【RT-DETR有效改进】EfficientFormerV2移动设备优化的视觉网络(附对比试验效果图)
前言
大家好,我是Snu77,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PPHGNet版本,其中ResNet为RT-DETR官方版本1:1移植过来的,参数量基本保持一致(误差很小很小),不同于ultralytics仓库版本的ResNet官方版本,同时ultralytics仓库的一些参数是和RT-DETR相冲的所以我也是会教大家调好一些参数和代码,真正意义上的跑ultralytics的和RT-DETR官方版本的无区别
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进机制是特征提取网络EfficientFormerV2,其是一种针对移动设备优化的视觉变换器(Vision Transformer),它通过重新考虑ViTs的设计选择,实现了低延迟和高参数效率,通过修改改网络我们的参数量降低了约百分之五十,GFLOPs也降低了百分之五十,其作为一种高效和轻量化的网络无论从精度还是效果上都非常推荐大家来使用。

专栏链接:RT-DETR剑指论文专栏,持续复现各种顶会内容——论文收割机RT-DETR
目录
一、本文介绍
二、EfficientFormerV2原理
三、EfficientformerV2的核心代码
四、手把手教你添加EfficientformerV2
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
4.5 修改五
4.6 修改六
4.7 修改七
4.8 修改八
4.9 RT-DETR不能打印计算量问题的解决
4.10 可选修改
五、EfficientformerV2的yaml文件
5.1 yaml文件
5.2 运行文件
5.3 成功训练截图
六、全文总结
二、EfficientFormerV2原理

