1. Presto基础
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。
文章目录
- 一、presto基础操作
- 二、时间函数
- 0、当前日期/当前时间
- 1、转时间戳
- 1)字符串转时间戳 (推荐)
- 2)按照format指定的格式,将字符串string解析成timestamp。
- 3)bigint 转时间戳
- 2、转年月日/取年月日
- 1)时间戳取年月日
- 2)字符串转年月日
- 3)bigint 转年月日
- 3、日期变换:间隔、加减、截取、提取
- 1)求时间间隔 date_diff
- 2)求几天前,几天后 interval、date_add
- 3)时间截取函数 date_trunc(unit, x)
- 4)时间提取函数 extract、year、month、day
- 4、转int
- 三、字符串函数
- 四、二进制函数(与字符串函数类似)
- 五、正则表达式
- 六、聚合函数
- 七、窗口函数
- 八、数组、MAP、Json函数
一、presto基础操作
逻辑操作 AND OR NOT
比较操作 > < >= <= = <> !=
范围操作 between and; not between and; ……
空值判断 is null; is not null
最大最小值 greatest(1,2,3); least(1,2,3)
条件表达式case when thenif(condition, true_value, false_value)nullif(value1, value2):value1 = value2返回null,否则返回value1try(expression):表达式异常则返回null(防止分母为0,数字超过范围,无效cast等)
转换函数 cast(value as type); try_cast(value as type) : 转换失败返回nulltypeof(expr) :返回数据类型数学运算 + - * / % abs() 绝对值ceil() 向上取整floor() 向下取整pow(x,p);power(x,p) x^prand();random() 返回[0,1)间随机数round(): 同int()round(x,d):保留基本d位小数nan():not a numberis_nan(x): 判断x是否为nan注:/与hive有差异!!!presto 10/6=1hive 10/6=1.6666666666666667 presto 中可采用: cast(10 as double)/6=1.6666666666666667
二、时间函数
0、当前日期/当前时间
presto:adm> select current_date,current_time,current_timestamp【=now()】-> ;_col0 | _col1 | _col2
------------+------------------+-----------------------------2019-04-28 | 13:04:22.232 PRC | 2019-04-28 13:04:22.232 PRC
1、转时间戳
1)字符串转时间戳 (推荐)
即:‘2019-04-26’ 转换成 2019-04-26 00:00:00.000
select cast('2019-04-26' as timestamp)
-- 2019-04-26 00:00:00.000select cast('2019-04-26 01:22:23' as timestamp)
-- 2019-04-26 01:22:23.000
2)按照format指定的格式,将字符串string解析成timestamp。
select date_parse('2019-04-06','%Y-%m-%d') 2019-04-06 00:00:00.000
select date_parse('2019-04-06 00:03:55','%Y-%m-%d %H:%i:%S') 2019-04-06 00:03:55.000
注:字符串格式和format格式需保持一致,以下为错误示例:
select date_parse('2019-04-06','%Y-%m-%d %H:%i:%S')
Invalid format: "2019-04-06" is too shortselect date_parse('2019-04-06 00:03:55','%Y-%m-%d')
Invalid format: "2019-04-06 00:03:55" is malformed at " 00:03:55"select date_parse('2019-04-06 00:03:55','%Y%m%d %H:%i:%S')
Invalid format: "2019-04-06 00:03:55" is malformed at "-04-06 00:03:55"
注:时间戳格式化 format_datetime(timestamp,‘yyyy-MM-dd HH:mm:ss’)
3)bigint 转时间戳
即:int型 转换成 2017-05-10 06:18:50.000
from_unixtime(create_time)
补充:时间转bigint:
select to_unixtime(current_date); 1556380800
2、转年月日/取年月日
推荐思路:先转时间戳,再格式化为年月日再date()为年月日。
1)时间戳取年月日
即:2017-09-18 13:40:31 转换成 2017-09-18
select date_format(current_date,'%Y-%m-%d')
select date(current_date)
select cast(current_date as date)
-- 2019-04-28
2)字符串转年月日
select date(cast('2019-04-28 10:28:00' as TIMESTAMP))
select date('2019-04-28')
select date_format(cast('2019-04-28 10:28:00' as TIMESTAMP),'%Y-%m-%d')
select to_date('2019-04-28','yyyy-mm-dd');-- 2019-04-28
注:格式不同时date、to_date无法使用
select date('2019-04-28 10:28:00')
-- failed: Value cannot be cast to date: 2019-04-28 10:28:00
select to_date('2019-04-28 10:28:00','yyyy-mm-dd');
-- Invalid format: "2019-04-28 10:28:00" is malformed at " 10:28:00"
3)bigint 转年月日
date(from_unixtime(1556380800))
select date_format(from_unixtime(1556380800),'%Y-%m-%d')-- 2019-04-28
3、日期变换:间隔、加减、截取、提取
1)求时间间隔 date_diff
date_diff(unit, timestamp1, timestamp2) → biginteg:select date_diff('day',cast('2019-04-24' as TIMESTAMP),cast('2019-04-26' as TIMESTAMP))
--2
注:与hive差异!!!
