Spark UI中 Shuffle Exchange 和 BroadcastExchange 中的 dataSize 值为什么不一样
背景
Spark 3.5
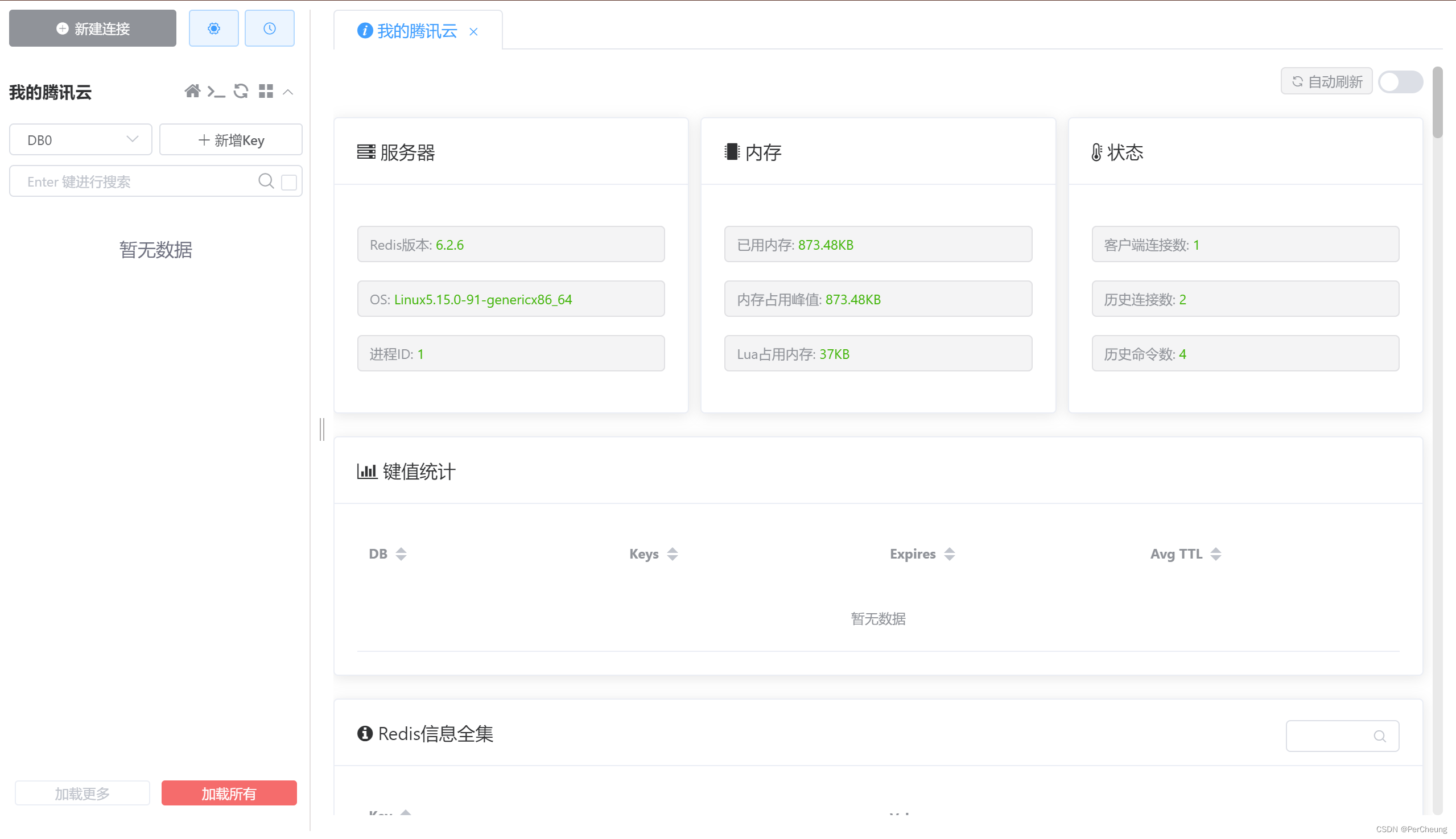
最近在看Spark UI 上的一些指标看到一个很有意思的东西, 相邻的Shuffle Exechange 和 BroadcastExechange 中的 datasize 居然不一样,
前者为 765KB, 后者为 64.5MB。差别还不少,中间就增加了一个 AQEShuffleRead 计划
