Oracle 日常健康脚本
文章目录
- 摘要
- 常用脚本
摘要
保持 Oracle 数据库的良好健康状况对于系统的可靠性和性能至关重要。本文将介绍一些常用的 Oracle 日常健康脚本,帮助您监控数据库并及时识别潜在的问题,以保证数据库的稳定运行。
常用脚本
1.查询数据库实例和实例级别的信息
通过 gv d a t a b a s e 、 g v database、 gv database、gvinstance
查询数据库实例和实例级别的信息。
获取数据库名称、实例名称、平台名称、主机名称、数据库版本和启动时间等信息。
SELECT a.NAME DBNAME,b.instance_name,a.PLATFORM_NAME,b.host_name,b.version,b.startup_timeFROM gV$DATABASE a, gv$instance b
where a.inst_id = b.inst_id
order by 2;
2.查询数据库注册表历史记录的详细信息
包括操作时间、动作和注释。通过按照时间降序排序,可以查看最近执行的注册表更改操作和对应的注释。
SELECT TO_CHAR(ACTION_TIME, 'YYYY-MM-DD HH24:MI:SS') ACTION_TIME,ACTION,COMMENTSFROM SYS.DBA_REGISTRY_HISTORY
ORDER BY 1 DESC;
3.查询从V$LOG_HISTORY表中检索最近10天的日志记录
按照日期和小时统计每个小时的日志数量。查询结果按日期和小时排序。
查询使用了SUBSTR函数来提取日期和小时部分,并通过TO_CHAR函数格式化为’MM/DD/RR HH24:MI:SS’的形式。然后使用DECODE函数根据小时值进行条件判断,如果符合条件则返回1,否则返回0。使用SUM函数对每个小时的返回值进行求和,得到每个小时的日志数量。最后使用COUNT函数统计总日志数量。
SELECT SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH:MI:SS'), 1, 5) DAY,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'00',1,0)) H00,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'01',1,0)) H01,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'02',1,0)) H02,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'03',1,0)) H03,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'04',1,0)) H04,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'05',1,0)) H05,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'06',1,0)) H06,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'07',1,0)) H07,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'08',1,0)) H08,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'09',1,0)) H09,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'10',1,0)) H10,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'11',1,0)) H11,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'12',1,0)) H12,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'13',1,0)) H13,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'14',1,0)) H14,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'15',1,0)) H15,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'16',1,0)) H16,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'17',1,0)) H17,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'18',1,0)) H18,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'19',1,0)) H19,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'20',1,0)) H20,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'21',1,0)) H21,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'22',1,0)) H22,SUM(DECODE(SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH24:MI:SS'), 10, 2),'23',1,0)) H23,COUNT(*) TOTALFROM V$LOG_HISTORY A
WHERE FIRST_TIME > TRUNC(SYSDATE - 10)
GROUP BY SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH:MI:SS'), 1, 5)
ORDER BY SUBSTR(TO_CHAR(FIRST_TIME, 'MM/DD/RR HH:MI:SS'), 1, 5);
4.检索有关数据库存储和结构的统计信息
TOTAL STORAGES 和对应的总存储大小
INDEX STORAGES 和对应的索引存储大小
TABLESPACES 和对应的表空间数量
FILES 和对应的数据文件数量
TOTAL TABLES 和对应的表数量
TOTAL INDEXES 和对应的索引数量
DB_BLOCK_SIZE 和对应的数据块大小
NLS_CHARACTERSET 和对应的字符集
NLS_NCHAR_CHARACTERSET 和对应的NCHAR字符集
set linesize 100
set pages 200
col ITEM format a30
col TOTAL_SIZE format a30
SELECT 'TOTAL STORAGES' AS ITEM,ROUND(SUM(BYTES) / 1024 / 1024 / 1024, 2) || 'GB' TOTAL_SIZEFROM DBA_SEGMENTS
UNION ALL
