Tarjan算法学习笔记
目录
无向图的割点与桥
时间戳:
搜索树:
追溯值:
割边判定法则:
割点判定法则:
无向图的双连通分量
定理:
边双连通分量(e-DCC)的求法:
e-DCC的缩点:
有向图的连通性
追溯值:
Tarjan算法求强连通分量(SCC):
无向图的割点与桥
无向连通图G=(V,E):
若对于 x 属于 V,从图中删去节点 x 以及所有与 x 关联的边之后,G 分裂成两个或两个以上不相连的子图,则称 x 为 G 的割点。
若对于 e 属于 E ,从图中删去边 e 之后,G 分裂成两个不相连的子图,则称 e 为 G 的桥或割边。
一般无向图(不一定连通)的“割点”和“桥”就是它的各个连通块恶的“割点”和“桥”。
Tarjan算法能够求出有向图的强连通分量、必经点与必经边。Tarjan算法是基于无向图的深度优先遍历。
时间戳:
在图的深度优先遍历过程中,按照每个节点第一次被访问的时间顺序,依次给与 N 个节点 1~N 的整数标记,给标记称为“时间戳”,记为 dfn[n]。
搜索树:
在无向连通图中任选一个节点出发进行深度优先遍历,每个点只访问一次。所有发生递归的边(x,y)(换言之,从x到y是对y的第一次访问)构成一棵树,我们把它称为“无向连通图的搜索树”。当然,一般无向图(不一定连通)的各个连通块的搜索树构成无向图的“搜索森林”。
追溯值:
设 subtree[x] 表示搜索树中以 x 为根的子树。low[x] 定义为以下节点的时间戳的最小值。
1)subtree[x] 中的节点。
2)通过1条不在搜索树上的边,能够到达 subtree[x] 的节点。
根据定义,为了计算 low[x],应该先令 low[x]=dfn[x],然后考虑从 x 出发的每条边。
若在搜索树上 x 是 y 的父节点,则令 low[x]=min(low[x],low[y]).
若无向边(x,y)不是搜索树上的边,则令 low[x]=min(low[x],dfn[y]).
割边判定法则:
无向边(x,y)是桥,当且仅当搜索树上存在 x 的一个子节点 y ,满足:dfn[x]<low[y].
根据定义,dfn[x]<low[y] 说明从 subtree[y] 出发,在不经过 (x,y)的前提下,不管走那条边,都无法到达 x 或比 x 更早访问的节点。若把(x,y)删除,则 subtree[y] 就好像形成了一个封闭的环境,与节点 x 没有边相连,图断开成了两部分,因此(x,y)是割边。
反之,若不存在这样的子节点 y ,使得 dfn[x]<low[y],则说明每个 subtree[y] 都能绕行其他边到达 x 或比 x 更早访问的节点,(x,y)自然就不是割边。
桥一定是搜索树中的边,并且一个简单环中的边一定都不是桥。
特别需要注意, 因为我们遍历的是无向图,所以从每个点 x 出发,总能访问到它的父节点 fa。 根据 low 的计算方法,(x,fa) 属于搜索树上的边,且 fa 不是 x 的子节点,故不能用 fa 的时间戳来更新low[x] 。
但是,如果仅记录每个节点的父节点,会无法处理重边的情况——当 x 与 fa 之间有多条边时,(x,fa) 一定不是桥。 在这些重复的边中, 只有一条算是“搜索树上的边” 其他的几条都不算。 故有重边时, dfn[fa] 能用来更新 low[x]。
一个好的解决方案是:改为记录“递归进入每个节点的边的编号” 。编号可认为是边在邻接表中存储的下标位置。 这里介绍“成对变换”技巧。把无向图的每一条边看作双向边, 成对存储在下标 “2和3” “4和5” “6和7”处。若沿着编号为的边递归进入了节点 x ,则忽略从 x 出发的编号为 i xor 1 的边,通过其他边计算 low[x] 即可。
割点判定法则:
若 x 不是搜索树的根节点(深度优先遍历的起点),则 x 是割点当且仅当搜索树上存在 x 的一个子节点 y,满足:dfn[x] <= low[y]
