使用 Vector 在 Kubernetes 中收集日志
多年来,我们一直在使用 Vector 在我们的 Kubernetes 平台中收集日志,并成功地将其应用于生产中以满足各种客户的需求,并且非常享受这种体验。因此,我想与更大的社区分享它,以便更多的 K8s 运营商可以看到潜力并考虑他们自己的设置的好处。
为此,我将首先简要回顾一下 Kubernetes 中可以收集哪些类型的信息。然后,我将探讨 Vector、它的架构以及我们为什么如此喜欢它。最后,我将分享我们对 Vector 的实际用例和实际经验。
Kubernetes 中的日志记录
让我们看一下 Kubernetes 中的日志。虽然 Kubernetes 的主要目标是在节点上运行容器,但必须记住,这些容器通常是根据 Heroku 的 12 个因素开发的。那么,他们如何在 Kubernetes 中生成日志,谁是其他生产者,日志驻留在何处?
1. 应用程序(pod)日志
在 K8s 中运行的应用程序将其日志写入 stdout 或 .然后,容器运行时收集这些日志并将其存储在一个目录中,该目录通常为 stderr/var/log/pods.它是可配置的,可以根据特定要求进行定制。

2. 节点服务日志
最重要的是,Kubernetes 节点上有一些服务在容器外部运行,例如 containerd 和 kubelet。
牢记这些服务并从 syslog 中收集相关消息(例如 SSH 身份验证消息)至关重要。
此外,在某些情况下,容器会将其日志写入特定的文件路径。例如,kube-apiserver,它通常会写入审计日志。因此,需要从相应的节点收集这些日志。
3. Events
Kubernetes 日志收集的另一个重要方面是事件。它们具有独特的结构,因为它们仅存在于 etcd 中,因此为了收集它们,您必须向 Kubernetes API 发出请求。
由于 reason 字段(请参阅下面的示例清单)和 count 字段(用作计数器,随着记录的事件越来越多而递增),因此可以将事件视为指标。
此外,还可以将事件收集为跟踪、特征和字段,这有助于创建全面的甘特图,以说明集群中的所有事件。firstTimestamp lastTimestamp
最后,事件提供人类可读的消息(字段),使它们能够作为日志收集。message
apiVersion: v1
kind: Event
count: 1
metadata:name: standard-worker-1.178264e1185b006fnamespace: default
reason: RegisteredNode
firstTimestamp: '2023-09-06T19:08:47Z'
lastTimestamp: '2023-09-06T19:08:47Z'
involvedObject:apiVersion: v1kind: Nodename: standard-worker-1uid: 50fb55c5-d97e-4851-85c6-187465154db6
message: 'Registered Node standard-worker-1 in Controller'从本质上讲,Kubernetes 可以收集 Pod 日志、节点服务日志和事件。但是,在本文中,我们将重点关注 Pod 日志和节点服务日志,因为事件需要额外的软件来抓取它们,这涉及到 Kubernetes API,因此将其扩展到我们的范围之外。
什么是 Vector
现在,让我们看看 Vector 是怎么回事。
Vector 显著特征(以及我们使用它的原因)
根据官方网站的说法,Vector 是一个“用于构建可观测性管道的轻量级、超快速工具”。但是,作为 Vector 用户,我想稍微改写一下这个定义,强调与我们的情况最相关的功能:
Vector 是一个开源的高效工具,用于构建日志收集管道。
对我们来说,这个定义中有什么重要意义?
- 开源是我们必须在其上构建可信的、持久的解决方案并将其推荐给其他人的必要条件。
- 另一个重要因素是 Vector 的效率。如果一个工具是轻量级的,但不能处理大量数据,它就不能满足我们的要求。同样,如果一个工具速度超快,但消耗大量资源,它也不适合作为日志收集器。因此,效率起着至关重要的作用。
- 值得一提的是,Vector 收集其他类型数据的能力对我们来说并不重要,因为我们目前的重点是日志。
Vector 的一个特殊功能是其与供应商无关。尽管 Vector 归 Datadog 所有,但它与其他各种供应商的解决方案无缝集成,包括 Splunk、Grafana Cloud 和 Elasticsearch Cloud。这种灵活性确保了单个软件解决方案可以跨多个供应商使用。
Vector 提供的另一个令人愉快的好处是它消除了在 Rust 中重写 Go 应用程序以提高其性能的需要。Vector 已经是用 Rust 编写的。
此外,它被设计为高性能。这是如何实现的?Vector 具有一个 CI 系统,可以对任何提议的拉取请求运行基准测试。维护人员会严格评估新功能对 Vector 性能的影响。如果出现任何不利影响,请贡献者及时纠正问题,因为性能仍然是 Vector 团队的首要任务。
此外,Vector 是一个灵活的构建块,我们将在下面详细介绍。
Vector 的架构
作为一种处理工具,Vector 从各种来源收集数据。它通过抓取或充当 HTTP 服务器来积累其他工具摄取的数据来做到这一点。
Vector 擅长转换日志条目,可以将多条消息修改、删除或聚合为一条消息。(不要被下面架构图中所示的转换数量所迷惑,它提供了更多功能。
在此转换之后,Vector 处理消息并将其转发到存储或队列系统。

