张量计算和操作
一、数据操作
1、基础
import torchx = torch.arange(12)
# x:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape
# torch.Size([12])x.numel()
# 12x = x.reshape(3, 4)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])torch.zeros((2, 3, 4))
# tensor([[[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]],
# [[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]]])torch.ones((2, 3, 4))
# tensor([[[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]],
# [[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]]])# 从某个特定的概率分布中随机采样来得到张量中每个元素的值。
# 随机初始化参数的值。
torch.randn(3, 4)
# tensor([[-0.0135, 0.0665, 0.0912, 0.3212],
# [ 1.4653, 0.1843, -1.6995, -0.3036],
# [ 1.7646, 1.0450, 0.2457, -0.7732]])torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
# tensor([[2, 1, 4, 3],
# [1, 2, 3, 4],
# [4, 3, 2, 1]])2、运算符
在相同形状的两个张量上执行按元素操作
import torch+-*/**运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
#(tensor([ 3., 4., 6., 10.]),
# tensor([-1., 0., 2., 6.]),
# tensor([ 2., 4., 8., 16.]),
# tensor([0.5000, 1.0000, 2.0000, 4.0000]),
# tensor([ 1., 4., 16., 64.]))计算e^x
torch.exp(x)
#tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])张量连结,端对端地叠形成一个更大的张量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])torch.cat((X, Y), dim=0)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [ 2., 1., 4., 3.],
# [ 1., 2., 3., 4.],
# [ 4., 3., 2., 1.]])torch.cat((X, Y), dim=1)
# tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
# [ 4., 5., 6., 7., 1., 2., 3., 4.],
# [ 8., 9., 10., 11., 4., 3., 2., 1.]])通过逻辑运算符构建二元张量
X == Y
# tensor([[False, True, False, True],
# [False, False, False, False],
# [False, False, False, False]])对张量中的所有元素进行求和,会产生一个单元素张量。
X.sum()
# tensor(66.)3、广播机制
在不同形状的两个张量上执行操作
1. 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
2. 对生成的数组执行按元素操作。
import torcha = torch.arange(3)
#tensor([0, 1, 2])
a = torch.arange(3).reshape((3, 1))
#tensor([[0],
# [1],
# [2]])b = torch.arange(2)
#tensor([0, 1])
b = torch.arange(2).reshape((1, 2))
#tensor([[0, 1]])a和b分别是3×1和1×2矩阵,如果让它们相加,它们的形状不匹配,可以将两个矩阵广播为一个更大的3×2矩阵。
矩阵a将复制列,矩阵b将复制行(这个过程程序自动执行),然后再按元素相加。
a
# tensor([[0, 0],
# [1, 1],
# [2, 2]])
b
# tensor([[0, 1],
# [0, 1],
# [0, 1]])
a+b
# tensor([[0, 1],
# [1, 2],
# [2, 3]])4、索引和切片
张量中的元素可以通过索引访问
第一个元素 的索引是0,最后一个元素索引是‐1;
可以指定范围以包含第一个元素和最后一个之前的元素。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
print(X)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])print(X[-1])
# tensor([ 8., 9., 10., 11.])print(X[1:3])
# tensor([[ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])X[1, 2] = 9
print(X)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 9., 7.],
# [ 8., 9., 10., 11.]])X[0:2, :] = 12
print(X)
# tensor([[12., 12., 12., 12.],
# [12., 12., 12., 12.],
# [ 8., 9., 10., 11.]])5、节省内存
运行一些操作可能会导致为新结果分配内存。
例如,如果我们用Y = X + Y,我们将取消引用Y指向的张量, 而是指向新分配的内存处的张量。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])#Python的id()函数提供了内存中引用对象的确切地址。
before = id(Y)
Y = Y + Xprint(id(Y) == before)
# False这可能是不可取的,原因有两个:
(1)首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。通常情况下,我们希望原地执行这些更新;
(2)如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能会无意中引用旧的参数。
执行原地操作非常简单,使用切片表示法将操作的结果分配给先前分配的数组。
例如Z[:] = <expression>
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
Z = torch.zeros_like(Y) #创建一个新的矩阵Z,其形状与X/Y相同print('id(Z):', id(Z))
# id(Z): 140070288237104Z[:] = X + Y
print('id(Z):', id(Z))
# id(Z): 140070288237104
如果在后续计算中没有重复使用X,可以使用X[:] = X + Y或X += Y来减少操作的内存开销。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])before = id(X)
X += Yprint(id(X) == before)
# True
6、转换为其他Python对象
张量tensor转换为数组张量numpy很容易,反之也同样容易。
torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])tensor转numpy
A = X.numpy()
# array([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]], dtype=float32)numpy转tensor
B = torch.tensor(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])print(type(A))
# <class 'numpy.ndarray'>print(type(B))
# <class 'torch.Tensor'>两者之间的区别
- PyTorch Tensors:PyTorch 中的 tensor 是这个深度学习框架的基础数据结构,可以在GPU上运行以加速计算。
- NumPy Arrays:NumPy 的 ndarray 是 Python 中用于科学计算的一个基本库的核心组件。它们被广泛用于各种数值计算任务,并且通常在 CPU 上运行。
- PyTorch tensors 支持自动微分,这对于训练神经网络来说是非常重要的。而 NumPy arrays 没有内建的自动微分功能。
相关文章:

