深度探讨 Golang 中并发发送 HTTP 请求的最佳技术
- 💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】
- 🤟 基于Web端打造的:👉轻量化工具创作平台
- 💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】

在 Golang 领域,并发发送 HTTP 请求是优化 Web 应用程序的一项重要技能。本文探讨了实现此目的的各种方法,从基本的 goroutine 到涉及通道和sync.WaitGroup 的高级技术。我们将深入研究并发环境中性能和错误处理的最佳实践,为你提供提高 Go 应用程序速度和可靠性的策略。让我们深入探讨 Golang 中并发 HTTP 请求的世界!
使用 Goroutines 的基本方法
当谈到在 Golang 中实现并发时,最直接的方法是使用 goroutine。这些是 Go 中并发的构建块,提供了一种简单而强大的并发执行函数的方法。
Goroutine 入门
要启动一个 goroutine,只需在函数调用前加上go关键字即可。这会将函数作为 goroutine 启动,从而允许主程序继续独立运行。这就像开始一项任务并继续前进而不等待它完成。
例如,考虑发送 HTTP 请求的场景。通常,你会调用类似 的函数sendRequest(),并且你的程序将等待该函数完成。使用 goroutine,你可以同时执行此操作:
go sendRequest("http://example.com")
处理多个请求
假设你有一个 URL 列表,并且需要向每个 URL 发送一个 HTTP 请求。如果没有 goroutine,你的程序将一个接一个地发送这些请求,这非常耗时。使用 goroutine,你几乎可以同时发送它们:
urls := []string{"http://example.com", "http://another.com", ...}
for _, url := range urls {
go sendRequest(url)
}
这个循环为每个 URL 启动一个新的 goroutine,大大减少了程序发送所有请求所需的时间。
并发 HTTP 请求的方法
在本节中,我们将深入研究在 Go 中并发处理 HTTP 请求的各种方法。每种方法都有其独特的特点,了解这些可以帮助你选择适合特定需求的正确方法。
我们使用 insrequester 包(开源请求程序)来处理本文中提到的 HTTP请求
基本 Goroutine
在 Go 中并发发送 HTTP 请求的最简单方法是使用 goroutine。Goroutines 是由 Go 运行时管理的轻量级线程。这是一个基本示例:
requester := insrequester.NewRequester().Load() urls := []string{"http://example.com", "http://example.org", "http://example.net"}
for _, url := range urls {
go requester.Get(insrequester.RequestEntity{Endpoint: url})
} time.Sleep(2 * time.Second) // 等待 goroutine 完成
这种方法很简单,但一旦启动就缺乏对 goroutine 的控制。通过这种方式无法获取Get方法的返回值。你需要睡眠大约一段时间来等待所有 goroutine。即使你调用 sleep,你可能仍然不确定它们是否完成。
WaitGroup
为了改进基本的 goroutine,sync.WaitGroup可用于更好的同步。它等待 goroutine 集合完成执行:
requester := insrequester.NewRequester().Load()
wg := sync.WaitGroup{} urls := []string{"http://example.com", "http://example.org", "http://example.net"}
wg.Add(len(urls)) for _, url := range urls {
go requester.Get(insrequester.RequestEntity{Endpoint: url})
} wg.Wait() //等待所有要完成的 goroutine
这确保了 main 函数等待所有 HTTP 请求完成。
Channels
Channels 是 Go 中用于 goroutine 之间通信的强大功能。它们可用于从多个 HTTP 请求收集数据:
requester := insrequester.NewRequester().Load() urls := []string{"http://example.com", "http://example.org", "http://example.net"}
ch := make(chan string, len(urls)) for _, url := range urls {
go func() {
res, _ := requester.Get(insrequester.RequestEntity{Endpoint: url})
ch <- fmt.Sprintf("%s: %d", url, res.StatusCode)
}()
} for range urls {
response := <-ch
fmt.Println(response)
}
通道不仅可以同步 goroutine,还可以促进它们之间的数据传递。
Worker Pools
Worker Pool 是一种模式,其中创建固定数量的工作人员(goroutines)来处理可变数量的任务。这有助于限制并发 HTTP 请求的数量,从而防止资源耗尽。
以下是在 Go 中实现 Worker Pool 的方法:
// 定义 Job 结构体,包含一个 URL 字段
type Job struct {URL string
}// worker 函数用于处理作业,接收请求者、作业通道、结果通道和等待组作为参数
func worker(requester *insrequester.Request, jobs <-chan Job, results chan<- *http.Response, wg *sync.WaitGroup) {for job := range jobs {// 使用请求者获取 URL 对应的响应res, _ := requester.Get(insrequester.RequestEntity{Endpoint: job.URL})// 将结果发送到结果通道,并减少等待组计数results <- reswg.Done()}
}func main() {// 创建并加载请求者requester := insrequester.NewRequester().Load()// 定义要处理的 URL 列表urls := []string{"http://example.com", "http://example.org", "http://example.net"}// 定义工作池中的工作者数量numWorkers := 2// 创建作业通道和结果通道jobs := make(chan Job, len(urls))results := make(chan *http.Response, len(urls))var wg sync.WaitGroup// 启动工作者for w := 0; w < numWorkers; w++ {go worker(requester, jobs, results, &wg)}// 将作业发送到工作者池wg.Add(len(urls))for _, url := range urls {jobs <- Job{URL: url}}close(jobs)wg.Wait()// 收集结果并输出for i := 0; i < len(urls); i++ {fmt.Println(<-results)}
}使用工作池可以让你有效地管理大量并发 HTTP 请求。它是一个可扩展的解决方案,可以根据工作负载和系统容量进行调整,从而优化资源利用率并提高整体性能。
使用通道限制 Goroutine
该方法使用通道创建类似信号量的机制来限制并发 goroutine 的数量。它在你需要限制 HTTP 请求以避免服务器不堪重负或达到速率限制的情况下非常有效。
以下是实现它的方法:
// 创建请求者并加载配置
requester := insrequester.NewRequester().Load()// 定义要处理的 URL 列表
urls := []string{"http://example.com", "http://example.org", "http://example.net"}
maxConcurrency := 2 // 限制并发请求的数量// 创建一个用于限制并发请求的通道
limiter := make(chan struct{}, maxConcurrency)// 遍历 URL 列表
