【cuda】四、基础概念:Cache Tiled 缓存分块技术
缓存分块是一种内存优化技术,主要用于提高数据的局部性(Locality),以减少缓存未命中(Cache Miss)的次数。在现代计算机体系结构中,处理器(CPU)的速度通常比内存快得多。因此,如果CPU在处理数据时需要频繁地等待数据从内存中加载,就会大大降低程序的执行效率。Cache Tiled技术通过将数据分割成较小的块(Tiles),并确保这些小块能够完全装入CPU的高速缓存(Cache),来减少这种等待时间。
CUDA编程中,用于优化内存访问模式,以减少全局内存(DRAM)访问次数并提高内存带宽的利用率。它的核心思想是将数据分成小块(称为“tiles”或“blocks”),这样每个块可以完全加载到共享内存中。共享内存是一种CUDA核心内的高速缓存内存,其访问速度比全局内存快得多。
基本原理
见啥使用DRAM,也就是全局内存。转而多用L1 Cache。缓存分块是有的时候数据太多了,每次只能加载一部分。
- 减少内存延迟:通过将数据加载到共享内存中,可以减少对全局内存的访问次数,从而减少延迟。
- 提高内存带宽利用率:将数据划分为小块后,可以更有效地利用内存带宽。
- 协同工作:多个线程可以协作加载一个Tile,然后从共享内存中高效读取数据。
实现步骤
- 定义Tile的大小:确定目标内存以及GPU的共享内存大小。计算index用于加载到共享内存。
- 加载数据到共享内存:在CUDA核心中,多个线程协作将全局内存中的数据加载到共享内存。
- 同步线程:确保所有数据都加载到共享内存后,再进行处理。
- 处理数据:从共享内存读取数据,进行计算。
- 将结果写回全局内存:如果需要,将处理后的数据写回到全局内存。
Coding
TILE_WIDTH是一个预定义的常量,它定义了Tile的大小。
__syncthreads() 是一个同步原语,用于确保一个线程块内的所有线程都达到这一点后才能继续执行。这在使用共享内存时尤其重要,因为它确保在所有线程开始读取共享内存中的数据之前,所有的写入操作都已完成。
#define TILE_WIDTH 16*16*4 // b c bit 定义每个Tile的宽度// CUDA核心函数,用于矩阵乘法
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width) {__shared__ float Mds[TILE_WIDTH][TILE_WIDTH]; // 定义共享内存,用于存储Md的一个Tile__shared__ float Nds[TILE_WIDTH][TILE_WIDTH]; // 定义共享内存,用于存储Nd的一个Tileint bx = blockIdx.x; // 获取当前块的x坐标int by = blockIdx.y; // 获取当前块的y坐标int tx = threadIdx.x; // 获取当前线程在块中的x坐标int ty = threadIdx.y; // 获取当前线程在块中的y坐标// 计算Pd矩阵中的行号和列号int Row = by * TILE_WIDTH + ty;int Col = bx * TILE_WIDTH + tx;float Pvalue = 0; // 初始化计算值// 遍历Md和Nd矩阵的Tile,计算Pd矩阵的元素for (int m = 0; m < Width/TILE_WIDTH; ++m) {// 协作加载Md和Nd的Tile到共享内存Mds[ty][tx] = Md[Row*Width + (m*TILE_WIDTH + tx)];Nds[ty][tx] = Nd[Col + (m*TILE_WIDTH + ty)*Width];__syncthreads(); // 确保所有线程都加载完毕// 计算Tile内的乘积并累加到Pvaluefor (int k = 0; k < TILE_WIDTH; ++k) {Pvalue += Mds[ty][k] * Nds[k][tx];}__syncthreads(); // 确保所有线程都计算完毕}// 将计算结果写入Pd矩阵Pd[Row*Width + Col] = Pvalue;