presto中 date_diff('day',date1,date2)【后-前】
hive,mysql中 datediff(date1,date2) 【前-后】
2)求几天前,几天后 interval、date_add
select current_date,(current_date - interval '7' day),date_add('day', -7, current_date)2019-04-28 | 2019-04-21 | 2019-04-21select current_date,(current_date + interval '7' day),date_add('day', 7, current_date)2019-04-28 | 2019-05-05 | 2019-05-05
3)时间截取函数 date_trunc(unit, x)
截取月初
select date_trunc('month',current_date)
2019-04-01截取年初
select date_trunc('year',current_date)
2019-01-01
4)时间提取函数 extract、year、month、day
extract(field FROM x) → bigint【注:field不带引号!】
year(x),month(x),day(x)
eg:
select extract(year from current_date),year(current_date),extract(month from current_date),month(current_date),extract(day from current_date),day(current_date);
-------+-------+-------+-------+-------+-------2019 | 2019 | 4 | 4 | 28 | 28
4、转int
思路:先转timestamp,再to_unixtime转int
to_unixtime(timestamp_col)
三、字符串函数
presto中字符串只能使用单引号
注意:hive中字符串可以使用单引号或双引号,presto中字符串只能使用单引号。
eg:
presto:adm> select d_module from adm.f_app_video_vv where dt='2019-04-27' and d_module="为你推荐-大屏" limit 10;
Query 20190428_034805_00112_ym89j failed: line 1:76: Column '为你推荐-大屏' cannot be resolvedpresto:adm> select d_module from adm.f_app_video_vv where dt='2019-04-27' and d_module='为你推荐-大屏' limit 10;d_module
---------------为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏为你推荐-大屏
(10 rows)
基础字符串函数 concat length lower upper
拼接 concat(string1, ..., stringN) → varchar取长度 length(string) → bigint字母全部转换为小写 lower(string) → varchar
字母全部转换为大写 upper(string) → varchar
eg:select lower('ABc'),upper('ABc')abc,ABC
字符串填充 lpad rpad
字符串左填充 lpad(string, size, padstring) string长度不足size则将padstring重复填充到左边直到长度等于sizestring长度超过size则截图string左侧的size个字符eg.select lpad('csdfasg',10,'a') aaacsdfasgselect lpad('csdfasg',3,'a') csd字符串右填充 rpad(string, size, padstring) → varchar
字符串清除空格 ltrim rtrim trim
清除字符串左侧空格 ltrim(string) → varchar清除字符串右侧空格 rtrim(string) → varchar清除字符串两侧空格 trim(string) → varchar
字符串替换字符 replace
替换字符-去掉string中的search: replace(string, search) 替换字符-将string中的search替换为replace:replace(string, search, replace)eg:select replace('23543','2'),replace('23543','2','8')3543, 83543
字符串拆分 split
拆分字符串:
split(string, delimiter) -> array(varchar)eg:select split('325f243f325f43','f');[325, 243, 325, 43]
拆分字符串-拆分到第limit-1个分隔符为止:
split(string, delimiter, limit) -> array(varchar)eg:select split('325f243f325f43','f',2);[325, 243f325f43]select split('325f243f325f43','f',3);[325, 243, 325f43]
拆分字符串-获取特定位置的拆分结果(注:index从1开始):
split_part(string, delimiter, index)eg:select split_part('325f243f325f43','f', 4)43
字符串定位 strpos position
定位函数-获取字符串中某个字符第一次出现的位置,从1开始:
strpos(string, substring) → bigint
position(substring IN string) → bigint
字符串截取 substr
截取函数-截取start右侧字符(含start):
substr(string, start) → varchar
【 substring(~)相同 】eg:select substr('325f243f325f43', 3),substr('325f243f325f43', -3)5f243f325f43,f43
截取函数-从start开始向右侧截取length个字符(含start):
substr(string, start, length) → varchar
【 substring(~)相同 】eg:select substr('325f243f325f43', 3, 3),substr('325f243f325f43', -3,2)5f2,f4
扩展:截取函数substr,定位函数strpos组合使用:
substr(remark,strpos(remark,'title'),strpos(remark,'status')-strpos(remark,'title')-3)
其他
string转UTF-8:to_utf8(string) → varbinary补充:
二进制转int:crc32(binary) → bigint
二进制转string:from_utf8(binary) → varchareg:
select to_utf8('你好') ,crc32(to_utf8('你好')), from_utf8(to_utf8('你好'))e4 bd a0 e5 a5 bd | 1352841281 | 你好
四、二进制函数(与字符串函数类似)
length、concat、substr、lpad、rpad等
md5(binary) → varbinary
crc32(binary) → biginteg:presto:adm> select to_utf8('为你推荐-大屏'), crc32(to_utf8('为你推荐-大屏'));_col0 | _col1-------------------------------------------------+------------e4 b8 ba e4 bd a0 e6 8e a8 e8 8d 90 2d e5 a4 a7 | 4200009045e5 b1 8f |(1 row)
五、正则表达式
返回string中符合pattern的元素: regexp_extract_all、regexp_extract
返回string中所有符合pattern的元素 :
regexp_extract_all(string, pattern) -> array(varchar)eg:SELECT regexp_extract_all('1a 2b 14m', '\d+'); -- [1, 2, 14]返回string中第一个符合pattern的元素 :
