MySQL夯实之路-查询性能优化深入浅出
MySQL调优分析
explain;show status查看服务器状态信息
优化
减少子任务,减少子任务执行次数,减少子任务执行时间(优,少,快)
查询优化分析方法
1.访问了太多的行和列:确认应用程序是否在检索大量超过需要的数据。这通常意味着访问了太多的行,但有时候也可能是访问了太多的列。
2.分析了太多的数据行:确认 MySQL服务器层是否在分析大量超过需要的数据行。
sql优化
1.减少查询的记录:使用select语句查询大量结果,然后再获取前N行(如新闻网站,取100条记录,只显示前面的10条;取最值),这时可以使用limit(limit 1,10;从1开始10行)
2.减少查询的列:不要总是SELECT *取出全部列,会额外消耗I/O、内存,CPU。
3.重复查询相同的数据:可以将数据缓存起来需要再取出
4.切分查询:有时需要将大查询切分为多个小查询。
删除旧数据:
定期地清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。将一个大的 DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL性能,同时还可以减少MySQL复制的延迟。
分解关联查询:


查询执行的基础
5.尽量用外连接代替子查询:通过测试来验证
6.尽量不要排序,文件排序很损耗性能,尽量使用索引排序。
7.尽量不要使用in,会导致全表扫描,可以用between
确定了查询只返回需要的数据后,看是否扫描了额外的数据
查询开销
对于MySQL,最简单的衡量查询开销的三个指标如下:
1.响应时间
2.扫描的行数
3.返回的行数


如果发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
1.使用索引覆盖扫描,把所有需要用的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果了。
2.改变库表结构。例如使用单独的汇总表。
3.重写这个复杂的查询,让 MySQL优化器能够以更优化的方式执行这个查询。
查询执行的过程
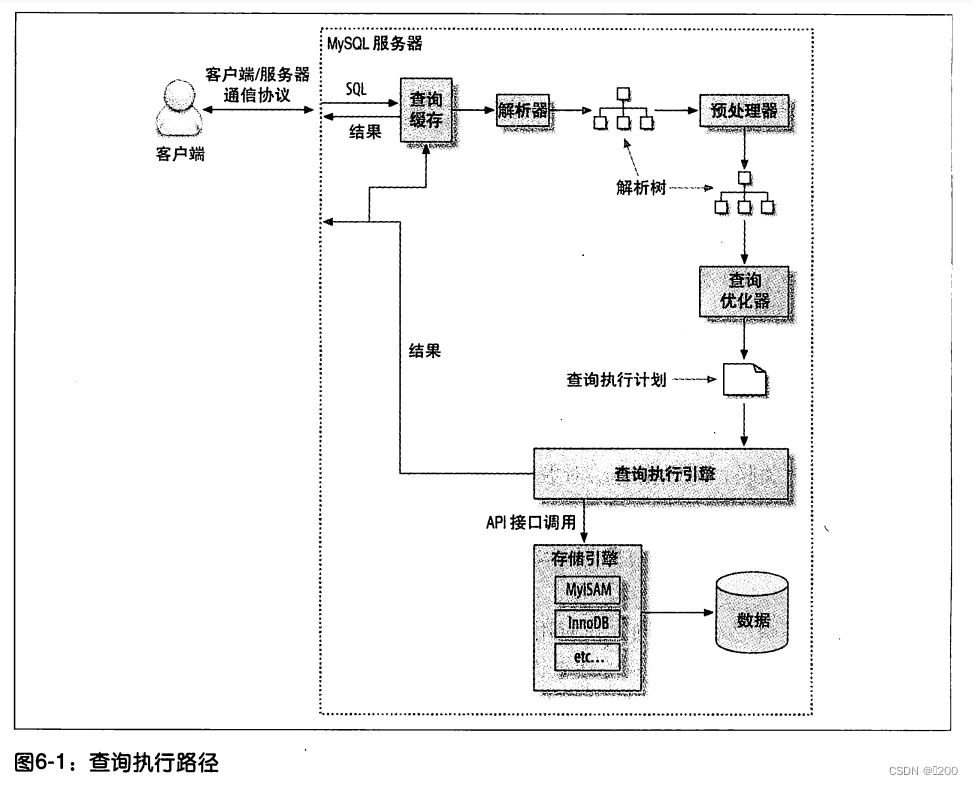
查询过程
1.客户端发送一条查询给服务器。
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则
进入下一阶段。
3.服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4. MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5.将结果返回给客户端。
Mysql客服端/服务端通信协议:
“半双工”的,同一时刻只能一方发送数据


