java中解码和编码出现乱码原因
一、UTF-8和GBK编码方式
- 如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节
- 如果采用GBK的编码方式,那么1个英文字母 占 1个字节,1个中文占2个字节
二、idea和eclipse的默认编码方式
其实idea和eclipse的默认编码方式是不一样的哦。
idea默认的编码方式是:UTF-8
eclipse默认采用的编码方式是GBK
三、解码和编码方法
1、java中编码的方法
- public byte[] getBytes() 使用默认的编码方式进行编码
- public byte[] getBytes(Charset charset) 使用指定方式进行编码
2、java中解码的方法
- public String(byte bytes[]) 使用默认的方式进行解码
- public String(byte bytes[], String charsetName) 使用指的方式进行解码
四、代码实现
以下代码demo均采用idea开发哦
编码
1、使用默认的编码方式进行编码看下面这段代码,请猜一猜数组中的元素有几个?
| 1 2 3 4 5 6 7 8 9 10 11 |
|
你答对了吗?数组中一共有8个元素,因为idea默认采用的编码方式是utf-8,如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节。我们看一下运行结果
[100, 107, -28, -67, -96, -27, -91, -67]
Process finished with exit code 0
如果使用指定的编码方式GBK进行编码呢?我们看一下代码
| 1 2 3 4 5 6 7 |
|
答案是:数组元素一共有6个,因为采用的是GBK编码方式,那么1个英文字母 占 1个字节,1个中文占2个字节。
我们看一下运行结果
[100, 107, -60, -29, -70, -61]
Process finished with exit code 0
解码
1、使用默认的方式进行解码
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
运行结果如下:
dk你好
Process finished with exit code 0
如果给他加上指定编码方式呢?
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
运行结果
dk浣犲ソ
Process finished with exit code 0
我们发现有乱码产生。那为什么呢?因为编码的时候,采用的是默认的utf-8方式,所以解码的时候,也需要使用utf-8进行解码,如果使用gbk就会产生乱码。因为utf-8和gbk对中文所占的字节数是不一样的。
- 如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节
- 如果采用GBK的编码方式,那么1个英文字母 占 1个字节,1个中文占2个字节
五、额外知识扩展
1、什么是字符集?字符集顾名思义,就是用来装多个字符的集合。不同的字符集中字符的个数是不同的,包含的字符也是不同的,甚至对于字符的编码格式也是不同的。
2、什么是字符编码?计算机中存储信息都是以二进制数表示的,而我们在电脑屏幕上看到的文字、数字、英文、标点符号等都是将二进制数转换过后的结果,按照某种规则,将计算机中的二进制数与某个抽象字符集合一一对应,这就是字符编码。
3、ASCII字符集ASCII 全称 (American Standard Code for Information Interchange)美国信息交换标准代码,它是基于拉丁字母的一套电脑编码系统,其最初在创建的时候主要是为了显示英语以及一些西欧语言,是国际通用的信息交换使用标准码。ASCII使用了7位二进制来表示128个字符和符号,目前已经停止更新。
4、Unicode字符集ASCII字符集只包含了128个字符,对于全世界的所有语言来说,并不能容纳下世界上所有的语言。所以Unicode字符集出现了。
Unicode又被称为统一码、万国码,是国际组织制定的用来容纳全世界字符的编码方案。是的,确切的说Unicode是一种编码方案,以实现跨语言、跨平台的文本处理、转换的要求。
但是Unicode只是一种字符与二进制数之间的一种逻辑映射编码,它并没有指定在计算集中应该如何的进行存储。所以此时就需要一种编码格式用来指定Unicode字符集中的字符是如何进行编码的。
在Unicode官方资料中,Unicode编码方式有三种:UTF-8、UTF-16、UTF-32,而其中UTF-8编码成为了现今互联网使用较多的编码方式。
5、GB2312GB2312编码是第一个汉字编码国家标准,于1980年由中国国家标准总局发布。其中共收录了汉字6763个。但是由于我国的汉字非常多,GB2312收录的汉字不够用了,所以GBK诞生了。GBK包含了GB2312的所有内容的同时还新增了20000多新的汉字,对于一些日常需求已经为完全够用了。
总结
到此这篇关于java中解码和编码出现乱码说明以及代码实现的文章就介绍到这了,更多相关java解码和编码乱码内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
简单描述:
1、get方式乱码:tomcat 的server.xml 中加 URIEncoding="UTF-8"
2、post方式乱码:使用过滤器即可解决
3、log4j在linux下显示乱码解决方法:
log4j配置文件中加一句话即可解决:log4j.appender.logfile.encoding=UTF-8
字符集的详细分解:
1. 概述
本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等。
在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是"d6d0 cec4",Unicode编码为"4e2d 6587",UTF编码就是"e4b8ad e69687"。注意,这两个字没有iso8859-1编码,但可以用iso8859-1编码来"表示"。
2. 编码基本知识
最早的编码是iso8859-1,和ascii编码相似。但为了方便表示各种各样的语言,逐渐出现了很多标准编码,重要的有如下几个。
2.1. iso8859-1
属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母'a'的编码为0x61=97。
很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然"中文"两个字不存在iso8859-1编码,以gb2312编码为例,应该是"d6d0 cec4"两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:"d6 d0 ce c4"(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节"e4 b8 ad e6 96 87"。很明显,这种表示方法还需要以另一种编码为基础。
2.2. GB2312/GBK