regexp_extract(string, pattern) → varchareg:SELECT regexp_extract('1a 2b 14m', '\d+'); -- 1返回string中所有符合"pattern组合"的元素中指定pattern位的元素 :
regexp_extract_all(string, pattern, group) -> array(varchar)
eg:SELECT regexp_extract_all('1a 2b 14m', '(\d+)([a-z]+)', 2); -- ['a', 'b', 'm']返回string中第一个符合"pattern组合"的元素中指定pattern位的元素 :
regexp_extract(string, pattern, group) → varchar
eg:SELECT regexp_extract('1a 2b 14m', '(\d+)([a-z]+)', 2); -- 'a'
判断string是否符合pattern: regexp_like
【可理解为多个like的组合,且比like组合高效】
regexp_like(string, pattern) → boolean
eg:
SELECT regexp_like('1a 2b 14m', '\d+n'),regexp_like('1a 2b 14m', '\d+m'),regexp_like('1a 2b 14m', '\d+n | \d+m')false,true,true
替换string中符合pattern的元素: regexp_replace
替换字符-将 string 中符合 pattern 的元素替换为空 (移除元素) :
regexp_replace(string, pattern) → varchar
eg:SELECT regexp_replace('1a 2b 14m', '\d+[ab] '); -- '14m'替换字符-将string中符合pattern的元素替换为replacement:
regexp_replace(string, pattern, replacement) → varchar
eg:SELECT regexp_replace('1a 2b 14m', '(\d+)([ab]) ', 'new'); -- newnew14mSELECT regexp_replace('1a 2b 14m', '(\d+)([ab]) ', '3c$2 '); -- '3ca 3cb 14m'注:$2指第二个parttern位对应元素替换字符-将string中符合pattern的元素替换为function结果 :
regexp_replace(string, pattern, function) → varchar
eg:SELECT regexp_replace('new york', '(\w)(\w*)', x -> upper(x[1]) || lower(x[2])); --'New York'按pattern拆分string: regexp_split
拆分字符串-按pattern拆分 :
regexp_split(string, pattern) -> array(varchar)
eg:presto:adm> SELECT regexp_split('1a 2b 14m', '\s'),regexp_split('1a 2b 14m', '[a-z]+');_col0 | _col1---------------+----------------[1a, 2b, 14m] | [1, 2, 14, ]
六、聚合函数
求和函数 sum
最大最小值函数 max min
最大值:max(x) → [same as input]
最大的n个值:max(x, n) → array<[same as x]>
最小值:min(x) → [same as input]
最小的n个值:min(x, n) → array<[same as x]>
注1:hive中没有 max(x, n)、min(x, n)
注2:max(x, n)、min(x, n) 与rank相比,书写更简单,但无法直接带出相关信息
eg:
select max(m_vvpv,3) from app.c_app_videodiscover_uv where dt='2019-04-27';[3333, 2222, 1111]
最大最小值函数扩展 max_by min_by
取出最大y值对应的x值:max_by(x, y) → [same as x]
取出最大的n个y值对应的x值:max_by(x, y, n) → array<[same as x]>取出最小y值对应的x值:min_by(x, y) → [same as x]
取出最小的n个y值对应的x值:min_by(x, y, n) → array<[same as x]>eg:
presto:adm> select max_by(d_module_type,m_vvpv) from app.c_app_videodiscover_uv where dt='2019-04-27';_col0
-------其他presto:adm> select max_by(d_module_type,m_vvpv,3) from app.c_app_videodiscover_uv where dt='2019-04-27';_col0
--------------------[其他, 搜索, 首页]-- 等同于hive中(但没有取出m_vvpv)
select d_module_type,m_vvpv
from app.c_app_videodiscover_uv
where dt='2019-04-27'
order by m_vvpv desc
limit 3d_module_type m_vvpv
1 其他 3333
2 搜索 2222
3 首页 1111适用场景:video表取播放量最大的几个视频,user表取签到次数最多的几个用户等(不需聚合)注:max_by无法实现如下聚合取top功能
-- hive 聚合
select d_module_type,sum(m_vvpv) m_vv
from app.c_app_videodiscover_uv
where dt='2019-04-27'
group by d_module_type
order by m_vv
limit 3相关推荐 33333
2 首页 22222
3 搜索 11111
计数函数 count count_if
计数:count()
满足条件则计数:count_if()【hive中没有,同hive中 sum(if(condition,1,0))】
eg:presto:adm> select count_if(d_module='为你推荐-大屏') from adm.f_app_video_vv where dt='2019-04-27' ;_col0---------6666
近似计数函数 approx_distinct
approx_distinct(x) → bigint
count(distinct x)的近似计算,较count distinct速度快,约有2.3%的误差。
eg:select approx_distinct(d_diu) from adm.f_app_video_vv where dt='2019-04-27' and d_module='为你推荐-大屏';select count(distinct d_diu) from adm.f_app_video_vv where dt='2019-04-27' and d_module='为你推荐-大屏';
分组计数函数 histogram
返回x值及其count组成的map:histogram(x) -> map(K, bigint)eg:
select histogram(client)
from app.c_app_videodiscover_uv
where dt='2019-04-27'----------------------------{其他=3, IOS=4, Android=4}
七、窗口函数
窗口函数和分组排序函数示例:
row_number() over (partition by u_appname order by share_dnu desc) rank
排序窗口函数对比 row_number、rank、dense_rank
1. row_number:不管排名是否有相同的,都按照顺序1,2,3…..n1. eg:12345672. RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位1. eg:12335673. DENSE_RANK() 生成数据项在分组中的排名,排名相等不会在名次中留下空位1. eg:1233456
**将每组分组排序个数限定在n以内[含n]:ntile(n) → bigint **
eg:
select client,d_module_type,m_vvpv,ntile(3) over (order by m_vvpv desc) rank
from app.c_app_videodiscover_uv
where dt='2019-04-27'client | d_module_type | m_vvpv | rank
