RabbitMQ之三种队列之间的区别及如何选型
目录
不同队列之间的区别
Classic经典队列
Quorum仲裁队列
Stream流式队列
如何使用不同类型的队列
Quorum队列
Stream队列
不同队列之间的区别
Classic经典队列
这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。

经典队列可以选择是否持久化(Durability)以及是否自动删除(Auto delete)两个属性。其中,Durability有两个选项,Durable和Transient。 Durable表示队列会将消息保存到硬盘,这样消息的安全性更高。但是同时,由于需要有更多的IO操作,所以生产和消费消息的性能,相比Transient会比较低。 Auto delete属性如果选择为是,那队列将在至少一个消费者已经连接,然后所有的消费者都断开连接后删除自己。Arguments部分,还有非常多的参数,可以点击后面的问号逐步了解。
在RabbitMQ中,经典队列是一种非常传统的队列结构。消息以FIFO先进先出的方式存入队列。消息被Consumer从队列中取出后就会从队列中删除。如果消息需要重新投递,就需要再次入队。这种队列都依靠各个Broker自己进行管理,在分布式场景下,管理效率是不太高的。并且这种经典队列不适合积累太多的消息。如果队列中积累的消息太多了,会严重影响客户端生产消息以及消费消息的性能。因此,经典队列主要用在数据量比较小,并且生产消息和消费消息的速度比较稳定的业务场景。比如内部系统之间的服务调用。
Quorum仲裁队列
仲裁队列,是RabbitMQ从3.8.0版本,引入的一个新的队列类型,整个3.8.X版本,也都是在围绕仲裁队列进行完善和优化。仲裁队列相比Classic经典队列,在分布式环境下对消息的可靠性保障更高。官方文档中表示,未来会使用Quorum仲裁队列代替传统Classic队列。

Quorum是基于Raft一致性协议实现的一种新型的分布式消息队列,他实现了持久化,多备份的FIFO队列,主要就是针对RabbitMQ的镜像模式设计的。简单理解就是quorum队列中的消息需要有集群中多半节点同意确认后,才会写入到队列中。这种队列类似于RocketMQ当中的DLedger集群。这种方式可以保证消息在集群内部不会丢失。同时,Quorum是以牺牲很多高级队列特性为代价,来进一步保证消息在分布式环境下的高可靠。从整体功能上来说,Quorum队列是在Classic经典队列的基础上做减法,因此对于RabbitMQ的长期使用者而言,其实是会影响使用体验的。
与普通队列的区别:

Quorum队列大部分功能都是在Classic队列基础上做减法,比如Non-durable queues表示是非持久化的内存队列。Exclusivity表示独占队列,即表示队列只能由声明该队列的Connection连接来进行使用,包括队列创建、删除、收发消息等,并且独占队列会在声明该队列的Connection断开后自动删除。
特例Poison Message handling(处理有毒的消息)。所谓毒消息是指消息一直不能被消费者正常消费(可能是由于消费者失败或者消费逻辑有问题等),就会导致消息不断的重新入队,这样这些消息就成为了毒消息。这些读消息应该有保障机制进行标记并及时删除。Quorum队列会持续跟踪消息的失败投递尝试次数,并记录在"x-delivery-count"这样一个头部参数中。然后,就可以通过设置 Delivery limit参数来定制一个毒消息的删除策略。当消息的重复投递次数超过了Delivery limit参数阈值时,RabbitMQ就会删除这些毒消息。当然,如果配置了死信队列的话,就会进入对应的死信队列。
Quorum队列更适合于长期存在的队列,并且在对容错、数据安全方面有更严格要求的场景。相对于追求低延迟、非持久化等高级队列,Quorum队列提供了更可靠的数据复制机制,以满足对数据一致性和高可用性的要求。
不适合使用的场景:
临时使用的队列:
比如transient临时队列,exclusive独占队列,或者经常会修改和删除的队列。
对消息低延迟要求高:
一致性算法会影响消息的延迟。
对数据安全性要求不高:
Quorum队列需要消费者手动通知或者生产者手动确认。
队列消息积压严重 :
如果队列中的消息很大,或者积压的消息很多,就不要使用Quorum队列。Quorum队列当前会将所有消息始终保存在内存中,直到达到内存使用极限。
Stream流式队列
Stream队列是RabbitMQ自3.9.0版本开始引入的一种新的数据队列类型。这种队列类型的消息是持久化到磁盘并且具备分布式备份的,更适合于消费者多,读消息非常频繁的场景。
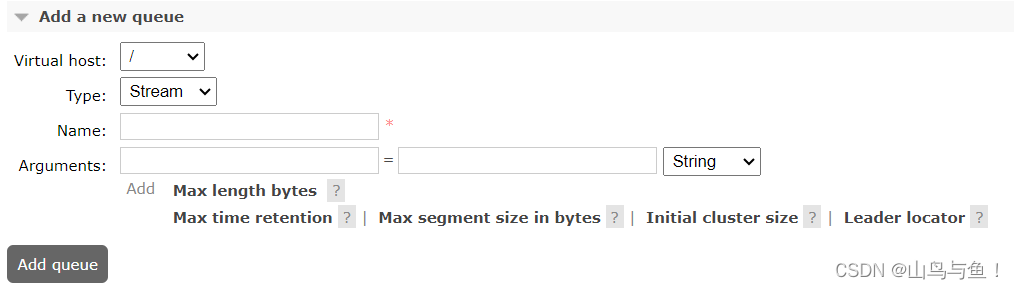
Stream队列的核心是以append-only只添加的日志来记录消息,整体来说,就是消息将以append-only的方式持久化到日志文件中,然后通过调整每个消费者的消费进度offset,来实现消息的多次分发。下方有几个属性也都是来定义日志文件的大小以及保存时间。如果你熟悉Kafka或者RocketMQ,会对这种日志记录消息的方式非常熟悉。这种队列提供了RabbitMQ已有的其他队列类型不太好实现的四个特点:
large fan-outs 大规模分发
当想要向多个订阅者发送相同的消息时,以往的队列类型必须为每个消费者绑定一个专用的队列。如果消费者的数量很大,这就会导致性能低下。而Stream队列允许任意数量的消费者使用同一个队列的消息,从而消除绑定多个队列的需求。
Replay/Time-travelling 消息回溯
RabbitMQ已有的这些队列类型,在消费者处理完消息后,消息都会从队列中删除,因此,无法重新读取已经消费过的消息。而Stream队列允许用户在日志的任何一个连接点开始重新读取数据。
Throughput Performance 高吞吐性能
Strem队列的设计以性能为主要目标,对消息传递吞吐量的提升非常明显。
Large logs 大日志
RabbitMQ一直以来有一个让人诟病的地方,就是当队列中积累的消息过多时,性能下降会非常明显。但是Stream队列的设计目标就是以最小的内存开销高效地存储大量的数据。使用Stream队列可以比较轻松的在队列中积累百万级别的消息。
整体上来说,RabbitMQ的Stream队列,其实有很多地方借鉴了其他MQ产品的优点,在保证消息可靠性的基础上,着力提高队列的消息吞吐量以及消息转发性能。因此,Stream也是在视图解决一个RabbitMQ一直以来,让人诟病的缺点,就是当队列中积累的消息过多时,性能下降会非常明显的问题。RabbitMQ以往更专注于企业级的内部使用,但是从这些队列功能可以看到,Rabbitmq也在向更复杂的互联网环境靠拢,未来对于RabbitMQ的了解,也需要随着版本推进,不断更新。
如何使用不同类型的队列
这几种不同类型的队列,虽然实现方式各有不同,但是本质上都是一种存储消息的数据结构。
Quorum队列
Quorum队列与Classic队列的使用方式是差不多的。最主要的差别就是在声明队列时有点不同。如果要声明一个Quorum队列,则只需要在后面的arguments中传入一个参数,x-queue-type,参数值设定为quorum。
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","quorum");
//声明Quorum队列的方式就是添加一个x-queue-type参数,指定为quorum。默认是classic
channel.queueDeclare(QUEUE_NAME, true, false, false, params);Quorum队列的消息是必须持久化的,所以durable参数必须设定为true,如果声明为false,就会报错。同样,exclusive参数必须设置为false。这些声明,在Producer和Consumer中是要保持一致的。
Stream队列
Stream队列相比于Classic队列,在使用上就要稍微复杂一点。如果要声明一个Stream队列,则 x-queue-type参数要设置为 stream 。
Map<String,Object> params = new HashMap<>();params.put("x-queue-type","stream");params.put("x-max-length-bytes", 20_000_000_000L); // maximum stream size: 20 GBparams.put("x-stream-max-segment-size-bytes", 100_000_000); // size of segment files: 100 MBchannel.queueDeclare(QUEUE_NAME, true, false, false, params);与Quorum队列类似, Stream队列的durable参数必须声明为true,exclusive参数必须声明为false。这其中,x-max-length-bytes 表示日志文件的最大字节数。x-stream-max-segment-size-bytes 每一个日志文件的最大大小。这两个是可选参数,通常为了防止stream日志无限制累计,都会配合stream队列一起声明。
当要消费Stream队列时,要重点注意他的三个必要的步骤:
1. channel必须设置basicQos属性。 与Spring框架集成使用时,channel对象可以在@RabbitListener声明的消费者方法中直接引用,Spring框架会进行注入。
2. 正确声明Stream队列。 在Queue对象中传入声明Stream队列所需要的参数。
3. 消费时需要指定offset。 与Spring框架集成时,可以通过注入Channel对象,使用原生API传入offset属性。
例如用原生API创建Stream类型的Consumer时,还必须添加一个参数x-stream-offset,表示从队列的哪个位置开始消费。
Map<String,Object> consumeParam = new HashMap<>();consumeParam.put("x-stream-offset","last");channel.basicConsume(QUEUE_NAME, false,consumeParam, myconsumer);x-stream-offset的可选值有以下几种:
first: 从日志队列中第一个可消费的消息开始消费
last: 消费消息日志中最后一个消息
next: 相当于不指定offset,消费不到消息。
Offset: 一个数字型的偏移量
Timestamp:一个代表时间的Data类型变量,表示从这个时间点开始消费。例如 一个小时前 Date timestamp = new Date(System.currentTimeMillis() - 60 * 60 * 1_000)
由于在Consumer中必须传入x-stream-offset这个参数,所以在与SpringBoot集成时,stream队列目前暂时无法正常消费。在目前版本下,使用RabbitMQ的SpringBoot框架集成,可以正常声明Stream队列,往Stream队列发送消息,但是无法直接消费Stream队列了。
SpringBoot框架集成RabbitMQ后,为了简化编程模型,就把channel,connection等这些关键对象给隐藏了,目前框架下,无法直接接入这些对象的注入过程,所以无法直接使用。
如果非要使用Stream队列,那么有两种方式,一种是使用原生API的方式,在SpringBoot框架下自行封装。另一种是使用RabbitMQ的Stream 插件。在服务端通过Strem插件打开TCP连接接口,并配合单独提供的Stream客户端使用。这种方式对应用端的影响太重了,并且并没有提供与SpringBoot框架的集成,还需要自行完善,因此Stream队列使用较少。
相关文章:
RabbitMQ之三种队列之间的区别及如何选型
目录 不同队列之间的区别 Classic经典队列 Quorum仲裁队列 Stream流式队列 如何使用不同类型的队列 Quorum队列 Stream队列 不同队列之间的区别 Classic经典队列 这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。 经典队列可以选…...

