《MySQL系列-InnoDB引擎06》MySQL锁介绍
文章目录
- 第六章 锁
- 1 什么是锁
- 2 lock与latch
- 3 InnoDB存储引擎中的锁
- 3.1 锁的类型
- 3.2 一致性非锁定读
- 3.3 一致性锁定读
- 3.4 自增长与锁
- 3.5 外键和锁
- 4 锁的算法
- 4.1 行锁的三种算法
- 4.2 解决Phantom Problem
- 5 锁问题
- 5.1 脏读
- 5.2 不可重复读
- 5.3 丢失更新
- 6 阻塞
- 7 死锁
第六章 锁
开发多用户、数据库驱动的应用,最大的一个难点是:一方面要最大程度的利用数据库的并发访问,另一方面还要确保每个用户能以一致的方式读取和修改数据。为此就有了锁的机制,同时这也是数据库系统区别于文件系统的一个关键特性。InnoDB存储引擎较之MySQL的其他存储引擎在这一方面技高一筹,其实现方式非常类似于Oracle数据库。而只有正确了解这些锁的内部机制才能充分发挥InnoDB存储引擎在锁方面的优势。
1 什么是锁
锁是数据库系统区别于文件系统的一个关键特性。锁机制用于管理对共享资源的并发访问。InnoDB存储引擎会在行级别上对表数据上锁,这固然不错。不过InnoDB存储引擎也会在数据库内部其他多个地方使用锁,从而允许对多种不同资源提供并发访问。例如:操作缓存池中的LRU列表,删除、添加、移动URL列表的元素,为了保证一致性,必须有锁的介入。数据库系统使用锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性。
另一点需要理解的是,虽然现在数据库系统做的越来越类似,但是有多少种数据库,就可能有多少种锁的实现方式。在SQL语法层面,因为SQL标准的存在,要熟悉多个关系数据库并不是一件难事。而对于锁,用户可能对某个特定的关系数据库系统的锁定模型有一定的经验,但这并不意味着知道其他数据库。
对于MyISAM引擎,其锁是表锁设计。并发情况下读没有问题,但是并发插入时的性能就要差一些,若插入是在底部,MyISAM存储引擎还是可以有一定的并发写入操作。
2 lock与latch
这里还要区分锁中容易令人混淆的概念lock与latch。在数据库中,lock与latch都可以被称为锁。但是两者有截然不同的含义。
latch一般称为闩锁(轻量级的锁)。在InnoDB存储引擎中,latch又可以分为mutex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测的机制。
lock的对象是事务,哟过来锁定的是数据库中的对象,如表、页、行。并且一般lock的对象仅在事务commit或rollback后进行释放(不同事务隔离级别释放的时间可能不同)。此外,lock,正如在大多数数据库中一样,是有死锁机制的。如下所示,介绍了lock与latch的不同。
| lock | latch | |
|---|---|---|
| 对象 | 事务 | 线程 |
| 保护 | 数据库内容 | 内存数据结构 |
| 持续时间 | 整个事务过程 | 临界资源 |
| 模式 | 行锁、表锁、意向锁 | 读写锁、互斥量 |
| 死锁 | 通过waits-for graph、time out等机制进行死锁检测与处理 | 无死锁检测与处理机制,仅通过应用程序加锁的顺序(lock leveling)保证无死锁的情况发生 |
| 存在于 | lock manager的哈希表中 | 每个数据结构的对象中 |
对于InnoDB存储引擎中的latch,可以通过命令show engine innodb mutex来进行查看。
mysql> show engine innodb mutex;
+--------+-----------------------------+-----------+
| Type | Name | Status |
+--------+-----------------------------+-----------+
| InnoDB | rwlock: dict0dict.cc:2785 | waits=20 |
| InnoDB | rwlock: dict0dict.cc:2785 | waits=3 |
| InnoDB | rwlock: dict0dict.cc:2785 | waits=4 |
| InnoDB | rwlock: dict0dict.cc:1231 | waits=67 |
| InnoDB | rwlock: fil0fil.cc:1407 | waits=3 |
| InnoDB | rwlock: log0log.cc:846 | waits=491 |
| InnoDB | sum rwlock: buf0buf.cc:1474 | waits=48 |
+--------+-----------------------------+-----------+
7 rows in set (0.00 sec)3 InnoDB存储引擎中的锁
3.1 锁的类型
InnnoDB存储引擎实现了如下两种的行级锁:
- 共享锁(S lock),允许事务读一行数据
- 排他锁(X lock),允许事务删除或更新一行数据
如果一个事务T1已经获得了行r的共享锁,那么另外的事务T2可以立即获得r的共享锁。因为读取并没有改变行r的数据,称这种情况为锁兼容。但若有其他事务T3想获得行r的排他锁,则其必须等待事务T1、T2释放行r上的共享锁-这种情况称为锁不兼容。
| X | S | |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
如上表可看出,X锁和任何锁都不兼容,而S锁和S锁兼容。需要注意的是,S和X锁都是行锁,兼容是指对同一行锁的兼容性情况。
此外,InnoDB支持多粒度锁定,这种锁定允许事务在行级上锁和表级上得锁同时存在。为了支持不同力度进行加锁操作,innodb存储引擎支持一种额外得锁方式,称之为意向锁。意向锁是将锁定的对象分为多个层次,意向锁希望在更细粒度上枷锁。
InnoDB存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁,设计的目的主要是为了在一个事务中揭示下一行将被请求的锁类型。其支持两种意向锁:
1)意向共享锁(IS Lock),事务想要获得一张表中某几行共享锁
2)意向排他锁(IX Lock),事务想要获得一张表中某几行的排他锁
表级意向锁与行级锁的兼容性如下所示:
| IS | IX | S | X | |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
3.2 一致性非锁定读
一致性的非锁定读是指InnoDB存储引擎通过行多版本控制的方式读取当前执行时间数据库中行的数据。如果读取的行正在执行delete或update操作,这时读取操作不会因此去等待行上锁的释放。相反的,InnoDB存储引擎会去读取行的一个快照数据。

