让AI帮你说话--GPT-SoVITS教程
有时候我们在录制视频的时候,由于周边环境嘈杂或者录音设备问题需要后期配音,这样就比较麻烦。一个比较直观的想法就是能不能将写好的视频脚本直接转换成我们的声音,让AI帮我们完成配音呢?在语音合成领域已经有很多这类工作了,最近网上了解到一个效果比较好的项目GPT-SoVITS,尝试了一下,趟了一些坑,记录一下操作过程。
首先附上大佬的仓库和教程:
- GitHub链接
- 视频教程
下载代码和创建环境
电脑配置
Windows11
CUDA 12.1
显卡RTX 4070
Anaconda
下载代码
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
创建环境
conda create -n gpt-sovits python=3.9
conda activate gpt-sovits
Windows
pip install -r requirements.txt
conda install ffmpeg
#下载以下两个文件到GPT-SoVITS项目根目录
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
下载模型
1、在GPT_SoVITS\pretrained_models打开终端输入:
git clone https://huggingface.co/lj1995/GPT-SoVITS
如果不成功,先尝试下面语句,然后再次clone代码:
git lfs install
如果还不成功,需要确认网络是否能连外网。
下载完模型后,将模型文件拷到GPT_SoVITS\pretrained_models目录下:

2、到modelscope下载以下模型:
git clone https://www.modelscope.cn/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch.git
git clone https://www.modelscope.cn/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch.git
git clone https://www.modelscope.cn/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch.git
将以上模型文件放到tools/damo_asr/models目录下:

如果训练的音频数据有杂音的话,还需要下载UVR5模型对音频先进行去噪处理,放到tools/uvr5/uvr5_weights目录下:
git clone https://huggingface.co/lj1995/VoiceConversionWebUI
运行demo
配置好环境和模型后,在终端输入:
python webui.py
如果报以下错误,说明装的Torch不是CUDA版本的,需要重装对应的CUDA版本的pytorch。
AssertionError: Torch not compiled with CUDA enabled
运行起来后界面如下:

微调和推理模型
处理数据
下载的原始模型一般就可以用来推理转换声音了,但是如果想要转换的声音更真实,本地又有GPU的话,可以进一步尝试微调模型,进一步提升转换声音的真实性。
-
首先我们要收集一段我们自己的录音作为微调数据集,最好将格式保存为wav格式。
-
然后将音频进行切分和标注,这里就用webUI工具进行处理,在音频自动切分输入路径中填入我们保存得wav格式音频文件路径,其余参数根据需要调整,点击开始语音切割,切割完成后的文件保存在output/slicer_opt文件夹中。

-
切分完后需要对语音进行识别成中文文本,执行下面的中文批量离线ASR工具,填写批量ASR输入文件夹路径为上一步的子音频输出目录。

若出现以下报错:
KeyError: 'funasr-pipeline is not in the pipelines registry group auto-speech-recognition. Please make sure the correct version of ModelScope library is used.'
说明funasr版本有问题,需要修改一下tools\damo_asr\cmd-asr.py为:
path_asr='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch'
path_vad='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch'
path_punc='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch'
path_asr=path_asr if os.path.exists(path_asr)else "damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
path_vad=path_vad if os.path.exists(path_vad)else "damo/speech_fsmn_vad_zh-cn-16k-common-pytorch"
path_punc=path_punc if os.path.exists(path_punc)else "damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
# 注释掉这块代码
# inference_pipeline = pipeline(
# task=Tasks.auto_speech_recognition,
# model=path_asr,
# vad_model=path_vad,
# punc_model=path_punc,
# )
model = AutoModel(model=path_asr,vad_model=path_vad,punc_model=path_punc,#spk_model="damo/speech_campplus_sv_zh-cn_16k-common",#spk_model_revision="v2.0.0")
opt=[]
for name in os.listdir(dir):try:# 这里也注释# text = inference_pipeline(audio_in="%s/%s"%(dir,name))["text"]text = model.generate(input="%s/%s"%(dir,name),batch_size_s=300, hotword='魔搭')print(f"asr text:{text}")opt.append("%s/%s|%s|ZH|%s"%(dir,name,opt_name,text))except:print(traceback.format_exc())
...
在转换完成后,会在目录 \GPT-SoVITS\output\asr_opt下生成slicer_opt.list文件,里面就是每段音频对应的文本。
4. 得到文本后,需要对文本进行打标矫正,将**\GPT-SoVITS\output\asr_opt\slicer_opt.list**路径填到 打标数据标注文件路径中,然后勾选开启打标webUI。

