深度学习(12)--Mnist分类任务
一.Mnist分类任务流程详解
1.1.引入数据集
Mnist数据集是官方的数据集,比较特殊,可以直接通过%matplotlib inline自动下载,博主此处已经完成下载,从本地文件中引入数据集。
设置数据路径
from pathlib import Path# 设置数据路径
# PATH = Path("data/minst")
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"# PATH.mkdir(parents=True, exist_ok=True) # 父目录不存在时创建父目录'''
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
'''读取数据
import pickle
import gzip# 读取数据
'''
gzip.open的作用是解压gzip文件
with gzip.open(PATH.as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
# rb表示以二进制格式打开一个文件用于只读
# 打开PATH路径的文件用以接下来的操作
# 保存数据的文件类型为pickle,所以用pickle.load打开文件,文件此处设置的别名为f
with open(PATH.as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")'''
as.posix()的作用:
#返回使用斜杠(/)分割路径的字符串
#将所有连续的正斜杠、反斜杠,统一修改为单个正斜杠
#相对路径 './' 替换为空,'../' 则保持不变。
'''测试引入数据集是否成功
from matplotlib import pyplot
import numpy as np# 测试数据集是否导入成功
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)

1.2.数据类型转换
数据需要转换成tensor类型才能参与后续建模训练
import torch# 通过map映射,将x_train等数据全都转为torch.tensor类型。tensor类型才能参与后续建模训练
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid)
)
测试数据类型是否转换成功
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())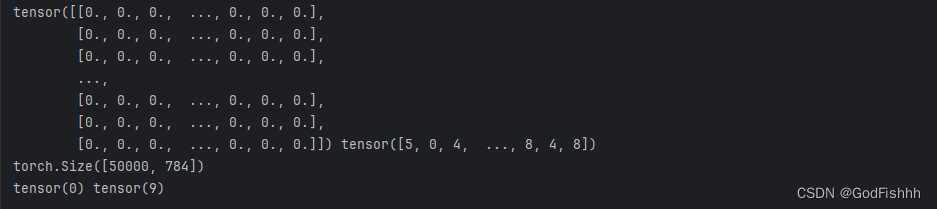
数据均为tensor类型,转换成功
1.3.设置损失函数
import torch.nn.functional as F# 设置损失函数,此处使用的损失函数为交叉熵
loss_func = F.cross_entropy
测试损失函数
手动设置初始权重和偏置值进行测试,真实情况下系统会自动帮我们初始化
bs = 64
xb = x_train[0:bs] # a mini-batch from x ,xb是x_train中0~64项的数
yb = y_train[0:bs]# 实际操作中模型会自动定义权重参数,不用我们手动设置
# 因为输入数据是784x1个像素点,而最后得到的是十个类别,所以权重矩阵的大小为784x10。
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
# bias矩阵的大小取决于最后的类别数量,此处的bias矩阵为10x1
bias = torch.zeros(10, requires_grad=True)def model(xb):return xb.mm(weights) + bias # .mm()是矩阵相乘 .mul()则是对应位相乘# 损失函数是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,此处model(xb)得到的是经过权重计算的预测值,yb是真实值。给损失函数传入的参数即为预测值和真实值。
print(loss_func(model(xb), yb))
1.4.神经网络构造
此处所选用的是传统神经网络完成Minist分类任务
from torch import nn# 创建一个模型类,注意一定要继承于nn.Module(取决于你要创建的网络类型)
