GaussDB如何创建和管理序列、定时任务
前言
GaussDB是华为自主创新研发的分布式关系型数据库,为企业提供功能全面、稳定可靠、扩展性强、性能优越的企业级数据库服务。在实际业务场景使用中,为了提高工作效率,数据库GaussDB提供定时任务的功能,本节为大家讲解GaussDB如何创建和管理,序列及定时任务。
目录
一、创建和管理序列
1、操作步骤
方法一: 声明字段类型为序列整型来定义标识符字段。
二、定时任务管理
步骤 1 创建测试表:
步骤 2 创建自定义存储过程:
步骤 3 创建任务:
步骤 4 通过视图查看当前用户已创建的任务信息。
步骤 5 停止任务。
步骤 6 启动任务。
步骤 7 修改任务属性:
步骤 8 删除JOB。
三、总结
一、创建和管理序列
序列Sequence是用来产生唯一整数的数据库对象。序列的值是按照一定规则自增的整数。因为自增所以不重复,因此说Sequence具有唯一标识性。这也是Sequence常被用作主键的原因。
通过序列使某字段成为唯一标识符的方法有两种:
1)一种是声明字段的类型为序列整理,由数据库在后台自动创建一个对应的Sequence。
2)另一种是使用CREATE SEQUENCE自定义一个新的Sequence,然后将nextval('sequence_name')函数读取的序列值,指定为某一字段的默认值,这样该字段就可以作为唯一标识符。
1、操作步骤
方法一: 声明字段类型为序列整型来定义标识符字段。例如:
postgres=# CREATE TABLE T1
(id serial,name text
);
当结果显示为如下信息,则表示创建成功。
CREATE TABLE
方法二:
创建序列,并通过nextval('sequence_name')函数指定为某一字段的默认值。这种方式更灵活,可以为序列定义cache,一次预申请多个序列值,减少与GTM的交互次数,来提高性能。
1、创建序列
postgres=# CREATE SEQUENCE seq1 cache 100;
当结果显示为如下信息,则表示创建成功。
CREATE SEQUENCE
2、指定为某一字段的默认值,使该字段具有唯一标识属性。
postgres=# CREATE TABLE T2
( id int not null default nextval('seq1'),name text
);
当结果显示为如下信息,则表示默认值指定成功。
CREATE TABLE
3、指定序列与列的归属关系。
将序列和一个表的指定字段进行关联。这样,在删除那个字段或其所在表的时候会自动删除已关联的序列。
postgres=# ALTER SEQUENCE seq1 OWNED BY T2.id;
当结果显示为如下信息,则表示指定成功。
ALTER SEQUENCE
注意事项
新序列值的产生是靠GTM维护的,默认情况下,每申请一个序列值都要向GTM发送一次申请,GTM在当前值的基础上加上步长值作为产生的新值返回给调用者。GTM作为全局唯一的节点,势必成为性能的瓶颈,所以对于需要大量频繁产生序列号的操作,如使用Bulkload工具进行数据导入场景,是非常不推荐产生默认序列值的。比如,在下面所示的场景中, INSERT FROM SELECT语句的性能会非常慢。
postgres=# CREATE SEQUENCE newSeq1;
postgres=# CREATE TABLE newT1( id int not null default nextval('newSeq1'), name text);
postgres=# INSERT INTO newT1(name) SELECT name from T1;
可以提高性能的写法是(假设T1表导入newT1表中的数据为10000行):
postgres=# INSERT INTO newT1(id, name) SELECT id,name from T1;
postgres=# SELECT SETVAL('newSeq1',10000);
如果必须要在bulkload场景下产生默认序列值,则一定要为newSeq1定义足够大的cache,并且不要定义Maxvalue或者Minvalue。数据库会试图将nextval('sequence_name')的调用下推到Data Node,以提高性能。 目前GTM对并发的连接请求是有限制的,当Data Node很多时,将产生大量并发连接, 这时一定要控制bulkload的并发数目,避免耗尽GTM的连接资源。如果目标表为复制表(DISTRIBUTE BY REPLICATION)时下推将不能进行。当数据量较大时,这对数据库将是个灾难。除了性能问题之外,空间也可能会剧烈膨胀,在导入结束后,需要用vacuum full来恢复。推荐采用如上建议,不要在bulkload的场景中产生默认序列值。
另外,序列创建后,在每个节点上都维护了一张单行表,存储序列的定义及当前值,但此当前值并非GTM上的当前值,只是保存本节点与GTM交互后的状态。如果其他节点也向GTM申请了新值,或者调用了Setval修改了序列的状态,不会刷新本节点的单行表,但因每次申请序列值是向GTM申请,所以对序列正确性没有影响。
二、定时任务管理
当用户在使用数据库过程中,如果白天执行一些耗时比较长的任务(例如:统计数据汇总之类或从其他数据库同步数据的任务),会对正常的业务有性能影响,所以用户经常选择在晚上执行,这增加了用户的工作量。因此数据库GaussDB提供定时任务的功能,可以由用户创建定时任务,当任务时间点到达后可以自动触发任务的执行,从而可以减少用户户运维的工作量。