特别地,若 x 是搜索树的根节点,则 x 是割点当且仅当搜索树上存在至少两个子节点 y1,y2 满足上述条件。
证明方法与割边的情形类似,这里就不再赞述。
因为割点判定法则是小于等于号,所以在求割点时, 不必考虑父节点和重边的问题,从X出发能访问到的所有点的时间戳都可以用来更新 low[x] 。
无向图的双连通分量
若一张无向连通图不存在割点,则称它为“点双连通图”。若一张无向连通图不存在桥,则称它为“边双连通图”。
无向图的极大点双连通子图被称为“点双连通分量”,简记为“v-DCC”。无向连通图的极大边双连通子图被称为“边双连通分量”,简记为“e-DCC”。 二者统称为“双连通分量”,简记为“DCC”。
在上面的定义中,我们称一个双连通子图 G'=(V',E')“极大” (其中 V' 属于 V , E' 属于 E ),是指不存在包含 G' 的更大的子图 G"=(V",E"),满足 V' 属于V"属于 V,E' 属于 P" 属于 E 并且 G" 也是双连通子图。
定理:
一张无向连通图是“点双连通图” ,当且仅当满足下列两个条件之一。
1).图的顶点数不超过2。
2).图中任意两点都同时包含在至少一个简单环中。其中“简单环”指的是不自交的环,也就是我们通常画出的环。
一张无向连通图是“边双连通图” ,当且仅当任意一条边都包含在至少一个简单环中。
证明:
该定理给出了无向连通图是“点双连通图”或“边双连通图”的充要条件。我们以“点双连通图”为例进行证明,“边双连通图”的证明类似。
对于顶点数不超过2的情况, 定理显然成立, 下面假设图中顶点数不小于3。先证充分性。若任意两点 x, y 都同时包含在至少一个简单环中,则 x,y 之间至少有两条不相交的路径。无论从图中删除哪个节点,x,y 均能通过两条路径之一相连。故图中不存在割点,是点双连通图。
再证必要性。反证法,假设一张无向连通图是“点双连通图” 并且存在两点 x,y,它们不同时处于任何一个简单环中。
如果 x,y 之间仅存在1条简单路径,那么路径上至少有一个割点,与“点双连通”矛盾。
如果 x,y 之间存在2条或2条以上的简单路径,那么容易发现,任意两条都至少有一个除x,y之外的交点:进一步可推导出, x,y之间的所有路径必定同时交于除 x,y 之外的某一点 p (不然就会存在两条没有交点的路径,形成一个简单环)
根据定义,p是一个割点,与“点双连通”矛盾。故假设不成立。证毕。
边双连通分量(e-DCC)的求法:
边双连通分量的计算非常容易。只需求出无向图中所有的桥,把桥都删除后,无向图会分成若干个连通块,每一个连通块就是一个“边双连通分量”。
在具体的程序实现中, 一般先用Tarjan算法标记出所有的桥边。然后,再对整个无向图执行一次深度优先遍历(遍历的过程中不访问桥边),划分出每个连通块。下面的代码在Taran求桥的参考程序基础上,计算出数组c,c[X]表示节点 x 所属的“边双连通分量”的编号。
e-DCC的缩点:
缩点:将一个强连通分量缩成一个点。
把每个 e-DCC 看作一个节点,把桥边 (x,y) 看作连接编号为 c[x] 和 c[y] 的 e-DCC 对应节点的无向边,会产生一棵树(若原来的无向图不连,则产生森林)。这种把 e-DCC 收缩为一个节点的方法就称为“缩点”。下面的代码在Tarjan求桥、求e-DCC的参考程序基础上,把e-DCC缩点,构成一棵新的树(或森林),存储在另一个邻接表中。
有向图的连通性
给定有向图 G=(V,E),若存在 r 属于 V,满足从 r 出发能够到达 V 中所有的点,则称G是一个“流图”(Flow Graph),记为 (G,r),其中 r 称为流图的源点。
与无向图的深度优先通历类似,我们也可以定义“流图”的搜索树和时间戳的概念。
在一个流图(G.r)上从 r 出发进行深度优先遍历,每个点只访问一次。所有发生通归的边 (x,y)(换言之,从 x 到是对 y 的第一次访问)构成一棵以 r 为根的树,我们把它称为流图(G,r)的搜索树。
