GPT2:Language Models are Unsupervised Multitask Learners
目录
一、背景与动机
二、卖点与创新
三、几个问题
四、具体是如何做的
1、更多、优质的数据,更大的模型
2、大数据量,大模型使得zero-shot成为可能
3、使用prompt做下游任务
五、一些资料
一、背景与动机
基于 Transformer 解码器的 GPT-1 证明了在特定的自然语言理解任务 (如文档分类等) 的标注数据较少的情况下,通过充分利用好大量的无标注的数据,也能取得很强的性能。几个月之后,基于 Transformer 编码器的 BERT 性能赶超了 GPT-1。GPT-2 希望构建更大的数据集和模型,同时在 Zero-shot 的多任务学习场景中展示出不错的性能。
说白了还是为了解决模型泛化性问题。GPT1 的 "pre-training + supervised finetuning" 的这一范式:
- 虽然借助预训练这一步提升性能,但是本质上还是需要有监督的 finetuning 才能使得模型执行下游任务。
- 需要在下游任务上面有标注的数据。当我们只有很少量的可用数据 (即 Zero-shot 的情况下) 时就不再使用了。
二、卖点与创新
Zero-shot: GPT-2 本质上还是一个语言模型,但是不一样的是,它证明了语言模型可以在 Zero-shot 的情况下执行下游任务,也就是说,GPT-2 在做下游任务的时候可以无需任何标注的信息,也无需任何参数或架构的修改。个人理解,GPT-2本身做的是GPT-1中的预训练,但是在一个更大的数据集上,用更大的模型通过自监督的方式学到了任务无关的特性。
三、几个问题
- 为什么是zero-shot?
- Zero-Shot 情况下怎么让模型做下游任务?
四、具体是如何做的
1、更多、优质的数据,更大的模型
数据:WebText数据集,一个包含了4500万个链接的文本数据集。经过重复数据删除和一些基于启发式的清理后,它包含略多于800万个文档,总文本容量为 40GB。
模型:GPT-2 的模型在 GPT 的基础上做了一些改进,如下:
- Layer Normalization 移动到了每个 Sub-Block 的输入部分,在每个 Self-Attention 之后额外添加了一个 Layer Normalization,最终顺序是:LN, Self-Attention , LN。
- 采用一种改进的初始化方法,该方法考虑了残差路径与模型深度的累积。在初始化时将 residual layers 的权重按
的因子进行缩放,其中
是 residual layers 的数量。
- 字典大小设置为50257。
- 无监督预训练可看到的上下文的 context 由512扩展为1024。
- Batch Size 大小调整为512。
2、大数据量,大模型使得zero-shot成为可能。
GPT-2 方法的核心是语言建模。大规模无监督训练过程使得模型学习到了任务相关的信息。
在GPT-1中,第一阶段是无监督预训练过程,训练的方法是让 GPT "预测未来"。具体而言,假设我们无标记的语料库里面有一句话是 ,GPT 的模型参数是 Θ ,作者设计了下面这个目标函数来最大化
:
![]()
式中, 是上下文窗口的大小。这个式子的含义是让模型看到前面
个词,然后预测下一个词是什么,再根据真实的下一个词来计算误差,并使用随机梯度下降来训练。上式的本质是希望模型能够根据前
个词更好地预测下一个词。
这个式子其实做的事情是让下式尽量大:
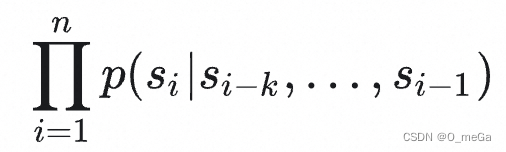
语言模型的这个式子可以表示为:,也就是在给定输入的情况下,最大化已知输出的概率。
注意到,GPT 之前在做这一步的时候,是在自然的文本上面训练的。自然文本的特点是,它里面有任务相关的信息,但是呢,这个信息通常是蕴含在文本里面的,比如下面这段话 (来自 GPT-2 论文):
"I'm not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I'm not a fool].In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: "Mentez mentez, il en restera toujours quelque chose," which translates as, "Lie lie and something will always remain." "I hate the word 'perfume,'" Burr says. 