《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树
文章目录
- 第5章 决策树
- 5.1 决策树模型与学习
- 5.1.1 决策树模型
- 5.1.2 决策树与if-then规则
- 5.1.3 决策树与条件概率分布
- 5.1.4 决策树学习
- 5.2 特征选择
- 5.2.1 特征选择问题
- 5.2.2 信息增益
- 5.2.3 信息增益比
- 5.3.1 ID3算法
- 5.3.2 C4.5的生成算法
- 5.4 决策树的剪枝
- 5.5 CART算法
- 5.5.1 CART生成
- 5.5.2 CART剪枝
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第1章 统计学习方法概论
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第 2章感知机
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第4章 朴素贝叶斯法
我算是有点基础的(有过深度学习和机器学的项目经验),但也是半路出家,无论是学Python还是深度学习,都是从问题出发,边查边做,没有系统的学过相关的知识,这样的好处是入门快(如果想快速入门,大家也可以试试,直接上手项目,从小项目开始),但也存在一个严重的问题就是,很多东西一知半解,容易走进死胡同出不来(感觉有点像陷入局部最优解,找不到出路),所以打算系统的学习几本口碑比较不错的书籍。
书籍选择: 当然,机器学习相关的书籍有很多,很多英文版的神书,据说读英文版的书会更好,奈何英文不太好,比较难啃。国内也有很多书,周志华老师的“西瓜书”我也有了解过,看了前几章,个人感觉他肯能对初学者更友好一点,讲述的非常清楚,有很多描述性的内容。对比下来,更喜欢《统计学习方法》,毕竟能坚持看完才最重要。
笔记内容: 笔记内容尽量省去了公式推导的部分,一方面latex编辑太费时间了,另一方面,我觉得公式一定要自己推到一边才有用(最好是手写)。尽量保留所有标题,但内容会有删减,通过标黑和列表的形式突出重点内容,要特意说一下,标灰的部分大家最好读一下(这部分是我觉得比较繁琐,但又不想删掉的部分)。
代码实现: 最后是本章内容的实践,如果想要对应的.ipynb文件,可以留言
第5章 决策树
决策树(decision tree)是一种基本的分类与回归方法。本章主要讨论用于分类的决策树。
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。
- 学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。
- 预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
5.1 决策树模型与学习
5.1.1 决策树模型
定义5.1(决策树) :分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。
- 内部结点表示一个特征或属性
- 叶结点表示一个类
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。
如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
5.1.2 决策树与if-then规则
可以将决策树看成一个if-then规则的集合。
决策树转换成if-then规则:由决策树的根结点到叶结点的每一条路径构建一条规则;
- 路径上内部结点的特征对应着规则的条件,
- 而叶结点的类对应着规则的结论。
决策树的路径或其对应的if-then规则集合具有一个重要的性质:互斥并且完备。
(这就是说,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。这里所谓覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件。)
5.1.3 决策树与条件概率分布
特征空间---划分
决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分(partition)上。将特征空间划分为互不相交的单元(cell)或区域(region),并在每个单元定义一个类的概率分布就构成了一个条件概率分布。
路径--划分单元
决策树的一条路径对应于划分中的一个单元。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。
条件概率分布
假设 X X X为表示特征的随机变量,Y为表示类的随机变量,那么这个条件概率分布可以表示为 P ( Y ∣ X ) P(Y|X) P(Y∣X)。
X取值于给定划分下单元的集合,Y取值于类的集合。
条件概率--类
各叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大。决策树分类时将该结点的实例强行分到条件概率大的那一类去。
决策树:
- 图5.2(a)示意地表示了特征空间的一个划分。图中的大正方形表示特征空间。这个大正方形被若干个小矩形分割,每个小矩形表示一个单元。特征空间划分上的单元构成了一个集合,X取值为单元的集合。
- 为简单起见,假设只有两类:正类和负类,即Y取值为+1和–1。小矩形中的数字表示单元的类。
- 图5.2(b)示意地表示特征空间划分确定时,特征(单元)给定条件下类的条件概率分布。
- 图5.2(b)中条件概率分布对应于图5.2(a)的划分。
- 当某个单元 c c c(每个单元定义一个类的概率分布)的条件概率满足 P ( Y = + 1 ∣ X = c ) > 0.5 P(Y=+1|X=c)>0.5 P(Y=+1∣X=c)>0.5时,则认为这个单元属于正类,即落在这个单元的实例都被视为正例。
- 图5.2(c)为对应于图5.2(b)中条件概率分布的决策树。

