python进程间通信——命名管道(Named Pipe、FIFO)
文章目录
- Python中的命名管道:深入理解进程间通信
- 1. 命名管道简介
- 2. 创建和删除命名管道
- 3. 写入命名管道
- 4. 读取命名管道
- 5. 示例:进程间通信
- write_to_pipe.py
- read_from_pipe.py
- 测试运行
- 6. 注意事项和限制
- 命名管道的半双工机制
- 命名管道读写任意一方未打开,另一方默认阻塞(可以尝试使用非阻塞方式打开`os.O_NONBLOCK`)
- 命名管道能被读写多方同时打开,但数据只能从某个写方到某个读方,不会产生数据复制现象(这属于非常规操作,不要这样使用)
- 命名管道权限问题
- 7. 命名管道非阻塞打开示例
- 说明
- 情况1:读取进程以阻塞方式打开命名管道,写入进程以非阻塞方式打开命名管道
- write_to_pipe_nonblock.py
- read_from_pipe_block.py
- 测试运行
- 额外功能:申请缓存帧
- 情况2:读取进程以非阻塞方式打开命名管道,写入进程以阻塞方式打开命名管道
- write_to_pipe_block.py
- read_from_pipe_nonblock.py
- 测试运行
- 注意事项
- 读进程报`BlockingIOError`错误
- 结论
Python中的命名管道:深入理解进程间通信
命名管道(Named Pipe),也被称为FIFO,是一种在UNIX、Linux和类Unix系统中用于实现进程间通信(IPC)的机制。在Python中,我们可以使用os模块来创建和操作命名管道。
1. 命名管道简介
命名管道与普通管道类似,都是基于字节流进行通信的,但不同的是命名管道有路径名与之关联,并且其生命周期超过了引发创建它的进程。这使得不相关的进程可以通过命名管道进行通信。
2. 创建和删除命名管道
在Python中,我们可以使用os.mkfifo()函数创建一个命名管道。该函数接受两个参数,第一个参数是要创建的命名管道的路径,第二个参数是管道的权限设置,它是可选的,默认值为0o666。
import ospipe_name = "my_pipe"# 创建命名管道
os.mkfifo(pipe_name)
当你不再需要这个命名管道时,可以使用os.unlink()或os.remove()函数删除它。
# 删除命名管道
os.unlink(pipe_name)
3. 写入命名管道
要向命名管道写入数据,我们首先需要使用os.open()函数以写入模式打开它。然后,可以使用os.write()函数写入数据。
pipeout = os.open(pipe_name, os.O_WRONLY)message = "Hello, World!"# 写入数据
os.write(pipeout, message.encode())# 关闭管道
os.close(pipeout)
注意,我们需要将要写入的字符串编码为字节对象,因为os.write()函数期望其参数是字节对象。
4. 读取命名管道
读取命名管道的数据与写入类似。我们首先使用os.open()函数以读取模式打开管道,然后使用os.read()函数读取数据。
pipein = os.open(pipe_name, os.O_RDONLY)# 读取数据
data = os.read(pipein, 100) # 读取前100个字节# 解码数据并打印
print(data.decode())# 关闭管道
os.close(pipein)
这里,我们使用了os.read()函数的两个参数版本,其中第二个参数指定要读取的最大字节数。如果不提供这个参数,os.read()函数将读取所有可用的数据。
5. 示例:进程间通信
现在让我们来看一个使用命名管道进行进程间通信的示例。假设我们有两个Python脚本,一个脚本负责向管道写入数据,另一个脚本负责从管道读取数据。
write_to_pipe.py
import ospipe_name = "my_pipe"# 创建命名管道
if not os.path.exists(pipe_name):os.mkfifo(pipe_name)pipeout = os.open(pipe_name, os.O_WRONLY)message = "Hello, World!"# 写入数据
os.write(pipeout, message.encode())# 关闭管道
os.close(pipeout)
read_from_pipe.py
import ospipe_name = "my_pipe"if os.path.exists(pipe_name):pipein = os.open(pipe_name, os.O_RDONLY)# 读取数据data = os.read(pipein, 100) # 读取前100个字节# 解码数据并打印print(data.decode())# 关闭管道os.close(pipein)
测试运行
在这个示例中,write_to_pipe.py脚本向命名管道写入一条消息,然后read_from_pipe.py脚本从同一个命名管道读取并打印这条消息。
无论先运行发送方,还是先运行接收方,另一方都会阻塞(等待):
(先运行发送方)