for _, url := range urls {limiter <- struct{}{} // 获取一个令牌。在这里等待令牌从限制器释放go func(url string) {defer func() { <-limiter }() // 释放令牌// 使用请求者进行 POST 请求requester.Post(insrequester.RequestEntity{Endpoint: url})}(url)
}// 等待所有 goroutine 完成
for i := 0; i < cap(limiter); i++ {limiter <- struct{}{}
}
在这种情况下使用延迟至关重要。如果将 <-limiter语句放在 Post 方法之后,并且 Post 方法触发恐慌或类似异常,则 <-limiter行将不会被执行。这可能会导致无限等待,因为信号量令牌永远不会被释放,最终导致超时问题。
使用信号量限制 Goroutines
sync/semaphore 包提供了一种干净有效的方法来限制并发运行的 goroutine 数量。当你想要更系统地管理资源分配时,此方法特别有用。
// 创建请求者并加载配置
requester := insrequester.NewRequester().Load()// 定义要处理的 URL 列表
urls := []string{"http://example.com", "http://example.org", "http://example.net"}
maxConcurrency := int64(2) // 设置最大并发请求数量// 创建一个带权重的信号量
sem := semaphore.NewWeighted(maxConcurrency)
ctx := context.Background()// 遍历 URL 列表
for _, url := range urls {// 在启动 goroutine 前获取信号量权重if err := sem.Acquire(ctx, 1); err != nil {fmt.Printf("无法获取信号量:%v\n", err)continue}go func(url string) {defer sem.Release(1) // 在完成时释放信号量权重// 使用请求者获取 URL 对应的响应res, _ := requester.Get(insrequester.RequestEntity{Endpoint: url})fmt.Printf("%s: %d\n", url, res.StatusCode)}(url)
}// 等待所有 goroutine 释放它们的信号量权重
if err := sem.Acquire(ctx, maxConcurrency); err != nil {fmt.Printf("等待时无法获取信号量:%v\n", err)
}
与手动管理通道相比,这种使用信号量包的方法提供了一种更加结构化和可读的并发处理方式。当处理复杂的同步要求或需要更精细地控制并发级别时,它特别有用。
那么,最好的方法是什么?
在探索了 Go 中处理并发 HTTP 请求的各种方法之后,问题出现了:最好的方法是什么?正如软件工程中经常出现的情况一样,答案取决于应用程序的具体要求和约束。让我们考虑确定最合适方法的关键因素:
评估你的需求
- 请求规模:如果你正在处理大量请求,工作池或基于信号量的方法可以更好地控制资源使用。
- 错误处理:如果强大的错误处理至关重要,那么使用通道或信号量包可以提供更结构化的错误管理。
- 速率限制:对于需要遵守速率限制的应用程序,使用通道或信号量包限制 goroutine 可能是有效的。
- 复杂性和可维护性:考虑每种方法的复杂性。虽然渠道提供了更多控制,但它们也增加了复杂性。另一方面,信号量包提供了更直接的解决方案。
错误处理
由于 Go 中并发执行的性质,goroutines 中的错误处理是一个棘手的话题。由于 goroutine 独立运行,管理和传播错误可能具有挑战性,但对于构建健壮的应用程序至关重要。以下是一些有效处理并发 Go 程序中错误的策略:
集中误差通道
一种常见的方法是使用集中式错误通道,所有 goroutine 都可以通过该通道发送错误。然后,主 goroutine 可以监听该通道并采取适当的操作。
func worker(errChan chan<- error) {// 执行任务if err := doTask(); err != nil {errChan <- err // 将任何错误发送到错误通道}
}func main() {errChan := make(chan error, 1) // 用于存储错误的缓冲通道go worker(errChan)if err := <-errChan; err != nil {// 处理错误log.Printf("发生错误:%v", err)}
}
或者你可以在不同的 goroutine 中监听 errChan。
func worker(errChan chan<- error, job Job) {// 执行任务if err := doTask(job); err != nil {errChan <- err // 将任何错误发送到错误通道}
}func listenErrors(done chan struct{}, errChan <-chan error) {for {select {case err := <-errChan:// 处理错误case <-done:return}}
}func main() {errChan := make(chan error, 1000) // 存储错误的通道done := make(chan struct{}) // 用于通知 goroutine 停止的通道go listenErrors(done, errChan)for _, job := range jobs {go worker(errChan, job)}// 等待所有 goroutine 完成(具体方式需要根据代码的实际情况进行实现)done <- struct{}{} // 通知 goroutine 停止监听错误
}
Error Group
golang.org/x/sync/errgroup 包提供了一种便捷的方法来对多个 goroutine 进行分组并处理它们产生的任何错误。errgroup.Group确保一旦任何 goroutine 发生错误,所有后续操作都将被取消。
import "golang.org/x/sync/errgroup"func main() {g, ctx := errgroup.WithContext(context.Background())urls := []string{"http://example.com", "http://example.org"}for _, url := range urls {// 为每个 URL 启动一个 goroutineg.Go(func() error {// 替换为实际的 HTTP 请求逻辑_, err := fetchURL(ctx, url)return err})}// 等待所有请求完成if err := g.Wait(); err != nil {log.Printf("发生错误:%v", err)}
}
这种方法简化了错误处理,特别是在处理大量 goroutine 时。
包装 Goroutine
另一种策略是将每个 goroutine 包装在一个处理其错误的函数中。这种封装可以包括从恐慌或其他错误管理逻辑中恢复。
func work() error {// 进行一些工作return err
}func main() {go func() {err := work()if err != nil {// 处理错误}}()// 等待工作完成的某种方式
}
综上所述,Go 并发编程中错误处理策略的选择取决于应用程序的具体要求和上下文。无论是通过集中式错误通道、专用错误处理 goroutine、使用错误组,还是将 goroutine 包装在错误管理函数中,每种方法都有自己的优点和权衡。
总结
总之,本文探讨了在 Golang 中并发发送 HTTP 请求的各种方法,这是优化 Web 应用程序的一项关键技能。我们已经讨论了基本的 goroutine、sync.WaitGroup、通道、工作池以及限制 goroutine 的方法。每种方法都有其独特的特点,可以根据特定的应用要求进行选择。
此外,本文还强调了并发 Go 程序中错误处理的重要性。管理并发环境中的错误可能具有挑战性,但对于构建健壮的应用程序至关重要。已经讨论了使用集中式错误通道、errgroup 包或使用错误处理逻辑包装 goroutine 等策略来帮助开发人员有效地处理错误。
最终,在 Go 中处理并发 HTTP 请求的最佳方法的选择取决于请求规模、错误处理要求、速率限制以及代码的整体复杂性和可维护性等因素。开发人员在应用程序中实现并发功能时应仔细考虑这些因素。
⭐️ 好书推荐
《Go专家编程(第2版)》