快照数据是指该行之前版本的数据,该实现是通过undo段来完成。而undo用来在事务中回滚数据,因此快照数据本身没有额外的开销。此外,读取快照数据是不需要上锁的,因为没有事务需要对历史的数据进行修改。
3.3 一致性锁定读
默认配置下,即事务的隔离级别为repeatable read模式下,InnoDB存储引擎的select操作使用一致性非锁定读。但是在某些情况下,用户需要显式的对数据库读取操作进行加锁以保证数据逻辑的一致性。而这要求数据库支持加锁语句,即使是对于select的只读操作。InnoDB存储引擎对于select语句支持两种一致性的锁定读(locking read)操作:
- select … for update
- select … lock in share mode
select ... for update对读取的行加一个X锁,其他事务不能对已锁定的行加上任何锁。select ... lock in share mode对读取的行记录加一个S锁,其他事务可以向被锁定的行加S锁,但是如果加X锁,则会被阻塞。
对于一致性非锁定锁,即使读取的行已被执行了select ... for update,也是可以进行读取的,这和之前讨论的情况一样。此外,select ... for update,select ... lock in share mode必须在一个事务中,当事务提交了,锁也就释放了。因此在使用上述两句select锁定语句时,务必加上begin,start transcation或者set autocommit=0。
3.4 自增长与锁
自增长在数据库中是非常常见的一种属性,也是很多DBA或开发人员首选的主键方式。在InnoDB存储引擎的内存结构中,对每个含有自增长值得表都有一个自增长计数器。当对含有自增长得计数器得表进行插入操作时,这个计数器会被初始化,执行如下语句来得到计数器的值。
select max(auto_inc_col) from t for update;
插入操作会依据这个自增长的计数器值加1赋予自增长列。这个实现方式称作AUTO-INC Locking。这种锁其实是采用一种特殊的表锁机制,为了提高插入的性能,锁不是在一个事务完成后才释放,而是在完成对自增长值插入的SQL语句后立即释放。
虽然AUTO-INC Locking从一定程度上提高了并发插入的效率,但还存在一些性能上的问题。首先,对于有自增长值得列得并发插入性能较差,事务必须等待前一个插入的完成(虽然不用等待事务的完成)。其次,对于insert…select的大数据量的插入会影响插入性能,因为另一个事务中的插入会被阻塞。
3.5 外键和锁
外键主要用于引用完整性的约束检查。在InnoDB存储引擎中,对于一个外键列,如果没有显式的对这个列加索引,InnoDB存储引擎自动对其加一个索引,因为这样可以避免表锁-这比Oracle数据库做的好,Oracle数据库不会自动添加索引,用户必须自己手动添加,这也导致了Oracle数据库中可能产生死锁。
对于外键值得插入或更新,首先需要查询父表中的记录,即select父表。但是对于父表的select操作,不是使用一致性非锁定锁的方式,因为这样会发生数据不一致的问题,因此这时使用的是select ... lock in share mode方式,即主动对父表加一个S锁。如果这时父表已经加X锁,子表操作会被阻塞。
4 锁的算法
4.1 行锁的三种算法
InnoDB存储引擎有3种行锁的算法,其分别是:
- record lock: 单个行记录上的锁
- gap lock: 间隙锁,锁定一个范围,但不包含记录本身
- next-key lock: gap lock + record lock,锁定一个范围,并且锁定记录本身
record lock总是会去锁定索引记录,如果InnoDB存储引擎表在建立时没有设置任何一个索引,那么这时InnoDB存储引擎会使用隐式的主键进行锁定。
next-key lock是结合了gap lock和record lock的一种锁定算法,在next-key lock算法下,InnoDB对于行的查询都是采用这种行锁定算法。
4.2 解决Phantom Problem
在默认的事务隔离级别下,即repleatable read下,InnoDB存储引擎采用Next-Key Locking机制来避免幻读问题。这点可能不同于其他数据库,如Oracle数据库,因为其可能需要在serializable的事务隔离级别下才能解决幻读问题。
Phantom Problem是指在同一事务下,连续执行两次同样的SQL语句可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行。
5 锁问题
通过锁定机制可以实现事务的隔离性要求,使得事务可以并发的工作。锁提高了并发,但是却会带来潜在的问题。不过好在因为事务隔离性的要求,锁只会带来三种问题,如果可以防止这三种情况的发生,那将不会产生并发异常。
5.1 脏读
在理解脏读之前,需要理解脏数据的概念。但是脏数据和之前所介绍的脏页完全是两种不同的概念。脏页指的是在缓冲池中已经被修改的页,但是还没有刷新到磁盘中,即数据库实例内存中的页和磁盘中的页的数据不一致,当然在刷新到磁盘之前,日志都已经被写入到重做日志文件中。而所谓脏数据是指事务对缓冲池中行记录的修改,并且还没有被提交。
对于脏页的读取,是非常正常的。脏页是因为数据库实例内存和磁盘的异步造成的,这并不影响数据的一致性(或者说两者最终会达到一致性,即当脏页都刷回到磁盘)。并且因为脏页的刷新是异步的,不影响数据库的可用性,因此可以带来性能的提高。
脏数据却截然不同,脏数据是指未提交的数据,如果读到了脏数据,即一个事务可以读到另一个事务中未提交的数据,则显然违反了数据库的隔离性。