SELECT 'INDEX STORAGES', ROUND(SUM(BYTES) / 1024 / 1024 / 1024, 2) || 'GB'FROM DBA_SEGMENTS
WHERE SEGMENT_TYPE = 'INDEX'
UNION ALL
SELECT 'TABLESPACES', TO_CHAR(COUNT(*))FROM V$TABLESPACE
UNION ALL
SELECT 'FILES', TO_CHAR(COUNT(*))FROM V$DATAFILE
UNION ALL
SELECT 'TOTAL TABLES', TO_CHAR(COUNT(*))FROM DBA_TABLES
UNION ALL
SELECT 'TOTAL INDEXES', TO_CHAR(COUNT(*))FROM DBA_INDEXES
UNION ALL
SELECT 'DB_BLOCK_SIZE', VALUEFROM V$PARAMETER
WHERE TRIM(UPPER(NAME)) = 'DB_BLOCK_SIZE'
UNION ALL
SELECT T1.PARAMETER, T1.VALUEFROM V$NLS_PARAMETERS T1
WHERE UPPER(TRIM(T1.PARAMETER)) IN('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
5.检索ASM磁盘的相关信息
从V$ASM_DISK视图检索ASM磁盘的相关信息
GROUP_NUMBER:ASM磁盘所属的磁盘组编号。
DISK_NUMBER:ASM磁盘的编号。
TOTAL_MB:ASM磁盘的总容量(以MB为单位)。
FREE_MB:ASM磁盘的可用容量(以MB为单位)。
NAME:ASM磁盘的名称。
FAILGROUP:ASM磁盘所属的失效组。
PATH:ASM磁盘的路径。
CREATE_DATE:ASM磁盘的创建日期和时间。
set linesize 400
set pages 300
col NAME format a15
col FAILGROUP format a15
col PATH format a30
SELECT GROUP_NUMBER,DISK_NUMBER,TOTAL_MB,FREE_MB,NAME,FAILGROUP,PATH,TO_CHAR(CREATE_DATE, 'YYYY-MM-DD HH24:MI:SS') CREATE_DATEFROM V$ASM_DISK A
ORDER BY 1;
6.检索ASM磁盘组的相关信息
GROUP_NUMBER:ASM磁盘组的编号。
NAME:ASM磁盘组的名称。
STATE:ASM磁盘组的状态。可能的值包括:MOUNTED(已挂载)、DISMOUNTED(已卸载)、UNKNOWN(未知)等。
TYPE:ASM磁盘组的类型。例如,NORMAL(普通磁盘组)或HIGH_REDUNDANCY(高冗余磁盘组)。
TOTAL_MB:ASM磁盘组的总容量(以MB为单位)。
FREE_MB:ASM磁盘组的可用容量(以MB为单位)。
这条SQL查询用于从V$ASM_DISKGROUP视图检索ASM磁盘组的相关信息,并按照GROUP_NUMBER和NAME进行排序。
SELECT A.GROUP_NUMBER,A.NAME,A.STATE,A.TYPE, A.TOTAL_MB, A.FREE_MB FROM V$ASM_DISKGROUP A ORDER BY 1, 2
7.查看表空间的相关信息
STATUS:表空间的状态。
NAME:表空间的名称。
TYPE:表空间的类型。
EXTENT_MGT:表空间的数据段管理方式。
SEGMENT_MGT:表空间的段空间管理方式。
TS_SIZE:表空间的总大小(以MB为单位)。
FREE:表空间的可用空间(以MB为单位)。
USED:表空间的已使用空间(以MB为单位)。
PCT_USED:表空间的使用率。
第一部分查询从SYS.DBA_TABLESPACES表、DBA_DATA_FILES表和DBA_FREE_SPACE表中检索非临时表空间的相关信息,并计算出表空间的总大小、可用空间、已使用空间以及使用率。
第二部分查询从SYS.DBA_TABLESPACES表、DBA_TEMP_FILES表和V$TEMP_EXTENT_POOL表中检索临时表空间的相关信息,并计算出表空间的总大小、可用空间、已使用空间以及使用率。
SELECT STATUS,NAME,TYPE,EXTENT_MGT,SEGMENT_MGT,TS_SIZE,FREE,USED,PCT_USEDFROM (SELECT DECODE(D.STATUS, 'OFFLINE', D.STATUS, D.STATUS) STATUS,D.TABLESPACE_NAME NAME,D.CONTENTS TYPE,D.EXTENT_MANAGEMENT EXTENT_MGT,D.SEGMENT_SPACE_MANAGEMENT SEGMENT_MGT,ROUND(NVL(A.BYTES, 0) / 1024 / 1024, 0) TS_SIZE,ROUND(NVL(F.BYTES, 0) / 1024 / 1024, 0) FREE,ROUND(NVL(A.BYTES - NVL(F.BYTES, 0), 0) / 1024 / 1024, 0) USED,DECODE((1 -SIGN(1 - SIGN(TRUNC(NVL((A.BYTES - NVL(F.BYTES, 0)) /A.BYTES * 100,0)) - 90))),1,TO_CHAR(TRUNC(NVL((A.BYTES - NVL(F.BYTES, 0)) / A.BYTES * 100,0))),TO_CHAR(TRUNC(NVL((A.BYTES - NVL(F.BYTES, 0)) / A.BYTES * 100,0)))) || '%%' PCT_USEDFROM SYS.DBA_TABLESPACES D,(SELECT TABLESPACE_NAME, SUM(BYTES) BYTESFROM DBA_DATA_FILESGROUP BY TABLESPACE_NAME) A,(SELECT TABLESPACE_NAME, SUM(BYTES) BYTESFROM DBA_FREE_SPACEGROUP BY TABLESPACE_NAME) FWHERE D.TABLESPACE_NAME = A.TABLESPACE_NAME(+)AND D.TABLESPACE_NAME = F.TABLESPACE_NAME(+)AND NOT (D.EXTENT_MANAGEMENT LIKE 'LOCAL' ANDD.CONTENTS LIKE 'TEMPORARY')ORDER BY 2)
UNION ALL