然后在打标界面进行标注矫正

在这个界面可以进一步拆分合并音频和修改文本,修改后需要点击Submit Text保存。
5. 接下来对得到的音频文件和文本标注文件进行格式化转换,切换到1-GPT-SoVITS-TTS页面,填写相应的实验名,文本标注文件和训练集音频文件,然后点击下面的一键三连等待转换完成即可。

等到输出信息显示一键三连进程结束说明格式化数据集成功。
若中途报错 Resource cmudict not found.Please use the NLTK Downloader to obtain the resource,在命令行中尝试下面语句,下载弹出界面的东西即可
import nltk
nltk.download('cmudict')
微调模型
然后切换到1B-微调训练界面,设置相应的训练参数即可开始训练SoVITS和GPT。需要注意根据显卡显存调整batch size大小避免OOM。

训练成功后,SoVITS权重和GPT权重会分别保存到SoVITS_weights和GPT_weights文件夹下,然后我们就可以选择我们微调好的模型进行推理了。
推理模型
选择1C-推理界面,点击刷新模型路径,在GPT模型列表和SoVITS模型列表中选择我们微调好的模型,然后勾选下面的 开启TTS推理WebUI,等待推理页面打开。

打开后选择上传参考音频,这里我们可以选择我们之前分割的音频和其对应的标注文本。然后在输入要合成的文本,选择相应的合成语种,点击合成语音,几秒后即可合成对应的语音。若输入的文本过长,需要使用下方的切分工具先对文本进行切分。

合成完成后,点击输出的语音即可试听和下载生成的语音。如果生成的效果不满意,可以重复多试几次。如果生成的效果实在不行,需要重新收集质量更好的自己的录音进行重新微调。
得到满意的模型之后,以后就可以将准备好的文字脚本直接转换成自己的声音,不用再专门录音去噪了,懒人福音~
最后,本文章仅为学习目的使用,请不要将方法应用于任何可能的非法用途。
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
注:本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.
相关文章:
让AI帮你说话--GPT-SoVITS教程
有时候我们在录制视频的时候,由于周边环境嘈杂或者录音设备问题需要后期配音,这样就比较麻烦。一个比较直观的想法就是能不能将写好的视频脚本直接转换成我们的声音,让AI帮我们完成配音呢?在语音合成领域已经有很多这类工作了&…...

