DeepSeek 发布全新开源大模型,数学推理能力超越 LLaMA-2
自从 LLaMA 被提出以来,开源大型语言模型(LLM)的快速发展就引起了广泛研究关注,随后的一些研究就主要集中于训练固定大小和高质量的模型,但这往往忽略了对 LLM 缩放规律的深入探索。
开源 LLM 的缩放研究可以促使 LLM 提高性能和拓展应用领域,对于推进自然语言处理和人工智能领域具有重要作用。在缩放规律的指导下,为了解决目前 LLM 缩放领域中存在的不明确性,由 DeepSeek 的 AI 团队发布了全新开源模型 LLMDeepSeek LLM。此外,作者还在这个基础模型上进行了监督微调(SFT)和直接偏好优化(DPO),从而创建了 DeepSeek Chat 模型。
在性能方面,DeepSeek LLM 67B 在代码、数学和推理任务中均超越了 LLaMA-2 70B,而 DeepSeek LLM 67B Chat 在开放性评估中更是超越了 GPT-3.5。这一系列的表现为开源 LLM 的未来发展奠定了一定基础。
论文题目:
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
论文链接:
https://arxiv.org/abs/2401.02954
与作为人工通用智能(AGI)新标杆的 LLaMa 相比,本文提出的 DeepSeek LLM:
-
数据集规模:DeepSeek LLM 使用了一个包含 2 万亿字符的双语数据集进行预训练,这比 LLaMA 的数据集更大。
-
模型性能:DeepSeek LLM 在多个基准测试中表现优于 LLaMA,特别是在代码、数学和推理方面。
-
模型架构:虽然 DeepSeek LLM 在微观设计上主要遵循 LLaMA ,但在宏观设计上有所不同。DeepSeek LLM 7B 是一个 30 层网络,而 DeepSeek LLM 67B 有 95 层。这些层数调整在保持与其他开源模型参数一致性的同时优化了模型的训练和推理。
-
可缩放研究:DeepSeek LLM 对模型和数据尺度的可缩放性进行了深入研究,并成功地揭示了最优模型/数据缩放分配策略,从而预测了大规模模型的性能。
-
安全性评估:DeepSeek LLM 67B 表现优秀,能够在实践中提供无害化的回复。
预训练
-
数据:为了在确保模型在预训练阶段能够充分学习并获得高质量的语言知识,在构建数据集过程中,采取了去重、过滤和混合三个基本阶段的方法,来增强数据集的丰富性和多样性。为了提高计算效率,作者还描述了分词器的实现方式,采用了基于 tokenizers 库的字节级字节对编码(BBPE)算法,使用了预分词化和设置了适当的词汇表大小。
-
架构:主要借鉴了 LLaMA 的 Pre-Norm 结构,其中包括 RMSNorm 函数,使用 SwiGLU 作为前馈层的激活函数,中间层维度为 ,此外还引入了 Rotary Embedding 用于位置编码。为了优化推理成本,67B 模型没采用传统的 Multi-Head Attention(MHA),而是用了 GroupedQuery Attention(GQA)。
-
超参数:通过我们的实验证明,使用多步学习率调度程序的最终性能与余弦调度程序基本一致,如图 1(a) 所示,作者还在图 1(b) 中演示了调整多步学习率调度程序不同阶段比例,可以略微提升性能。
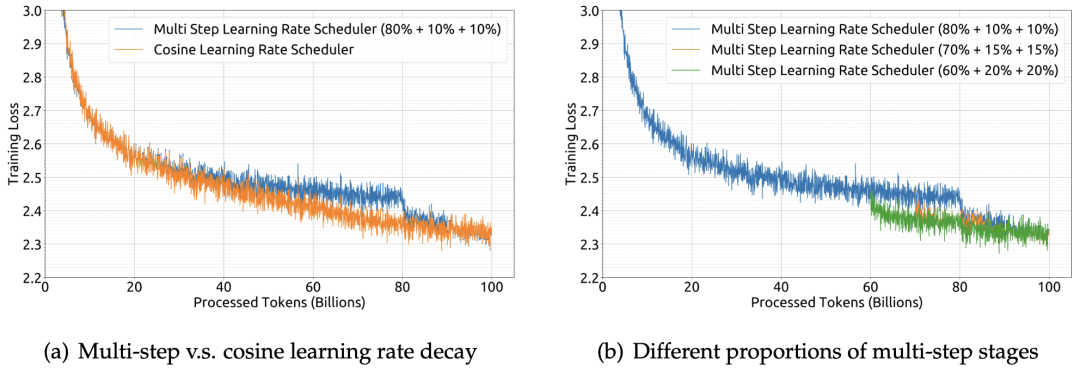
▲图1 使用不同学习率调度程序或调度程序不同参数的训练损失曲线
缩放规律及影响
作者通过大量实验,探讨了模型和数据大小与计算预算之间的关系。研究发现,随着计算预算的增加,模型性能可以通过增加模型规模和数据规模来预测性地提高。但是,不同数据集对缩放法则有显著影响,高质量的数据可以推动更大模型的训练。
超参数的缩放规律
在这部分,作者研究了 batch size 和学习率的缩放律,并找到了它们随模型大小的变化趋势。图 2 的实验展示了 batch size 和学习率与计算预算之间的关系,为确定最佳超参数提供了经验框架。
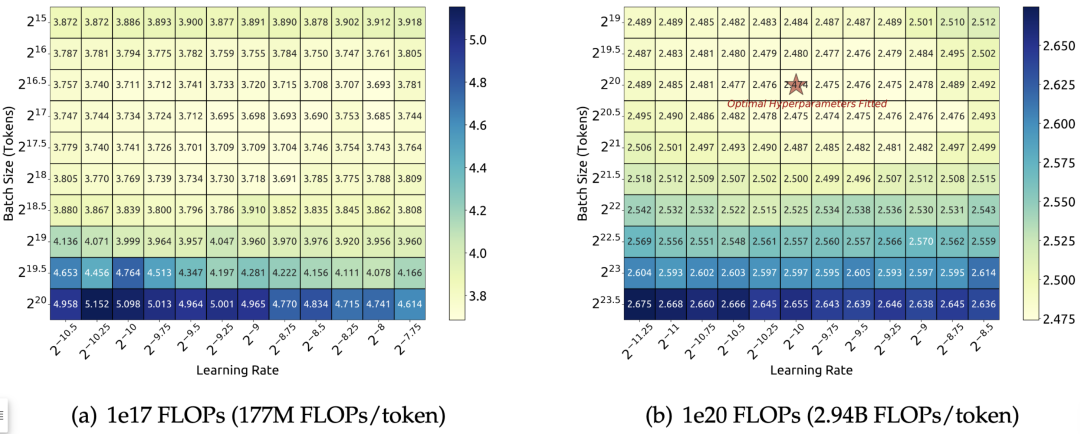
▲图2 训练损失关于 batch size 和学习率的变化
如图 3 所示,经验证实,batch size 随计算预算的增加而增加,而学习率则随计算预算的增加而减小。作者指出,他们的研究结果与一些早期研究中提到的观点不一致。这些研究可能认为最佳 batch size 仅与泛化误差𝐿有关。然而,本文的发现似乎暗示了更为复杂的关系,可能受到模型规模和数据分配的影响。作者将在未来工作中进一步研究以了解如何进行超参数和训练动态选择。
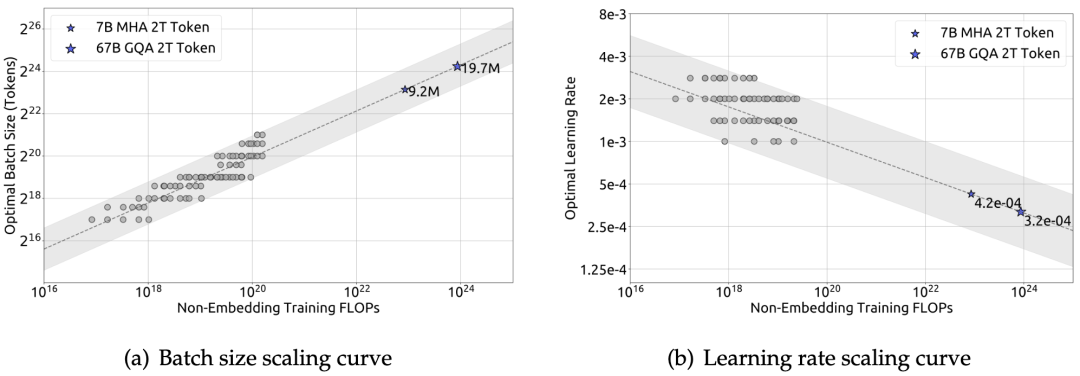
