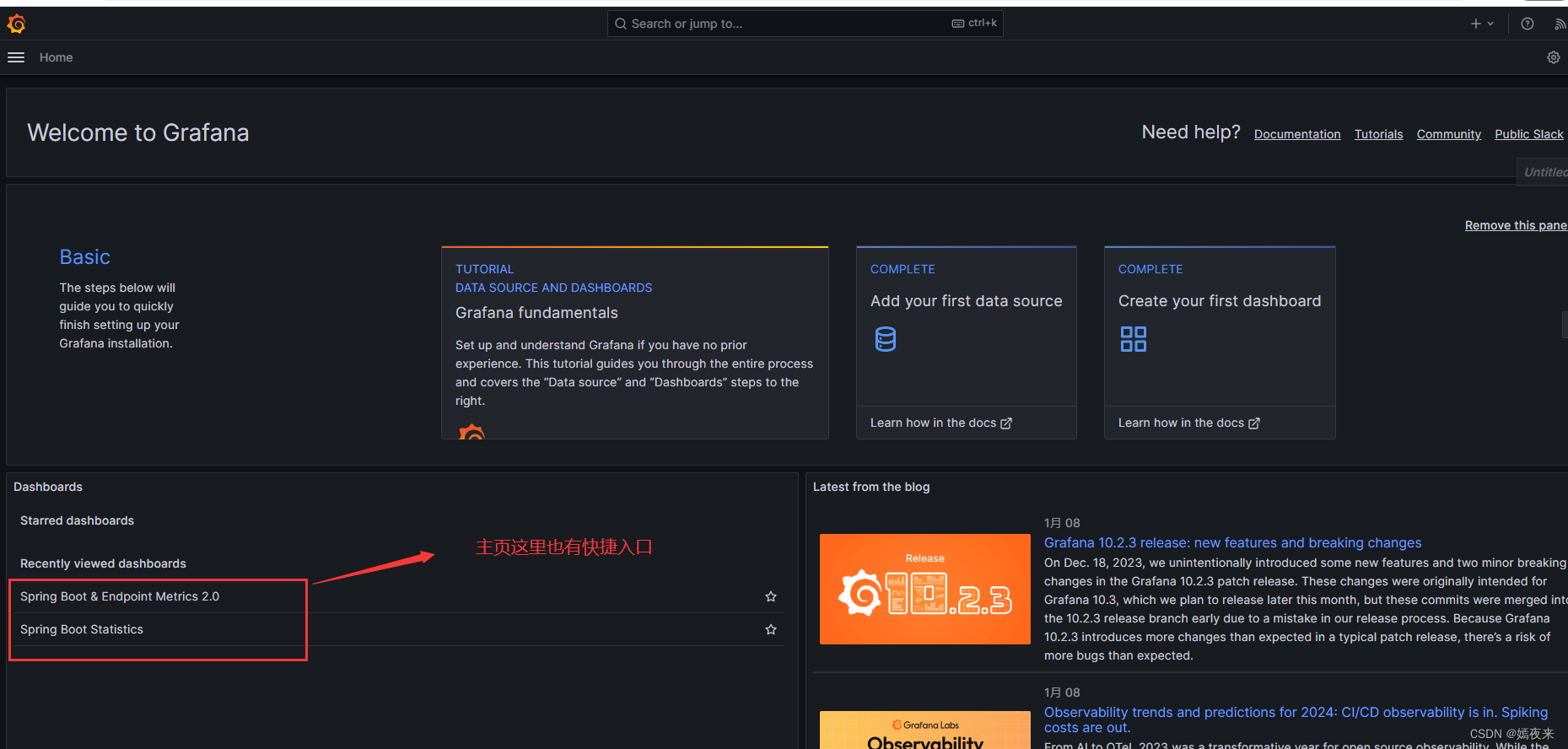
SpringBoot+Prometheus+Grafana搭建应用监控系统
1.应用监控系统介绍 SpringBoot的应用监控方案比较多,SpringBootPrometheusGrafana是比较常用的一种解决方案,主要的监控数据的处理逻辑如下: SpringBoot 的 actuator 提供了应用监控端点,可以对外暴露监控数据信息。Prometheu…...
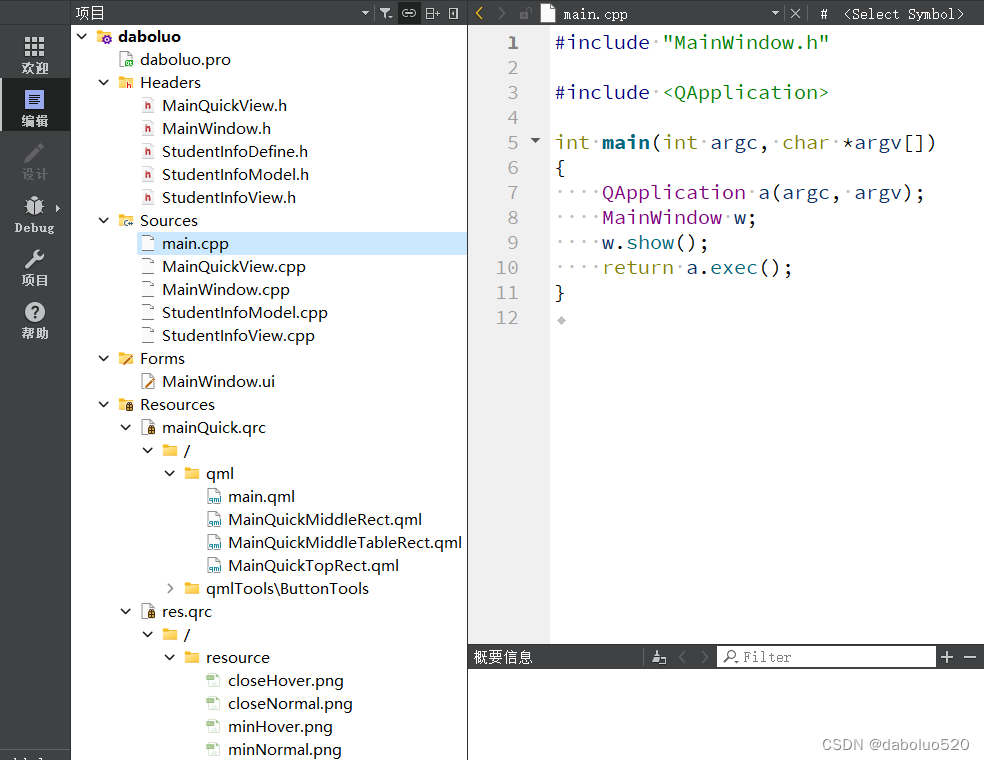
QT c++和qml交互实例
文章目录 一、demo效果图二、c和qml交互的基本方式1、qml 调用 C 类对象2、C 类对象调用 qml3、qml 给 C 发送信号4、C 给 qml 发送信号 三、关键代码1、工程结构图2、c代码MainWindow.cppMainQuickView.cppStudentInfoView.cppStudentInfoModel.cpp 3、qml代码main.qmlMainQui…...
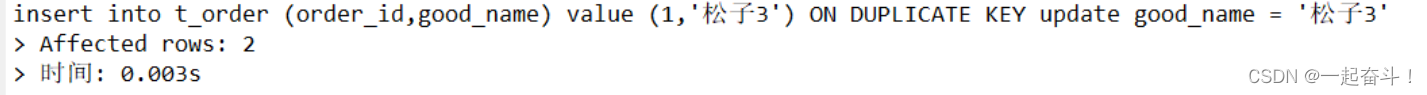