论文地址: 论文官方代码
代码地址: 代码官方代码

EfficientFormerV2是一种针对移动设备优化的视觉变换器(Vision Transformer),它通过重新考虑ViTs的设计选择,实现了低延迟和高参数效率。
关键改进包括:
1. 统一的前馈网络(FFN):通过在FFN中集成深度卷积来增强局部信息处理能力,减少了显式的局部令牌混合器,简化了网络架构。
2. 搜索空间细化:探索了网络深度和宽度的变化,发现更深更窄的网络能够在提高准确性的同时降低参数数量和延迟。
3. MHSA(多头自注意力)改进:通过在值矩阵中加入局部信息和增加不同注意力头之间的交流来提升性能,而不增加模型大小和延迟。
4. 高分辨率下的注意力机制:研究了在早期阶段应用MHSA的策略,通过简化注意力模块的复杂度来提升效率。
5. 双路径注意力下采样:结合了静态局部下采样和可学习的局部下采样,以及通过残差连接的常规跨步卷积来形成局部-全局方式,进一步提高准确性。
6. 联合优化模型大小和速度:通过精细化的联合搜索算法来优化模型大小和速度,找到适合移动设备部署的最优视觉骨干网络。这张图展示了EfficientFormerV2的网络架构设计,它包括不同的阶段,每个阶段都有不同的组件和功能。
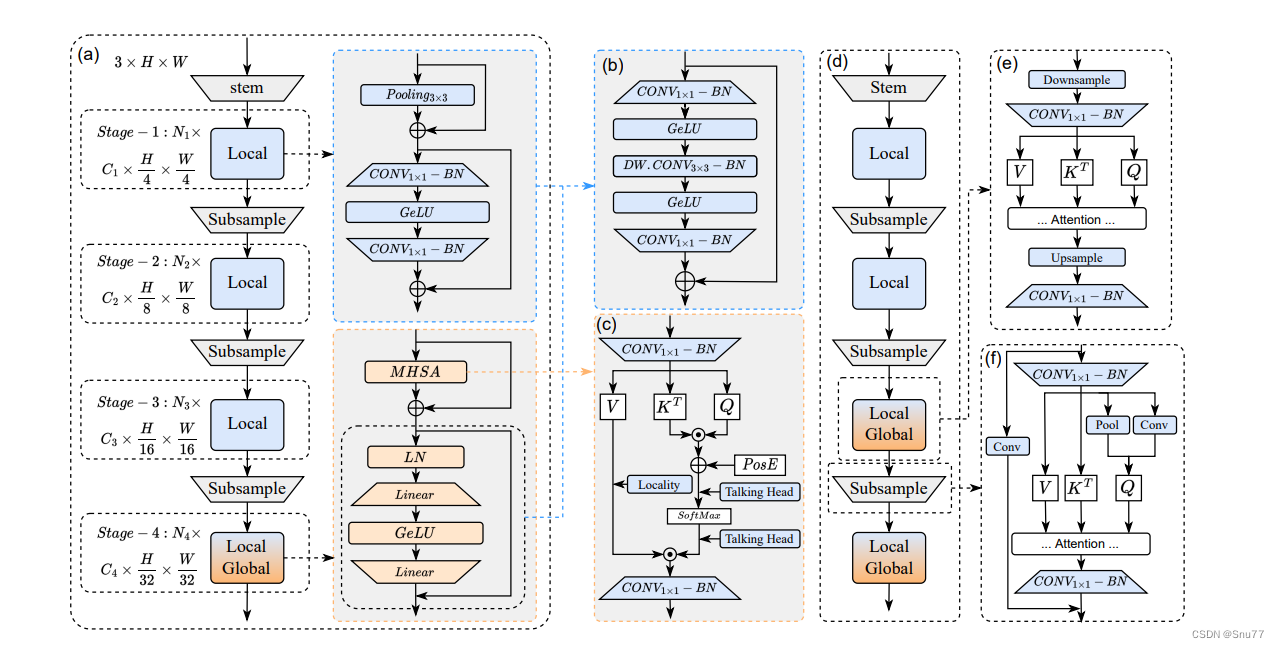
a. 整体架构:从输入层(stem)开始,通过四个阶段逐渐降低分辨率,同时提升特征维度。
b. 统一FFN模块:这一部分结合了池化操作和深度可分离卷积,用于增强局部特征的提取。结合了深度卷积层(DW.Conv3x3-BN),用以加强局部信息的处理。
c. MHSA模块:这是一个多头自注意力机制,其中包含局部性引入和Talking Head机制以提高性能。多头自注意力(MHSA)模块通过引入局部性(Locality)和不同注意力头之间的对话(Talking Head)来提升性能。
d/e. 注意力高分辨率解决方案:在网络的早期层次使用注意力机制,以处理高分辨率的特征图。
f. 双路径注意力下采样:结合了传统的卷积和注意力机制,它结合了卷积和池化操作,实现有效的特征下采样。
三、EfficientformerV2的核心代码
代码的使用方式看章节四。
import os
import torch
import torch.nn as nn
import math
import itertools
from timm.models.layers import DropPath, trunc_normal_, to_2tuple__all__ = ['efficientformerv2_s0', 'efficientformerv2_s1', 'efficientformerv2_s2', 'efficientformerv2_l']EfficientFormer_width = {'L': [40, 80, 192, 384], # 26m 83.3% 6attn'S2': [32, 64, 144, 288], # 12m 81.6% 4attn dp0.02'S1': [32, 48, 120, 224], # 6.1m 79.0'S0': [32, 48, 96, 176], # 75.0 75.7
}EfficientFormer_depth = {'L': [5, 5, 15, 10], # 26m 83.3%'S2': [4, 4, 12, 8], # 12m'S1': [3, 3, 9, 6], # 79.0'S0': [2, 2, 6, 4], # 75.7
}# 26m
expansion_ratios_L = {'0': [4, 4, 4, 4, 4],'1': [4, 4, 4, 4, 4],'2': [4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4],'3': [4, 4, 4, 3, 3, 3, 3, 4, 4, 4],
}# 12m
expansion_ratios_S2 = {'0': [4, 4, 4, 4],'1': [4, 4, 4, 4],'2': [4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4],'3': [4, 4, 3, 3, 3, 3, 4, 4],
}# 6.1m
expansion_ratios_S1 = {'0': [4, 4, 4],'1': [4, 4, 4],'2': [4, 4, 3, 3, 3, 3, 4, 4, 4],'3': [4, 4, 3, 3, 4, 4],
}# 3.5m
expansion_ratios_S0 = {'0': [4, 4],'1': [4, 4],'2': [4, 3, 3, 3, 4, 4],'3': [4, 3, 3, 4],
}class Attention4D(torch.nn.Module):def __init__(self, dim=384, key_dim=32, num_heads=8,attn_ratio=4,resolution=7,act_layer=nn.ReLU,stride=None):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.nh_kd = nh_kd = key_dim * num_headsif stride is not None:self.resolution = math.ceil(resolution / stride)self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),nn.BatchNorm2d(dim), )self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')else:self.resolution = resolutionself.stride_conv = Noneself.upsample = Noneself.N = self.resolution ** 2self.N2 = self.Nself.d = int(attn_ratio * key_dim)self.dh = int(attn_ratio * key_dim) * num_headsself.attn_ratio = attn_ratioh = self.dh + nh_kd * 2self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),nn.BatchNorm2d(self.num_heads * self.key_dim), )self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),nn.BatchNorm2d(self.num_heads * self.key_dim), )self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),nn.BatchNorm2d(self.num_heads * self.d),)self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),nn.BatchNorm2d(self.num_heads * self.d), )self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)self.proj = nn.Sequential(act_layer(),nn.Conv2d(self.dh, dim, 1),nn.BatchNorm2d(dim), )points = list(itertools.product(range(self.resolution), range(self.resolution)))N = len(points)attention_offsets = {}idxs = []for p1 in points:for p2 in points:offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))if offset not in attention_offsets:attention_offsets[offset] = len(attention_offsets)idxs.append(attention_offsets[offset])self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets)))self.register_buffer('attention_bias_idxs',torch.LongTensor(idxs).view(N, N))@torch.no_grad()def train(self, mode=True):super().train(mode)if mode and hasattr(self, 'ab'):del self.abelse:self.ab = self.attention_biases[:, self.attention_bias_idxs]def forward(self, x): # x (B,N,C)B, C, H, W = x.shapeif self.stride_conv is not None:x = self.stride_conv(x)q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)v = self.v(x)v_local = self.v_local(v)v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)attn = ((q @ k) * self.scale+(self.attention_biases[:, self.attention_bias_idxs]if self.training else self.ab))# attn = (q @ k) * self.scaleattn = self.talking_head1(attn)attn = attn.softmax(dim=-1)attn = self.talking_head2(attn)x = (attn @ v)out = x.transpose(2, 3).reshape(B, self.dh, self.resolution, self.resolution) + v_localif self.upsample is not None:out = self.upsample(out)out = self.proj(out)return outdef stem(in_chs, out_chs, act_layer=nn.ReLU):return nn.Sequential(nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(out_chs // 2),act_layer(),nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(out_chs),act_layer(),)class LGQuery(torch.nn.Module):def __init__(self, in_dim, out_dim, resolution1, resolution2):super().__init__()self.resolution1 = resolution1self.resolution2 = resolution2self.pool = nn.AvgPool2d(1, 2, 0)self.local = nn.Sequential(nn.Conv2d(in_dim, in_dim, kernel_size=3, stride=2, padding=1, groups=in_dim),)self.proj = nn.Sequential(nn.Conv2d(in_dim, out_dim, 1),nn.BatchNorm2d(out_dim), )def forward(self, x):local_q = self.local(x)pool_q = self.pool(x)q = local_q + pool_qq = self.proj(q)return qclass Attention4DDownsample(torch.nn.Module):def __init__(self, dim=384, key_dim=16, num_heads=8,attn_ratio=4,resolution=7,out_dim=None,act_layer=None,):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.nh_kd = nh_kd = key_dim * num_headsself.resolution = resolutionself.d = int(attn_ratio * key_dim)self.dh = int(attn_ratio * key_dim) * num_headsself.attn_ratio = attn_ratioh = self.dh + nh_kd * 2if out_dim is not None:self.out_dim = out_dimelse:self.out_dim = dimself.resolution2 = math.ceil(self.resolution / 2)self.q = LGQuery(dim, self.num_heads * self.key_dim, self.resolution, self.resolution2)self.N = self.resolution ** 2self.N2 = self.resolution2 ** 2self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),nn.BatchNorm2d(self.num_heads * self.key_dim), )self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),nn.BatchNorm2d(self.num_heads * self.d),)self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,kernel_size=3, stride=2, padding=1, groups=self.num_heads * self.d),nn.BatchNorm2d(self.num_heads * self.d), )self.proj = nn.Sequential(act_layer(),nn.Conv2d(self.dh, self.out_dim, 1),nn.BatchNorm2d(self.out_dim), )points = list(itertools.product(range(self.resolution), range(self.resolution)))points_ = list(itertools.product(range(self.resolution2), range(self.resolution2)))N = len(points)N_ = len(points_)attention_offsets = {}idxs = []for p1 in points_:for p2 in points:size = 1offset = (abs(p1[0] * math.ceil(self.resolution / self.resolution2) - p2[0] + (size - 1) / 2),abs(p1[1] * math.ceil(self.resolution / self.resolution2) - p2[1] + (size - 1) / 2))if offset not in attention_offsets:attention_offsets[offset] = len(attention_offsets)idxs.append(attention_offsets[offset])self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets)))self.register_buffer('attention_bias_idxs',torch.LongTensor(idxs).view(N_, N))@torch.no_grad()def train(self, mode=True):super().train(mode)if mode and hasattr(self, 'ab'):del self.abelse:self.ab = self.attention_biases[:, self.attention_bias_idxs]def forward(self, x): # x (B,N,C)B, C, H, W = x.shapeq = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N2).permute(0, 1, 3, 2)k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)v = self.v(x)v_local = self.v_local(v)v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)attn = ((q @ k) * self.scale+(self.attention_biases[:, self.attention_bias_idxs]if self.training else self.ab))# attn = (q @ k) * self.scaleattn = attn.softmax(dim=-1)x = (attn @ v).transpose(2, 3)out = x.reshape(B, self.dh, self.resolution2, self.resolution2) + v_localout = self.proj(out)return outclass Embedding(nn.Module):def __init__(self, patch_size=3, stride=2, padding=1,in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d,light=False, asub=False, resolution=None, act_layer=nn.ReLU, attn_block=Attention4DDownsample):super().__init__()self.light = lightself.asub = asubif self.light:self.new_proj = nn.Sequential(nn.Conv2d(in_chans, in_chans, kernel_size=3, stride=2, padding=1, groups=in_chans),nn.BatchNorm2d(in_chans),nn.Hardswish(),nn.Conv2d(in_chans, embed_dim, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(embed_dim),)self.skip = nn.Sequential(nn.Conv2d(in_chans, embed_dim, kernel_size=1, stride=2, padding=0),nn.BatchNorm2d(embed_dim))elif self.asub:self.attn = attn_block(dim=in_chans, out_dim=embed_dim,resolution=resolution, act_layer=act_layer)patch_size = to_2tuple(patch_size)stride = to_2tuple(stride)padding = to_2tuple(padding)self.conv = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,stride=stride, padding=padding)self.bn = norm_layer(embed_dim) if norm_layer else nn.Identity()else:patch_size = to_2tuple(patch_size)stride = to_2tuple(stride)padding = to_2tuple(padding)self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,stride=stride, padding=padding)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):if self.light:out = self.new_proj(x) + self.skip(x)elif self.asub:out_conv = self.conv(x)out_conv = self.bn(out_conv)out = self.attn(x) + out_convelse:x = self.proj(x)out = self.norm(x)return outclass Mlp(nn.Module):"""Implementation of MLP with 1*1 convolutions.Input: tensor with shape [B, C, H, W]"""def __init__(self, in_features, hidden_features=None,out_features=None, act_layer=nn.GELU, drop=0., mid_conv=False):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.mid_conv = mid_convself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)self.apply(self._init_weights)if self.mid_conv:self.mid = nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1,groups=hidden_features)self.mid_norm = nn.BatchNorm2d(hidden_features)self.norm1 = nn.BatchNorm2d(hidden_features)self.norm2 = nn.BatchNorm2d(out_features)def _init_weights(self, m):if isinstance(m, nn.Conv2d):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.fc1(x)x = self.norm1(x)x = self.act(x)if self.mid_conv:x_mid = self.mid(x)x_mid = self.mid_norm(x_mid)x = self.act(x_mid)x = self.drop(x)x = self.fc2(x)x = self.norm2(x)x = self.drop(x)return xclass AttnFFN(nn.Module):def __init__(self, dim, mlp_ratio=4.,act_layer=nn.ReLU, norm_layer=nn.LayerNorm,drop=0., drop_path=0.,use_layer_scale=True, layer_scale_init_value=1e-5,resolution=7, stride=None):super().__init__()self.token_mixer = Attention4D(dim, resolution=resolution, act_layer=act_layer, stride=stride)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,act_layer=act_layer, drop=drop, mid_conv=True)self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.use_layer_scale = use_layer_scaleif use_layer_scale:self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)def forward(self, x):if self.use_layer_scale:x = x + self.drop_path(self.layer_scale_1 * self.token_mixer(x))x = x + self.drop_path(self.layer_scale_2 * self.mlp(x))else:x = x + self.drop_path(self.token_mixer(x))x = x + self.drop_path(self.mlp(x))return xclass FFN(nn.Module):def __init__(self, dim, pool_size=3, mlp_ratio=4.,act_layer=nn.GELU,drop=0., drop_path=0.,use_layer_scale=True, layer_scale_init_value=1e-5):super().__init__()mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,act_layer=act_layer, drop=drop, mid_conv=True)self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.use_layer_scale = use_layer_scaleif use_layer_scale:self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)def forward(self, x):if self.use_layer_scale:x = x + self.drop_path(self.layer_scale_2 * self.mlp(x))else:x = x + self.drop_path(self.mlp(x))return xdef eformer_block(dim, index, layers,pool_size=3, mlp_ratio=4.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,drop_rate=.0, drop_path_rate=0.,use_layer_scale=True, layer_scale_init_value=1e-5, vit_num=1, resolution=7, e_ratios=None):blocks = []for block_idx in range(layers[index]):block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)mlp_ratio = e_ratios[str(index)][block_idx]if index >= 2 and block_idx > layers[index] - 1 - vit_num:if index == 2:stride = 2else:stride = Noneblocks.append(AttnFFN(dim, mlp_ratio=mlp_ratio,act_layer=act_layer, norm_layer=norm_layer,drop=drop_rate, drop_path=block_dpr,use_layer_scale=use_layer_scale,layer_scale_init_value=layer_scale_init_value,resolution=resolution,stride=stride,))else:blocks.append(FFN(dim, pool_size=pool_size, mlp_ratio=mlp_ratio,act_layer=act_layer,drop=drop_rate, drop_path=block_dpr,use_layer_scale=use_layer_scale,layer_scale_init_value=layer_scale_init_value,))blocks = nn.Sequential(*blocks)return blocksclass EfficientFormerV2(nn.Module):def __init__(self, layers, embed_dims=None,mlp_ratios=4, downsamples=None,pool_size=3,norm_layer=nn.BatchNorm2d, act_layer=nn.GELU,num_classes=1000,down_patch_size=3, down_stride=2, down_pad=1,drop_rate=0., drop_path_rate=0.,use_layer_scale=True, layer_scale_init_value=1e-5,fork_feat=True,vit_num=0,resolution=640,e_ratios=expansion_ratios_L,**kwargs):super().__init__()if not fork_feat:self.num_classes = num_classesself.fork_feat = fork_featself.patch_embed = stem(3, embed_dims[0], act_layer=act_layer)network = []for i in range(len(layers)):stage = eformer_block(embed_dims[i], i, layers,pool_size=pool_size, mlp_ratio=mlp_ratios,act_layer=act_layer, norm_layer=norm_layer,drop_rate=drop_rate,drop_path_rate=drop_path_rate,use_layer_scale=use_layer_scale,layer_scale_init_value=layer_scale_init_value,resolution=math.ceil(resolution / (2 ** (i + 2))),vit_num=vit_num,e_ratios=e_ratios)network.append(stage)if i >= len(layers) - 1:breakif downsamples[i] or embed_dims[i] != embed_dims[i + 1]:# downsampling between two stagesif i >= 2:asub = Trueelse:asub = Falsenetwork.append(Embedding(patch_size=down_patch_size, stride=down_stride,padding=down_pad,in_chans=embed_dims[i], embed_dim=embed_dims[i + 1],resolution=math.ceil(resolution / (2 ** (i + 2))),asub=asub,act_layer=act_layer, norm_layer=norm_layer,))self.network = nn.ModuleList(network)if self.fork_feat:# add a norm layer for each outputself.out_indices = [0, 2, 4, 6]for i_emb, i_layer in enumerate(self.out_indices):if i_emb == 0 and os.environ.get('FORK_LAST3', None):layer = nn.Identity()else:layer = norm_layer(embed_dims[i_emb])layer_name = f'norm{i_layer}'self.add_module(layer_name, layer)self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, resolution, resolution))]def forward_tokens(self, x):outs = []for idx, block in enumerate(self.network):x = block(x)if self.fork_feat and idx in self.out_indices:norm_layer = getattr(self, f'norm{idx}')x_out = norm_layer(x)outs.append(x_out)return outsdef forward(self, x):x = self.patch_embed(x)x = self.forward_tokens(x)return xdef efficientformerv2_s0(pretrained=False, **kwargs):model = EfficientFormerV2(layers=EfficientFormer_depth['S0'],embed_dims=EfficientFormer_width['S0'],downsamples=[True, True, True, True, True],vit_num=2,drop_path_rate=0.0,e_ratios=expansion_ratios_S0,**kwargs)return modeldef efficientformerv2_s1(pretrained=False, **kwargs):model = EfficientFormerV2(layers=EfficientFormer_depth['S1'],embed_dims=EfficientFormer_width['S1'],downsamples=[True, True, True, True],vit_num=2,drop_path_rate=0.0,e_ratios=expansion_ratios_S1,**kwargs)return modeldef efficientformerv2_s2(pretrained=False, **kwargs):model = EfficientFormerV2(layers=EfficientFormer_depth['S2'],embed_dims=EfficientFormer_width['S2'],downsamples=[True, True, True, True],vit_num=4,drop_path_rate=0.02,e_ratios=expansion_ratios_S2,**kwargs)return modeldef efficientformerv2_l(pretrained=False, **kwargs):model = EfficientFormerV2(layers=EfficientFormer_depth['L'],embed_dims=EfficientFormer_width['L'],downsamples=[True, True, True, True],vit_num=6,drop_path_rate=0.1,e_ratios=expansion_ratios_L,**kwargs)return modelif __name__ == '__main__':inputs = torch.randn((1, 3, 640, 640))model = efficientformerv2_l()res = model(inputs)for i in res:print(i.size())四、手把手教你添加EfficientformerV2
下面教大家如何修改该网络结构,主干网络结构的修改步骤比较复杂,我也会将task.py文件上传到CSDN的文件中,大家如果自己修改不正确,可以尝试用我的task.py文件替换你的,然后只需要修改其中的第1、2、3、5步即可。
⭐修改过程中大家一定要仔细⭐
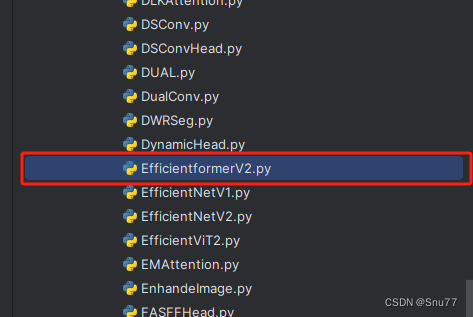
4.1 修改一
首先我门中到如下“ultralytics/nn”的目录,我们在这个目录下在创建一个新的目录,名字为'Addmodules'(此文件之后就用于存放我们的所有改进机制),之后我们在创建的目录内创建一个新的py文件复制粘贴进去 ,可以根据文章改进机制来起,这里大家根据自己的习惯命名即可。
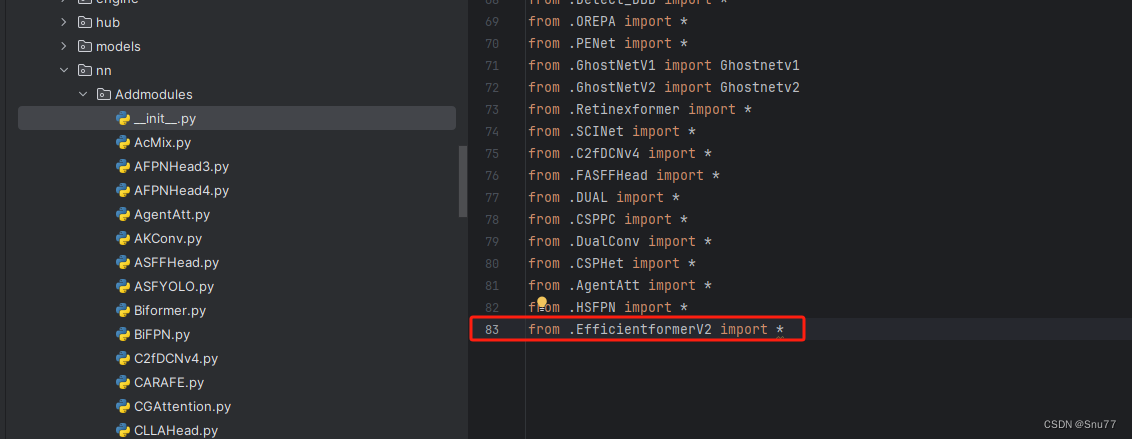
4.2 修改二
第二步我们在我们创建的目录内创建一个新的py文件名字为'__init__.py'(只需要创建一个即可),然后在其内部导入我们本文的改进机制即可,其余代码均为未发大家没有不用理会!。
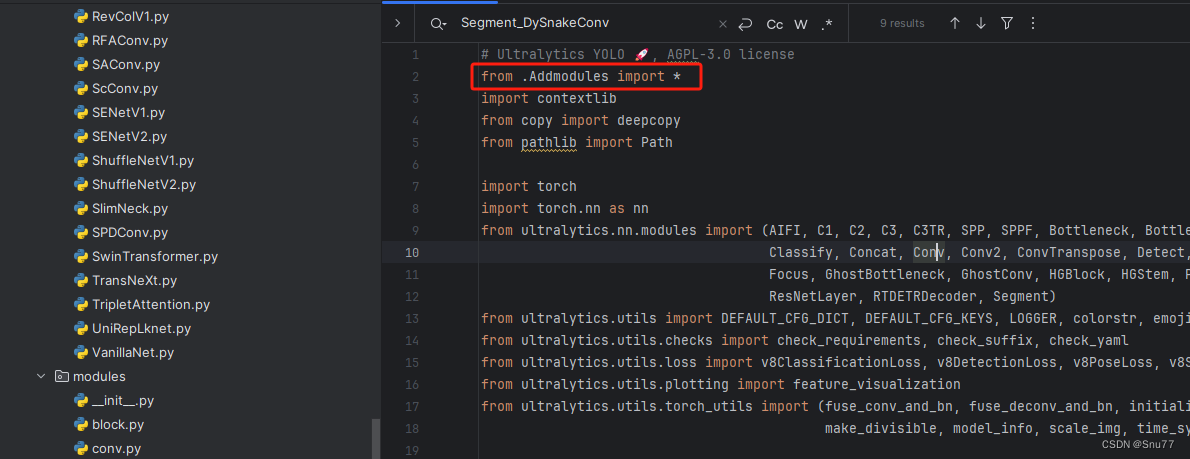
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'然后在开头导入我们的所有改进机制(如果你用了我多个改进机制,这一步只需要修改一次即可)。
4.4 修改四
添加如下两行代码!!!