▲图3 batch size 和学习率的缩放曲线
估算最优的模型和数据缩放
表 1 的结果表明,数据质量会影响最优模型/数据缩放分配策略。数据质量越高,增加的计算预算应更多地分配给模型缩放。作者使用了三个不同的数据集来研究缩放定律,发现最优模型/数据缩放分配策略与数据质量一致。数据质量提高时,模型缩放指数逐渐增加,而数据缩放指数减小,这表明增加的计算预算应更多地分配给模型而不是数据。
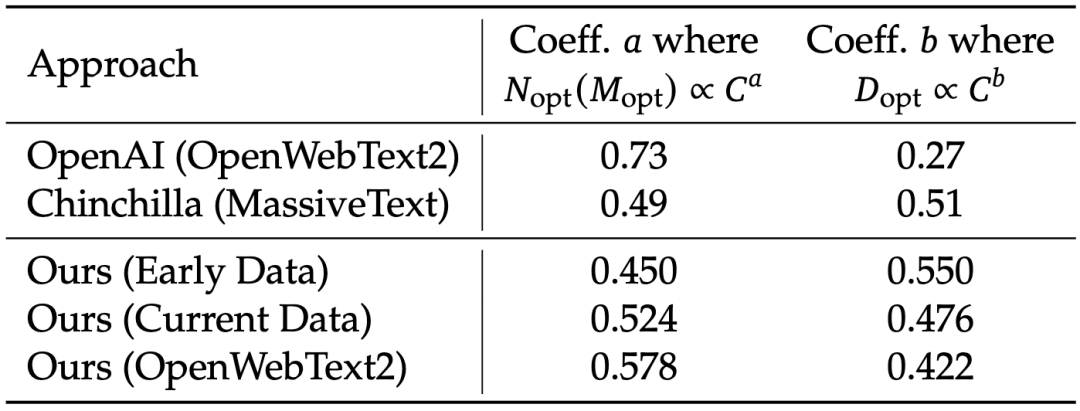
▲表1 模型缩放和数据缩放的系数随训练数据分布而变化
对齐
对齐流程主要包括两个阶段:监督微调(SFT)和直接偏好优化(DPO)。
监督微调
在微调阶段,作者对 7B 模型进行了 4 个 epoch 的微调,而由于观察到 67B 模型存在较为严重的过拟合问题,对 67B 模型仅进行了 2 个 epoch 的微调。
作者还评估了微调过程中聊天模型的重复率。根据实验结果所示,随着数学 SFT 数据量的增加,重复率往往上升。这可以归因于数学 SFT 数据中偶尔包含相似的推理模式。
直接偏好优化(DPO)
此外,作者还采用了直接偏好优化算法(DPO)以进一步增强模型的能力,这是对齐大语言模型的一种简单而有效的方法。为了构建 DPO 训练的偏好数据,模型根据有益和无害两个方面进行了训练。
实验结果显示,DPO 在增强模型的开放性生成能力方面很成功,同时在标准基准测试中几乎没有差异。
实验评估
实验表明,尽管 DeepSeek 模型是在 2 万亿字符的双语语料库上预训练的,但在英语语言理解基准上表现与 token 数差不多但侧重于英语的 LLaMA-2 模型相当。实验结果显示,在相同数据集上训练的 7B 和 67B 模型之间,模型缩放对某些任务(如 GSM8K 和 BBH)的性能提升效果明显。然而,随着数学数据比例的增加,小型和大型模型之间的性能差异可能会减小。
在表 2 中,DeepSeek 67B 相对于 LLaMA-2 70B 的优势大于 DeepSeek 7B 相对于 LLaMA-2 7B 的优势,突显了语言冲突对较小模型的更大影响。此外,LLaMA-2 在某些中文任务上表现出色,这表明某些基本能力如数学推理可以在语言之间有效地迁移。然而,对于涉及中文成语使用的任务,DeepSeek LLM 相较于 LLaMA-2 表现更出色,特别是在预训练期间涉及大量中文 token 的情况下。
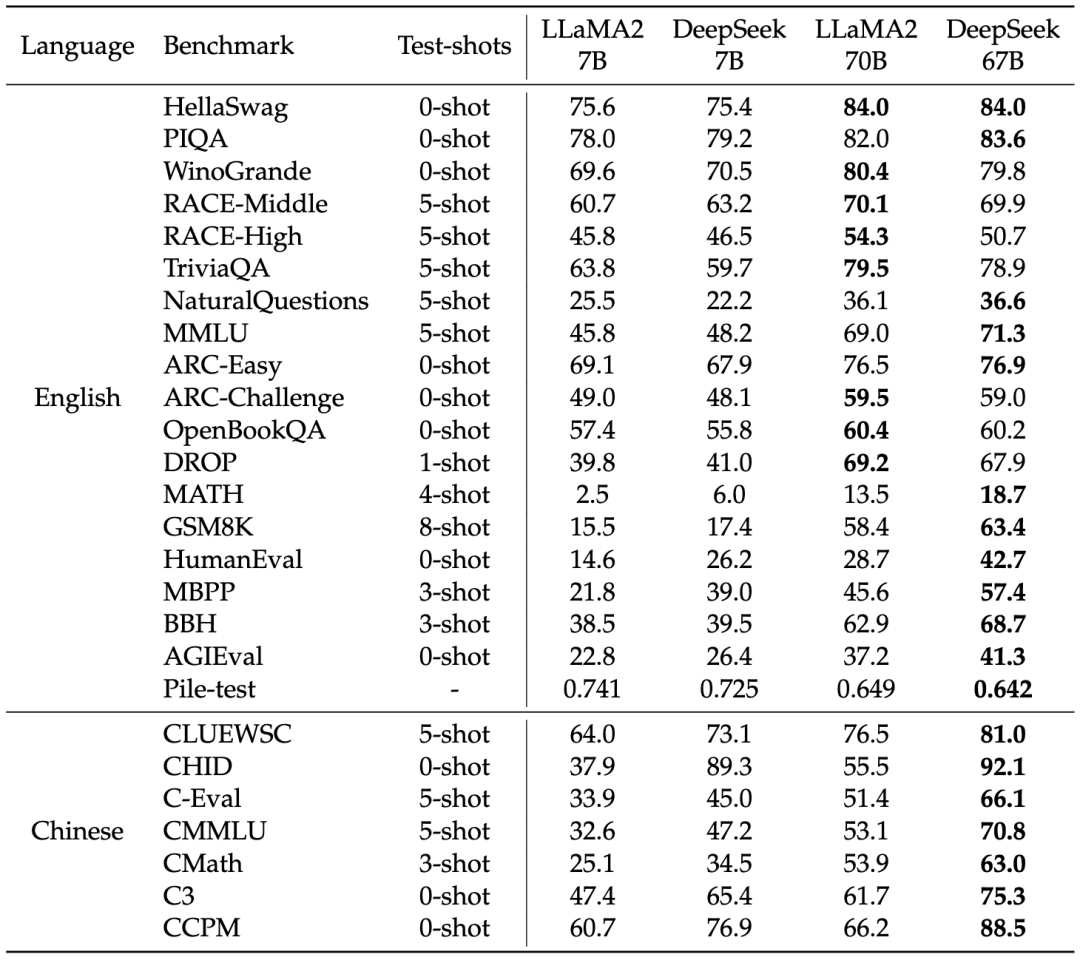
▲表2 主要实验结果
聊天模型
如表格 3 所示,微调后的 DeepSeek 聊天模型在大多数任务上取得了整体改进,表现出对多样性任务的适应能力。
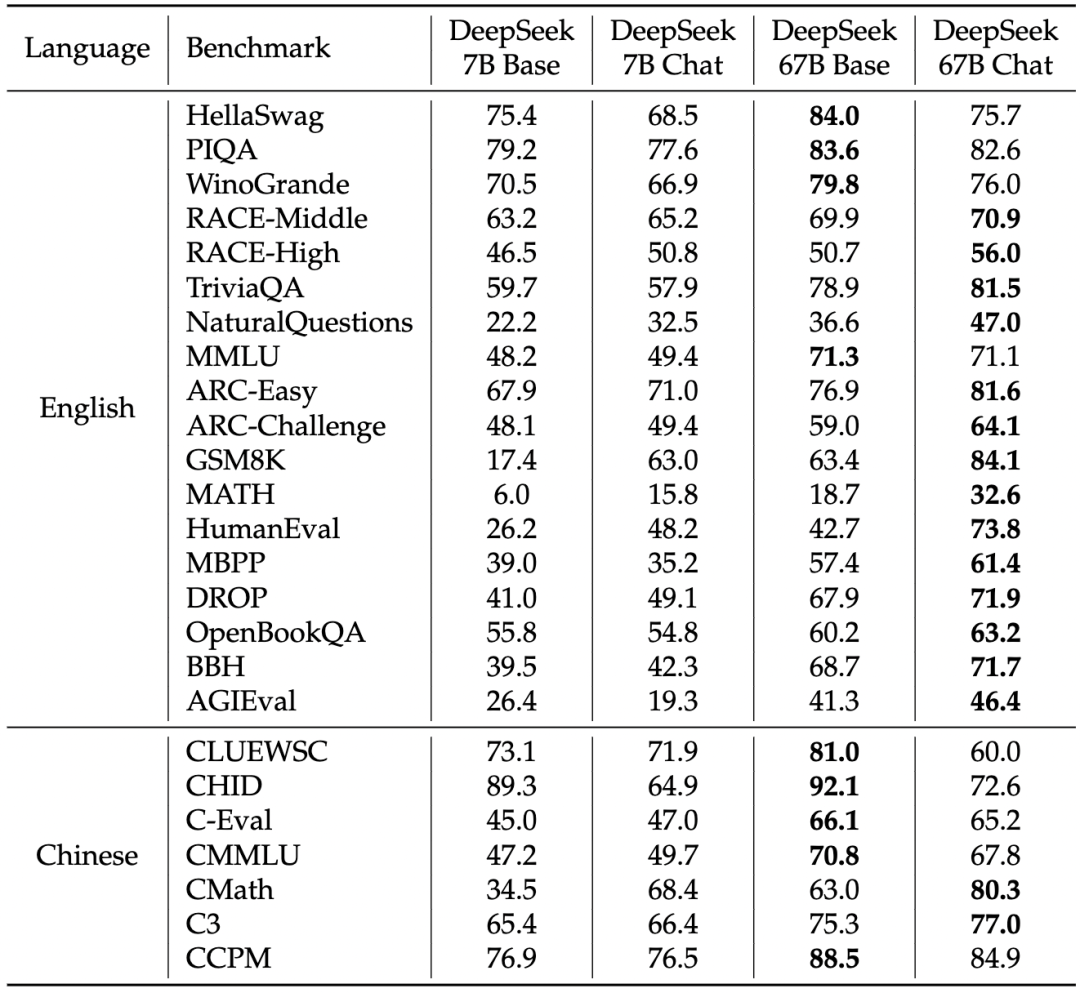
▲表3 基础模型和聊天模型之间的比较
-
知识相关任务:在与知识相关的任务(如 TriviaQA、MMLU、C-Eval)中,基础模型和聊天模型之间存在一些波动。作者指出,这种波动不一定意味着在 SFT(聊天模型监督微调)后获取或失去了知识,而是强调 SFT 的价值在于实现聊天模型在零样本设置中的性能与基础模型在少样本设置中相当,这与真实场景一致。
-
推理任务:由于 SFT 实例采用了 CoT 格式,聊天模型在推理任务中表现出些许改进。作者认为 SFT 阶段并未学到推理能力,而是学到了正确的推理路径格式。
-
性能下降任务:一些任务在微调后持续表现出性能下降,特别是涉及填空或句子完成的任务(如 HellaSwag)。可能纯语言模型更适合处理这类任务。
-
数学和编程任务:在数学和编程任务中,微调后的模型表现出显著的改进,例如 HumanEval 和 GSM8K 的提升了 20 多分。这可能是由于 SFT 阶段学到了编程和数学方面的额外知识,尤其是在代码完成和代数问题方面。作者指出,未来工作可能需要在预训练阶段引入更多样化的数据以全面理解数学和编程任务。
开放性评估
中文开放性评估
实验结果显示,DeepSeek 67B Chat 模型在基本的中文语言任务中位于所有模型的第一梯队,甚至在中文基础语言能力方面超过了最新版本的 GPT-4。在高级中文推理任务中,本文的模型得分明显高于其他中文 LLM,在更复杂的中文逻辑推理和数学计算中有着卓越性能。
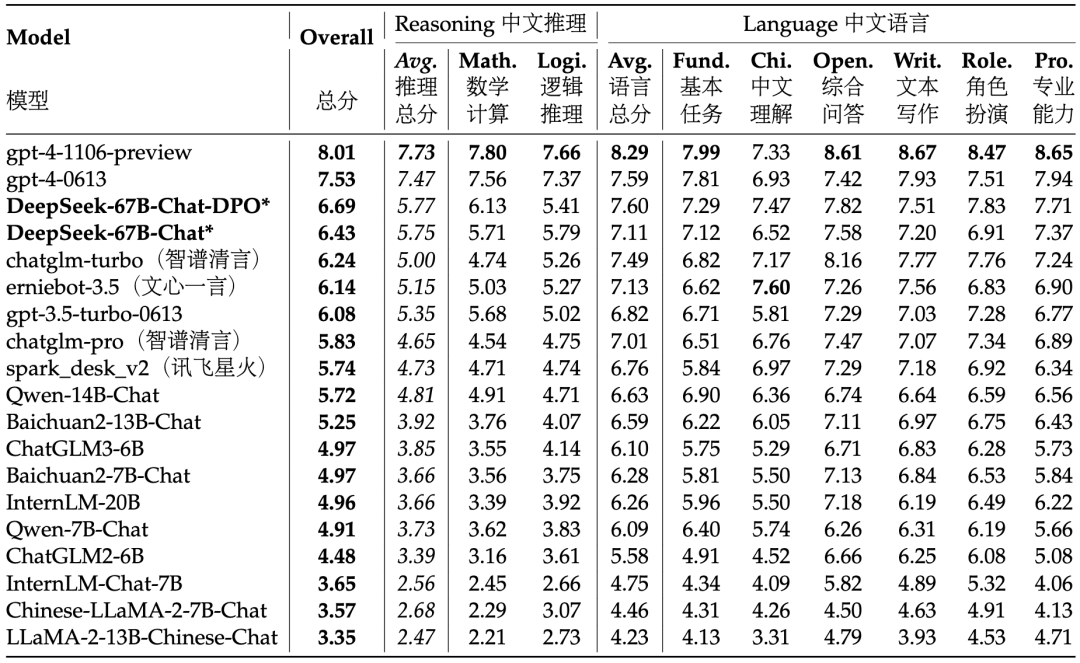
▲表4 AlignBench 排行榜
英文开放性评估
DeepSeek LLM 67B Chat 在性能上超过了 LLaMA-2-Chat 70B 等其他开源模型,与 GPT-3.5-turbo 相媲美。此外,经过 DPO 阶段后,DeepSeek LLM 67B Chat 的平均分进一步提升,仅次于 GPT-4。这表明 DeepSeek LLM 在多轮开放性生成方面具有强大能力。

