【Spark系列6】如何做SQL查询优化和执行计划分析
Apache Spark SQL 使用 Catalyst 优化器来生成逻辑执行计划和物理执行计划。逻辑执行计划描述了逻辑上如何执行查询,而物理执行计划则是 Spark 实际执行的步骤。
一、查询优化
示例 1:过滤提前
未优化的查询
val salesData = spark.read.parquet("hdfs://sales_data.parquet")
val result = salesData.groupBy("product_id").agg(sum("amount").alias("total_sales")).filter($"total_sales" > 1000)
优化后的查询
val salesData = spark.read.parquet("hdfs://sales_data.parquet")
val filteredData = salesData.filter($"amount" > 1000)
val result = filteredData.groupBy("product_id").agg(sum("amount").alias("total_sales"))
优化解释:通过在聚合之前应用过滤,减少了聚合操作处理的数据量,从而减少了执行时间和资源消耗。
示例 2:使用广播连接
未优化的查询
val largeTable = spark.read.parquet("hdfs://large_table.parquet")
val smallTable = spark.read.parquet("hdfs://small_table.parquet")
val result = largeTable.join(smallTable, Seq("key"))
优化后的查询
import org.apache.spark.sql.functions.broadcastval largeTable = spark.read.parquet("hdfs://large_table.parquet")
val smallTable = spark.read.parquet("hdfs://small_table.parquet")
val result = largeTable.join(broadcast(smallTable), Seq("key"))
优化解释:如果有一个小表和一个大表需要连接,使用广播连接可以将小表的数据发送到每个节点,减少数据传输和shuffle操作,提高查询效率。
示例 3:避免不必要的Shuffle操作
未优化的查询
val transactions = spark.read.parquet("hdfs://transactions.parquet")
val result = transactions.repartition(100, $"country").groupBy("country").agg(sum("amount").alias("total_amount"))
优化后的查询
val transactions = spark.read.parquet("hdfs://transactions.parquet")
val result = transactions.groupBy("country").agg(sum("amount").alias("total_amount"))
优化解释:repartition会导致全局shuffle,而如果后续的操作是按照同一个键进行聚合,这个操作可能是不必要的,因为groupBy操作本身会引入shuffle。
示例 4:处理数据倾斜
未优化的查询
val skewedData = spark.read.parquet("hdfs://skewed_data.parquet")
val referenceData = spark.read.parquet("hdfs://reference_data.parquet")
val result = skewedData.join(referenceData, "key")
优化后的查询
val skewedData = spark.read.parquet("hdfs://skewed_data.parquet")
val referenceData = spark.read.parquet("hdfs://reference_data.parquet")
val saltedSkewedData = skewedData.withColumn("salted_key", concat($"key", lit("_"), (rand() * 10).cast("int")))
val saltedReferenceData = referenceData.withColumn("salted_key", explode(array((0 to 9).map(lit(_)): _*))).withColumn("salted_key", concat($"key", lit("_"), $"salted_key"))
val result = saltedSkewedData.join(saltedReferenceData, "salted_key").drop("salted_key")
优化解释:当存在数据倾斜时,可以通过给键添加随机后缀(称为salting)来分散倾斜的键,然后在连接后去除这个后缀。
示例 5:缓存重用的DataFrame
未优化的查询
val dataset = spark.read.parquet("hdfs://dataset.parquet")
val result1 = dataset.filter($"date" === "2024-01-01").agg(sum("amount"))
val result2 = dataset.filter($"date" === "2024-01-02").agg(sum("amount"))
优化后的查询
val dataset = spark.read.parquet("hdfs://dataset.parquet").cache()
val result1 = dataset.filter($"date" === "2024-01-01").agg(sum("amount"))
val result2 = dataset.filter($"date" === "2024-01-02").agg(sum("amount"))
优化解释:如果同一个数据集被多次读取,可以使用cache()或persist()方法将数据集缓存起来,避免重复的读取和计算。
在实际应用中,优化Spark SQL查询通常需要结合数据的具体情况和资源的可用性。通过观察Spark UI上的执行计划和各个stage的详情,可以进一步诊断和优化查询性能。
二、执行计划分析
逻辑执行计划
逻辑执行计划是对 SQL 查询语句的逻辑解释,它描述了执行查询所需执行的操作,但不涉及具体如何在集群上执行这些操作。逻辑执行计划有两个版本:未解析的逻辑计划(unresolved logical plan)和解析的逻辑计划(resolved logical plan)。
举例说明
假设我们有一个简单的查询:
SELECT name, age FROM people WHERE age > 20
在 Spark SQL 中,这个查询的逻辑执行计划可能如下所示:
== Analyzed Logical Plan ==
name: string, age: int
Filter (age#0 > 20)
+- Project [name#1, age#0]+- Relation[age#0,name#1] parquet
这个逻辑计划的组成部分包括:
Relation: 表示数据来源,这里是一个 Parquet 文件。Project: 表示选择的字段,这里是name和age。Filter: 表示过滤条件,这里是age > 20。
物理执行计划
物理执行计划是 Spark 根据逻辑执行计划生成的,它包含了如何在集群上执行这些操作的具体细节。物理执行计划会考虑数据的分区、缓存、硬件资源等因素。
举例说明
对于上面的逻辑执行计划,Spark Catalyst 优化器可能生成以下物理执行计划:
== Physical Plan ==
*(1) Project [name#1, age#0]
+- *(1) Filter (age#0 > 20)+- *(1) ColumnarToRow+- FileScan parquet [age#0,name#1] Batched: true, DataFilters: [(age#0 > 20)], Format: Parquet, Location: InMemoryFileIndex[file:/path/to/people.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(age), GreaterThan(age,20)], ReadSchema: struct<age:int,name:string>
这个物理执行计划的组成部分包括:
FileScan: 表示数据的读取操作,这里是从 Parquet 文件读取。ColumnarToRow: 表示数据格式的转换,因为 Parquet 是列式存储,需要转换为行式以供后续操作。Filter: 表示过滤操作,这里是执行age > 20的过滤条件。Project: 表示字段选择操作,这里是选择name和age字段。
物理执行计划还包含了一些优化信息,例如:
Batched: 表示是否批量处理数据,这里是true。DataFilters: 实际应用于数据的过滤器。PushedFilters: 表示已推送到数据源的过滤器,这可以减少从数据源读取的数据量。
要查看 Spark SQL 查询的逻辑和物理执行计划,可以在 Spark 代码中使用.explain(true)方法:
val df = spark.sql("SELECT name, age FROM people WHERE age > 20")
df.explain(true)
这将输出上述的逻辑和物理执行计划信息,帮助开发者理解和优化查询。
相关文章:

【Spark系列6】如何做SQL查询优化和执行计划分析
Apache Spark SQL 使用 Catalyst 优化器来生成逻辑执行计划和物理执行计划。逻辑执行计划描述了逻辑上如何执行查询,而物理执行计划则是 Spark 实际执行的步骤。 一、查询优化 示例 1:过滤提前 未优化的查询 val salesData spark.read.parquet(&quo…...

Observability:在 Elastic Stack 8.12 中使用 Elastic Agent 性能预设
作者:来自 Elastic Nima Rezainia, Bill Easton 8.12 中 Elastic Agent 性能有了重大改进 最新版本 8.12 标志着 Elastic Agent 和 Beats 调整方面的重大转变。 在此更新中,Elastic 引入了 Performance Presets,旨在简化用户的调整过程并增强…...
空间数据分析和空间统计工具库PySAL入门
空间数据分析是指利用地理信息系统(GIS)技术和空间统计学等方法,对空间数据进行处理、分析和可视化,以揭示数据之间的空间关系和趋势性,为决策者提供有效的空间决策支持。空间数据分析已经被广泛运用在城市规划、交通管理、环境保护、农业种植…...
LabVIEW电液伺服控制系统
介绍了如何利用ARM微处理器和LabVIEW软件开发一个高效、精准的电液伺服控制系统。通过结合这两种技术,我们能够提高系统的数字化程度、集成化水平,以及控制精度,从而应对传统电液伺服控制器面临的问题。 该电液伺服控制系统由多个关键部分组…...