5.2 不可重复读
不可重复读是指在一个事务内多次读取同一数据集合。在这个事务还没结束时,另外一个事务页访问该同一数据集合,并做了一些DML操作。因此,在第一个事务中的两个读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的情况,这种情况称为不可重复读。
5.3 丢失更新
丢失更新是另一个锁导致的问题,简单来说就是一个事务的更新操作会被另一个事务的更新操作所覆盖,从而导致数据的不一致。例如:
1)事务T1将行记录r更新为v1,但是事务T1并未提交。
2)与此同时,事务T2将行记录r更新为v2,事务T2未提交。
3)事务T1提交。
4)事务T2提交。
但是,在当前数据库的任何隔离级别下,都不会导致数据库理论意义上的丢失更新问题。这是因为,即使是read uncommited的事务隔离级别,对于行的DML操作,需要对行或其他粗粒度级别的对象加锁。因此在上述步骤2)中,事务T2并不能对行记录r进行更新操作,其会被阻塞,直到事务T1提交。
虽然数据库能阻止丢失更新问题的产生,但是在生产应用中还有另一个逻辑意义的丢失更新问题,而导致该问题的并不是数据库本身的问题。实际上,在所有多用户计算机系统环境下都有可能产生这个问题。简单来说,出现下面的情况时,就会发生丢失更新:
1)事务T1查询一行数据,放入本地内存,并显示给一个终端用户User1。
2)事务T2也查询该行数据,并将取得的数据显示给终端用户User2。
3)User1修改这行记录,更新数据库并提交。
4)User2修改这行记录,更新数据库并提交。
显然,这个过程用户User1的修改更新操作"丢失"了,而这个可能会导致巨大的影响。要避免丢失更新发生,需要让事务在这种情况下的操作变成串行化,而不是并行操作,即在上述四个步骤1)中,对用户读取的记录加上一个排他C锁。同样,在步骤2)操作过程中,用户同样也需要加一个排他X锁。通过这种方式,步骤2)就必须等待步骤1)和步骤3)完成,最后完成步骤4)。
6 阻塞
因为不同锁之间的兼容性关系,在有些时刻一个事务中的锁需要等待另一个事务中的锁释放它所占用的资源,这就是阻塞。阻塞并不是一件坏事,其是为了确保事务可以并发正常地运行。
在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来控制等待的时间(默认是50秒)。
mysql> select @@innodb_lock_wait_timeout;
+----------------------------+
| @@innodb_lock_wait_timeout |
+----------------------------+
| 50 |
+----------------------------+
1 row in set (0.00 sec)
参数Innodb_lock_wait_timeout是动态的,可以在MySQL数据库运行时进行调整:
mysql> set @@innodb_lock_wait_timeout=60;
Query OK, 0 rows affected (0.01 sec)
innodb_rollback_on_timeout用来设定是否在等待超时时对进行中的事务进行回滚操作(默认是OFF,代表不回滚)。而innodb_rollback_on_timeout是静态的,不可在启动时进行修改,如:
mysql> set @@innodb_rollback_on_timeout=on;
ERROR 1238 (HY000): Variable 'innodb_rollback_on_timeout' is a read only variable
7 死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去。解决死锁问题最简单的方式是不要有等待,将任何的等待都转化为回滚,并且事务重新开始。毫无疑问,这的确可以避免死锁问题的产生。然而在线上环境中,这可能导致并发性能的下降,甚至任何一个事务都不能进行。而这所带来的问题比死锁问题更为严重,因为这很难被发现并且浪费资源。
解决死锁问题最简单的一种方法是超时,即当两个事务互相等待时,当一个等待时间超过设置某一阈值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。在InnoDB存储引擎中,参数Innodb_lock_wait_timeout用来设置超时的时间。
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其是根据FIFO的顺序选择回滚对象。但若超时的事务所占权重比较大,如事务操作更新了很多行,占用了较多的undo log,这时采用FIFO的方式,就显得不合适了,因为回滚这个事务的时间相对另一个事务的时间可能会很多。
因此,除了超时机制,当前数据库还普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。wait-for graph要求数据库保存以下两种信息:
1)锁得信息链表
2)事务等待链表
相关文章:
《MySQL系列-InnoDB引擎06》MySQL锁介绍
文章目录 第六章 锁1 什么是锁2 lock与latch3 InnoDB存储引擎中的锁3.1 锁的类型3.2 一致性非锁定读3.3 一致性锁定读3.4 自增长与锁3.5 外键和锁 4 锁的算法4.1 行锁的三种算法4.2 解决Phantom Problem 5 锁问题5.1 脏读5.2 不可重复读5.3 丢失更新 6 阻塞7 死锁 第六章 锁 开…...