4.5 修改五
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名(此处我的文件里已经添加很多了后期都会发出来,大家没有的不用理会即可)。
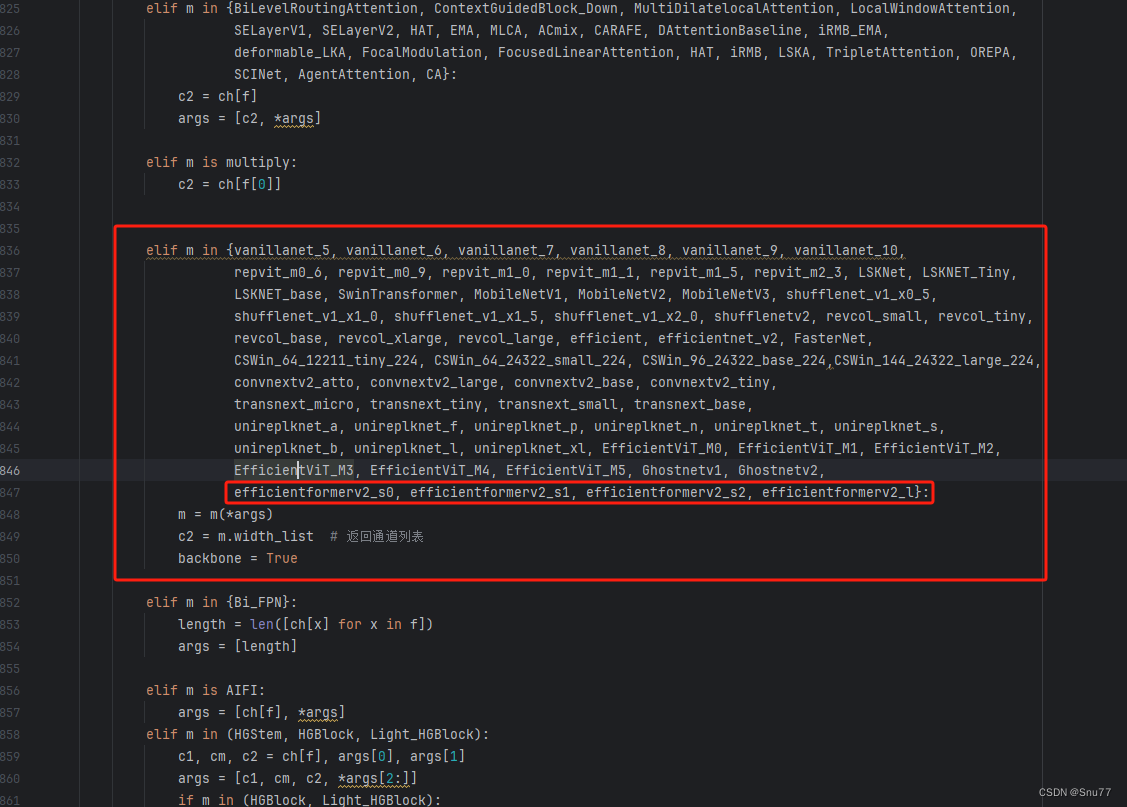
elif m in {自行添加对应的模型即可,下面都是一样的}:m = m(*args)c2 = m.width_list # 返回通道列表backbone = True4.6 修改六
用下面的代码替换红框内的内容。
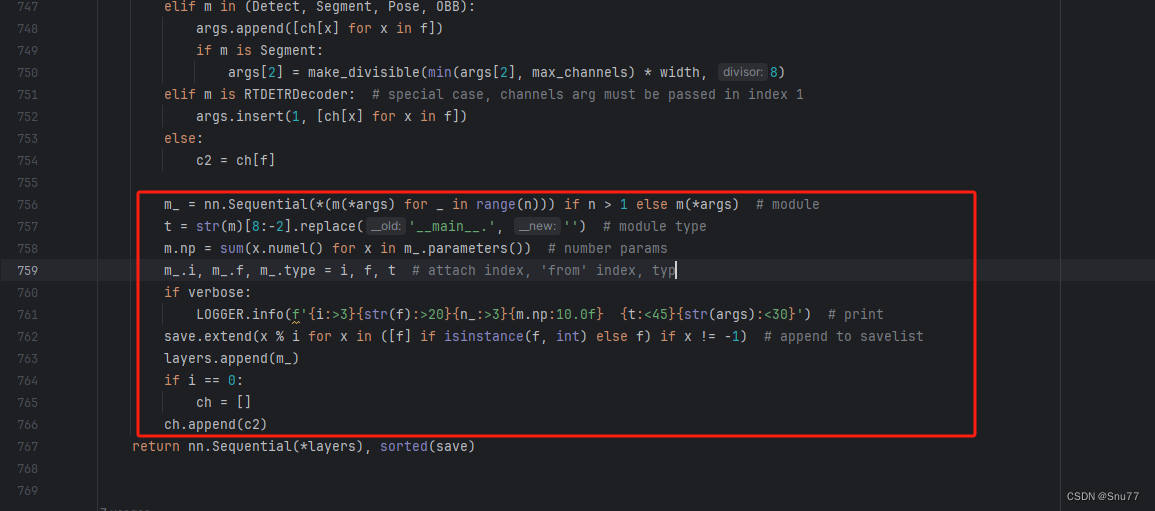
if isinstance(c2, list):m_ = mm_.backbone = True
else:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type
if verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:ch = []
if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)
else:ch.append(c2)4.7 修改七
修改七这里非常要注意,不是文件开头YOLOv8的那predict,是400+行的RTDETR的predict!!!初始模型如下,用我给的代码替换即可!!!