【ArcGIS微课1000例】0099:土地利用变化分析
本实验讲述在ArcGIS软件中基于两期土地利用数据,做土地利用变化分析。 文章目录 一、实验描述二、实验过程三、注意事项一、实验描述 对城市土地利用情况进行分析时,需要考虑不同时期土地利用图层在空间上的差异性,如农用地转建筑用地的空间变化。而该变化过程表现为各时期…...
学习鸿蒙基础(2)
arkts是声名式UI DevEcoStudio的右侧预览器可以预览。有个TT的图标可以看布局的大小。和html的布局浏览很像。 上图布局对应的代码: Entry //入口 Component struct Index {State message: string Hello Harmonyos //State 数据改变了也刷新的标签build() {Row()…...

2024年美国大学生数学建模竞赛思路与源代码【2024美赛C题】
B站账号,提前关注,会有直播:有为社的个人空间-有为社个人主页-哔哩哔哩视频 (bilibili.com) 题目 待定 问题一 思路 待定 模型 待定 程序 待定 问题二 待定 思路 待定 模型 待定 程序 待定...
Windows11搭建GPU版本PyTorch环境详细过程
Anaconda安装 https://www.anaconda.com/ Anaconda: 中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。从官网下载Setup:点击安装,之后勾选上可以方便在普通命令行cmd和PowerShell中使用…...