SELECT DECODE(D.STATUS, 'OFFLINE', D.STATUS, D.STATUS) STATUS,D.TABLESPACE_NAME,D.CONTENTS TYPE,D.EXTENT_MANAGEMENT EXTENT_MGT,D.SEGMENT_SPACE_MANAGEMENT SEGMENT_MGT,ROUND(NVL(A.BYTES, 0) / 1024 / 1024, 2) TS_SIZE,ROUND(NVL(A.BYTES - NVL(T.BYTES, 0), 0) / 1024 / 1024, 2) FREE,ROUND(NVL(T.BYTES, 0) / 1024 / 1024, 2) USED,DECODE((1 -SIGN(1 - SIGN(TRUNC(NVL(T.BYTES / A.BYTES * 100, 0)) - 90))),1,TO_CHAR(TRUNC(NVL(T.BYTES / A.BYTES * 100, 0))),TO_CHAR(TRUNC(NVL(T.BYTES / A.BYTES * 100, 0)))) PCT_USEDFROM SYS.DBA_TABLESPACES D,(SELECT TABLESPACE_NAME, SUM(BYTES) BYTESFROM DBA_TEMP_FILESGROUP BY TABLESPACE_NAME) A,(SELECT TABLESPACE_NAME, SUM(BYTES_CACHED) BYTESFROM V$TEMP_EXTENT_POOLGROUP BY TABLESPACE_NAME) T
WHERE D.TABLESPACE_NAME = A.TABLESPACE_NAME(+)AND D.TABLESPACE_NAME = T.TABLESPACE_NAME(+)AND D.EXTENT_MANAGEMENT LIKE 'LOCAL'AND D.CONTENTS LIKE 'TEMPORARY'
ORDER BY 2;
8.查询RMAN备份作业的相关信息
包括备份名称(BACKUP_NAME)
开始时间(START_TIME)
耗时(ELAPSED_TIME)
状态(STATUS)
输入类型(INPUT_TYPE)
输出设备类型(OUTPUT_DEVICE_TYPE)
输入大小(INPUT_SIZE)
输出大小(OUTPUT_SIZE)
输出速率(OUTPUT_RATE_PER_SEC)
SELECT R.COMMAND_ID BACKUP_NAME,TO_CHAR(R.START_TIME, 'MM/DD/YYYY HH24:MI:SS') START_TIME,R.TIME_TAKEN_DISPLAY ELAPSED_TIME,DECODE(R.STATUS,'COMPLETED',R.STATUS,'RUNNING',R.STATUS,'FAILED',R.STATUS,R.STATUS) STATUS,R.INPUT_TYPE,R.OUTPUT_DEVICE_TYPE,R.INPUT_BYTES_DISPLAY INPUT_SIZE,R.OUTPUT_BYTES_DISPLAY OUTPUT_SIZE,R.OUTPUT_BYTES_PER_SEC_DISPLAY OUTPUT_RATE_PER_SECFROM (SELECT COMMAND_ID,START_TIME,TIME_TAKEN_DISPLAY,STATUS,INPUT_TYPE,OUTPUT_DEVICE_TYPE,INPUT_BYTES_DISPLAY,OUTPUT_BYTES_DISPLAY,OUTPUT_BYTES_PER_SEC_DISPLAYFROM V$RMAN_BACKUP_JOB_DETAILSORDER BY START_TIME DESC) R
WHERE ROWNUM < 30;
9.查看备份集信息(控制文件)
从V$BACKUP_SET,V$BACKUP_PIECE视图查询
BS_KEY:备份集标识(BS.RECID)
PIECE:备份片号(BP.PIECE#)
COPY: 备份片拷贝号(BP.COPY#)
BP_KEY:备份片标识(BP.RECID)
CONTROLFILE_INCLUDED:控制文件是否包含在备份集中的标志列,如果是’NO’则显示为’-',否则显示原值。
STATUS:备份片的状态,将’A’转换为’AVAILABL’,‘D’转换为’DELETED’,‘X’转换为’EXPIRED’。AVAILAB代表可用状态
HANDLE:备份片的句柄信息。格式化为最大长度为25的字符串。
该查询筛选出满足以下条件的备份集和备份片:
备份片的状态为’A’或’X’。
备份集中包含控制文件。
备份集的完成时间在当前时间的前一天以后。
set linesize 500
set pages 500
column BS_KEY format 999999
column PIECE format 99
column COPY format 99
column BS_KEY format 999999
column CONTROLFILE_INCLUDED format a15
column STATUS format a20
column HANDLE format a25
SELECT BS.RECID BS_KEY,BP.PIECE# PIECE,BP.COPY# COPY,BP.RECID BP_KEY,DECODE(BS.CONTROLFILE_INCLUDED, 'NO', '-', BS.CONTROLFILE_INCLUDED) CONTROLFILE_INCLUDED,DECODE(STATUS, 'A', 'AVAILABL', 'D', 'DELETED', 'X', 'EXPIRED') STATUS,HANDLE HANDLEFROM V$BACKUP_SET BS, V$BACKUP_PIECE BP
WHERE BS.SET_STAMP = BP.SET_STAMPAND BS.SET_COUNT = BP.SET_COUNTAND BP.STATUS IN ('A', 'X')AND BS.CONTROLFILE_INCLUDED != 'NO'AND BS.COMPLETION_TIME > SYSDATE - 1
ORDER BY BS.RECID DESC, PIECE# ;
10.获取数据库日志的相关信息
LOG_MODE:数据库的日志模式,将根据LOG_MODE的值进行解码,并显示为更易读的形式。如果LOG_MODE是’ARCHIVELOG’,则显示为’ARCHIVE MODE;如果LOG_MODE是’NOARCHIVELOG’,则显示为’NO ARCHIVE MODE’;否则,将显示原始的LOG_MODE值。
LOG_ARCHIVE_START:日志归档是否启用的标志,根据LOG_MODE进行解码。如果LOG_MODE是’ARCHIVELOG’,则显示为’ENABLED’;如果LOG_MODE是’NOARCHIVELOG’,则显示为’DISABLED’。
CURRENT_LOG_SEQ:当前日志的序列号,从VKaTeX parse error: Expected 'EOF', got '#' at position 35: …’的日志条目的SEQUENCE#̲进行获取。 OLDEST_ON…LOG视图中选择SEQUENCE#的最小值作为最旧的在线日志的序列号。
通过执行这个查询,可以获取数据库的日志模式、日志归档是否启用、当前日志的序列号以及最旧的在线日志的序列号。这些信息对于管理和监控数据库日志非常有用。
SELECT D.LOG_MODE,P.LOG_ARCHIVE_START,C.CURRENT_LOG_SEQ,O.OLDEST_ONLINE_LOG_SEQUENCEFROM (SELECT DECODE(LOG_MODE,'ARCHIVELOG','ARCHIVE MODE','NOARCHIVELOG','NO ARCHIVE MODE',LOG_MODE) LOG_MODEFROM V$DATABASE) D,(SELECT DECODE(LOG_MODE,'ARCHIVELOG','ENABLED','NOARCHIVELOG','DISABLED') LOG_ARCHIVE_STARTFROM V$DATABASE) P,(SELECT A.SEQUENCE# CURRENT_LOG_SEQFROM V$LOG AWHERE A.STATUS = 'CURRENT') C,(SELECT MIN(A.SEQUENCE#) OLDEST_ONLINE_LOG_SEQUENCE FROM V$LOG A) O;
