day01 深度学习介绍
目录
1.1深度学习介绍
1.2神经网络NN
1、概念:
2、神经元
3、(单层)神经网络
4、感知机(两层)
5、多层神经网络
6、激活函数
(1)饱和与非饱和激活函数
(2)饱和激活函数
① Sigmoid激活函数
② tanh激活函数
(3)非饱和激活函数
① ⚠️ReLU激活函数
② Leaky Relu激活函数
③ ELU激活函数
1.3pytorch安装+入门
1、pytorch安装
2、Tensor张量
3、张量的创建方法
4、张量的方法和属性
5、tensor的数据类型
6、tensor的其他操作
(1)tensor 和 tensor相加。
(2)tensor和数字操作
(3)CUDA中的tensor
1.4梯度下降和反向传播
1、梯度
2、梯度下降
3、常见的导数的计算
4、反向传播
5、使用Pytorch完成线性回归
6、手动实现线性回归。
7、nn.Module
1.1深度学习介绍
1、深度学习
机器学习的分支。人工神经网络为基础,对数据的特征进行学习的方法。
2、机器学习和深度学习的区别:
【特征抽取】:
- 机器学习:人工的特征抽取。
- 深度学习:自动的进行特征抽取。
【数据量】:
- 机器学习:数据少,效果不是很好
- 深度学习:数据多,效果更好
3、深度学习应用场景:
- 图像识别:物体识别、场景识别、人脸检测跟踪、人脸身份认证。
- 自然语言处理技术:机器翻译、文本识别、聊天对话。
- 语音技术:语音识别
4、深度学习框架:pytorch
- 目前企业常见的深度学习框架有很多:TensorFlow、Caffe2、Theano、Pytorch、Chainer、DyNet、MXNet等。
1.2神经网络NN
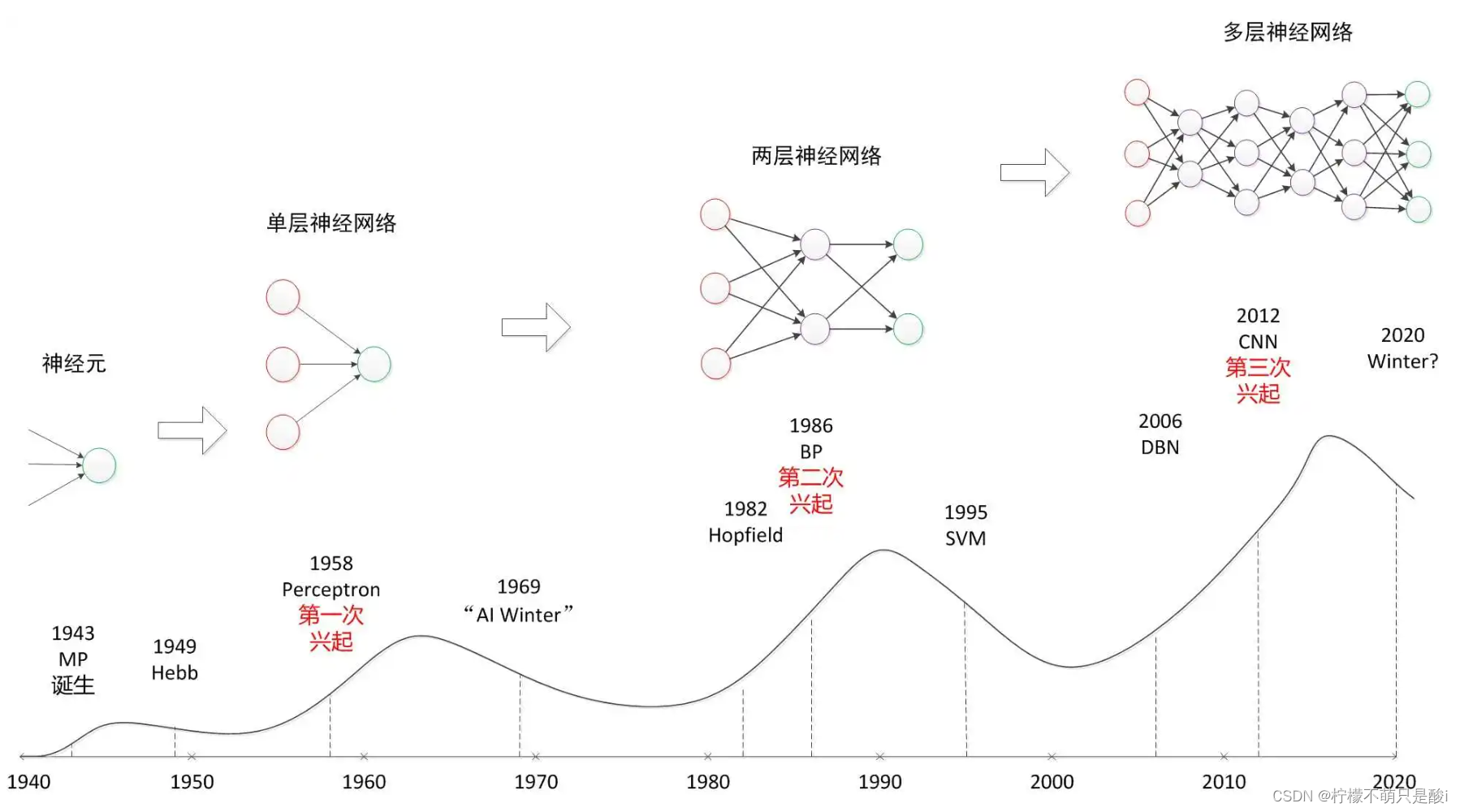
1、概念:
又称为人工神经网络ANN(Artificial Netural Network)。简称神经网络(NN)或类神经网络。模拟生物的神经系统,对函数进行估计或近似。
2、神经元
概念:神经网络中的基础单元,相互连接,组成神经网络。
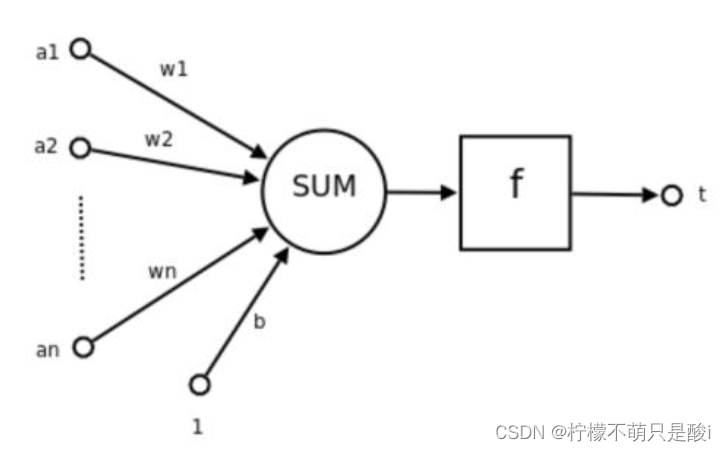
其中:
①a1、a2... an为各个输入的分量。
②w1、w2...wn为各个输入分量对应的权重参数。
③b为偏置
④f为激活函数。常见的激活函数有tanh、sigmoid、relu
⑤t为神经元的输出。
使用数学公式表示: 其中:
表示W的转置
对公式的理解:输出 = 激活函数( 权重*输入求和 + 偏置)
可见:一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
3、(单层)神经网络
最简单的神经网络的形式。
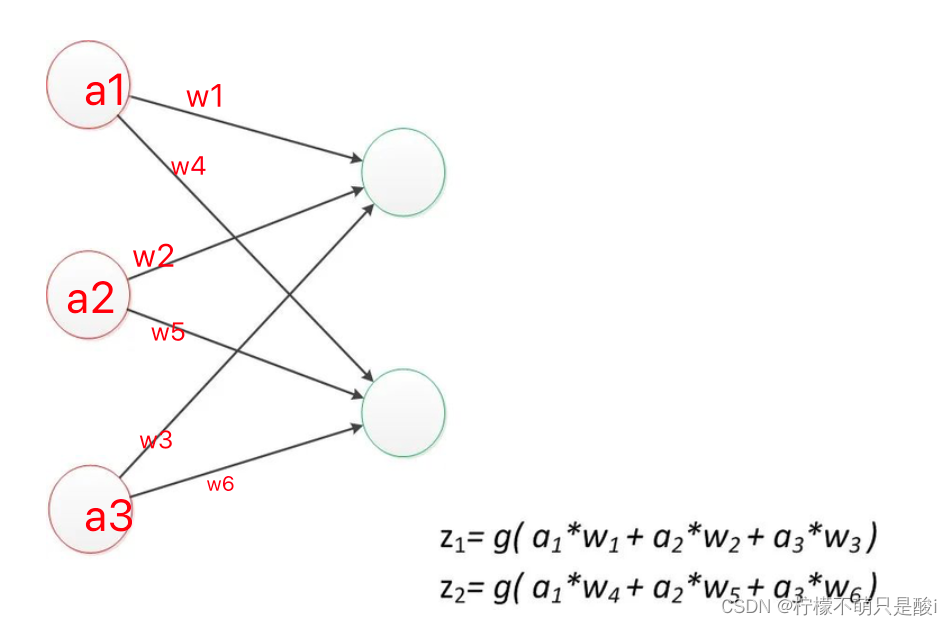
4、感知机(两层)
- 两层的神经网络。
- 简单的二分类的模型,给定阈值,判断数据属于哪一部分。
5、多层神经网络
- 输入层、
- 输出层、
- 隐藏层:可以有多层,每一层的神经元的个数可以不确定。
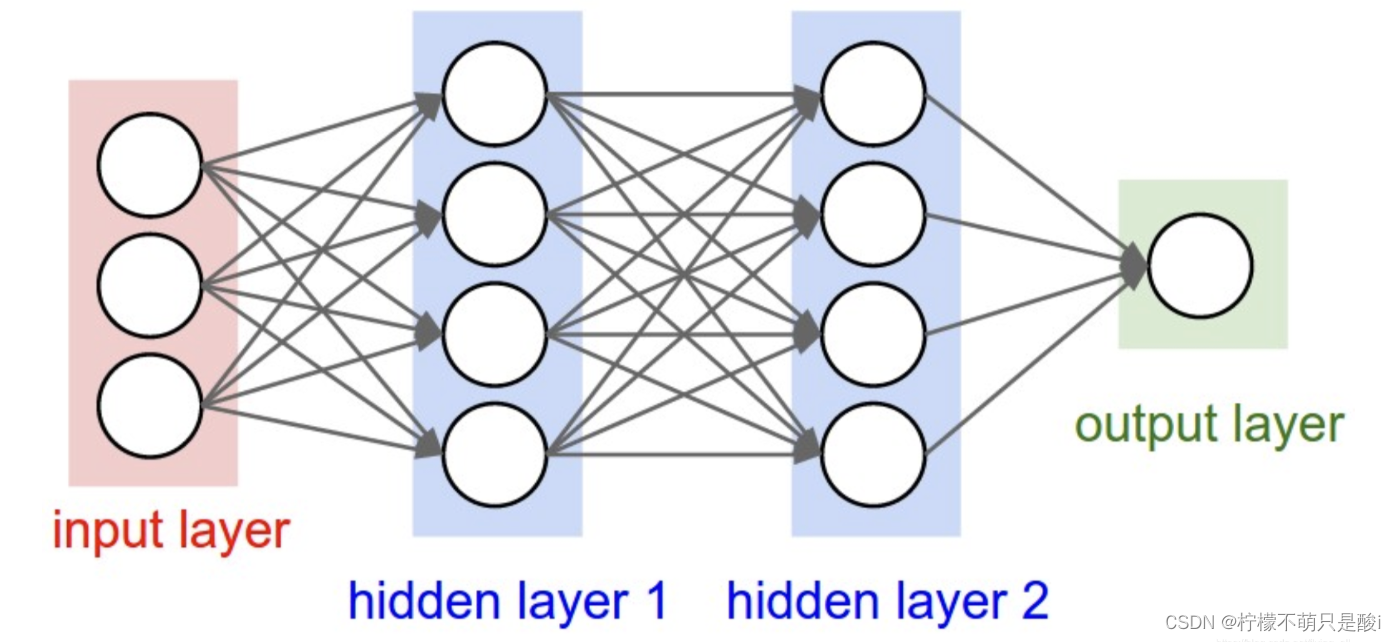
全连接层:当前层和前一层每个神经元相互连接,我们称当前这一层为全连接层。
即:第N层和第N-1层中的神经元两两之间都有连接。
- 进行的是 y = Wx + b
6、激活函数
作用:
- 增加模型的非线性分割能力。
- 提高模型稳健性
- 缓解梯度消失问题
- 加速模型收敛等。
(1)饱和与非饱和激活函数
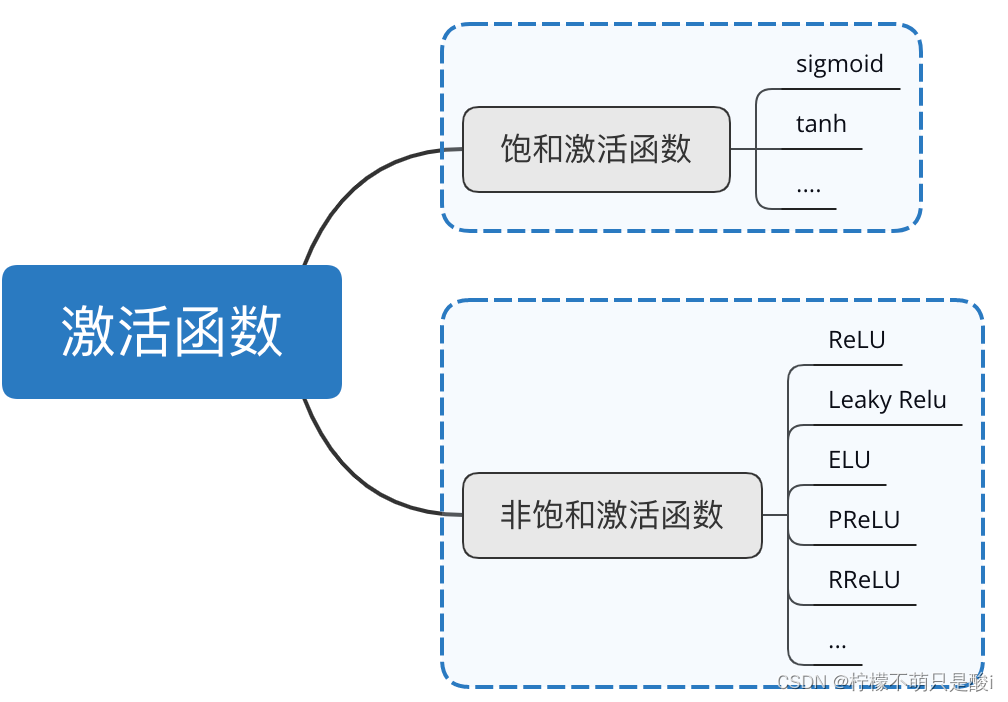