▲表5 MT-Bench 评估
保留集评估
保留集是模型在训练阶段未曾接触到的数据集,用于评估模型在面对新领域和未见过的样本时的泛化能力。作者采用了多个基准任务和指标,包括对话、数学、编程、语言理解等方面的测试。这些任务涵盖了模型需要在实际应用中面对的各种场景和挑战。DeepSeek 在各个阶段的保留集评估中都展现出卓越的性能,验证了其在处理未知任务和领域时的强大能力。
安全性评估
DeepSeek 67B Chat 模型在安全性评估方面表现良好,其安全性得分高于 ChatGPT 和 GPT-4。在不同的安全测试类别中,该模型的表现也相对出色。然而,模型在某些任务上的表现可能受到数据集的局限性影响。例如,初始版本的中文数据可能在某些中文特定主题上表现不佳。此外,由于模型主要基于中英文数据集,对其他语言的熟练程度可能相对较低,需要在实际应用中审慎对待。
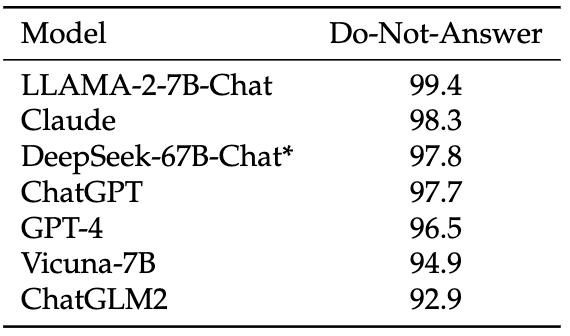
▲表6 Do-Not-Answer 得分
进一步讨论
分阶段微调
小型模型在数学和代码数据集上需要更长时间的微调,但这将损害模型的对话能力。为了解决这个问题,作者进行了分阶段微调:
-
第一阶段使用所有可用数据进行微调;
-
第二阶段专注于使用对话数据进行微调。
表 7 的结果表明,第二阶段不会损害模型在编程和数学方面的熟练程度,同时降低了重复行为并增强了指令跟随的能力。