---------+---------------+---------+------Android | 其他 | 7777 | 1Android | 搜索 | 6666 | 1Android | 首页 | 5555 | 1Android | 相关推荐 | 4444 | 1IOS | 其他 | 3333 | 2IOS | 搜索 | 2222 | 2IOS | 相关推荐 | 1111 | 2IOS | 首页 | 999 | 2其他 | 相关推荐 | 88 | 3其他 | 首页 | 1 | 3其他 | 其他 | NULL | 3
(11 rows)
返回排名/最大排名:percent_rank() → double
eg:
select client,d_module_type,m_vvpv,percent_rank() over (partition by client order by m_vvpv desc) rank
from app.c_app_videodiscover_uv
where dt='2019-04-27'client | d_module_type | m_vvpv | rank
---------+---------------+---------+--------------------Android | 其他 | 7777 | 0.0Android | 搜索 | 6666 | 0.3333333333333333Android | 首页 | 5555 | 0.6666666666666666Android | 相关推荐 | 4444 | 1.0其他 | 相关推荐 | 88 | 0.0其他 | 首页 | 1 | 0.5其他 | 其他 | NULL | 1.0IOS | 其他 | 3333| 0.0IOS | 搜索 | 2222 | 0.3333333333333333IOS | 相关推荐 | 1111 | 0.6666666666666666IOS | 首页 | 999 | 1.0
(11 rows)
八、数组、MAP、Json函数
数组:
SELECT ARRAY [1,2] -- [1, 2]array_distinct(x) → array
array_max(x) → x
array_min(x) → x
array_sort(x) → array
Map:
map_keys(x(K, V)) -> array(K)
map_values(x(K, V)) -> array(V)
element_at(map(K, V), key) → V扩展:取map中的key变成数组,数组中查看包含'cid'返回true:contains(map_keys(event_args),'cid') = true
Json:
判断是否为json:is_json_scalar(u_bigger_json)eg:select is_json_scalar(u_bigger_json)from edw.user_elogwhere dt='2019-04-27'limit 3-------falsefalsefalsestring转json-推荐:json_parse(u_bigger_json)
eg:
select json_parse(u_bigger_json)
from edw.user_elog
where dt='2019-04-27'
limit 3
-- {"u_rank":",0,1,2","u_recsid":",100002,100002,100002","u_rmodelid":",17,17,17",
-- {"u_abtag":"35","u_device_s":"HWMYA-L6737","u_frank":"8","u_package":"com.bokec
-- {"u_abtag":"97","u_all_startid":"1556315003775","u_buglyupdate":"1","u_device_sstring转json-不建议:cast(u_bigger_json as json)
eg:
select cast(u_bigger_json as json) from edw.user_elog where dt='2019-04-27' limit 10;
-- "{\"u_vpara\":\"0\",\"u__\":\"1556317886230\",\"u_callback\":\"jQuery17206597692994207338
_1556317875402\"}"获取json中某key的值:
select json_extract_scalar(json_parse(u_bigger_json),'$.u_abtag')
from edw.user_elog
where dt='2019-04-27'
limit 30
-- -------
-- 29
-- 21
-- 16
-- ~判断value是否在json(json格式的字符串)中存在:
json_array_contains(json, value) → boolean
SELECT json_array_contains('[1, 2, 3]', 2)判断json中是否含有某key
法1:失败
select json_array_contains('[1, 2, u_p_source, 3]', 'u_p_source')
法2:结合split和cardinality(获取array长度)
SELECT split('[1, 2, u_p_source, 3]', 'u_p_source'),split('[1, 2, 3]', 'u_p_source'),cardinality(split('[1, 2, u_p_source, 3]', 'u_p_source')),cardinality(split('[1, 2, 3]', 'u_p_source'))
["[1, 2, ",", 3]"]
["[1, 2, 3]"]
2
1即:where cardinality(split(u_bigger_json,{{ para }}))>1
扩展:string格式的json中取某key的value
select dt,-- function1: split stringsum(cast(split(split(split(split(u_bigger_json,'u_num')[2],',')[1],':')[2],'"')[2] as int)) flower_send_pv,-- function2: string to json, get valuesum(cast(json_extract_scalar(json_parse(u_bigger_json),'$.u_num')as int)) flower_send_pv_2,count(distinct u_diu) flower_send_uv
from edw.user_ilog
where dt= cast(current_date - interval '1' day as varchar)
and u_mod='flower'
and u_ac='new_send'
group by dtdt | flower_send_pv | flower_send_pv_2 | flower_send_uv
------------+----------------+------------------+----------------2019-04-27 | 8888 | 8888 | 5678
相关文章:

1. Presto基础
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 一、presto基础操作二、时间函数0、当前日期/当前时间1、转时间戳1)字符串转时间戳 (推荐)2)按照format指定的格式,将字符串str…...
ChatGPT可以帮你做什么?
学习 利用ChatGPT学习有很多,比如:语言学习、编程学习、论文学习拆解、推荐学习资源等,使用方法大同小异,这里以语言学习为例。 在开始前先给GPT充分的信息:(举例) 【角色】充当一名有丰富经验…...
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包 2024/1/11 18:25 百度搜搜:ubuntu rar文件怎么解压 rootrootrootroot-X99-Turbo:~/temp$ ll total 2916 drwx------ 3 rootroot rootroot 4096 1月 11 18:28 ./ drwxr-xr-x 25 rootroot rootroot 4096 1月…...
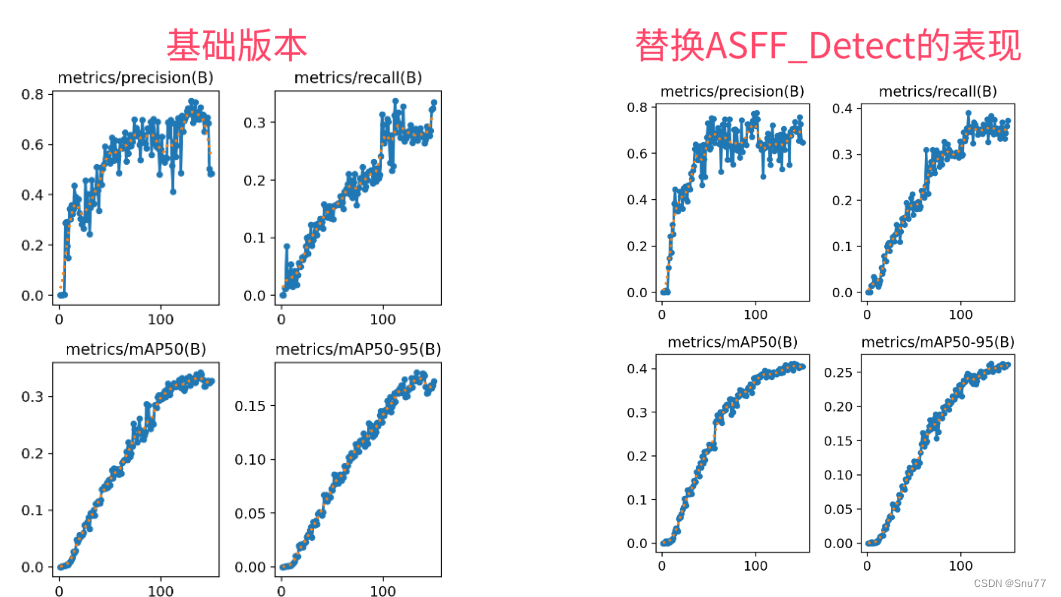
YOLOv5改进 | 检测头篇 | ASFFHead自适应空间特征融合检测头(全网首发)
一、本文介绍 本文给大家带来的改进机制是利用ASFF改进YOLOv5的检测头形成新的检测头Detect_ASFF,其主要创新是引入了一种自适应的空间特征融合方式,有效地过滤掉冲突信息,从而增强了尺度不变性。经过我的实验验证,修改后的检测头在所有的检测目标上均有大幅度的涨点效果,…...