class Mnist_NN(nn.Module):def __init__(self):# 调用父类的构造函数super().__init__()# 创建两个隐层 由784->128->256->10self.hidden1 = nn.Linear(784, 128)self.hidden2 = nn.Linear(128, 256)# 创建输出层,由256->10,即最后输出十个类别self.out = nn.Linear(256, 10)self.dropout = nn.Dropout(0.5)# torch框架需要自己定义前向传播,反向传播由框架自己实现# 传入的x是一个batch x 特征值def forward(self, x):# x经过第一个隐层x = F.relu(self.hidden1(x))# x经过dropout层x = self.dropout(x)# x经过第二个隐藏x = F.relu(self.hidden2(x))# x经过dropout层x = self.dropout(x)# x经过输出层x = self.out(x)return x测试构造的神经网络
net = Mnist_NN()
print(net)
查看网络中构建好的权重和偏置项
for name, parameter in net.named_parameters():print(name, parameter,parameter.size())1.5.使用TensorDataset和DataLoader简化数据
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader# TensorDataset获取数据,再由DataLoader打包数据传给GPU(包的大小位batch_size)
# 训练集一般打乱顺序,验证集不打乱顺序
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)def get_data(train_ds, valid_ds, bs):return (DataLoader(train_ds, batch_size=bs, shuffle=True),DataLoader(valid_ds, batch_size=bs * 2),)1.6.模型训练
优化器设置
from torch import optim
def get_model():model = Mnist_NN() # 使用先前创建的类构造一个网络return model, optim.SGD(model.parameters(), lr=0.001) # 返回值为模型和优化器# 优化器的设置,optim.SGD(),参数分别为:要优化的参数、学习率def loss_batch(model, loss_func, xb, yb, opt=None):# 计算损失,参数为预测值和真实值loss = loss_func(model.forward(xb), yb) # 预测值由定义的前向传播过程计算处# 如果存在优化器if opt is not None: loss.backward() # 反向传播,算出更新的权重参数opt.step() # 执行backward()计算出的权重参数的更新opt.zero_grad() # torch会进行迭代的累加,通过zero_grad()将之前的梯度清空(不同的迭代之间应当是没有关系的)return loss.item(), len(xb)常用优化器:
- 随机梯度下降(SGD, stochastic gradient descent)
- SGDM(加入了一阶动量)
- AdaGrad(加入了二阶动量)
- RMSProp
- Adam
模型训练
import numpy as np#epoch和batch的关系,
#eg:有10000个数据,batch=100,则一个1epoch需要训练100个batch(1一个epoch就是训练整个数据一次)
# 定义训练函数,传入的参数分别为:迭代的次数、模型、损失函数、优化器、训练集、验证集
def fit(steps, model, loss_func, opt, train_dl, valid_dl):for step in range(steps):# 训练模式:model.train() for xb, yb in train_dl:loss_batch(model, loss_func, xb, yb, opt) # 得到由loss_batch更新的权重值# 验证模式:model.eval() with torch.no_grad(): # 没有梯度,即不更新权重参数# zip将两个矩阵配对,例如两个一维矩阵配对成一个二维矩阵,下述情况中即为一个losses对应一个nums -> [(losses,nums)]。zip*是解包操作,即将二维矩阵又拆分成一维矩阵,并返回拆分得到的一维矩阵。losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) # 计算平均损失:对应的损失值和样本数相乘的总和 / 总样本数print('当前step:'+str(step), '验证集损失:'+str(val_loss))二.完整代码
from pathlib import Path
import pickle
import gzipfrom matplotlib import pyplot