'It's somewhat better in French: 'parfum.' If listened carefully at 29:55, a conversation can be heard between two guys in French: "-Comment on fait pour aller de l'autre cot ́e? -Quel autre cot ́e?", which means "- How do you get to the other side? - What side?". If this sounds like a bit of a stretch, consider this question in French: As-tu aller au cin ́ema?, or Did you go to the movies?, which literally translates as Have-you to go to movies/theater? "Brevet Sans Garantie Du Gouvernement", translated to English: "Patented without government warranty".
上面这段文本中,"Mentez mentez, il en restera toujours quelque chose," 是法语句子,"Lie lie and something will always remain." 是英文句子,而我们在无监督训练语言模型的时候,并没有告诉模型要做 translation 的任务,但是我们的文本中却有 which translates as 这样的字样。换句话说,这一与具体下游任务任务相关的信息,竟然可以通过具体下游任务任务无关的无监督预训练过程学习到。
3、使用prompt做下游任务
因为在 Zero-Shot 的任务设置下,没有这些带有开始符和结束符的文本给模型训练了,所以这时候做下游任务的时候也就不适合再给模型看开始符和结束符了。
大规模无监督训练过程学习到了任务相关的信息。作者认为:比如下游任务是英文翻译法文,那么如果模型在无监督预训练的过程中看过了引用的那一大段的文字 (这句话 "Mentez mentez, il en restera toujours quelque chose," which translates as, "Lie lie and something will always remain." 是训练的语料),那么模型就能够学会 (translate to french, english text, french text) 这样的下游任务。
也就是说,原则上,通过大量的语料训练,语言建模能够学习到一系列下游任务,而不需要明确的监督信息。为什么可以这么讲呢?因为作者认为:下游任务 (有监督训练) 可以视为预训练过程 (无监督训练) 的一个子集。无监督目标的全局最优解也是有监督训练的全局最优解。当预训练规模足够大时,把无监督的任务训练好了,有监督的下游任务即不再需要额外训练,就是所谓的 "Zero-Shot"。
所以下面的问题就变成了:在实践中,我们如何能够优化无监督预训练过程以达到收敛。初步实验证实,足够大的语言模型能够在无监督的预训练过程之后做下游任务,但学习速度比显式监督方法慢得多。
那么最后一个问题就是具体怎么去做下游任务呢?以英文翻译法文为例,我们需要在下游任务时预先告诉模型 "translate English to French",即给模型一个提示 (Prompt)。
五、一些资料
LLM 系列超详细解读 (二):GPT-2:GPT 在零样本多任务学习的探索 - 知乎本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者。专栏目录科技猛兽:多模态大模型超详细解读 (目录)本文目录1 GPT-2:GPT 在零样本多任务学习的探索 (来自 OpenAI) 1.1 背景和动机 1.2 大规模无…![]() https://zhuanlan.zhihu.com/p/616975731
https://zhuanlan.zhihu.com/p/616975731
相关文章:
GPT2:Language Models are Unsupervised Multitask Learners
目录 一、背景与动机 二、卖点与创新 三、几个问题 四、具体是如何做的 1、更多、优质的数据,更大的模型 2、大数据量,大模型使得zero-shot成为可能 3、使用prompt做下游任务 五、一些资料 一、背景与动机 基于 Transformer 解码器的 GPT-1 证明…...
微创新与稳定性的权衡
之前做过一个项目,业务最高峰CPU使用率也才50%,是一个IO密集型的应用。里面涉及一些业务编排,所以为了提高CPU使用率,我有两个方案:一个是简单的梳理将任务可并行的采用并行流、额外线程池等方式做并行;另外…...
对回调函数的各种讲解说明
有没有跟我师弟一样的童靴~,学习和使用ROS节点时,对其中的callback函数一直摸不着头脑的,以下这么多回调函数的讲解,挨个看,你总会懂的O.o 回调函数怎么调用,如何定义回调函数: 回调函数怎么调用,如何定义…...