这就是汉子的国标码,专门用来表示汉字,是双字节编码,而英文字母和iso8859-1一致(兼容iso8859-1编码)。其中gbk编码能够用来同时表示繁体字和简体字,而gb2312只能表示简体字,gbk是兼容gb2312编码的。
2.3. unicode
这是最统一的编码,可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母'a'为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
2.4. UTF
考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字使用三个字节。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包含了很多的英文字符。
3. java对字符的处理
在java应用软件中,会有多处涉及到字符集编码,有些地方需要进行正确的设置,有些地方需要进行一定程度的处理。
3.1. getBytes(charset)
这是java字符串处理的一个标准函数,其作用是将字符串所表示的字符按照charset编码,并以字节方式表示。注意字符串在java内存中总是按unicode编码存储的。比如"中文",正常情况下(即没有错误的时候)存储为"4e2d 6587",如果charset为"gbk",则被编码为"d6d0 cec4",然后返回字节"d6 d0 ce c4"。如果charset为"utf8"则最后是"e4 b8 ad e6 96 87"。如果是"iso8859-1",则由于无法编码,最后返回 "3f 3f"(两个问号)。
3.2. new String(charset)
这是java字符串处理的另一个标准函数,和上一个函数的作用相反,将字节数组按照charset编码进行组合识别,最后转换为unicode存储。参考上述getBytes的例子,"gbk" 和"utf8"都可以得出正确的结果"4e2d 6587",但iso8859-1最后变成了"003f 003f"(两个问号)。
因为utf8可以用来表示/编码所有字符,所以new String( str.getBytes( "utf8" ), "utf8" ) === str,即完全可逆。
3.3. setCharacterEncoding()
该函数用来设置http请求或者相应的编码。
对于request,是指提交内容的编码,指定后可以通过getParameter()则直接获得正确的字符串,如果不指定,则默认使用iso8859-1编码,需要进一步处理。参见下述"表单输入"。值得注意的是在执行setCharacterEncoding()之前,不能执行任何getParameter()。java doc上说明:This method must be called prior to reading request parameters or reading input using getReader()。而且,该指定只对POST方法有效,对GET方法无效。分析原因,应该是在执行第一个getParameter()的时候,java将会按照编码分析所有的提交内容,而后续的getParameter()不再进行分析,所以setCharacterEncoding()无效。而对于GET方法提交表单是,提交的内容在URL中,一开始就已经按照编码分析所有的提交内容,setCharacterEncoding()自然就无效。
对于response,则是指定输出内容的编码,同时,该设置会传递给浏览器,告诉浏览器输出内容所采用的编码。
3.4. 处理过程
下面分析两个有代表性的例子,说明java对编码有关问题的处理方法。
3.4.1. 表单输入
User input *(gbk:d6d0 cec4) browser *(gbk:d6d0 cec4) web server iso8859-1(00d6 00d 000ce 00c4) class,需要在class中进行处理:getbytes("iso8859-1")为d6 d0 ce c4,new String("gbk")为d6d0 cec4,内存中以unicode编码则为4e2d 6587。
l 用户输入的编码方式和页面指定的编码有关,也和用户的操作系统有关,所以是不确定的,上例以gbk为例。
l 从browser到web server,可以在表单中指定提交内容时使用的字符集,否则会使用页面指定的编码。而如果在url中直接用?的方式输入参数,则其编码往往是操作系统本身的编码,因为这时和页面无关。上述仍旧以gbk编码为例。
l Web server接收到的是字节流,默认时(getParameter)会以iso8859-1编码处理之,结果是不正确的,所以需要进行处理。但如果预先设置了编码(通过request. setCharacterEncoding ()),则能够直接获取到正确的结果。
l 在页面中指定编码是个好习惯,否则可能失去控制,无法指定正确的编码。
3.4.2. 文件编译
假设文件是gbk编码保存的,而编译有两种编码选择:gbk或者iso8859-1,前者是中文windows的默认编码,后者是linux的默认编码,当然也可以在编译时指定编码。
Jsp *(gbk:d6d0 cec4) java file *(gbk:d6d0 cec4) compiler read uincode(gbk: 4e2d 6587; iso8859-1: 00d6 00d 000ce 00c4) compiler write utf(gbk: e4b8ad e69687; iso8859-1: *) compiled file unicode(gbk: 4e2d 6587; iso8859-1: 00d6 00d 000ce 00c4) class。所以用gbk编码保存,而用iso8859-1编译的结果是不正确的。
class unicode(4e2d 6587) system.out / jsp.out gbk(d6d0 cec4) os console / browser。
l 文件可以以多种编码方式保存,中文windows下,默认为ansi/gbk。
l 编译器读取文件时,需要得到文件的编码,如果未指定,则使用系统默认编码。一般class文件,是以系统默认编码保存的,所以编译不会出问题,但对于jsp文件,如果在中文windows下编辑保存,而部署在英文linux下运行/编译,则会出现问题。所以需要在jsp文件中用pageEncoding指定编码。
l Java编译的时候会转换成统一的unicode编码处理,最后保存的时候再转换为utf编码。
l 当系统输出字符的时候,会按指定编码输出,对于中文windows下,System.out将使用gbk编码,而对于response(浏览器),则使用jsp文件头指定的contentType,或者可以直接为response指定编码。同时,会告诉browser网页的编码。如果未指定,则会使用iso8859-1编码。对于中文,应该为browser指定输出字符串的编码。
l browser显示网页的时候,首先使用response中指定的编码(jsp文件头指定的contentType最终也反映在response上),如果未指定,则会使用网页中meta项指定中的contentType。
3.5. 几处设置
对于web应用程序,和编码有关的设置或者函数如下。