线性回归需要满足的几个假设
线性回归模型是基于一些假设构建的,这些假设有助于确保模型的有效性和可解释性。以下是线性回归需要满足的几个主要假设: 线性关系假设(Linearity): 线性回归假设因变量(目标变量)与自变量(特征…...
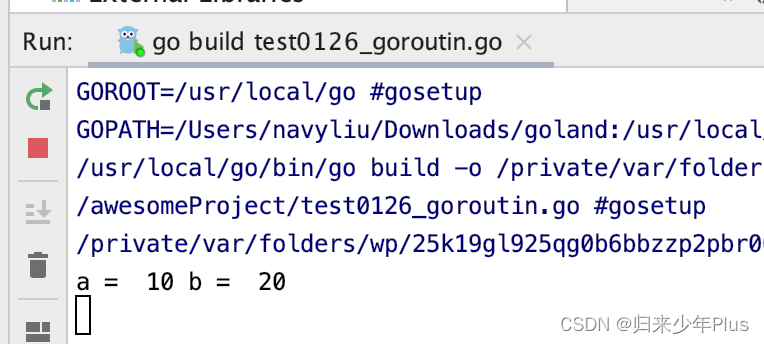
go语言(十八)---- goroutine
一、goroutine package mainimport ("fmt""time" )func main() {//用go创建承载一个形参为空,返回值为空的一个函数go func() {defer fmt.Println("A.defer")func() {defer fmt.Println("B.defer")//退出当前goroutinefmt…...
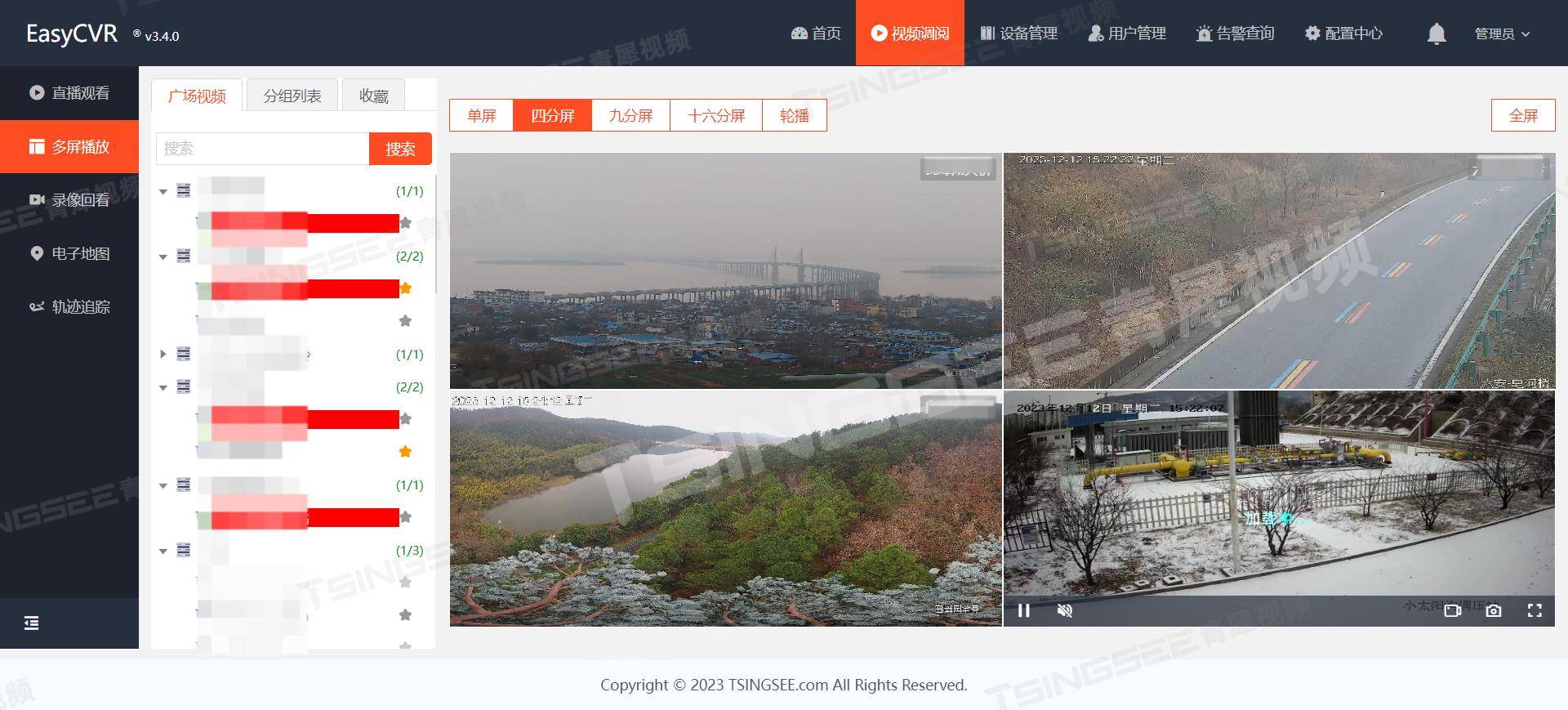
城市开发区视频系统建设方案:打造视频基座、加强图像数据治理
一、背景需求 随着城市建设的步伐日益加快,开发区已经成为了我国工业化、城镇化和对外开放的重要载体。自贸区、开发区和产业园的管理工作自然也变得至关重要。在城市经开区的展览展示馆、进出口商品展示交易中心等地,数千路监控摄像头遍布各角落&#…...

宏景eHRSmsAcceptGSTXServle存在XXE漏洞
指纹特征 app"HJSOFT-HCM"漏洞复现 POST /servlet/sms/SmsAcceptGSTXServlet HTTP/1.1 Host: User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 Content-Length: 137 Content…...

LLVM实战之模块化设计
目录 1. llvm基础理念 2. 准备工作 3. 详细步骤 3.1 指令合并优化 3.2 无用参数消除优化 4. Pass管理器(Pass Manager)...
可以运行在浏览器的Windows 2000
Windows 2000 可以在浏览器里跑了,缺点就是速度慢。 JSLinux JSLinux 在浏览器中运行 Linux 或其他操作系统! 可以使用以下仿真系统: 中央处理器操作系统用户 界面VF同步 访问启动 链接TEMU 配置评论x86阿尔派Linux 3.12.0安慰是的点击这…...