▲表7 两阶段微调结果
多选题
多选题要求模型不仅具有相应的知识,还要理解选项的含义。在对齐阶段,作者测试了添加 2000 万个中文多项选择问题并获得了如表 8 所示的性能。为防止数据污染,作者对 C-Eval 验证集和 CMMLU 测试集进行了去重。

▲表8 添加多项选择问题数据的影响
额外添加的多项选择问题不仅对中文多项选择基准有益,还有助于改善英文基准,这表明模型解决多选题的能力已经得到了增强。然而,用户在对话交互中可能不会认为模型变得更加智能,因为这些交互是生成回复而非解决多项选择问题。
在预训练中的指令数据
作者探讨了在预训练的后期阶段引入指令数据对基础模型性能的影响。他们在预训练的最后 10% 阶段整合了包含多项选择题在内的 500 万条指令数据,结果观察到基础 LLM 模型的性能改进。然而,最终结果几乎与在 SFT 阶段添加相同数据时获得的结果相同。因此,尽管这种方法增强了基础模型在基准测试中的性能,但其整体与在预训练过程中不引入这些指令数据相当。
系统提示
这里探讨了系统提示对模型性能的影响。他们采用 LLaMA-2 的系统提示,并稍微修改成为他们的系统提示,明确要求模型以有益、尊重、诚实的方式回答问题,同时禁止包含有害内容。
如表 9 所示,作者观察到一个有趣的现象,即在引入系统提示时,7B LLM 的性能略微下降。然而,当使用 67B LLM 时,添加提示导致结果显著改善。他们解释这种差异的原因是更大的模型能更好理解系统提示背后的预期含义,使它们能够更有效地遵循指令并生成更出色的回复。相反,较小的模型难以充分理解系统提示,训练和测试之间的不一致可能对它们的性能产生负面影响。
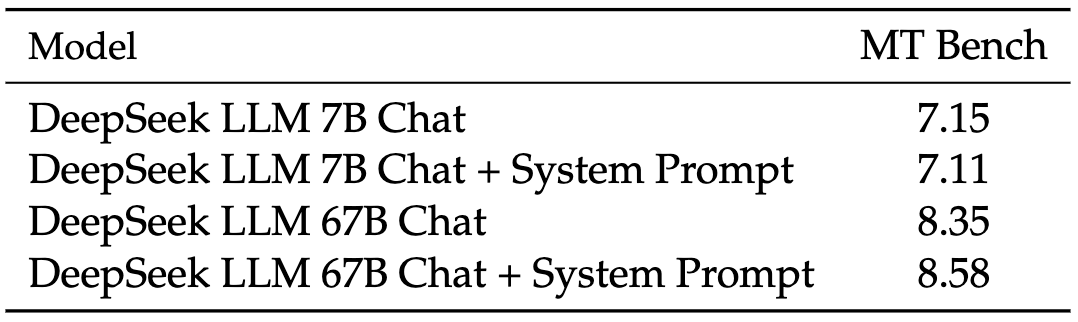
▲表9 添加系统提示的影响
总结
作者在本文中提出了 DeepSeek LLM,并详细解释了超参数选择、缩放规律以及进行的各种微调尝试,校准了以前工作中的缩放规律,提出了一种新的最优模型/数据缩放分配策略。通过缩放规律的指导,我们使用最佳超参数进行预训练,并进行了更为全面的评估。
然而,DeepSeek Chat 仍然存在一些已知限制:如在预训练后缺乏知识更新、生成非事实信息以及在某些中文特定主题上性能不佳。此外,模型在其他语言上的熟练程度仍然相对脆弱,需要谨慎对待。
目前,该团队正在为即将推出的 DeepSeek LLM 版本构建更大、更完善的数据集,希望能在下一版本中改进推理、中文知识、数学和编程能力。作者的这一系列努力,也体现了他们要在推动 NLP 和 AIG 领域的创新和提升模型性能方面长期努力的承诺。