11.查询数据库dblink
包含以下列:OWNER:链接所属的所有者。
DB_LINK:链接的名称。
USERNAME:连接到链接所使用的用户名。
HOST:链接的目标主机。
CREATED:链接的创建时间,格式为 ‘MM/DD/YYYY HH24:MI:SS’
set linesize 500set pagesize 400column OWNER format a10column DB_LINK format a25column USERNAME format a15column HOST format a20column CREATED format a20SELECT OWNER , DB_LINK , USERNAME , HOST , TO_CHAR(CREATED, 'MM/DD/YYYY HH24:MI:SS') CREATED FROM DBA_DB_LINKS ORDER BY OWNER, DB_LINK;
12.查询表的高水位线
SELECT * FROM (SELECT OWNER, SEGMENT_NAME TABLE_NAME, SEGMENT_TYPE, NVL(HWM - AVG_USED_BLOCKS, 0) WASTE_BLOCKS, GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) / GREATEST(NVL(HWM, 1), 1)), 2), 0) WASTE_PER, ROUND(BYTES / 1024 / 1024, 2) TABLE_MB, ROUND(BYTES / 1024 / 1024, 2) * GREATEST(ROUND((NVL(HWM - AVG_USED_BLOCKS, 0) / GREATEST(NVL(HWM, 1), 1)), 2), 0) WASTE_MB, O_TABLESPACE_NAME TABLESPACE_NAME FROM (SELECT A.OWNER OWNER, A.SEGMENT_NAME, A.SEGMENT_TYPE, A.BYTES, B.NUM_ROWS, A.BLOCKS BLOCKS, B.EMPTY_BLOCKS EMPTY_BLOCKS, A.BLOCKS - B.EMPTY_BLOCKS - 1 HWM, DECODE(ROUND((B.AVG_ROW_LEN * NUM_ROWS * (1 + (PCT_FREE / 100))) / C.BLOCKSIZE, 0), 0, 1, ROUND((B.AVG_ROW_LEN * NUM_ROWS * (1 + (PCT_FREE / 100))) / C.BLOCKSIZE, 0)) + 2 AVG_USED_BLOCKS, ROUND(100 * (NVL(B.CHAIN_CNT, 0) / GREATEST(NVL(B.NUM_ROWS, 1), 1)), 2) CHAIN_PER, ROUND(100 * (A.EXTENTS / A.MAX_EXTENTS), 2) ALLO_EXTENT_PER, A.EXTENTS EXTENTS, A.MAX_EXTENTS MAX_EXTENTS, B.NEXT_EXTENT NEXT_EXTENT, B.TABLESPACE_NAME O_TABLESPACE_NAME FROM SYS.DBA_SEGMENTS A, SYS.DBA_TABLES B, SYS.TS$ C WHERE A.OWNER = B.OWNER AND SEGMENT_NAME = TABLE_NAME AND SEGMENT_TYPE = 'TABLE' AND B.TABLESPACE_NAME = C.NAME UNION ALL SELECT A.OWNER OWNER, SEGMENT_NAME || '.' || B.PARTITION_NAME, SEGMENT_TYPE, BYTES, B.NUM_ROWS, A.BLOCKS BLOCKS, B.EMPTY_BLOCKS EMPTY_BLOCKS, A.BLOCKS - B.EMPTY_BLOCKS - 1 HWM, DECODE(ROUND((B.AVG_ROW_LEN * B.NUM_ROWS * (1 + (B.PCT_FREE / 100))) / C.BLOCKSIZE, 0), 0, 1, ROUND((B.AVG_ROW_LEN * B.NUM_ROWS * (1 + (B.PCT_FREE / 100))) / C.BLOCKSIZE, 0)) + 2 AVG_USED_BLOCKS, ROUND(100 * (NVL(B.CHAIN_CNT, 0) / GREATEST(NVL(B.NUM_ROWS, 1), 1)), 2) CHAIN_PER, ROUND(100 * (A.EXTENTS / A.MAX_EXTENTS), 2) ALLO_EXTENT_PER, A.EXTENTS EXTENTS, A.MAX_EXTENTS MAX_EXTENTS, B.NEXT_EXTENT, B.TABLESPACE_NAME O_TABLESPACE_NAME FROM SYS.DBA_SEGMENTS A, SYS.DBA_TAB_PARTITIONS B, SYS.TS$ C, SYS.DBA_TABLES D WHERE A.OWNER = B.TABLE_OWNER AND SEGMENT_NAME = B.TABLE_NAME AND SEGMENT_TYPE = 'TABLE PARTITION' AND B.TABLESPACE_NAME = C.NAME AND D.OWNER = B.TABLE_OWNER AND D.TABLE_NAME = B.TABLE_NAME AND A.PARTITION_NAME = B.PARTITION_NAME), (SELECT TABLESPACE_NAME F_TABLESPACE_NAME, MAX(BYTES) MAX_FREE_SPACE FROM SYS.DBA_FREE_SPACE GROUP BY TABLESPACE_NAME) WHERE F_TABLESPACE_NAME = O_TABLESPACE_NAME AND GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) / GREATEST(NVL(HWM, 1), 1)), 2), 0) > 20 AND OWNER NOT IN ('CTXSYS', 'DBSNMP', 'DMSYS', 'EXFSYS', 'IX', 'LBACSYS', 'MDSYS', 'OLAPSYS', 'ORDSYS', 'OUTLN', 'SYS', 'SYSMAN', 'SYSTEM', 'WKSYS', 'WMSYS', 'XDB', 'APEX_030200', 'ORDDATA') AND BLOCKS > 128 ORDER BY 4 DESC, 1 ASC, 2 ASC)where rownum <= 30;
相关文章:

Oracle 日常健康脚本
文章目录 摘要常用脚本 摘要 保持 Oracle 数据库的良好健康状况对于系统的可靠性和性能至关重要。本文将介绍一些常用的 Oracle 日常健康脚本,帮助您监控数据库并及时识别潜在的问题,以保证数据库的稳定运行。 常用脚本 1.查询数据库实例和实例级别的…...

leetcode670最大交换
给定一个非负整数,你至多可以交换一次数字中的任意两位。返回你能得到的最大值。 示例 1 : 输入: 2736 输出: 7236 解释: 交换数字2和数字7。 示例 2 : 输入: 9973 输出: 9973 解释: 不需要交换。 注意: 给定数字的范围是 [0, 108] int maximumSwap(int num) {…...

XML 注入漏洞原理以及修复方法
漏洞名称:XML注入 漏洞描述:可扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具 有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XM…...

x-cmd pkg | dasel - JSON、YAML、TOML、XML、CSV 数据的查询和修改工具
目录 简介首次用户快速实验指南基本功能性能特点竞品进一步探索 简介 dasel,是数据(data)和 选择器(selector)的简写,该工具使用选择器查询和修改数据结构。 支持 JSON,YAML,TOML&…...

Oracle 19c RAC集群管理 ---------关键参数以及常用命令
Oracle 19c RAC集群管理 ---------关键参数 Oracle 19C RAC 参数最佳实践 --开启强制归档 ALTER DATABASE FORCE LOGGING; --设置 30分钟 强制归档 ALTER SYSTEM SET ARCHIVE_LAG_TARGET1800 SCOPEBOTH SID*; --设置期望undo保持时间3h ALTER SYSTEM SET UNDO_RETENTION21600…...

时限挑战——深度解析Pytest插件 pytest-timeout
在软件开发中,测试用例的执行时间通常是一个关键考虑因素。Pytest插件 pytest-timeout 提供了一个强大的插件,允许你设置测试用例的超时时间。本文将深入介绍 pytest-timeout 插件的基本用法和实际案例,助你精确掌控测试用例的执行时限。 什么…...

Java入门篇:打造你的Java开发环境——从零开始配置IDEA与Eclipse
引言 “工欲善其事,必先利其器” 作为每一位Java初学者的必经之路,搭建合适的开发环境是至关重要的第一步。本篇将详细指导你如何安装并配置两大主流Java开发工具——IntelliJ IDEA和Eclipse,助你在编程之旅上迈出坚实的第一步。 一、Java开发环境准备 1. 下载并安装Java D…...
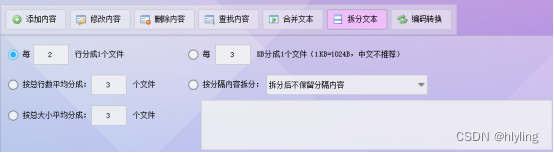
文本批量处理大师:简化文本处理,释放无限生产力!
在数字化时代,我们每天都要处理大量的文本数据,无论是办公文档、网页内容还是社交媒体帖子。然而,面对海量的信息,传统的一键式操作已经无法满足我们的需求。我们需要一个更高效、更智能的工具来提升我们的工作效率。今天…...

Go 方法
第 1 章 方法 Go 语言也支持面向对象的思想;所谓面向对象编程:1对象就是简单的一个值或者变量,并且拥有其方法2方法是某种特定类型的函数3 面向对象编程就是使用方法来描述每个数据结构的属性和操作; 使用者不需要了解对象本身的…...