CUDA笔记
CUDA笔记 nvidia-smi 命令使用 nvidiasmi -q:查询GPU详细信息; nvidia-smi -q -l 0:查询特定GPU详细信息; nvidia-smi -q -l 0 -d MEMORY:显示GPU特定信息; nvidia-smi -h:英伟达的帮助命令。…...

Open CASCADE学习| 提取曲面的PCurve
PCurve这个概念,字面上来理解就是参数曲线(Parametric Curve)。参数空间曲线是在参数曲面的双参数空间中的二维样条曲线。 二维曲线定义的目的只有一个:pCurve,参数曲线。OCC采用参数法构建几何结构,所有的…...
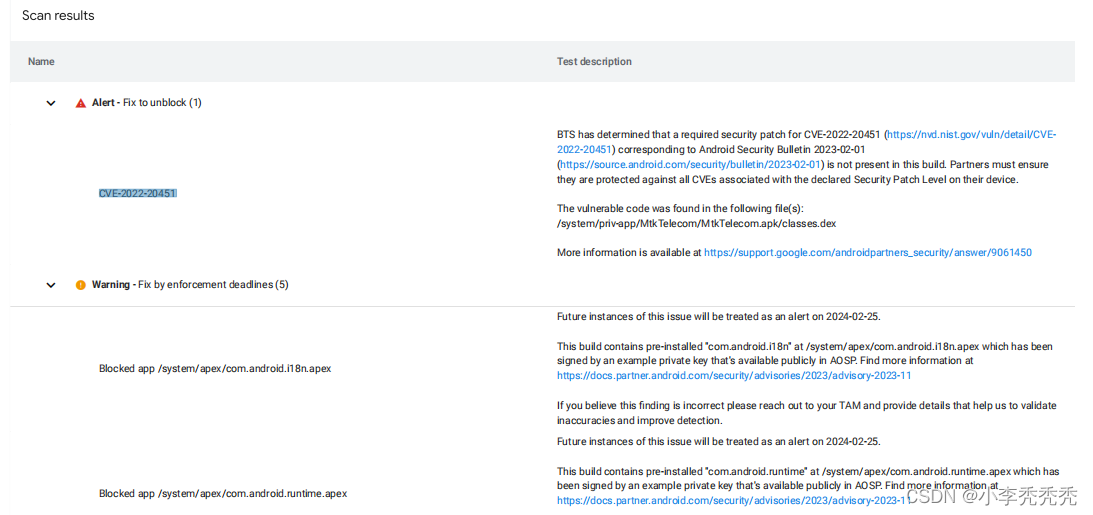
GMS测试BTSfail-CVE-2022-20451
描述: 项目需要过GMS兼容性测试,BTS这块我们环境没有,送检之后出现了一个BTS的Alert,这个是必须要解决的。下面的warning可以不考虑。 这个是patch问题,根据代理提供的pdf文件找到一个id:为A-235098883的补丁…...