结论
Shuffle Exechange 中的是真实 UnsafeRow的大小
BroadcastExechange 中的是 MemoryBlock 类型数据结构所占的大小 ,而不是UnsafeRow的大小。
且BroadcastExechange中的datasize大小 和 2的整数倍接近。
现象以及分析
上图:
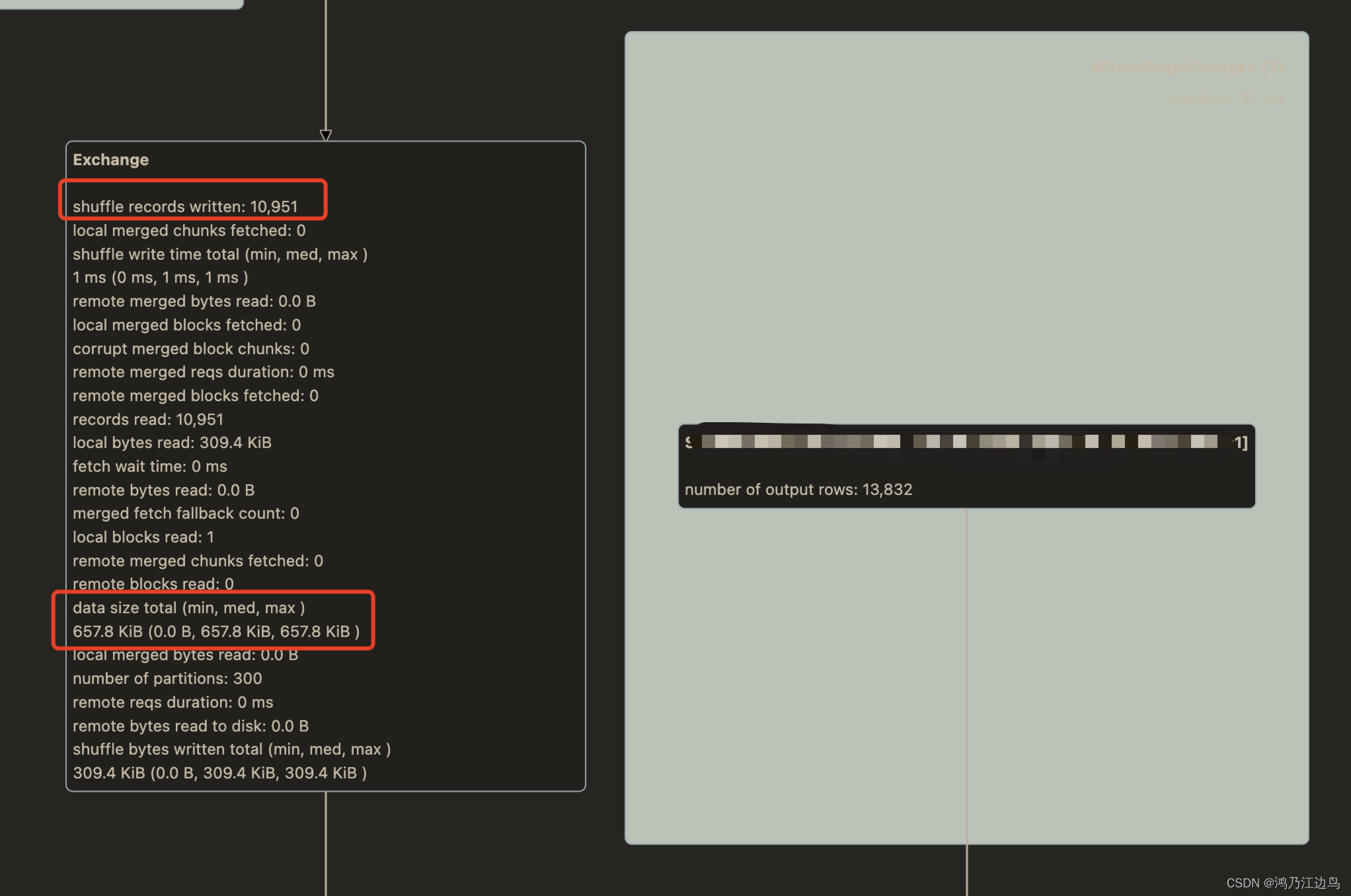
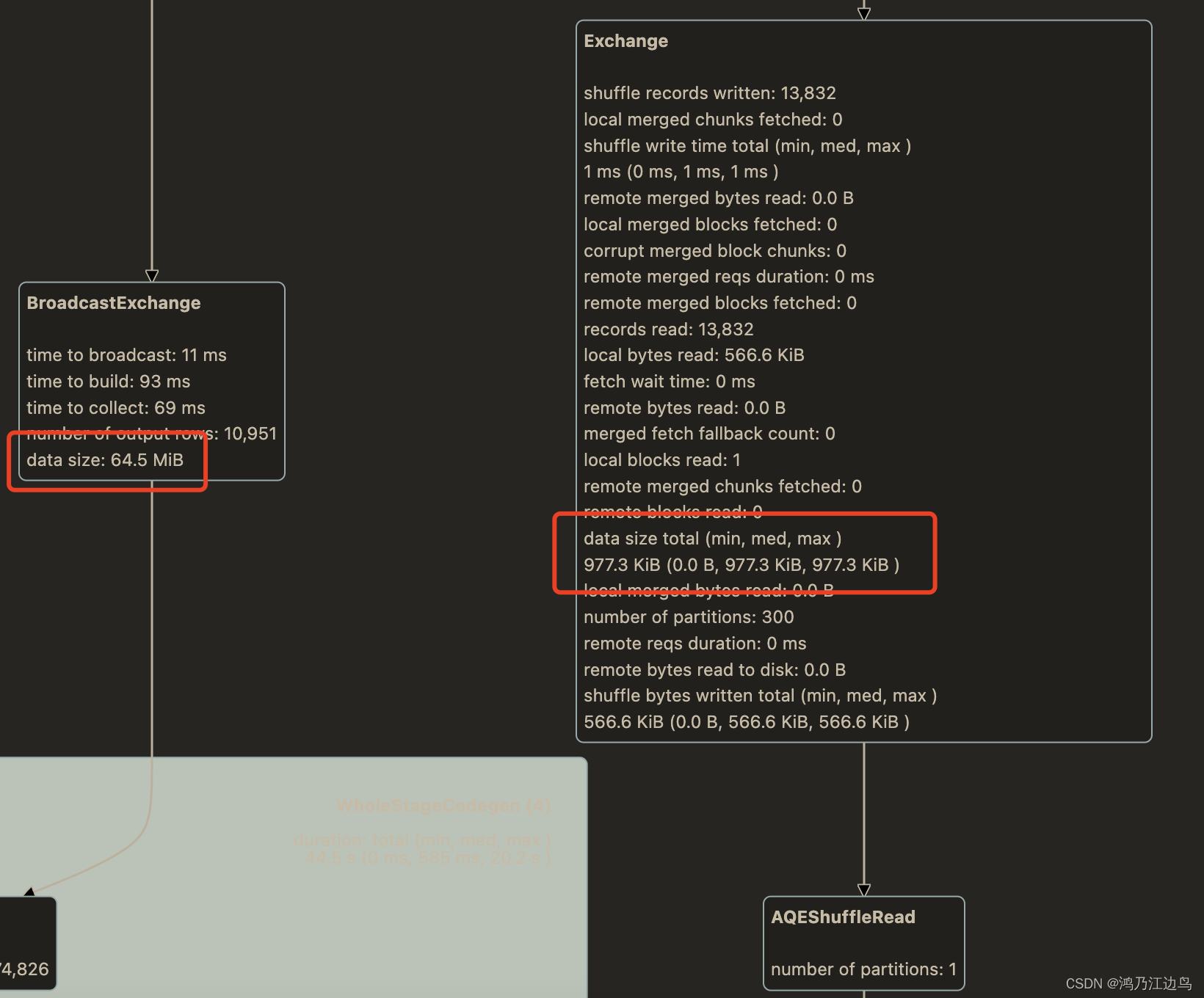