5.1.4 决策树学习
决策树学习—数据集
假设给定训练数据集 D = ( ( x 1 , y 1 ) , ( x 2 , y 2 ) … . , ( x N , y N ) ) D=((x_1,y_1),(x_2,y_2)….,(x_N,y_N)) D=((x1,y1),(x2,y2)….,(xN,yN))
决策树学习—目的
其中, x i = ( x i 1 , x i 2 , . . . . . . , x i n ) T x_i=(x_i^1,x_i^2,......,x_i^n)^T xi=(xi1,xi2,......,xin)T为输入实例(特征向量),n为特征个数 Y i ∈ ( 1 , ⋅ ⋅ K ) Y_i \in ({1 ,·· K} ) Yi∈(1,⋅⋅K)为类标记, N N N 为样本容量。决策树学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习—本质
决策树学习本质上是从训练数据集中归纳出一组分类规则。(与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。)
我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。从另一个角度看,决策树学习是由训练数据集估计条件概率模型。基于特征空间划分的类的条件概率模型有无穷多个。我们选择的条件概率模型应该不仅对训练数据有很好的拟合,而且对未知数据有很好的预测。
决策树学习—损失函数
决策树学习用损失函数表示这一目标。如下所述,决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
决策树学习—学习问题
当损失函数确定以后, 学习问题就变为在损失函数意义下选择最优决策树**的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优(suboptimal)的。
决策树学习—构建决策树过程
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
开始,构建根结点:
- 将所有训练数据都放在根结点。
- 选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
- 如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去;
- 如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。
- 如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。
- 最后每个子集都被分到叶结点上,即都有了明确的类。这就生成了一棵决策树。
决策树学习—剪枝
剪枝原因:以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。
剪枝过程:我们需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点。
如果特征数量很多,也可以在决策树学习开始的时候,对特征进行选择,只留下对训练数据有足够分类能力的特征。
决策树学习—模型
可以看出,决策树学习算法包含特征选择、决策树的生成与决策树的剪枝过程。由于决策树表示一个条件概率分布,所以深浅不同的决策树对应着不同复杂度的概率模型。
- 决策树的生成对应于模型的局部选择,
- 决策树的剪枝对应于模型的全局选择。
决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
决策树学习常用的算法有ID3、C4.5与CART,下面结合这些算法分别叙述决策树学习的特征选择、决策树的生成和剪枝过程。
5.2 特征选择
5.2.1 特征选择问题
特征选择—--什么是具有分类能力的特征
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。(如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。)
特征选择—--特征选择的准则
经验上扔掉这样的特征对决策树学习的精度影响不大。通常特征选择的准则是信息增益或信息增益比。
首先通过一个例子来说明特征选择问题。
例5.1
[1] 表5.1是一个由15个样本组成的贷款申请训练数据。数据包括贷款申请人的4个特征(属性):
- 第1个特征是年龄,有3个可能值:青年,中年,老年;
- 第2个特征是有工作,有2个可能值:是,否;
- 第3个特征是有自己的房子,有2个可能值:是,否;
- 第4个特征是信贷情况,有3个可能值:非常好,好,一般。
表的最后一列是类别,
- 是否同意贷款,取2个值:是,否。
特征选择是决定用哪个特征来划分特征空间。 直观上,如果 个特征具有更好的分类能力,或者说,按照这个特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。信息增益 Cinformation gain) 就能够很好地表示这 直观的准则。
5.2.2 信息增益
为了便于说明,先给出熵与条件熵的定义。在信息论与概率统计中,熵(entropy) 是表示随机变量不确定性的度量。
------熵-------
设X是一个取有限个值的离散随机变量,其概率分布为:
P ( X = x i ) = p i P(X=x_i)=p_i P(X=xi)=pi
则随机变量X的熵定义为:
H ( X ) = − ∑ i = 1 n p i l o g ( p i ) ( 5.1 ) H(X)=-\sum_{i=1}^np_ilog(p_i) (5.1) H(X)=−i=1∑npilog(pi)(5.1)
在式(5.1)中,若 p i = 0 p_i=0 pi=0,则定义 0 l o g 0 = 0 0log0=0 0log0=0。
通常,式(5.1)中的对数以2为底或以e为底(自然对数),这时熵的单位分别称作比特(bit)或纳特(nat)。
由定义可知,熵只依赖于X的分布,而与X的取值无关,所以也可将X的熵记作 H ( p ) H(p) H(p),即
H ( p ) = − ∑ i = 1 n p i l o g ( p i ) ( 5.1 ) H(p)=-\sum_{i=1}^np_ilog(p_i) (5.1) H(p)=−i=1∑npilog(pi)(5.1)
熵越大,随机变量的不确定性就越大。
------条件熵-------
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性。
随机变量 X X X给定的条件下随机变量 Y Y Y的 条件熵(conditional entropy)H(Y|X),定义为 X X X给定条件下 Y Y Y的 条件概率分布的熵对X的数学期望
H ( Y ∣ X ) = ∑ i = 1 n H ( Y ∣ X = x i ) H(Y|X)=\sum_{i=1}^nH(Y|X=x_i) H(Y∣X)=i=1∑nH(Y∣X=xi)
------经验熵-------
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为 经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。
------信息增益-------
此时,如果有0概率,令0log0=0。信息增益(information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。