代码如下->
def predict(self, x, profile=False, visualize=False, batch=None, augment=False, embed=None):"""Perform a forward pass through the model.Args:x (torch.Tensor): The input tensor.profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.batch (dict, optional): Ground truth data for evaluation. Defaults to None.augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.embed (list, optional): A list of feature vectors/embeddings to return.Returns:(torch.Tensor): Model's output tensor."""y, dt, embeddings = [], [], [] # outputsfor m in self.model[:-1]: # except the head partif m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)if embed and m.i in embed:embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flattenif m.i == max(embed):return torch.unbind(torch.cat(embeddings, 1), dim=0)head = self.model[-1]x = head([y[j] for j in head.f], batch) # head inferencereturn x4.8 修改八
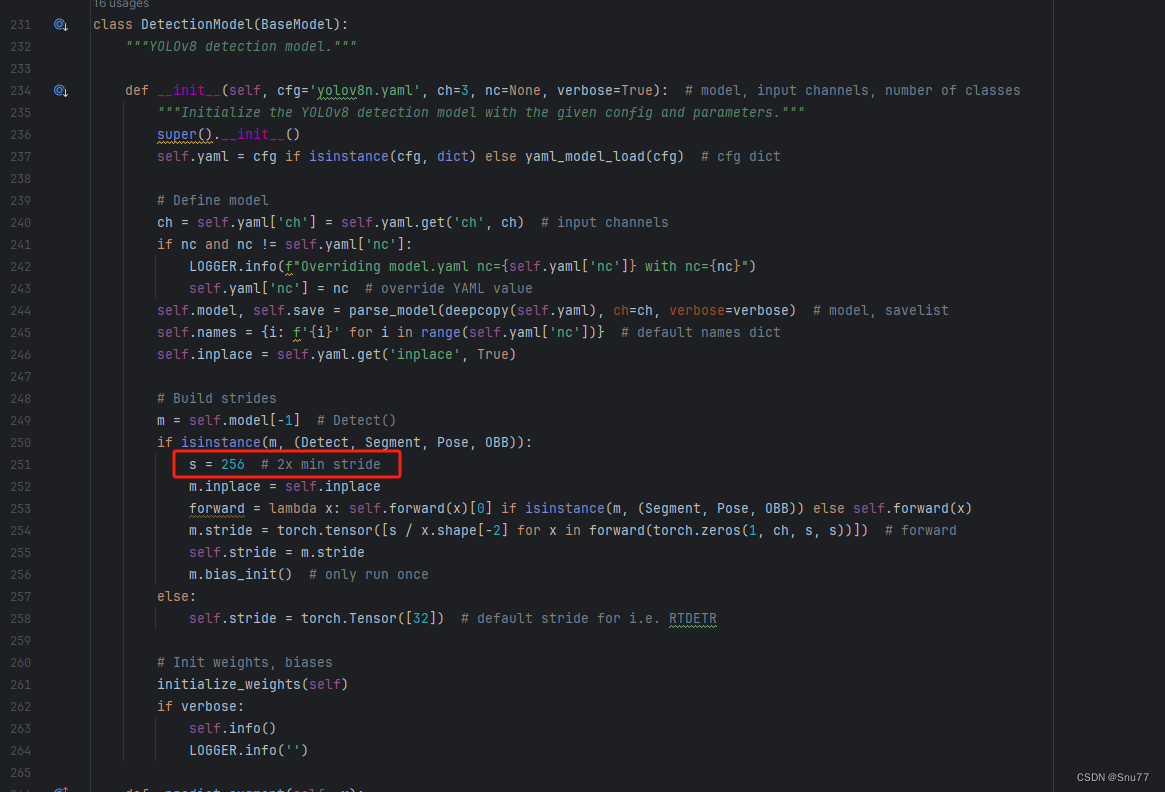
我们将下面的s用640替换即可,这一步也是部分的主干可以不修改,但有的不修改就会报错,所以我们还是修改一下。
4.9 RT-DETR不能打印计算量问题的解决
计算的GFLOPs计算异常不打印,所以需要额外修改一处, 我们找到如下文件'ultralytics/utils/torch_utils.py'文件内有如下的代码按照如下的图片进行修改,大家看好函数就行,其中红框的640可能和你的不一样, 然后用我给的代码替换掉整个代码即可。
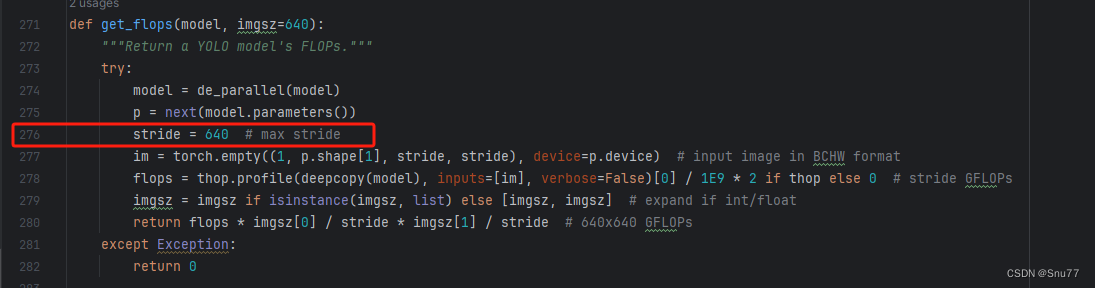
def get_flops(model, imgsz=640):"""Return a YOLO model's FLOPs."""try:model = de_parallel(model)p = next(model.parameters())# stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stridestride = 640im = torch.empty((1, 3, stride, stride), device=p.device) # input image in BCHW formatflops = thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1E9 * 2 if thop else 0 # stride GFLOPsimgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/floatreturn flops * imgsz[0] / stride * imgsz[1] / stride # 640x640 GFLOPsexcept Exception:return 0
4.10 可选修改
有些读者的数据集部分图片比较特殊,在验证的时候会导致形状不匹配的报错,如果大家在验证的时候报错形状不匹配的错误可以固定验证集的图片尺寸,方法如下 ->
找到下面这个文件ultralytics/models/yolo/detect/train.py然后其中有一个类是DetectionTrainer class中的build_dataset函数中的一个参数rect=mode == 'val'改为rect=False

