Haar小波下采样模块
论文原址:Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation - ScienceDirect
原文代码:HWD/HWD.py at main · apple1986/HWD (github.com)
介绍
深度卷积神经网络 (DCNN) 通常采用标准的下采样操作,例如最大池化、平均池化和跨步卷积,这可能会导致信息丢失。丢失的信息,如边界和纹理,对于语义分割可能是必不可少的。为了缓解这个问题,一般有下面四种方法:
- 通过跳过连接到解码器子网(如U-Net、LCU-Net、CENet、LinkNet和RefineNet )。
- 提取具有空间金字塔池化或扩展卷积的多尺度特征图到融合模块中(如DeepLab、PSPNet、PCPLP-Net、BiSenet和ICNet)。
- 向编码器提供多模态图像(如DiSegNet、MMADT、CANet和CCFFNet)。
- 增加先验信息。轮廓增强关注模块,旨在从CT图像中提取边界和形状线索,以细化分割区域。
这些方法的主要目的是通过基于多尺度、先验指导、多模态等各种策略提供更多的学习信息或特征,帮助下采样特征与分割标签之间建立良好的关系。
因此,是否可以设计一个保留信息的下采样模块,使DCNNs中尽可能多地保留信息进行语义分割?这就是作者的想法。
下采样模块
最大池化与平均池化
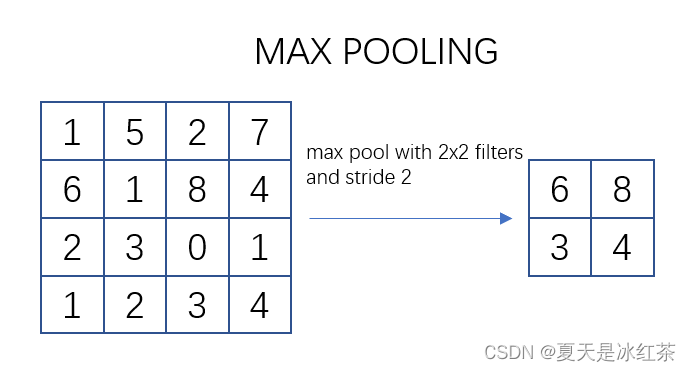
池化过程类似于卷积过程。在这个示意图中,我们看到对一个 4x4 的特征图邻域进行操作,使用了一个 2x2 的滤波器,步长为2进行扫描。这个过程被称为最大池化(Max Pooling),其中选择邻域内的最大值并输出到下一层。
常用的 max pooling 参数是 S=2、f=2,其效果是将特征图的高度和宽度减半,而通道数保持不变。