Dubbo_入门
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 Dubbo_入门 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、什么是分布式系统二、什么…...
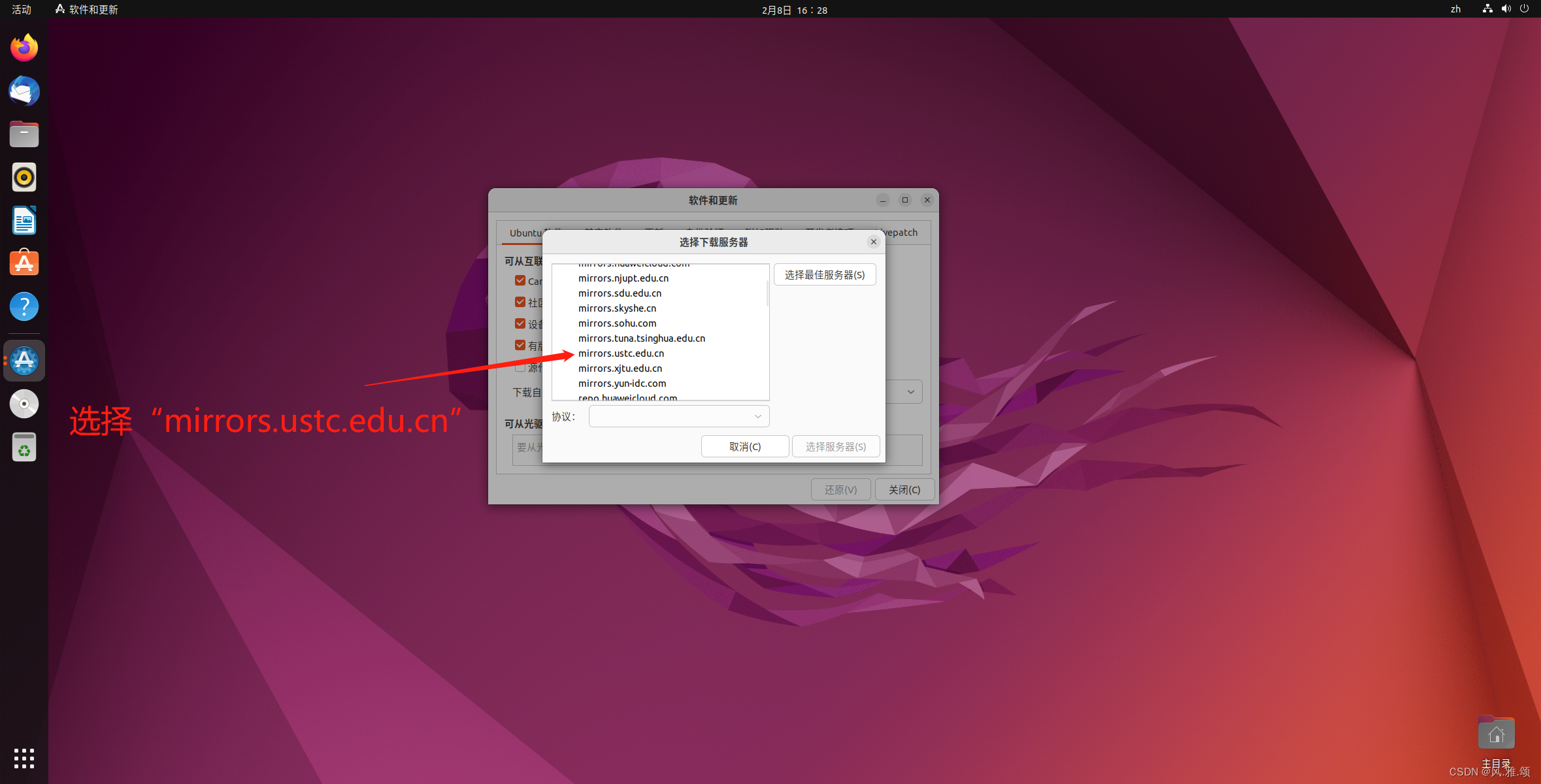
Ubuntu22.04更换软件源
本文以Ubuntu22.04更换科大源为例演示更改软件源的方法,其他版本的Ubuntu系统或更换其他软件源,如清华源,阿里源等,方法类似。 前言 中国科学技术大学开源软件镜像由中国科学技术大学网络信息中心提供支持。 mirrors.ustc.edu.…...