相对于饱和激活函数,使用非饱和激活函数的优势在于:
- 非饱和激活函数能解决深度神经网络(层数非常多)带来的梯度消失问题。
- 使用非饱和激活函数能加快收敛速度。
(2)饱和激活函数
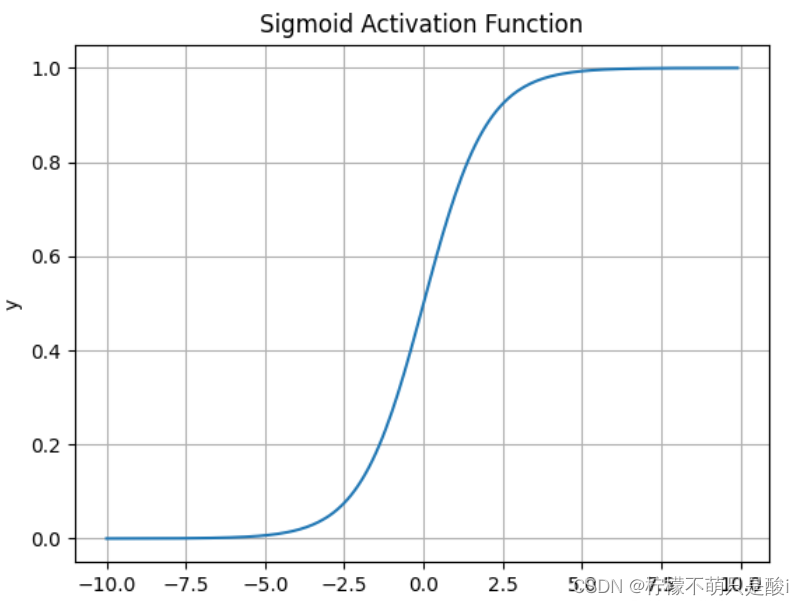
① Sigmoid激活函数
数学表达式为:
求导:
结果:输出值范围为(0,1)之间的实数。
② tanh激活函数
数学表达式为:
实际上,Tanh函数是 sigmoid 的变形:
tanh是“零为中心”的。
结果:输出值范围为(-1,1)之间的实数。