张量计算和操作
一、数据操作 1、基础 import torchx torch.arange(12) # x:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape # torch.Size([12])x.numel() # 12x x.reshape(3, 4) # tensor([[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]])torch.zeros((2…...

【Spring Boot 3】【JPA】枚举类型持久化
【Spring Boot 3】【JPA】枚举类型持久化 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...
)
SVN 常用命令汇总(2024)
1、前言 1.1、如何检索本文档 使用CSDN自带的“目录”功能进行检索,会更容易查找到自己需要的命令。 1.2、svn常用命令查询:help —— 帮助 在使用过程中,可随时使用help命令查看各常用svn命令: svn help2、检出及更新 2.1、…...
K8S四层代理Service-02
Service的四种类型使用 ClusterIP使用示例Pod里使用service的服务名访问应用 NodePort使用示例 ExternalName使用示例 LoadBalancer K8S支持以下4种Service类型:ClusterIP、NodePort、ExternalName、LoadBalancer 以下是使用4种类型进行Service创建,应对…...

3、非数值型的分类变量
非数值型的分类变量 有很多非数字的数据,这里介绍如何使用它来进行机器学习。 在本教程中,您将了解什么是分类变量,以及处理此类数据的三种方法。 本课程所需数据集夸克网盘下载链接:https://pan.quark.cn/s/9b4e9a1246b2 提取码:uDzP 文章目录 1、简介2、三种方法的使用1…...

国内免费chartGPT网站汇总
https://s.suolj.com - (支持文心、科大讯飞、智谱等国内大语言模型,Midjourney绘画、语音对讲、聊天插件)国内可以直连,响应速度很快 很稳定 https://seboai.github.io - 国内可以直连,响应速度很快 很稳定 http://gp…...

【Alibaba工具型技术系列】「EasyExcel技术专题」实战研究一下 EasyExcel 如何从指定文件位置进行读取数据
实战研究一下 EasyExcel 如何从指定文件位置进行读取数据 EasyExcel的使用背景EasyExcel的时候痛点EasyExcel对比其他框架 EasyExcel的编程模式EasyExcel读取的指定位置导入数据的流程表头校验invokeHeadMap()方法 数据处理invoke()方法 执行中断hasNextdoAfterAllAnalysed()方…...