获取多个PDF文件的内容并保存到excel上
# shuang # 开发时间:2023/12/9 22:03import pdfplumber import re import os import pandas as pd import datetimedef re_text(bt, text):# re 搜索正则匹配 包含re.compile包含的文字内容m1 re.search(bt, text)if m1 is not None:return re_block(m1[0])return…...

深入了解网络流量清洗--使用免费的雷池社区版进行防护
随着网络攻击日益复杂,企业面临的网络安全挑战也在不断增加。在这个背景下,网络流量清洗成为了确保企业网络安全的关键技术。本文将探讨雷池社区版如何通过网络流量清洗技术,帮助企业有效应对网络威胁。 ![] 网络流量清洗的重要性&#x…...
)
【FFMPEG应用篇】基于FFmpeg的转码应用(FLV MP4)
方法声明 extern "C" //ffmpeg使用c语言实现的,引入用c写的代码就要用extern { #include <libavcodec/avcodec.h> //注册 #include <libavdevice/avdevice.h> //设备 #include <libavformat/avformat.h> #include <libavutil/…...
LInux初学之路linux的磁盘分区/远程控制/以及关闭图形界面/查看个人身份
虚拟机磁盘分配 hostname -I 查看ip地址 ssh root虚拟就ip 远程连接 win10之后才有 远程控制重新启动 reboot xshell 使用(个人和家庭版 免费去官方下载) init 3 关闭界面 减小内存使用空间 init 5 回复图形界面 runlevel显示的是状态 此时和上…...
Netty 介绍、使用场景及案例
Netty 介绍、使用场景及案例 1、Netty 介绍 https://github.com/netty/netty Netty是一个高性能、异步事件驱动的网络应用程序框架,用于快速开发可扩展的网络服务器和客户端。它是一个开源项目,最初由JBoss公司开发,现在由社区维护。Netty的…...