(3)非饱和激活函数
① ⚠️ReLU激活函数
数学表达式为:
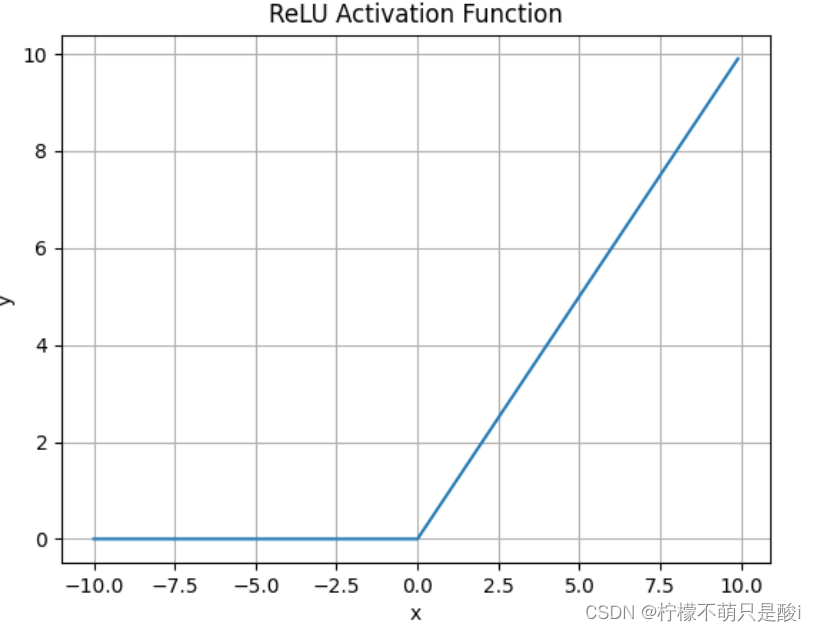
使用场景:
- ReLU解决了梯度消失的问题,当输入值为正时,神经元不会饱和
- 由于ReLU线性、非饱和的性质,在SGD中能够快速收敛
- 计算复杂度低,不需要进行指数运算
缺点:
-
与Sigmoid一样,其输出不是以0为中心的
② Leaky Relu激活函数
数学表达式为:
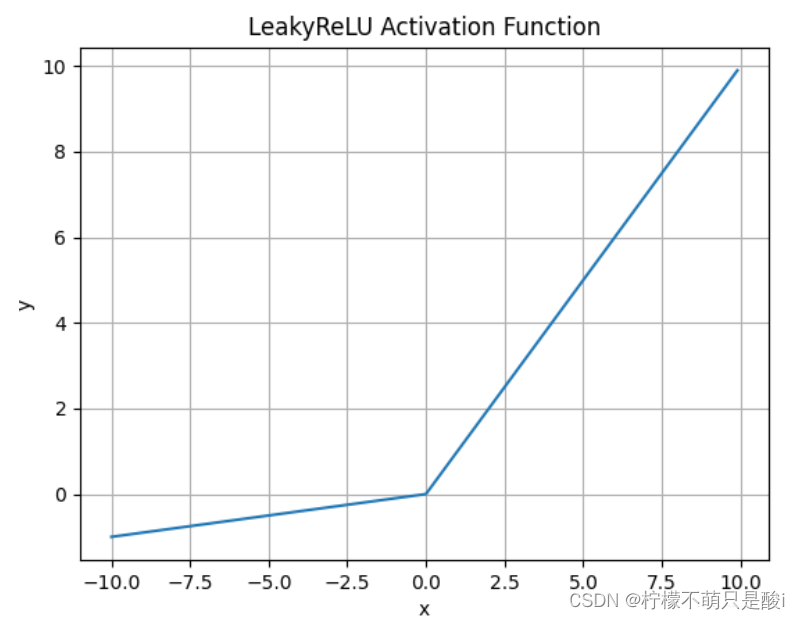
什么情况下适合使用Leaky ReLU?
- 解决了ReLU输入值为负时神经元出现的死亡的问题
- Leaky ReLU线性、非饱和的性质,在SGD中能够快速收敛
- 计算复杂度低,不需要进行指数运算
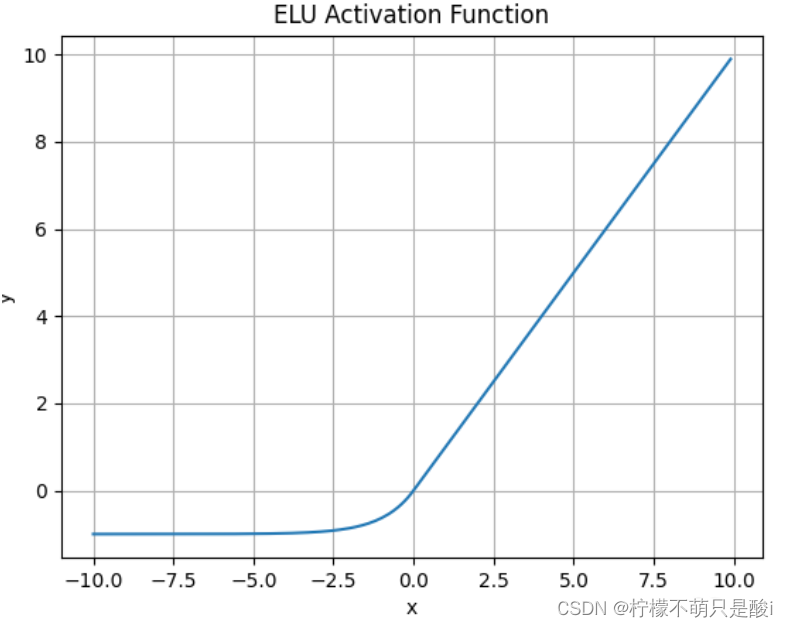
③ ELU激活函数
数学表达式为:
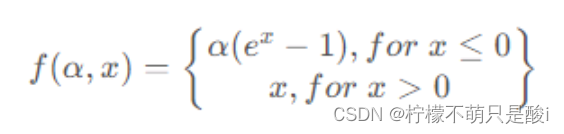
1.3pytorch安装+入门
1、pytorch安装
2、Tensor张量
各种数值数据称为张量。
0阶张量:常数 scaler
1阶张量:向量vector
2阶张量:矩阵matrix
3阶张量:...
3、张量的创建方法
打开jupyter,使用命令jupyter notebook
(1)使用python中的列表或者序列创建tensor