Springboot项目基础配置:小白也能快速上手!
推荐文章 给软件行业带来了春天——揭秘Spring究竟是何方神圣(一) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(二) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(三) 给软件行业带来了春天—…...
20240127在ubuntu20.04.6下配置whisper
20240131在ubuntu20.04.6下配置whisper 2024/1/31 15:48 首先你要有一张NVIDIA的显卡,比如我用的PDD拼多多的二手GTX1080显卡。【并且极其可能是矿卡!】800¥ 2、请正确安装好NVIDIA最新的驱动程序和CUDA。可选安装! 3、配置whispe…...

C# 递归执行顺序
为了方便进一步理解递归,写了一个数字输出 class Program {static void Main(string[] args){int number 5;RecursiveDecrease(number);}static void RecursiveDecrease(int n){if (n > 0){Console.WriteLine("Before recursive call do : " n);Rec…...
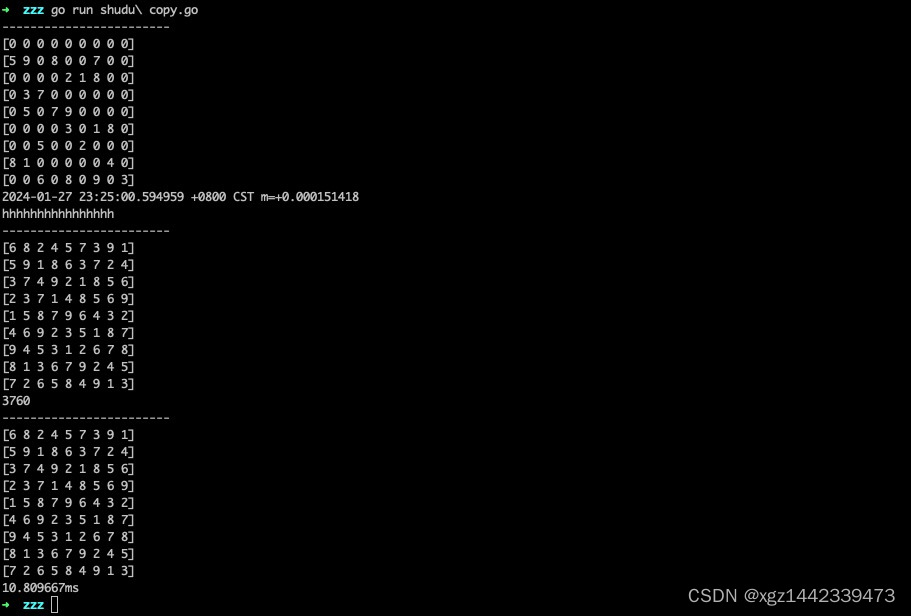
go 实现暴力破解数独
一切罪恶的来源是昨晚睡前玩了一把数独,找虐的选了个最难的模式,做了一个多小时才做完,然后就睡不着了..........程序员不能受这委屈,今天咋样也得把这玩意儿破解了 破解思路(暴力破解加深度遍历) 把数独…...