GaussDB提供定时任务的创建、任务到期自动执行、任务删除、修改任务属性(包括:任务id、任务的关闭开启、任务的触发时间、触发时间间隔、任务内容等)。
步骤 1 创建测试表:
postgres=# CREATE TABLE test(id int, time date);当结果显示为如下信息,则表示创建成功。
CREATE TABLE步骤 2 创建自定义存储过程:
postgres=# CREATE OR REPLACE PROCEDURE PRC_JOB_1()
AS
N_NUM integer :=1;
BEGIN
FOR I IN 1..1000 LOOP
INSERT INTO test VALUES(I,SYSDATE);
END LOOP;
END;
/当结果显示为如下信息,则表示创建成功。
CREATE PROCEDURE步骤 3 创建任务:
- 新创建的任务(未指定job_id)表示每隔1分钟执行一次存储过程PRC_JOB_1。
postgres=# call dbe_task.submit('call public.prc_job_1(); ', sysdate, 'interval ''1 minute''', :a);
job
-----
1
(1 row)- 指定job_id创建任务,其中job_id可用范围为1~32767。
postgres=# call dbe_task.id_submit(2,'call public.prc_job_1(); ', sysdate, 'interval ''1 minute''');
isubmit
---------(1 row)步骤 4 通过视图查看当前用户已创建的任务信息。
postgres=# select job,dbname,start_date,last_date,this_date,next_date,broken,status,interval,failures,what from my_jobs;
job | dbname | start_date | last_date | this_date | next_date | broken | status | interval | failures | what
-----+--------+---------------------+----------------------------+----------------------------+---------------------+--------+--------+---------------------+----------+---------------------------
1 | postgres | 2017-07-18 11:38:03 | 2017-07-18 13:53:03.607838 | 2017-07-18 13:53:03.607838 | 2017-07-18 13:54:03 | n | s | interval '1 minute' | 0 | call public.prc_job_1();
(1 row)步骤 5 停止任务。
postgres=# call dbe_task.finish(1,true);
broken
--------(1 row)步骤 6 启动任务。
postgres=# call dbe_task.finish(1,false);
broken
--------(1 row)步骤 7 修改任务属性:
- 修改JOB的Next_date参数信息。
--修改Job1的Next_date为1小时以后开始执行。
postgres=# call dbe_task.next_time(1, sysdate+1.0/24);
next_date
-----------(1 row)- 修改JOB的Interval参数信息。
--修改Job1的Interval为每隔1小时执行一次。
postgres=# call dbe_task.interval(1,'sysdate + 1.0/24');
interval
----------(1 row)- 修改JOB的What参数信息。
--修改Job1的What为执行SQL语句“insert into public.test values(333, sysdate+5);”。
postgres=# call dbe_task.content(1,'insert into public.test values(333, sysdate+5);');
what
------(1 row)- 同时修改JOB的Next_date、Interval、What等多个参数信息。
postgres=# call dbe_task.update(1, 'call public.prc_job_1();', sysdate, 'interval ''1 minute''');
change
--------(1 row)步骤 8 删除JOB。
postgres=# call dbe_task.cancel(1);
remove
--------(1 row)三、总结
GaussDB数据库提供了便捷的定时任务功能,以满足不同的需求。在使用这个功能的同时,需要注意,定时任务的设置和使用需要谨慎,避免误删重要数据或影响业务正常运行。同时,也需要保证定时任务的可靠性和稳定性,避免出现任务漏执行或执行重复的情况。
在使用GaussDB数据库时,创建定时任务可以在很多场景中应用,同时可以帮助我们提高系统的运行效率,大大的增加了数据库的便利性。
相关文章:

GaussDB如何创建和管理序列、定时任务
前言 GaussDB是华为自主创新研发的分布式关系型数据库,为企业提供功能全面、稳定可靠、扩展性强、性能优越的企业级数据库服务。在实际业务场景使用中,为了提高工作效率,数据库GaussDB提供定时任务的功能,本节为大家讲解GaussDB如…...

mybatis-plus:代码生成器
一、依赖 代码生成器需要添加一下依赖 <dependencies><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-generator</artifactId><version>3.0.7.1</version></dependency><!-- https://mvnre…...
几款提高开发效率的Idea 插件
1、ignore 开发代码过程中经常会有一些需要提交到代码仓库的文件,比如java文件生成的.class、.jar 等,如果将编译后的文件都提交到代码库那么代码库会很大,关键是没有必要。 这款插件就可以很方便的解决某类文件或者某个文件夹不需要提交到…...
Redisson 分布式锁可重入的原理
目录 1. 使用 Redis 实现分布式锁存在的问题 2. Redisson 的分布式锁解决不可重入问题的原理 1. 使用 Redis 实现分布式锁存在的问题 不可重入:同一个线程无法两次 / 多次获取锁举例 method1 执行需要获取锁method2 执行也需要(同一把)锁如…...
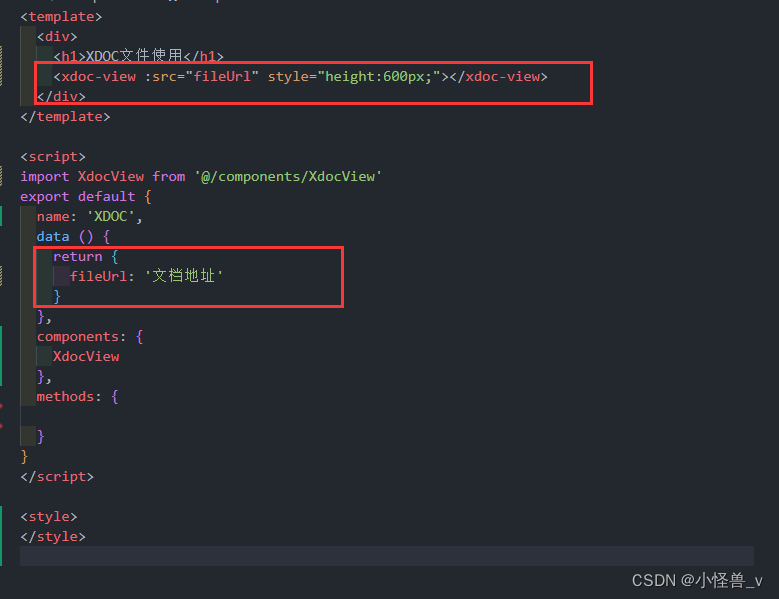
【Vue实用功能】Vue实现文档在线预览功能,在线预览PDF、Word等office文件
1、Office Web(微软的开发接口) 优点 没有 Office也可以直接查看Office 文件适用于移动端、PC无需下载文件就可以在浏览器中查看 <iframe src"文档地址" frameborder"0" /> const docUrl 外网可预览的地址 const url encodeURIComponent(docUrl…...