查询状态
Show full processlist(返回结果的command列为当前状态)


查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据。这个检查是通过一个对大小写敏感的哈希查找实现的。查询和缓存中的查询即使只有一个字节不同,那也不会匹配缓存结果#",这种情况下查询就会进入下--阶段的处理。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前MySQL会检查一次用户权限。这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,MySQL会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
查询优化处理
查询的生命周期的下一步是将一个SQL转推成一个执行计划,MySQL再依照这个执行计划和存储引擎进行交互。这包括多个子阶段:解析SQL、预处理、优化SQL执行计划。这个过程中任何错误(例如语法错误)都可能终止查询。
语法解析器和预处理
首先,MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。例如,它将验证是否使用错误的关键字,或者使用关键字的顺序是否正确等,再或者它还会验证引号是否能前后正确匹配。
预处理器则根据一些MySQL规则进一步检查解析树是否合法,例如,这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。
下一步预处理器会验证权限。这通常很快,除非服务器上有非常多的权限配置。
查询优化器
现在语法树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。MySQL使用基于成本的优化器,它将尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。最初,成本的最小单位是随机读取一个4K数据页的成本,后来(成本计算公式)变得更加复杂,并且引入了一些“因子”来估算某些操作的代价,如当执行一次MERE条件比较的成本。可以通过查询当前会话的Last_query_cost的值来得知MySQL计算的当前查询的成本。
Mysql能处理的优化类型:
重新定义关联表的顺序,
将外连接转化为内连接,
使用等价变换规则,
优化count,min,max,
预估并转换为常数表达式,
覆盖索引扫描,
子查询优化
提前终止查询
等值传播
列表in()的比较
执行关联查询
当前MySQL关联执行的策略很简单:MySQL对任何关联都执行嵌套循环关联操作,即MySQL先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。MySQL会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行以后,MySQL返回到上一层次关联表,看是否能够找到更多的匹配记录,依此类推迭代执行。
关于MylSAM的神话
MyISAM的COUNT()函数总是非常快,不过这是有前提条件的,即只有没有任何WHERE条件的COUNT(*)才非常快,因为此时无须实际地去计算表的行数。MySQL可以利用存储引擎的特性直接获得这个值。如果 MySQL 知道某列col不可能为NULL值,那么MySQL内部会将COUNT(col)表达式优化为COUNT(*)。


优化关联查询

使用用户自定义变量


相关文章:
MySQL夯实之路-查询性能优化深入浅出
MySQL调优分析 explain;show status查看服务器状态信息 优化 减少子任务,减少子任务执行次数,减少子任务执行时间(优,少,快) 查询优化分析方法 1.访问了太多的行和列࿱…...

UniApp面试题
面试题1 问:什么是 UniApp?它有哪些特点? 答:UniApp 是一种基于 Vue.js 开发跨平台应用的框架。它可以同时构建运行在多个平台(包括但不限于小程序、H5、App)的应用程序。UniApp 的特点包括:一…...

30 树的定义
树的定义 树的度?叶节点? 注意:k为叶节点 孩子/双亲/子孙/祖先 树的高度? 有序树 森林 树的一些操作: 粗略的框架代码: 省略。。。 小结: 树是线性表的扩展...

程序员必备的面试技巧
程序员必备的面试技巧 “程序员必备的面试技巧,就像是编写一段完美的代码一样重要。在面试战场上,我们需要像忍者一样灵活,像侦探一样聪明,还要像无敌铁金刚一样坚定。只有掌握了这些技巧,我们才能在面试的舞台上闪耀…...
【NI-DAQmx入门】LabVIEW中DAQmx同步
1.同步解释 1.1 同步基础概念 触发器:触发器是控制采集的命令。您可以使用触发器来启动、停止或暂停采集。触发信号可以源自软件或硬件源。 时钟:时钟是用于对数据采集计时的周期性数字信号。根据具体情况,您可以使用时钟信号直接控制数据采…...