(2)使用numpy中的数组创建tensor


(3)使用torcch的api创建tensor
①torch.empty(3,4) 创建3行4列的空的tensor,会用无用数据进行填充。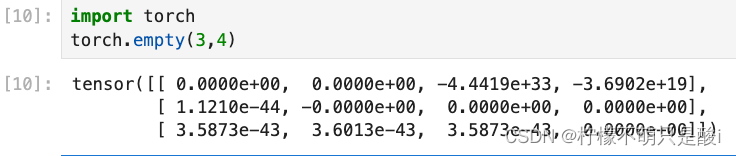
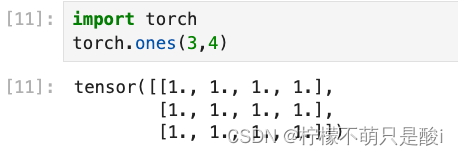
②torch.ones(3,4) 创建3行4列的全为1 的tensor
③torch.zeros(3,4) 创建3行4列的全为0的tensor

④torch.rand(3,4) 创建3行4列的随机值的tensor,随机值的区间是[0,1)
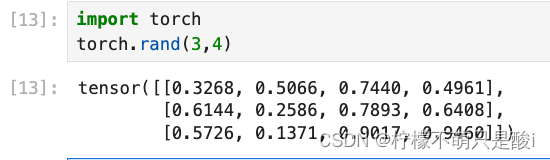
⑤torch.randint( low = 0,high = 10, size = [3,4]) 创建3行4列的随机整数的tensor,随机值的区间是[ low,high)

⑥torch.randn([3,4]) 创建3行4列的随机数的tensor ,随机值的分布均值为0,方差为1
(这里的randn ,n表示normal)
4、张量的方法和属性
(1)获取tensor中的数据(当tensor中只有一个元素可用):tensor.item( )

(2)转化为numpy数组
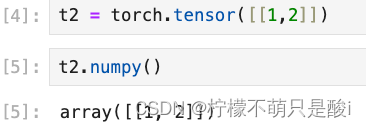
(3)获取形状:tensor.size()
tensor.size(0) 获取第一个维度的形状

(4)形状改变:tensor.view((3,4)) 。类似numpy中的reshape,是一种浅拷贝,仅仅是形状发生改变。
(5)获取维数:tensor.dim()
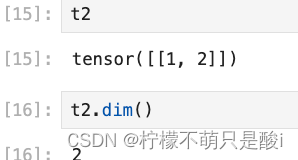
(6)获取最大值:tensor.max()

(7)转置:tensor.t() 二维
高维:tensor.transpose(1,2) 将第一维度和第二维度交换、tensor.permute(0,2,1)

(8)获取tensor[1,3] 获取tensor中第一行第三列的值。(行和列的索引都是从0开始)

(9)tensor[1,3] 对tensor中第一行,第散列的位置进行赋值。
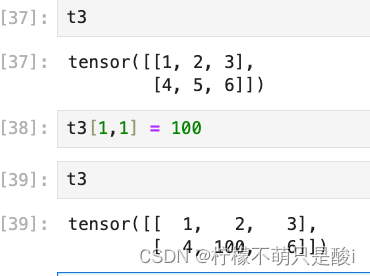
(10)tensor切片:

图片所示,取了第一列。
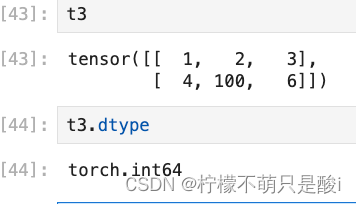
5、tensor的数据类型
(1)获取tensor 的数据类型:tensor.dtype
(2)创建数据的时候指定类型

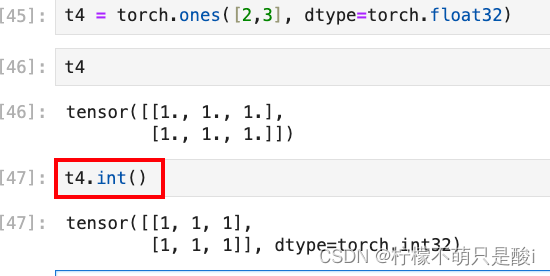
(3)类型的修改
6、tensor的其他操作
(1)tensor 和 tensor相加。
x.add(y) 不会直接修改x的值。
x.add_(y) 会直接修改x的值。⚠️

(2)tensor和数字操作

(3)CUDA中的tensor
通过.to 方法能够把一个tensor转移到另外一个设备(比如从CPU转到GPU)

# 实例化device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 把tensor转化为CUDA支持的tensor,或者cpu支持的tensor
tensor.to(device)1.4梯度下降和反向传播
1、梯度
概念:梯度是一个向量,导数+变化最快的方向(学习的前进方向)
回顾下机器学习:
① 收集数据x,构建机器学习模型f,得到f(x,w) = Ypredict
②判断模型好坏的方法:
loss = (Ypredict - Ytrue)^2 ( 回归损失)
loss = Ytrue · log(Yredict) (分类损失)③目标:通过调整(学习)参数w,尽可能的降低loss。
2、梯度下降
算出梯度、
3、常见的导数的计算
链式法则、求偏导数、
4、反向传播
(1)前向传播:将训练集数据输入到ANN的输入层,经过隐藏层,最后到达输出层并输出结果。【输入层—隐藏层–输出层】
(2)反向传播:由于ANN的输入结果与输出结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层。【输出层–隐藏层–输入层】
(3)权重更新:在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
5、使用Pytorch完成线性回归
(1)tensor(data, requires_grad = True)
① 该tensor后续会被计算梯度、tensor所有的操作都会被记录在grade_in
② 当requires_grad = True时,tensor.data 和 tensor不相同。否则,得到是相同的结果。
(2)with torch.no_grad()
其中的操作不会被跟踪
(3)反向传播:output.backward()
(4)获取某个参数的梯度:x.grad 累加梯度,每次反向传播之前需要先把梯度置为0之后。
6、手动实现线性回归。
假设基础模型y=wx+b , 其中w和b均为参数,我们使用y = 3x+0.8 来构造数据x,y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。
(1)准备数据(2)计算预测值
(3)计算损失,把参数的梯度置为0,进行反向传播(4)更新参数
import torch
import matplotlib.pyplot as plt
learning_rate = 0.01 # 定义一个学习率# 1、准备数据
"""
y = wx + b
y = 3x + 0.8
"""
x = torch.rand([100, 1])
y_true = x*3 + 0.8# 2、通过模型计算 y_project
w = torch.rand([1, 1], requires_grad=True)
b = torch.tensor(0, requires_grad=True, dtype=torch.float32)# 4、通过循环,反向传播,更新参数
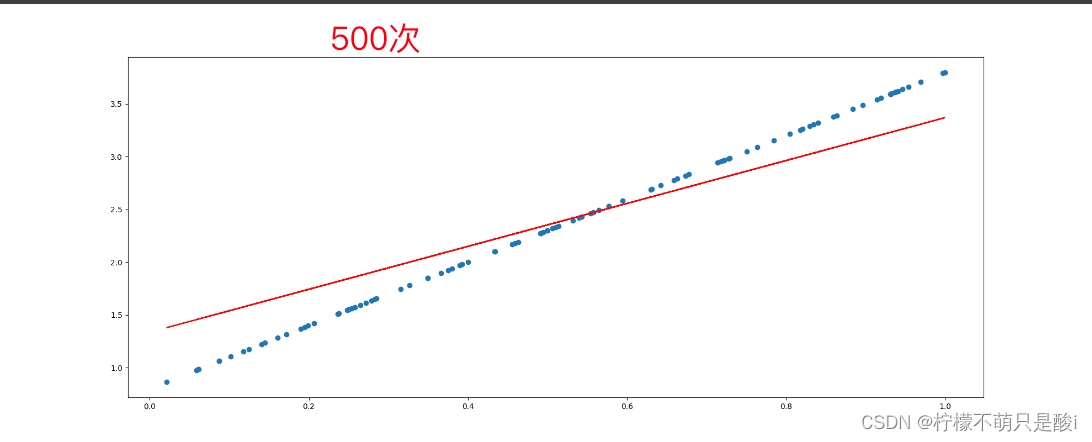
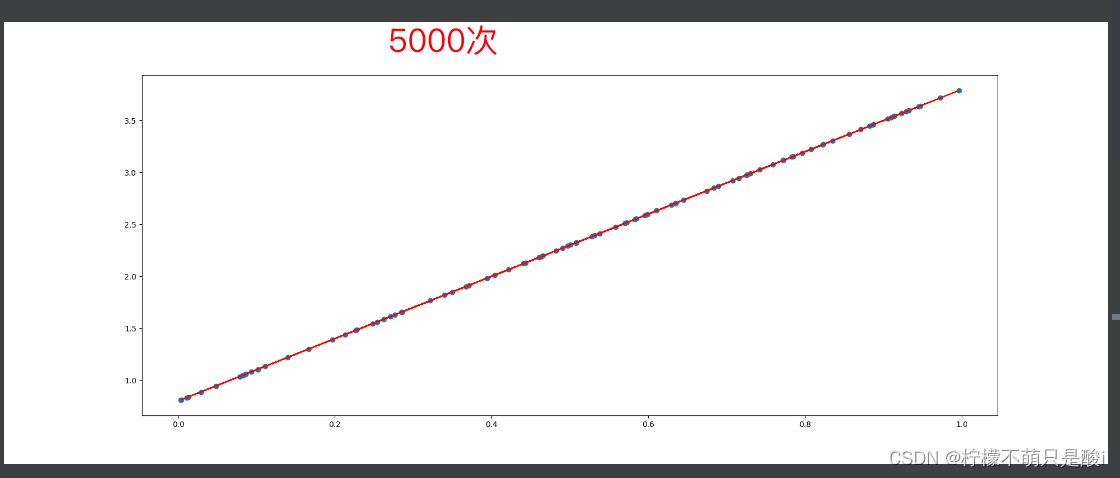
for i in range(500):# 3、计算lossy_predict = torch.matmul(x, w) + bloss = (y_true - y_predict).pow(2).mean() # 平方,再均值if w.grad is not None: # 将梯度置为0w.grad.data.zero_()if b.grad is not None:b.grad.data.zero_()loss.backward() # 反向传播w.data = w.data - learning_rate * w.gradb.data = b.data - learning_rate * b.gradprint(f"w:{w.item()},b:{b.item()},loss:{loss.item()}")# 画图
plt.figure(figsize=(20, 8))
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1))
y_predict = torch.matmul(x, w) + b
plt.plot(x.numpy().reshape(-1), y_predict.detach().reshape(-1), c='r')
plt.show()
7、nn.Module
nn.Module 是torch.nn提供的一个类,是pytorch 中我们自定义网络的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类定义网络的时候非常简单。
相关文章:
day01 深度学习介绍
目录 1.1深度学习介绍 1.2神经网络NN 1、概念: 2、神经元 3、(单层)神经网络 4、感知机(两层) 5、多层神经网络 6、激活函数 (1)饱和与非饱和激活函数 (2)饱和激活…...
k8s 部署 Nginx 并代理到tomcat
一、已有信息 [rootmaster nginx]# kubectl get nodes -o wide [rootmaster nginx]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2…...