【一站解决您的问题】mac 利用命令升级nodejs、npm、安装Nodejs的多版本管理器n、nodejs下载地址
一:下载nodejs 官网地址,点击下载稳定版 https://nodejs.org/en 如果官网下载特别慢,可以点击这个地址下载 点击这里 https://nodejs.cn/download/current/ 安装完成后,就包含了nodejs 和 npm。此时您的版本就是下载安装的版本…...
【RabbitMQ】死信(延迟队列)的使用
目录 一、介绍 1、什么是死信队列(延迟队列) 2、应用场景 3、死信队列(延迟队列)的使用 4、死信消息来源 二、案例实践 1、案例一 2、案例二(消息接收确认 ) 3、总结 一、介绍 1、什么是死信队列(延迟队列) 死信,在官网中对应的单词…...
)
java 解析word模板(2024-01-25)
本文主要功能是解析word模板 这是一个word解析类,因为我做的系统用到了而且没有可用的帮助类,只能自己写。之前的实现方式是freemarker 模板解析。但是这次要求用poi不在使用freemarker。实现功能比较少,主要是满足开发需求即可,没…...

flutter-相关个人记录
1、flutter 安卓打包打包报错 flutter build apk -v --no-tree-shake-icons 2、获取华为指纹证书命令 keytool -list -v -keystore ***.jks 3、IOS项目中私有方法查找隐藏文件中 1、cd 项目目录地址 2、grep -r xerbla. "xerbla"为需要查找的关键字 3…...
互斥锁/读写锁(Linux)
一、互斥锁 临界资源概念: 不能同时访问的资源,比如写文件,只能由一个线程写,同时写会写乱。 比如外设打印机,打印的时候只能由一个程序使用。 外设基本上都是不能共享的资源。 生活中比如卫生间,同一…...

Jackson序列化Bean额外属性附加--@JsonAnyGetter、@JsonUnwrapped用户
1. 场景 有一项工作,需要将数据从一个服务S中读取出来(得到的是一个JSON),将数据解析转换以后构造成一个数组的类型A的对象,写入到一个服务T中。 A.class Data public class A {String f0 ;String f1 ; }在发现需要…...

排序算法——冒泡排序算法详解
冒泡排序算法详解 1.引言2.算法概览2.1输入处理2.2核心算法步骤2.3数据结构2.4复杂度分析 3.算法优化4.边界条件和异常处理5.实验和测试6.应用和扩展7.代码示例8.总结 1.引言 冒泡排序是一种简单而直观的比较排序算法,它通过多次遍历数组,比较相邻元素并…...
宋仕强论道之华强北的缺货潮(十六)
始于2019年缺货潮让华强北又生产一大批亿万富翁,缺货的原因主要是:首先,疫情封控导致大量白领在家远程办公,需要购买电脑、打印机等办公设备,同时孩子们也要在家上网课,进一步增加对电子智能终端产品的需求…...

登录注册页面
前提:基于element-ui环境 模态登录组件 分析Login.vue <template><div class"login"><span click"handleClose">X</span></div> </template><script> export default {name: "Login",m…...

视频美颜SDK详解:动态贴纸技术的前沿探索
当下,美颜SDK的动态贴纸技术作为视频美颜的独特亮点,吸引了越来越多开发者和用户的关注。 一、技术详解 动态贴纸技术是视频美颜SDK中的一项创新性功能,它通过在实时视频中添加各种动态效果,为用户提供更加生动有趣的拍摄体验。…...

vue3 实现上传图片裁剪
在线的例子以及代码,请点击访问链接...

flink1.18 广播流 The Broadcast State Pattern 官方案例scala版本
对应官网 https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/fault-tolerance/broadcast_state/ 测试数据 * 广播流 官方案例 scala版本* 广播状态* https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/fault-tolerance…...

vueRouter中scrollBehavior实现滚动固定位置
使用前端路由,当切换到新路由时,想要页面滚到顶部,或者是保持原先的滚动位置,就像重新加载页面那样。 vue-router 能做到,而且更好,它让你可以自定义路由切换时页面如何滚动。 注意: 这个功能只在 HTML5 h…...