------互信息-------
一般地,熵 H ( Y ) H(Y) H(Y)与条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)之差称为**互信息**(mutual information)。
决策树学习中的信息增益等价于训练数据集中类与特征
相关文章:
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树
文章目录 第5章 决策树5.1 决策树模型与学习5.1.1 决策树模型5.1.2 决策树与if-then规则5.1.3 决策树与条件概率分布5.1.4 决策树学习5.2 特征选择5.2.1 特征选择问题5.2.2 信息增益5.2.3 信息增益比5.3.1 ID3算法5.3.2 C4.5的生成算法5.4 决策树的剪枝5.5 CART算法5.5.1 CART生…...

【C++11(一)】列表初始化and右值引用
一、 统一的列表初始化 1.1 {}初始化 在C98中,标准允许 使用花括号{}对数组或者结构体元素 进行统一的列表初始值设定 C11扩大了用大括号 括起的列表(初始化列表)的使用范围 使其可用于所有的内置类型和 用户自定义的类型 使用初始化列表时…...

为什么SSL会握手失败?SSL握手失败原因及解决方案
随着网络安全技术的发展,SSL证书作为网站数据安全的第一道防线,被越来越多的企业选择。SSL证书使用的是SSL协议,而SSL握手是SSL协议当中最重要的一部分。当部署SSL证书时,如果服务器和客户端之间无法建立安全连接,就会…...

STM32——智能小车
STM32——智能小车 硬件接线 B-1A – PB0 B-1B – PB1 A-1A – PB2 A-1B – PB10 其余接线参考51单片机小车项目。 1.让小车动起来 motor.c #include "motor.h" void goForward(void) {// 左轮HAL_GPIO_WritePin(GPIOB, GPIO_PIN_2, GPIO_PIN_SET);HAL_GPIO…...