Java多线程:创建多线程的三种方式
在Java中,有三种方式创建多线程,继承类Thread,继承接口Runnable,继承接口Callable。其中Thread和Runnable需要重写方法run,方法run没有返回值;Callable需要重写方法call,方法call可以返回值。 …...

Unity中打印信息的两种方式
不继承MonoBehaviour的普通C#类中打印信息: 使用Debug类的方法: Unity提供了Debug类,其中包含了一些用于打印信息的静态方法。以下是常用的几种方法: Debug.Log(message):打印普通信息。Debug.LogWarning(message)&a…...

给定n个字符串s[1...n], 求有多少个数对(i, j), 满足i < j 且 s[i] + s[j] == s[j] + s[i]?
题目 思路: 对于字符串a,b, (a.size() < b.size()), 考虑对字符串b满足什么条件: 由1、3可知a是b的前后缀,由2知b有一个周期是3,即a.size(),所以b是用多个a拼接而成的,有因为a是b的前后缀&…...

Linux磁盘空间与文件大小查看命令详解
1. 查看磁盘空间大小 在Linux系统中,有多个命令可以用来查看磁盘空间的使用情况。最常用的命令是df(disk free)。 df -hdf命令的 -h 选项以人类可读的方式显示磁盘空间,该命令将显示文件系统的使用情况、剩余空间等信息。 2. 查看…...
网络通信过程的一些基础问题
客户端A在和服务器进行TCP/IP通信时,发送和接收数据使用的是同一个端口吗? 这个问题可以这样来思考:在客户端A与服务器B建立连接时,A需要指定一个端口a向服务器发送数据。当服务器接收到A的报文时,从报文头部解析出A的…...
STL——stack容器和queue容器详解
目录 💡stack 💡基本概念 常用接口 💡queue 💡基本概念 💡常用接口 💡stack 💡基本概念 栈(stack):一种特殊的线性表,其只允许在固定的一端…...
django websocket实现聊天室功能
注意事项channel版本 django2.x 需要匹配安装 channels 2 django3.x 需要匹配安装 channels 3 Django3.2.4 channels3.0.3 Django3.2.* channels3.0.2 Django4.2 channles3.0.5 是因为最新版channels默认不带daphne服务器 直接用命令 python manage.py runsever 默认运行的是w…...

软件测评中心▏性能测试之压力测试、负载测试的区别和联系简析
在如今的信息时代,软件已经成为人们日常工作和生活不可或缺的一部分。然而,随着软件的发展和应用范围的不断扩大,软件性能的优劣也成为了影响用户使用体验的重要因素。 软件性能测试即对软件在不同条件下的性能进行评估和验证的过程。通过模…...

Go 语言 panic 和 recover 详解
panic() 和 recover() 是 Go 语言中用于处理错误的两个重要函数。panic() 函数用于中止程序并引发panic,而 recover() 函数用于捕获panic并恢复程序的执行。 什么是panic和recover? panic panic() 函数用于中止程序并引发panic。panic() 函数可以接收…...
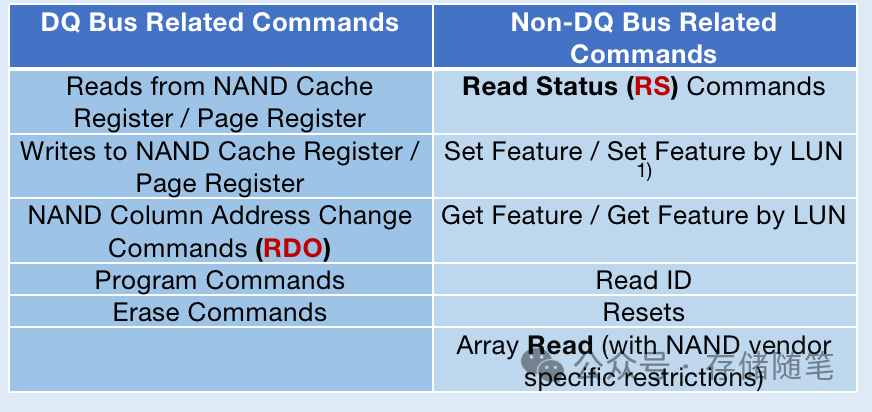
NAND Separate Command Address (SCA) 接口数据传输解读
在采用Separate Command Address (SCA) 接口的存储产品中,DQ input burst和DQ output burst又是什么样的策略呢? DQ Input Burst: 在读取操作期间,数据以一种快速并行的方式通过DQ总线传送到控制器。在SCA接口下,虽然命令和地址信…...