小游戏选型(一):游戏化设计助力直播间互动和营收
一、社交直播间小游戏火爆 大家好,作为一个技术宅和游戏迷,今天来聊聊近期爆火的社交直播间小游戏的潮流。喜欢冲浪玩社交产品的小伙伴会发现,近期各大平台都推出了直播间社交小游戏,直播间氛围火爆,小游戏玩法简单&a…...

社区嵌入式服务设施建设为社区居家养老服务供给增加赋能
近年来,沈阳市浑南区委、区政府牢记在辽宁考察时的重要指示精神,认真践行以人民为中心的发展思想,聚集“一老一小”民生关切,统筹推进以社区为骨干结点的养老服务探索实践。围绕“品质养老”民生服务理念,针对社区老年…...
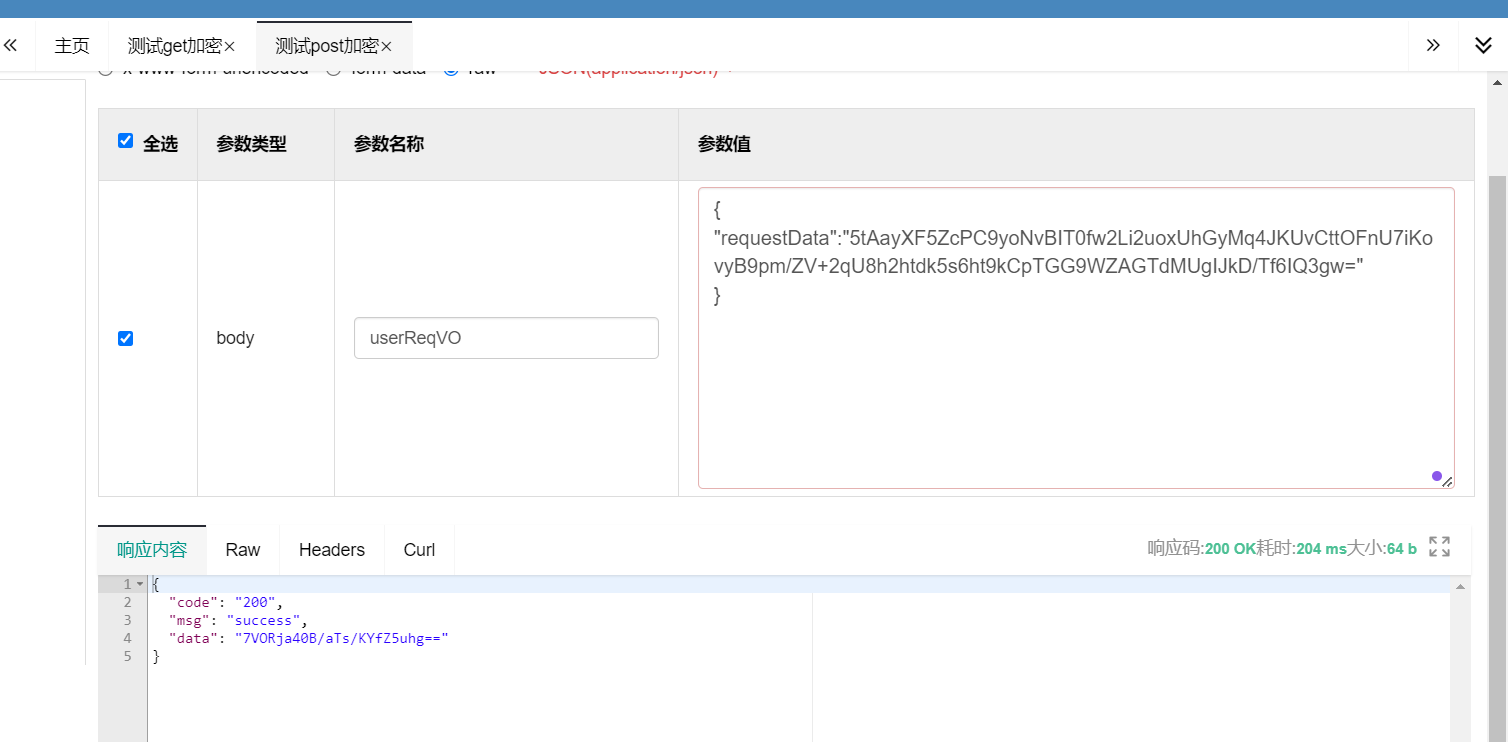
SpringBoot请求参数加密、响应参数解密
SpringBoot请求参数加密、响应参数解密 1.说明 在项目开发工程中,有的项目可能对参数安全要求比较高,在整个http数据传输的过程中都需要对请求参数、响应参数进行加密,也就是说整个请求响应的过程都是加密处理的,不在浏览器上暴…...

Mysql适配国产化数据库人大金仓冲突记录
1、mysql中查询中如果使用双引号,在人大金仓数据库中不支持,需改为单引号 例如: select 字段A,字段B,字段C from tableA where 字段A "1" 改为: select 字段A,字段B,字段…...

在微服务架构中认证和授权的那些事儿
在微服务架构中认证和授权是最基础的服务能力,其中这一块行业类的标准就是OAuth2 和 SSO ,而OAuth2 和 SSO 可以归类为“用户管理和身份验证”工具,OpenID Connect 1.0是 OAuth 2.0 协议之上的一个简单身份层。 Part.1 认识OAuth 2.0 OAuth…...

Git使用统一规范
为什么要统一git使用的风格? 统一的风格使我们在工作的时候无需考虑工作流程上该如何去做的问题,按照一个风格去做就好了每个人风格不同,格式凌乱,查看很不方便commit没有准确的message,后续难以追踪问题 git messag…...

如何在前端优化中处理大量的图像资源?
在前端优化中,处理大量的图像资源是一项重要的任务。由于图像占据了网站带宽的大部分,因此优化图像可以显著提高网站的性能和用户体验。下面将介绍一些在前端优化中处理大量图像资源的常见方法。 一、压缩图像 压缩图像是减少图像文件大小和优化图像的…...