开源:基于Vue3.3 + TS + Vant4 + Vite5 + Pinia + ViewPort适配..搭建的H5移动端开发模板
vue3.3-Mobile-template 基于Vue3.3 TS Vant4 Vite5 Pinia ViewPort适配 Sass Axios封装 vconsole调试工具,搭建的H5移动端开发模板,开箱即用的。 环境要求: Node:16.20.1 pnpm:8.14.0 必须装上安装pnpm,没装的看这篇…...
的理论基础)
缩略图保持加密(thumbnail-preserving encryption, TPE)的理论基础
这涉及到一些视觉心理学等方面知识: 1、参考文献: 云存储图像缩略图保持的加密研究进展(中国图像图形学报) 一些视觉心理学的研究为TPE的成功实现提供了理论基础。Potter(1975, 1976)的研究表明人类的视觉系统能够在100 ms内从一个新场景中提取出相应的语义信息;250 ms内…...
nodejs+vue+mysql校园失物招领网站38tp1
本高校失物招领平台是为了提高用户查阅信息的效率和管理人员管理信息的工作效率,可以快速存储大量数据,还有信息检索功能,这大大的满足了用户和管理员这两者的需求。操作简单易懂,合理分析各个模块的功能,尽可能优化界…...
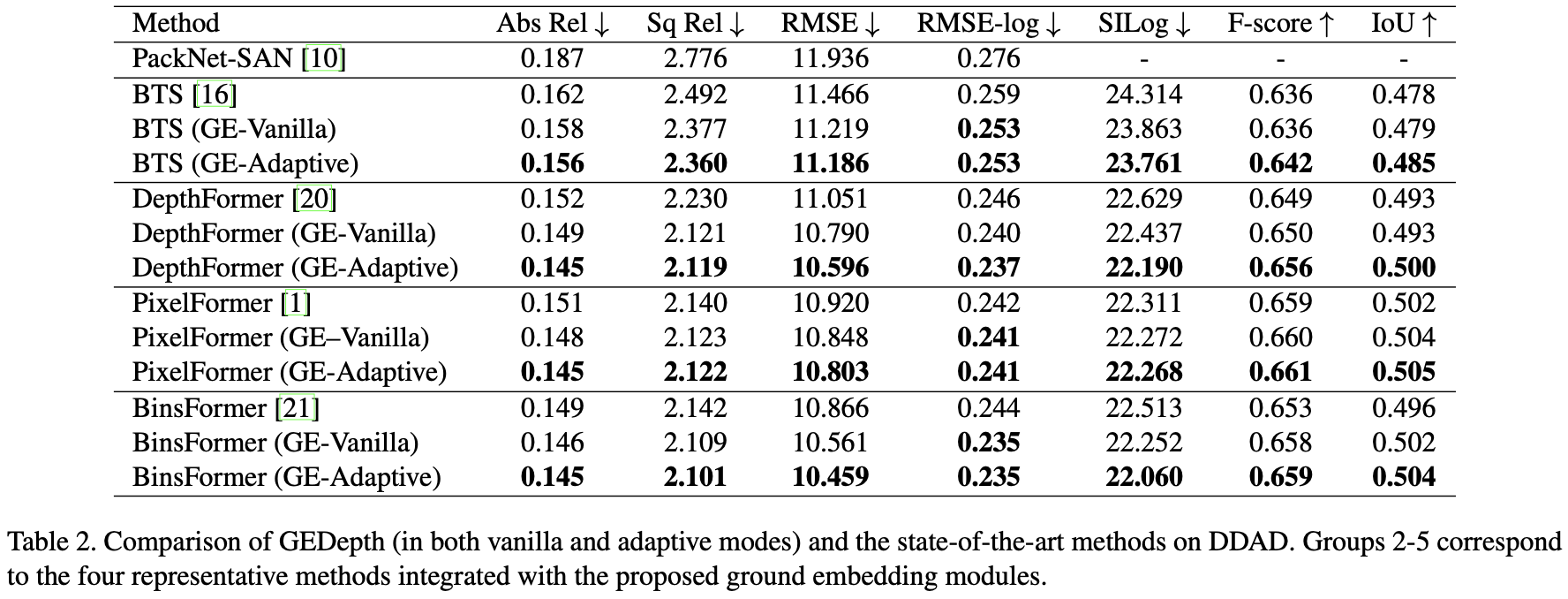
GEDepth:Ground Embedding for Monocular Depth Estimation