医学图像的数据增强技术 --- 切割-拼接数据增强(CS-DA)
医学图像的新型数据增强技术 CS-DA 核心思想自然图像和医学图像之间的关键差异CS-DA 步骤确定增强后的数据数量 代码复现 CS-DA 核心思想 论文链接:https://arxiv.org/ftp/arxiv/papers/2210/2210.09099.pdf 大多数用于医学分割的数据增强技术最初是在自然图像上开…...
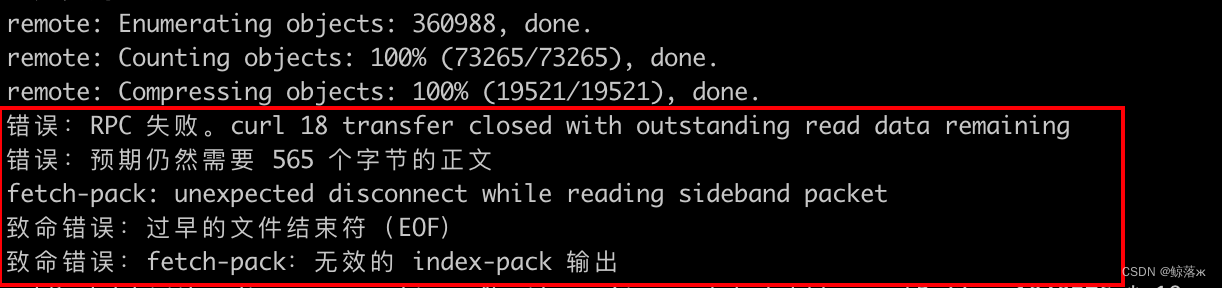
git克隆/拉取报错过早的文件结束符(EOF)的原因及解决
近期使用git拉取仓库的时候,拉取了好几次都不行,总是反馈说过早的文件结束符 总是这样,当然我的报错信息并没有描述完整,因为在我检索此类问题的时候,我发现有好多种所谓的过早的文件结束符这样的报错,但是…...

【ARM 嵌入式 编译系列 2.5 -- GCC 编译参数学习 --specs=nano.specs选项 】
请阅读【嵌入式开发学习必备专栏 之 ARM GCC 编译专栏】 文章目录 概述nano.specs示例使用注意事项问题总结概述 ARM 工具链 (arm-none-eabi-) 包括了一个叫作 --specs 的编译器和链接器选项,这个选项允许用户指定一个或多个 “specs” 文件,以影响编译或链接阶段的行为。Sp…...
构造函数和析构函数)
C语言大师(5)构造函数和析构函数
引言 在C的面向对象编程中,构造函数和析构函数扮演着至关重要的角色。它们分别管理对象的初始化和销毁过程,确保资源的有效分配和释放。了解这些函数如何工作,对于编写高效和可靠的C程序至关重要。 1. 构造函数 构造函数在每次创建类的新对…...
安全审查常见要求
一、是否有密码复杂度策略、是否有密码有效期 1)密码长度至少8位; 2)要求用户密码必须包含大小写字母、数字、特殊字符 3)避免常见密码 123456,qwerty, password; 4) 强制用户定期修改密码; 5&#x…...

最新 生成pdf文字和表格
生成pdf文字和表格 先看效果 介绍 java项目,使用apache的pdfbox工具,可分页,自定义列 依赖 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.22<…...
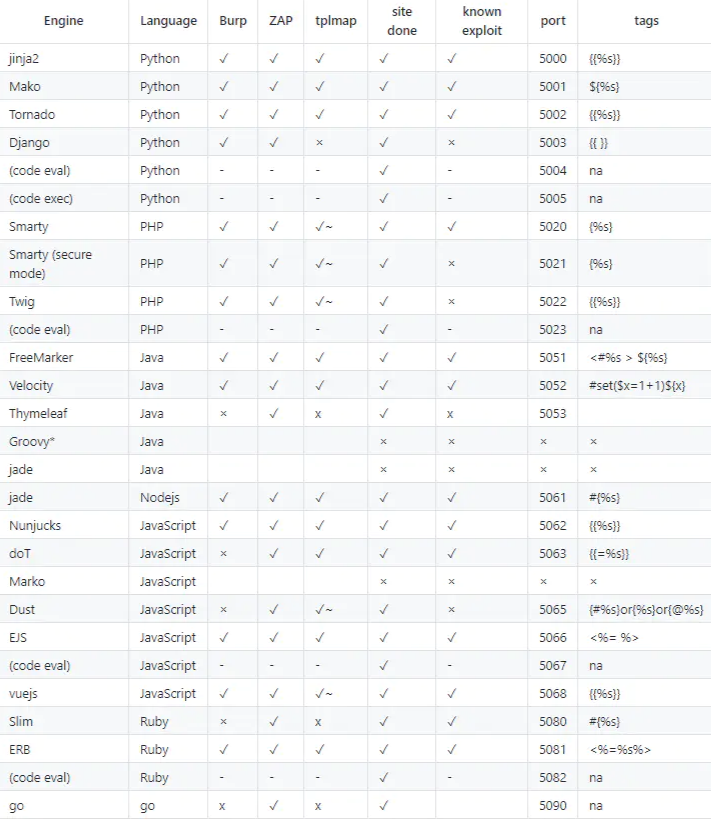
安全基础~攻防特性3
文章目录 SSTI(模板注入)1. 简介2. 成因3. 常见框架存在注入4. 判断存在SSTI SSTI(模板注入) 1. 简介 (Server-Side Template Injection) 服务端模板注入 1、使用框架(MVC的模式),如python的flask,php的tp,java的sp…...
Windows7关闭谷歌浏览器提示“若要接收后续 Google Chrome 更新,您需使用 Windows 10 或更高版本”的方法
背景 电脑比较老,系统一直没有更新,硬件和软件版本如下: 操作系统版本:Windows7 企业版 谷歌浏览器版本:109.0.5414.120(正式版本) (64 位) 该版本的谷歌浏览器是支持…...