Vercor 架构:收集日志、转换日志并发送日志
简而言之,Vector 包含一种强大的转换语言,称为矢量重映射语言 (VRL),允许无限数量的可能转换。
矢量重映射语言示例
让我们快速浏览一下 VRL,然后从日志过滤开始。在下面的代码片段中,我们使用 VRL 表达式来确保 severity 字段不等于 :info
[transforms.filter_severity]
type = "filter"
inputs = ["logs"]
condition = '.severity != "info"'当 Vector 收集 Pod 日志时,它还会使用其他 Pod 元数据(例如 Pod 名称、Pod IP 和 Pod 标签)来丰富日志行。但是,在 Pod 标签中,可能有一些标签只有 Kubernetes 控制器使用,因此对人类用户没有价值。为了获得最佳存储性能,我们建议删除以下标签:
[transforms.sanitize_kubernetes_labels]
type = "remap"
inputs = ["logs"]
source = '''if exists(.pod_labels."controller-revision-hash") {del(.pod_labels."controller-revision-hash")}if exists(.pod_labels."pod-template-hash") {del(.pod_labels."pod-template-hash")}
'''下面是如何将多个日志行连接成一行的示例:
[transforms.backslash_multiline]
type = "reduce"
inputs = ["logs"]
group_by = ["file", "stream"]
merge_strategies."message" = "concat_newline"
ends_when = '''matched, err = match(.message, r'[^\\]$');if err != null {false;} else {matched;}
'''
在本例中,该字段将向消息字段添加换行符。最重要的是,该部分使用 VRL 表达式来检查一行是否以反斜杠结尾(以连接多行 Bash 注释的方式)。merge_strategies ends_when
日志收集拓扑
好了,是时候探索几种不同的日志收集拓扑以用于 Vector 了。第一种是分布式拓扑,其中 Vector 代理部署在 Kubernetes 集群中的所有节点上。然后,这些代理收集、转换日志并将其直接发送到存储。
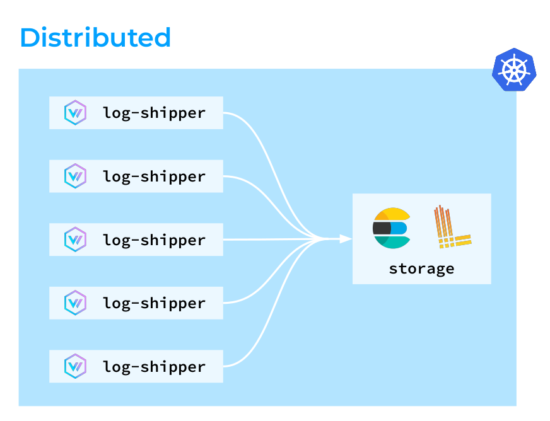
第二个是集中式拓扑。在其中,Vector 代理也在所有节点上运行,尽管它们不执行任何复杂的转换:聚合器会处理这些转换。这种设置的好处是其出色的负载可预测性。您可以为聚合器部署专用节点,并在必要时对其进行扩展,从而优化 Vector 在集群节点上的资源消耗。