解密Android某信聊天记录
前置条件 frida, frida-tools, adb 获取密码 h.js console.log(script loaded successfully);function xx() {function strf(str, replacements) {return str.replace(/\$\{\w\}/g, function(placeholderWithDelimiters) {var placeholderWithoutDelimiters placeholderWi…...

海外云手机对于亚马逊卖家的作用
近年来,海外云手机作为一种新型模式迅速崭露头角,成为专业的出海SaaS平台软件。海外云手机在云端运行和存储数据,通过网页端操作,将手机芯片放置在机房,通过网络连接到服务器,为用户提供便捷的上网功能。因…...

交换机的发展历史
交换机发展历史是什么,详细介绍每代交换机的性能特点,特色功能 交换机的发展历史可以大致分为以下几个阶段,每个阶段的设备性能特点和特色功能有所差异: 1. 第一代以太网交换机(1980年代末至1990年代初) …...

用katalon解决接口/自动化测试拦路虎--参数化
不管是做接口测试还是做自动化测试,参数化肯定是一个绕不过去的坎。 因为我们要考虑到多个接口都使用相同参数的问题。所以,本文将讲述一下katalon是如何进行参数化的。 全局变量 右侧菜单栏中打开profile,点击default,打开之后…...
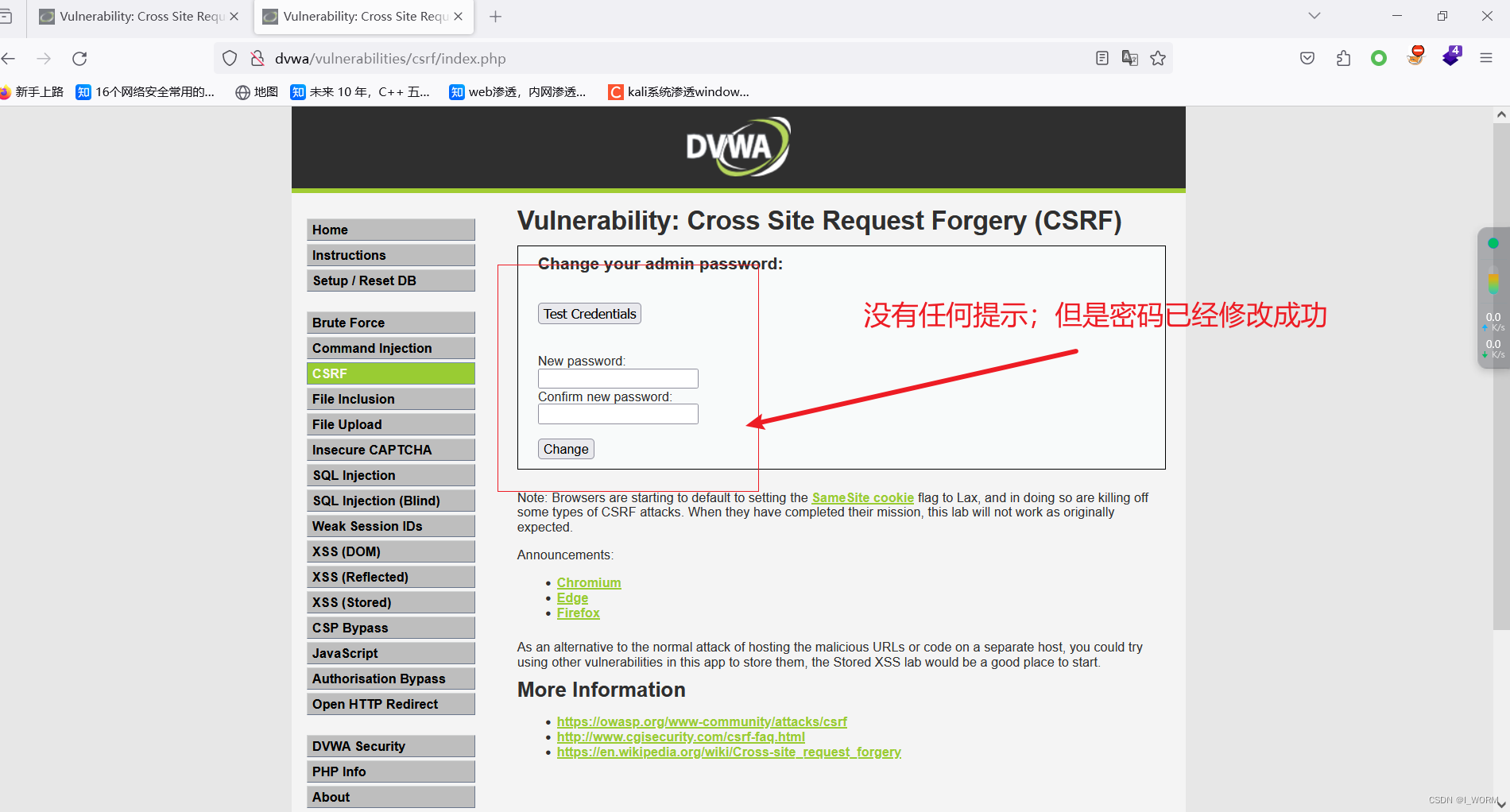
CSRF靶场练习
简述:CSRF漏洞实际很少;条件限制很多;局限性很大;实验仅供参考,熟悉csrf概念和攻击原理即可 Pikachu靶场 CSRF GET 登录用户vince的账户可以看到用户的相关信息; 点击修改个人信息,发现数据包…...