3.5.1. jsp编译
指定文件的存储编码,很明显,该设置应该置于文件的开头。例如:<%@page pageEncoding="GBK"%>。另外,对于一般class文件,可以在编译的时候指定编码。
3.5.2. jsp输出
指定文件输出到browser是使用的编码,该设置也应该置于文件的开头。例如:<%@ page contentType="text/html; charset= GBK" %>。该设置和response.setCharacterEncoding("GBK")等效。
3.5.3. meta设置
指定网页使用的编码,该设置对静态网页尤其有作用。因为静态网页无法采用jsp的设置,而且也无法执行response.setCharacterEncoding()。例如:<META http-equiv="Content-Type" content="text/html; charset=GBK" />
如果同时采用了jsp输出和meta设置两种编码指定方式,则jsp指定的优先。因为jsp指定的直接体现在response中。
需要注意的是,apache有一个设置可以给无编码指定的网页指定编码,该指定等同于jsp的编码指定方式,所以会覆盖静态网页中的meta指定。所以有人建议关闭该设置。
3.5.4. form设置
当浏览器提交表单的时候,可以指定相应的编码。例如:<form accept-charset= "gb2312">。一般不必不使用该设置,浏览器会直接使用网页的编码。
4. 系统软件
下面讨论几个相关的系统软件。
4.1. mysql数据库
很明显,要支持多语言,应该将数据库的编码设置成utf或者unicode,而utf更适合与存储。但是,如果中文数据中包含的英文字母很少,其实unicode更为适合。
数据库的编码可以通过mysql的配置文件设置,例如default-character-set=utf8。还可以在数据库链接URL中设置,例如: useUnicode=true&characterEncoding=UTF-8。注意这两者应该保持一致,在新的sql版本里,在数据库链接URL里可以不进行设置,但也不能是错误的设置。
4.2. apache
appache和编码有关的配置在httpd.conf中,例如AddDefaultCharset UTF-8。如前所述,该功能会将所有静态页面的编码设置为UTF-8,最好关闭该功能。
另外,apache还有单独的模块来处理网页响应头,其中也可能对编码进行设置。
4.3. linux默认编码
这里所说的linux默认编码,是指运行时的环境变量。两个重要的环境变量是LC_ALL和LANG,默认编码会影响到java URLEncode的行为,下面有描述。
建议都设置为"zh_CN.UTF-8"。
4.4. 其它
为了支持中文文件名,linux在加载磁盘时应该指定字符集,例如:mount /dev/hda5 /mnt/hda5/ -t ntfs -o iocharset=gb2312。
另外,如前所述,使用GET方法提交的信息不支持request.setCharacterEncoding(),但可以通过tomcat的配置文件指定字符集,在tomcat的server.xml文件中,形如:<Connector ... URIEncoding="GBK"/>。这种方法将统一设置所有请求,而不能针对具体页面进行设置,也不一定和browser使用的编码相同,所以有时候并不是所期望的。
5. URL地址
URL地址中含有中文字符是很麻烦的,前面描述过使用GET方法提交表单的情况,使用GET方法时,参数就是包含在URL中。
5.1. URL编码
对于URL中的一些特殊字符,浏览器会自动进行编码。这些字符除了"/?&"等外,还包括unicode字符,比如汉子。这时的编码比较特殊。
IE有一个选项"总是使用UTF-8发送URL",当该选项有效时,IE将会对特殊字符进行UTF-8编码,同时进行URL编码。如果改选项无效,则使用默认编码"GBK",并且不进行URL编码。但是,对于URL后面的参数,则总是不进行编码,相当于UTF-8选项无效。比如"中文.html?a=中文",当UTF-8选项有效时,将发送链接"%e4%b8%ad%e6%96%87.html?a=\x4e\x2d\x65\x87";而UTF-8选项无效时,将发送链接"\x4e\x2d\x65\x87.html?a=\x4e\x2d\x65\x87"。注意后者前面的"中文"两个字只有4个字节,而前者却有18个字节,这主要时URL编码的原因。
当web server(tomcat)接收到该链接时,将会进行URL解码,即去掉"%",同时按照ISO8859-1编码(上面已经描述,可以使用URLEncoding来设置成其它编码)识别。上述例子的结果分别是"\ue4\ub8\uad\ue6\u96\u87.html?a=\u4e\u2d\u65\u87"和"\u4e\u2d\u65\u87.html?a=\u4e\u2d\u65\u87",注意前者前面的"中文"两个字恢复成了6个字符。这里用"\u",表示是unicode。
所以,由于客户端设置的不同,相同的链接,在服务器上得到了不同结果。这个问题不少人都遇到,却没有很好的解决办法。所以有的网站会建议用户尝试关闭UTF-8选项。不过,下面会描述一个更好的处理办法。
5.2. rewrite
熟悉的人都知道,apache有一个功能强大的rewrite模块,这里不描述其功能。需要说明的是该模块会自动将URL解码(去除%),即完成上述web server(tomcat)的部分功能。有相关文档介绍说可以使用[NE]参数来关闭该功能,但我试验并未成功,可能是因为版本(我使用的是apache 2.0.54)问题。另外,当参数中含有"?& "等符号的时候,该功能将导致系统得不到正常结果。
rewrite本身似乎完全是采用字节处理的方式,而不考虑字符串的编码,所以不会带来编码问题。
5.3. URLEncode.encode()
这是Java本身提供对的URL编码函数,完成的工作和上述UTF-8选项有效时浏览器所做的工作相似。值得说明的是,java已经不赞成不指定编码来使用该方法(deprecated)。应该在使用的时候增加编码指定。
当不指定编码的时候,该方法使用系统默认编码,这会导致软件运行结果得不确定。比如对于"中文",当系统默认编码为"gb2312"时,结果是"%4e%2d%65%87",而默认编码为"UTF-8",结果却是"%e4%b8%ad%e6%96%87",后续程序将难以处理。另外,这儿说的系统默认编码是由运行tomcat时的环境变量LC_ALL和LANG等决定的,曾经出现过tomcat重启后就出现乱码的问题,最后才郁闷的发现是因为修改修改了这两个环境变量。
建议统一指定为"UTF-8"编码,可能需要修改相应的程序。
5.4. 一个解决方案
上面说起过,因为浏览器设置的不同,对于同一个链接,web server收到的是不同内容,而软件系统有无法知道这中间的区别,所以这一协议目前还存在缺陷。
针对具体问题,不应该侥幸认为所有客户的IE设置都是UTF-8有效的,也不应该粗暴的建议用户修改IE设置,要知道,用户不可能去记住每一个web server的设置。所以,接下来的解决办法就只能是让自己的程序多一点智能:根据内容来分析编码是否UTF-8。