(先运行接收方)

当双方都开启,接收方才会收到消息,发送方也才会结束:


6. 注意事项和限制
虽然命名管道是一种非常有用的IPC机制,但在使用它时还需要注意一些事项。
命名管道的半双工机制
首先,命名管道是半双工的,这意味着数据只能(同一时间)在一个方向上流动。如果你需要实现全双工通信(即两个进程可以互相发送和接收数据),那么你需要创建两个命名管道。
注意:只用一个命名管道,两个进程交替进行读/写是可行的,但这需要非常谨慎的同步管理来确保正确的操作顺序和数据完整性,通常不建议这么使用。
命名管道读写任意一方未打开,另一方默认阻塞(可以尝试使用非阻塞方式打开os.O_NONBLOCK)
其次,当你尝试读取或写入一个没有打开的管道时,你的进程将被阻塞,直到管道的另一端被打开。为了避免这种情况,你可以在调用os.open()函数时使用os.O_NONBLOCK标志。
命名管道能被读写多方同时打开,但数据只能从某个写方到某个读方,不会产生数据复制现象(这属于非常规操作,不要这样使用)
命名管道权限问题
最后,当你使用命名管道时,需要考虑到权限和安全问题。任何有访问权限的进程都可以读写命名管道。因此,如果你的程序处理敏感信息,那么你应该小心地设置管道的权限,以防止未授权的访问。
7. 命名管道非阻塞打开示例
说明
对于大多数应用来说,通常只有一个进程(读或写)会以非阻塞方式打开命名管道,而另一个进程则以正常(阻塞)方式打开。这样可以确保当一方尝试读取或写入数据时,如果数据不可用或管道已满,那么该进程就会被阻塞,直到条件满足为止。
然而,在某些情况下,可能需要两个进程都以非阻塞方式打开命名管道。比如在某些实时系统或高性能计算中,进程不能接受任何形式的阻塞,即使是等待IPC操作也不行。在这种情况下,进程会以非阻塞方式打开命名管道,并使用轮询、事件通知或其他机制来检查是否可以进行读/写操作。
此外,还有一些特殊的情况,比如网络编程或者并发编程中,程序可能需要同时处理多个I/O操作(包括文件操作、网络操作和IPC操作等),并且不能因为任何一个操作的阻塞而停止处理其他操作。在这种情况下,程序可能会选择以非阻塞方式打开所有的I/O资源,包括命名管道,并使用select、poll、epoll等机制来高效地管理这些I/O操作。
但是,总体来说,除非有特殊的需求,否则通常不会让两个进程都以非阻塞方式打开命名管道。
情况1:读取进程以阻塞方式打开命名管道,写入进程以非阻塞方式打开命名管道
write_to_pipe_nonblock.py
import os
import timepipe_name = "my_pipe"# 创建命名管道
if not os.path.exists(pipe_name):os.mkfifo(pipe_name)pipeout = os.open(pipe_name, os.O_WRONLY | os.O_NONBLOCK)message = "Hello, World!"try:# 写入数据os.write(pipeout, message.encode())
except BlockingIOError:print("Pipe is full. Waiting...")# 关闭管道
os.close(pipeout)
read_from_pipe_block.py
import ospipe_name = "my_pipe"if os.path.exists(pipe_name):pipein = os.open(pipe_name, os.O_RDONLY) # 阻塞模式# 读取数据data = os.read(pipein, 100) # 读取前100个字节# 解码数据并打印print(data.decode())# 关闭管道os.close(pipein)
测试运行