pgsql的查询语句有没有走索引
使用EXPLAIN ANALYZE命令: EXPLAIN ANALYZE [ ( option [, ...] ) ]statement示例: EXPLAIN ANALYZE SELECT * FROM employees WHERE age > 30;在执行计划中,如果看到索引扫描(Index Scan)或位图堆扫描࿰…...
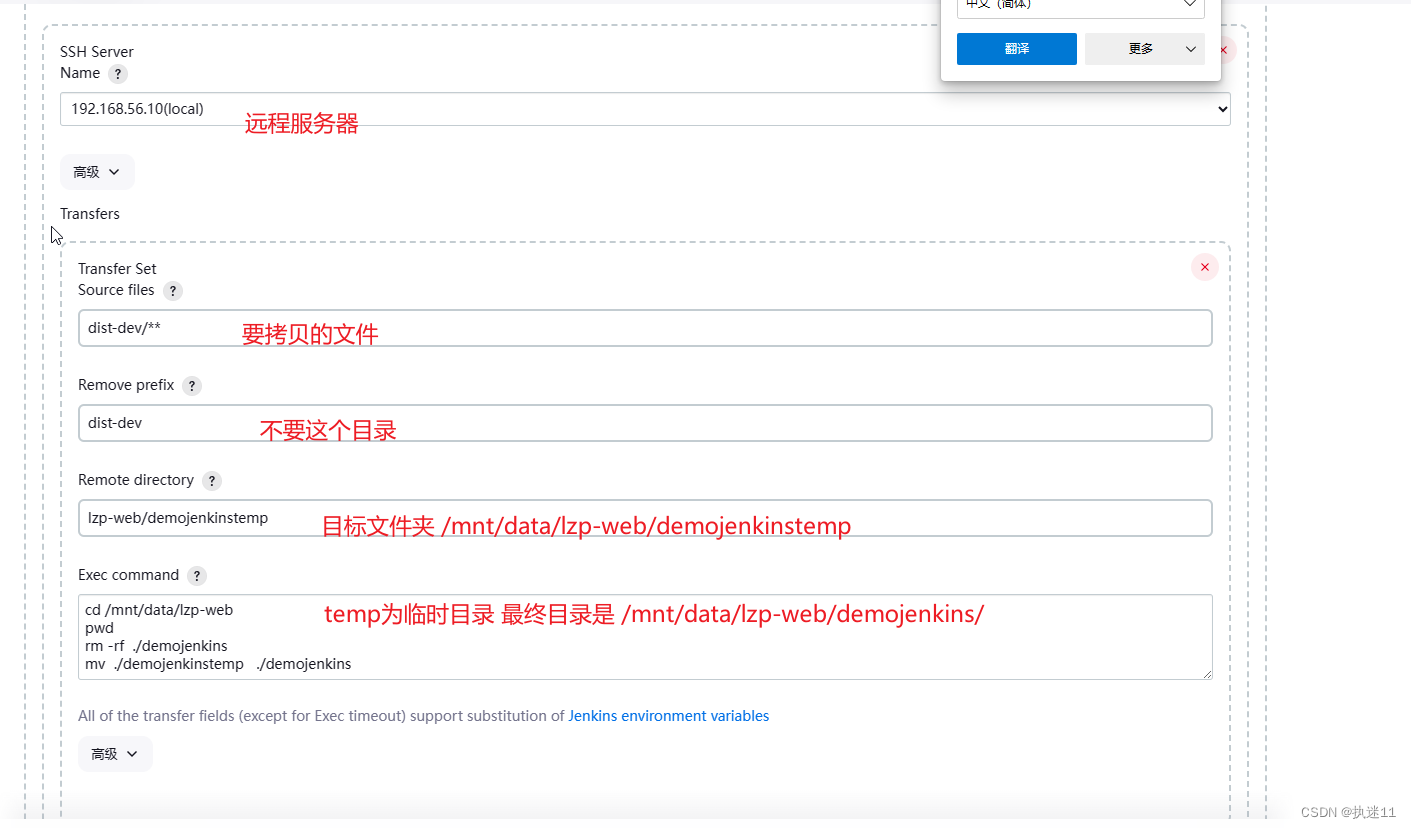
jenkins部署(docker)
docker部署,避免安装tomcat 1.拉镜像 docker pull jenkins/jenkins2.宿主机创建文件夹 mkdir -p /lzp/jenkins_home chmod 777 /lzp/jenkins_home/3.启动容器 docker run -d -p 49001:8080 -p 49000:50000 --privilegedtrue -v /lzp/jenkins_home:/var/jenkins_…...
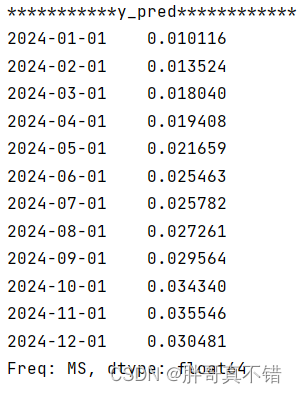