比较幸运的是UTF-8编码相当有规律,所以可以通过分析传输过来的链接内容,来判断是否是正确的UTF-8字符,如果是,则以UTF-8处理之,如果不是,则使用客户默认编码(比如"GBK"),下面是一个判断是否UTF-8的例子,如果你了解相应规律,就容易理解。
public static boolean isValidUtf8(byte[] b,int aMaxCount){
int lLen=b.length,lCharCount=0;
for(int i=0;i<lLen && lCharCount<aMaxCount;++lCharCount){
byte lByte=b[i++];//to fast operation, ++ now, ready for the following for(;;)
if(lByte>=0) continue;//>=0 is normal ascii
if(lByte<(byte)0xc0 || lByte>(byte)0xfd) return false;
int lCount=lByte>(byte)0xfc?5:lByte>(byte)0xf8?4
:lByte>(byte)0xf0?3:lByte>(byte)0xe0?2:1;
if(i+lCount>lLen) return false;
for(int j=0;j<lCount;++j,++i) if(b[i]>=(byte)0xc0) return false;
}
return true;
}
相应地,一个使用上述方法的例子如下:
public static String getUrlParam(String aStr,String aDefaultCharset)
throws UnsupportedEncodingException{
if(aStr==null) return null;
byte[] lBytes=aStr.getBytes("ISO-8859-1");
return new String(lBytes,StringUtil.isValidUtf8(lBytes)?"utf8":aDefaultCharset);
}
不过,该方法也存在缺陷,如下两方面:
l 没有包括对用户默认编码的识别,这可以根据请求信息的语言来判断,但不一定正确,因为我们有时候也会输入一些韩文,或者其他文字。
l 可能会错误判断UTF-8字符,一个例子是"学习"两个字,其GBK编码是" \xd1\xa7\xcf\xb0",如果使用上述isValidUtf8方法判断,将返回true。可以考虑使用更严格的判断方法,不过估计效果不大。
有一个例子可以证明google也遇到了上述问题,而且也采用了和上述相似的处理方法,比如,如果在地址栏中输入"http://www.google.com/search?hl=zh-CN&newwindow=1&q=学习",google将无法正确识别,而其他汉字一般能够正常识别。
最后,应该补充说明一下,如果不使用rewrite规则,或者通过表单提交数据,其实并不一定会遇到上述问题,因为这时可以在提交数据时指定希望的编码。另外,中文文件名确实会带来问题,应该谨慎使用。
6. 其它
下面描述一些和编码有关的其他问题。
6.1. SecureCRT
除了浏览器和控制台与编码有关外,一些客户端也很有关系。比如在使用SecureCRT连接linux时,应该让SecureCRT的显示编码(不同的session,可以有不同的编码设置)和linux的编码环境变量保持一致。否则看到的一些帮助信息,就可能是乱码。
另外,mysql有自己的编码设置,也应该保持和SecureCRT的显示编码一致。否则通过SecureCRT执行sql语句的时候,可能无法处理中文字符,查询结果也会出现乱码。
对于Utf-8文件,很多编辑器(比如记事本)会在文件开头增加三个不可见的标志字节,如果作为mysql的输入文件,则必须要去掉这三个字符。(用linux的vi保存可以去掉这三个字符)。一个有趣的现象是,在中文windows下,创建一个新txt文件,用记事本打开,输入"连通"两个字,保存,再打开,你会发现两个字没了,只留下一个小黑点。
6.2. 过滤器
如果需要统一设置编码,则通过filter进行设置是个不错的选择。在filter class中,可以统一为需要的请求或者回应设置编码。参加上述setCharacterEncoding()。这个类apache已经给出了可以直接使用的例子SetCharacterEncodingFilter。
6.3. POST和GET
很明显,以POST提交信息时,URL有更好的可读性,而且可以方便的使用setCharacterEncoding()来处理字符集问题。但GET方法形成的URL能够更容易表达网页的实际内容,也能够用于收藏。
从统一的角度考虑问题,建议采用GET方法,这要求在程序中获得参数是进行特殊处理,而无法使用setCharacterEncoding()的便利,如果不考虑rewrite,就不存在IE的UTF-8问题,可以考虑通过设置URIEncoding来方便获取URL中的参数。
6.4. 简繁体编码转换
GBK同时包含简体和繁体编码,也就是说同一个字,由于编码不同,在GBK编码下属于两个字。有时候,为了正确取得完整的结果,应该将繁体和简体进行统一。可以考虑将UTF、GBK中的所有繁体字,转换为相应的简体字,BIG5编码的数据,也应该转化成相应的简体字。当然,仍旧以UTF编码存储。
例如,对于"语言 ?言",用UTF表示为"\xE8\xAF\xAD\xE8\xA8\x80 \xE8\xAA\x9E\xE8\xA8\x80",进行简繁体编码转换后应该是两个相同的 "\xE8\xAF\xAD\xE8\xA8\x80>"。
相关文章:
java中解码和编码出现乱码原因
一、UTF-8和GBK编码方式 如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节如果采用GBK的编码方式,那么1个英文字母 占 1个字节,1个中文占2个字节 二、idea和eclipse的默认编码方式 其实idea和eclipse的…...
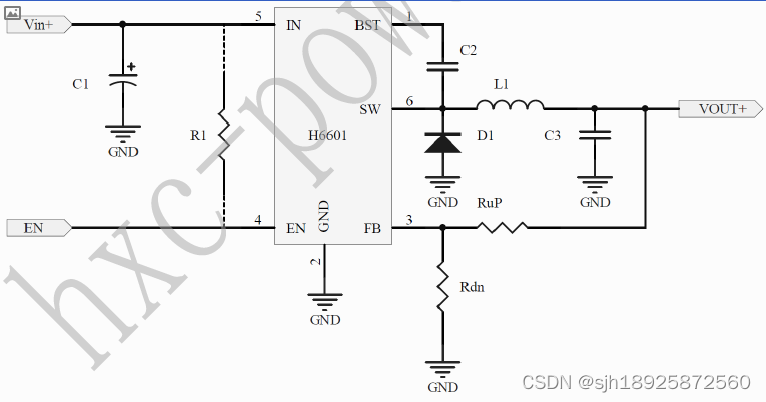
60V降压3.3V稳压芯片 60V降压5V稳压芯片60V降压12V稳压芯片
60V降压3.3V稳压芯片、60V降压5V稳压芯片和60V降压12V稳压芯片是针对不同输出电压需求的降压稳压芯片。这些芯片通常被用于工业控制、通信设备、汽车电子和其他需要高电压输入并提供稳定输出电压的场合。 这些芯片通常具有高效率、低功耗和高稳定性的特点,能够在输…...
01第一个Mybatis程序+引入Junit+引入日志文件logback
Mybatis MyBatis本质上就是对JDBC的封装,通过MyBatis完成CRUD。而对于JDBC,SQL语句写死在Java程序中,不灵活。改SQL的话就要改Java代码。违背开闭原则OCP。对于事务机制,MyBatis支持 或managed模式,JDBC模式中MyBatis…...
音乐制作软件Studio One mac有哪些特点
Studio One mac是一款专业的音乐制作软件,该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One mac软件特点 1. 直观易用的界面&…...