write_to_pipe_nonblock.py脚本以非阻塞方式打开命名管道,并尝试写入一条消息。如果此时管道没有进程在读,os.open()函数将引发OSError;如果管道已满,os.write()函数将引发BlockingIOError异常。所以非阻塞写要求读进程先打开。
read_from_pipe_block.py脚本以阻塞方式打开同一个命名管道,并从中读取将要写入管道的消息。如果管道为空,那么os.read()函数将阻塞,直到有数据可读为止。
额外功能:申请缓存帧
客户端向缓存帧编码服务申请缓存帧的时候,可以先客户端先开启阻塞读,然后用http接口告知缓存帧编码服务自身已开启读监听,同时告知其监听的命名管道名和申请帧所属摄像头,然后缓存帧编码服务器取对应摄像头最新帧,用非阻塞写方式写到对应命名管道中,完成缓存帧交付。
情况2:读取进程以非阻塞方式打开命名管道,写入进程以阻塞方式打开命名管道
write_to_pipe_block.py
import os
import timepipe_name = "my_pipe"# 创建命名管道
if not os.path.exists(pipe_name):os.mkfifo(pipe_name)pipeout = os.open(pipe_name, os.O_WRONLY)message = "Hello, World!"try:# 写入数据os.write(pipeout, message.encode())
except BlockingIOError:print("Pipe is full. Waiting...")# time.sleep(5) # 确保读取进程有足够的时间来读取数据# 关闭管道
os.close(pipeout)read_from_pipe_nonblock.py
import ospipe_name = "my_pipe"if os.path.exists(pipe_name):pipein = os.open(pipe_name, os.O_RDONLY | os.O_NONBLOCK) # 阻塞模式# 读取数据#data = os.read(pipein, 100) # 读取前100个字节while True:try:data = os.read(pipein, 100)breakexcept BlockingIOError:continue# 解码数据并打印print(data.decode())# 关闭管道os.close(pipein)
测试运行
当没有阻塞写时,非阻塞读不会报错,会读到空内容:

当有阻塞写时,非阻塞读能正常读到内容:

注意事项
读进程报BlockingIOError错误
Traceback (most recent call last):File "read_from_pipe_nonblock.py", line 10, in <module>data = os.read(pipein, 100) # 读取前100个字节
BlockingIOError: [Errno 11] Resource temporarily unavailable
当你的读进程运行os.read()方法时,由于你使用了O_NONBLOCK标志打开了管道,如果此时管道中没有任何可供读取的数据,那么程序会立即返回一个BlockingIOError。
要解决这个问题,你可以尝试以下两种方法:
-
让你的读进程在尝试读取数据之前先等待一段时间,以确保写进程有足够的时间把数据写入管道。你可以使用time.sleep()函数来实现这个等待操作。
if os.path.exists(pipe_name):pipein = os.open(pipe_name, os.O_RDONLY | os.O_NONBLOCK) # 阻塞模式time.sleep(1) # 等待1秒# 然后进行读取操作... -
或者你可以捕获BlockingIOError异常,并在发生这种异常时再次尝试读取数据,直到成功为止。
while True:try:data = os.read(pipein, 100)breakexcept BlockingIOError:continue# 然后进行解码和打印操作...
结论
命名管道是UNIX和Linux系统中一种非常强大的IPC机制,它使得不相关的进程能够方便地进行通信。Python通过os模块提供了对命名管道的支持,使得我们可以很容易地在Python程序中使用这种机制。然而,尽管命名管道很有用,但在使用它时还需要注意其半双工性质、可能出现的阻塞情况,以及权限和安全问题。
相关文章:
python进程间通信——命名管道(Named Pipe、FIFO)
文章目录 Python中的命名管道:深入理解进程间通信1. 命名管道简介2. 创建和删除命名管道3. 写入命名管道4. 读取命名管道5. 示例:进程间通信write_to_pipe.pyread_from_pipe.py测试运行 6. 注意事项和限制命名管道的半双工机制命名管道读写任意一方未打开…...

03 OSPF 学习大纲
参考文章 1 初步认识OSPF的大致内容(第三课)-CSDN博客 2...

HJ7 取近似值【C语言】
【华为机试题 HJ7】取近似值 描述输入描述:输出描述:示例1示例2参考代码1参考代码2参考代码3描述 写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于 0.5 ,向上取整;小于 0.5 ,则向下取整。 数据范围:保证输入的数字在 32 位浮点数范…...
php基础学习之常量
php常量的基本概念 常量是在程序运行中的一种不可改变的量(数据),常量一旦定义,通常不可改变(用户级别)。 php常量的定义形式 使用define函数:define("常量名字", 常量值);使用cons…...