mysql基础-数据操作之增删改
目录 1.新增数据 1.1单条数据新增 1.2多条数据新增 1.3查询数据新增 2.更新 2.1单值更新 2.2多值更新 2.3批量更新 2.3.1 批量-单条件更新 2.3.2批量-多条件更新 2.4 插入或更新 2.5 联表更新 3.删除 本次分享一下数据库的DML操作语言。 操作表的数据结构…...
)
写字母(文件)
请编写函数,将大写字母写入文件中。 函数原型 void WriteLetter(FILE *f, int n);说明:参数 f 为文件指针,n 为字母数目(1 ≤ n ≤ 26)。函数将前 n 个大写英文字母写入 f 所指示的文件中。 裁判程序 #include <stdio.h> #include &…...
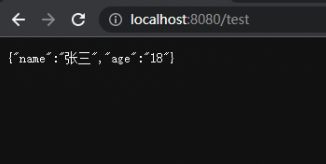
基于Jackson自定义json数据的对象转换器
1、问题说明 后端数据表定义的id主键是Long类型,一共有20多位。 前端在接收到后端返回的json数据时,Long类型会默认当做数值类型进行处理。但前端处理20多位的数值会造成精度丢失,于是导致前端查询数据出现问题。 测试前端Long类型的代码 …...