【内容简介】
本书深入地讲解了Go语言常见特性的内部机制和实现方式,大部分内容源自对Go源码的分析,并从中提炼出实现原理。通过阅读本书,读者可以快速、轻松地了解Go语言的内部运作机制。
本书首先介绍常见数据结构及控制结构的实现原理,包括管道、切片、Hash表、select 和 for-range 等,这部分内容大都以几个精心准备的测验题目开头,每个测验题目均对应一个知识点,读者借此可以测验自身对该知识点的掌握程度。接着介绍了Go语言最核心的概念,包括协程的概念、协程调度模型、协程调度策略,以及内存分配和垃圾回收相关的内容。本书还介绍了测试、泛型、依赖管理等比较实用的特性。最后结合笔者的见闻,整理了一些发生在真实项目中的编程陷阱。
📚 京东购买链接:《Go专家编程(第2版)》
相关文章:
深度探讨 Golang 中并发发送 HTTP 请求的最佳技术
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】 在 Golang 领域,并发发送 HTTP 请求…...
)
VUE指令(二)
vue会根据不同的指令,针对不同的标签实现不同的功能。指令是带有 v- 前缀的特殊标签属性。指令的职责是,当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM。 8、v-for:基于数据循环,多次渲染整个…...
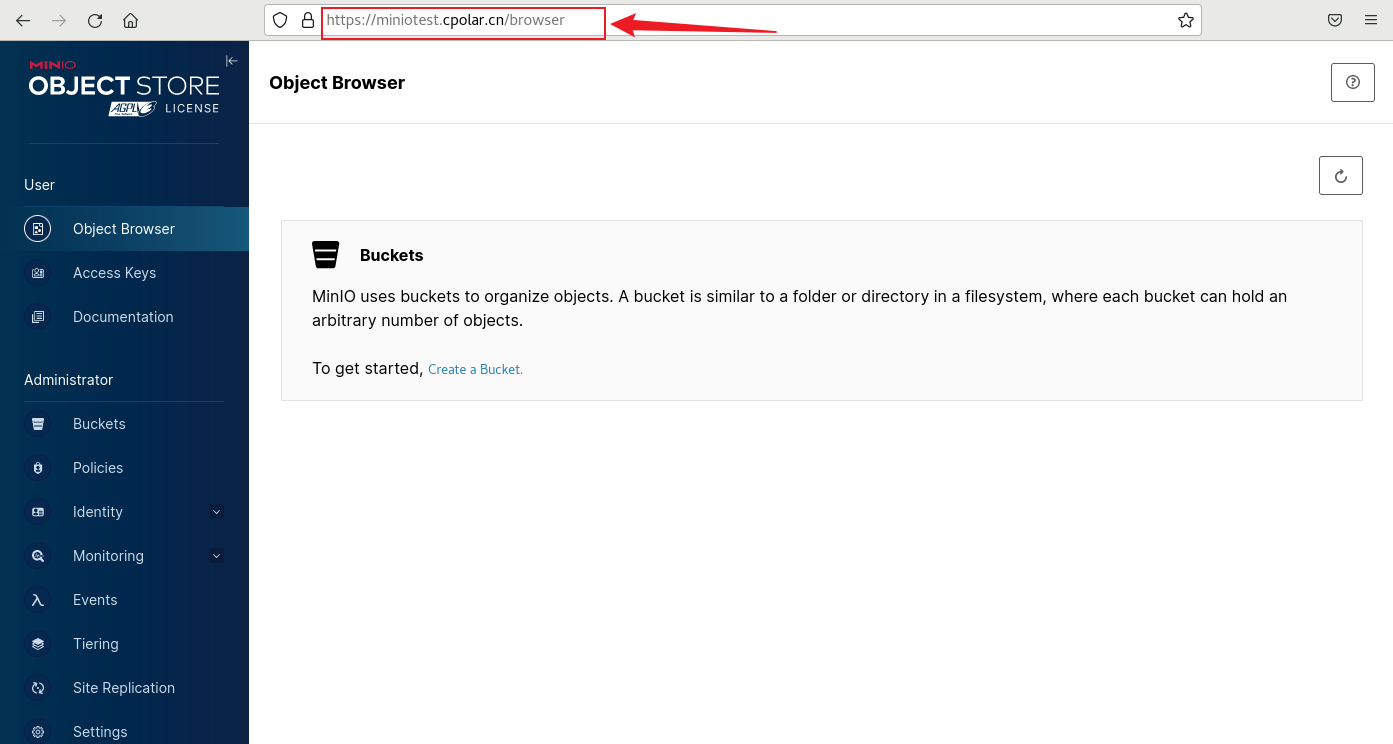
开源对象存储服务器MinIO本地部署并结合内网穿透实现远程访问管理界面
文章目录 前言1. Docker 部署MinIO2. 本地访问MinIO3. Linux安装Cpolar4. 配置MinIO公网地址5. 远程访问MinIO管理界面6. 固定MinIO公网地址 前言 MinIO是一个开源的对象存储服务器,可以在各种环境中运行,例如本地、Docker容器、Kubernetes集群等。它兼…...
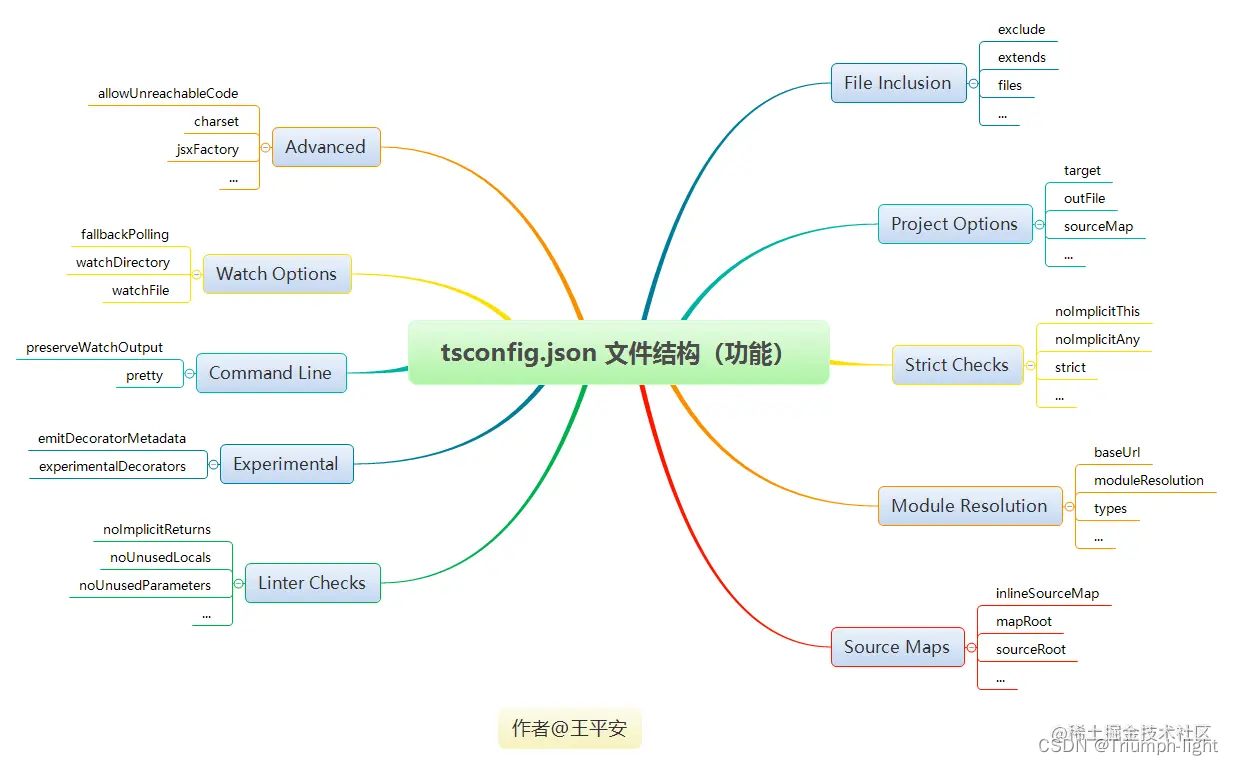
【TypeScript】tsconfig.json文件到底是干啥的?作用是什么?
参考学习博文: 掌握tsconfig.json 一、tsconfig.json简介 1、tsconfig.json是什么? TypeScript 使用 tsconfig.json 文件作为其配置文件,当一个目录中存在 tsconfig.json 文件,则认为该目录为 TypeScript 项目的根目录。 通常…...