两个同样的 ShuffleExechange 记录条数和 ShuffleExechange 中 datasize 大小不一样,而在BroadcastExechange 中 dataSize 大小却是一样的(都是64.5MB)
关于 ShuffleExchange中的 dataSize的计算可以参考:Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别,这里重点分析一下后者.
直接看BroadcastExechange代码:
override lazy val relationFuture: Future[broadcast.Broadcast[Any]] = {SQLExecution.withThreadLocalCaptured[broadcast.Broadcast[Any]](session, BroadcastExchangeExec.executionContext) {try {// Setup a job tag here so later it may get cancelled by tag if necessary.sparkContext.addJobTag(jobTag)sparkContext.setInterruptOnCancel(true)val beforeCollect = System.nanoTime()// Use executeCollect/executeCollectIterator to avoid conversion to Scala typesval (numRows, input) = child.executeCollectIterator()...val relation = mode.transform(input, Some(numRows))val dataSize = relation match {case map: HashedRelation =>map.estimatedSizecase arr: Array[InternalRow] =>arr.map(_.asInstanceOf[UnsafeRow].getSizeInBytes.toLong).sumcase _ =>throw new SparkException("[BUG] BroadcastMode.transform returned unexpected " +s"type: ${relation.getClass.getName}")}longMetric("dataSize") += dataSize
其中child.executeCollectIterator() 是在把数据从各个 Executor 收集到 Driver 端来,便于进行广播操作。
最主要的是 mode.transform(input, Some(numRows)),这里的数据流如下:
HashedRelationBroadcastMode.transform||\/
HashedRelation.apply(rows, key, numRows.toInt, isNullAware = isNullAware)||\/
UnsafeHashedRelation.apply(input, key, sizeEstimate, mm, isNullAware, allowsNullKey,ignoresDuplicatedKey)||\/
new UnsafeHashedRelation(key.size, numFields, binaryMap)最终调用的 UnsafeHashedRelation.estimatedSize的方法:
override def estimatedSize: Long = binaryMap.getTotalMemoryConsumption而 getTotalMemoryConsumption 是dataPages所占用的大小再加上longArray的大小:
public long getTotalMemoryConsumption() {long totalDataPagesSize = 0L;for (MemoryBlock dataPage : dataPages) {totalDataPagesSize += dataPage.size();}return totalDataPagesSize + ((longArray != null) ? longArray.memoryBlock().size() : 0L);}那么 BytesToBytesMap 是怎么分配的呢?如下:
val binaryMap = new BytesToBytesMap(taskMemoryManager,// Only 70% of the slots can be used before growing, more capacity help to reduce collision(sizeEstimate * 1.5 + 1).toInt,pageSizeBytes)默认的PageSize值为:defaultPageSizeBytes:
private lazy val defaultPageSizeBytes = {val minPageSize = 1L * 1024 * 1024 // 1MBval maxPageSize = 64L * minPageSize // 64MBval cores = if (numCores > 0) numCores else Runtime.getRuntime.availableProcessors()// Because of rounding to next power of 2, we may have safetyFactor as 8 in worst caseval safetyFactor = 16val maxTungstenMemory: Long = tungstenMemoryMode match {case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.poolSizecase MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.poolSize}val size = ByteArrayMethods.nextPowerOf2(maxTungstenMemory / cores / safetyFactor)val chosenPageSize = math.min(maxPageSize, math.max(minPageSize, size))if (Utils.isG1GC && tungstenMemoryMode == MemoryMode.ON_HEAP) {chosenPageSize - Platform.LONG_ARRAY_OFFSET} else {chosenPageSize}}这个跟内存以及core有关。
当在进行val loc = binaryMap.lookup 以及loc.append操作的时候就会进行dataPage以及longArray的分配。而该size的大小并不是实际占用的大小,而是分配给该dataPage的大小。其实你会发现该datasize的大小几乎和2的倍数接近。
相关文章:
Spark UI中 Shuffle Exchange 和 BroadcastExchange 中的 dataSize 值为什么不一样
背景 Spark 3.5 最近在看Spark UI 上的一些指标看到一个很有意思的东西, 相邻的Shuffle Exechange 和 BroadcastExechange 中的 datasize 居然不一样, 前者为 765KB, 后者为 64.5MB。差别还不少,中间就增加了一个 AQEShuffleRead 计划 结论 Shuffle E…...