【Java】缓存击穿解决方案
文章目录 什么是SingleFlight?优化缺点优化策略 什么是SingleFlight? SingleFlight是go语言中sync包中的一个东西。它用于确保在并发环境下某个操作(例如,函数调用)即使被多个goroutine同时请求,也只会被执…...
【HarmonyOS】掌握 Stage 模型的核心概念与应用
从今天开始,博主将开设一门新的专栏用来讲解市面上比较热门的技术 “鸿蒙开发”,对于刚接触这项技术的小伙伴在学习鸿蒙开发之前,有必要先了解一下鸿蒙,从你的角度来讲,你认为什么是鸿蒙呢?它出现的意义又是…...
2024年甘肃省职业院校技能大赛 “信息安全管理与评估”赛项样题卷①
2024年甘肃省职业院校技能大赛 高职学生组电子与信息大类信息安全管理与评估赛项样题 第一阶段:第二阶段:模块二 网络安全事件响应、数字取证调查、应用程序安全第二阶段 网络安全事件响应第一部分 网络安全事件响应第二部分 数字取证调查第三部分 应用程…...

我的AI之旅开始了
知道重要,但是就是不动。 今天告诉自己,必须开始学习了。 用这篇博文作为1月份AI学习之旅的起跑点吧。 从此,无惧AI,无惧编程。 AI之路就在脚下。 AI,在我理解,就是让机器变得更加智能&#…...

Day25 235二叉搜索树的公共祖先 701二叉搜索树插入 450二叉搜索树删除
235 二叉搜索树的最近公共祖先 如果利用普通二叉树的方法,就是利用后序遍历回溯从低向上搜索,遇到左子树有p,右子树有q,那么当前结点就是最近公共祖先。本题是二叉搜索树,所以说是有序的,一定能够简化上面…...

android系列-init 挂载文件系统
1.init 挂载文件系统 //android10\system\core\init\main.cppint main(int argc, char** argv) {return FirstStageMain(argc, argv); } //android10\system\core\init\first_stage_init.cppint FirstStageMain(int argc, char** argv) {CHECKCALL(mount("tmpfs",…...

Spring 七种事务传播性介绍
作者:vivo 互联网服务器团队 - Zhou Shaobin 本文主要介绍了Spring事务传播性的相关知识。 Spring中定义了7种事务传播性: PROPAGATION_REQUIRED PROPAGATION_SUPPORTS PROPAGATION_MANDATORY PROPAGATION_REQUIRES_NEW PROPAGATION_NOT_SUPPORTED…...

Count the Colors ZOJ - 1610
题目链接 题意: 给定n个区间[ l, r ]和颜色c, 每次给[l, r]涂上c这个颜色. 后面的涂色会覆盖之前的涂色. 最后要求输出区间[0, 8000]中每种颜色及其出现的次数, 如果该颜色没有出现过则不输出. 思路:典型的线段树区间染色问题,一般这种题…...

MATLAB点云处理总目录
一、点云滤波 原始点云包含过多噪点和冗余点,滤波和采样往往是点云预处理的必要步骤 1.滤波 重复点去除 NAN或INF无效点去除 自定义半径滤波 2.采样 基于空间格网的点云抽稀 随机下采样 均匀体素下采样 非均匀体素下采样 二、邻近搜索 如何组织点云快速获取当前…...