如上图所示,描述的是对一个 4x4 的特征图邻域内的数值进行操作。使用了一个 2x2 的滤波器,步长为2进行扫描,计算邻域内数值的平均值并将其输出到下一层。这种操作被称为平均池化(Mean Pooling)。
"""
Copyright (c) 2023, Auorui.
All rights reserved.The Torch implementation of average pooling and maximum pooling has been compared with the official Torch implementation
"""
import torch
import torch.nn as nn__all__ = ["MaxPool2d", "AvgPool2d"]class MaxPool2d(nn.Module):"""池化层计算公式:output_size = [(input_size−kernel_size) // stride + 1]"""def __init__(self, kernel_size, stride):super(MaxPool2d, self).__init__()self.kernel_size = kernel_sizeself.stride = stridedef max_pool2d(self, input_tensor, kernel_size, stride):batch_size, channels, height, width = input_tensor.size()output_height = (height - kernel_size) // stride + 1output_width = (width - kernel_size) // stride + 1output_tensor = torch.zeros(batch_size, channels, output_height, output_width)for i in range(output_height):for j in range(output_width):# 获取输入张量中与池化窗口对应的部分window = input_tensor[:, :,i * stride: i * stride + kernel_size, j * stride: j * stride + kernel_size]output_tensor[:, :, i, j] = torch.max(window.reshape(batch_size, channels, -1), dim=2)[0]return output_tensordef forward(self, input_tensor):return self.max_pool2d(input_tensor, kernel_size=self.kernel_size, stride=self.stride)class AvgPool2d(nn.Module):"""池化层计算公式:output_size = [(input_size−kernel_size) // stride + 1]"""def __init__(self, kernel_size, stride):super(AvgPool2d, self).__init__()self.kernel_size = kernel_sizeself.stride = stridedef avg_pool2d(self, input_tensor, kernel_size, stride):batch_size, channels, height, width = input_tensor.size()output_height = (height - kernel_size) // stride + 1output_width = (width - kernel_size) // stride + 1output_tensor = torch.zeros(batch_size, channels, output_height, output_width)for i in range(output_height):for j in range(output_width):# 获取输入张量中与池化窗口对应的部分window = input_tensor[:, :,i * stride: i * stride + kernel_size, j * stride:j * stride + kernel_size]output_tensor[:, :, i, j] = torch.mean(window.reshape(batch_size, channels, -1), dim=2)return output_tensordef forward(self, input_tensor):return self.avg_pool2d(input_tensor, kernel_size=self.kernel_size, stride=self.stride)if __name__=="__main__":# input_data = torch.rand((1, 3, 3, 3))input_data = torch.Tensor([[[[0.3939, 0.8964, 0.3681],[0.5134, 0.3780, 0.0047],[0.0681, 0.0989, 0.5962]],[[0.7954, 0.4811, 0.3329],[0.8804, 0.3986, 0.3561],[0.2797, 0.3672, 0.6508]],[[0.6309, 0.1340, 0.0564],[0.3101, 0.9927, 0.5554],[0.0947, 0.2305, 0.8299]]]])print(input_data.shape)kernel_size = 3stride = 1MaxPool2d1 = nn.MaxPool2d(kernel_size, stride)output_data_with_torch_max = MaxPool2d1(input_data)AvgPool2d1 = nn.AvgPool2d(kernel_size, stride)output_data_with_torch_avg = AvgPool2d1(input_data)AvgPool2d2 = AvgPool2d(kernel_size, stride)output_data_with_torch_Avg = AvgPool2d2(input_data)MaxPool2d2 = MaxPool2d(kernel_size, stride)output_data_with_torch_Max = MaxPool2d2(input_data)# output_data_with_max = max_pool2d(input_data, kernel_size, stride)# output_data_with_avg = avg_pool2d(input_data, kernel_size, stride)print("\ntorch.nn pooling Output:")print(output_data_with_torch_max,"\n",output_data_with_torch_max.size())print(output_data_with_torch_avg,"\n",output_data_with_torch_avg.size())print("\npooling Output:")print(output_data_with_torch_Max,"\n",output_data_with_torch_Max.size())print(output_data_with_torch_Avg,"\n",output_data_with_torch_Avg.size())# 直接使用bool方法判断会因为浮点数的原因出现偏差print(torch.allclose(output_data_with_torch_max,output_data_with_torch_Max))print(torch.allclose(output_data_with_torch_avg,output_data_with_torch_Avg))# tensor([[[[0.8964]], # output_data_with_max# [[0.8804]],# [[0.9927]]]])# tensor([[[[0.3686]], # output_data_with_avg# [[0.5047]],# [[0.4261]]]])在这里,简单地与PyTorch官方的实现进行了比对,成功的进行复现。
跨步卷积
import torch
import torch.nn as nnclass StridedConvolution(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=2, is_relu=True):super(StridedConvolution, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=1)self.relu = nn.ReLU(inplace=True)self.is_relu = is_reludef forward(self, x):x = self.conv(x)if self.is_relu:x = self.relu(x)return xif __name__ == '__main__':input_data = torch.rand((1, 3, 64, 64))strided_conv = StridedConvolution(3, 64)output_data = strided_conv(input_data)print("Input shape:", input_data.shape)print("Output shape:", output_data.shape)对输入进行跨步卷积,并根据 is_relu 参数选择是否添加ReLU激活函数。在构建卷积神经网络时经常被用于下采样步骤,以减小特征图的尺寸。
Haar小波下采样
这一部分就直接参考的作者的代码,与池化不同的是,这里它是要指定输入输出几个通道。
"""
Haar Wavelet-based Downsampling (HWD)Original address of the paper: https://www.sciencedirect.com/science/article/abs/pii/S0031320323005174
Code reference: https://github.com/apple1986/HWD/tree/main
"""
import torch
import torch.nn as nn
from pytorch_wavelets import DWTForwardclass HWDownsampling(nn.Module):def __init__(self, in_channel, out_channel):super(HWDownsampling, self).__init__()self.wt = DWTForward(J=1, wave='haar', mode='zero')self.conv_bn_relu = nn.Sequential(nn.Conv2d(in_channel * 4, out_channel, kernel_size=1, stride=1),nn.BatchNorm2d(out_channel),nn.ReLU(inplace=True),)def forward(self, x):yL, yH = self.wt(x)y_HL = yH[0][:, :, 0, ::]y_LH = yH[0][:, :, 1, ::]y_HH = yH[0][:, :, 2, ::]x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)x = self.conv_bn_relu(x)return xif __name__ == '__main__':downsampling_layer = HWDownsampling(3, 64)input_data = torch.rand((1, 3, 64, 64))output_data = downsampling_layer(input_data)print("Input shape:", input_data.shape)print("Output shape:", output_data.shape)Haar小波变换是一种基于小波的信号处理方法,它将信号分解成低频和细节高频两个部分。在图像处理中,Haar小波通常用于图像压缩和特征提取,代码中使用的DWTForward模块中离散小波变换,通过选择 yH 中的不同方向上的高频分量,构建了新的特征图。将原始低频分量 yL 与新构建的高频分量拼接在一起。最后通过一个包含卷积、批归一化和ReLU激活函数的序列处理最终的特征图。
实验验证