Vue学习笔记12--Vue3之setup/ref函数/reactive函数/Vue3响应式原理/reactive对比ref
一、拉开序幕的setup 理解:Vue3中一个新的配置项,值为一个函数。setup是所有Composition API(组合API)表演的舞台。组件中所用到的:数据、方法等,均要配置在setup中。setup函数的两种返回值: 若返回一个对…...
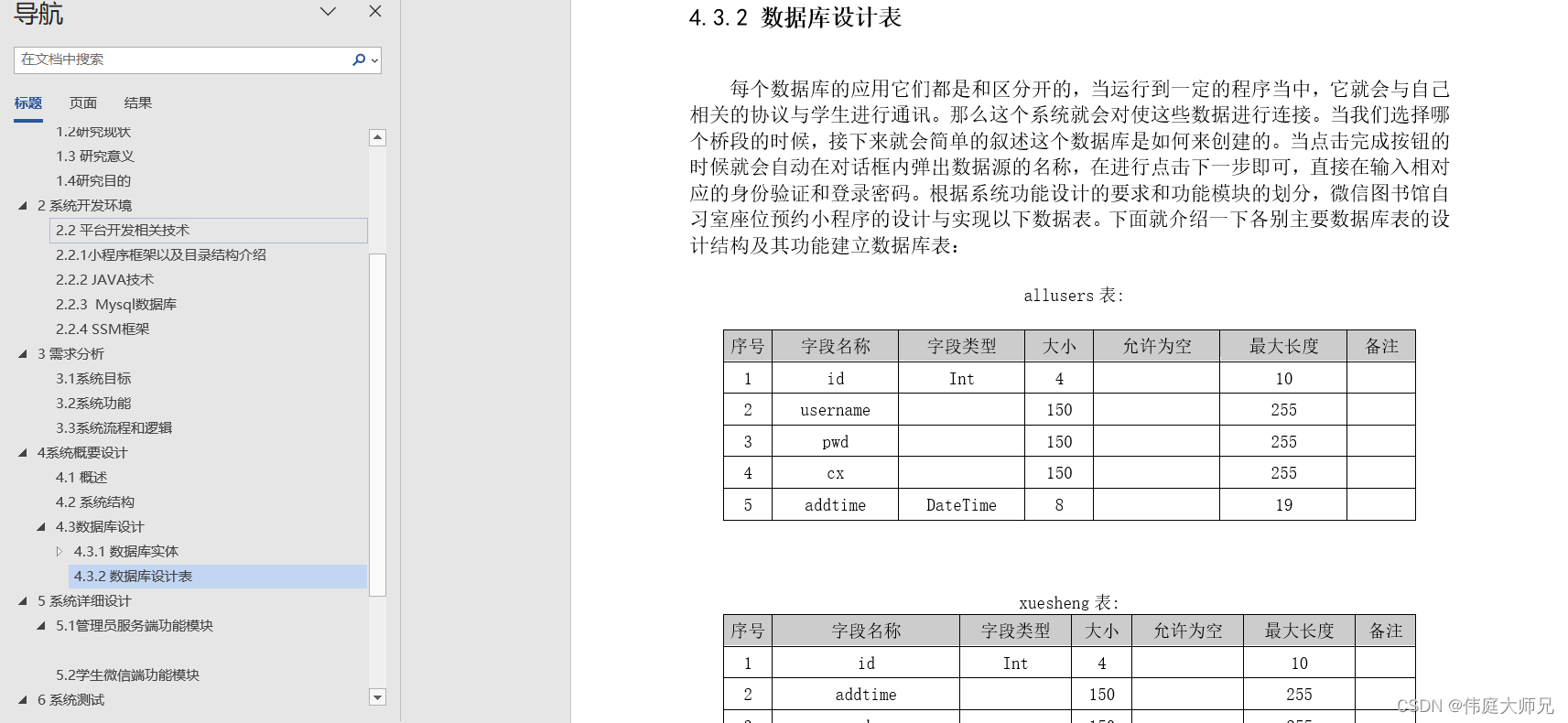
座位预约|座位预约小程序|基于微信小程序的图书馆自习室座位预约管理系统设计与实现(源码+数据库+文档)
座位预约小程序目录 目录 基于微信小程序的图书馆自习室座位预约管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员服务端功能模块 2、学生微信端功能模块 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 …...
03 Redis之命令(基本命令+Key命令+String型Value命令与应用场景)
Redis 根据命令所操作对象的不同,可以分为三大类:对 Redis 进行基础性操作的命令,对 Key 的操作命令,对 Value 的操作命令。 3.1 Redis 基本命令 一些可选项对大小写敏感, 所以应尽量将redis的所有命令大写输入 首先通过 redis-…...
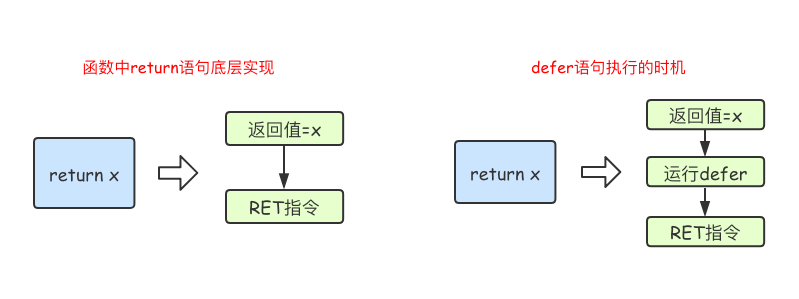
go语言函数进阶
1.变量作用域 全局变量 全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效。 在函数中可以访问到全局变量。 package mainimport "fmt"//定义全局变量num var num int64 10func testGlobalVar() {fmt.Printf("num%d\n", num) /…...