}
在这个示例中,MatrixMulKernel 是用于矩阵乘法的CUDA核心。它使用了两个共享内存数组Mds和Nds来存储两个输入矩阵的Tile。每个线程块处理输出矩阵Pd的一个Tile。线程块中的每个线程共同工作,加载输入矩阵的相应部分到共享内存,然后使用这些数据来计算输出矩阵的一个元素。
__syncthreads() 出现在两个关键位置:
- 加载数据到共享内存之后:这里的
__syncthreads()确保了所有线程都完成了对共享内存的写入操作。即使这个写入操作是在for循环中完成的,我们也需要确保每个线程都完成了当前迭代的加载操作,才能安全地开始使用这些共享内存中的数据进行计算。 - 计算Tile内的乘积并累加到Pvalue之后:第二个
__syncthreads()确保了所有线程都完成了当前Tile的计算。在开始处理下一个Tile之前,这是必要的,因为下一个Tile的计算可能依赖于共享内存中的新数据。
在这两种情况下,__syncthreads() 的作用是确保所有线程在继续执行之前都达到同一点。
对比原始矩阵乘法的代码:
__global__ void MatrixMulSimple(float* A, float* B, float* C, int Width) {int Row = blockIdx.y * blockDim.y + threadIdx.y;int Col = blockIdx.x * blockDim.x + threadIdx.x;if (Row < Width && Col < Width) {float Pvalue = 0;for (int k = 0; k < Width; ++k) {Pvalue += A[Row * Width + k] * B[k * Width + Col];}C[Row * Width + Col] = Pvalue;}
}
变量存储类别 关键字总结
用于指定变量的存储类别,这些关键字决定了变量的存储位置以及如何在不同线程和线程块之间共享:
| 关键字 | 描述 | 作用域 | 生命周期 |
|---|---|---|---|
| device | 用于在GPU的全局内存中声明变量。 | 所有线程 | 应用程序执行期间 |
| global | 用于定义在主机上调用但在设备上执行的函数(即CUDA核心函数)。 | - | - |
| host | 用于定义在主机上调用并执行的函数。 | - | - |
| shared | 用于声明位于共享内存中的变量。 | 同一个线程块内的线程 | 线程块的执行期间 |
| constant | 用于声明位于常量内存中的变量。 | 所有线程 | 应用程序执行期间 |
| managed | 用于声明在主机和设备之间共享的统一内存变量。 | 所有线程和主机 | 应用程序执行期间 |
__device__:这些变量存储在设备的全局内存中,可以被所有线程访问,但访问延迟较高。__global__:定义的是CUDA核心函数,这种函数可以从主机(CPU)调用并在设备(GPU)上异步执行。__host__:定义的是常规的C++函数,仅在主机上执行。__shared__:声明的变量位于共享内存中,这是一种较快的内存类型,但仅在同一个线程块内的线程之间共享。__constant__:用于声明常量内存中的变量,这种内存对于所有线程来说是只读的,访问速度快,但空间有限。__managed__:Unified Memory(统一内存)中的变量,可以被GPU和CPU共同访问,CUDA运行时负责管理内存的迁移。
相关文章:

【cuda】四、基础概念:Cache Tiled 缓存分块技术
缓存分块是一种内存优化技术,主要用于提高数据的局部性(Locality),以减少缓存未命中(Cache Miss)的次数。在现代计算机体系结构中,处理器(CPU)的速度通常比内存快得多。因…...

[C#]winform部署openvino官方提供的人脸检测模型
【官方框架地址】 https://github.com/sdcb/OpenVINO.NET 【框架介绍】 OpenVINO(Open Visual Inference & Neural Network Optimization)是一个由Intel推出的,针对计算机视觉和机器学习任务的开源工具套件。通过优化神经网络ÿ…...

Java中对日期的处理
Java中对日期的处理 这个案例主要掌握: 1.怎么获取系统当前时间 2.String-->Date 3.Date-->String Import java.text.SimpleDateFormat; Import java.util.Date; public class DateTest01{ public static void main(String[] args) throws Exception{ //获取…...
【Linux install】Ubuntu和win双系统安装及可能遇到的所有问题
文章目录 1.前期准备1.1 制作启动盘1.2关闭快速启动、安全启动、bitlocker1.2.1 原因1.2.2 进入BIOSshell命令行进入BIOSwindows设置中高级启动在开机时狂按某个键进入BIOS 1.2.3 关闭Fast boot和Secure boot 1.3 划分磁盘空间1.3.1 查看目前的虚拟内存大小 2.开始安装2.1 使用…...
Helm Dashboard — Kubernetes 中管理 Helm 版本的 GUI
Helm Dashboard 通过提供图形用户界面,使在 Kubernetes 中管理 Helm 版本变得更加容易,这是许多开发人员所期望的。它可用于在 Kubernetes 中创建、部署和更新应用程序的版本,并跟踪其状态。 本文将探讨 Helm Dashboard 提供的特性和优势&am…...

【Guava笔记01】Guava Cache本地缓存的常用操作方法
这篇文章,主要介绍Guava Cache本地缓存的常用操作方法。 目录 一、Guava Cache本地缓存 1.1、引入guava依赖 1.2、CacheBuilder类 1.3、Guava-Cache使用案例...
Flink(十三)【Flink SQL(上)SqlClient、DDL、查询】
前言 最近在假期实训,但是实在水的不行,三天要学完SSM,实在一言难尽,浪费那时间干什么呢。SSM 之前学了一半,等后面忙完了,再去好好重学一遍,毕竟这玩意真是面试必会的东西。 今天开始学习 Flin…...

Labview局部变量、全局变量、引用、属性节点、调用节点用法理解及精讲
写本章前想起题主初学Labview时面对一个位移台程序,傻傻搞不清局部变量和属性节点值有什么区别,概念很模糊。所以更新这篇文章让大家更具象和深刻的去理解这几个概念,看完记得点赞加关注喔~ 本文程序源代码附在后面,大家可以自行下…...

openssl3.2 - 官方demo学习 - signature - EVP_ED_Signature_demo.c
文章目录 openssl3.2 - 官方demo学习 - signature - EVP_ED_Signature_demo.c概述笔记END openssl3.2 - 官方demo学习 - signature - EVP_ED_Signature_demo.c 概述 ED25519 签名/验签算法, 现在是最好的. 产生ED25519私钥/公钥 用私钥对明文签名, 得到签名数据 用公钥对明文…...

AI辅助编程工具—Github Copilot
一、概述 Copilot是一种基于Transformer模型的神经网络,具有12B个参数。是GitHub和OpenAPI共同开发的编程辅助工具。GitHubCopilot是一款由人工智能驱动的结对编程编辑器,旨在帮助开发人员更加高效地工作。它利用OpenAICodex技术,将开发…...

三大3D引擎对比,直观感受AMRT3D渲染能力
作为当前热门的内容呈现形式,3D已经成为了广大开发者、设计师工作里不可或缺的一部分。 用户对于3D的热衷,源于其带来的【沉浸式体验】和【超仿真视觉效果】。借此我们从用户重点关注的四个3D视觉呈现内容: 材质- 呈现多元化内容水效果- 展…...
k8s之对外服务ingress
一、service 1、service作用 ①集群内部:不断跟踪pod的变化,不断更新endpoint中的pod对象,基于pod的IP地址不断变化的一种服务发现机制(endpoint存储最终对外提供服务的IP地址和端口) ②集群外部:类似负…...

Ubuntu使用docker-compose安装mysql8或mysql5.7
ubuntu环境搭建专栏🔗点击跳转 Ubuntu系统环境搭建(十四)——使用docker-compose安装mysql8或mysql5.7 文章目录 Ubuntu系统环境搭建(十四)——使用docker-compose安装mysql8或mysql5.7MySQL81.新建文件夹2.创建docke…...
【办公类-21-02】20240118育婴员操作题word打印2.0
作品展示 把12页一套的操作题批量制作10份,便于打印 背景需求 将昨天整理的育婴师操作题共享, 因为题目里面有大量的红蓝颜色文字,中大班办公室都是黑白单面手动翻页打印。只有我待的教务室办公室有彩色打印机打印(可以自动双面…...