FlinkRestAPI
which flink 找到Flink客户端地址 如果输出结果为空,则说明 Flink 客户端没有安装在系统路径中。在这种情况下,您可以通过设置 FLINK_HOME 环境变量来指定 Flink 客户端的路径。例如: export FLINK_HOME/opt/flink 然后,您可以使…...

Qt获取当前系统网络接口信息
1.QInterface获取网络接口信息 void NetProperty::init() {// 获取所有网络接口const QList<QNetworkInterface> interfaces QNetworkInterface::allInterfaces();ui->com_Interface->clear();for(const QNetworkInterface& interface : interfaces){ui->…...
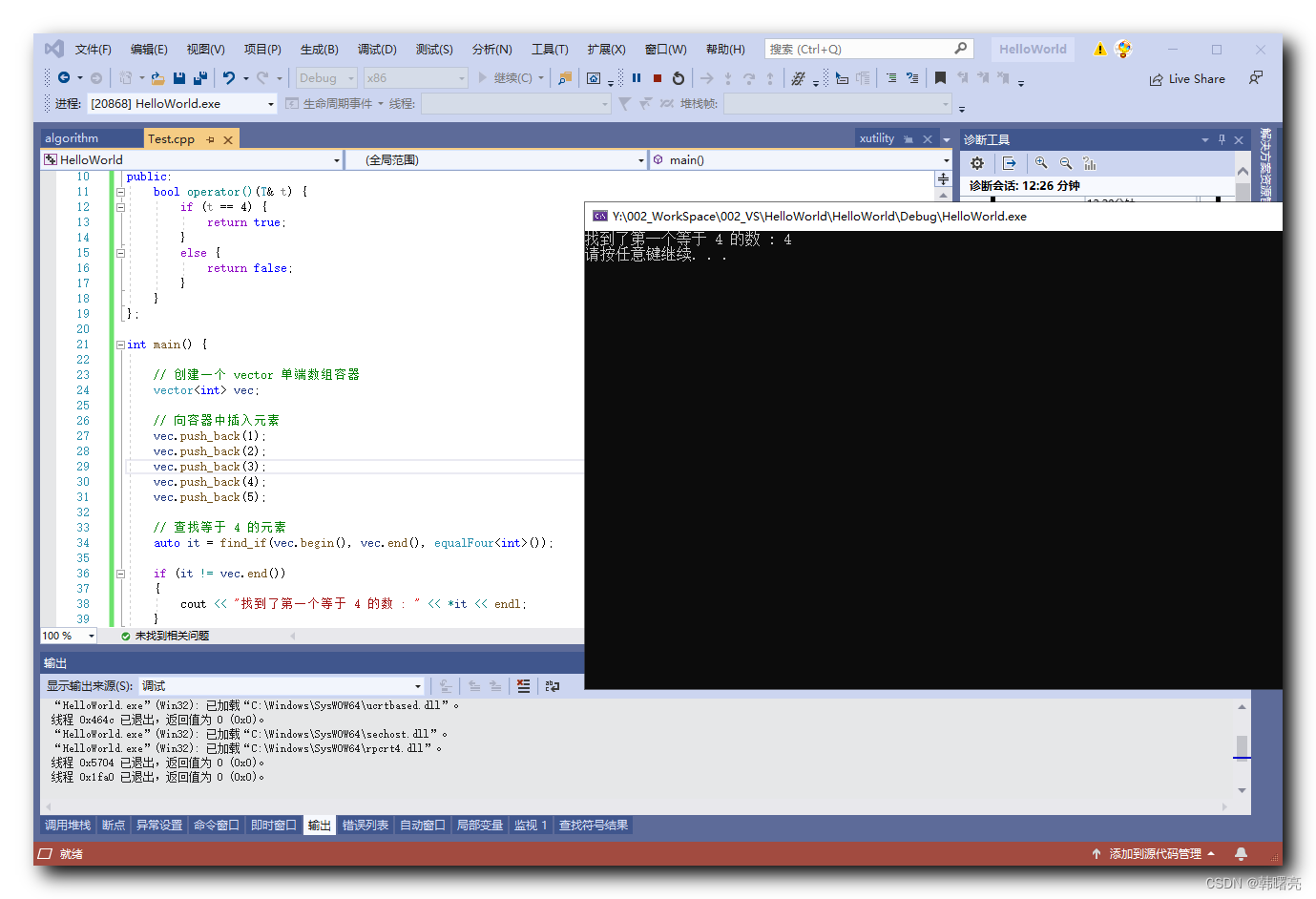
【C++】STL 算法 ④ ( 函数对象与谓词 | 一元函数对象 | “ 谓词 “ 概念 | 一元谓词 | find_if 查找算法 | 一元谓词示例 )
文章目录 一、函数对象与谓词1、一元函数对象2、" 谓词 " 概念3、find_if 查找算法 二、一元谓词示例1、代码示例 - 一元谓词示例2、执行结果 一、函数对象与谓词 1、一元函数对象 " 函数对象 " 是通过 重载 函数调用操作符 () 实现的 operator() , 函数对…...