go语言-字符串处理常用函数
本文介绍go语言处理字符串类型的常见函数。 ## 多行字符串 在 Go 中创建多行字符串非常容易。只需要在你声明或赋值时使用 () 。 str : This is a multiline string. ## 字符串的拼接 go // fmt.Sprintf方式拼接字符串 str1 : "abc" str2 : "def" …...
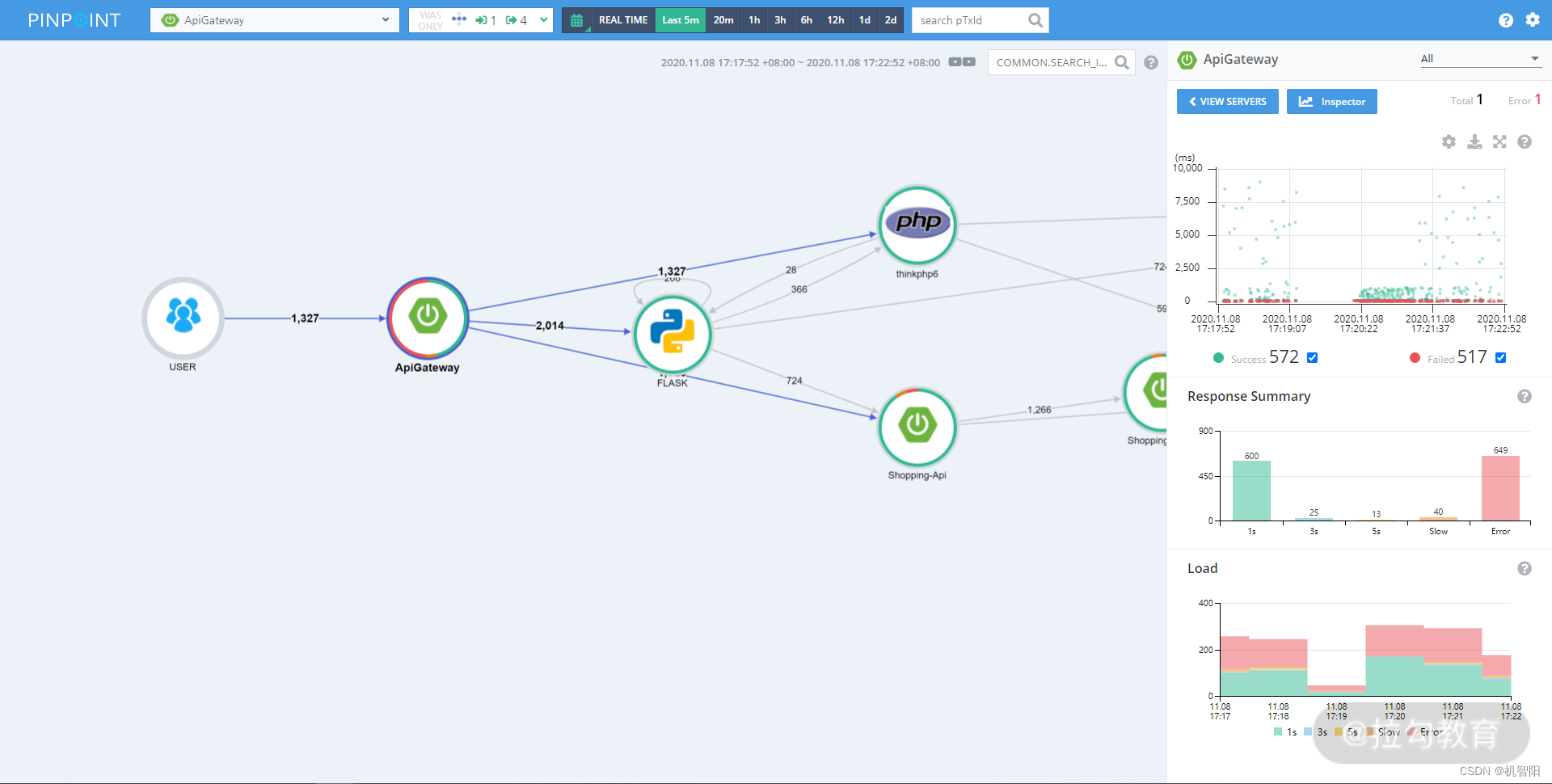
DevOps落地笔记-05|非功能需求:如何有效关注非功能需求
上一讲主要介绍了看板方法以及如何使用看板方法来解决软件研发过程中出现的团队过载、工作不均、任务延期等问题。通过学习前面几个课时介绍的知识,你的团队开始源源不断地交付用户价值。用户对交付的功能非常满意,但等到系统上线后经常出现服务不可用的…...
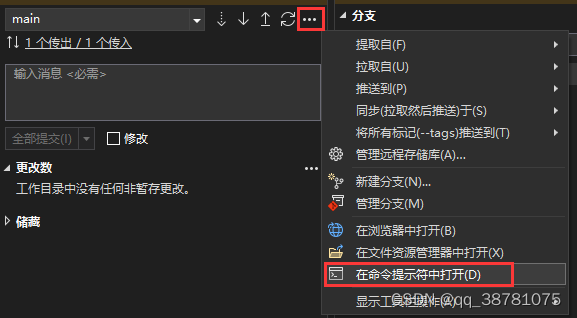
vs 撤销本地 commit 并保留更改
没想到特别好的办法,我想的是用 vs 打开 git 命令行工具 然后通过 git 命令来撤销提交,尝试之前建议先建个分支实验,以免丢失代码, git 操作见 git 合并多个 commit / 修改上一次 commit...