)
第十三章 接口测试(笔记)
一、接口测试分类 内部接口:测试被测系统各个子模块之间的接口,或者被测系统提供给内部系统使用的接口 外部接口: 1.被测系统调用外部的接口 2.系统对外提供的接口 接口测试重点:检查接口参数传递的正确性,接口功能的正确性,输出结果的正确性,以及对各种异常情况的容错…...
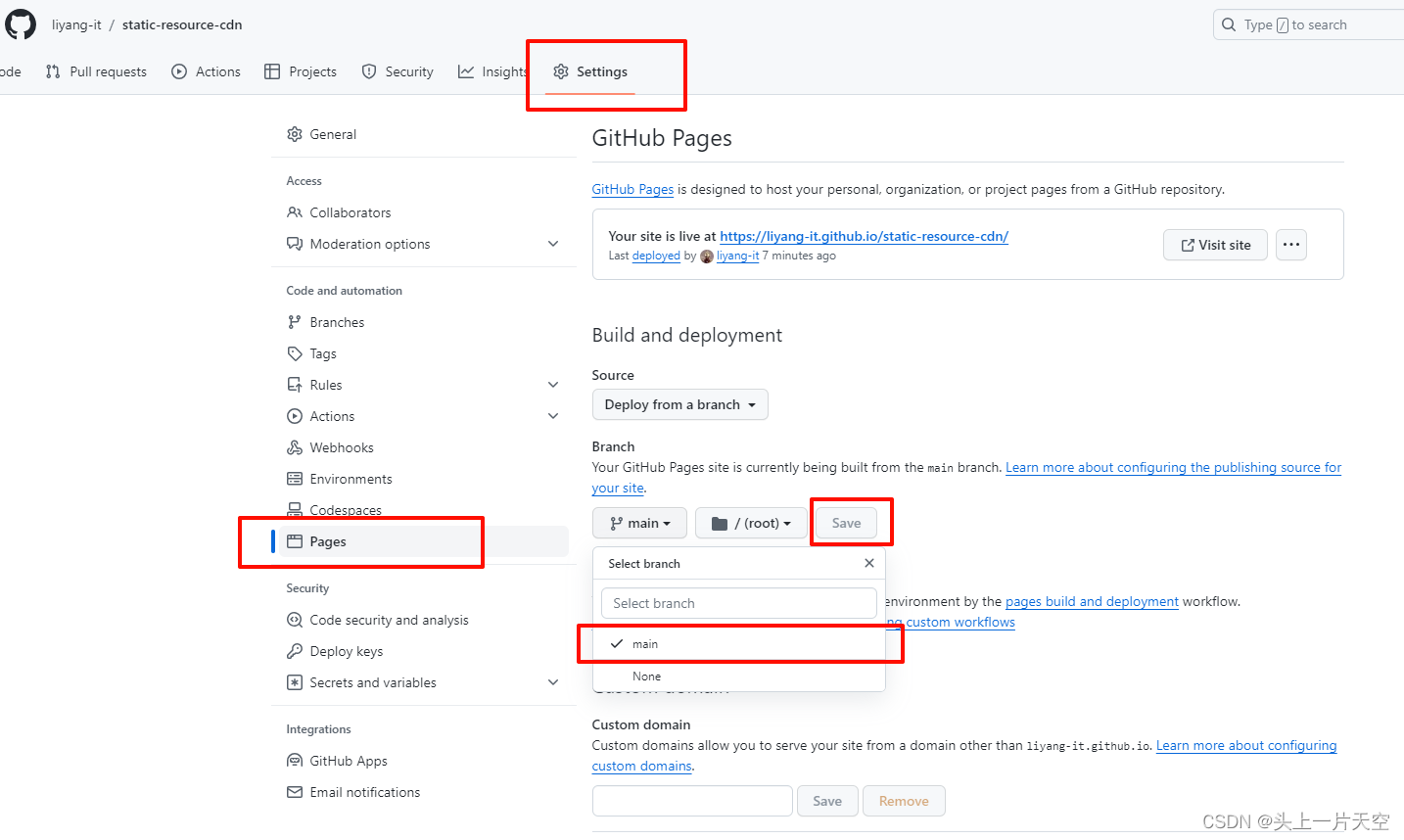
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问 前言1、创建仓库2、开启 gh-pages页面功能3、访问测试 前言 写博客文章时,图片的上传和存放是一个问题,使用小众第三方图床,怕不稳定和倒闭&…...