阿里云优惠券领取入口、使用方法和限制条件,2024最新
阿里云优惠代金券领取入口,阿里云服务器优惠代金券、域名代金券,在领券中心可以领取当前最新可用的满减代金券,阿里云百科aliyunbaike.com分享阿里云服务器代金券、领券中心、域名代金券领取、代金券查询及使用方法: 阿里云优惠券…...
自己构建webpack+vue3+ts
先看看我的目录结构(我全局使用TS): 一、安装配置webpack打包 安装esno npm install esnoesno 是基于 esbuild 的 TS/ESNext node 运行时,有了它,就可以直接通过esno *.ts的方式启动脚本,package.json中添加 type:…...
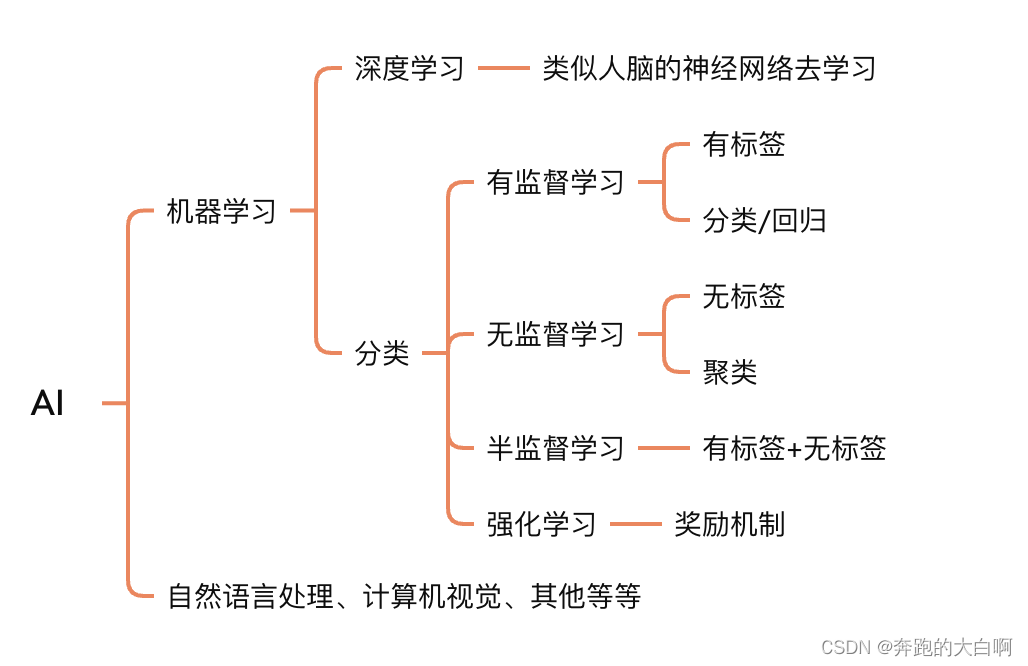
【AI】小白入门笔记
前言 2024年,愿新年胜旧年!作为AI世界的小白,今天先来从一些概念讲起,希望路过的朋友们多多指教! 正文 AI (人工智能) 提起AI, 大家可能会想起各种机器人,移动手机的“Siri”,"小爱同学", 是语…...