SpringMVC 文件上传和下载
文章目录 1、文件下载2、文件上传3. 应用 Spring MVC 提供了简单而强大的文件上传和下载功能。 下面是对两者的简要介绍: 文件上传: 在Spring MVC中进行文件上传的步骤如下: 在表单中设置 enctype“multipart/form-data”,这样…...
强缓存、协商缓存(浏览器的缓存机制)是么子?
文章目录 一.为什么要用强缓存和协商缓存?二.什么是强缓存?三.什么是协商缓存?四.总结 一.为什么要用强缓存和协商缓存? 为了减少资源请求次数,加快资源访问速度,浏览器会对资源文件如图片、css文件、js文…...

android 13.0 Camera2 去掉后置摄像头 仅支持前置摄像头功能
1.概述 在定制化13.0系统rom定制化开发中,当产品只有一个前置摄像头单摄像头,这时调用相机时就需要默认打开前置摄像头就需要来看调用摄像头这块的代码,屏蔽掉后置摄像头的调用api就可以了,接下来就来具体实现相关功能的开发 2.Camera2 去掉后置摄像头 仅支持前置摄像头功…...
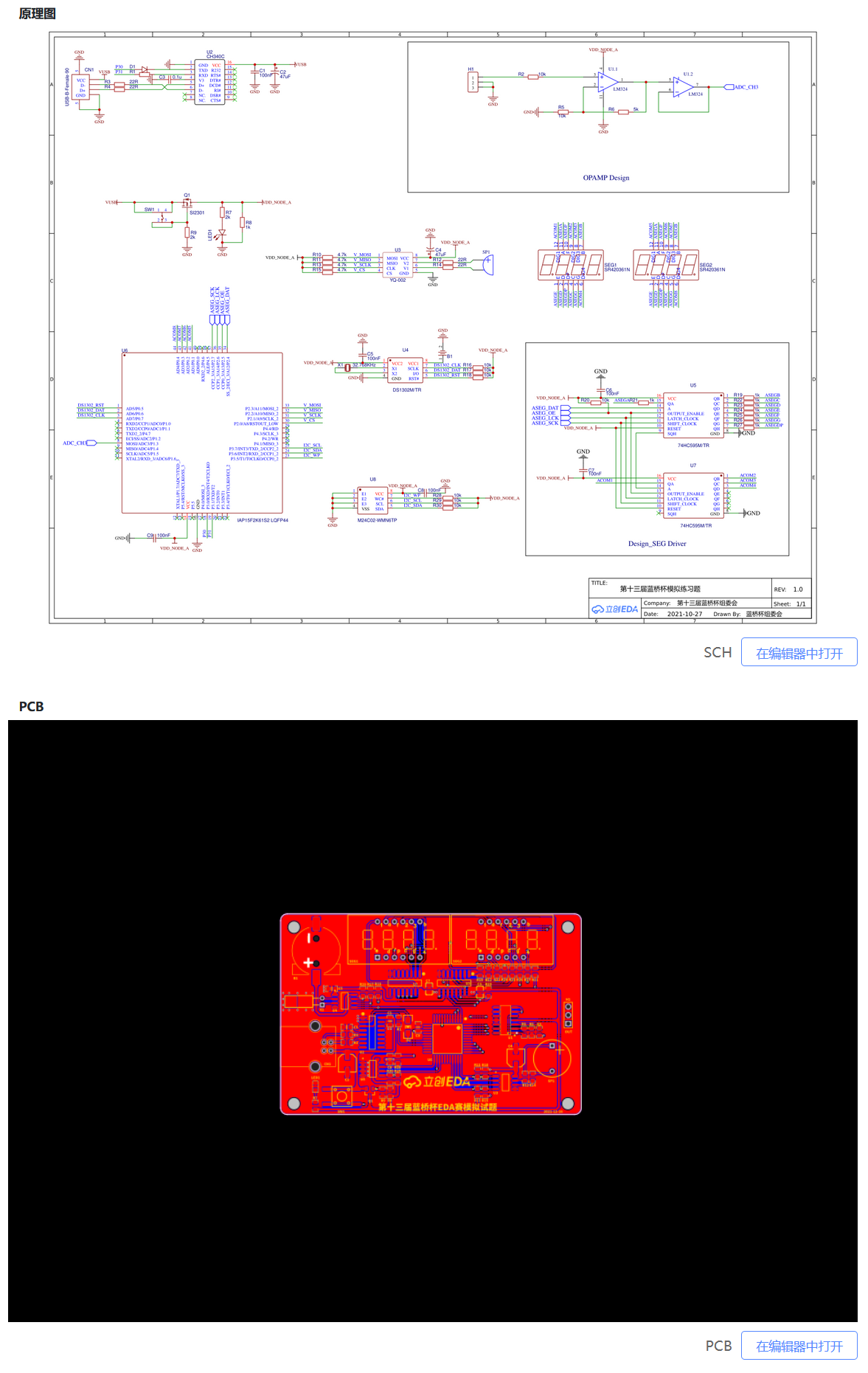
【蓝桥杯EDA设计与开发】立创开源社区分享的关于蓝桥被EDA真题与仿真题的项目分析
立创开源社区内有几个项目分享了往年 EDA 设计题目与仿真题,对此展开了学习。 【本人非科班出身,以下对项目的学习仅在我的眼界范围内发表意见,如有错误,请指正。】 项目一 来源:第十四届蓝桥杯EDA赛模拟题一 - 嘉立…...
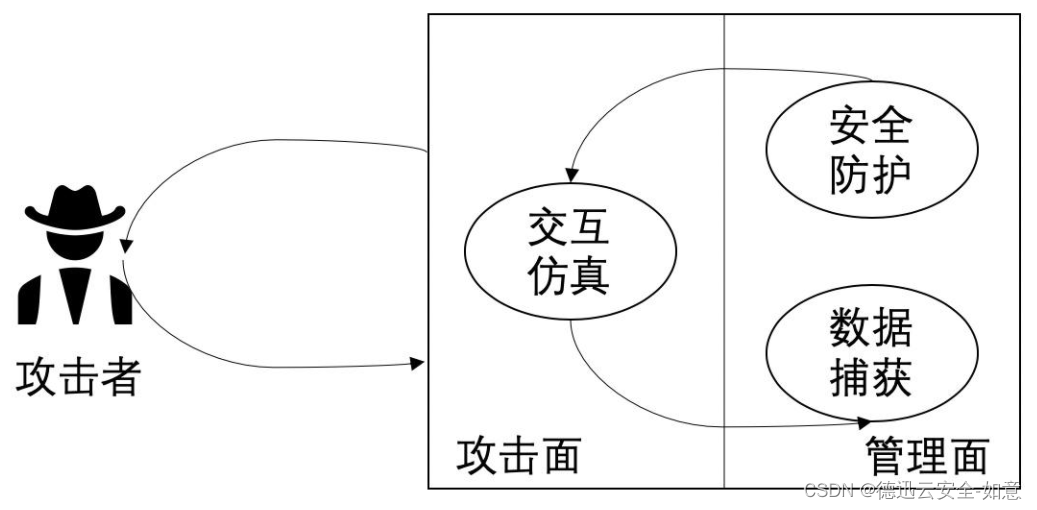
电影《潜行》中说的蜜罐是什么(网络安全知识)
近期刘德华、彭于晏主演的电影《潜行》在网上掀起了轩然大波,电影中有提到网络蜜罐,这引起了很多观众的疑问,蜜罐到底是什么? 从字面意思上来看,蜜罐就是为黑客设下的诱饵。这是一种具有牺牲性质的计算机系统ÿ…...