开源C语言库Melon之日志模块
本文向大家介绍一个名为Melon的开源C语言库的日志模块。 简述Melon Melon是一个包含了开发中常用的各类组件的开源C语言库,支持Linux、MacOS、Windows系统,可用于服务器开发亦可用于嵌入式开发,无第三方软件依赖,安装简单&…...

[NOIP2006 提高组] 作业调度方案(修改)
题目: 这里对于之前的题目进行修改记录。果然还是受不了等待,利用晚饭时间又看了这个题目。于是发现了问题。 之前的博客:https://blog.csdn.net/KLSZM/article/details/135522867?spm1001.2014.3001.5501 问题修改描述 上午书写的代码中是…...

uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -全局异常统一处理实现
锋哥原创的uniapp微信小程序投票系统实战: uniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )_哔哩哔哩_bilibiliuniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )共计21条视频…...
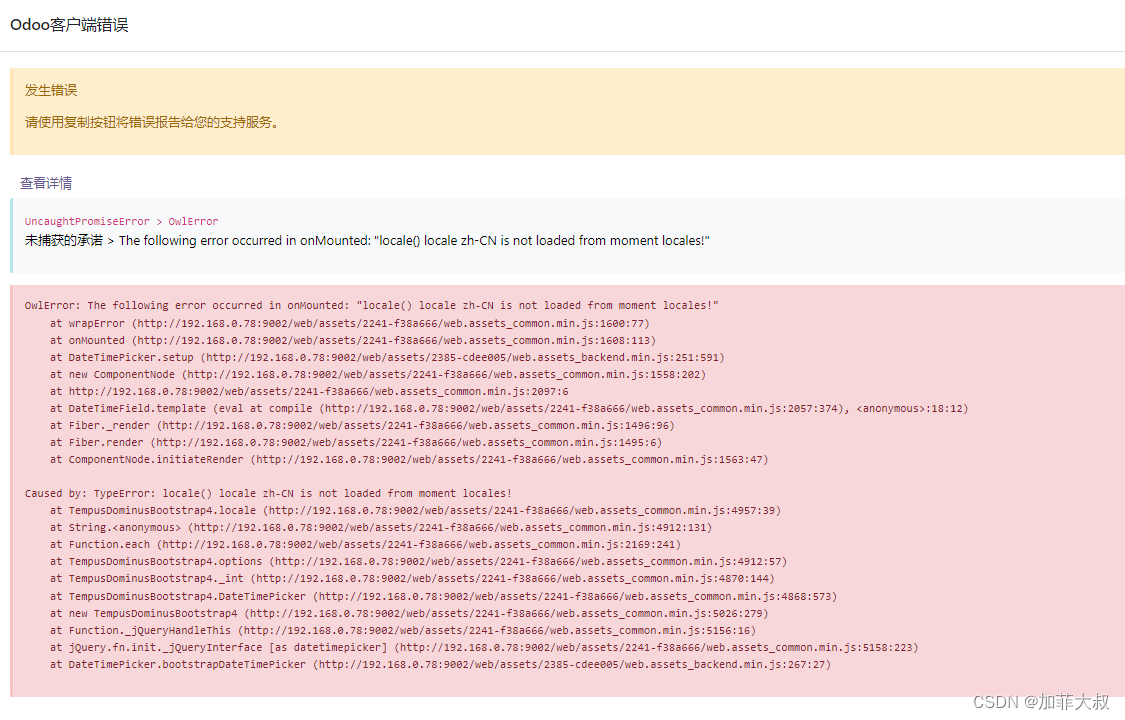
浏览器缓存引发的odoo前端报错
前两天,跑了一个odoo16项目,莫名其妙的前端报错, moment.js 报的错, 这是一个时间库,不是我自己写的代码,我也没做过任何修改,搞不清楚为什么报错。以为是odoo的bug,所以从gitee下载…...
如何搭建开源知识库软件AFFiNE并实现公网环境远程协作【内网穿透】
目录 前言 1. 使用Docker安装AFFINE 2. 安装cpolar内网穿透工具 3. 配置AFFINE公网访问地址 4. 实现公网远程访问AFFINE 结语 作者简介: 懒大王敲代码,计算机专业应届生 今天给大家聊聊如何搭建开源知识库软件AFFiNE并实现公网环境远程协作【内网穿…...