java.security.InvalidKeyException: Illegal key size错误
出现的问题 最近在对接第三方,涉及获取token鉴权。在本地调试能获取到token,但是在Linux环境上调用就报错:java.security.InvalidKeyException: Illegal key size 与三方沟通 ,排除了是传参和网络的原因;搜索资料发现…...

python脚本,实现监控系统的各项资源
今天的文章涉及到docker的操作和一个python脚本,实现监控网络的流量、CPU使用率、内存使用率和磁盘使用情况。一起先看看效果吧: 这是在控制台中出现的数据,可以很简单的看到我们想要的监控指标。如果实现定时任务和数据的存储、数据的展示&a…...
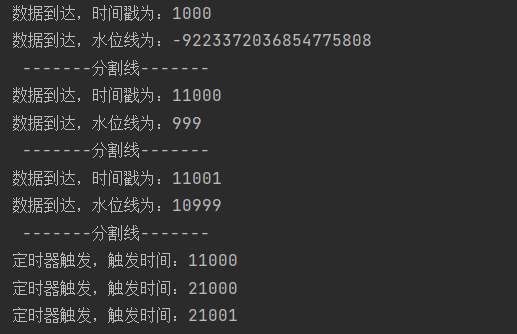
Flink处理函数(2)—— 按键分区处理函数
按键分区处理函数(KeyedProcessFunction):先进行分区,然后定义处理操作 1.定时器(Timer)和定时服务(TimerService) 定时器(timers)是处理函数中进行时间相关…...
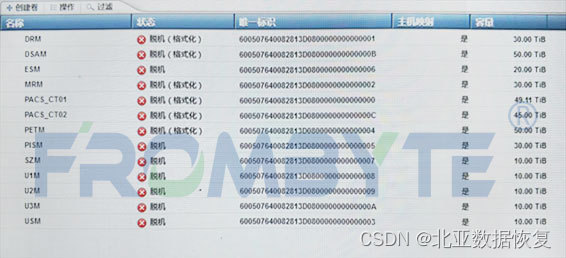
服务器数据恢复—服务器进水导致阵列中磁盘同时掉线的数据恢复案例
服务器数据恢复环境: 数台服务器数台存储阵列柜,共上百块硬盘,划分了数十组lun。 服务器故障&检测: 外部因素导致服务器进水,进水服务器中一组阵列内的所有硬盘同时掉线。 北亚数据恢复工程师到达现场后发现机房内…...
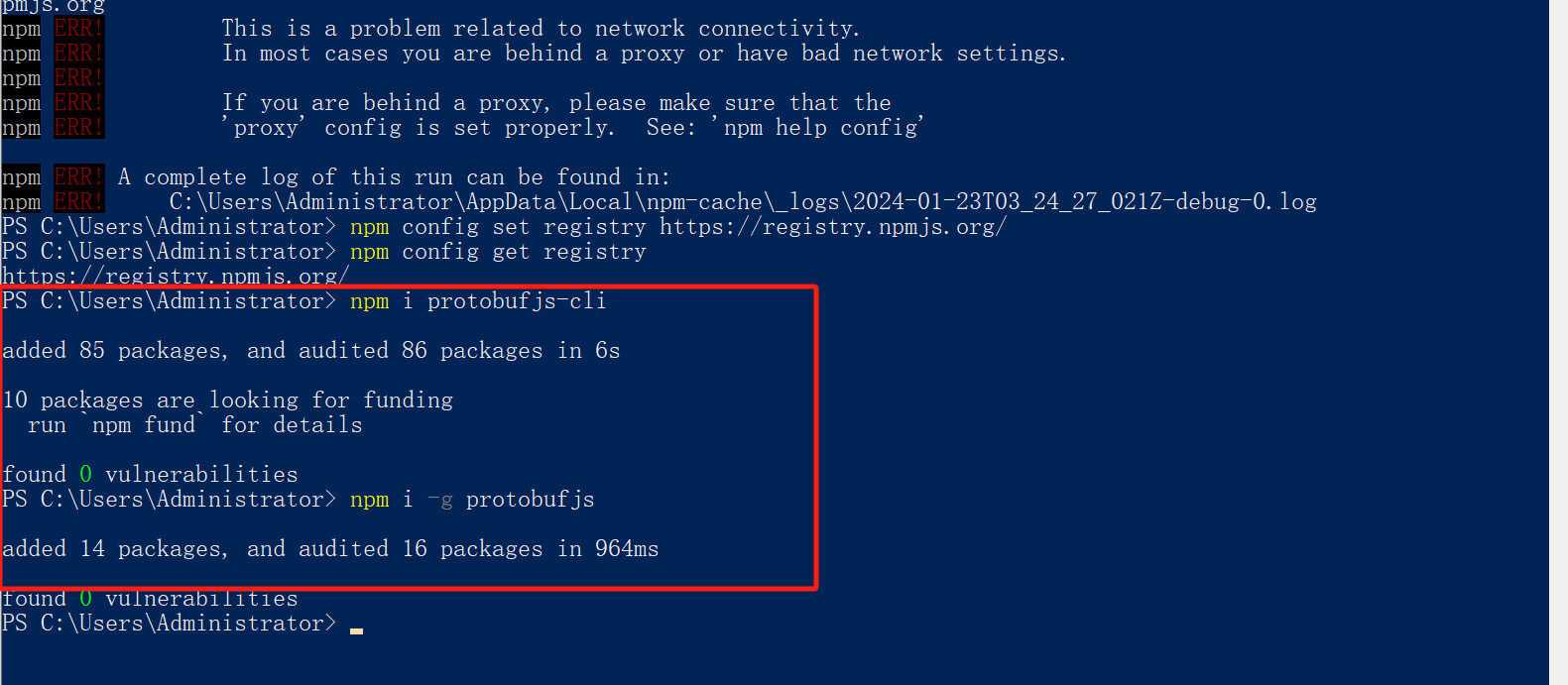
npm或者pnpm或者yarn安装依赖报错ENOTFOUND解决办法
如果报错说安装依赖报错,大概率是因为npm源没有设置对,比如我这里安装protobufjs的时候报错:ENOTFOUND npm ERR! code ENOTFOUND npm ERR! syscall getaddrinfo npm ERR! errno ENOTFOUND npm ERR! network request to https://registry.cnpm…...