C语言逗号表达式如何计算
在 C 语言中,逗号表达式是一种特殊的表达式形式,它由逗号分隔的多个表达式组成。 逗号表达式的计算过程如下:1、从左到右依次计算每个表达式的值。2、最终返回的值是最右边表达式的值。3、逗号表达式的求值过程是顺序执行的,不会…...

如何提升SQL存储过程逻辑复用_封装通用存储过程函数
SQL Server无函数式存储过程,需用标量函数(单值计算)或表值函数(结果集)替代;标量函数禁用DML和非确定性函数,ITVF性能优于MSTVF;MySQL函数须声明DETERMINISTIC等属性;跨…...

基于MCP协议构建专属AI开发助手:从原理到实践
1. 项目概述:一个为开发者定制的MCP服务器最近在折腾AI应用开发,特别是想给Claude、Cursor这类智能助手增加一些“超能力”,让它们能直接操作我本地的开发环境。比如,让AI帮我直接运行单元测试、查看最近的Git提交、或者分析某个目…...

WebGL入门:Three.js高级材质与光照
WebGL入门:Three.js高级材质与光照 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊WebGL和Three.js的高级特性。作为一个全栈开发者和极客玩家,我对3D可视化有着浓厚的兴趣。今天就来分享一下Three.js中的高级材质和光…...

Bootstrap-Sass 终极指南:如何在现代 Web 项目中快速集成 Bootstrap 3
Bootstrap-Sass 终极指南:如何在现代 Web 项目中快速集成 Bootstrap 3 【免费下载链接】bootstrap-sass Official Sass port of Bootstrap 2 and 3. 项目地址: https://gitcode.com/gh_mirrors/bo/bootstrap-sass Bootstrap-Sass 是 Bootstrap 3 的官方 Sass…...
)
认识Python网络套接字编程之流式套接字(一)
流式套接字当你需要使用 TCP 协议进行通信时,需要创建流式套接字。这是套接字编程中最常用的一种。光谈这些概念显得很抽象,还是举送外卖的这个例子,假设你点了一份烤鸭,外卖骑手需要先去店铺取餐,然后送到你的家门口&…...
【Transformer系列】从One-Hot到Embedding:构建AI语言理解的基石
1. 从One-Hot编码说起:AI的第一堂语言课 想象你正在教一个外星人认识汉字。你拿出一本字典说:"这里有10万个字,每个字对应一个编号,猫是第12345号,狗是第67890号。"这就是最原始的One-Hot编码思想——用一串…...

【模块化设计-13】OAM 线程模块详解
该模块是基于 RT-Thread 实时操作系统实现的一个 OAM(Operation, Administration and Maintenance,操作、管理和维护)专用线程模块,核心功能是提供独立的 OAM 业务处理线程、消息队列机制和定时器管理能力,适用于嵌入式…...

免费抠图软件一键抠图无水印有哪些?2026年最全工具推荐
最近在小红书和抖音上,我看到很多人都在问同一个问题:有没有好用的免费抠图软件,一键抠图还无水印的?说实话,现在抠图工具确实多,但真正好用的、免费的、还无水印的,选择反而没那么多。我自己用…...
系统安装)
从零到一:手把手教你用U盘搞定OpenEuler(欧拉)系统安装
1. 为什么选择OpenEuler? OpenEuler作为一款开源的企业级Linux发行版,凭借其高性能、高可靠性和安全性,已经成为众多开发者和企业的首选。我第一次接触OpenEuler是在一个服务器迁移项目中,当时需要寻找一个稳定且长期维护的Linux发…...
)
超越‘点亮出图’:深入Sensor AE增益配置的三种模式与实战验证(以SC230AI/OV08A10/IMX335为例)
超越“点亮出图”:深入Sensor AE增益配置的三种模式与实战验证 在嵌入式Camera开发领域,成功点亮Sensor并输出图像仅仅是万里长征的第一步。真正的挑战往往出现在图像质量调优阶段,尤其是自动曝光(AE)与增益配置这一专…...