相关文章:
DeepSeek 发布全新开源大模型,数学推理能力超越 LLaMA-2
自从 LLaMA 被提出以来,开源大型语言模型(LLM)的快速发展就引起了广泛研究关注,随后的一些研究就主要集中于训练固定大小和高质量的模型,但这往往忽略了对 LLM 缩放规律的深入探索。 开源 LLM 的缩放研究可以促使 LLM…...
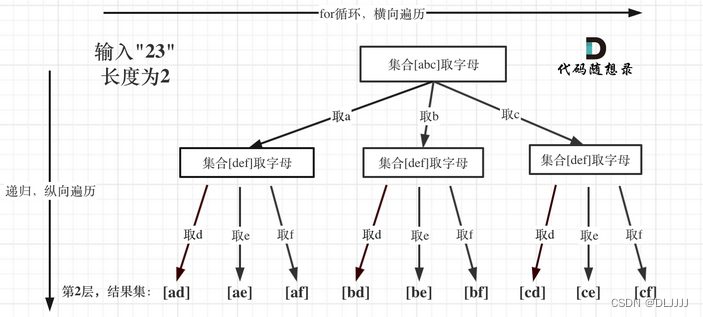
代码随想录算法训练营第二十一天| 回溯 216. 组合总和 III 17. 电话号码的字母组合
216. 组合总和 III 可以参考77.组合中关于选取数组的相关操作。 递归函数的返回值以及参数:一般为void类型 递归函数终止条件:path这个数组的大小如果达到k,说明我们找到了一个子集大小为k的组合了,然后当n为0的时候࿰…...
微服务架构最佳实践
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 构建和管理微服务是一项艰巨的任务。这是因为微服务就像多个并行的整体应用程序,它们都必须处于同步通信和并发运行时间。因此,在设计和构建…...