import numpy as npimport torchimport torch.nn.functional as Ffrom torch import nnfrom torch.utils.data import TensorDataset
from torch.utils.data import DataLoaderfrom torch import optimimport numpy as np# 设置数据路径
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist.pkl"# PATH.mkdir(parents=True, exist_ok=True)'''
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
'''# 读取数据
'''
gzip.open的作用是解压gzip文件
with gzip.open(PATH.as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
# rb表示以二进制格式打开一个文件用于只读
# 打开PATH路径的文件用以接下来的操作
# 保存数据的文件类型为pickle,所以用pickle.load打开文件,文件此处设置的别名为f
with open(PATH.as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")'''
as.posix()的作用:
#返回使用斜杠(/)分割路径的字符串
#将所有连续的正斜杠、反斜杠,统一修改为单个正斜杠
#相对路径 './' 替换为空,'../' 则保持不变。
''''''
# 测试数据集是否导入成功
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
'''# 数据类型转换为torch# 通过map映射,将x_train等数据全都转为torch.tensor类型。tensor类型才能参与后续建模训练
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid)
)# 测试数据类型是否转换成功
'''
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
'''# 设置损失函数
loss_func = F.cross_entropybs = 64
xb = x_train[0:bs] # a mini-batch from x ,xb是x_train中0~64项的数
yb = y_train[0:bs]'''
# 手动初始化进行测试# 实际操作中模型会自动定义权重参数,不用我们手动设置
# 因为输入数据是784x1个像素点,而最后得到的是十个类别,所以权重矩阵的大小为784x10。
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
# bias矩阵的大小取决于最后的类别数量,此处的bias矩阵为10x1
bias = torch.zeros(10, requires_grad=True)def model(xb):return xb.mm(weights) + bias # .mm()是矩阵相乘 .mul()则是对应位相乘# 损失函数是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,此处model(xb)得到的是经过权重计算的预测值,yb是真实值。给损失函数传入的参数即为预测值和真实值。
print(loss_func(model(xb), yb))
'''# 创建一个模型类,注意一定要继承于nn.Module(取决于你要创建的网络类型)
class Mnist_NN(nn.Module):def __init__(self):# 调用父类的构造函数super().__init__()# 创建两个隐层 由784->128->256->10self.hidden1 = nn.Linear(784, 128)self.hidden2 = nn.Linear(128, 256)# 创建输出层,由256->10,即最后输出十个类别self.out = nn.Linear(256, 10)self.dropout = nn.Dropout(0.5)# torch框架需要自己定义前向传播,反向传播由框架自己实现# 传入的x是一个batch x 特征值def forward(self, x):# x经过第一个隐层x = F.relu(self.hidden1(x))# x经过dropout层x = self.dropout(x)# x经过第二个隐藏x = F.relu(self.hidden2(x))# x经过dropout层x = self.dropout(x)# x经过输出层x = self.out(x)return x'''
# 测试构造的网络模型
net = Mnist_NN()