GPT应用开发:编写插件获取实时天气信息
欢迎阅读本系列文章!我将带你一起探索如何利用OpenAI API开发GPT应用。无论你是编程新手还是资深开发者,都能在这里获得灵感和收获。 本文,我们将继续展示聊天API中插件的使用方法,让你能够轻松驾驭这个强大的工具。 插件运行效…...
揭开Spring MVC的真面目
官方对于Spring MVC的描述为: Spring Web MVC是基于Servlet API框架构建的原始Web框架,从一开始就包含在Spring框架中。它的正式名称“Spring Web MVC”来自其源模块的名称(Spring-webmvc),但它通常被称为“Spring-MVC…...

AI大模型开发架构设计(3)——如何打造自己的大模型
文章目录 如何打造自己的大模型1 新时代职场人应用AIGC的5重境界2 人人需要掌握的大模型原理职场人都能听懂的大语音模型的训练过程职场人都能听得懂的大语言模型的Transformer推理过程 3 如何构建自己的大模型需要具备三个方面的能力LangChain是什么?LangChain主要…...
运算符和表达式)
Linux C语言开发(三)运算符和表达式
目录 一.什么是运算符 二.什么是表达式 一.什么是运算符 在C语言中,运算符是用于执行特定操作的符号。这些操作可以涉及一个或多个值(称为操作数),并产生一个新的值或效果。C语言提供了多种类型的运算符,用于执行算术、比较、逻辑和其他类型的操作。 以下是C语言中常见的…...
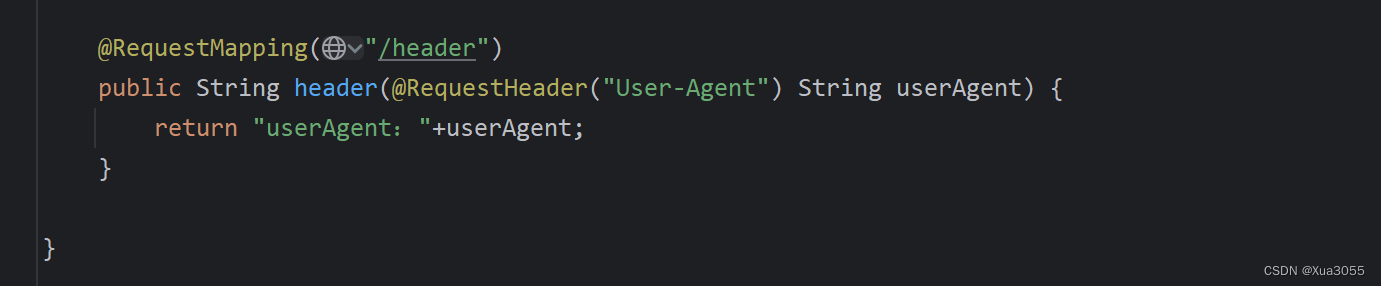
Spring-AOP入门案例
文章目录 Spring-AOP入门案例概念:通知(Advice)切入点(Pointcut )切面(Aspect) 目标对象(target)代理对象(Proxy)顾问(Advisor)连接点(JoinPoint) 简单需求:在接口执行前输出当前系统时间Demo原始未添加aop前1 项目包结构2 创建相…...

中仕教育:国考调剂和补录的区别是什么?
国考笔试成绩和进面名单公布之后,考生们就需要关注调剂和补录了,针对二者之间的区别很多考生不太了解,本文为大家解答一下关于国考调剂和补录的区别。 1.补录 补录是在公式环节之后进行的,主要原因是经过面试、体检和考察&#…...
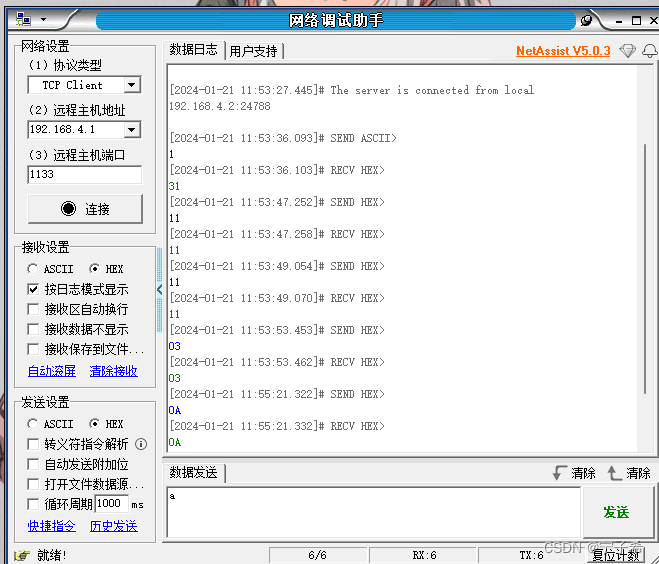
ESP32-TCP服务端(Arduino)
将ESP32设置为TCP服务器 介绍 TCP(Transmission Control Protocol)传输控制协议,是一种面向连接的(一个客户端对应一个服务端)、可靠的传输层协议。在TCP的工作原理中,它会将消息或文件分解为更小的片段&a…...