国内首款支持苹果Find My芯片-伦茨科技ST17H6x
深圳市伦茨科技有限公司(以下简称“伦茨科技”)发布ST17H6x Soc平台。成为继Nordic之后全球第二家取得Apple Find My「查找」认证的芯片厂家,该平台提供可通过Apple Find My认证的Apple查找(Find My)功能集成解决方案。…...
linux 01 centos镜像下载,服务器,vmware模拟服务器
https://www.bilibili.com/video/BV1pz4y1D73n?p3&vd_source4ba64cb9b5f8c56f1545096dfddf8822 01.使用的版本 国内主要使用的版本是centos 02.centos镜像下载 这里的是centos7 一.阿里云官网地址:https://www.aliyun.com/ 二. -----【文档与社区】 —【…...
)
Linux安装RabbitMq明白纸(无图)
Linux安装RabbitMq步骤 安装环境Erlang和RabbitMQ版本对照安装包下载地址登录Linux服务器创建安装目录将之前下载的两个rpm文件上传到这个目录下,并解压安装Erlang安装完成后,查看Erlang版本安装socat(RabbitMq安装需要这个)解压并…...
Android - CrashHandler 全局异常捕获器
官网介绍如下:Thread.UncaughtExceptionHandler (Java Platform SE 8 ) 用于线程因未捕获异常而突然终止时调用的处理程序接口。当线程由于未捕获异常而即将终止时,Java虚拟机将使用thread . getuncaughtexceptionhandler()查询该线程的UncaughtExceptio…...