Airtest-Selenium实操小课②:刷B站视频
1. 前言 上一课我们讲到用Airtest-Selenium爬取网站上我们需要的信息数据,还没看的同学可以戳这里看看~ 那么今天的推文,我们就来说说看,怎么实现看b站、刷b站的日常操作,包括点击暂停,发弹幕,点赞&#…...
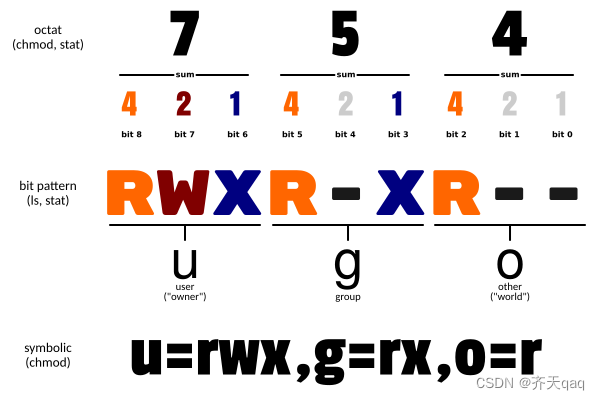
Linux chmod命令详解
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令 Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)…...

求幸存数之和 - 华为OD统一考试
OD统一考试(C卷) 分值: 100分 题解: Java / Python / C++ 题目描述 给一个正整数列nums,一个跳数jump,及幸存数量left。运算过程为:从索引为0的位置开始向后跳,中间跳过 J 个数字,命中索引为 J+1 的数字,该数被敲出,并从该点起跳,以此类推,直到幸存left个数为止。…...
【QML COOK】- 008-自定义属性
前面介绍了用C定义QML类型,通常在使用Qt Quick开发项目时,C定义后端数据类型,前端则完全使用QML实现。而QML类型或Qt Quick中的类型时不免需要为对象增加一些属性,本篇就来介绍如何自定义属性。 1. 创建项目,并编辑Ma…...
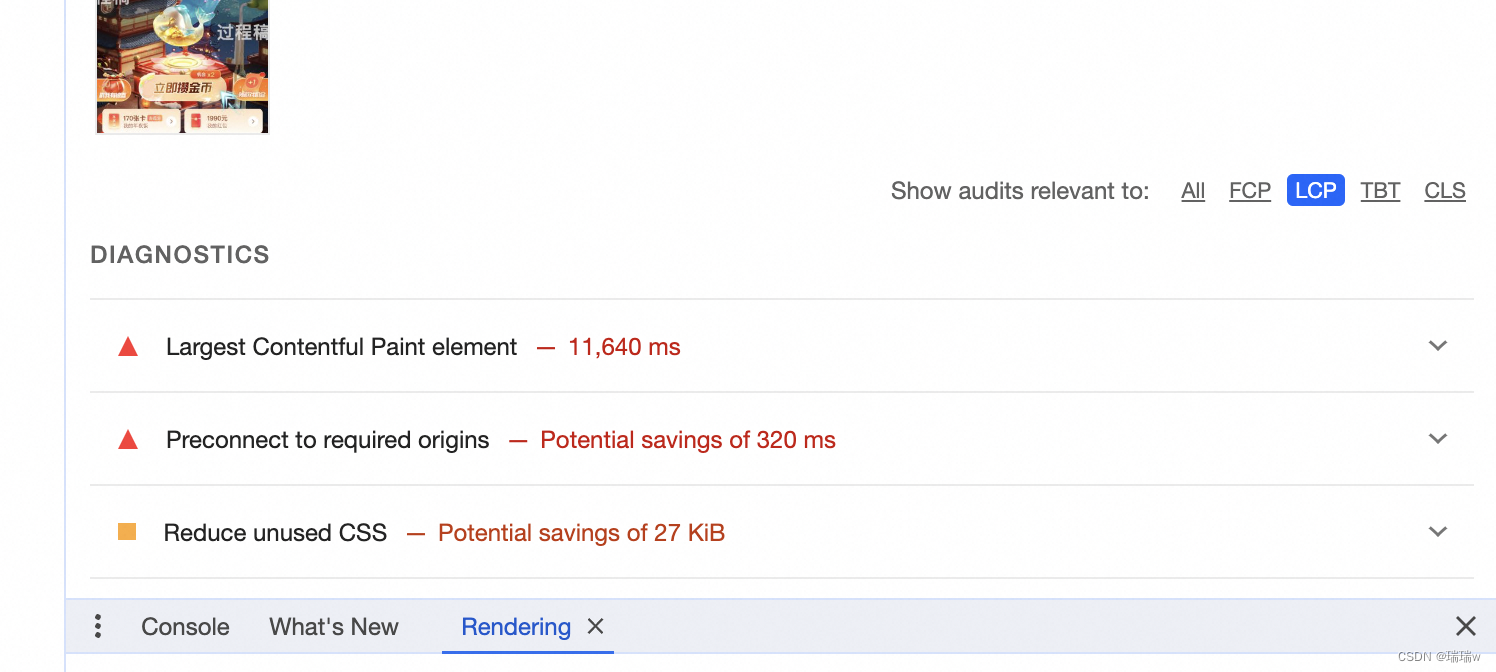
前端页面优化做的工作
1.分析模块占用空间 new (require(webpack-bundle-analyzer).BundleAnalyzerPlugin)() 2.使用谷歌浏览器中的layers,看下有没有影响性能的模块,或者应该销毁没销毁的 3.由于我们页面中含有很大的序列帧动画,所以会导致页面性能低࿰…...
Spark六:Spark 底层执行原理SparkContext、DAG、TaskScheduler
Spark底层执行原理 学习Spark运行流程 学习链接:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ 一、Spark运行流程 流程: SparkContext向管理器注册并向资源管理器申请运行Executor资源管理器分配Executor,然后资源管理器启动Execut…...