HCIA-HarmonyOS设备开发认证-序
序 最近涉及到HarmonyOS鸿蒙系统设备开发,在网络上已经有很多相关资料,视频教程,我也移植了公司的一个stm32G474板卡,运行LiteOS-m L0系统。 一面看资料一面移植,遇到不少坑,当看到运行的LOGO时࿰…...
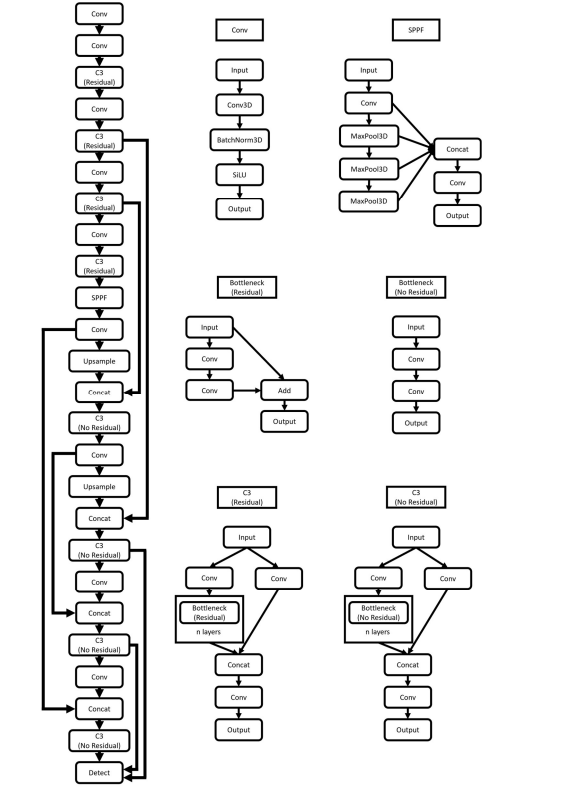
Med-YOLO:3D + 医学影像 + 检测框架
Med-YOLO:3D 医学影像 检测框架 提出背景设计思路网络设计训练设计讨论分析 魔改代码:加强小目标检测总结 提出背景 论文链接:https://arxiv.org/abs/2312.07729 代码链接:https://github.com/JDSobek/MedYOLO 提出背景&…...