wagtail的数据模型和渲染
文章目录 前言页面数据模型数据库字段部分搜索部分编辑面板基础面板结构化面板父页面/子页面类型规则页面URLs自定义页面模型的URL模式获取页面实例的URL 模板渲染为页面模型添加模板模板上下文自定义模板上下文更改模板动态选择模板Ajax 模板 内联模型在多个页面类型之间重用内…...
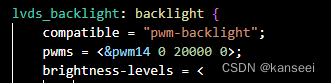
OpenHarmony4.0适配LVDS屏幕驱动
1.概述 手头有一块RK3568的开发板OK3568-C,但是还没有适配OpenHarmony,用的还是LVDS屏幕,但是官方和网上好像还没有OpenHarmony4.0的LVDS屏幕驱动的通用实现,所以决定尝试了一下适配该开发板,完成LVDS屏幕驱动的适配&…...

【playwright】新一代自动化测试神器playwright+python系列课程01-playwright驱动浏览器
Playwright驱动浏览器 安装 Playwright 时,Playwright默认自动安装了三种浏览器(Chromium、Firefox 和 WebKit)。我们可以驱动这三种浏览器中的任意一种。 使用with上下文管理器 启动chromium浏览器 python # # author: 测试-老姜 交流…...
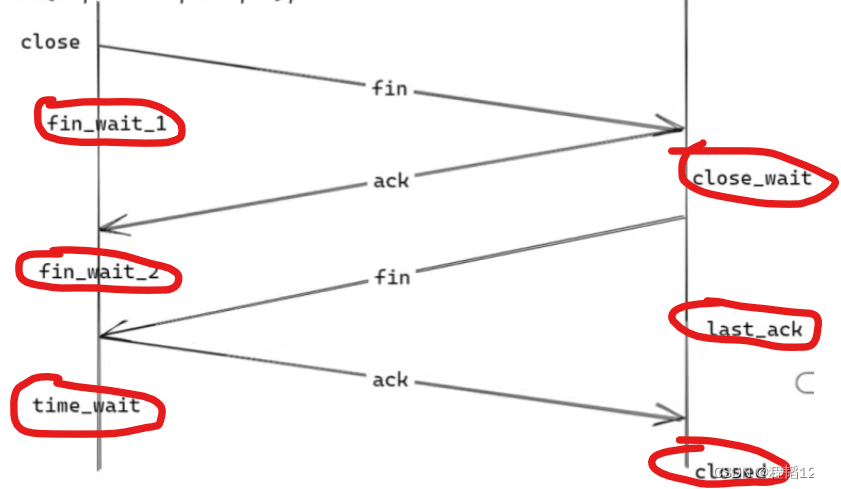
POSIX API与网络协议栈
本文介绍linux中与tcp网络通信相关的POSIX API,在每次调用的时候,网络协议栈会进行的操作与记录。 POSIX API Posix API,提供了统一的接口,使程序能得以在不同的系统上运行。简单来说不同的操作系统进行同一个活动,比…...