五、EfficientformerV2的yaml文件
5.1 yaml文件
大家复制下面的yaml文件,然后通过我给大家的运行代码运行即可,RT-DETR的调参部分需要后面的文章给大家讲,现在目前免费给大家看这一部分不开放。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'# [depth, width, max_channels]l: [1.00, 1.00, 1024]# 支持下面的版本均可替换
# ['efficientformerv2_s0', 'efficientformerv2_s1', 'efficientformerv2_s2', 'efficientformerv2_l']'
backbone:# [from, repeats, module, args]- [-1, 1, efficientformerv2_s0, []] # 4head:- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 5 input_proj.2- [-1, 1, AIFI, [1024, 8]] # 6- [-1, 1, Conv, [256, 1, 1]] # 7, Y5, lateral_convs.0- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 8- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 9 input_proj.1- [[-2, -1], 1, Concat, [1]] # 10- [-1, 3, RepC3, [256, 0.5]] # 11, fpn_blocks.0- [-1, 1, Conv, [256, 1, 1]] # 12, Y4, lateral_convs.1- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13- [2, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.0- [[-2, -1], 1, Concat, [1]] # 15 cat backbone P4- [-1, 3, RepC3, [256, 0.5]] # X3 (16), fpn_blocks.1- [-1, 1, Conv, [256, 3, 2]] # 17, downsample_convs.0- [[-1, 12], 1, Concat, [1]] # 18 cat Y4- [-1, 3, RepC3, [256, 0.5]] # F4 (19), pan_blocks.0- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.1- [[-1, 7], 1, Concat, [1]] # 21 cat Y5- [-1, 3, RepC3, [256, 0.5]] # F5 (22), pan_blocks.1- [[16, 19, 22], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)5.2 运行文件
大家可以创建一个train.py文件将下面的代码粘贴进去然后替换你的文件运行即可开始训练。
import warnings
from ultralytics import RTDETR
warnings.filterwarnings('ignore')if __name__ == '__main__':model = RTDETR('替换你想要运行的yaml文件')# model.load('') # 可以加载你的版本预训练权重model.train(data=r'替换你的数据集地址即可',cache=False,imgsz=640,epochs=72,batch=4,workers=0,device='0',project='runs/RT-DETR-train',name='exp',# amp=True)5.3 成功训练截图
下面是成功运行的截图(确保我的改进机制是可用的),已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。