第三种拓扑是基于流的方法。在其中,Kubernetes Pod 会尽快“摆脱”日志。日志被直接摄取到存储中,然后 Elasticsearch 解析日志行并调整索引,这可能是一个占用大量资源的过程。尽管如此,在 Kafka 的案例中,消息被简单地视为字符串。因此,我们可以轻松地从 Kafka 中检索这些日志,以便进一步存储和分析。
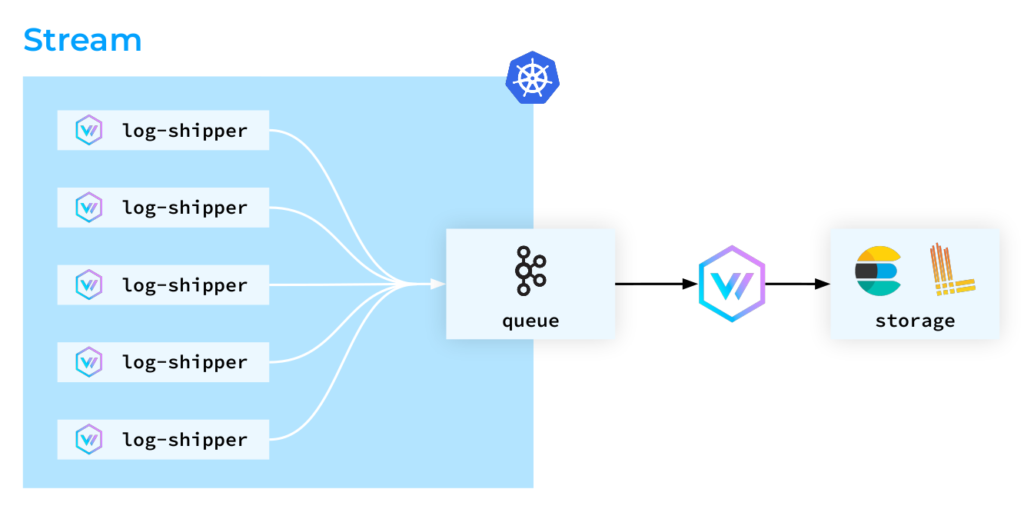
请注意,在本文中,我们不会介绍 Vector 充当聚合器的拓扑结构。相反,我们将只关注它作为群集节点上的日志收集代理的角色。
Kubernetes 中的 Vector
我们将如何看待 Kubernetes 中的 Vector?让我们看一下下面的 pod:

Kubernetes 部署为 DaemonSet 后的 Vector 容器
这样的设计乍一看可能很复杂,但这背后是有原因的。我们在这个 pod 中有三个容器:
- 第一个运行 Vector 本身。其主要目的是收集日志。
- 第二个容器称为 Reloader,使我们的平台用户能够创建自己的日志收集和引入管道。我们有一个特殊的运算符,它假设用户定义的规则并为 Vector 生成配置映射。Reloader 容器验证该配置映射并相应地重新加载 Vector。
- 第三个容器 Kube RBAC 代理起着至关重要的作用,因为 Vector 公开了有关其收集的日志行的各种指标。由于此信息可能是敏感的,因此必须通过适当的授权对其进行保护。
Vector 被部署为 DaemonSet(参见下面的列表),因为我们必须在 Kubernetes 集群中的所有节点上部署它的代理。
为了有效地收集日志,我们需要将额外的目录挂载到 Vector 中:
- 目录,因为如前所述,所有 Pod 的日志都存储在那里。
/var/log - 最重要的是,我们需要将一个持久卷挂载到 Vector 中,用于存储检查点。每次 Vector 发送日志行时,它都会写入一个检查点,以避免重复发送到同一存储的日志。
- 此外,我们挂载 以查看节点的时区。
localtime
apiVersion: apps/v1
kind: DaemonSet
volumes:
- name: var-loghostPath:path: /var/log/
- name: vector-data-dirhostPath:path: /mnt/vector-data
- name: localtimehostPath:path: /etc/localtime
volumeMounts:
- name: var-logmountPath: /var/log/readOnly: true
terminationGracePeriodSeconds: 120
shareProcessNamespace: true关于此列表的其他一些说明:
- 挂载目录时,请务必记住启用该模式。此预防措施可防止未经授权修改日志文件。
/var/logreadOnly - 我们使用终止宽限期(120 秒)来确保 Vector 在重新启动之前完成分配给它的所有任务。
- 共享进程命名空间对于使 Reloader 能够向 Vector 发送信号以重新启动它至关重要。
这总结了我们在 Kubernetes 中部署 Vector 的设置。
接下来,让我们继续讨论最有趣的部分——实际用例。所有这些都不是假设的场景——它们是我们在值班期间遇到的真实世界的停电。
实际用例
案例 #1:设备空间不足
有一天,由于磁盘空间不足,所有 Pod 都被逐出节点。我们展开了调查,发现 Vector 实际上保留了已删除的文件。现在,为什么会这样?
- Vector 监视目录中的文件。
/var/log/pods - 当应用程序主动写入日志时,文件大小会超过 10 兆字节的限制,达到 20、30、40、50......兆 字节。
- 在某些时候,kubelet 会轮换日志文件,使其恢复到原始大小 10 MB。
- 然而,与此同时,Vector 试图将日志发送给 Loki。不幸的是,Loki 无法处理如此大量的数据!
- Vector 作为一个负责任的软件,仍然打算将所有日志发送到存储中。
不幸的是,应用程序不会等待所有这些内部操作完成,它们只是继续运行。这导致 Vector 尝试保留所有日志文件,并且随着 kubelet 继续轮换它们,节点上的可用空间会耗尽。