这是作者论文中做的实验,这样看起来,似乎HWD在细节上确实是比池化和跨步卷积效果要好。
这里因为我也用我自己的数据进行了实验:

最大池化效果
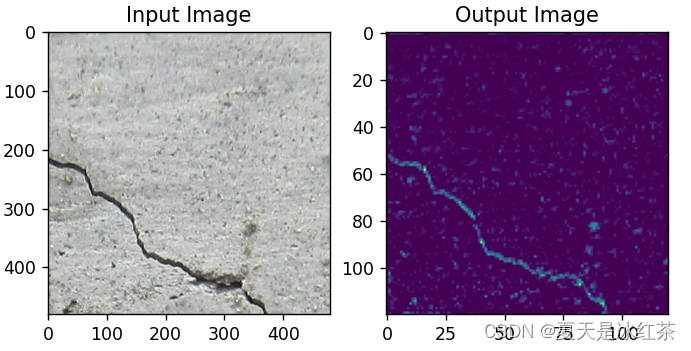
平均池化效果

跨步卷积效果
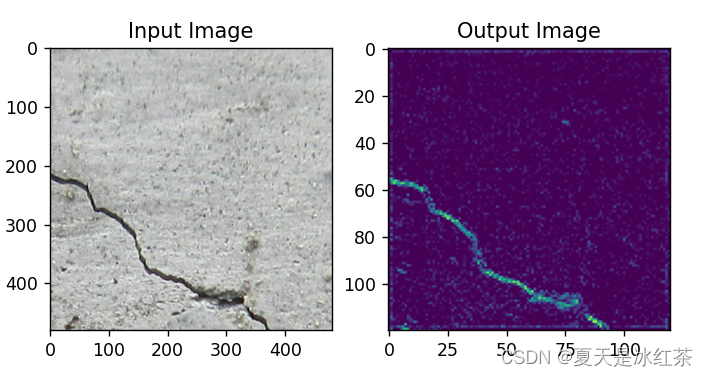
HDW效果
从肉眼上来看,HDW的效果确实要比其他的效果要好一些。
下面是我做实验的代码,感兴趣的可以在自己的数据上面进行实验,我觉得用于交通和医学上应该会有比较好的效果。
import cv2
import torch
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch.nn as nn
from pytorch_wavelets import DWTForwardclass StridedConvolution(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=2, is_relu=True):super(StridedConvolution, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=1)self.relu = nn.ReLU(inplace=True)self.is_relu = is_reludef forward(self, x):x = self.conv(x)if self.is_relu:x = self.relu(x)return xclass HWDownsampling(nn.Module):def __init__(self, in_channel, out_channel):super(HWDownsampling, self).__init__()self.wt = DWTForward(J=1, wave='haar', mode='zero')self.conv_bn_relu = nn.Sequential(nn.Conv2d(in_channel * 4, out_channel, kernel_size=1, stride=1),nn.BatchNorm2d(out_channel),nn.ReLU(inplace=True),)def forward(self, x):yL, yH = self.wt(x)y_HL = yH[0][:, :, 0, ::]y_LH = yH[0][:, :, 1, ::]y_HH = yH[0][:, :, 2, ::]x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)x = self.conv_bn_relu(x)return xclass DeeperCNN(nn.Module):def __init__(self):super(DeeperCNN, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)self.batch_norm1 = nn.BatchNorm2d(16)self.relu = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)# self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)# self.pool1 = HWDownsampling(16, 16)self.pool1 = StridedConvolution(16, 16, is_relu=True)self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.batch_norm2 = nn.BatchNorm2d(32)# self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)# self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)# self.pool2 = HWDownsampling(32, 32)self.pool2 = StridedConvolution(32, 32, is_relu=True)self.conv6 = nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1)def forward(self, x):x = self.pool1(self.relu(self.batch_norm1(self.conv1(x))))print(x.shape)x = self.pool2(self.relu(self.batch_norm2(self.conv2(x))))print(x.shape)x = self.conv6(x)return ximage_path = r'D:\PythonProject\Crack_classification_training_script\data\base\val\crack\2416.png'
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)transform = transforms.Compose([transforms.ToTensor()])
input_image = transform(image).unsqueeze(0)
import numpy as np
model = DeeperCNN()
output = model(input_image)
print("Output shape:", output.shape)input_image = input_image.squeeze(0).permute(1, 2, 0).numpy()
output_image = output.squeeze(0).permute(1, 2, 0).detach().numpy()
output_image = output_image / output_image.max()
output_image = np.clip(output_image, 0, 1)plt.subplot(1, 2, 1)
plt.imshow(input_image)
plt.title('Input Image')plt.subplot(1, 2, 2)
plt.imshow(output_image)
plt.title('Output Image')plt.show()总结
在论文当中,作者也做了大量的消融实验去证实这个下采样模块的有效性,建议大家去看看原著作,或许会有更多的收获。
相关文章:
Haar小波下采样模块
论文原址:Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation - ScienceDirect 原文代码:HWD/HWD.py at main apple1986/HWD (github.com) 介绍 深度卷积神经网络 (DCNN) 通…...