参考代码:gedepth 出发点与动机 相机的外参告诉了相机在世界坐标系下的位置信息,那么可以用这个外参构建一个地面基础深度作为先验,后续只需要在这个地面基础深度先验基础上添加offset就可以得到结果深度,这样可以极大简化深度估…...
校园圈子论坛系统--APP小程序H5,前后端源码交付,支持二开!uniAPP+PHP书写!
随着移动互联网的快速发展,校园社交成为了大学生们日常生活中重要的一部分。为了方便校园内学生的交流和互动,校园社交小程序逐渐走入人们的视野。本文将探讨校园社交小程序的开发以及其带来的益处。 校园社交小程序的开发涉及许多技术和设计方面。首先&…...
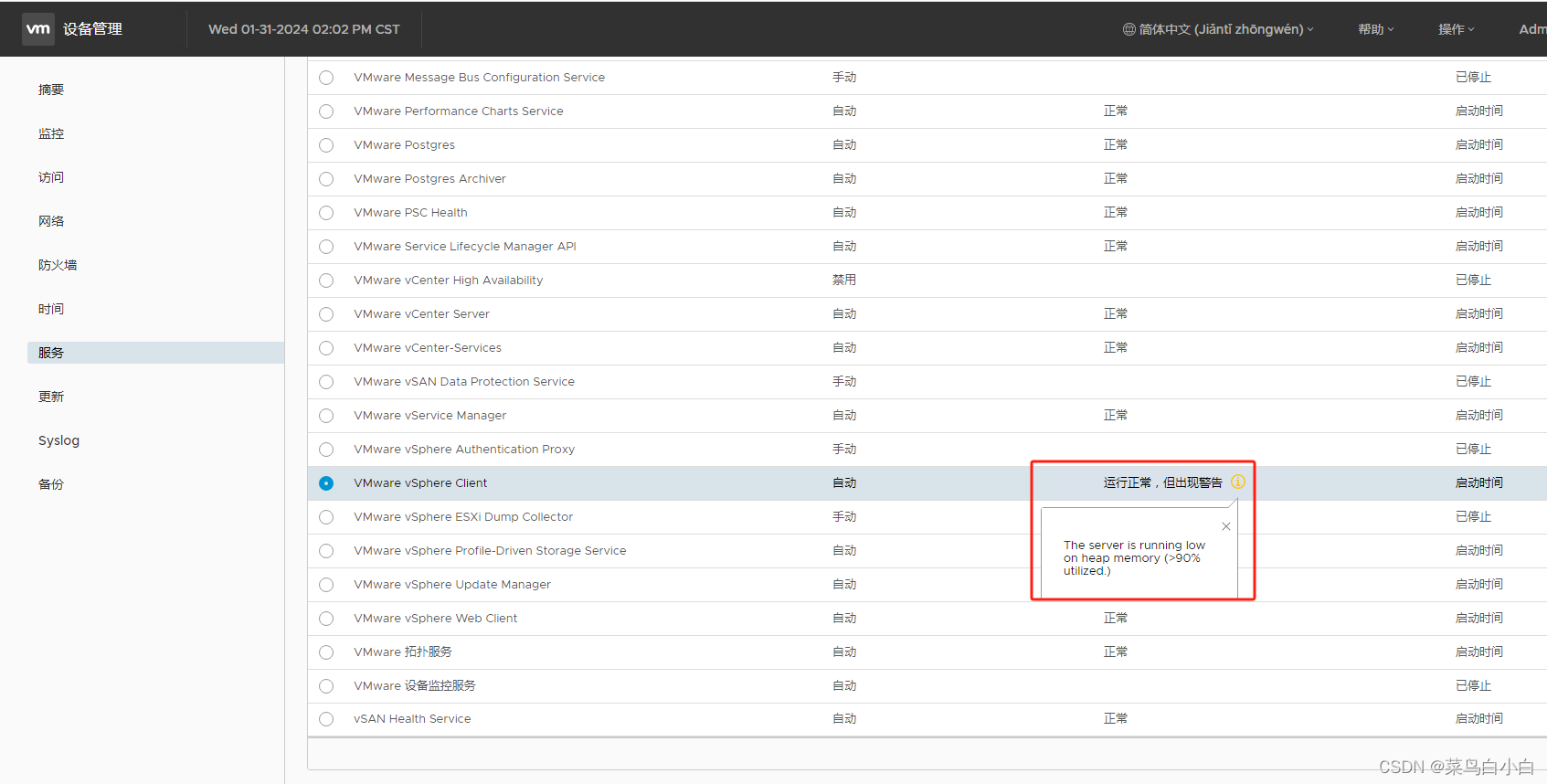
VMware vCenter告警:vSphere UI运行状况警报
vSphere UI运行状况警报 不会详细显示告警的具体内容,需要我们自己进一步确认告警原因。 vSphere UI运行状况警报是一种监控工具,用于检测vSphere环境中的潜在问题。当警报触发时,通常表示系统遇到了影响性能或可用性的问题。解决vSphere UI…...
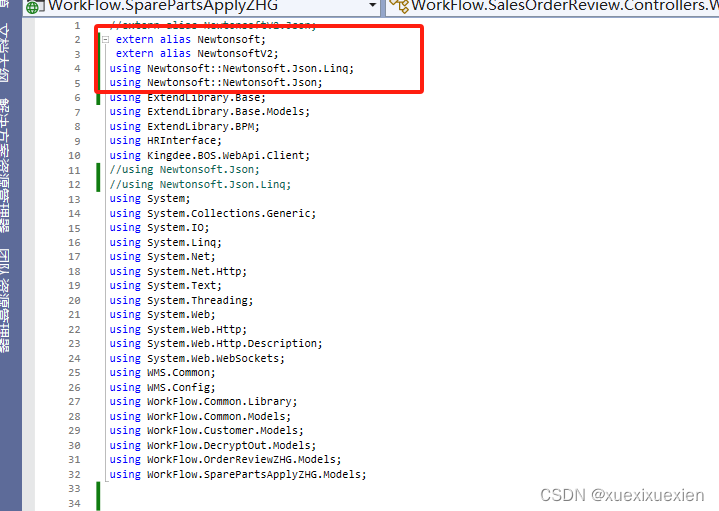
C# 引用同一个dll不同版本的程序集
因为项目需要所以必须在项目中引用不同版本的同一程序集 我要引用的文件是newtonsoft.json.dll 两个版本为12.0.0.0 和4.0.0.0 1.如果已经先引入了newtonsoft.json 12.0.0.0版本的程序集,如果直接引入另一个版本的程序集的话会提示不成功,所以先将另一个…...