print(net)打印权重和偏置项
for name, parameter in net.named_parameters():print(name, parameter,parameter.size())
'''# TensorDataset获取数据,再由DataLoader打包数据传给GPU
# 训练集一般打乱顺序,验证集不打乱顺序
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)def get_data(train_ds, valid_ds, bs):return (DataLoader(train_ds, batch_size=bs, shuffle=True),DataLoader(valid_ds, batch_size=bs * 2),)# 优化器设置
def get_model():model = Mnist_NN()return model, optim.SGD(model.parameters(), lr=0.001)# 优化器的设置,optim.SGD(),参数分别为:要优化的参数、学习率def loss_batch(model, loss_func, xb, yb, opt=None):# 计算损失,参数为预测值和真实值loss = loss_func(model.forward(xb), yb) # 预测值由定义的前向传播过程计算处# 如果存在优化器if opt is not None:loss.backward() # 反向传播,算出更新的权重参数opt.step() # 执行backward()计算出的权重参数的更新opt.zero_grad() # torch会进行迭代的累加,通过zero_grad()将之前的梯度清空(不同的迭代之间应当是没有关系的)return loss.item(), len(xb)# 模型训练
# epoch和batch的关系,
# eg:有10000个数据,batch=100,则一个1epoch需要训练100个batch(1一个epoch就是训练整个数据一次)
# 定义训练函数,传入的参数分别为:迭代的次数、模型、损失函数、优化器、训练集、验证集
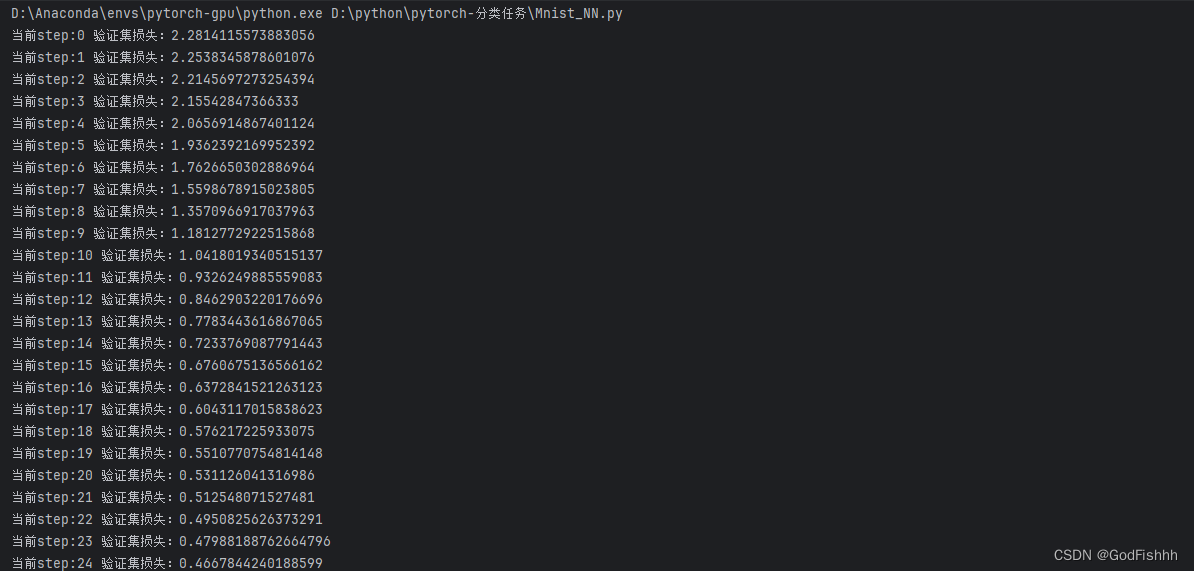
def fit(steps, model, loss_func, opt, train_dl, valid_dl):for step in range(steps):# 训练模式:model.train()for xb, yb in train_dl:loss_batch(model, loss_func, xb, yb, opt) # 得到由loss_batch更新的权重值# 验证模式:model.eval()with torch.no_grad(): # 没有梯度,即不更新权重参数# zip将两个矩阵配对,例如两个一维矩阵配对成一个二维矩阵,下述情况中即为一个losses对应一个nums -> [(losses,nums)]。zip*是解包操作,即将二维矩阵又拆分成一维矩阵,并返回拆分得到的一维矩阵。losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) # 计算平均损失:对应的损失值和样本数相乘的总和 / 总样本数print('当前step:'+str(step), '验证集损失:'+str(val_loss))# 输出
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(25, model, loss_func, opt, train_dl, valid_dl)# 准确率的计算
correct = 0
total = 0
for xb,yb in valid_dl:outputs = model(xb)_, predicted = torch.max(outputs.data,1) # 返回最大的值和对应的列索引(列索引在此处就是对应的类别) (, 0)则返回行索引total += yb.size(0) # yb的样本数correct += (predicted == yb).sum().item( ) # .sum()返回验证正确了的样本数,item()从tensor数据类型中取值,方便后续的画图等(tensor数据类型不好画图)print('Accuracy of the network on the 10000 test image: %d %%' %(100*correct/total))三.输出结果
相关文章:
深度学习(12)--Mnist分类任务
一.Mnist分类任务流程详解 1.1.引入数据集 Mnist数据集是官方的数据集,比较特殊,可以直接通过%matplotlib inline自动下载,博主此处已经完成下载,从本地文件中引入数据集。 设置数据路径 from pathlib import Path# 设置数据路…...