六、全文总结
从今天开始正式开始更新RT-DETR剑指论文专栏,本专栏的内容会迅速铺开,在短期呢大量更新,价格也会乘阶梯性上涨,所以想要和我一起学习RT-DETR改进,可以在前期直接关注,本文专栏旨在打造全网最好的RT-DETR专栏为想要发论文的家进行服务。
专栏链接:RT-DETR剑指论文专栏,持续复现各种顶会内容——论文收割机RT-DETR

相关文章:
【RT-DETR有效改进】EfficientFormerV2移动设备优化的视觉网络(附对比试验效果图)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…...

《动手学深度学习(PyTorch版)》笔记4.4
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

Linux/Academy
Enumeration nmap 首先扫描目标端口对外开放情况 nmap -p- 10.10.10.215 -T4 发现对外开放了22,80,33060三个端口,端口详细信息如下 结果显示80端口运行着http,且给出了域名academy.htb,现将ip与域名写到/et/hosts中,然后从ht…...
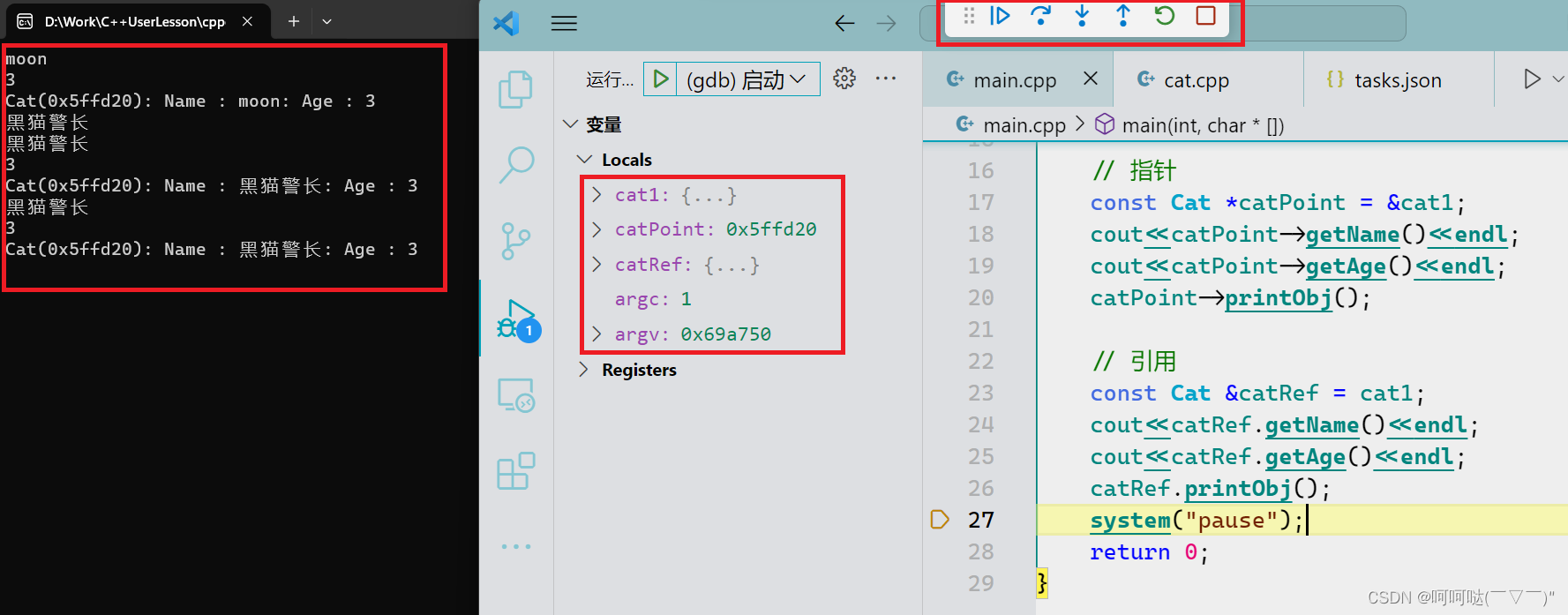
windows .vscode的json文件配置 CMake 构建项目 调试窗口中文设置等
一、CMake 和 mingw64的安装和环境配置 二、tasks.json和launch.json文件配置 tasks.json {"version": "2.0.0","options": {"cwd": "${workspaceFolder}/build"},"tasks": [{"type": "shell&q…...