C++ 并发编程 | 并发世界
一、C 并发世界 1、什么是并发? 并发是指两个或更多独立的活动同时发生,计算机中的并发指的是,在单个系统里同时执行多个独立的活动...

GitHub注册新账号的操作流程(详细)
目录 第一步 进入官网,点击右上角的"Sign up" 第二步 输入email地址 第三步 设置密码 第四步 输入昵称 第五步 根据个人喜好决定要不要接收GitHub的邮件推送。然后回答他们的验证问题 第六步 输入验证码 我在注册github账号时遇到过一些阻碍&#x…...

Kali安装Xrdp结合内网穿透实现无公网ip远程访问系统桌面
文章目录 前言1. Kali 安装Xrdp2. 本地远程Kali桌面3. Kali 安装Cpolar 内网穿透4. 配置公网远程地址5. 公网远程Kali桌面连接6. 固定连接公网地址7. 固定地址连接测试 前言 Kali远程桌面的好处在于,它允许用户从远程位置访问Kali系统,而无需直接物理访…...

【WEB API自动化测试】接口文档与在线测试
这一篇我们主要介绍如何做API帮助文档,给API的调用人员介绍各个 API的功能, 输入参数,输出参数, 以及在线测试 API功能(这个也是方便我们自己开发调试) 我们先来看看我们的API最终帮助文档及在线测试最终达到的效果: 概要图 GET API 添加产品API: 删除…...

【深度学习每日小知识】Training Data 训练数据
训练数据是机器学习的基本组成部分,在模型的开发和性能中起着至关重要的作用。它是指用于训练机器学习算法的标记或注释数据集。以下是与训练数据相关的一些关键方面和注意事项。 Quantity 数量 训练数据的数量很重要,因为它会影响模型的泛化能力。通常…...

[acm算法学习] 后缀数组SA
学习自B站up主 kouylan 定义 后缀是包含最后个字母的子串 把字符串 str 的所有后缀按字典排序,sa[i]表示排名为 i 的后缀的开头下标 如何求解SA 倍增的方法 先把每个位置开始的长度为1的子串排序,在此基础上再把长度为2的子串排序(长度…...