深度解读NVMe计算存储协议-1
随着云计算、企业级应用以及物联网领域的飞速发展,当前的数据处理需求正以前所未有的规模增长,以满足存储行业不断变化的需求。这种增长导致网络带宽压力增大,并对主机计算资源(如内存和CPU)造成极大负担,进…...
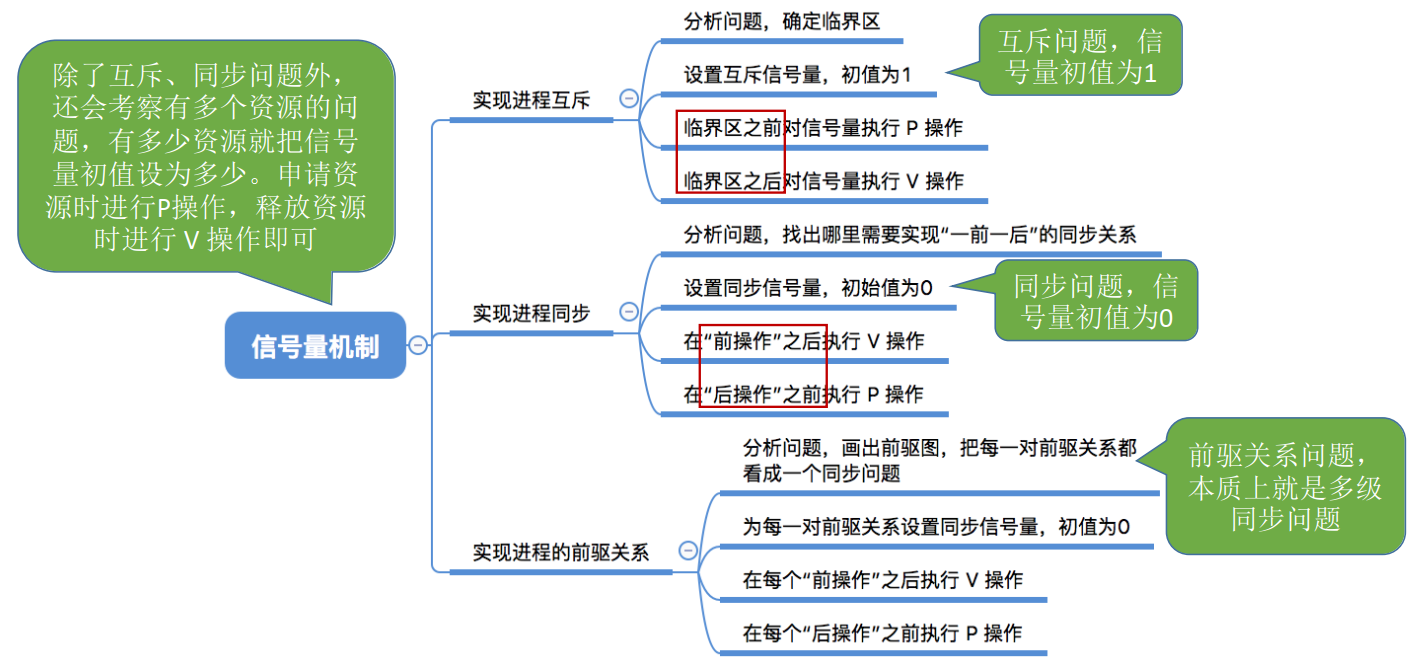
CHS_06.2.3.4_2+用信号量实现进程互斥、同步、前驱关系
CHS_06.2.3.4_2用信号量实现进程互斥、同步、前驱关系 知识总览信号量机制实现进程互斥信号量机制实现进程同步信号量机制实现前驱关系 知识回顾 各位同学 大家好 在这个小节中 我们要学习怎么用信号量机制来实现进程的同步互制关系 知识总览 那么 我们之前学习了互斥的几种软…...
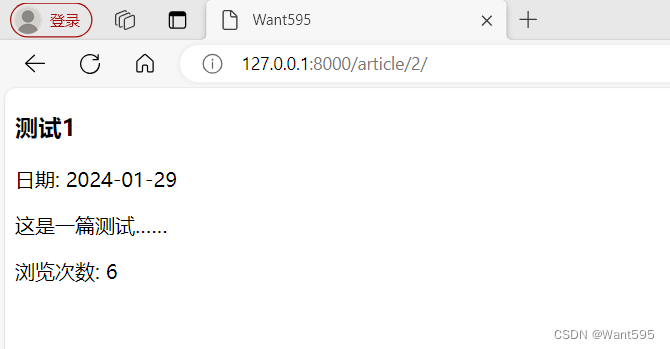
Web实战丨基于Django的简单网页计数器
文章目录 写在前面Django简介主要程序运行结果系列文章写在后面 写在前面 本期内容 基于django的简单网页计数器 所需环境 pythonpycharm或vscodedjango 下载地址 https://download.csdn.net/download/m0_68111267/88795604 Django简介 Django 是一个用 Python 编写的高…...