uniapp canvas做的刮刮乐解决蒙层能自定义图片
最近给湖南中烟做元春活动,一个月要开发4个小活动,这个是其中一个难度一般,最难的是一个类似鲤鱼跃龙门的小游戏,哎,真实为难我这个“拍黄片”的。下面是主要代码。 <canvas :style"{width:widthpx,height:hei…...

利用SPI,结合数据库连接池durid进行数据服务架构灵活设计
接着上一篇文章业务开始围绕原始凭证展开,而展开的基础无疑是围绕着科目展开的。首先我们业务层面以财政部的小企业会计准则的一级科目引入软件中。下面我们来考虑如何将科目切入软件更加灵活,方便业务扩展、维护与升级。 SPI是首先想到的数据服务方式 为什么会想到它呢?首…...

自动驾驶的决策层逻辑
作者 / 阿宝 编辑 / 阿宝 出品 / 阿宝1990 自动驾驶意味着决策责任方的转移 我国2020至2025年将会是向高级自动驾驶跨越的关键5年。自动驾驶等级提高意味着对驾驶员参与度的需求降低,以L3级别为界,低级别自动驾驶环境监测主体和决策责任方仍保留于驾驶…...

排序算法——希尔排序算法详解
希尔排序算法详解 一. 引言1. 背景介绍1.1 数据排序的重要性1.2 希尔排序的由来 2. 排序算法的分类2.1 比较排序和非比较排序2.2 希尔排序的类型 二. 希尔排序基本概念1. 希尔排序的定义1.1 缩小增量排序1.2 插入排序的变种 2. 希尔排序的工作原理2.1 分组2.2 插入排序2.3 逐步…...

Docker 容器内运行 mysqldump 命令来导出 MySQL 数据库,自动化备份
备份容器数据库命令: docker exec 容器名称或ID mysqldump -u用户名 -p密码 数据库名称 > 导出文件.sql请替换以下占位符: 容器名称或ID:您的 MySQL 容器的名称或ID。用户名:您的 MySQL 用户名。密码:您的 MySQL …...

【Java万花筒】数字信号魔法:Java库的魅力解析
从傅立叶到矩阵:数字信号Java库全景剖析 前言 随着数字信号处理在科学、工程和数据分析领域的广泛应用,开发者对高效、灵活的工具的需求日益增长。本文旨在探讨几个与数字信号处理相关的Java库,通过介绍其特点、用途以及与已有库的关系&…...

面试高频知识点:2线程 2.1 线程池 2.1.2 JDK中常见的线程池实现有哪些?
1. Executors类 Executors类是线程池的工厂类,提供了一些静态方法用于创建不同类型的线程池。然而,它的使用并不推荐在生产环境中,因为它存在一些缺点,比如默认使用无界的任务队列,可能导致内存溢出。 2. ThreadPool…...
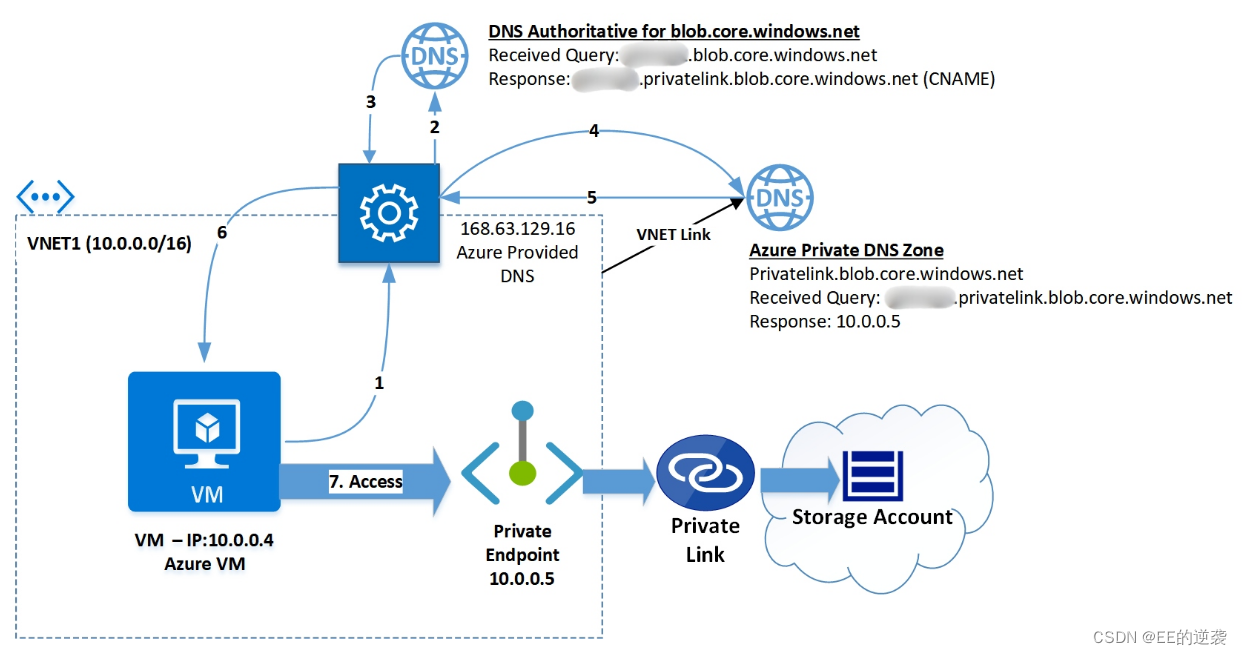
Azure Private endpoint DNS 记录是如何解析的
Private endpoint 从本质上来说是Azure 服务在Azure 虚拟网络中安插的一张带私有地址的网卡。 举例来说如果Storage account在没有绑定private endpoint之前,查询Storage account的DNS记录会是如下情况: Seq Name …...

windows 安装sql server 华为云文档
先安装net3.5,剩下安装sqlserver步骤看下面文档 安装SQL Server_弹性云服务器 ECS_最佳实践_搭建Microsoft SharePoint Server 2016_华为云 (huaweicloud.com)...