彻底认识Unity ui设计中Space - Overlay、Screen Space - Camera和World Space三种模式
文章目录 简述Screen Space - Overlay优点缺点 Screen Space - Camera优点缺点 World Space优点缺点 简述 用Unity中开发了很久,但是对unity UI管理中Canvas组件的Render Mode有三种主要类型:Screen Space - Overlay、Screen Space - Camera和World Spa…...

档案数字化怎样快速整理资料
对于机构和组织来说,档案数字化是一个重要的信息管理和保护措施。要快速整理资料进行档案数字化,可以遵循以下步骤: 1. 准备工具和设备:确保有一台计算机、扫描仪和相关软件。 2. 分类和组织资料:先将资料分类…...
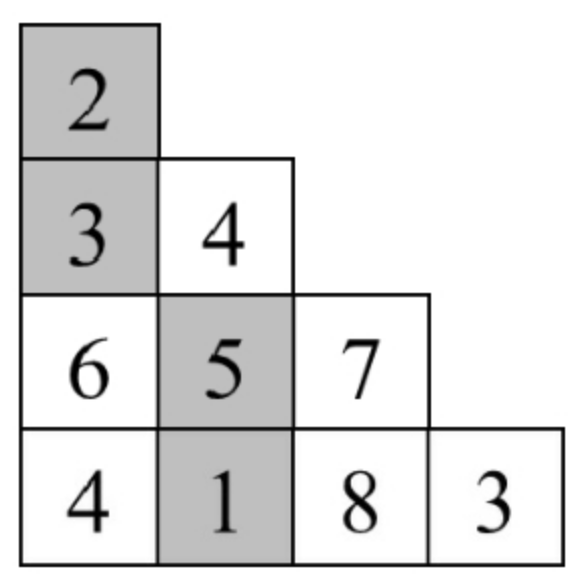
面试算法100:三角形中最小路径之和
题目 在一个由数字组成的三角形中,第1行有1个数字,第2行有2个数字,以此类推,第n行有n个数字。例如,下图是一个包含4行数字的三角形。如果每步只能前往下一行中相邻的数字,请计算从三角形顶部到底部的路径经…...
androj studio安装及运行源码
抖音教学视频 目录 1、 jdk安装 2、下载安装androj studio 3 、打开源码安装运行相关组件 4、 安装模拟器 1、 jdk安装 安卓项目也是java开发的,运行在虚拟机上,安装jdk及运行的时候,就会自动生成虚拟机, jdk前面已经讲过&…...

【Web】token机制
🍎个人博客:个人主页 🏆个人专栏:Web ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 机制基本: 优势: 结语 我的其他博客 前言 在当今互联网时代,安全、高效的用户身份验证和资源授…...

JVM 11 调优指南:如何进行JVM调优,JVM调优参数
JVM 11的优化指南:如何进行JVM调优,以及JVM调优参数有哪些”这篇文章将包含JVM 11调优的核心概念、重要性、调优参数,并提供12个实用的代码示例,每个示例都会结合JVM调优参数和Java代码 本文已收录于,我的技术网站 dd…...