那么,如何解决这个问题呢?
- 首先,您可以从调整缓冲区设置开始。默认情况下,如果 Vector 无法将所有日志发送到存储,则会将其存储在内存中。默认缓冲区容量限制为仅 1000 条消息,这是相当低的。您可以将其扩展到 10000。
- 或者,将行为从阻止更改为删除新日志也可能有所帮助。通过该行为,Vector 将简单地丢弃其缓冲区中无法容纳的任何日志。
drop newest - 另一种选择是使用磁盘缓冲区而不是内存缓冲区。不利的一面是 Vector 会花费更多时间在输入输出操作上。在这种情况下,在决定此方法是否适合您时,必须考虑性能要求。
消除此问题的经验法则是采用流拓扑。通过允许日志尽快离开节点,可以降低生产应用程序中断的风险。我们当然不想因为监控问题而毁掉生产集群,不是吗?
最后,如果你足够勇敢,你可以用它来调整一个进程的最大打开文件数。但是,我不推荐这种方法。sysctl
案例#2:Prometheus “爆炸”
Vector 在一个节点上运行并执行几个不同的任务。它从 Pod 收集日志,并公开收集的日志行数和遇到的错误数等指标。这要归功于 Vector 卓越的可观测性功能。
但是,许多指标都有特定的文件标签,这可能会导致高基数,这是 Prometheus 无法消化的。这是因为当 Pod 重新启动时,Vector 开始公开新 Pod 的指标,同时仍保留旧 Pod 的指标,这意味着这些指标具有不同的文件标签。此行为是 Prometheus 导出器工作方式(按设计)的结果。不幸的是,在几个吊舱重新启动后,这种情况导致普罗米修斯的负载突然激增,随后发生了“爆炸”。
为了解决这个问题,我们应用了一个指标标签规则来消除麻烦的文件标签。这解决了 Prometheus 的问题——它现在运行正常。
然而,一段时间后,Vector 遇到了自己的问题。问题是,Vector 消耗了越来越多的内存来存储所有这些指标,导致内存泄漏。为了纠正这个问题,我们在 Vector 中使用了一个全局选项,称为:expire_metric_secs
- 如果将其设置为 60 秒,Vector 将检查它是否仍在从这些 pod 收集数据。
- 否则,它将停止导出这些文件的指标。
尽管此解决方案有效运行,但它也影响了其他一些指标,例如 Vector 组件错误指标。如下图所示,最初记录了 7 个错误,但在触发过期后,数据中出现了差距。

不幸的是,Prometheus,尤其是 PromQL 函数(和类似函数),无法处理这样的数据差距。相反,Prometheus 希望指标在整个时间段内公开。rate
为了解决这个限制,我们修改了 Vector 的代码,以完全消除文件标签——只需删除几个地方的“文件”条目即可。事实证明,此解决方法已成功解决该问题。
案例 #3:Kubernetes 控制平面中断
有一天,我们注意到当 Vector 实例同时重启时,Kubernetes 控制平面往往会失败。在分析我们的仪表板后,我们确定这个问题源于过度的内存使用,主要是 etcd 内存消耗。

为了更好地理解根本原因,我们首先需要深入研究 Kubernetes API 的内部工作原理。
当 Vector 实例启动时,它向 Kubernetes API 发出请求,以使用 Pod 元数据填充缓存。如前所述,Vector 依赖于此元数据来丰富日志条目。LIST