k8s的包管理工具helm
Helm是什么? 之前的这篇文章介绍了一开始接触k8s的时候接触到的几个命令工具 kubectl&kubelet&rancher&helm&kubeadm这几个命令行工具是什么关系?-CSDN博客 Helm 是一个用于管理和部署 Kubernetes 应用程序的包管理工具。它允许用户定义、安装和…...
《WebKit 技术内幕》学习之八(1):硬件加速机制
《WebKit 技术内幕》之八(1):硬件加速机制 1 硬件加速基础 1.1 概念 这里说的硬件加速技术是指使用GPU的硬件能力来帮助渲染网页,因为GPU的作用主要是用来绘制3D图形并且性能特别好,这是它的专长所在,它…...

【Linux对磁盘进行清理、重建、配置文件系统和挂载,进行系统存储管理调整存储结构】
Linux 调整存储结构 前言一、查看磁盘和分区列表二、创建 ext4 文件系统,即:格式化分区为ext4文件系统。1.使用命令 mkfs.ext4 (make file system)报错如下:解决办法1:(经测试,不采用)X解决办法…...

RT-DETR算法优化改进:DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测
💡💡💡本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和RT-DETR结合,助力涨点 DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DC…...

Docker基础使用
Docker基础使用 1.查看容器挂载文件夹一定要放开权限,否则后面启动nexus时会无法启动1.查询远程镜像重启docker服务容器自启动关闭容器自启动查看docker容器是否挂载容器挂载解释保存和加载本地镜像创建mysql容器容器转换为镜像创建dockerfile容器相互通讯查看容器的…...
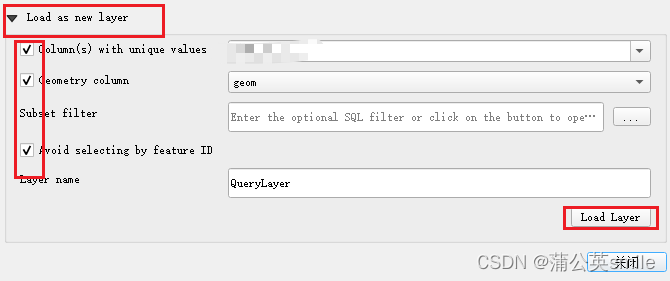
数据库中的经纬度数据如何在QGIS中显示
思路:必须先将经纬度数据转换成POINT,MULTILINESTRING等格式才能在QGIS中展示 步骤 1、首先在postgresql数据中建一张包括经纬度数据的表 **注意:**如果是新建数据库,一定要执行如下代码,否则后面的函数ST_GeomFrom…...