深度学习与大数据在自然语言处理中的应用与进展
引言 在当今社会,深度学习和大数据技术的快速发展为自然语言处理(NLP)领域带来了显著的进步。这种技术能够使计算机更好地理解和生成人类语言,从而推动了搜索引擎、语音助手、机器翻译等领域的创新和改进。 NLP的发展与技术进步…...
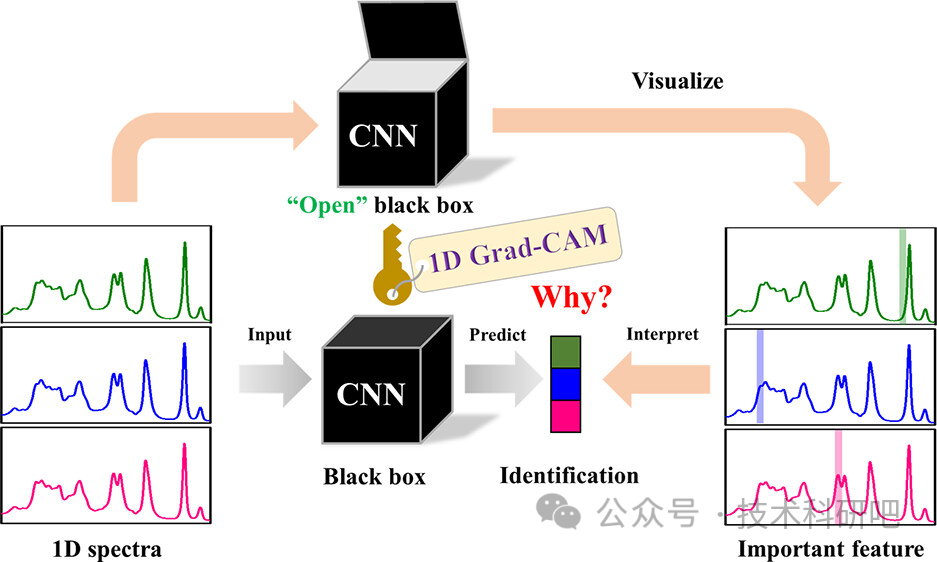
GPT4+Python近红外光谱数据分析及机器学习与深度学习建模
详情点击链接:GPT4Python近红外光谱数据分析及机器学习与深度学习建模 第一:GPT4 1、ChatGPT(GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4模型的演变) 2、ChatGPT对话初体验 3、GPT-4与GPT-3.5的区别,以及与国内大语言模…...
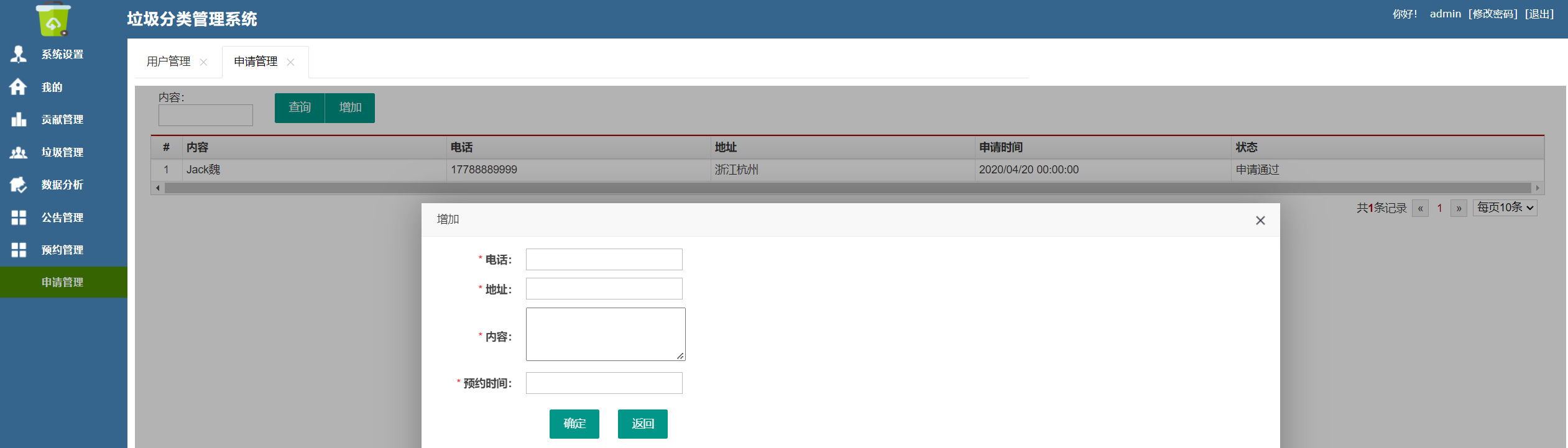
Java项目:12 Springboot的垃圾回收管理系统
作者主页:源码空间codegym 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 1.介绍 垃圾分类查询管理系统,对不懂的垃圾进行查询进行分类并可以预约上门回收垃圾。 让用户自己分类垃圾, 按国家标准自己分类…...

HarmonyOS自定义弹出对话框CustomDialog并传递变量
HarmonyOS定义了一系列弹窗反馈类的组件 和前端开发框架VUE3配套生态库element plus中的提供各种组件相比,还是要少一些。可能是手机端操作和PC端操作的差异导致的 如果内置的弹窗不满足要求,可以基于CustomDialog自定义出各种个性化的反馈组件。 首先新建一个ets文件,…...