因此,每个 Vector 实例都请求 Kubernetes API 为 Vector 运行的同一节点上的 Pod 提供元数据。但是,对于每个单独的请求,Kubernetes API 都会从 etcd 读取。
etcd 用作键值数据库。键由资源的种类、命名空间和名称组成。对于节点上涉及 110 个 Pod 的每个请求,Kubernetes API 都会访问 etcd 并检索所有 Pod 的数据。这会导致 kube-apiserver 和 etcd 的内存使用量激增,最终导致它们失败。
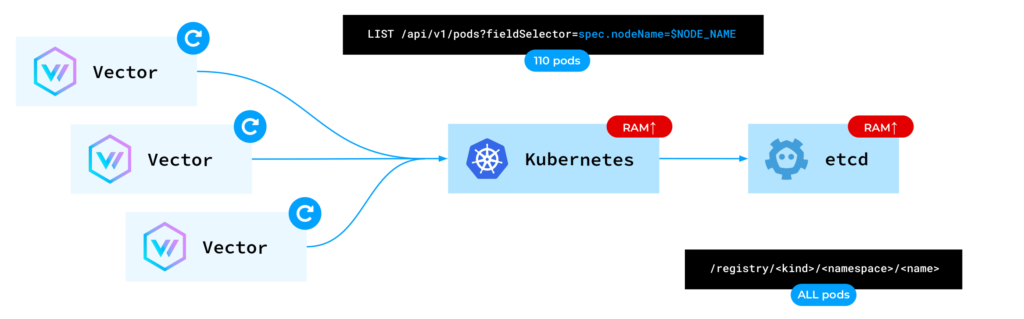
此问题有两种可能的解决方案。首先,我们可以采用缓存读取方法。在这种方法中,我们指示 API 服务器从其现有的缓存中读取数据,而不是从 etcd 中读取数据。尽管在某些情况下可能会出现不一致,但这对于监视工具来说是可以接受的。不幸的是,这样的功能在 Kubernetes Rust 客户端中不可用。因此,我们向 Vector 提交了一个拉取请求,启用了该选项。use_apiserver_cache=true
第二种解决方案涉及利用 Kubernetes 优先级和公平性 API 的独特功能。问题是,你可以定义一个请求队列:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:name: limit-list-custom
spec:type: Limitedlimited:assuredConcurrencyShares: 5limitResponse:queuing:handSize: 4queueLengthLimit: 50queues: 16type: Queue...并将其与特定服务帐户相关联:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:name: limit-list-custom
spec:priorityLevelConfiguration:name: limit-list-customdistinguisherMethod:type: ByUserrules:- resourceRules:- apiGroups: [""]clusterScope: truenamespaces: ["*"]resources: ["pods"]verbs: ["list", "get"]subjects:- kind: ServiceAccountserviceAccount:name: ***namespace: ***通过此类配置,您可以限制并发预检请求的数量,并有效降低峰值的严重性,从而最大程度地减少其影响。
最后,您可以使用 kubelet API 通过向 /pods 端点发送请求来获取 Pod 元数据,而不是依赖 Kubernetes API。但是,此功能尚未在 Vector 中实现。
结论
Vector 非常适合平台工程工作,因为它具有灵活性、多功能性和日志摄取和传输选项的广度。我全心全意地推荐 Vector,并鼓励您充分利用它的功能。
相关文章:
使用 Vector 在 Kubernetes 中收集日志
多年来,我们一直在使用 Vector 在我们的 Kubernetes 平台中收集日志,并成功地将其应用于生产中以满足各种客户的需求,并且非常享受这种体验。因此,我想与更大的社区分享它,以便更多的 K8s 运营商可以看到潜力并考虑他们…...
 篇)
ardupilot开发 --- 固件定制(OEM) 篇
0. 前言 固件功能定制OEM Customization: 原厂设备制造商OEM(Original Equipment Manufacturer)、代工功能勾选参数预设固件名称自定义 1. 基于某个飞控硬件来定制自己的飞控产品 可以自定义的包括:固件名称、预设参数、lua脚本…...

爬虫代理IP在电商行业的应用
随着互联网的快速发展,电商行业已经成为人们购物的主要渠道之一。在电商行业中,数据分析和挖掘至关重要。爬虫代理IP作为一种能够提供大量模拟请求和收集数据的工具,被广泛应用于电商行业。下面介绍爬虫代理IP在电商行业中的应用。 1、保护隐…...

Vue配置语法检查及关闭语法检查的说明
1. 第一种方式://eslint-disable-next-line 2. 第二种方式:/*eslint-disable*/ 3. 第三种方式:vue.config.js中配置 ,具体配置如下: const { defineConfig } require(vue/cli-service)module.exports defineConfig…...

【Linux】yum
个人主页 : zxctsclrjjjcph 文章封面来自:艺术家–贤海林 如有转载请先通知 yum 1. 什么是yum?2. Linux系统(Centos)的生态3. yum的相关操作4. yum的本地配置5. 如何安装软件 1. 什么是yum? yum是一个软件下载安装的一个客户端&a…...