制作linux运行包
从源码制作 syslinux:https://mirrors.edge.kernel.org/pub/linux/utils/boot/syslinux/syslinux-6.03.tar.gz busybox:https://busybox.net/downloads/busybox-1.26.0.tar.bz2 kernel:https://mirrors.edge.kernel.org/pub/linux/kernel/v6.x/linux-6.5.7.tar.gz 遇到问题&…...

一些 AI 机构
文章目录 OpenAITHUDMMetaAITIIStability AINousResearch OpenAI hf : https://huggingface.co/openai 官网:https://openai.com THUDM 清华大学 KEG 和 THUDM 团队 Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University hf : https://h…...
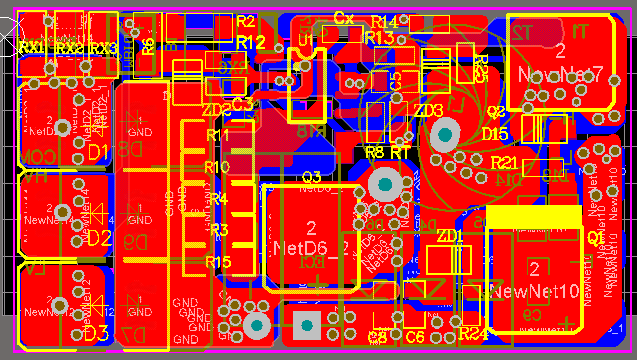
AP5191 降压恒流 双灯 12V5A 一切一LED车灯汽车大灯驱动方案
AP5191是一款PWM工作模式,高效率、外围简 单、内置功率MOS管,适用于4.5-150V输入的高 精度降压LED恒流驱动芯片。输出功率150W, 电流6A。 AP5191可实现线性调光和PWM调光,线性调 光脚有效电压范围0.55-2.6V. AP5191 工作频率可以通过RT 外部…...
)
淘宝/天猫获取卖出的商品订单列表 API(taobao.seller_order_list)
淘宝和天猫平台提供了一个API接口(taobao.seller_order_list),用于获取卖家出售的商品订单列表。以下是使用该API的基本步骤: 获取API密钥:首先,您需要在淘宝开放平台(Open Platform)…...