记忆泊车信息安全技术要求
一.概述 1.1 编写目的 记忆泊车过程涉及车辆通信、远程控制车辆等关键操作,因此需要把信息安全考虑进去,确保整个自动泊车过程的信息安全。 1.2 编写说明 此版为信息安全需求,供应商需要整体的信息安全方案。 1.3 适用范围 …...
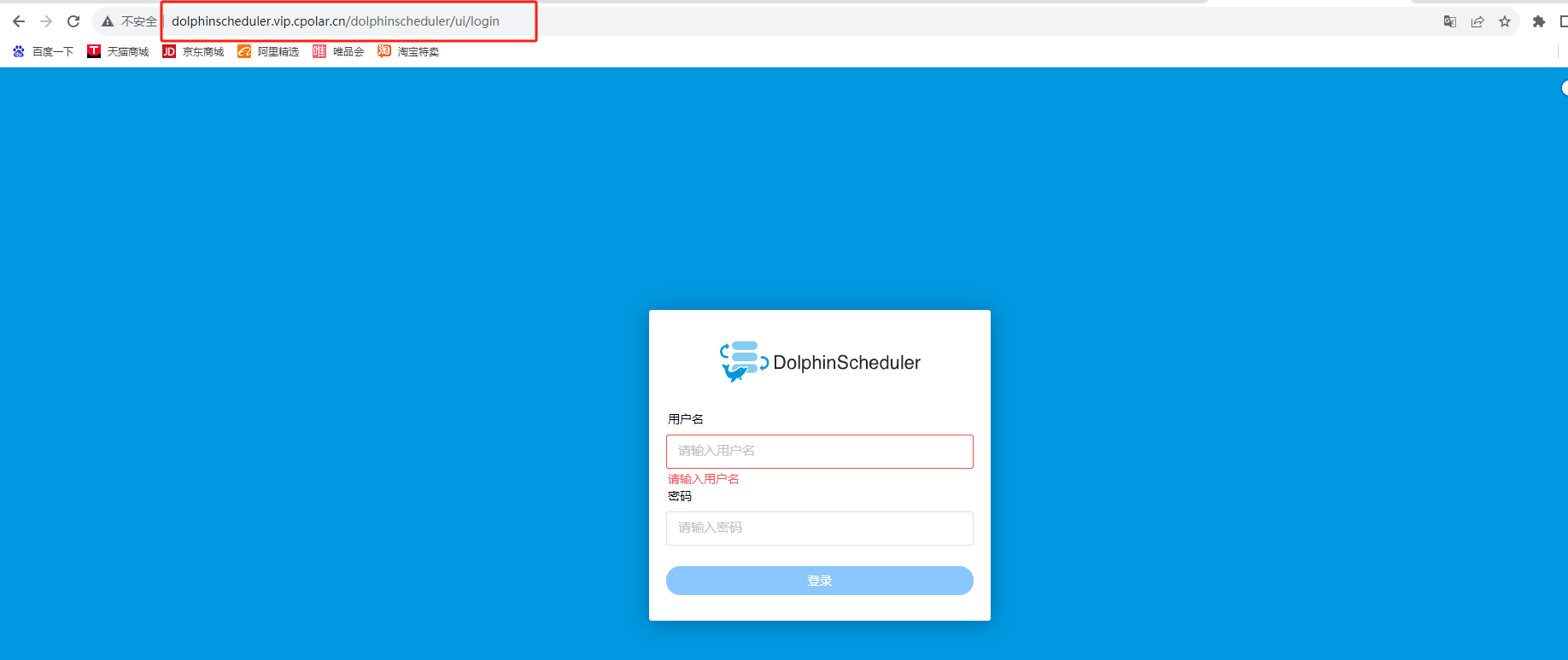
开源分布式任务调度系统DolphinScheduler本地部署与远程访问
文章目录 前言1. 安装部署DolphinScheduler1.1 启动服务 2. 登录DolphinScheduler界面3. 安装内网穿透工具4. 配置Dolphin Scheduler公网地址5. 固定DolphinScheduler公网地址 前言 本篇教程和大家分享一下DolphinScheduler的安装部署及如何实现公网远程访问,结合内…...