安装sftpgo
1.下载安装包;选择自己需要的cpu架构和操作系统的版本 https://github.com/drakkan/sftpgo/releases/tag/v2.5.6推荐使用版本下载地址 https://github.com/drakkan/sftpgo/releases/download/v2.5.6/sftpgo_v2.5.6_linux_x86_64.tar.xz2.解压文件到某个文件夹,根据需要修改配…...
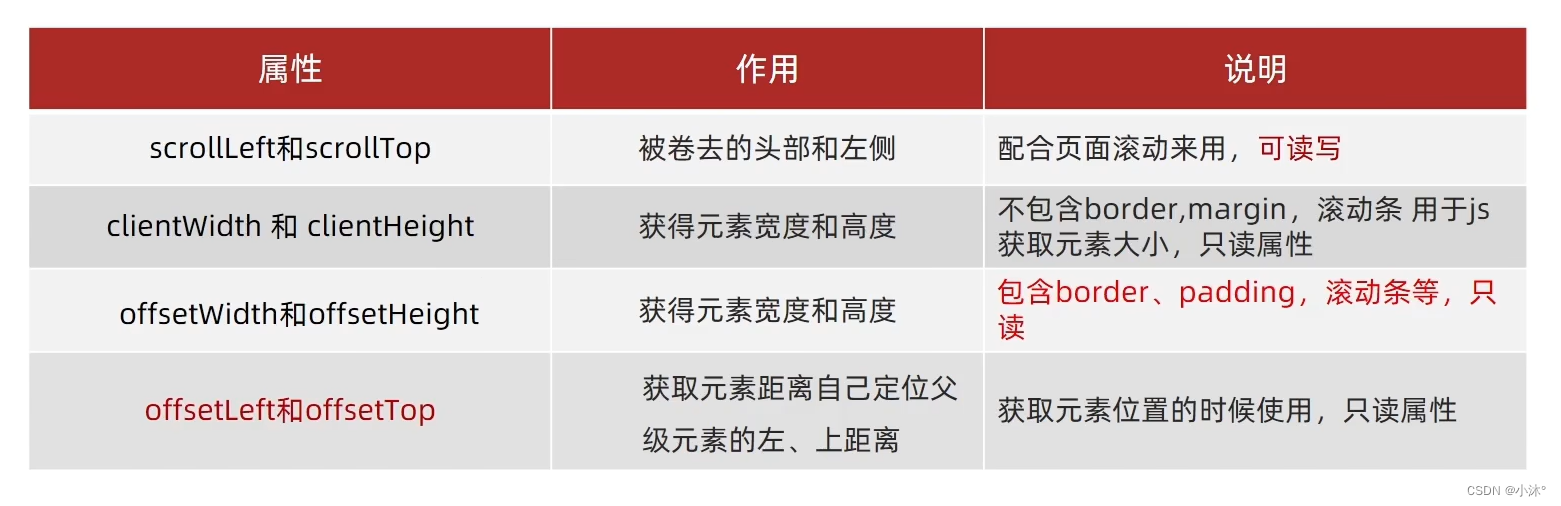
JS-元素尺寸与位置
通过js的方式,得到元素在页面中的位置 获取宽高 元素.offsetWidth 元素.offsetHeight 1)获取元素的自身宽高、包括元素自身设置的宽高paddingborder 2)获取出来的是数值,方便计算 3)注意:获取的是可视…...
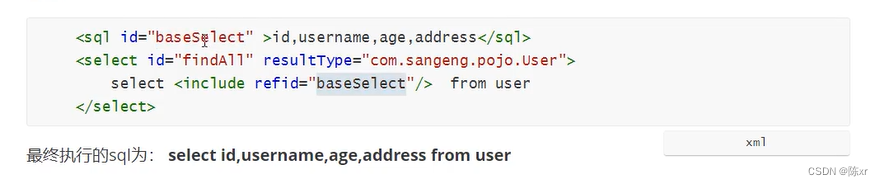
2024-01-15(SpringMVCMybatis)
1.拦截器:如果我们想在多个handler方法(controller中的方法)执行之前或者之后都进行一些处理,甚至某些情况下需要拦截掉,不让handler方法执行,那么就可以使用SpringMVC为我们提供的拦截器。 拦截器和过滤器的区别:过滤…...
Node+Express编写接口---前端
前端页面 vue_node_admin: 第一个以node后端,vue为前端的后台管理项目https://gitee.com/ah-ah-bao/vue_node_admin.git...

防火墙技术
防火墙(英语:Firewall)技术是通过有机结合各类用于安全管理与筛选的软件和硬件设备,帮助计算机网络于其内、外网之间构建一道相对隔绝的保护屏障,以保护用户资料与信息安全性的一种技术。 防火墙技术的功能主要在于及…...

图灵日记之java奇妙历险记--String类
目录 String常用方法字符串构造String对象的比较字符串查找char charAt(int index)int indexOf(int ch)int indexOf(int ch, int fromIndex)int indexOf(String str)int indexOf(String str, int fromIndex)int lastIndexOf(String str)int lastIndexOf(String str, int fromIn…...