AI工具【OCR 01】Java可使用的OCR工具Tess4J使用举例(身份证信息识别核心代码及信息提取方法分享)
Java可使用的OCR工具Tess4J使用举例 1.简介1.1 简单介绍1.2 官方说明 2.使用举例2.1 依赖及语言数据包2.2 核心代码2.3 识别身份证信息2.3.1 核心代码2.3.2 截取指定字符2.3.3 去掉字符串里的非中文字符2.3.4 提取出生日期(待优化)2.3.5 实测 3.总结 1.简…...

【MySQL复制】半同步复制
介绍 除了内置的异步复制之外,MySQL 5.7 还支持通过插件实现的半同步复制接口。本节讨论半同步复制的概念及其工作原理。接下来的部分将涵盖与半同步复制相关的管理界面,以及如何安装、配置和监控它。 异步复制 MySQL 复制默认是异步的。源服务器将事…...

PHP面试知识点--echo、print、print_r、var_dump区别
echo、print、print_r、var_dump 区别 echo 输出单个或多个字符,多个使用逗号分隔无返回值 echo "String 1", "String 2";print 只可以输出单个字符返回1,因此可用于表达式 print "Hello"; if ($expr && pri…...
centos 7 部署若依前后端分离项目
目录 一、新建数据库 二、修改需求配置 1.修改数据库连接 2.修改Redis连接信息 3.文件路径 4.日志存储路径调整 三、编译后端项目 四、编译前端项目 1.上传项目 2.安装依赖 3.构建生产环境 五、项目部署 1.创建目录 2.后端文件上传 3. 前端文件上传 六、服务启…...

RFID手持终端_智能pda手持终端设备定制方案
手持终端是一款多功能、适用范围广泛的安卓产品,具有高性能、大容量存储、高端扫描头和全网通数据连接能力。它能够快速平稳地运行,并提供稳定的连接表现和快速的响应时,适用于医院、物流运输、零售配送、资产盘点等苛刻的环境。通过快速采集…...

51单片机学习——矩阵按键
目录 gitee链接 小程吃饭饭 (xiaocheng-has-a-meal) - Gitee.comhttps://gitee.com/xiaocheng-has-a-meal 1.图~突突突突突 矩阵键盘原理图 矩阵键盘的实物图 2.矩阵键盘 引入~啦啦啦啦啦 原理~沥沥沥沥沥 代码~嗷嗷嗷嗷嗷 【1】延时函数 【2】 LCD1602 【3】检测按…...

重写Sylar基于协程的服务器(1、日志模块的架构)
重写Sylar基于协程的服务器(1、日志模块的架构) 重写Sylar基于协程的服务器系列: 重写Sylar基于协程的服务器(0、搭建开发环境以及项目框架 || 下载编译简化版Sylar) 重写Sylar基于协程的服务器(1、日志模…...

ElementUI Form:Radio 单选框
ElementUI安装与使用指南 Radio 单选框 点击下载learnelementuispringboot项目源码 效果图 el-radio.vue (Radio 单选框)页面效果图 项目里el-radio.vue代码 <script> export default {name: el_radio,data() {return {radio: 1,radio2: 2,ra…...

react-activation实现缓存,且部分页面刷新缓存,清除缓存
1.安装依赖 npm i -S react-activation2.使用AliveScope 包裹根组件 import { AliveScope } from "react-activation" <AliveScope><Router><Switch><Route exact path"/" render{() > <Redirect to"/login" push …...
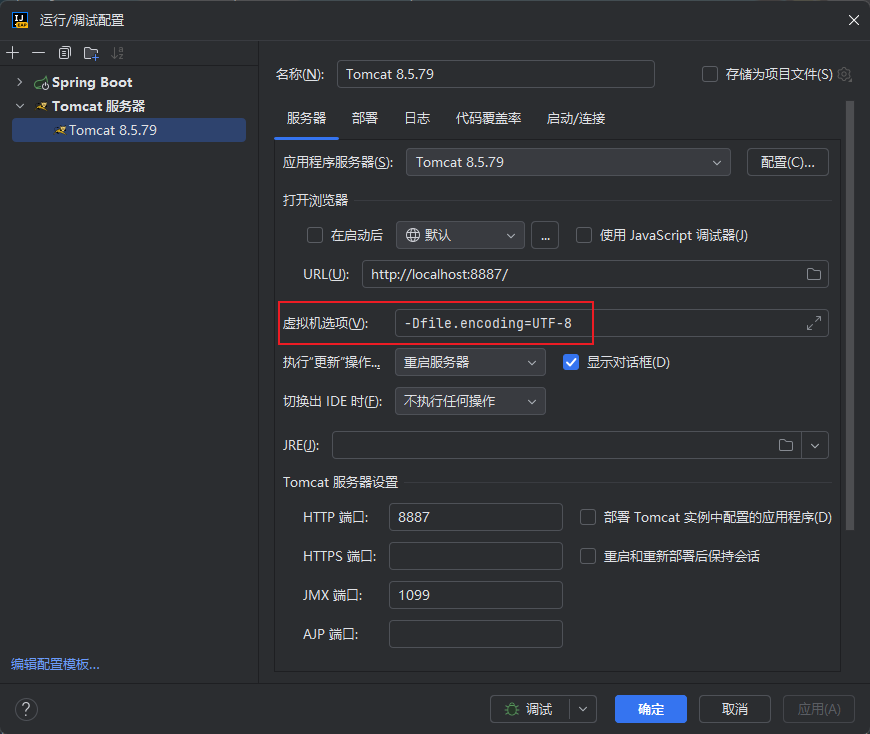
idea 中 tomcat 乱码问题修复
之前是修改 Tomcat 目录下 conf/logging.properties 的配置,将 UTF-8 修改为 GBK,现在发现不用这样修改了。只需要修改 IDEA 中 Tomcat 的配置就可以了。 修改IDEA中Tomcat的配置:添加-Dfile.encodingUTF-8 本文结束...