解决WinForms跨线程操作控件的问题
解决WinForms跨线程操作控件的问题 介绍 在构建Windows窗体应用程序时,我们通常会遇到需要从非UI线程更新UI元素的场景。由于WinForms控件并不是线程安全的,直接这样做会抛出一个异常:“控件’control name’是从其他线程创建的,…...

从零开始:Git 上传与使用指南
Git 是一种非常强大的版本控制系统,它可以帮助您在多人协作开发项目中更好地管理代码版本,并确保每个团队成员都能及时地获取最新的代码更改。在使用 Git 进行版本控制之前,您需要先进行一些设置,以确保您的代码能够顺利地与远程仓…...

PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南
PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Onl…...

宝塔面板磁盘爆满排查与清理全记录
前言前几天登录宝塔面板,发现磁盘空间告急(日志文件都清理了,怎么磁盘占用率还这么高):81.52G / 98.3G,剩余不足 17%。虽然服务器负载不高,但这个磁盘占用率让人隐隐不安——如果不及时处理&…...

ML:SARSA 的基本原理与实现
在强化学习中,智能体(Agent)并不是一次性从已有标签中学习答案,而是在环境(Environment)中不断尝试动作、观察结果、获得奖励,并根据经验逐步调整行为策略。在 Q 学习中,智能体可以通…...

工业DC-DC电源模块性能选型解析|钡特电源 VB15-48S24MD 与 URB4824YMD-15WR3 封装互通
在工业控制、通信设备、仪器仪表等领域,工业 DC-DC 模块电源作为核心供电单元,其稳定性、兼容性与性价比直接影响系统整体可靠性。随着国产化进程加速,国产工业电源模块在技术、品质上已达到国际先进水平,成为硬件工程师选型的重要…...

React 安装指南
React 安装指南 引言 React 是一个用于构建用户界面的JavaScript库,由Facebook开发。它被广泛用于开发单页应用(SPA)和复杂的前端应用。React的核心库仅负责视图层,而React生态系统还包括了许多其他库和工具,如React Router、Redux等。本指南将详细介绍如何在不同的环境…...

德尔·考德威尔:从微波校准到计量标准,塑造现代精密测量的隐形基石
1. 一位计量学巨匠的遗产:从德尔考德威尔看精密测量的基石在电子工程与测试测量这个庞大而精密的领域里,我们常常关注的是最新的示波器带宽、最前沿的矢量网络分析技术,或是某个芯片的测试方案。然而,支撑起整个现代工业测量体系可…...

从原理到实践:InSAR技术如何重塑地表形变监测
1. 从雷达信号到毫米级形变:InSAR技术原理揭秘 想象一下,你站在湖边向平静的水面扔一块石头,水波会以同心圆的形式向外扩散。如果这时有人在水面另一处也扔了一块石头,两列水波相遇时就会产生干涉现象——有的地方波峰叠加变得更高…...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...

功率MOSFET工作原理与电力电子应用解析
1. 功率MOSFET基础概念解析 功率MOSFET(金属氧化物半导体场效应晶体管)是现代电力电子系统的核心开关器件。与普通MOSFET不同,功率MOSFET专为处理高电压(通常>60V)和大电流(>1A)而设计。其…...
)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点) 在工业自动化领域,老旧产线升级改造往往面临新旧设备通讯协议不兼容的难题。当传统S7-300系统需要与现代化S7-400或带PN接口的PLC进行数据交互时…...