React16源码: React中的renderRoot的错误处理的源码实现
renderRoot的错误处理 1 )概述 在 completeWork这个方法之后, 再次回到 renderRoot 里面在 renderRoot 里面执行了 workLoop, 之后,对 workLoop 使用了try catch如果在里面有任何一个节点在更新的过程当中 throw Error 都会被catch到catch到之后就是错误…...
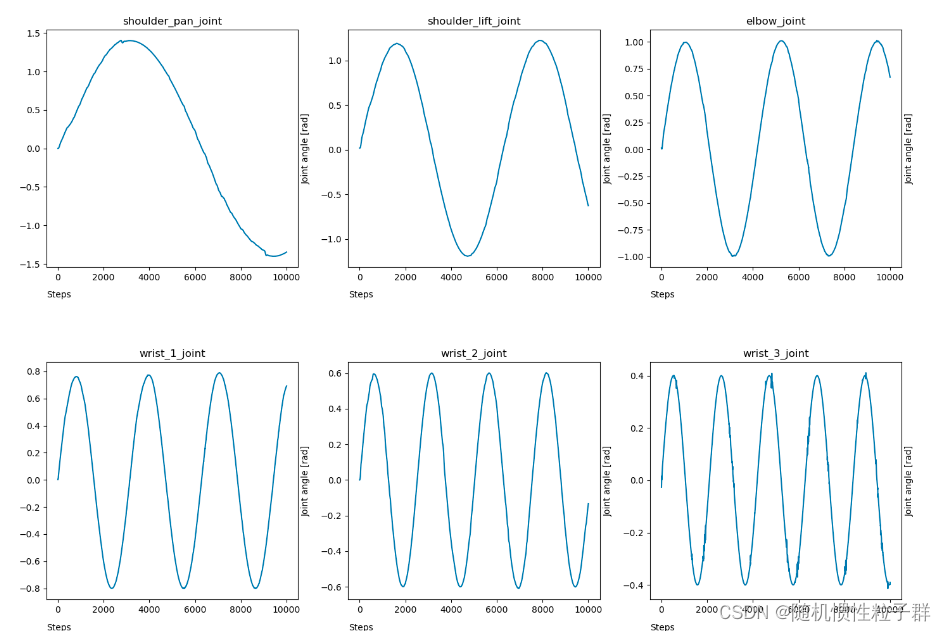
强化学习:MuJoCo机器人强化学习仿真入门(1)
声明:我们跳过mujoco环境的搭建,搭建环境不难,可自行百度 下面开始进入正题(需要有一定的python基础与xml基础): 下面进入到建立机器人模型的部分: 需要先介绍URDF模型文件和导出MJCF格式 介绍完…...

8.Gateway服务网关
3.Gateway服务网关 Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式…...

JVM篇----第四篇
系列文章目录 文章目录 系列文章目录前言一、虚拟机栈(线程私有)二、本地方法区(线程私有)三、你能保证 GC 执行吗?四、怎么获取 Java 程序使用的内存?堆使用的百分比?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到…...

WPF引用halcon的HSmartWindowControlWPF控件一加上Name属性就,无缘无故运行后报错
报错内容: 严重性 代码 说明 项目 文件 行 禁止显示状态 错误 MC1000 未知的生成错误“Could not find assembly System.Drawing.Common, Version0.0.0.0, Cultureneutral, PublicKeyTokencc7b13ffcd2ddd51. Either explicitly load this assembly using a method …...
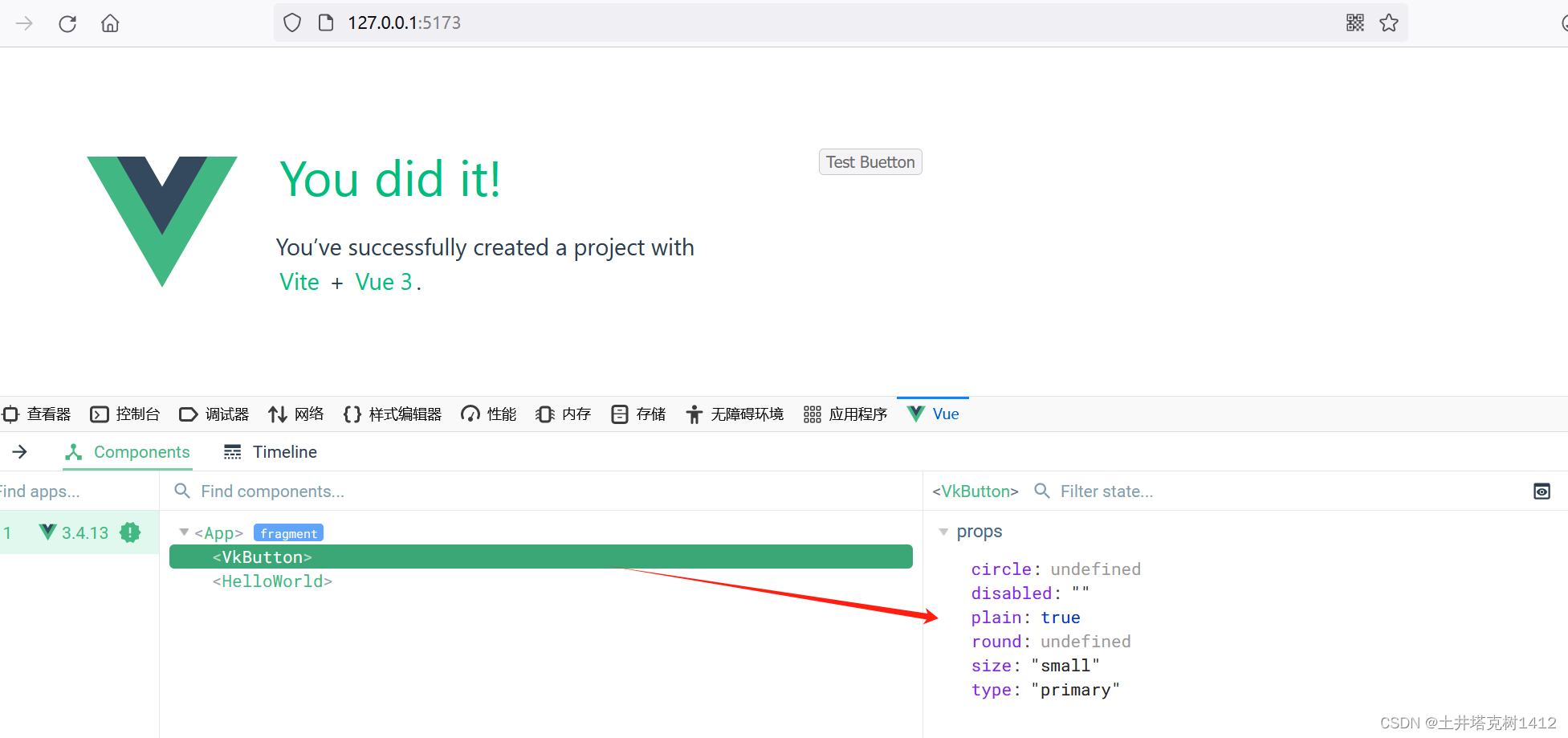
Vue3组件库开发 之Button(2) 未完待续
Vue3组件库开发 之Button(1) 中新建项目,但未安装成功ESLINT 安装ESLINT npm install eslint vite-plugin-eslint --save-dev 安装eslint后,组件文件出现错误提示 添加第三方macros ,虽然不是官网但很多开发者都是vue3开发人员 安装macros…...
k8s节点RouteCreated为false
出现该情况后,一般是初始化节点失败。因此,需要把节点从集群中移除,再加入到集群中,即可解决。 通常出现这个状况后,该节点上是没有被分配pod ip的,可以通过命令查看: # 发现没有PodCIDR、PodC…...