Modbus协议学习第七篇之libmodbus库API介绍(modbus_write_bits等)
写在前面 在第六篇中我们介绍了基于libmodbus库的演示代码,那本篇博客就详细介绍一下第六篇的代码中使用的基于该库的API函数。另各位读者,Modbus相关知识受众较少,如果觉得我的专栏文章有帮助,请一定点个赞,在此跪谢&…...

第九节HarmonyOS 常用基础组件13-TimePicker
1、描述 时间选择组件,根据指定参数创建选择器,支持选择小时以及分钟。默认以24小时的时间区间创建滑动选择器。 2、接口 TimePicker(options?: {selected?: Date}) 3、参数 selected - Date - 设置选中项的时间。默认是系统当前的时间。 4、属性…...

力扣刷题-55.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 class Solution { publ…...

Ruby安装演示教程
安装 Ruby 的过程会根据您的操作系统(如 Windows、MacOS、Linux)而有所不同。以下是在这些主要平台上安装 Ruby 的基本指南。 在 Windows 上安装 Ruby 下载 Ruby Installer:访问 RubyInstaller 官方网站下载适合您系统的 Ruby Installer 版…...

前端使用vue-simple-uploader进行分片上传
目录 一、安装vue-simple-uploader 二、在vue中使用 一、安装vue-simple-uploader npm install vue-simple-uploader --save main.js初始化vue-simple-uploader import uploader from vue-simple-uploaderVue.use(uploader) common/config文件 export const ACCEPT_CONF…...

Java 源代码中常见的数据类型
在Java源代码中,常见的数据类型包括基本数据类型(Primitive Data Types)和引用数据类型(Reference Data Types)。这些数据类型在Java中用于存储不同种类的数据,如整数、小数、字符、布尔值以及对象等。 1.…...
Web3行业研究逐步加强,“链上数据”缘何成为关注焦点?
据中国电子报报道,近日,由中关村区块链产业联盟指导,中国信息通信研究院牵头,欧科云链控股有限公司参与编写的《全球Web3产业全景与发展趋势研究报告(2023年)》正式发布。研究报告通过全面追踪国内外Web3产…...
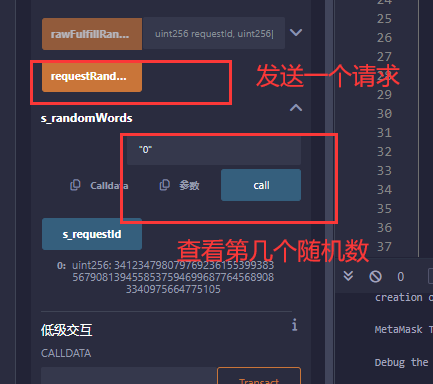
逸学区块链【solidity】真随机数
参考Get a Random Number | Chainlink Documentation 但是很贵,价格 Gas Price:当前gas价格,根据网络状况而波动。Callback gas :返回您所请求的随机值时,回调请求消耗的gas 量。验证gas :量gas 用于验证…...