单机搭建hadoop环境(包括hdfs、yarn、hive)
单机可以搭建伪分布式hadoop环境,用来测试和开发使用,hadoop包括: hdfs服务器 yarn服务器,yarn的前提是hdfs服务器, 在前面两个的基础上,课可以搭建hive服务器,不过hive不属于hadoop的必须部…...
LEETCODE 170. 交易逆序对的总数
class Solution { public:int reversePairs(vector<int>& record) {if(record.size()<1)return 0;//归并 递归int left,right;left0;rightrecord.size()-1;int nummergeSort(left,right,record);return num;}int mergeSort(int left,int right, vector<int>…...

「HarmonyOS」EventHub事件通知详细使用方法
需求背景: 在开发过程中,肯定会出现触发特定事件,需要全局进行通知,与之相关的部分进行执行相应的修改方法。举个例子:修改了用户个人昵称,需要进行全局通知,在涉及昵称的部分收到通知后&#…...

为什么golang不支持可重入锁呢?
为什么golang不需要可重入锁? 在工程中使用锁的原因在于为了保护不变量,也可以用于保护内、外部的不变量。 基于此,Go 在互斥锁设计上会遵守这几个原则。如下: 在调用 mutex.Lock 方法时,要保证这些变量的不变性保持…...
聊一聊Tomcat的架构和运行流程,尽量通俗易懂一点
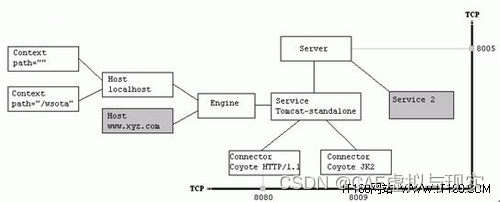
1、Tomcat的架构 这里可以看出 A、一个Tomcat就是一个Server,一个Server下会有多个Service, B、Service只负责封装多个Connector和一个Container(Service本身不是容器,可以看做只是用来包装Connector和Container的壳,…...