学会使用ubuntu——ubuntu22.04使用Google、git的魔法操作
ubuntu22.04使用Google、git的魔法操作 转战知乎写作 https://zhuanlan.zhihu.com/p/679332988...

【机组】计算机组成原理实验指导书.
🌈个人主页:Sarapines Programmer🔥 系列专栏:《机组 | 模块单元实验》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 第一章 性能特点 1.1 系…...

解决Sublime Text V3.2.2中文乱码问题
目录 中文乱码出现情形通过安装插件来解决乱码问题 中文乱码出现情形 打开一个中文txt文件,显示乱码,在File->Reopen With Encoding里面找不到支持简体中文正常显示的编码选项。 通过安装插件来解决乱码问题 安装Package Control插件 打开Tool->…...

Oracle 12CR2 RAC部署翻车,bug避坑经历
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

情绪共享机器:潜力与挑战
在设想的未来科技世界中,有一种神奇的机器,它能够让我们戴上后即刻感知并体验他人当下的情绪。这种情绪共享机器无疑将深刻地改变我们对人际关系、社会交互乃至人性本质的理解。然而,这一科技创新所带来的影响并非全然积极,也伴随…...

docker 安装python3.8环境镜像并导入局域网
一、安装docker yum -y install docker docker version #显示 Docker 版本信息 可以看到已经下载下来了 拉取镜像python3镜像 二、安装docker 中python3环境 运行本地镜像,并进入镜像环境 docker run -itd python-38 /bin/bash docker run -itd pyth…...