DNS解析和它的三个实验
一、DNS介绍 DNS:domain name server 7层协议 名称解析协议 tcp /53 主从之间的同步 udp/53 名字解析 DNS作用:将域名转换成IP地址的协议 1.1DNS的两种实现方式 1.通过hosts文件(优先级最高) 分散的管理 linux /etc/hos…...
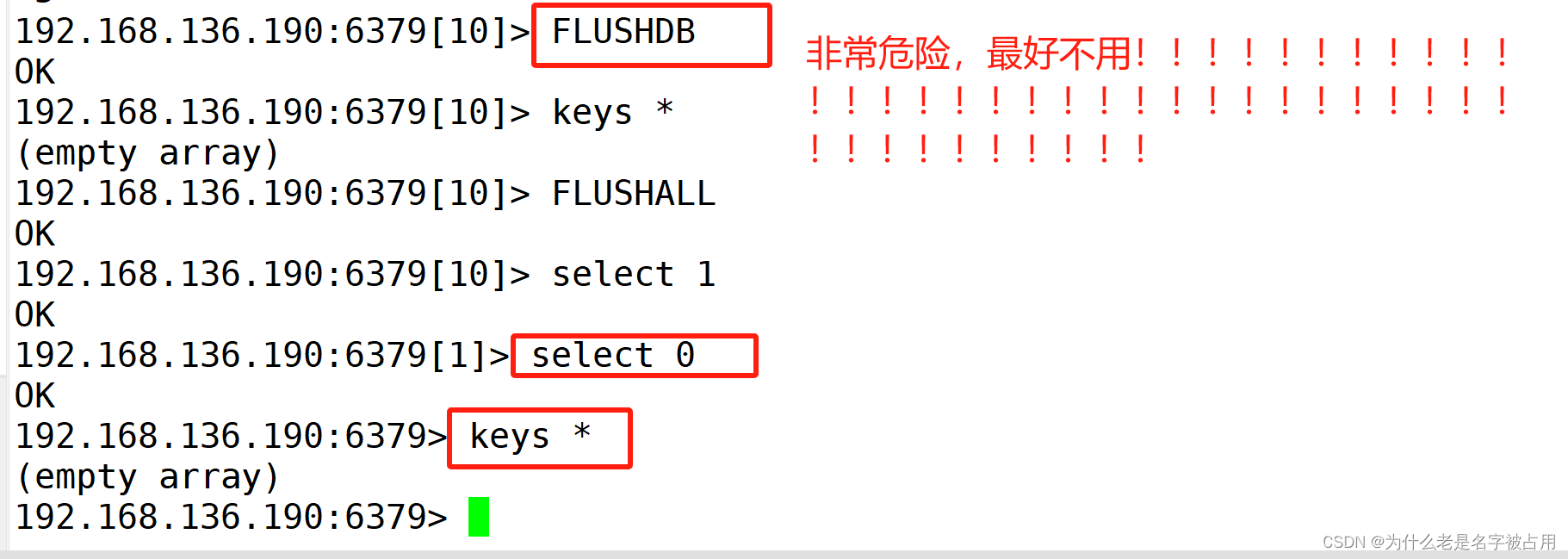
[redis] redis的安装,配置与简单操作
一、缓存的相关知识 1.1 缓存的概念 缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且…...

C++ STL set容器
和 map、multimap 容器不同,使用 set 容器存储的各个键值对,要求键 key 和值 value 必须相等。 举个例子,如下有 2 组键值对数据: {<a, 1>, <b, 2>, <c, 3>} {<a, a>, <b, b>, <c, c>} 显然&…...

专业课148,总分410+电子科技大学858信号与系统考研经验电子信息与通信
今年专业课148分,总分410顺利被电子科技大学录取,回望这一年复习还有很多不足,总结一下自己的复习经历,希望对大家复习有所帮助。 数学:(多动手,多计算,多总结,打好基础…...
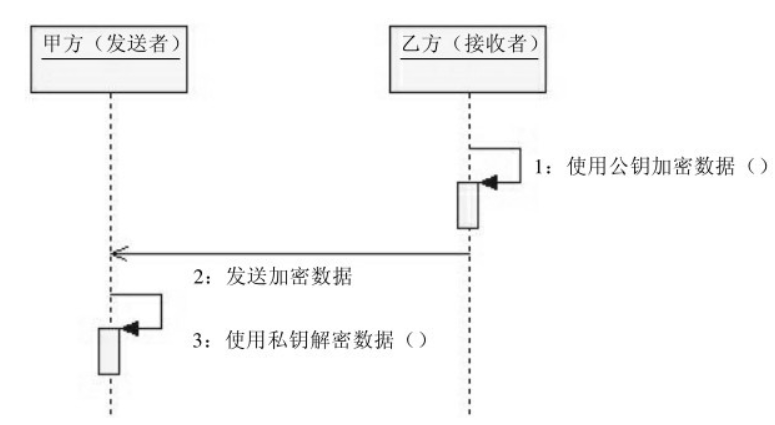
密码学:一文读懂非对称加密算法 DH、RSA
文章目录 前言非对称加密算法的由来非对称加密算法的家谱1.基于因子分解难题2.基于离散对数难题 密钥交换算法-DH密钥交换算法-DH的通信模型初始化DH算法密钥对甲方构建DH算法本地密钥乙方构建DH算法本地密钥DH算法加密消息传递 典型非对称加密算法-RSARSA的通信模型RSA特有的的…...