[一]ffmpeg音视频解码
[一]ffmpeg音视频解码 一.编译ffmpeg1.安装vmware虚拟机2.vmware虚拟机安装linux操作系统3.安装ftp和fshell软件4.在Ubuntu(Linux)中编译Android平台的FFmpeg( arm和x86 )5.解压FFmpeg6.Android编译脚本(1)…...
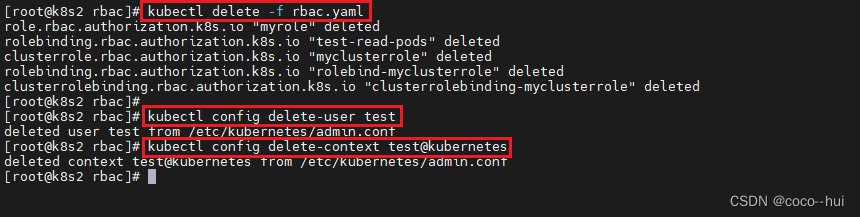
k8s-认证授权 14
Kubernetes的认证授权分为认证(鉴定用户身份)、授权(操作权限许可鉴别)、准入控制(资源对象操作时实现更精细的许可检查)三个阶段。 Authentication(认证) 认证方式现共有8种&…...
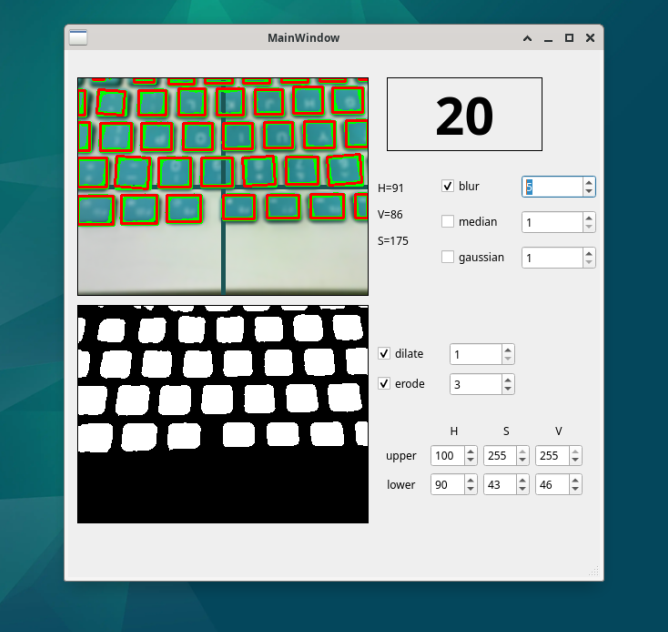
在全志H616核桃派上实现USB摄像头的OpenCV颜色检测
在给核桃派开发板用OpenCV读取图像并显示到pyqt5的窗口上并加入颜色检测功能,尝试将图像中所有蓝色的东西都用一个框标记出来。 颜色检测核心api 按照惯例,先要介绍一下opencv中常用的hsv像素格式。颜色还是那个颜色,只是描述颜色用的参数变…...

mac安装部署gitbook教程
mac安装部署gitbook教程 前言一、安装准备二、GitBook安装三、项目初始化 前言 一些自己实际操作的记录。 一、安装准备 Node.js gitbook基于Node.js,所以需要提前安装。 下载地址:https://nodejs.org/en/,可以下载比较新的版本。(但我的建议…...

有关软件测试的,任何时间都可以,软件测试主要服务项目:测试用例 报告 计划
有关软件测试的,任何时间都可以,软件测试主要服务项目: 1. 测试用例 2. 测试报告 3. 测试计划 4. 白盒测试 5. 黑盒测试 6. 接口测试 7.自动…...

快乐过寒假,安全不放假
寒假将至,春节即来,为了使孩子们过上一个平安、快乐、文明、祥和、健康、有益的寒假和春节,在共青团永宁县委员会、永宁县望洪镇人民政府的大力支持下,在永宁新华中心村校外少工委的积极配合下,1月20日下午宁夏妇女儿童…...

qt学习:模仿qq界面+添加资源+无边框界面+修改样式
目录 一,创建登录ui界面类 LoginWidget 二,添加图片资源 三,通过样式的方法将图片设置成圆圈的背景 四,新建登录后的ui界面 MWindow 简陋的就可以,因为只为了学习,可以自己补充 五,新建三个嵌套ui界面类,ChatWidget聊天界面 FriendWiidget好友界面 CollectW…...

【Linux】基本指令收尾
文章目录 日期查找打包压缩系统信息Linux和Windows互传文件 日期 这篇是基本指令的收尾了,还有几个基本指令我们需要说一下 首先是Date,它是用来显示时间和日期 直接输入date的话显示是有点不好看的,所以我们可以根据自己的喜欢加上分隔符&…...