C++day3作业
完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到其他界面 如果账号和密码不匹配…...

设计模式⑤ :一致性
一、前言 有时候不想动脑子,就懒得看源码又不像浪费时间所以会看看书,但是又记不住,所以决定开始写"抄书"系列。本系列大部分内容都是来源于《 图解设计模式》(【日】结城浩 著)。该系列文章可随意转载。 …...

Android通过Recyclerview实现流式布局自适应列数及高度
调用 FlowAdapter 跟普通recyclerview一样使用 RecyclerView rvLayout holder.getView(R.id.spe_tag_layout); FlowAdapter rvAdapter new FlowAdapter(); FlowLayoutManager flowLayoutManager new FlowLayoutManager(); rvLayout.setLayoutManager(flowLayoutManager); r…...
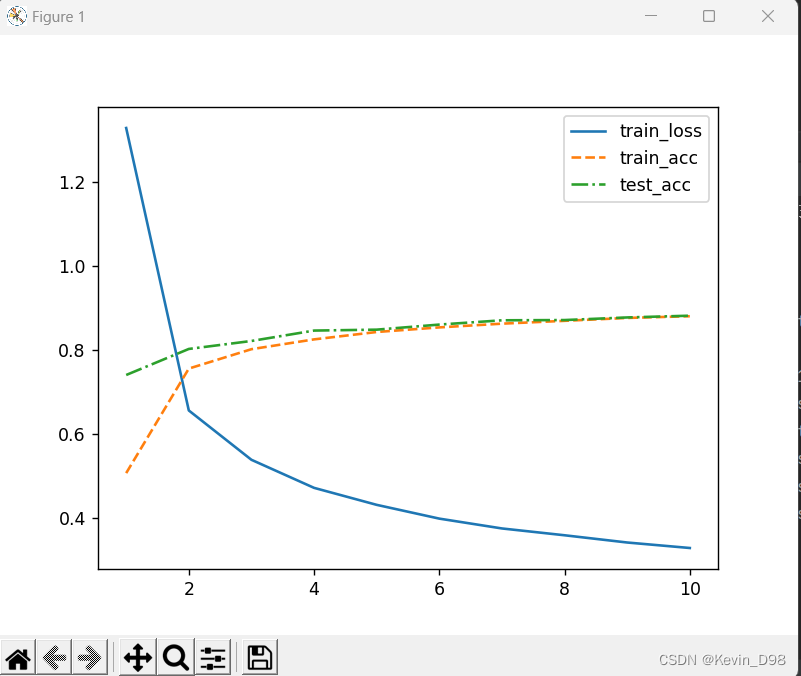
AlexNet(fashion-mnist)
前言 AlexNet相较于LeNet-5具有更深的网络结构,采用relu激活函数。 AlexNet 参数更多,计算量更大,计算速度更慢,精度更高。 netnn.Sequential(nn.Conv2d(1,96,kernel_size11,stride4,padding1),nn.ReLU(),nn.MaxPool2d(kernel…...
2024新年烟花代码完整版
文章目录 前言烟花效果展示使用教程查看源码HTML代码CSS代码JavaScript 新年祝福 前言 在这个充满希望和激动的2024年,新的一年即将拉开帷幕,而数字科技的创新与发展也如火如荼。烟花绚丽多彩的绽放,一直以来都是新年庆典中不可或缺的元素。…...
Fontfabric:一款字体与设计的完美结合
一、产品介绍 Fontfabric是一款由国际字体设计公司Fontfabric开发的字体设计软件。它提供了一整套完整的字体设计工具,让用户可以轻松地创建、设计和定制自己的字体。Fontfabric拥有丰富的字体库,包括各种风格和类型,能够满足用户在不同场景…...