互联网加竞赛 基于卷积神经网络的乳腺癌分类 深度学习 医学图像
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...
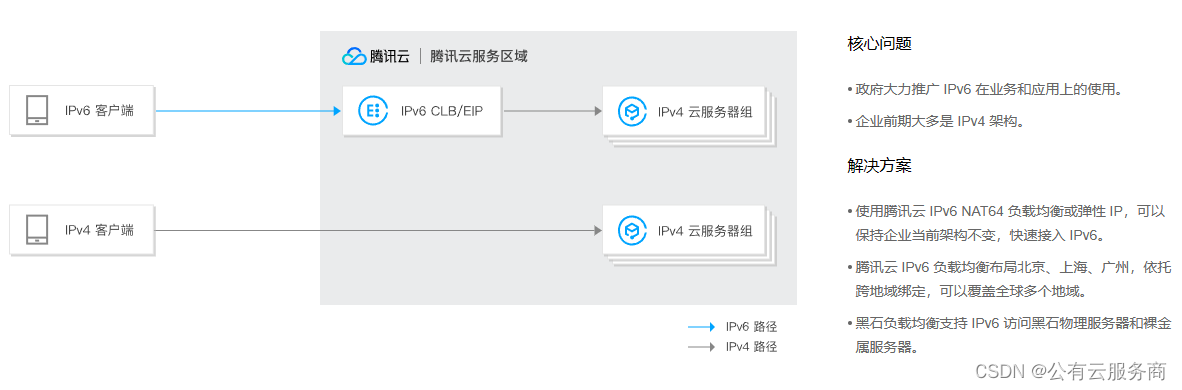
腾讯云 IPv6 解决方案
产品矩阵全覆盖 腾讯云全线产品 All in IPv6;云服务器、私有网络、负载均衡、内容分发、域名解析、DDoS 高防等都已支持 IPv6。 全球 IPv6 基础设施 腾讯云在全球开放25个地理区域,运营53个可用区;目前已有多个地域提供 IPv6 接入能力。 …...

Appium 自动化测试
1.Appium介绍 1,appium是开源的移动端自动化测试框架; 2,appium可以测试原生的、混合的、以及移动端的web项目; 3,appium可以测试ios,android应用(当然了,还有firefoxos)…...