Python实现时间序列分析AR定阶自回归模型(ar_select_order算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 时间序列分析中,AR定阶自回归模型(AR order selection)是指确定自回…...
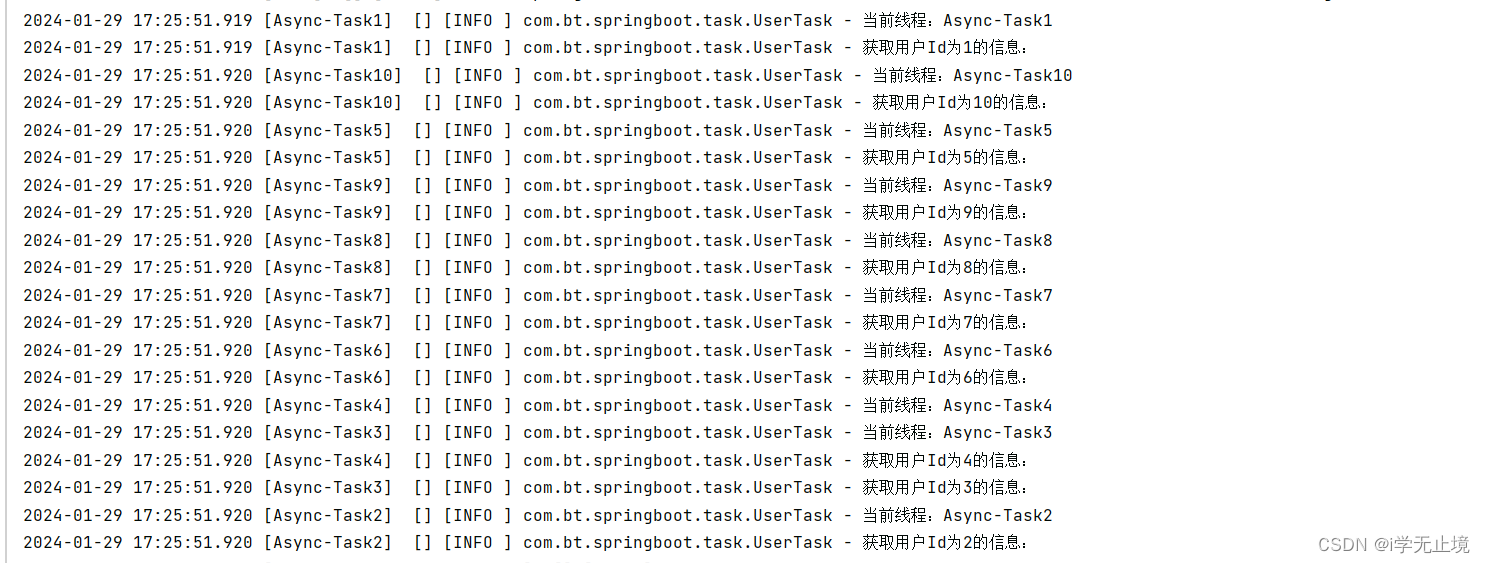
Springboot自定义线程池实现多线程任务
1. 在启动类添加EnableAsync注解 2.自定义线程池 package com.bt.springboot.config;import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.concurrent.ThreadPoolTask…...
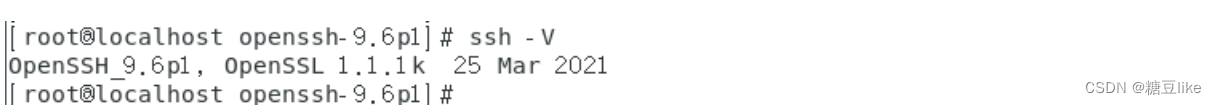
linux离线升级openssh方法
检查openssh版本: 升级前openssh 版本为7.4 openssl 版本为1.0.2k Openssh9.6 所需openssl >1.1.1 因此openssl也需要升级。 为了防止升级失败,无法使用SSH登录,首先安装telnet 预防。查看是否安装了telnet 客户端及服务 未安装tel…...