关于鸿蒙的笔记整理
提示:有使用过 vue 或 react 的小伙伴更容易理解 知识点强调: ArkTS所有内容都不支持深层数据更新 UI渲染 文章目录 一、关于样式1 . 默认单位 vp2 . 写公共样式 二 、 加载图片三 、 自定义构建函数 Builder四、构建函数-BuilderParam 传递UI五 、 父子…...
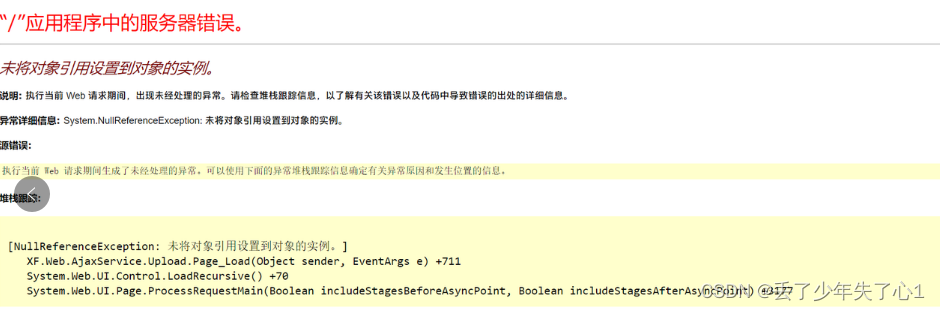
【漏洞复现】先锋WEB燃气收费系统文件上传漏洞 1day
漏洞描述 /AjaxService/Upload.aspx 存在任意文件上传漏洞 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作…...
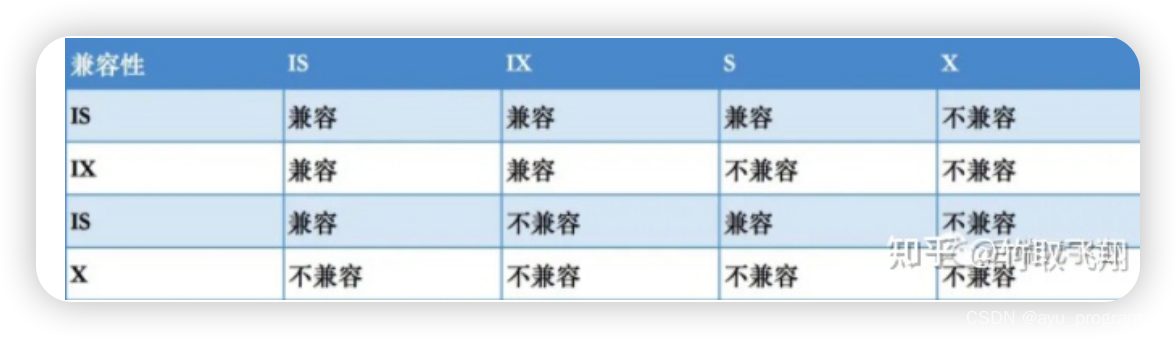
MYSQL篇--锁机制高频面试题
Mysql锁机制 1对mysql的锁有了解吗? 首先我们要知道,mysql的锁 其实是为了解决在并发事务时所导致的数据不一致问题的一种处理机制,也就是说 在事务的隔离级别实现中,就需要利用锁来解决幻读问题 然后我们可以聊到锁的分类 按锁…...
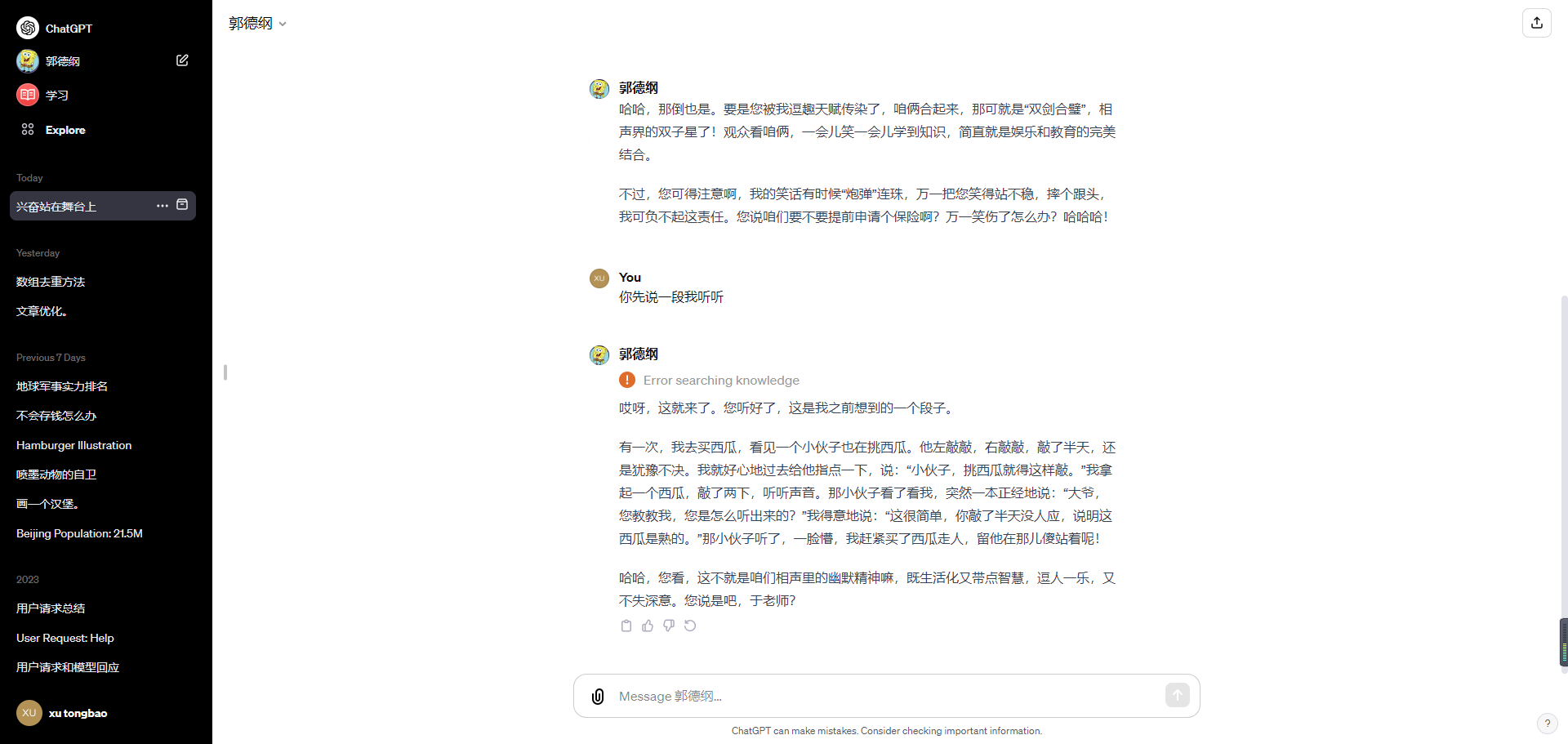
创建一个郭德纲相声GPTs
前言 在这篇文章中,我将分享如何利用ChatGPT 4.0辅助论文写作的技巧,并根据网上的资料和最新的研究补充更多好用的咒语技巧。 GPT4的官方售价是每月20美元,很多人并不是天天用GPT,只是偶尔用一下。 如果调用官方的GPT4接口&…...