横版动作闯关游戏:幽灵之歌 GHOST SONG 中文版
在洛里安荒凉的卫星上,一件长期休眠的死亡服从沉睡中醒来。踏上发现自我、古老谜团和宇宙骇物的氛围2D冒险之旅。探索蜿蜒的洞穴,获得新的能力来揭开这个外星世界埋藏已久的秘密。 游戏特点 发现地下之物 探索这个广阔而美丽如画,充满密室和诡…...

ChatGLM-6B真实反馈:用户对话满意度调查结果分享
ChatGLM-6B真实反馈:用户对话满意度调查结果分享 1. 引言:一次真实的对话体验调查 最近,我们围绕ChatGLM-6B智能对话服务进行了一次小范围的用户满意度调查。这不是一份冷冰冰的技术评测报告,而是一次真实的对话体验分享。我们邀…...

EMQX Dashboard 5.1新手指南:从安装到安全配置的完整流程
EMQX Dashboard 5.1新手指南:从安装到安全配置的完整流程 在物联网和实时消息传递领域,EMQX作为一款高性能的MQTT消息服务器,已经成为众多企业构建可靠物联网平台的首选。而EMQX Dashboard作为其内置的Web管理控制台,在5.1版本中迎…...

Linux服务器安装Linux宝塔面板并部署wordpress网站以及雷池WAF,设置禁止使用IP地址访问网站,只能使用域名访问网站
一、Linux服务器安装Linux宝塔面板 这个步骤参考网上其他教程。 二、Linux宝塔面板部署wordpress网站 这个步骤参考网上其他教程,保证网站能够正常访问,并且使用Linux宝塔面板申请并部署了SSL证书,使用https协议默认443端口正常访问网站。 三…...

当柔性车间遇上强化学习:从传统规则到DRL的调度进化史
柔性车间调度的智能革命:深度强化学习如何重塑制造业决策 在当今快节奏、定制化需求激增的制造业环境中,传统的生产调度方法正面临前所未有的挑战。想象一下,一个典型的电子设备制造车间:数百种不同规格的订单不断涌入,…...

主流开源License深度解析:从BSD到CC的适用场景与商业考量
1. 开源许可证的本质与核心价值 第一次接触开源许可证时,我和大多数人一样困惑:为什么明明是我的代码,却需要别人来告诉我怎么使用?后来在参与多个开源项目后才发现,许可证就像代码世界的交通规则,它不是为…...

3步精通Rufus:ext文件系统格式化实战攻略
3步精通Rufus:ext文件系统格式化实战攻略 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 在Linux系统管理中,USB设备格式化常常成为技术人员的痛点——要么工具功能单一&a…...

计算机毕设 java 基于 Java+Spring 的疫苗接种管理系统的设计与实现 智能疫苗接种预约系统 疫苗接种全流程管理平台
计算机毕设 java 基于 JavaSpring 的疫苗接种管理系统的设计与实现 69geq9(配套有源码 程序 mysql 数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联 xi 可分享在社会对公共卫生安全愈发重视的背景下,疫苗接种作为重要…...

WPF拖拽实战避坑指南:从DragDropEffects到QueryContinueDrag,解决拖拽后鼠标事件失效的诡异问题
WPF拖拽实战避坑指南:从DragDropEffects到QueryContinueDrag,解决拖拽后鼠标事件失效的诡异问题 当你在WPF项目中实现拖拽功能时,是否遇到过这样的场景:拖拽操作完成后,控件的MouseMove事件突然"失灵"&#…...

Open Webాలు架构设计:构建高性能自托管AI平台的工程实践
Open Webాలు架构设计:构建高性能自托管AI平台的工程实践 【免费下载链接】open-webui Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,设计用于完全离线操作,支持各种大型语言模型(LLM)运行器…...

Qwen All-in-One部署实战:极简依赖,快速搭建AI应用
Qwen All-in-One部署实战:极简依赖,快速搭建AI应用 1. 引言:轻量级AI服务的新选择 在当今AI应用遍地开花的时代,开发者们常常面临一个两难选择:要么使用功能强大但资源消耗巨大的模型,要么选择轻量级但功…...