商品源数据如何采集,您知道吗?
如今,电子商务已经渗透到了人们生活的方方面面。2020年新冠肺炎突如其来,打乱了人们正常的生产生活秩序,给经济发展带来了极大的影响。抗击疫情过程中,为避免人员接触和聚集,以“无接触配送”为营销卖点的电子商务迅速…...
输入输出流、字符字节流、NIO
1、对输入输出流、字符字节流的学习,以之前做的批量下载功能为例 批量下载指的是,将多个文件打包到zip文件中,然后下载该zip文件。 1.1下载网络上的文件 代码参考如下: import java.io.*; import java.net.URL; import java.n…...
格式化处理)
js中对数字,超大金额(千位符,小数点)格式化处理
前言 这个问题的灵感来自线上一个小bug,前两天刚看完同事写的代码,对数字类型处理的很好,之前一直都是用正则和toFixed(2)处理数字相关,后面发现使用numeral.js处理更完美。 对于下面这种数据的处理,你能想到几种方法…...

Android 打开热点2.4G系统重启解决
Android 打开热点2.4G系统重启解决 文章目录 Android 打开热点2.4G系统重启解决一、前言二、过程分析1、Android 设备开机后第一次打开热点2.4G系统重启2、日志分析3、设备重启原因 三、解决方法四、其他1、wifi/有线网 代理信息也可能导致系统重启2、Android13 热点默认5G频道…...

全链路压力测试有哪些主要作用
全链路压力测试是在软件开发和维护过程中不可或缺的一环,尤其在复杂系统和高并发场景下显得尤为重要。下面将详细介绍全链路压力测试的主要作用。 一、全链路压力测试概述 全链路压力测试是指对软件系统的全部组件(包括前端、后端、数据库、网络、中间件等)在高负载…...