2024最新面试经验分享
目录 重点掌握的知识点JavaMySQLRedis 微服务分布式系统项目亮点场景题/设计题短链抢红包多租户 开放性问题自我介绍为什么跳槽团队规模如何带团队如何看待加班职业规划 主要针对Java程序员,当然也包含一些通用的内容。 重点掌握的知识点 需要重点掌握的知识点必须…...
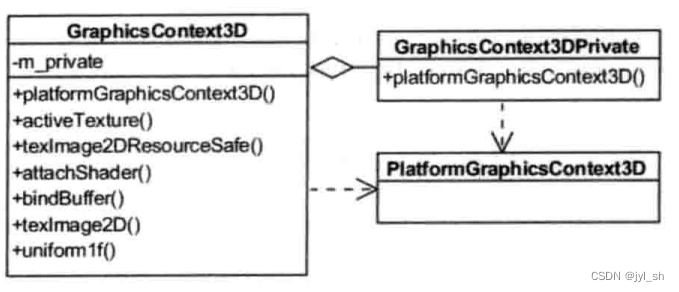
《WebKit 技术内幕》之八(1):硬件加速机制
《WebKit 技术内幕》之八(1):硬件加速机制 1 硬件加速基础 1.1 概念 这里说的硬件加速技术是指使用GPU的硬件能力来帮助渲染网页,因为GPU的作用主要是用来绘制3D图形并且性能特别好,这是它的专长所在,它…...
子表单扫码录入,显著节省填写时间
01/17 主要更新模块概览 扫 码 识 别 新 增 字 号 登 录 配 置 匹 配 搜 素 扫码识别 路径:表单设计 >> 字段属性 功能简介 之前对子表单扫码录入,是单独在组件内设置扫码,操作需重新点击扫码功能,手工新增子表数据&a…...

【Redis】Ubuntu安装配置
目录 一、安装Redis 1.1 从APT仓库安装Redis 二、启动&关闭&重启 三、Redis核心配置 3.1 CONFIG命令 3.2 redis.conf文件说明 一、安装Redis 1.1 从APT仓库安装Redis 从APT仓库可以安装最新的Redis稳定版,步骤如下: 【1】安装需要用到的…...

idea远程服务调试
1. 配置idea远程服务调试 这里以 idea 新 ui 为例,首先点击上面的 debug 旁边的三个小圆点,然后在弹出的框框中选择 “Edit”,如下图所示。 然后进入到打开的界面后,点击左上角的 “” 进行添加,找到 “Remote JVM De…...

Google Colab运行Pytorch项目
Google Colab运行Pytorch项目 连接google drive切换到某一文件夹显示当前目录文件安装依赖执行py文件numpy相关numpy.random.randn() 参考文章:文章1 文章2 连接google drive from google.colab import drive import os drive.mount(/content/drive)切换到某一文件…...
Android Studi安卓读写NDEF智能海报源码
本示例使用的发卡器:https://item.taobao.com/item.htm?id615391857885&spma1z10.5-c.w4002-21818769070.11.1f60789ey1EsPH <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmln…...

Demo: 实现PDF加水印以及自定义水印样式
实现PDF加水印以及自定义水印样式 <template><div><button click"previewHandle">预览</button><button click"downFileHandle">下载</button><el-input v-model"watermarkText" /><el-input v-mo…...

每日OJ题_算法_二分查找①_力扣704. 二分查找
目录 二分查找算法原理 力扣704. 二分查找 解析代码 二分查找算法原理 二分查找一种效率较高的查找方法。但是,二分查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。一般步骤如下: 首先,假设表中元素是按升…...

【Python】--- 基础语法(1)
目录 1.变量和表达式2.变量和类型2.1变量是什么2.2变量的语法2.3变量的类型2.3.1整数2.3.2浮点数(小数)2.3.3字符串2.3.4布尔2.3.5其他 2.4为什么要有这么多类型2.5动态类型特征 3.注释3.1注释的语法3.2注释的规范 结语 1.变量和表达式 对python的学习就…...