代码随想录算法训练营第六天| 242 有效的字母异位词 349 两个数组的交集 202 快乐数 1 两数之和
目录 242 有效的字母异位词 349 两个数组的交集 202 快乐数 1 两数之和 242 有效的字母异位词 排序 class Solution { public:bool isAnagram(string s, string t) {sort(s.begin(),s.end());sort(t.begin(),t.end());return t s;} }; 时间复杂度O(nlogn) 空间复杂度O(l…...
数学建模--比赛
内容来自数学建模BOOM:【快速入门】北海:数模建模基础MATLAB入门论文写作数学模型与算法(推荐数模美赛国赛小白零基础必看教程)_哔哩哔哩_bilibili 目录 1.学习内容 2.参赛须知 1)参赛作品的组成 2)参赛作品的提交 3.软件安装 4.注意…...

JVM工作原理与实战(十六):运行时数据区-Java虚拟机栈
专栏导航 JVM工作原理与实战 RabbitMQ入门指南 从零开始了解大数据 目录 专栏导航 前言 一、运行时数据区 二、Java虚拟机栈 1.栈帧的组成 2.局部变量表 3.操作数栈 4.帧数据 总结 前言 JVM作为Java程序的运行环境,其负责解释和执行字节码,管理…...
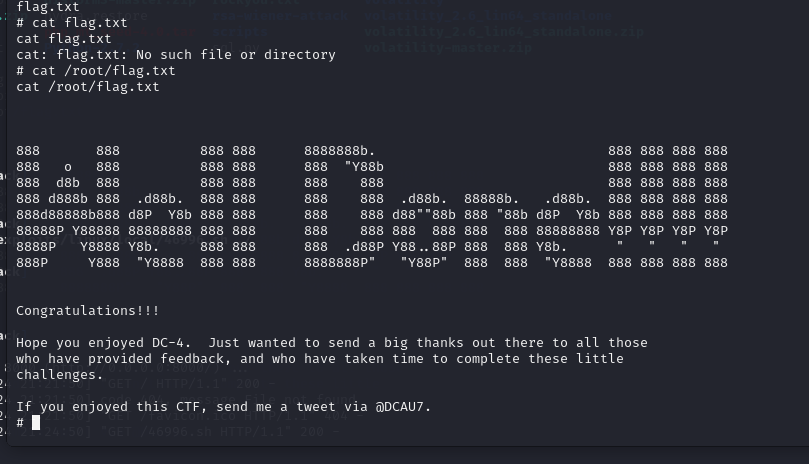
DC-4靶机刷题记录
靶机下载地址: 链接:https://pan.baidu.com/s/1YbPuSw_xLdkta10O9e2zGw?pwdn6nx 提取码:n6nx 参考: 【【基础向】超详解vulnhub靶场DC-4-爆破反弹shell信息收集】 https://www.bilibili.com/video/BV1Le4y1o7Sx/?share_sourc…...

【前端学习笔记1】css基础
css可以使页面更漂亮,即美化网页 css:层叠样式表 标签选择器: 类选择器: id只能单次调用,类似人的身份证 css里只要是word里面有的功能,他们都有对应的,不会的时候查一下就行 实现垂直居中:h…...
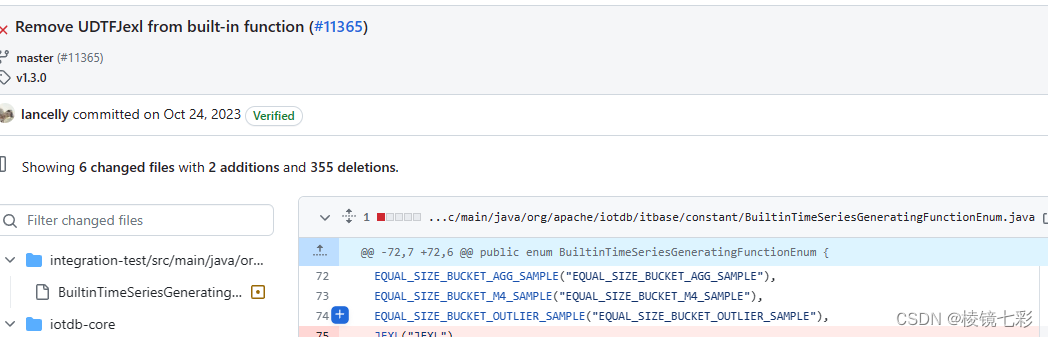
CVE-2023-46226 Apache iotdb远程代码执行漏洞
项目介绍 Apache IoTDB 是针对时间序列数据收集、存储与分析一体化的数据管理引擎。它具有体量轻、性能高、易使用的特点,完美对接 Hadoop 与 Spark 生态,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求。 项目地址 https://io…...
Redis实战之-分布式锁
一、基本原理和实现方式对比 分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。 分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行…...