Python爬虫—requests模块简单应用
Python爬虫—requests模块简介 requests的作用与安装 作用:发送网络请求,返回响应数据 安装:pip install requests requests模块发送简单的get请求、获取响应 需求:通过requests向百度首页发送请求,获取百度首页的…...
江科大STM32
参考: https://blog.csdn.net/weixin_54742551/article/details/132409170?spm1001.2014.3001.5502 https://blog.csdn.net/Johnor/article/details/128539267?spm1001.2014.3001.5502 SPI:https://blog.csdn.net/weixin_62127790/article/details/132…...
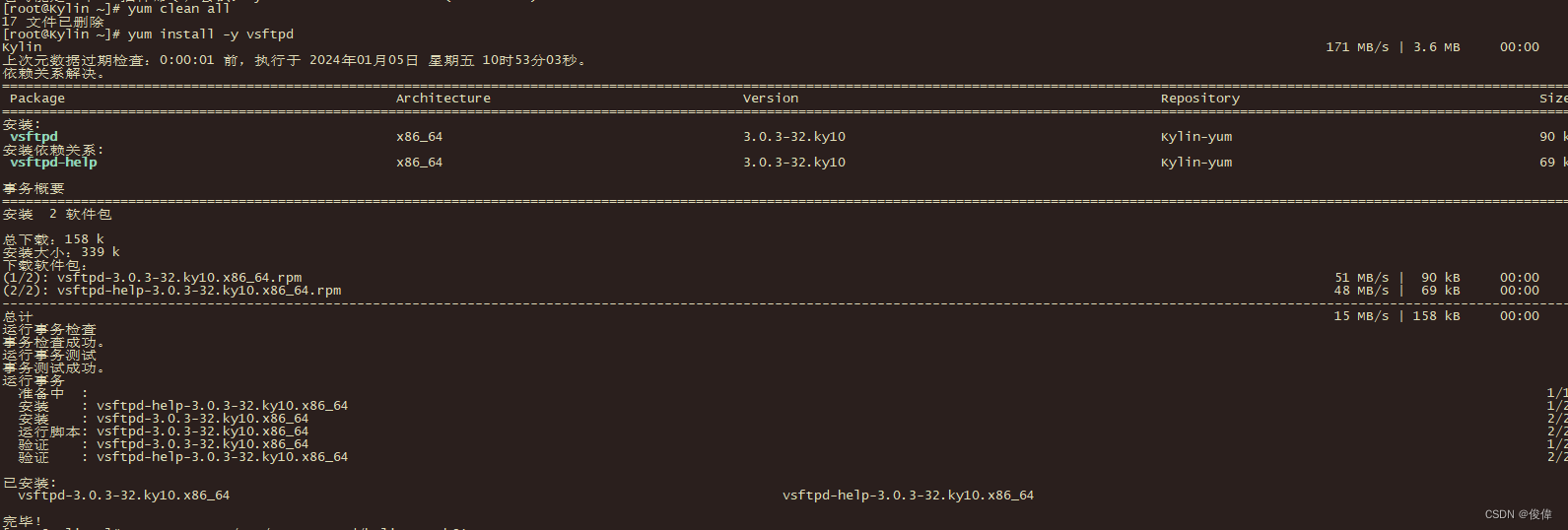
银河麒麟Kylin-Server-V10-SP3使用ISO镜像搭建本地内网YUM/DNF源cdrom/http
机房服务器安装一般是内网环境,需要配置本地的YUM/DNF源。本文介绍通过ISO镜像搭建内网环境的UM/DNF源 准备工作: 提前准备好Kylin-Server-V10-SP3的ISO镜像文件。 本机IP地址:192.168.40.201 镜像存放目录/data/iso/Kylin-Server-V10-SP3-Ge…...

技术解析【无人机实时建图】 - DenseFusion:如何实现CPU上的大规模密集点云与DSM在线融合
1. DenseFusion框架的核心价值 第一次接触DenseFusion时,最让我惊讶的是它在普通笔记本电脑CPU上就能跑出实时建图效果。要知道传统无人机建图方案要么依赖昂贵GPU,要么需要后期数小时处理。这个框架通过三个关键创新点实现了突破:虚拟立体对…...

语音克隆从入门到商用变现,手把手教你在TikTok/播客/AI助手部署高保真克隆声,今天就能上线
更多请点击: https://kaifayun.com 第一章:语音克隆技术演进与ElevenLabs核心能力解析 语音克隆技术已从早期基于拼接的单元选择(Unit Selection)和统计参数合成(HMM-based TTS),跨越深度学习驱…...

理发师会被 AI 取代吗?这可能是 AI 时代最有意思的一个社会学问题
今天去理发了。对着镜子,看着我的头发随着剪刀的飞舞一点点掉下来时,我忽然开始神游:AI 会不会取代理发师? 这问题乍一听有点像胡思乱想,可越想越觉得,它其实非常适合拿来当成 AI 时代的一块切片。 因为理发…...

使用taotoken后matlab调用大模型api的延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken后matlab调用大模型api的延迟与稳定性体验分享 1. 背景与接入动机 在数据处理与科学计算项目中,我们经常…...

3分钟掌握:U校园智能刷课自动化终极实战指南
3分钟掌握:U校园智能刷课自动化终极实战指南 【免费下载链接】AutoUnipus U校园脚本,支持全自动答题,百分百正确 2024最新版 项目地址: https://gitcode.com/gh_mirrors/au/AutoUnipus 还在为重复的网课练习消耗宝贵时间而烦恼吗?AutoUnipus智能刷…...

Chrome 148紧急安全更新深度解析:127个漏洞背后的GPU UAF沙箱逃逸与防御实战
一、引言:史上最密集的Chrome安全更新风暴 2026年5月5日,Google紧急推送了Chrome 148稳定版的第二次安全更新(版本号Windows/Mac 148.0.7778.96/97,Linux 148.0.7778.96),一次性修复了127个安全漏洞&#x…...

猫抓插件:三步轻松下载网页视频音频资源的终极指南
猫抓插件:三步轻松下载网页视频音频资源的终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经在网上看到一个精彩的视频…...

开源KMS激活神器:3分钟搞定Windows和Office永久激活难题
开源KMS激活神器:3分钟搞定Windows和Office永久激活难题 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题烦恼吗?KMS_VL_ALL_AIO是一款开…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

命令行故障自动修复工具 fix-my-claw:原理、插件架构与实战指南
1. 项目概述:一个修复“爪子”的实用工具最近在GitHub上看到一个挺有意思的项目,叫caopulan/fix-my-claw。光看名字,你可能会有点摸不着头脑——“爪子”是什么?需要修复什么?这其实是一个典型的、由开发者社区需求催生…...