精准核酸检测 - 华为OD统一考试
OD统一考试(C卷) 分值: 100分 题解: Java / Python / C 题目描述 为了达到新冠疫情精准防控的需要,为了避免全员核酸检测带来的浪费,需要精准圈定可能被感染的人群。 现在根据传染病流调以及大数据分析&a…...
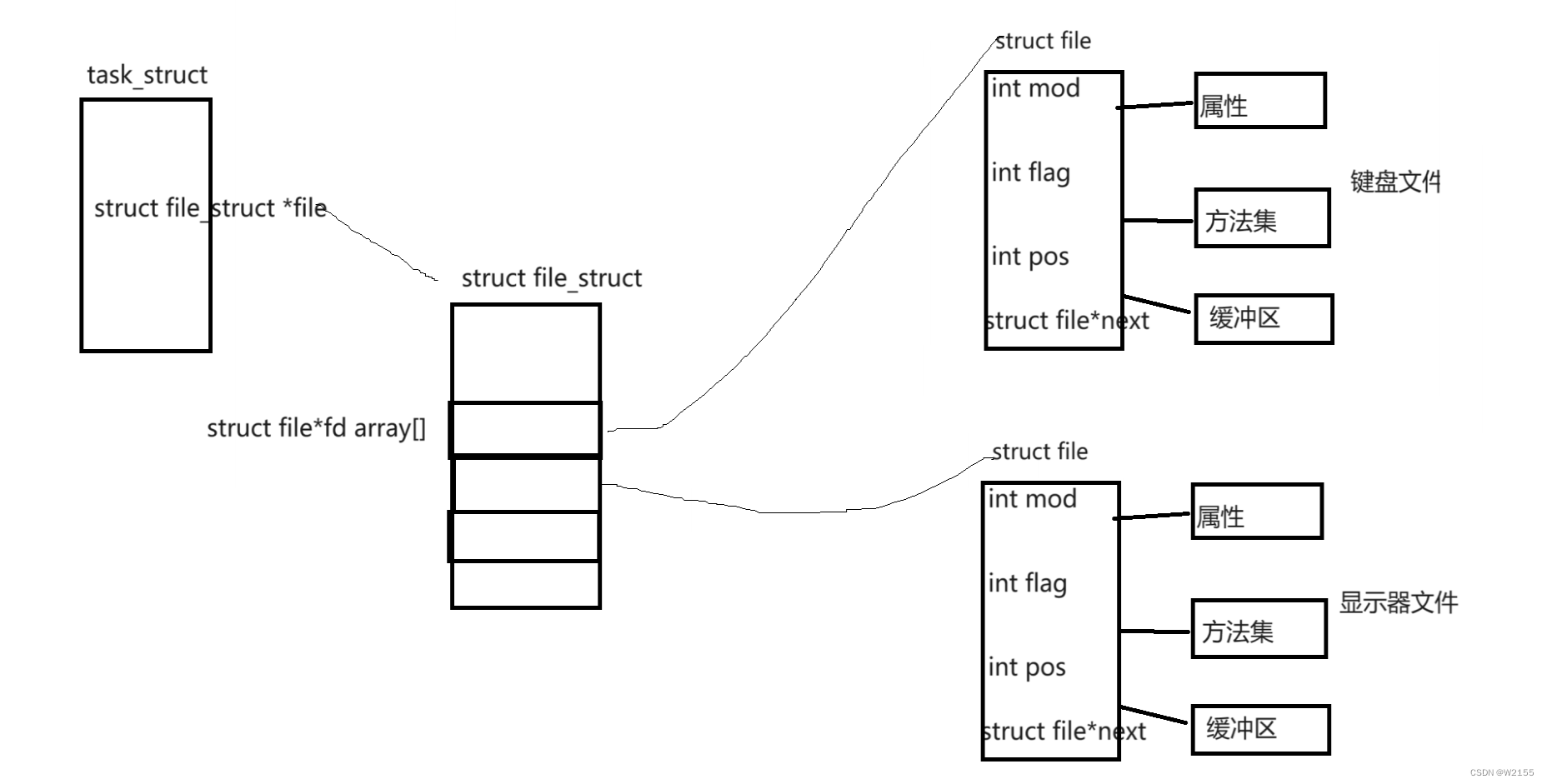
LINUX文件fd(file descriptor)文件描述符
目录 1.文件接口 1.1open 1.2C语言为什么要对open进行封装 2.fd demo代码 第一个问题 第二个问题 打开文件流程 引言:在学习C语言的时候,我们见过很多的文件的接口,例如fopen,fwrite,fclose等等,但…...

保姆级教程:用QGIS的SRTM-Downloader插件,5分钟搞定中国区域地形图下载与渲染
5分钟极速出图:QGIS地形图制作全流程实战指南 当你在凌晨三点赶制项目报告,或是课程作业截止前两小时突然需要一张专业地形图时,传统GIS软件的复杂操作流程往往让人抓狂。本文将带你用QGIS的SRTM-Downloader插件,像点外卖一样简单…...

5个核心功能技巧:用MPh实现COMSOL仿真自动化
5个核心功能技巧:用MPh实现COMSOL仿真自动化 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh 你是一个文章写手,你负责为开源项目写专业易懂的文章。今天我们要介绍…...

嵌入式边缘AI论坛参会全攻略:从技术趋势到实战社交
1. 论坛核心价值与参会目标拆解“6天倒计时!”这个标题,精准地抓住了所有技术从业者在面对一个高价值行业活动时,那种既兴奋又略带紧迫感的共同心理。这不仅仅是一个简单的会议通知,它更像是一份来自同行的“战前简报”。对于嵌入…...

基于RP2040与CircuitPython的互动声光按钮:从硬件到代码的完整实现
1. 项目概述:一个能听会“说”的互动按钮几年前,我第一次接触嵌入式开发时,被那些能感知物理世界并做出回应的“智能”小玩意儿深深吸引。从简单的闪烁LED,到能根据环境光调整亮度的灯带,再到能播放声音的互动装置&…...

转向现代C++——优先选用限定作用域的枚举型别,而非不限作用域的枚举型别
文章目录优先选用限定作用域的枚举型别,而非不限作用域的枚举型别名字空间污染强类型安全与隐式转换前置声明特例:什么时候不限作用域的 enum 更好?现代 C 的替代方案(C17 结构化绑定)优先选用限定作用域的枚举型别&am…...

Adams新手避坑指南:从几何点、Marker坐标系到立方体,这些基础元素你真的用对了吗?
Adams新手避坑指南:几何元素背后的工程逻辑与实战陷阱 刚接触Adams的工程师常会陷入一个误区——把软件操作手册当作圣经,却忽略了每个几何元素背后的物理意义和工程逻辑。这种"知其然不知其所以然"的学习方式,往往会导致仿真结果失…...
)
JDK 17 + Hadoop 3.3.5 + Spark 3.3.2 集群搭建保姆级避坑指南(CentOS 8.5 + VMware)
JDK 17 Hadoop 3.3.5 Spark 3.3.2 集群搭建实战避坑手册 当你第一次尝试在本地环境搭建大数据集群时,是否曾被各种兼容性问题、配置错误和莫名其妙的报错折磨得焦头烂额?本文将带你完整走一遍从零开始搭建基于JDK 17、Hadoop 3.3.5和Spark 3.3.2的集群…...

从电路哲学到工程实践:无源与有源器件设计心法全解析
1. 从“人生如电路”到“玩电路设计,也可以这样有情怀”看到“人生如电路”这个比喻,很多电子爱好者或工程师都会心一笑。它把抽象的电子元件特性,巧妙地映射到我们每个人的学习、工作和生活状态上,确实挺有道理,也很有…...

别再死磕GAN了!用PyTorch从零实现DDPM扩散模型,手把手带你跑通CIFAR-10生成
从GAN到DDPM:用PyTorch实战扩散模型的图像生成革命 当我在2022年第一次看到DALLE 2生成的超现实图像时,作为一名长期使用GAN的开发者,我意识到生成式AI正在经历一场静默的革命。传统GAN虽然能生成惊艳的结果,但其训练过程就像在钢…...

Python股票数据查询工具:适配器模式与缓存策略实战
1. 项目概述:一个股票价格查询工具的核心价值最近在GitHub上看到一个挺有意思的项目,叫tjefferson/stock-price-query。光看名字,你可能会觉得这不就是个简单的数据抓取脚本吗?市面上类似的工具一抓一大把。但作为一个在金融数据和…...