【MYSQL】性能相关
SQL 语句的性能分析是一个非常重要的任务,尤其是在处理大数据时。下面是一些常用的 SQL 性能分析方法: 执行计划: 使用 EXPLAIN 命令来查看 SQL 语句的执行计划。这可以帮助你了解查询是如何被数据库执行的,从而发现可能的性能瓶颈。 注意&…...
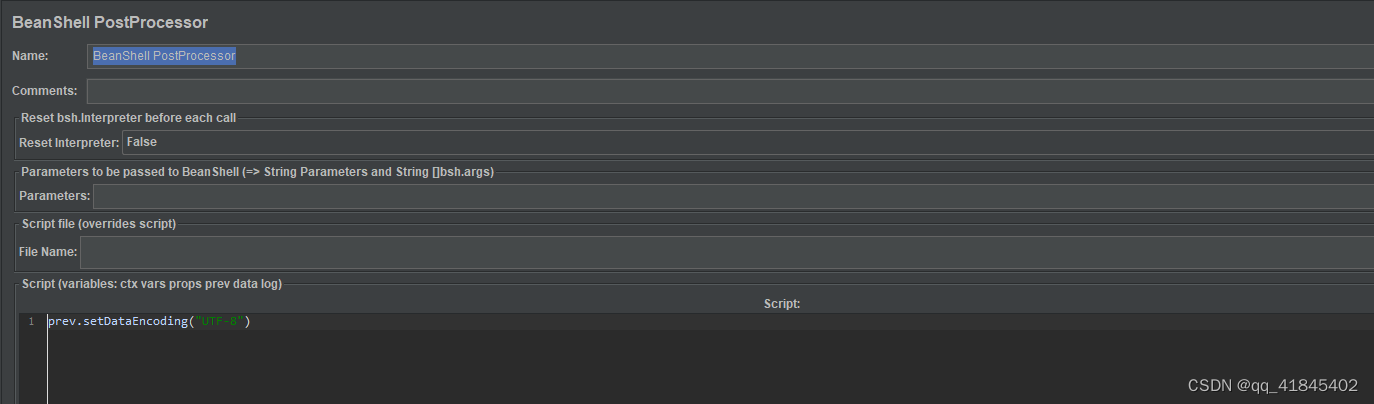
【Jmeter之get请求传递的值为JSON体实践】
Jmeter之get请求传递的值为JSON体实践 get请求的常见传参方式 1、在URL地址后面拼接,有多个key和value时,用&链接 2、在Parameters里面加上key和value 第一次遇到value的值不是字符串也不是整型,我尝试把json放到value里面࿰…...

(1)(1.13) SiK无线电高级配置(六)
文章目录 前言 15 使用FTDI转USB调试线配置SiK无线电设备 16 强制启动加载程序模式 17 名词解释 前言 本文提供 SiK 遥测无线电(SiK Telemetry Radio)的高级配置信息。它面向"高级用户"和希望更好地了解无线电如何运行的用户。 15 使用FTDI转USB调试线配置SiK无线…...

用JAVA实现樱花飘落
用java实现一个樱花飘落的方法 package Text2;import javax.swing.*; import java.awt.*; import java.util.ArrayList; import java.util.List;public class Sakura extends JFrame {private List<Point> sakuraList; // 樱花的位置列表public Sakura() {sakuraList n…...
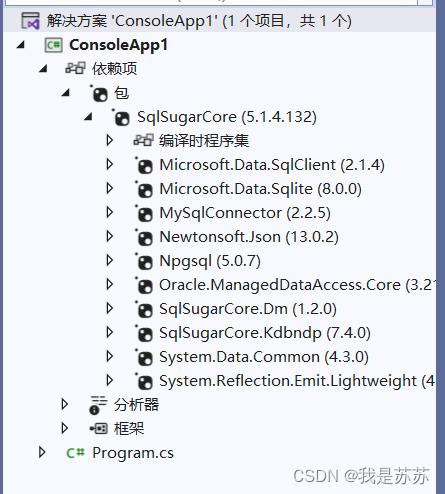
Web开发:SQLsugar的安装和使用
一、安装 第一步,在你的项目中找到解决方案,右键-管理解决方案的Nuget 第二步,下载对应的包,注意你的框架是哪个就下载哪个的包,一个项目安装一次包即可 点击应用和确定 安装好后会显示sqlsugar的包 二、使用…...