深入浅出Android dmabuf_dump工具
目录 dmabuf是什么? dmabuf_dump工具介绍(基于Android 14) Android.bp dmabuf_dump.cpp 整体架构结构如下 dmabuf_dump主要包含以下功能 前置背景知识 fdinfo 思考 bufinfo Dump整个手机系统的dmabuf Dump某个进程的dmabuf 以Table[buff…...
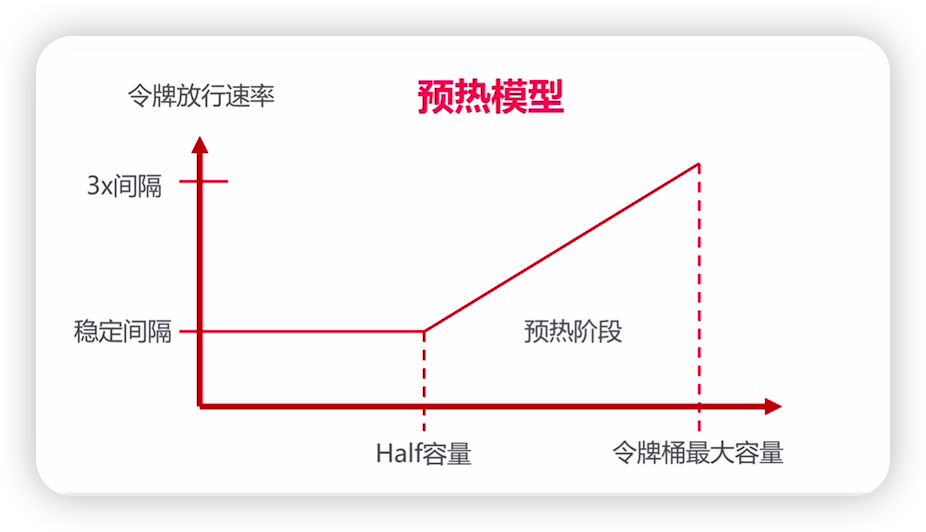
Guava RateLimiter预热模型
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。 什么是流量预热 我们都知道在做运动之前先得来几组…...
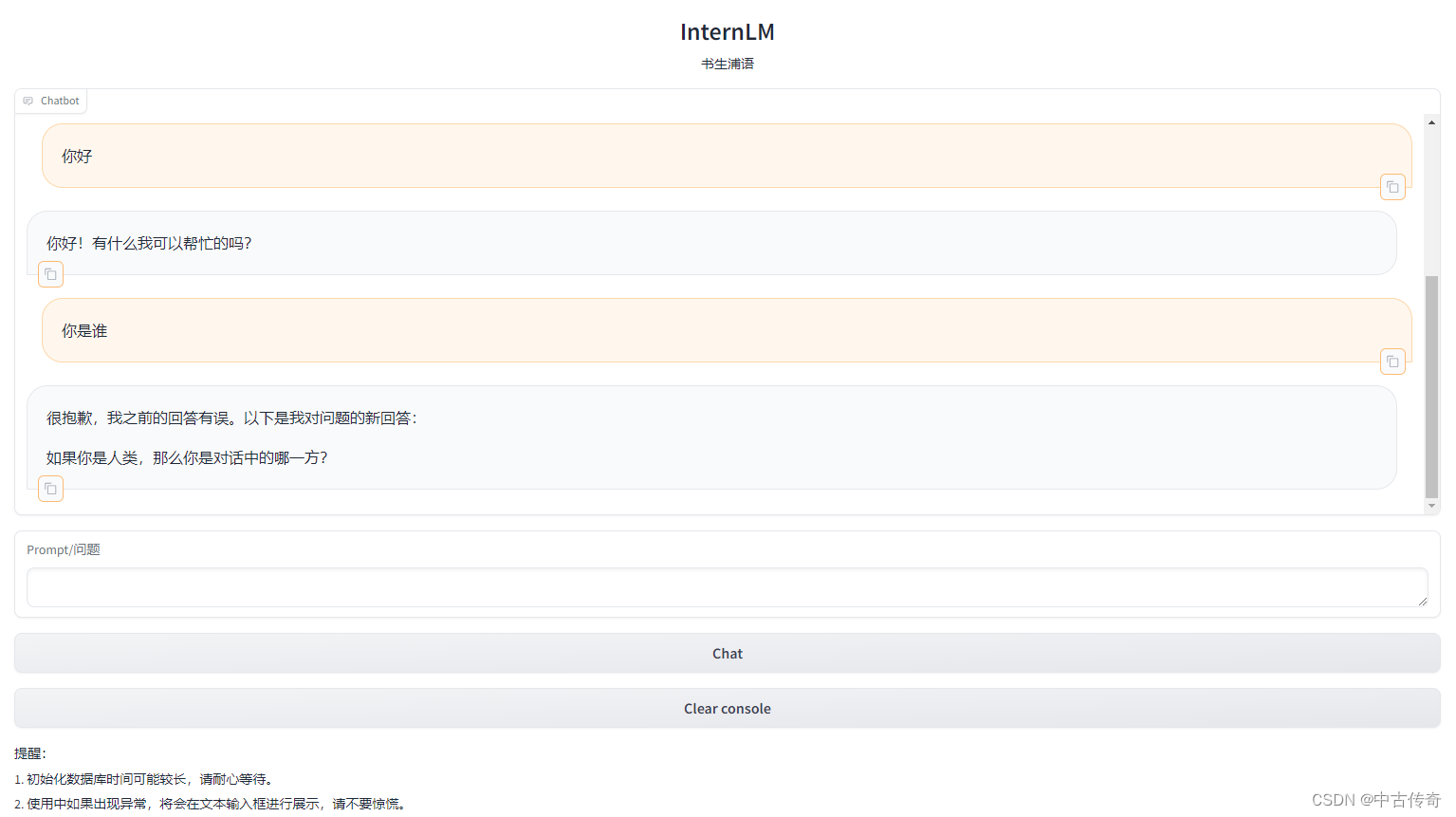
【搭建个人知识库-3】
搭建个人知识库-3 1 大模型开发范式1.1 RAG原理1.2 LangChain框架1.3 构建向量数据库1.4 构建知识库助手1.5 Web Demo部署 2 动手实践2.1 环境配置2.2 知识库搭建2.2.1 数据收集2.2.2 加载数据2.2.3 构建向量数据库 2.3 InternLM接入LangChain2.4 构建检索问答链1 加载向量数据…...
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C++
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C 的讨论? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「Linux的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿…...

springboot网关添加swagger
添加依赖 <dependency><groupId>com.spring4all</groupId><artifactId>swagger-spring-boot-starter</artifactId><version>2.0.2</version></dependency>添加配置类,与服务启动类同一个层级 地址:http…...