Docker部署Golang服务
不管是开发还是生产环境,通过 docker 方式部署服务都是一种不错的选择,能够解决不同开发环境一致性的问题。 本文以项目:https://github.com/johncxf/go-api 为例。 Dockerfile 构建 Go 运用环境 在项目根目录下添加 Dockerfile 文件&…...
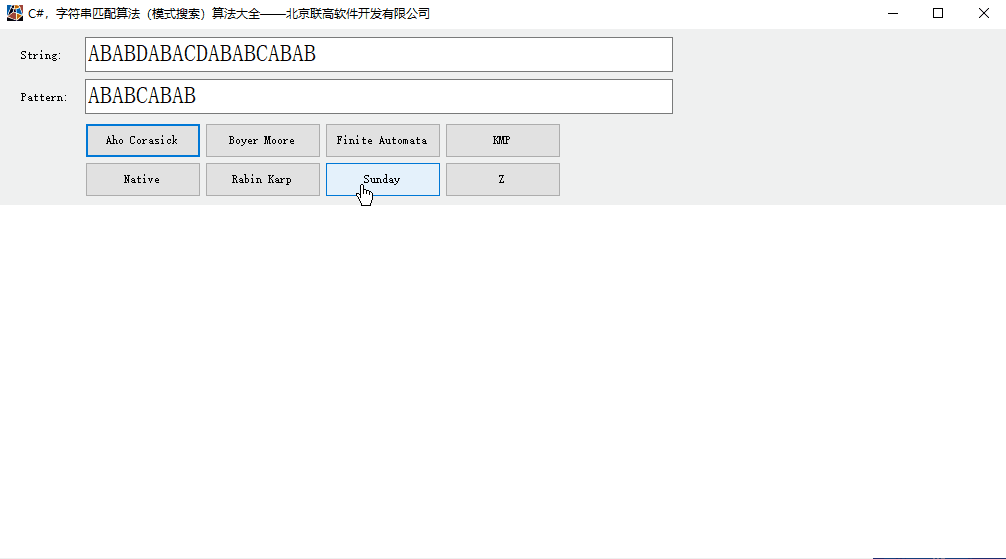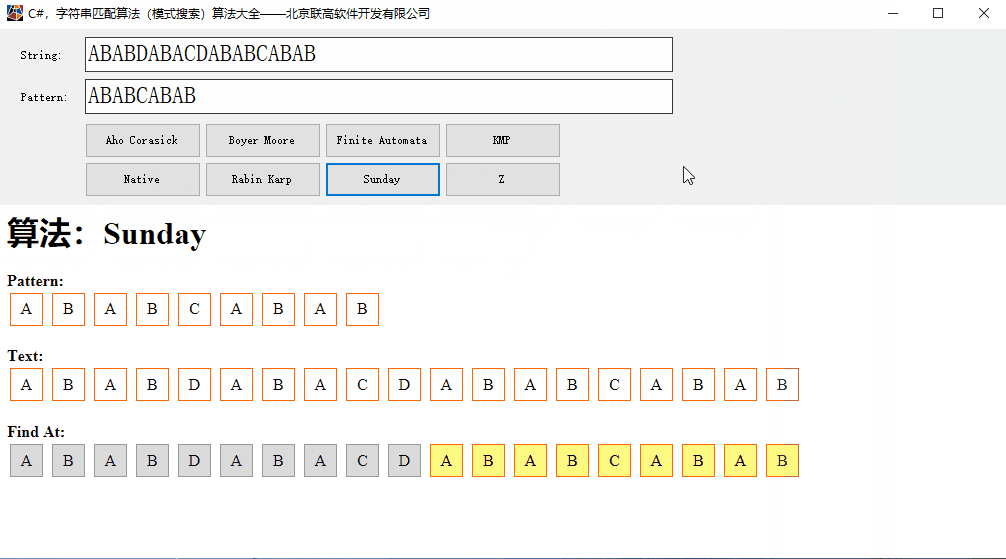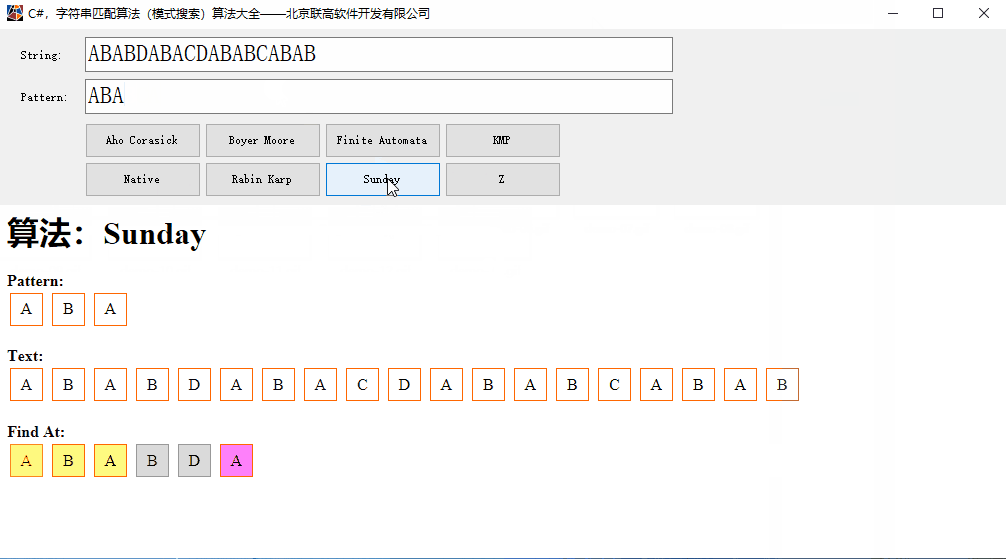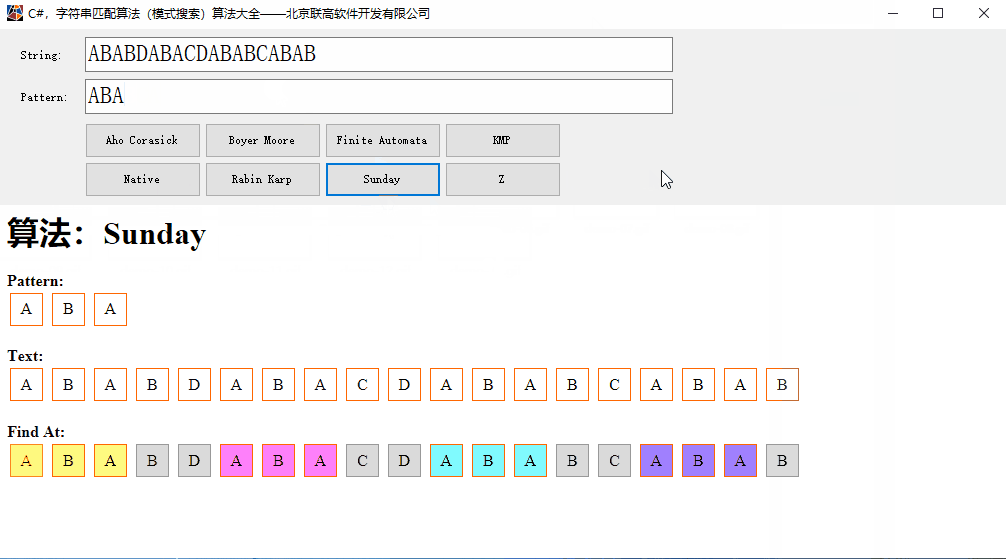
C#,字符串匹配(模式搜索)Sunday算法的源代码
Sunday算法是Daniel M.Sunday于1990年提出的一种字符串模式匹配算法。 核心思想:在匹配过程中,模式串并不被要求一定要按从左向右进行比较还是从右向左进行比较,它在发现不匹配时,算法能跳过尽可能多的字符以进行下一步的匹配&…...

makefile 编译动态链接库使用(.so库文件)
makefile 编译动态链接库使用(.so库文件) 动态链接库:不会把代码编译到二进制文件中,而是在运行时才去加载, 好处是程序可以和库文件分离,可以分别发版,然后库文件可以被多处共享 动态链接库 动态&#…...