靶机实战(10):OSCP备考之VulnHub Tre 1
靶机官网:Tre: 1[1] 实战思路: 一、主机发现二、端口发现(服务、组件、版本)三、漏洞发现(获取权限) 8082端口/HTTP服务 组件漏洞URL漏洞(目录、文件)80端口/HTTP服务 组件漏洞URL漏…...

在windows11系统上利用docker搭建linux记录
我的windows11系统上,之前已经安装好了window版本的docker,没有安装的小伙伴需要去安装一下。 下面直接记录安装linux的步骤: 一、创建linux容器 1、拉取镜像 docker pull ubuntu 2、查看镜像 docker images 3、创建容器 docker run --…...

swift对接环信sdk
准备 熟练objective-c语言 有一台mac电脑,并安装了xcode 和 cocoapods 内容篇幅较长,需要内心平和耐心看下去,务必戒躁. 学习目的 手把手教大家如何在iOS应用中集成环信IM 明确表示,内容一定全面,没有任何丢失,只要沉得住气,耐得下心,3小时即可搞定. 若经常阅读文档以及语…...
单片机中的PWM(脉宽调制)的工作原理以及它在电机控制中的应用。
目录 工作原理 在电机控制中的应用 脉宽调制(PWM)是一种在单片机中常用的控制技术,它通过调整信号的脉冲宽度来控制输出信号的平均电平。PWM常用于模拟输出一个可调电平的数字信号,用于控制电机速度、亮度、电压等。 工作原理 …...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

RTX 5090功耗传闻解析:600W显卡对PC生态的挑战与应对
1. 项目概述:从一则功耗新闻到显卡生态的深度思考最近,英伟达下一代旗舰显卡RTX 5090的功耗传闻在硬件圈里炸开了锅。消息称其TGP(总图形功耗)可能高达600W,相比RTX 4090的450W,直接激增了150W。这不仅仅是…...

绿色AI能耗优化:从模型架构到MLOps实践
1. 绿色AI能耗研究的现实意义在深度学习模型参数量呈指数级增长的今天,AI系统的能源消耗已成为不可忽视的环境负担。根据最新研究,训练一个大型语言模型的碳排放量相当于五辆汽车整个生命周期的排放总量。这种惊人的能源消耗与全球减碳目标形成了尖锐矛盾…...

AI Agent在科学研究中的辅助作用
AI Agent在科学研究中的辅助作用 关键词:AI Agent, 科学研究辅助, 自主代理架构, 多模态推理, 文献挖掘, 实验设计, 未来展望 摘要:本文将像给小学生讲魔法实验室故事一样,深入浅出地拆解AI Agent这个“超级科研小助手天团”的核心原理、架构…...

基于RP2040与Santroller固件,复活旧吉他控制器玩转现代音游
1. 项目概述:让尘封的“神器”重获新生如果你和我一样,是个从《吉他英雄》、《摇滚乐队》时代走过来的老玩家,家里大概率还躺着一两把当年斥“巨资”购入的专用吉他控制器。它们手感扎实,造型酷炫,但最大的悲哀莫过于&…...

)
避坑指南:HugeGraph-Server 0.12.0 用MySQL做后端存储,配置文件到底怎么改?(附完整流程)
HugeGraph-Server 0.12.0 MySQL后端配置深度解析与实战避坑指南 当选择MySQL作为HugeGraph-Server的后端存储时,配置文件的细微差异往往成为项目落地的"拦路虎"。本文将深入剖析hugegraph.properties中MySQL相关配置的每一个关键参数,结合典型…...

如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南
如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款强大的Unity游戏插件框架,为游戏模组…...
)
别再只盯着P值了!用Stata做格兰杰检验后,这样解读结果才专业(含VAR模型与脉冲响应分析)
超越P值陷阱:格兰杰检验的深度解读与Stata实战指南 当屏幕上跳出那个熟悉的P值时,大多数研究者会条件反射般地做出二元判断——"显著"或"不显著",然后匆匆写下结论。这种机械式的数据分析方式正在学术界和业界制造大量&q…...