(五)MySQL的备份及恢复
1、MySQL日志管理 在数据库保存数据时,有时候不可避免会出现数据丢失或者被破坏,这样情况下,我们必须保证数据的安全性和完整性,就需要使用日志来查看或者恢复数据了 数据库中数据丢失或被破坏可能原因: 误删除数据…...

VitePress-04-文档中的表情符号的使用
说明 vitepress 的文档中是支持使用表情符号的,像 😂 等常用的表情都是支持的。 本文就来介绍它的使用方式。 使用语法 语法 : :表情名称: 例如 : :joy: 😂 使用案例代码 # 体会【表情】的基本使用 > hello world …...
Redisson组件)
Redis客户端之Redisson(二)Redisson组件
Redisson的几个常用客户端 一、RedissonClient 1、创建 通过Config对象配置RedissonClient所需要的参数,然后获取RedissonClient对象即可。 Config config new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); RedissonC…...
用Visual Studio Code创建JavaScript运行环境【2024版】
用Visual Studio Code创建JavaScript运行环境 JavaScript 的历史 JavaScript 最初被称为 LiveScript,由 Netscape(Netscape Communications Corporation,网景通信公司)公司的布兰登艾奇(Brendan Eich)在 …...
)
DeepSeek熔断决策延迟超23ms?,基于eBPF实时观测的熔断器内核态性能瓶颈诊断指南(限内部技术圈流通)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek熔断降级方案 DeepSeek大模型服务在高并发、低质量请求或底层依赖异常时,需具备快速响应的熔断与降级能力,以保障系统整体可用性与资源稳定性。该方案基于响应延迟、错误…...