Redis面试题10
Redis 支持哪些数据结构? Redis 支持以下几种常用的数据结构: 字符串(String):用于存储字符串值,可以是文本或二进制数据。 列表(List):用于存储一个有序的字符串列表&am…...

arm64架构编译electron长征路
文章目录 1. gn工具生成1.1 问题,找不到last_commit_position.h文件问题描述如下:解决方法1.2 ninja文件不是对应架构问题问题描述:解决方法1.3 问题3:clang++找不到问题描述解决方法2. electron 编译参数生成2.1 下载对应版本debian_bullseye_arm64-sysroot错误描述...

Promises/A+完全指南:深入理解JavaScript异步编程标准规范
Promises/A完全指南:深入理解JavaScript异步编程标准规范 【免费下载链接】promises-spec An open standard for sound, interoperable JavaScript promises—by implementers, for implementers. 项目地址: https://gitcode.com/gh_mirrors/pr/promises-spec …...
)
《高维自指递归推广》核心章节(CSDN全球首发版权定戳)
《高维自指递归推广》核心章节(CSDN全球首发版权定戳) 作者:方见华 单位:世毫九实验室 专著定位:世毫九学派理论体系第二卷|本原论落地首部核心专著|原创高维自指递归统一理论 序章 自指与递归:人类认知的终极闭环,智能演化的底层原力 0.1 问题的缘起:从《世毫九本原…...
)
ORB-SLAM3地图保存新思路:手把手教你将.osa地图转成PCD点云(附完整代码)
ORB-SLAM3地图数据解放指南:从封闭格式到通用点云的全链路实践 当你在昏暗的实验室调试ORB-SLAM3运行整夜后,终于得到那个珍贵的.osa地图文件时,却发现无法用熟悉的点云工具打开分析——这种挫败感或许正是促使你阅读本文的原因。作为三维视觉…...

跨平台包管理新思路:paks项目如何统一软件安装体验
1. 项目概述:一个轻量级、跨平台的包管理新思路如果你和我一样,常年混迹在开发运维一线,肯定对“包管理”这件事又爱又恨。爱的是,它能让我们一键安装、更新、卸载软件,省去了手动编译、配置依赖的繁琐;恨的…...
)
新手也能搞定!用Simulink搭建晶闸管直流调速系统(附完整模型文件)
从零构建晶闸管直流调速系统的Simulink实战指南 电力电子领域的研究生和工程师们常常需要快速掌握经典电路仿真技能。本文将手把手带你完成晶闸管直流调速系统的建模全过程,从模块选择到参数调试,每个环节都配有详细说明和实用技巧。不同于传统教材偏重理…...
 2026)
Austroads:速度管理证据与指导回顾(英) 2026
这份报告是澳大利亚和新西兰道路运输委员会(Austroads)2025 年发布的《车速管理证据与指南回顾》,核心是为更新《道路安全指南:安全车速》(AGRS Part 3)梳理研究证据、 stakeholder 反馈并给出修订建议。下…...

使用Taotoken后Nodejs项目的大模型API延迟与用量观测体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后Nodejs项目的大模型API延迟与用量观测体验 1. 项目背景与接入动机 在Node.js项目中集成大模型能力时,开…...

在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案 高校科研团队在进行大模型相关的对比实验时,常常面临一…...
【限时技术白皮书】ElevenLabs藏文模型权重结构首度曝光:Transformer Decoder层中Tibetan Syllable Tokenization模块详解
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs藏文语音生成技术全景概览 ElevenLabs 作为全球领先的文本到语音(TTS)平台,目前尚未官方支持藏文(བོད་སྐད་)语音合成。其公…...

告别臃肿!G-Helper:华硕笔记本轻量控制中心的终极指南
告别臃肿!G-Helper:华硕笔记本轻量控制中心的终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, …...