Hive 数仓及数仓设计方案
数仓(Data Warehouse) 数据仓库存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供一个统一、规范的出口。做数仓就是做方案,是用数据治理企业的方案。 数据仓库的特点 面向主题集成 公司中不同的部门都会去数据仓库中拿数据,把独…...
Ubuntu使用docker-compose安装redis
ubuntu环境搭建专栏🔗点击跳转 Ubuntu系统环境搭建(十三)——使用docker-compose安装redis 文章目录 Ubuntu系统环境搭建(十三)——使用docker-compose安装redis1.搭建文件夹2.docker-compose.yaml配置文件3.redis.co…...

大数据安全 | 期末复习(上)| 补档
文章目录 📚概述⭐️🐇大数据的定义、来源、特点🐇大数据安全的含义🐇大数据安全威胁🐇保障大数据安全🐇采集、存储、挖掘环节的安全技术🐇大数据用于安全🐇隐私的定义、属性、分类、…...
Kylin 安装novnc 远程访问
noVNC可以使用浏览器直接访问服务器,而不需要使用VNC客户端。 1.初始环境 关闭防火墙或允许IP访问本机 2.安装依赖 dnf install -y tigervnc-server git 3.git下载novnc git clone https://github.com/novnc/noVNC.git git clone https://gitee.com/yangyizhao…...

别再为485传感器没文档发愁了!一个USB转485模块+两款免费软件,5分钟搞定Modbus通信测试
5分钟极简方案:用USB转485模块与开源工具破解Modbus传感器通信 当你拿到一个没有文档的485温湿度传感器时,是否曾为如何读取数据而头疼?本文将分享一套经过实战验证的极简工具组合——仅需一个常见的USB转485转换器和两款免费软件,…...

441GB香港OSGB数据实战:从ContextCapture目录到Smart3D加载的完整指南
1. 441GB香港OSGB数据背景解析 第一次拿到441GB的香港OSGB数据时,我的硬盘指示灯疯狂闪烁了整整一晚上。这种规模的倾斜摄影数据在业内确实罕见,特别是覆盖香港565平方公里区域的完整数据集。实测发现,这套数据采用ContextCapture标准目录结构…...
)
PySOT单目标跟踪实战:从零搭建环境到模型部署的避坑指南(手把手教学,附代码)
1. 环境准备:从零搭建PySOT开发环境 第一次接触PySOT时,我花了整整两天时间折腾环境配置,踩遍了所有能踩的坑。为了让你们少走弯路,我把这些经验整理成可复现的步骤。首先需要明确的是,PySOT对系统环境有特定要求&…...

STM32H7网络延迟问题分析与解决方案
1. 问题现象与背景分析最近在将STM32H7系列设备的DFP(Device Family Pack)从v2.2.0升级到v2.3.0版本后,不少开发者反馈网络数据传输出现了明显的延迟问题。通过简单的ping测试可以直观观察到,使用v2.3.0版本的往返时间(RTT)相比v2…...
)
ESP32项目编译后,如何看懂Output里的内存占用(DRAM/IRAM/Flash详解)
ESP32项目编译后内存占用分析:从DRAM到Flash的深度解读 当你在VSCode中按下编译按钮,看到终端输出那一连串内存占用数据时,是否曾感到困惑?这些数字背后隐藏着ESP32内存架构的秘密,也直接关系到你的项目性能和稳定性。…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

大语言模型在模块化布局优化中的应用与实战
1. 项目概述:当大语言模型遇见模块化布局优化在芯片设计和建筑规划领域,模块布局优化一直是个令人头疼的NP难问题。想象一下,你面前有16个形状各异的乐高积木(模块),需要将它们严丝合缝地拼成一个矩形底板&…...

AI智能体的开发与测试
AI智能体(AI Agent)的开发与测试是一项将大语言模型(LLM)能力转化为企业级稳定应用的系统工程。它不仅需要先进的算法,更依赖于严密的工程架构与创新的测试方法。以下是AI智能体开发与测试的全景指南:第一部…...

八大排序算法-选择排序
介绍选择排序:每一次从待排序序列中找出最小值和待排序序列的第一个值进行交换,重复这个过程,直到待排序序列没有值选择排序:时间复杂度O(n^2) 空间复杂度O(1) 稳定性:不稳定 难度范围:简单可以设置一个变量来保存最小…...

Adobe-GenP:告别订阅烦恼,5分钟解锁Adobe全家桶完整功能
Adobe-GenP:告别订阅烦恼,5分钟解锁Adobe全家桶完整功能 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾被Adobe Creative Cloud的高…...