Linux常规操作指南
1. 文件系统操作 (1)查看当前目录内容 ls或查看详细信息: ls -l(2)切换工作目录 cd /path/to/directory(3)创建新目录 mkdir directory_name(4)删除空目录 rmdir d…...
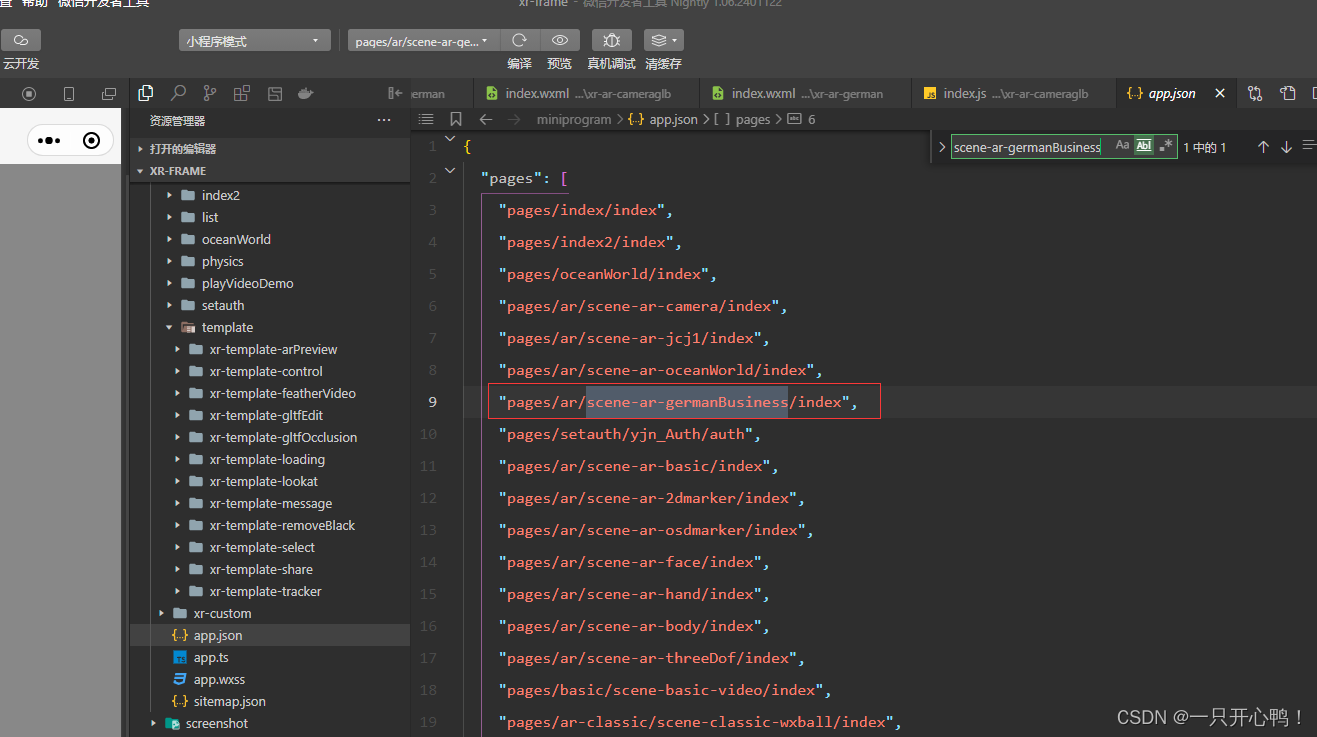
原生微信小程AR序实现模型动画播放只播放一次,且停留在最后一秒
1.效果展示 0868d9b9f56517a9a07dfc180cddecb2 2.微信小程序AR是2023年初发布,还有很多问提(比如glb模型不能直接播放最后一帧;AR识别不了金属、玻璃材质的模型等…有问题解决了的小伙伴记得告诉我一声) 微信官方文档地址 3.代码…...
【Docker】在centos中安装nginx
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是平顶山大师,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《【Docker】安装nginx》。🎯&#…...
leetcode:最接近的三数之和---(双指针,排序,数组)
题目: 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解。 示例: 示例 1: 输入:nums [-1…...