【WPF.NET开发】优化性能:对象行为
本文内容 不删除对象的事件处理程序可能会使对象保持活动状态依赖属性和对象Freezable 对象用户界面虚拟化 了解 WPF 对象的内部行为有助于在功能和性能之间做出适当的取舍。 1、不删除对象的事件处理程序可能会使对象保持活动状态 对象传递给其事件的委托是对该对象的有效…...

Lychee-Rerank高可用部署架构:基于Docker Compose的多实例负载均衡
Lychee-Rerank高可用部署架构:基于Docker Compose的多实例负载均衡 如果你正在把Lychee-Rerank这类重排序模型用到线上业务里,可能已经发现了一个问题:单个服务实例太脆弱了。流量一上来,服务就卡顿;服务器出点小毛病…...

Fun-ASR-MLT-Nano-2512实战教程:FFmpeg音频降噪预处理提升远场识别率
Fun-ASR-MLT-Nano-2512实战教程:FFmpeg音频降噪预处理提升远场识别率 1. 引言 远场语音识别一直是个头疼的问题——背景噪音、回声干扰、声音衰减,这些因素让语音识别准确率大幅下降。在实际应用中,我们经常遇到这样的场景:会议…...

S2-Pro辅助3D建模与场景描述:连接自然语言与Blender脚本生成
S2-Pro辅助3D建模与场景描述:连接自然语言与Blender脚本生成 1. 当3D建模遇上自然语言 想象一下这样的场景:你脑海中浮现出一个充满未来感的客厅设计,但打开Blender后却不知从何下手。传统3D建模需要掌握复杂软件操作和脚本编写,…...

基于Matlab实现 IEEE33节点配电网系统simulink仿真模型,并配套前推回代法潮流计算程序
基于Matlab实现 IEEE33节点配电网系统simulink仿真模型,并配套前推回代法潮流计算程序。 改进的IEEE33节点,潮流计算,电压分析,可自行加风机光伏,接电动机负载。 结果图如图所展示,附带IEEE33节点数据MATLA…...

如何用双路PWM实现16bit DAC输出?MCU音频信号处理实战
如何用双路PWM实现16bit DAC输出?MCU音频信号处理实战 在嵌入式音频开发中,高精度DAC输出往往是提升音质的关键。但当你手头的MCU主频有限,内置DAC分辨率不足时,如何突破硬件限制?本文将带你深入双路PWM分频叠加技术的…...

兄弟同心,其利断金:Tomcat、Nginx 与 Node.js 的“三重奏”
写在前面初学后端开发时,我一直困惑一个问题:Tomcat、Nginx、Node.js,它们之间到底是什么关系?刚开始用 Spring Boot,发现里面集成了 Tomcat,启动项目后访问 localhost:8080 就能调接口。那时我以为&#x…...
)
为什么你的EventHandler仍触发装箱?C# 13 `ref delegate`与`unmanaged`委托语法(仅限.NET 8.0.3+ RTM)
第一章:为什么你的EventHandler仍触发装箱?C# 13 ref delegate与unmanaged委托语法(仅限.NET 8.0.3 RTM)即使在 .NET 8.0.3 RTM 中启用了 C# 13 的新委托特性,许多开发者仍观察到 EventHandler 回调中频繁发生值类型参…...

从零到一:借助MCP与Neo4j实现无代码知识图谱的快速落地
1. 为什么你需要无代码知识图谱 想象一下这样的场景:你手头堆积着大量会议记录、产品文档和客户反馈,这些信息就像散落的拼图碎片,彼此之间似乎存在某种联系,但你却找不到合适的方法把它们串联起来。传统的数据处理工具面对这种非…...

【论文解读】SparseDriveV2: Scoring is All You Needfor End-to-End Autonomous Driving
https://github.com/swc-17/SparseDriveV2 【摘要】 【引言】 【相关工作】 【方法】 【实验】...

嵌入式贝叶斯优化:Arduino/ESP32轻量级1D黑箱调参库
1. 项目概述Bayesian Optimization(贝叶斯优化)Arduino 库是一个面向资源受限嵌入式平台的轻量级、确定性、单输入维度(1D)黑箱函数优化器。它并非通用数值计算库,而是专为微控制器场景深度定制的实时决策引擎——当目…...