Python编程技巧 – 函数参数
Python编程技巧 – 函数参数 Python Programming Skills - Functional Parameters 1. 函数的定义 函数有简明扼要的定义。 函数是一个代码块,仅在调用时运行。可以将数据(称为参数)传递到函数中。函数可以返回数据作为结果。 2. 函数的结…...
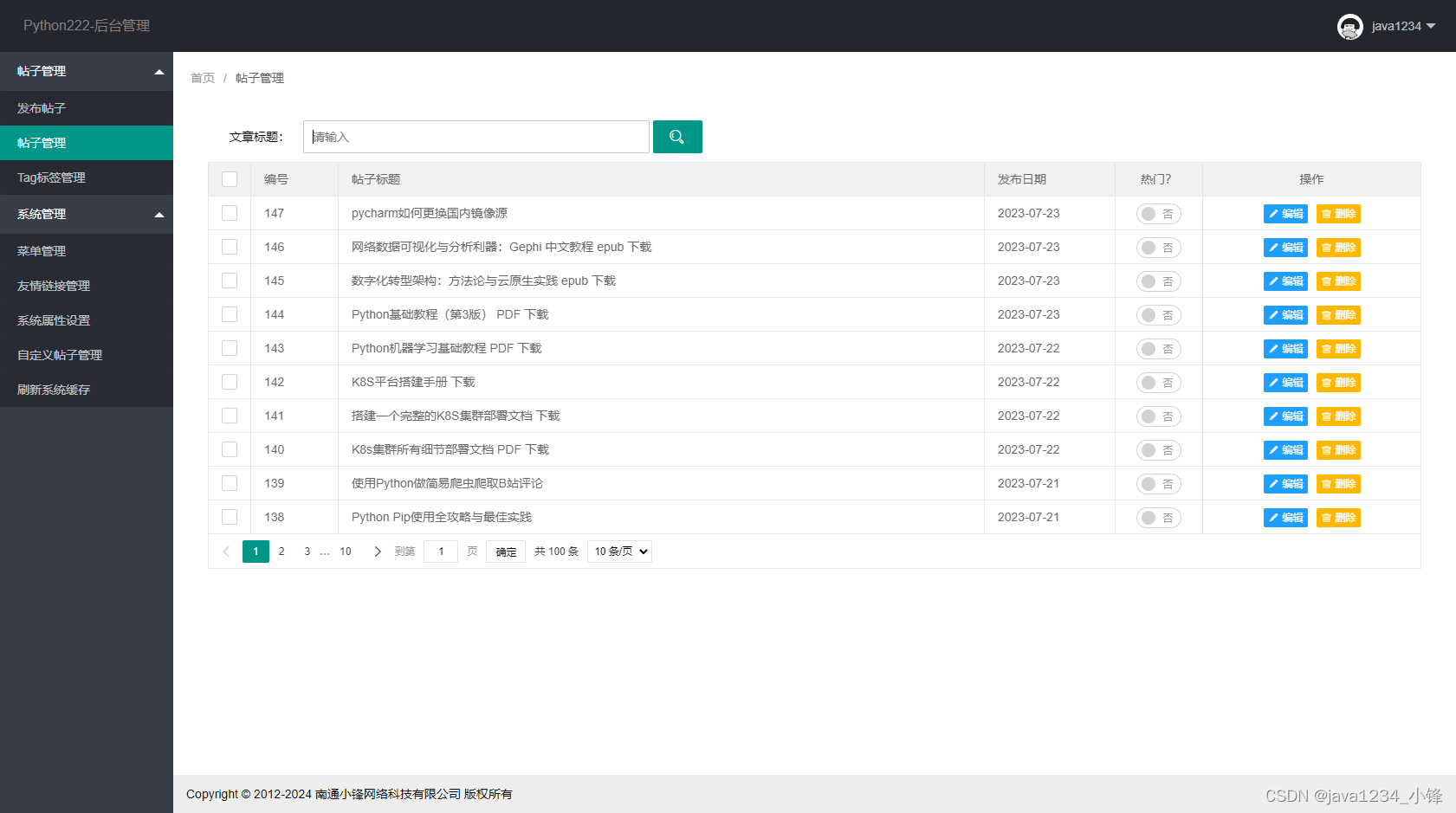
python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-帖子管理实现
锋哥原创的SpringbootLayui python222网站实战: python222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火爆连载更新中... )_哔哩哔哩_bilibilipython222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火…...
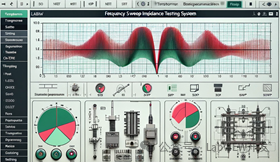
LabVIEW扫频阻抗测试系统
实现扫频阻抗法用于检测变压器绕组变形,结合了短路阻抗法和频响法的优点,但受限于硬件精度,尤其是50 Hz短路阻抗测试存在稳定性和准确性的问题。通过LabVIEW编程,控制宽频带信号发生器和高速采集卡,提高测试结果的稳定…...