mysql8安装基础操作(一)
一、下载mysql8.0 1.查看系统glibc版本 这里可以看到glibc版本为2.17,所以下载mysql8.0的版本时候尽量和glibc版本对应 [rootnode2 ~]# rpm -qa |grep -w glibc glibc-2.17-222.el7.x86_64 glibc-devel-2.17-222.el7.x86_64 glibc-common-2.17-222.el7.x86_64 gl…...
MIT6.5830 实验0
前置 本次实验使用 Golang 语言实现,在之前的年份中,都是像 cs186 那样使用 Java 实现。原因: Golang 语言作为现代化语言,简单易上手但功能强大。 使参加实验的同学有同一起跑线,而不是像Java那样,有些同…...
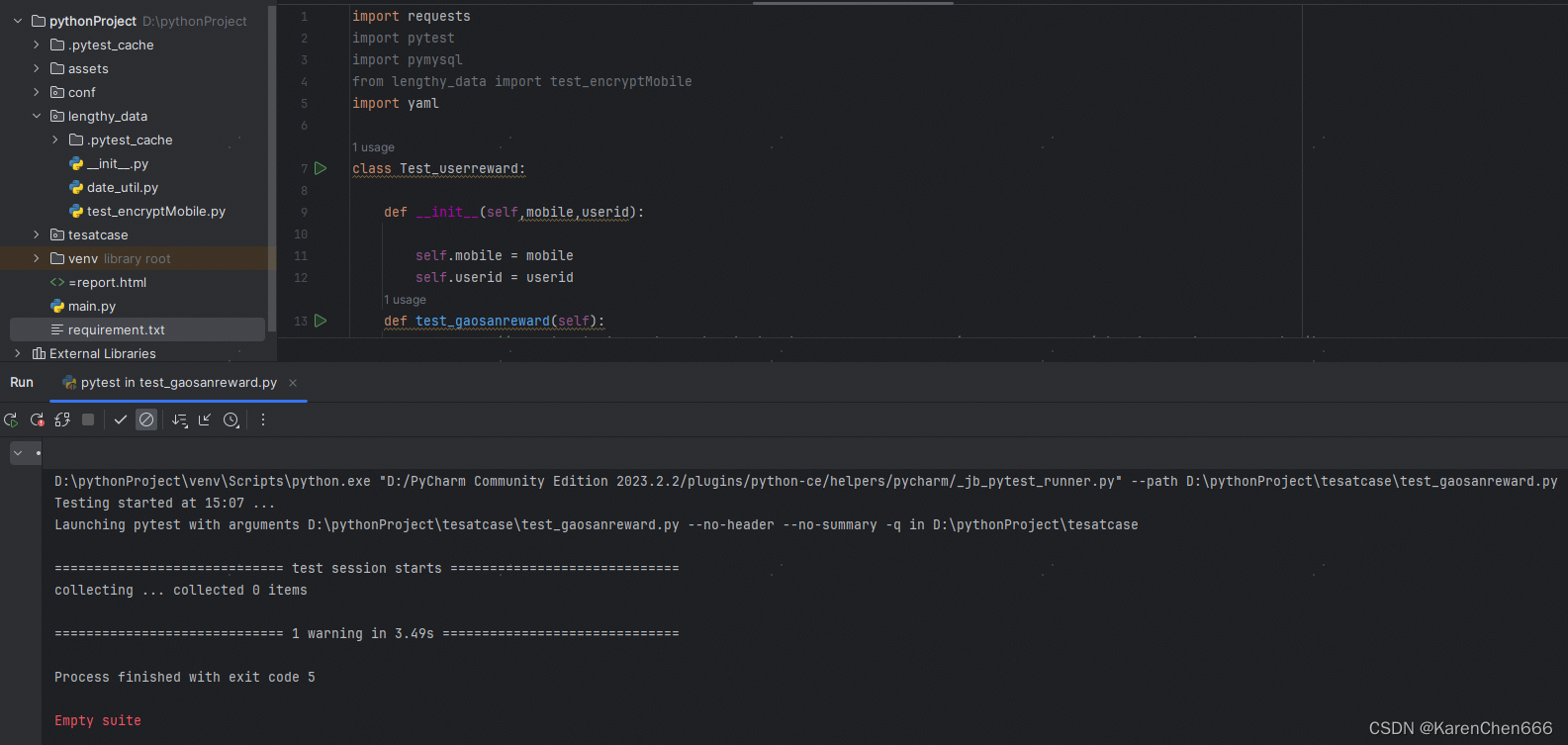
【简便方法和积累】pytest 单元测试框架中便捷安装插件和执行问题
又来进步一点点~~~ 背景:之前写了两篇关于pytest单元测试框架的文章,本篇内容对之前的做一个补充 一、pytest插件: pytest 有非常多的插件,很方便,以下为插件举例: pytest,pytest-html&#x…...
Zabbix数据库分离与邮件报警
基础环境:要有zabbix服务端与被监控端实验目标:源数据库与服务端存放在一台服务器上,分离后源数据库单独在一台服务器上,zabbix服务端上不再有数据库。环境拓扑图: 实验步骤: 1.在8.7服务器上安装相同版本…...