相同主题文章竟同时发表在同一个2区期刊 | 孟德尔随机化周报(1.10-1.16)
欢迎报名2024年郑老师团队课程课程! 郑老师科研统计培训,包括临床数据、公共数据分析课程,欢迎报名 孟德尔随机化,Mendilian Randomization,简写为MR,是一种在流行病学领域应用广泛的一种实验设计方法,利用…...

网络安全的使命:守护数字世界的稳定和信任
在数字化时代,网络安全的角色不仅仅是技术系统的守护者,更是数字社会的信任保卫者。网络安全的使命是保护、维护和巩固数字世界的稳定性、可靠性以及人们对互联网的信任。本文将深入探讨网络安全是如何履行这一使命的。 第一部分:信息资产的…...

【七、centos要停止维护了,我选择Almalinux】
搜索镜像 https://developer.aliyun.com/mirror/?serviceTypemirror&tag%E7%B3%BB%E7%BB%9F&keywordalmalinux dvd是有界面操作的,minimal是最小化只有命里行 镜像下载地址 安装和centos基本一样的,操作命令也是一样的,有需要我…...
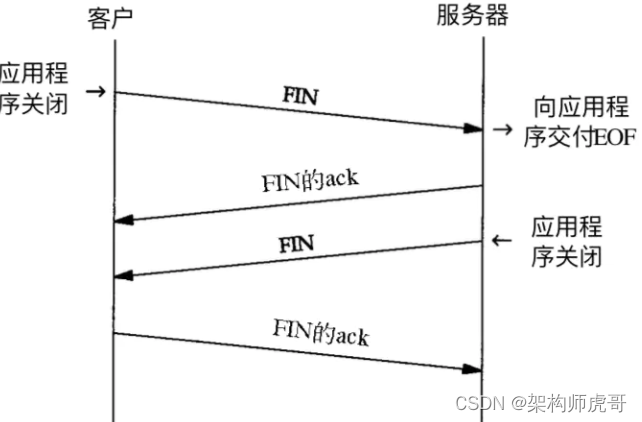
架构师之路(十六)计算机网络(传输层)
前置知识(了解):计算机基础。 作为架构师,我们所设计的系统很少为单机系统,因此有必要了解计算机和计算机之间是怎么联系的。局域网的集群和混合云的网络有啥区别。系统交互的时候网络会存在什么瓶颈。 既然网络层已经…...

python 调用SumatraPDF 静默打印PDF
SumatraPDF 文档 https://www.sumatrapdfreader.org/docs/Command-line-arguments ⽆边框 noscale/缩⼩到合适⼤⼩(默认)shrink/合适⼤⼩ fit/compat 兼容 # 分为 Portrait (纵向)和 Landscape (横向)两类 https://github.com/sumatrapdfreader/sumatrap…...

nginx部署https域名ssl证书
1、在你服务器nginx文件夹下创建ssl文件夹存放证书文件和秘钥文件 把.crt和.key证书放上 2、在nginx.conf文件中配置 在nginx.conf文件中server下加入listen 443 ssl; server {listen 443 ssl;charset utf-8;index index.html index.htm index.jsp index.do;add_heade…...

Python学习之路-Django基础:HelloDjango
Python学习之路-Django基础:HelloDjango 简介 Django,发音为[dʒŋɡəʊ],是用python语言写的开源web开发框架,并遵循MVC设计。劳伦斯出版集团为了开发以新闻内容为主的网站,而开发出来了这个框架,于2005年7月在BSD…...

SAP S/4HANA Cloud Public Edition 3-System Landscape 里的系统与 Tenant 设计
做 SAP S/4HANA Cloud Public Edition 项目时,最容易被低估的一件事,不是功能点本身,而是系统与 tenant 的边界。很多实施风险,并不是来自某个配置字段填错,也不是来自某段 ABAP 扩展代码写得不够优雅,而是项目一开始就没有把 Development、Test、Production、Customizin…...

ChatGPT-PerfectUI:开源前端界面部署与核心功能解析
1. 项目概述:一个为ChatGPT打造的“完美”前端界面如果你和我一样,是ChatGPT的重度用户,每天都要和它进行大量的对话,那么你肯定对官方那个略显简陋的Web界面有过一些“怨念”。功能切换不够直观、对话管理略显笨拙、界面风格万年…...

哈佛医学院:空间组学范式转变!单细胞分子谱→多细胞功能
摘要 空间分辨单细胞技术能够实现细胞的原位分子谱分析,但能够同时发现多细胞空间模式并表征其分子程序的计算方法仍十分有限。本文提出SpatialQuery框架,可同时识别细胞基序(即反复出现的多细胞共定位模式)并开展基序靶向的分子分析。该框架通过差异表达分析挖掘受空间微…...

从YUYV到MJPEG:一次搞懂Linux V4L2摄像头像素格式的坑,附帧数据保存实战
从YUYV到MJPEG:深入解析Linux V4L2摄像头像素格式与实战避坑指南 当你在Linux系统下通过V4L2框架采集摄像头数据时,是否遇到过保存的图片无法打开、颜色显示异常或者帧数据莫名其妙损坏的情况?这些问题的根源往往在于对像素格式的理解不足。本…...

如何永久免费使用Cursor Pro:完整破解指南与工具详解
如何永久免费使用Cursor Pro:完整破解指南与工具详解 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

Neovim AI编程助手codecompanion.nvim:无缝集成与高效开发实践
1. 项目概述:一个为Neovim而生的AI编程伴侣如果你和我一样,是个深度依赖Neovim进行日常开发的程序员,那么你一定经历过这样的时刻:面对一段复杂的逻辑,需要反复查阅文档;或者写一个函数时,卡在某…...

MarkFlowy桌面应用打包与发布:Tauri框架实战经验分享
MarkFlowy桌面应用打包与发布:Tauri框架实战经验分享 【免费下载链接】MarkFlowy The AI Markdown Editor 项目地址: https://gitcode.com/gh_mirrors/ma/MarkFlowy MarkFlowy作为一款高性能智能化跨端Markdown编辑器,采用Tauri框架实现了轻量级桌…...

Linux系统变更追踪工具whatdiditdo:实现文件级监控与审计
1. 项目概述:一个追踪系统变更的“时光机”最近在排查一个线上服务故障,问题最终定位到是某个依赖库在几天前的一次静默升级上。为了搞清楚到底是谁、在什么时候、改了什么东西,我不得不翻遍了近一周的服务器操作日志、CI/CD流水线记录和版本…...

AI VTuber技术栈全解析:从Live2D到GPT-SoVITS的实战搭建指南
1. 项目概述:为什么我们需要一份AI VTuber的“Awesome”清单? 如果你最近在GitHub、B站或者一些技术社区里逛过,大概率会看到一个词反复出现: AI VTuber 。它不再是科幻电影里的概念,而是正在快速渗透到直播、内容创…...

对抗测试框架:用字节码增强与混沌工程提升系统韧性
1. 项目概述:一个对抗测试的“剧院”最近在开源社区里,我注意到一个名字挺有意思的项目,叫nanami7777777/anti-test-theater。乍一看,这个标题有点让人摸不着头脑——“反测试剧院”?测试和剧院能扯上什么关系…...