ModelArts加速识别,助力新零售电商业务功能的实现
前言 如果说为客户提供最好的商品是产品眼中零售的本质,那么用户的思维是什么呢? 在用户眼中,极致的服务体验与优质的商品同等重要。 企业想要满足上面两项服务,关键在于提升效率,也就是需要有更高效率的零售&#…...

Qt/C++音视频开发65-切换声卡/选择音频输出设备/播放到不同的声音设备/声卡下拉框
一、前言 近期收到一个用户需求,要求音视频组件能够切换声卡,首先要在vlc上实现,于是马不停蹄的研究起来,马上查阅对应vlc有没有自带的api接口,查看接口前,先打开vlc播放器,看下能不能切换&…...
MySQL原理(一)架构组成之逻辑模块(1)组成
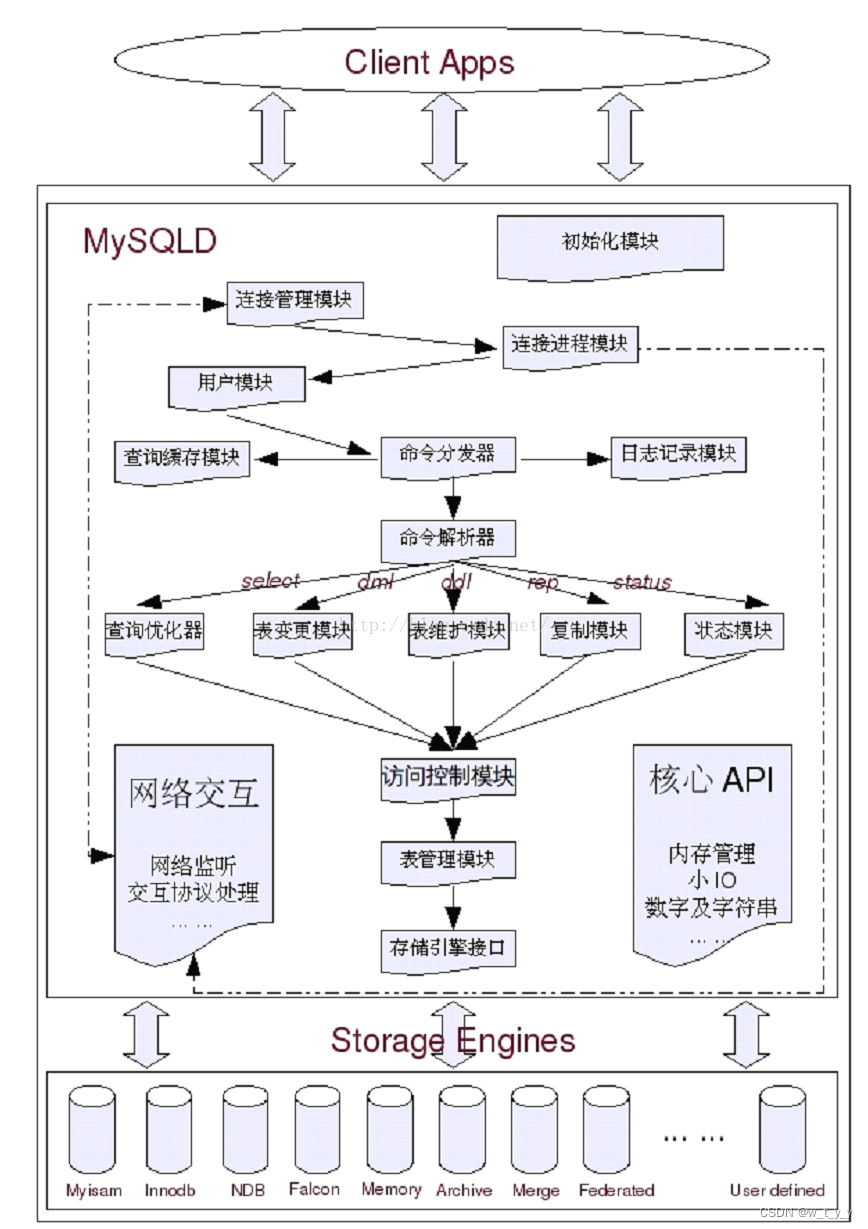
总的来说,MySQL可以看成是二层架构,第一层我们通常叫做SQL Layer,在MySQL数据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断,sql解析,执行计划优化,query cache的处理等等&…...