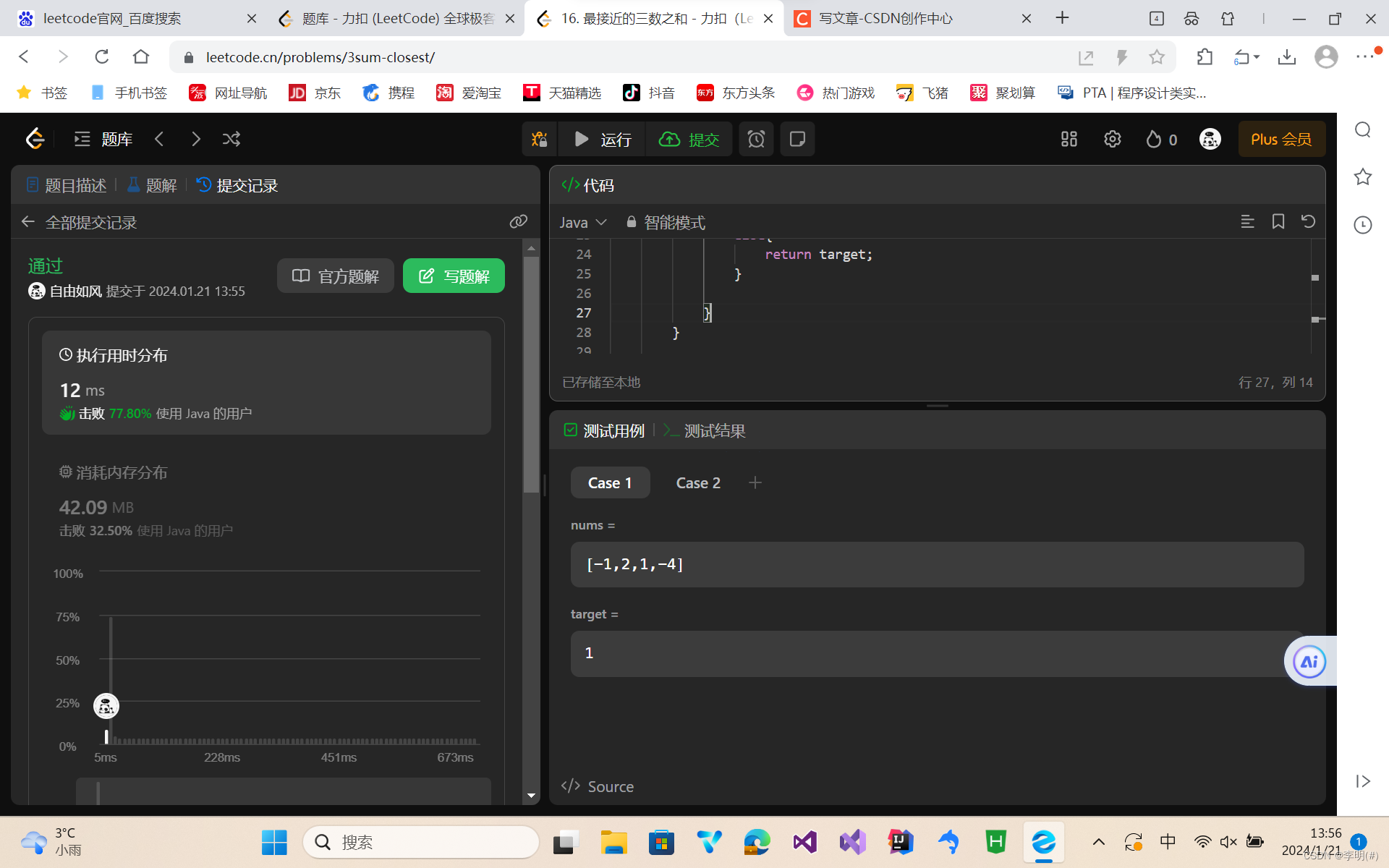
dpdk网络转发环境的搭建
文章目录 前言ip命令的使用配置dpdk-basicfwd需要的网络结构测试dpdk-basicfwddpdk-basicfwd代码分析附录basicfwd在tcp转发时的失败抓包信息DPDK的相关设置 前言 上手dpdk有两难。其一为环境搭建。被绑定之后的网卡没有IP,我如何给它发送数据呢?当然&a…...
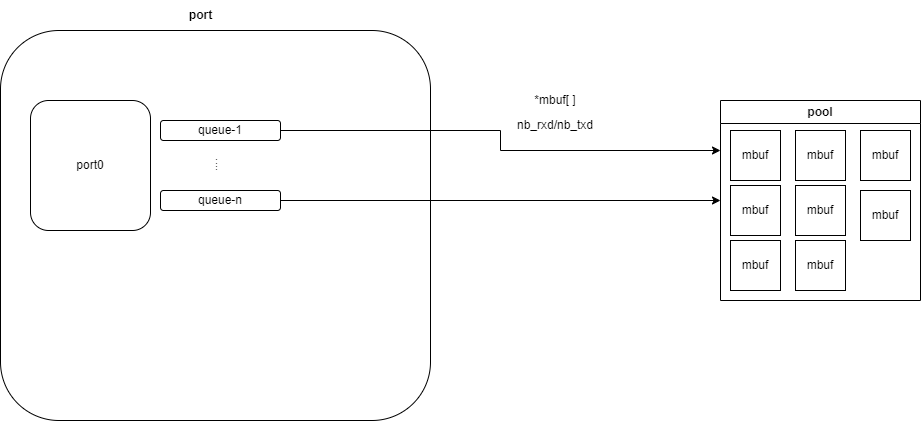
【MYSQL】存储引擎MyISAM和InnoDB
MYSQL 存储引擎 查看MySQL提供所有的存储引擎 mysql> show engines; mysql常用引擎包括:MYISAM、Innodb、Memory、MERGE 1、MYISAM:全表锁,拥有较高的执行速度,不支持事务,不支持外键,并发性能差&#x…...
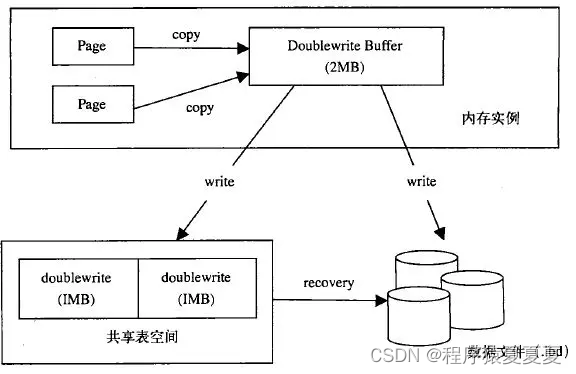
什么是DOM?(JavaScript DOM是什么?)
1、DOM简洁 DOM是js中最重要的一部分,没有DOM就不会通过js实现和用户之间的交互。 window是最大的浏览器对象,在它的下面还有很多子对象,我们要学习的DOM就是window对象下面的document对象 DOM(Document Object Model)…...