mybatisplus-多数据源配置
1. 流程 pom文件yml配置多数据源具体服务添加注解DS(“***”) 1.pom文件 <!--mybatis plus 起步依赖--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.0</vers…...

英语长期没进步?大多是学习方式错了
很多人英语学了很久却毫无起色,归根结底,都栽在了同一个核心问题上。前阵子整理电脑文件,我翻出了早年的英语学习笔记。厚厚几十页的单词汇总、密密麻麻的语法批注,收藏夹里囤了上百个教学视频,还有曾经热血满满给自己…...

一文看懂 Hermes Agent 的 Prompt Builder:系统提示词到底拼进了什么?
一、先说结论:Prompt Builder 是 Hermes 的“提示词总装车间”普通 Chatbot 的系统提示词往往是一段固定文字,告诉模型“你是谁、怎么回答”。Hermes Agent 的 Prompt Builder 更像一条总装线:它会把身份、记忆、用户画像、项目规则、技能目录…...

FlashAttention 深度解读:让大模型注意力机制“一口气算完“
FlashAttention:让大模型注意力机制"一口气算完" 想象你在厨房做菜。冰箱在远处(HBM,高带宽内存),料理台在面前(SRAM,片上缓存)。每次要切菜,都得走过去开冰箱…...

手语识别实战:CNN-LSTM混合架构与轻量化部署指南
1. 项目概述:手语识别不是“翻译”,而是构建一座可触摸的沟通桥梁手语识别这件事,我从2019年第一次在残联康复中心做志愿者时就盯上了。当时一位老师傅用双手比划“苹果”“医院”“谢谢”,而旁边的年轻人盯着手机里刚装的某款APP…...

如何快速配置FanControl风扇控制:从安装到优化的完整指南
如何快速配置FanControl风扇控制:从安装到优化的完整指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

Vue大屏自适应解决方案:如何应对多分辨率设备下的数据可视化挑战
Vue大屏自适应解决方案:如何应对多分辨率设备下的数据可视化挑战 【免费下载链接】v-scale-screen Vue large screen adaptive component vue大屏自适应组件 项目地址: https://gitcode.com/gh_mirrors/vs/v-scale-screen 在数字化转型浪潮中,企业…...

2026 年 AI 毕业论文工具横评:okbiye 领衔,9 款工具实测对比,帮你避开 90% 的写作坑
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、前言:AI 写论文,别只盯着 “一键生成” 毕业论文写作,是每个大学生都绕不开的关卡。从选题定方向、…...

Office Custom UI Editor终极指南:30秒打造专属Office工作界面
Office Custom UI Editor终极指南:30秒打造专属Office工作界面 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/of/office-custom-ui-editor …...

BGA翻新安全的核心风险—热损伤与机械失效底层逻辑
BGA(球栅阵列)芯片翻新是电子制造业降本增效、资源循环的重要工艺,广泛应用于服务器 CPU、手机基带芯片、车载处理器等高价值元器件修复场景。但 BGA 封装结构精密,焊点隐藏在芯片底部,翻新过程需经历多次高温加热、机…...

终极自动化指南:如何用AALC解放你的Limbus Company游戏时间
终极自动化指南:如何用AALC解放你的Limbus Company游戏时间 【免费下载链接】AhabAssistantLimbusCompany AALC,PC端Limbus Company小助手。AALC,Limbus Company Assistant on PC 项目地址: https://gitcode.com/gh_mirrors/ah/AhabAssista…...