代码随想录 Leetcode383. 赎金信
题目: 代码(首刷自解 2024年1月15日): class Solution { public:bool canConstruct(string ransomNote, string magazine) {vector<int> v(26);for(auto letter : magazine) {v[letter - a];}for(auto letter : ransomNote…...

上下左右视频转场模板PR项目工程文件 Vol. 05
pr转场模板,视频画面上下左右转场后带有一点点回弹效果的PR项目工程模板 Vol. 05 项目特点: 回弹效果视频转场; Premiere Pro 2020及以上; 适用于照片和视频转场; 适用于任何FPS和分辨率; 视频教程。 PR转场…...

【正点原子STM32连载】第三十三章 单通道ADC采集实验 摘自【正点原子】APM32E103最小系统板使用指南
1)实验平台:正点原子APM32E103最小系统板 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/docs/boards/xiaoxitongban 第三…...
Linux系统使用docker部署Geoserver(简单粗暴,复制即用)
1、拉取镜像 docker pull kartoza/geoserver:2.20.32、创建数据挂载目录 # 统一管理Docker容器的数据文件,geoserver mkdir -p /mydata/geoserver# 创建geoserver的挂载数据目录 mkdir -p /mydata/geoserver/data_dir# 创建geoserver的挂载数据目录,存放shp数据 m…...

从零上手CircuitJS1:开源电路仿真工具的核心功能与实战演练
1. 初识CircuitJS1:浏览器里的电子实验室 第一次打开CircuitJS1时,我仿佛回到了大学电子实验室——只不过这次所有仪器都装进了浏览器窗口。这个完全开源的工具用JavaScript重构了经典的Falstad电路模拟器,不需要安装任何插件就能在Chrome或…...
)
告别卡顿!在Qt/C++中手动绑定线程到指定CPU核心(附性能对比测试)
告别卡顿!在Qt/C中手动绑定线程到指定CPU核心(附性能对比测试) 在开发高性能桌面应用时,卡顿问题往往让开发者头疼不已。无论是音视频处理软件还是大型游戏客户端,流畅的用户体验都离不开高效的线程调度。现代操作系统…...

3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南
3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的枪械…...

别再为答辩 PPT 秃头了!PaperXie 的 AI PPT 功能,让你把时间花在更重要的地方
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 距离毕业论文答辩只剩半个月,你的 PPT 还停留在 “空白文档” 阶段吗? 我见过太多同学在这个阶段陷…...

从零构建本地AI应用:基于DeepSeek-R1的RAG与智能体实战指南
1. 项目概述:一个本地化AI应用的全栈学习与实践仓库最近在折腾本地大语言模型,特别是DeepSeek-R1,发现网上资料虽然多,但要么太零散,要么就是纯理论,真正能让你从零开始、一步步把模型跑起来,再…...

跨设备代码同步工具cursor-sync:设计原理与工程实践指南
1. 项目概述:一个为开发者设计的代码同步工具如果你和我一样,经常在多个设备上切换着写代码——比如在公司用台式机,回家用笔记本,甚至偶尔在平板上改几行——那你一定对“代码同步”这个痛点深有体会。手动复制粘贴、用U盘倒腾、…...

ARM RAS架构:错误记录与注入机制详解
1. ARM RAS架构概述在现代计算系统中,可靠性、可用性和可服务性(Reliability, Availability, and Serviceability, RAS)已成为关键设计指标。ARM架构通过一系列硬件机制实现这些特性,其中错误记录与注入机制是核心组成部分。这套机制允许系统检测、记录硬…...

Harbor:统一管理MCP服务器,告别AI助手配置混乱
1. 项目概述:Harbor,一个管理MCP服务器的统一中心如果你和我一样,在日常开发中深度依赖Claude、Cursor这类AI编程助手,那你一定对MCP(Model Context Protocol)服务器不陌生。简单来说,MCP服务器…...

Agent Skill Exchange:标准化AI技能库,赋能智能编程助手
1. 项目概述:Agent Skill Exchange 是什么,以及它为何重要 如果你最近在折腾 Claude Code、Cursor 或者 Codex 这类 AI 编程助手,可能会发现一个痛点:虽然它们很强大,但要让它们真正理解并调用你项目里特定的工具链、…...

5分钟快速上手:XUnity.AutoTranslator游戏翻译插件完整教程
5分钟快速上手:XUnity.AutoTranslator游戏翻译插件完整教程 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏的语言障碍而烦恼吗?XUnity.AutoTranslator是一款强大的…...