开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南
开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南 【免费下载链接】tuxguitar Open source guitar tablature editor 项目地址: https://gitcode.com/gh_mirrors/tu/tuxguitar 想要免费创作专业的吉他乐谱吗?TuxGuitar这款开源吉他谱编辑…...
)
UE5.1实战:用MySQL插件做个游戏内数据查询器(附完整蓝图)
UE5.1实战:构建高性能游戏内MySQL数据查询系统在虚幻引擎5.1中集成数据库功能已经成为现代游戏开发的重要需求。无论是玩家排行榜、道具管理系统还是实时数据分析,直接访问数据库都能显著提升开发效率和游戏体验。本文将带你从零开始构建一个完整的游戏内…...

BetterJoy:三步搞定Windows玩转任天堂Switch控制器的终极方案
BetterJoy:三步搞定Windows玩转任天堂Switch控制器的终极方案 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitco…...

Wand-Enhancer:三步解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:三步解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高额订阅费用…...
)
告别虚拟机!在WSL2上直接运行Unity打包的Linux游戏(Ubuntu 22.04实测)
在WSL2中高效运行Unity Linux游戏的完整指南对于独立游戏开发者和中小团队来说,频繁的跨平台测试往往意味着在虚拟机中反复折腾。每次修改代码后,都需要经历漫长的虚拟机启动、文件传输和依赖配置过程。这种开发体验不仅低效,还会严重打断创作…...

跨VM RowHammer攻击防御技术与DRAM安全研究
1. 跨VM RowHammer攻击与防御技术概述在云计算环境中,虚拟机(VM)之间的安全隔离是保障多租户数据安全的核心机制。然而,RowHammer攻击的出现对这一基础安全假设提出了严峻挑战。RowHammer是一种利用DRAM物理特性的硬件漏洞攻击方式,攻击者通过…...
)
Unity异步编程新选择:用R3和NuGetForUnity搞定响应式事件流(附AOT兼容性测试)
Unity异步编程新选择:R3与NuGetForUnity的深度实践指南引言:为什么我们需要更好的事件处理方案?在Unity开发中,事件驱动编程早已成为构建复杂交互系统的核心范式。从传统的UnityEvent到协程(Coroutine),再到曾经风靡一…...

基于图神经网络的机器学习有限区域模型:边界处理与图结构设计实战
1. 项目概述与核心挑战最近几年,机器学习天气预测(MLWP)的进展让人有点兴奋,又有点眼花缭乱。从全球尺度的大模型到区域性的精细化预报,数据驱动的方法正在重新定义我们对大气模拟的理解。作为一名长期混迹在气象和计算…...
)
UE5 RPG开发实战:用MVC架构重构你的UI系统(GAS项目避坑指南)
UE5 RPG开发实战:用MVC架构重构UI系统的工程化实践当你的UE5 RPG项目从原型阶段进入正式开发,UI系统往往会成为第一个显露出架构问题的模块。属性面板、技能栏、BUFF指示器等数十个UI组件相互纠缠,每次新增功能都像在走钢丝——这就是我们引入…...