C语言——指针进阶(四)
目录 一.前言 二.指针和数组笔试题解析 2.1 二维数组 2.2 指针笔试题 三.全部代码 四.结语 一.前言 本文我们将迎来指针的结尾,包含了二维数组与指针的试题解析。码字不易,希望大家多多支持我呀!(三连+关注&…...
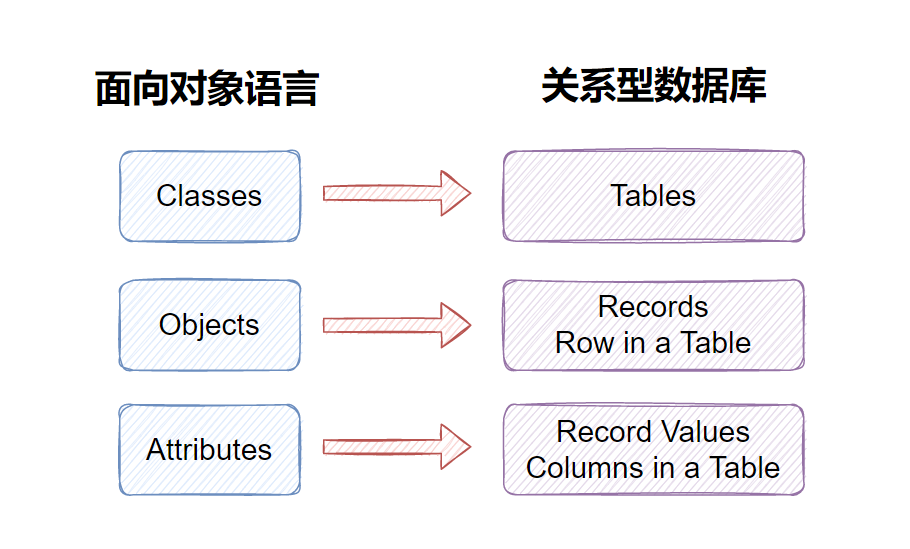
Django介绍
一、介绍 Django是Python语言中的一个Web框架,Python语言中主流的web框架有Django、Tornado、Flask 等多种 优势:大而全,框架本身集成了ORM、模型绑定、模板引擎、缓存、Session等功能,是一个全能型框架,拥有自己的A…...

【idea】几个不错的idea插件让我码速又快了
目录 前言 Gradianto插件 jclasslib Bytecode viewer插件 Grep Console 插件 GenerateAllSetter 插件 GsonFormat 插件 JRebel and XRebel 插件 leetcode editor 插件 maven helper 插件 SequenceDiagram 插件 Statistic 插件 Translation 插件 前言 idea可以说是j…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南
如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专业的Windows桌…...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...
)
Windows11上VMware Workstation 16.1.1保姆级安装与Win11虚拟机配置全流程(含激活与优化)
Windows 11 虚拟化开发环境搭建全指南:从 VMware 安装到系统优化虚拟化技术已经成为现代开发者和运维人员的必备技能。想象一下,你正在开发一个需要跨平台测试的应用程序,或者需要在不影响主系统的情况下尝试新软件——这时候一个可靠的虚拟化…...

抖音内容自动化采集与管理的技术实现方案
抖音内容自动化采集与管理的技术实现方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载工具&am…...

魔兽争霸III终极兼容性解决方案:WarcraftHelper完整使用指南
魔兽争霸III终极兼容性解决方案:WarcraftHelper完整使用指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在现代电脑…...

集团型企业的知识产权管理:多主体架构与数据隔离
对于拥有多家子公司、分公司或关联企业的集团型公司而言,知识产权管理面临一个特有的挑战:如何在集团层面统一管理所有主体的专利商标资产,同时确保各子公司之间的数据相互独立、不被交叉访问?这一问题在传统Excel管理模式或单公司…...