基于 UniAPP 社区论坛项目多端开发实战
社区论坛项目多端开发实战 基于 UniAPP 社区论坛项目多端开发实战一、项目准备1.1 ThinkSNS 简介及相关文档1.2 使用 UniAPP 构建项目1.3 构建项目文件结构1.4 配置页面 TabBar 导航1.5 使用 npm 引入 uView UI 插件库 二、首页功能实现2.1 首页 header 广告位轮播图功能实现2.…...

从“杯子放球”到“射击命中”:用Python模拟帮你彻底搞懂离散随机变量
从“杯子放球”到“射击命中”:用Python模拟帮你彻底搞懂离散随机变量 概率论中的离散随机变量概念常常让初学者感到抽象难懂。传统的数学推导虽然严谨,但缺乏直观性。本文将带你用Python代码亲手模拟几个经典概率问题,通过可视化手段让这些概…...

C++ `dynamic_cast
1. 基础 C类型转换概览为什么需要dynamic_cast 2. dynamic_cast 的使用 基本语法与其他类型转换(如 static_cast、reinterpret_cast 和 const_cast)的对比 3. RTTI (运行时类型信息) 什么是RTTI如何在C中启用和禁用RTTI 4. dynamic_cast 与多态 使用dyna…...

mpv.net 高效配置实战:从媒体播放到专业调优的进阶指南
mpv.net 高效配置实战:从媒体播放到专业调优的进阶指南 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 作为一款基于mpv核心的现代化Windows媒体播…...

AI Scientist-v2论文撰写流程:从实验结果到ICLR格式论文的自动化转换
AI Scientist-v2论文撰写流程:从实验结果到ICLR格式论文的自动化转换 【免费下载链接】AI-Scientist-v2 The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search 项目地址: https://gitcode.com/GitHub_Trending/ai/AI-Sci…...

从‘马鞍波’到‘圆形磁场’:深入浅出图解SVPWM如何让电机转得更平滑、更省电
从‘马鞍波’到‘圆形磁场’:深入浅出图解SVPWM如何让电机转得更平滑、更省电 想象一下,当你按下电动车的加速踏板时,电机如何从静止状态平稳过渡到高速旋转?这背后隐藏着一项关键技术——空间矢量脉宽调制(SVPWM&…...

AI 写的鸿蒙 ArkTS 代码能跑?我测了 37 个案例,翻车率 60%
先扔结论:如果你现在把 Claude 或 Cursor 当成 ArkTS 专家来用,大概率会掉坑里。我上周闲得慌,跑了 37 个常见开发场景的测试,结果 AI 生成的代码能直接编译通过的,不到四成。剩下的要么语法错误,要么用了废…...

三个00后给母校捐了“20亿”,全网炸了——结果这20亿可能就值几百块?
整件事最魔幻的地方在于:你第一眼看到“20亿”,脑子里自动补上的单位是“人民币”。然后一算账,发现可能连捐的那个展示牌都不如。这事到底是怎么回事?前几天,郑州西亚斯学院搞了一场挺隆重的捐赠仪式。三个00后校友—…...
)
别再套table了!手把手教你用LaTeX的longtable搞定跨页表格(附字体调整避坑指南)
LaTeX长表格排版实战:从table到longtable的平滑迁移与字体优化 第一次在LaTeX中遇到需要跨页的表格时,我像大多数初学者一样,本能地在longtable外面套了一层table环境——结果表格不仅无法正确分页,还出现了各种诡异的格式错乱。经…...

从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活
从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活 清晨醒来,你按下智能手机的闹钟关闭按钮,这个简单的动作背后是无线电波在基站与设备间的无声对话;早餐时微波炉加热牛奶的嗡嗡声,本质上是特定频率电磁场对水分…...
)
从DICOM到3D打印:手把手教你用3D Slicer处理医学影像全流程(含STL导出)
从DICOM到3D打印:医学影像处理全流程实战指南 在数字化医疗时代,将CT、MRI等医学影像转化为可触摸的3D打印模型,正在成为临床教学、手术规划和医患沟通的革命性工具。这套技术链条中最关键的桥梁,正是开源的3D Slicer平台——它能…...