修复“电脑引用的账户当前已锁定”问题的几个方法,看下有没有能帮助到你的
面对“电脑引用的账户当前已锁定,且可能无法登录”可能会让你感到焦虑。这是重复输入错误密码后出现的登录错误。当帐户锁定阈值策略配置为限制未经授权的访问时,就会发生这种情况。 但是,如果你在等待半小时后输入正确的密码,你可以重新访问你的帐户。同样,如果你有一个…...
vp9协议笔记
vp9协议笔记📒 本文主要是对vp9协议的梳理,协议的细节参考官方文档:VP9协议链接(需要加速器) vp9协议笔记 vp9协议笔记📒1. 视频编码概述2. 超级帧superframe(sz):2. fr…...

基于SpringBoot+Flowable的办公流程审批系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Flowable框架的办公流程审批系统以解决传统审批模式中存在的效率低下问题。当前多数组织机构在日常运营中普遍采用人工审批…...

解放你的文档下载焦虑:一键保存30+平台内容的神器
解放你的文档下载焦虑:一键保存30平台内容的神器 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您…...

XSS-Game 实战解析:从Level1到Level18的攻防思维演进
1. XSS-Game入门:理解基础注入逻辑 第一次接触XSS-Game时,很多人会疑惑这到底是个什么游戏。简单来说,这是一个专门设计用来练习XSS(跨站脚本攻击)技术的在线靶场,包含18个难度递增的关卡。每个关卡都模拟了…...
)
保姆级教程:用PennyLane和泰坦尼克号数据集,5分钟上手你的第一个量子分类器(VQC)
量子机器学习实战:用PennyLane构建泰坦尼克号生存预测模型 量子计算正从实验室走向实际应用,而量子机器学习作为交叉领域的前沿方向,为传统算法提供了新的可能性。本文将带您用PennyLane框架,在经典数据集上完成一次完整的量子分类…...

每日大赛间歇期通过Taotoken模型广场探索新模型特性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 每日大赛间歇期通过Taotoken模型广场探索新模型特性 对于每日参与各类AI应用开发或创意大赛的选手而言,比赛间歇期并非…...

终极NGA论坛浏览体验优化指南:5分钟打造你的专属摸鱼神器
终极NGA论坛浏览体验优化指南:5分钟打造你的专属摸鱼神器 【免费下载链接】NGA-BBS-Script NGA论坛增强脚本,给你完全不一样的浏览体验 项目地址: https://gitcode.com/gh_mirrors/ng/NGA-BBS-Script 还在为NGA论坛繁杂的界面和低效的浏览体验烦恼…...

容器化自动化数据抓取平台OpenClaw-Compose部署与实战指南
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一个自动化数据抓取和处理的项目,发现了一个挺有意思的GitHub仓库:alexleach/openclaw-compose。乍一看标题,你可能会觉得这又是一个普通的Docker Compose编排文件集合…...

对比按需计费与Token Plan套餐在长期项目中的成本体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与Token Plan套餐在长期项目中的成本体感 1. 项目背景与初始计费模式 我们团队维护着一个面向内部的知识库问答应用&…...

UVM配置机制深度解析:从字符串匹配原理到验证平台实战
1. 项目概述:从“会用”到“懂它”的跨越在芯片验证的日常工作中,uvm_config_db就像空气和水一样,无处不在。我们用它传递虚拟接口,用它开关某个子系统的功能,用它动态调整测试场景的配置。绝大多数验证工程师都能熟练…...

3D结构光相机 | 抓取/焊接/测量全搞定,高反光黑色物体重建精度高,工业场景全覆盖,户外无惧强光
一 产品介绍苏州三迪斯维出品的3D相机采用主动结构光技术,拍摄速度快、成像精细、方案成熟稳定,针对不同应用场景物体可输出高质量点云数据图,精度高、速度快、环境自适应性强,不用系列适用场景不同,分别如下ÿ…...