详解gorm中DB对象的clone属性
详解gorm中DB对象的clone属性 Gorm 版本:v1.22.4 Where函数源码 // Where add conditions func (db *DB) Where(query interface{}, args ...interface{}) (tx *DB) {tx db.getInstance()if conds : tx.Statement.BuildCondition(query, args...); len(conds) &…...
数据库(MySQL库表操作)
目录 1.1 SQL语句基础(SQL命令) 1.1.1 SQL的简介 1.1.2 SQL语句的分类 1.1.3 SQL语句的书写规范 1.2 数据库操作 1.2.1 查看 1.2.2 自建库 1.2.3 切换数据库 1.2.4 删库 1.3 MySQL字符集 1.3.1 MySQL字符集包括: 1.3.2 utf8 和 u…...
内网穿透的应用-如何使用Docker部署Redis数据库并结合内网穿透工具实现公网远程访问
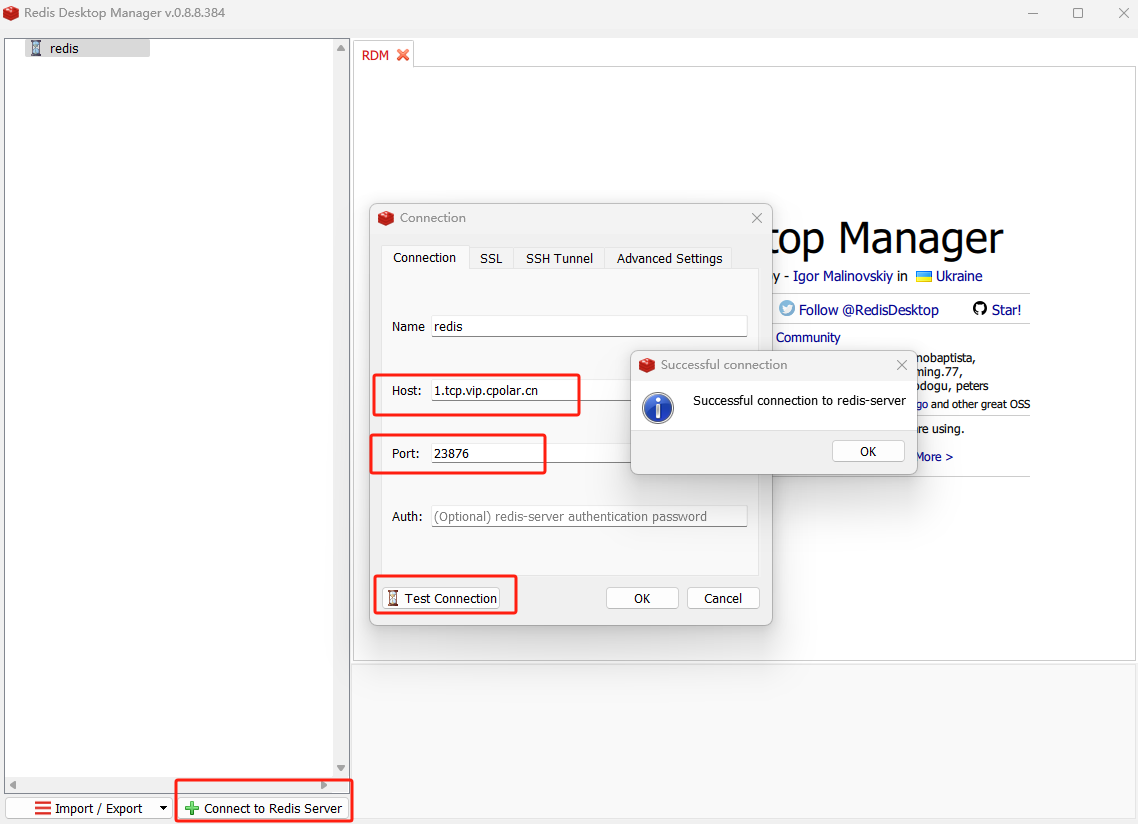
文章目录 前言1. 安装Docker步骤2. 使用docker拉取redis镜像3. 启动redis容器4. 本地连接测试4.1 安装redis图形化界面工具4.2 使用RDM连接测试 5. 公网远程访问本地redis5.1 内网穿透工具安装5.2 创建远程连接公网地址5.3 使用固定TCP地址远程访问 前言 本文主要介绍如何在Ub…...

计算机网络复试
第1章 概述 时延:发送(传输)时延传播时延 链路中每多一个路由器,就增加一个分组的发送时延 第2章 物理层 2.4 编码与调制->编码(基带调制)->曼彻斯特编码 ->带通调制->混合调制->正交振幅调制QAM 信道极限容量 奈氏准则 无噪声最大速…...