ZooKeeper 实战(二) 命令行操作篇
文章目录 ZooKeeper 实战(二) 命令行操作篇1. 服务端命令1.1. 服务启动1.2. 查看服务1.3. 重启服务1.4. 停止服务 2. 客户端命令2.1. 启动客户端2.2. 查看节点信息查看根节点详情 ls -s /添加一个watch监视器 ls -w /列举出节点的级联节点 ls -R / 2.3. 查看节点状态2.4. 创建节…...

FLUX.1-dev实战教程:像素幻梦中多LoRA叠加与风格混合生成技巧
FLUX.1-dev实战教程:像素幻梦中多LoRA叠加与风格混合生成技巧 1. 像素幻梦工坊简介 Pixel Dream Workshop(像素幻梦工坊)是基于FLUX.1-dev扩散模型构建的专业像素艺术生成工具。与传统AI绘图工具不同,它专为像素艺术创作优化&am…...

vue3-count-to避坑指南:数字增长动画的7个常见问题与解决方案
Vue3-Count-To深度避坑实战:数字动画7大疑难解析 数字动态增长效果在数据可视化、金融仪表盘和运营数据展示中扮演着关键角色。vue3-count-to作为Vue3生态中专精于此的轻量级库,虽然API简洁,但在真实业务场景中往往会遇到各种边界情况。本文将…...

NaViL-9B部署实操手册:supervisor服务管理+日志排查全流程详解
NaViL-9B部署实操手册:supervisor服务管理日志排查全流程详解 1. 平台简介 NaViL-9B是原生多模态大语言模型,支持纯文本问答和图片理解功能。该模型采用双24GB显卡配置,已预处理好模型权重和注意力机制兼容性问题,开箱即用。 2.…...

AI Agent 的动态知识更新:保持 LLM 知识的实时性
AI Agent 的动态知识更新:保持 LLM 知识的实时性 关键词:AI Agent、动态知识更新、大语言模型(LLM)、实时性、知识图谱 摘要:本文聚焦于 AI Agent 的动态知识更新,旨在探讨如何保持大语言模型(LLM)知识的实时性。首先介绍了相关背景,包括目的、预期读者等。接着阐述了…...

天津专业的阀门厂排名
在天津,阀门行业发展态势良好,众多阀门厂各有特色与优势。中国通用机械工业协会最新发布的《2026年阀门行业高质量发展白皮书》显示,天津的阀门产业在技术创新、产品质量和市场份额等方面都有不错的表现。下面为大家介绍几家天津比较知名的阀…...

AI 模型推理框架性能分析与对比
AI模型推理框架性能分析与对比 随着人工智能技术的快速发展,AI模型推理框架成为支撑各类应用落地的核心工具。无论是计算机视觉、自然语言处理还是推荐系统,高效的推理框架直接影响模型的响应速度、资源占用和部署成本。本文将从多个维度对比主流AI推理…...

从C语言到裸机运行:i.MX6ULL 的 GPIO 控制与编译链接过程分析
引言在嵌入式系统开发中,从高级语言到硬件控制的完整链路涉及编译、链接、寄存器配置等多个环节。本文基于 i.MX6ULL 平台,以 C 语言实现 LED 与蜂鸣器控制为例,系统分析 ARM 裸机开发中的编译工具链使用、链接脚本的作用,以及 GP…...

避坑指南:Xdocreport模板制作中的5个常见错误及解决方案
Xdocreport实战避坑指南:模板制作中的5个高频错误与深度解决方案 在Java生态中处理动态Word文档生成时,Xdocreport凭借其与MS Office的无缝兼容性和模板灵活性,已成为企业级文档自动化的重要工具。但许多开发者在从Freemarker迁移到Xdocrepor…...

Linux文件系统架构与缓存机制解析
Linux文件系统架构与缓存机制深度解析1. 文件系统核心架构1.1 文件系统基本组织形式Linux文件系统采用分层结构设计,主要包含以下核心组件:块存储机制:硬盘被划分为固定大小的块(默认4KB),文件数据分散存储…...

告别杂乱农场:星露谷物语规划神器助你打造高效田园
告别杂乱农场:星露谷物语规划神器助你打造高效田园 【免费下载链接】stardewplanner Stardew Valley farm planner 项目地址: https://gitcode.com/gh_mirrors/st/stardewplanner 你是否曾在星露谷物语中面对一片荒地感到无从下手?种植区域混乱、…...