量子计算优化Benders分解:减少量子比特与提升收敛效率
1. 量子辅助Benders分解框架概述混合整数线性规划(MILP)在供应链管理、金融优化和资源调度等领域有着广泛应用。传统Benders分解算法通过将原问题拆分为处理整数变量的主问题(MP)和处理连续变量的子问题(SP)进行迭代求解。然而,随着问题规模扩大,主问题的…...

如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南
如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南 【免费下载链接】ncbi-genome-download Scripts to download genomes from the NCBI FTP servers 项目地址: https://gitcode.com/gh_mirrors/nc/ncbi-genome-download NCBI基因组数据批量…...
)
出租车计价器控制电路的设计(有完整资料)
编号:CJ-32-2022-046设计简介:本设计是出租车计价器控制电路的设计,主要实现以下功能:1、出租车计价器系统以Km 为单位统计里程,以元为单位统计总金额; 2、通过霍尔传感器和电机获取速度和路程;…...

YouTube 视频翻译中文:基于 Whisper + FFmpeg 的自动化流水线实战
一、背景 YouTube 视频翻译中文,本质上是将外语视频通过语音识别(ASR)、文本翻译(NMT)、语音合成(TTS)三个环节处理后,重新合成为中文版本。每一个环节都有成熟的开源工具链支持&am…...

c++ 端口扫描程序实现案例
第一、原理端口扫描的原理很简单,就是建立socket通信,切换不通端口,通过connect函数,如果成功则代表端口开发者,否则端口关闭。所有需要多socket程序熟悉,本内容是在window环境下的第二、单线程实现方式123…...

基于CircuitPython与GBoard的Android摩斯码输入外设制作指南
1. 项目概述与核心价值如果你对摩斯码感兴趣,或者身边有朋友因为行动不便,使用传统触摸屏键盘输入文字非常困难,那么这个项目可能会给你带来一些全新的思路。我们这次要做的,不是一个复杂的、需要焊接和精密加工的电子项目&#x…...

PCL2启动器:离线登录功能完整指南与实战应用
PCL2启动器:离线登录功能完整指南与实战应用 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL Plain Craft Launcher 2(PCL2)作为一款功能…...

基于CircuitPython的红外遥控发射器:从原理到实现的万能控制方案
1. 项目概述:打造你的万能红外遥控发射器搞嵌入式开发的朋友,对红外遥控肯定不陌生。家里电视、空调、风扇的遥控器,本质上都是一个红外信号发射器。你有没有想过,自己动手做一个能模拟所有遥控器的“万能发射器”?今天…...

3大技术优势:AEUX如何实现Sketch/Figma到After Effects的无缝设计转换
3大技术优势:AEUX如何实现Sketch/Figma到After Effects的无缝设计转换 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX AEUX是一款专注于提升UX动效设计效率的开源工具&#…...

DeepMind CEO 访谈:人类离 AGI 只剩 4 年,只差最后 3 块拼图
作者:老纪的技术唠嗑局 楔子 前几天(4 月 29 日),Google DeepMind CEO、2024 年诺贝尔化学奖得主 Demis Hassabis 在一期播客节目《Agents, AGI & The Next Big Scientific Breakthrough》[1] 中,预测 AGI&#…...