一、cadence PDK 自学笔记-心法
我这边ADS /Cadence PDK基本大部分都是自学完成的。 当然也非常感谢我的前同事周**的帮忙,教了我很多基础的。另外也感谢我现在同事,李**和程*的帮忙,学习了很多cad的视角。 其实对于自学写PDK的小伙伴,一般都要如何学习呢&…...

达梦数据库dmfldr:从入门到实战的性能调优与避坑指南
1. 初识达梦数据库dmfldr工具 第一次接触达梦数据库的dmfldr工具时,我正面临一个棘手的问题:需要将超过2TB的销售数据从旧系统迁移到达梦数据库。当时尝试了几种常见的数据迁移方式,要么速度慢得令人崩溃,要么在中途就报错退出。直…...

从HIP4082到IR2184:直流电机驱动芯片怎么选?聊聊全桥与半桥方案的取舍
从HIP4082到IR2184:直流电机驱动芯片的工程化选型指南 在智能硬件和工业自动化项目中,电机驱动方案的选择往往决定着整个系统的可靠性边界。当工程师面对满目琳琅的驱动芯片时,IR2184和HIP4082这两个经典型号总会出现在候选清单中——前者以半…...

别再只用filter了!MATLAB的filtfilt函数如何帮你消除心电信号里的相位延迟?
零相位滤波实战:如何用MATLAB的filtfilt精准提取心电信号特征 生物医学信号处理工程师们经常面临一个棘手问题:传统滤波器在消除噪声的同时,会扭曲信号的时间特征。想象一下,当你精心设计的算法因为滤波导致的相位延迟,…...

基于MCP协议与FCM构建AI助手移动推送通知系统
1. 项目概述:一个连接MCP与FCM的推送桥梁 最近在折腾一些自动化工作流,经常需要在不同的服务和应用之间传递消息和通知。比如,一个脚本运行成功了,或者服务器出了点小状况,如果能第一时间推送到手机上,那处…...

深入Linux内核:SysRq‘魔法键’的驱动实现与串口触发机制剖析
Linux内核魔法键:SysRq机制的深度实现与串口调试实战 在嵌入式Linux开发中,当系统出现严重故障甚至完全冻结时,传统调试手段往往束手无策。此时,SysRq(System Request)功能就像一把瑞士军刀,为…...

3大功能场景深度解析:如何用Umi-OCR高效解决日常文字识别难题
3大功能场景深度解析:如何用Umi-OCR高效解决日常文字识别难题 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置…...

终极AI斗地主助手:DouZero_For_HappyDouDiZhu完整使用指南
终极AI斗地主助手:DouZero_For_HappyDouDiZhu完整使用指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 还在为斗地主胜率低而烦恼吗?想…...

基于TensorRT-LLM的DeepSeek模型本地部署与推理加速实战
1. 项目概述与核心价值最近在本地部署和运行大语言模型(LLM)的朋友越来越多了,无论是出于数据隐私的考虑,还是为了获得更低的推理延迟和成本,本地化部署都成了一个绕不开的话题。我自己也在这个方向上折腾了很久&#…...

构建私有数字生命线:Go+SQLite+Vue3实现端到端加密个人数据管理
1. 项目概述:一个为个人数字生活打造的“生命线”最近在整理自己的数字资产时,我意识到一个严重问题:我的照片、文档、笔记、代码片段,以及各种服务的账号密码,分散在手机、电脑、云盘和无数个在线服务里。一旦某个设备…...

ESP8266定时开关进阶玩法:不用写App,用微信小程序也能远程+定时控制
ESP8266智能控制新思路:用微信小程序替代原生App的完整实践指南 在物联网项目开发中,ESP8266因其高性价比和丰富的功能库成为智能硬件开发的首选。然而,传统方案往往需要用户安装专用App,这不仅增加了用户使用门槛,也提…...