Cookie同源策略
同源策略(Same-Origin Policy)是浏览器安全机制的一部分,用于限制一个源(域名、协议和端口的组合)的文档或脚本如何与来自另一个源的资源进行交互。这个策略帮助防止潜在的恶意网站在用户浏览器中执行恶意操作。 关于C…...

6、Numpy形状操纵
目录 1. 使用 reshape 改变形状 2. 使用 resize 改变大小和形状 3. 使用 ravel 或 flatten 展平数组 4. 使用 -1 推断尺寸 5. 使用 newaxis 增加维度 6. 使用 squeeze 移除单维度条目 1. 使用 reshape 改变形状 对于任何 NumPy 数组,你可以使用 reshape 方法来…...

QMCDecode:三步快速解密QQ音乐加密音频的免费工具
QMCDecode:三步快速解密QQ音乐加密音频的免费工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

jquery.inputmask插件介绍
目录 一、什么是 jQuery.inputmask? 主要应用场景 二、快速上手 1. 引入依赖文件 2. 基础用法 3. 掩码字符定义 三、高级功能 1. 自定义占位符 2. 完成回调 3. 扩展自定义字符 4. 重复掩码 5. 移除默认占位符 四、配合 Vue.js 使用 五、更多实用示例 …...

Tomcat Windows路径导致HTTP响应头信息泄露漏洞解析
1. 这个漏洞不是“能读文件”那么简单,而是Tomcat在特定配置下主动把敏感信息塞进HTTP响应头里CVE-2024-21733这个编号刚出来时,我第一反应是又一个常规的路径遍历或文件读取漏洞。但实际复现后才发现,它根本不是靠构造恶意URL去“偷”东西&a…...

深入剖析Golang环境搭建:从基础配置到高效开发实践
1. 项目概述:为什么Golang环境搭建值得深究?如果你刚接触Go语言,可能会觉得“环境搭建”不就是下载、安装、配个变量吗?网上教程一搜一大把,五分钟搞定。但作为一名在多个生产环境中部署过Go服务的老兵,我必…...

Arty S7 FPGA开发板实战指南:从硬件解析到项目开发
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计爱好者,或者正在寻找一块能兼顾学习、原型验证和低成本部署的FPGA开发板,那么Digilent的Arty S7系列很可能已经进入了你的视野。我最初接触这块板子ÿ…...

完全自由操作系统的构建秘密:从可验证构建到信任链转移
1. 项目概述:探寻“完全自由”操作系统的内核秘密最近在技术社区里,一个话题反复被提起:“一套完全自由的操作系统都有这个秘密”。这听起来像是一个谜语,又像是一个宣言。作为一个在系统软件领域摸爬滚打了十几年的老手ÿ…...

别再纠结Unity和Godot了!用Python写游戏,从零开始30分钟搞定你的第一个Ren`Py视觉小说
用Python写游戏:30分钟打造你的第一款RenPy视觉小说 当Python开发者想要涉足游戏创作时,往往会面临一个尴尬的选择:要么学习C#配合Unity,要么用GDScript适应Godot,这些额外的语言学习曲线常常让人望而却步。但鲜为人知…...
)
Vue3项目里SignalR怎么用?一个聊天室Demo带你从配置到上线(.NET 6 + Vue 3)
Vue3与SignalR实战:构建高互动聊天室的全栈指南 引言 在当今追求实时交互体验的Web应用中,传统的HTTP请求-响应模式已无法满足即时通讯、实时通知等场景需求。SignalR作为ASP.NET Core生态中的实时通信库,通过自动选择最佳传输协议࿰…...

从官方demo到真实项目:手把手教你定制uniapp uni-card卡片的样式与交互
从官方demo到真实项目:手把手教你定制uniapp uni-card卡片的样式与交互 在移动应用开发中,卡片式设计已经成为展示内容的黄金标准。uni-app的uni-card组件为开发者提供了一个快速构建卡片式界面的基础工具,但实际项目中,我们往往需…...

技术债的“利息”怎么算?一个让非技术领导也能理解的比喻
一、从“信用卡账单”到“技术债利息”:一个通俗的起点软件测试从业者对“技术债”这个词绝不陌生,每次面对历史代码里的“隐秘角落”,看着新功能开发时层出不穷的连锁Bug,我们都能直观感受到技术债带来的拖累。但要向非技术领导解…...