【python基础教程】print输出函数和range()函数的正确使用方式
嗨喽,大家好呀~这里是爱看美女的茜茜呐 print()有多个参数,参数个数不固定。 有四个关键字参数(sep end file flush),这四个关键字参数都有默认值。 print作用是将objects的内容输出到file中,objects中的…...

LeetCode255.用队列实现栈
题目传送门:Leetcode255.用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压…...
PHPStudy快速搭建网站并结合内网穿透远程访问本地站点
文章目录 [toc]使用工具1. 本地搭建web网站1.1 下载phpstudy后解压并安装1.2 打开默认站点,测试1.3 下载静态演示站点1.4 打开站点根目录1.5 复制演示站点到站网根目录1.6 在浏览器中,查看演示效果。 2. 将本地web网站发布到公网2.1 安装cpolar内网穿透2…...

AI嵌入式K210项目(1)-芯片开发板介绍
系列文章目录 在人工智能大潮滚滚而来的时代,作为一个从事嵌入式行业多年的程序猿倍感焦虑,有被替代的焦虑,也有跟不上新技术步伐的无奈,本系列文章将介绍一个从硬件设计到ai训练、最后到模型部署的完整案例;第一阶段…...

Blazor中使用impress.js
impress.js是什么? 你想在浏览器中做PPT吗?比如在做某些类似于PPT自动翻页,局部放大之类,炫酷无比。 在Blazor中,几经尝试,用以下方法可以实现。写文不易,请点赞、收藏、关注,并在转…...

ros2 ubuntu 20.04 安装 foxy
设置区域设置 确保您有一个支持UTF-8. 如果您处于最小环境(例如 docker 容器)中,则区域设置可能是最小的,例如POSIX. 我们使用以下设置进行测试。但是,如果您使用不同的 UTF-8 支持的区域设置,应该没问题。…...
Blazor 错误笔记
1. 运行时问题 Microsoft.NETCore.App.Runtime.Mono.browser-wasm Microsoft.NETCore.App.Runtime.Mono.browser-wasm 是一个 .NET Core 运行时的包,用于在浏览器中运行 .NET Core 应用程序。它是针对 WebAssembly 架构的 .NET Core 运行时,可以在浏览…...
【深度学习1对1指导】
...

【软考高级架构】论文范文19——论软件系统架构风格
论软件系统架构风格 摘要 软件系统架构风格是描述系统结构和行为的抽象模式,为不同应用领域提供了经过验证的设计方案。合理选择与组合架构风格能够有效指导系统分解、组件划分和交互设计,从而提升系统的可维护性、可扩展性和性能等质量属性。本文以笔者主导的某大型制造企…...

3步掌握SMUDebugTool:AMD Ryzen处理器调试完全指南
3步掌握SMUDebugTool:AMD Ryzen处理器调试完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitco…...

黑苹果配置神器Hackintool:从新手到高手的完整指南
黑苹果配置神器Hackintool:从新手到高手的完整指南 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool Hackintool被誉为"黑苹果瑞士军刀",是配置和…...

转子永磁式无刷混合励磁电机关键技术【附仿真】
✨ 长期致力于次谐波、无刷调磁、有限元建模与分析、多目标鲁棒优化、弱磁运行研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于次谐波调制与变电流…...

Orange Pi i 96开发板实战:从硬件解析到家庭服务器与物联网应用部署
1. 项目概述:为什么是Orange Pi i 96?最近在捣鼓一些边缘计算和轻量级服务器的项目,手头正好需要一块性能足够、接口丰富但又足够小巧、功耗可控的开发板。市面上树莓派当然是首选,但供货和价格嘛,你懂的。于是我把目光…...

STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍
STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍 在电池供电的嵌入式设备开发中,功耗控制往往是决定产品成败的关键因素。想象一下,一款设计精良的便携式环境监测仪,如果因为功耗问题导致频繁更换电池&am…...

独立开发者应对Claude Code封号风险的备用方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者应对Claude Code封号风险的备用方案与接入实践 对于依赖Claude Code进行日常开发的独立开发者或小型团队而言࿰…...
)
WRF-CHEM模拟翻车?可能是你的namelist.chem没设对(附MEIC数据实战配置清单)
WRF-CHEM模拟异常排查指南:MEIC数据与namelist.chem的深度适配 当WRF-CHEM模拟结果出现异常时,很多用户会第一时间怀疑MEIC数据处理环节的问题,但实际上,namelist.chem参数与MEIC特性的匹配度才是更隐蔽的关键因素。本文将带您深入…...

在线水印怎么去除?2026年最新在线水印去除方法与工具推荐
图片、视频上的水印是版权保护的常见方式,但在内容创作、素材整理或个人使用时,有时需要移除这些标记。在线水印去除工具因为无需下载安装、跨平台兼容而成为不少人的选择。本文汇总了2026年实用的在线水印去除方法和工具推荐,帮你快速找到适…...

终极Switch游戏安装指南:5分钟掌握Awoo Installer的完整教程
终极Switch游戏安装指南:5分钟掌握Awoo Installer的完整教程 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦…...