UIElement编辑器扩展 组件 Inspector
UIElement编辑器扩展 组件 Inspector https://docs.unity.cn/cn/2021.3/Manual/UIE-create-a-binding-uxml-inspector.html 简单开始 声明序列化VisualTreeAsset [SerializeField] VisualTreeAsset visualTree; 声明完,直接在脚本的Inspector面板,把你…...

Flask 3.x log全域配置(包含pytest)
最近使用到flask3.x,配置了全域的log,这边记录下 首先需要创建logging的配置文件,我是放在项目根目录的, Logging 配置 logging.json {"version": 1, # 配置文件版本号"formatters": {"default&qu…...

2026最新!录音软件哪个最好用?4款亲测免费实用神器,避坑省钱真香!
做内容的要整理访谈,职场要记会议纪要,学生要转课堂录音,做调研的要整理访谈录音——不同人群需求不一样,但核心诉求都是:准、快、不瞎收钱。我花了一周亲测4款热门录音转写工具,直接给结论:听脑…...

Awesome-LLM-Apps:大语言模型应用开发实战指南与开源项目宝库
1. 项目概述:一个大型语言模型应用的开源宝库如果你最近在折腾大语言模型,想找点现成的、能跑起来的应用来学习或者直接部署,那你大概率在GitHub上见过这个项目。awesome-llm-apps, 一个由开发者Shubham Saboo维护的仓库ÿ…...
)
从热设计小白到专家:我是如何用RC6-4-01这颗TEC搞定激光器温控的(真实项目复盘)
从热设计小白到专家:我是如何用RC6-4-01这颗TEC搞定激光器温控的(真实项目复盘) 激光器温控从来不是简单的"制冷片贴上去就行"。去年接手某光纤激光器项目时,面对客户要求的0.1℃控温精度,我盯着规格书里密密…...

从 API 密钥管理角度看 Taotoken 控制台提供的安全与便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从 API 密钥管理角度看 Taotoken 控制台提供的安全与便捷性 1. 引言:集中管理的起点 在开发涉及大模型的应用时&#…...

如何自动化监控线上问题
要实现线上问题的自动化监控,不能仅停留在工具的堆砌,而需要从体系规划、数据采集、智能告警、动态诊断到流程规范进行全盘设计。以下是基于行业最佳实践的自动化监控构建指南:一、 体系规划与监控点梳理构建自动化监控的第一步是明确“监控什…...

长期使用Taotoken的TokenPlan套餐带来的月度成本变化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的TokenPlan套餐带来的月度成本变化感受 作为一名中度频率的大模型API使用者,我的日常工作涉及代码生…...

《流浪的梦想家》的传播入口:漂泊感如何形成记忆点
从内容传播角度看,《流浪的梦想家》的入口在两个词的拉扯:流浪意味着还在路上,梦想家意味着心里仍有方向。这个反差足够形成记忆点。这首歌不适合被写成空泛远方。更准确的场景,是一个人背着行李、换城市、换工作、或者在深夜车窗…...

MASA模组汉化包完整教程:让Minecraft模组界面瞬间变中文的终极指南
MASA模组汉化包完整教程:让Minecraft模组界面瞬间变中文的终极指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中MASA模组复杂的英文界面而头疼吗&#…...

独立开发者应对Claude Code封号风险的备用方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者应对Claude Code封号风险的备用方案与接入实践 对于依赖Claude Code进行日常开发的独立开发者或小型团队而言࿰…...

稀疏矩阵运算全解析:从基础算术到高效求解与性能调优
1. 稀疏矩阵运算操作全景解析在数值计算、机器学习、图形学乃至各类工程仿真领域,处理大规模数据时,我们总会遇到一个“熟悉的陌生人”——稀疏矩阵。它不像密集矩阵那样,每个元素都占据着内存空间,而是像一个精打细算的管家&…...