Android学习之路(23)组件化框架ARouter的使用
一、功能介绍 支持直接解析标准URL进行跳转,并自动注入参数到目标页面中支持多模块工程使用支持添加多个拦截器,自定义拦截顺序支持依赖注入,可单独作为依赖注入框架使用支持InstantRun支持MultiDex(Google方案)映射关系按组分类、多级管理&…...
HCIA vlan练习
目录 实验拓扑 实验要求 实验步骤 1、交换机创建vlan 2、交换机上的各个接口划分到对应vlan中 3、trunk干道 4、路由器单臂路由 5、路由器DHCP设置 实验测试 华为交换机更换端口连接模式报错处理 实验拓扑 实验要求 根据图划分vlan,并通过DHCP给主机下发…...

Unity HDRP 2023.2水系统实战:从清澈泳池到湍急溪流,5分钟调出电影感水体
Unity HDRP 2023.2水系统实战:从清澈泳池到湍急溪流,5分钟调出电影感水体 在游戏和影视级实时渲染中,水体的表现力往往决定了场景的沉浸感上限。Unity 2023.2的HDRP Water Surface系统通过物理参数的艺术化组合,让开发者无需编写着…...

AI迈向“自动驾驶”,零售回归“人间清醒”:2026商业底层逻辑正在重组
导读:2026年的初夏,商业世界正处在一个奇妙的交汇点。一边是AI编程正式宣告进入“无人驾驶”时代,生产力工具迎来质变;另一边,零售巨头们在狂热中开始自省,重新审视效率与人性的边界。从阿里、腾讯的智能体…...

Matlab 2020b隐藏技能:用Image Labeler制作自定义数据集,轻松喂给你的深度学习模型
Matlab 2020b图像标注实战:从零构建医学影像分割数据集 在医学影像分析领域,数据标注的质量直接决定了深度学习模型的性能上限。许多研究者花费大量时间调试模型结构,却忽略了最基础的数据准备环节。Matlab 2020b内置的Image Labeler工具&am…...

从CLIP到多模态:对比学习驱动的视觉-语言模型演进与实战
1. 对比学习:CLIP的基石与多模态革命 我第一次接触CLIP模型是在2021年初,当时OpenAI发布的这篇论文彻底颠覆了我对视觉模型训练方式的认知。传统计算机视觉任务总是离不开人工标注的海量数据,而CLIP却另辟蹊径,用自然语言作为监督…...
)
Labelme版本不兼容报错?手把手教你修改源码和JSON文件(附3.18.0与4.5.6对比)
Labelme版本兼容性实战:从源码修改到JSON批量处理的完整指南 当你正专注于一个重要的数据标注项目,突然遭遇"Error opening file lineColor"的红色报错框,整个团队的标注进度被迫停滞——这种场景对于使用Labelme进行图像标注的开发…...

SQL注入技术详解:从联合查询到盲注实战
前言: 继续开始我们的SQL注入吧!本文详细讲解SQL注入的各类技术,包括联合查询、报错注入、布尔盲注、时间盲注、UA注入、Referer注入等,涵盖漏洞判断、利用方法和实战步骤。内容基于MySQL 5.0以上环境,围绕information…...

如何用XUnity.AutoTranslator打破游戏语言壁垒:终极实时翻译插件指南
如何用XUnity.AutoTranslator打破游戏语言壁垒:终极实时翻译插件指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂的外语游戏而烦恼吗?XUnity.AutoTranslator正是你…...
)
【免费下载】 JIRA用户操作指南(详细版)
JIRA用户操作指南(详细版) 【下载地址】JIRA用户操作指南详细版 JIRA用户操作指南(详细版)欢迎使用JIRA用户操作指南,本指南旨在帮助您全面理解并高效地使用JIRA这一强大的问题跟踪与项目管理工具 项目地址: https:/…...

数组指针VS指针数组
【C语言】指针数组 VS 数组指针 原来这么简单! - 知乎 数组的名字就是数组首元素的指针。 判断指针类型指针口诀:先右后左,由近及远,括号优先。(从变量名看起) 指针数组: int *p[5] &…...
)
TVA智能体范式的工业视觉革命(7)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...