同时,在深度优先遍历的过程中,按照每个节点第一次被访问的时间顺序,依次给子流图中N个节点1~N的整数标记,该标记被称为时间戳,记为dfn[x]。
流图中的每条有向边(x,y)必然是以下四种之一。
1).树枝边,指搜索树中的边,即x是y的父节点(一种特殊的前向边)。
2).前向边,指搜索树中x是y的祖先节点。
3).后向边,指搜索树中y是x的祖先节点。
4).横叉边,指除了以上三种情况之外的边,它一定满足 dfn[y]<dfn[x] .
给定一张有向图。岩对于图中任意两个节点,y,既存在从x到的路,也存在从y到x的路径,则称该有向图是“强连通图”。
有向图的极大强连通子图被称为“强连通分量” 简记为SCC。 此处“极大”的含义与双连通分量“极大”的含义类似。
Tarjan 算法基于有向图的深度优先遍历,能够在线性时间内求出一张有向图的各个强连通分量。
一个“环” 一定是强连通图。如果既存在从x到y的路径,也存在从y到的那么x,y显然在一个环中。因此,Tarjan算法的基本思路就是对于每个点,尽找到与它一起能构成环的所有节点。
容易发现,前向边”(x,y)没有什么用处,因为搜索树上本来就存在从x到y。“后向边” (x,y) 非常有用,因为它可以和搜索树上从y到x的路径一起构成环。“横叉边” (x,y) 视情况而定,如果从y出发能找到一条路径回到x的祖先节点,那么(x,y)就是有用的。
为了找到通过“后向边”和“横叉边”构成的环,Tarjan 算法在深度优先遍历的同时维护了一个栈。当访问到节点x时,栈中需要保存以下两类节点。
1).搜索树上x的祖先节点,记为集合 anc(x)。
设y属于anc(x)。 若存在后向边(x,y),则(x,y) 与y到x的路径一起形成环。
2).已经访问过, 并且存在一条路径到达 anc(x) 的节点。
设z是一个这样的点,从出发存在一条路径到达y属于anc(x)。 若存在横叉边(x,2), 则(x,z)、z到y的路径、y到x的路径形成一个环。
综上所述,栈中的节点就是能与从x出发的“后向边”和“横叉边”形成环的节点。进而可以引入“追溯值”的概念。
追溯值:
设 subtree(x) 表示流图的搜索树中以x为根的子树。x的追溯值low[x]定义为满足以下条件的节点的最小时间戳。
1).该点在栈中。
2).存在一条从 subtree(x) 出发的有向边, 以该点为终点。
根据定义, Tarjan 算法按照以下步骤计算“追溯值”
1.当节点x第一次被访问时,把x入栈, 初始化low[x]=dfn[x]。
2.扫描从 x出发的每条边(x,y)。
(1)若y没被访问过,则说明(x,y)是树枝边,递归访问y,从回潮之后,
令low[x]=min(low[xl,lowly)。
(2)若y 被访问过并且y在栈中,则令lowlx]= min(lowlxl.dfnly).
3.从x回溯之前,判断是否有lowlx]=dfn[x]。若成立,则不断从栈中弹出节点,直至x出栈。
__________________________________________________________________________
1).树枝边,指搜索树中的边,即x是y的父节点(一种特殊的前向边)。
2).前向边,指搜索树中x是y的祖先节点。
3).后向边,指搜索树中y是x的祖先节点。
4).横叉边,指除了以上三种情况之外的边,它一定满足 dfn[y]<dfn[x] .
如何判断某一点是否在某个强连通分量内:
情况一:存在后向边指向祖先节点。
情况二:先走到横叉边,横叉边再走到祖先节点。
Tarjan算法求强连通分量(SCC):
对每个点定义两个时间戳
dfn[u]表示遍历到u的时间戳
low[u]从u开始走,所能遍历到的最小时间戳是什么
u是其所在的强连通分量的最高点,等价于dfn[u]==low[u]
相关文章:

Tarjan算法学习笔记
目录 无向图的割点与桥 时间戳: 搜索树: 追溯值: 割边判定法则: 割点判定法则: 无向图的双连通分量 定理: 边双连通分量(e-DCC)的求法: e-DCC的缩点: 有向图的连通性 追…...

vue 项目涉及的焦点聚焦、格式化日期、判断是否为对象或数组、判断是否为空、深拷贝、节流、防抖
焦点聚焦 import Vue from vue // 插件对象(必须有 install 方法, 才可以注入到 Vue.use 中) export default {install () {Vue.directive(fofo, {inserted (el) {el el.querySelector(input)el.focus()}})} }格式化日期格式 export const formatDate (time) > {// 将xx…...
软件工程知识梳理6-运行和维护
软件维护需要的工作量很大,大型软件的维护成本高达开发成本的4倍左右。所以,软件工程的主要目的就是要提高软件的可维护性,减少软件维护所需要的工作量,降低软件系统的总成本。 定义:软件已经交付使用之后,…...

docker- php7.4
安装 gd拓展 anzhuanga在Dockerfile里面安装php7.4的GD库 - 知乎 apt update apt install -y libwebp-dev libjpeg-dev libpng-dev libfreetype6-devdocker-php-source extractdocker-php-ext-configure gd \ --with-jpeg/usr/include \ --with-freetype/usr/include/docker-…...

开发一个Android App,在项目中完成添加联系人的功能,通过ContentResolver向系统中添加联系人信息。
实现步骤: (1)添加动态联系人的权限。 (2)创建Activity和布局文件,添加输入框和按钮等控件。 (3)完成添加联系人的功能。 代码文件如下: activity_main.xml文件 <!…...

Flume搭建
压缩包版本:apache-flume-1.9.0-bin.tar 百度盘链接:https://pan.baidu.com/s/1ZhSiePUye9ax7TW5XbfWdw 提取码:ieks 1.解压 tar -zxvf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/ 2. 修改文件名 [rootbigdata1 opt]…...

Web APIs 1 DOM操作
Web APIs 1 引入:const优先Web API 基本认知01 作用和分类02 什么是DOM03 DOM树04 DOM对象 获取DOM对象01 根据CSS选择器获取02 其他获取DOM元素方法 操作元素内容01 innerText 属性02 innerHTML 属性 操作元素属性操作元素的常用属性操作元素的样式属性操作表单元素…...
dvwa,xss反射型lowmedium
xss,反射型,low&&medium low发现xss本地搭建实操 medium作为初学者的我第一次接触比较浅的绕过思路high low 发现xss 本关无过滤 <script>alert(/xss/)</script> //或 <script>confirm(/xss/)</script> //或 <scr…...

从云计算到物联网:虚拟化技术的演变与嵌入式系统的融合
文章目录 一、硬件性能提升:摩尔定律与嵌入式虚拟化二、CPU多核技术:为嵌入式虚拟化提供支持三、业务负载整合:嵌入式虚拟化的核心需求四、降低硬件成本:虚拟化技术的经济效益五、软件重用与移植:虚拟化技术的优势六、…...

linux 文件查看 head 、 cat 、 less 、tail 、grep
查看文件详细信息 stat 文件 cat 》》适合显示小文件【行数比较少】,如果行数较多,屏幕显示不完整(如果虚拟操作,是无法上下键的,或者滚动鼠标的,第三方 xsheel,crt 可以方向键查看…...
)
13.2 Web与Servlet进阶(❤❤)
13.2 Web与Servlet进阶 1. 请求与响应1.1 URL与URI1.2 HTTP请求的结构1. 结构2.后端获取访问工具类型:getHeader().toLowerCase方法1.3 响应的结构1. 结构2. 响应常见状态码3. 后端设置响应参数4. 响应的ContentType作用1.4 请求转发与响应重定向应用1. 请求转发:getRequestDis…...
)
记录解决报错--vue前后端分离,接口401(Unauthorized)
1.场景 前端访问不了后端接口。报错401。 2.解决步骤 ①在页面console.log(111)查看走到代码的位置没有。(走到了,没问题) ②查看vue.config.js配置。这段配置就是vue访问api的url。(没问题) devServer: {port: 80…...
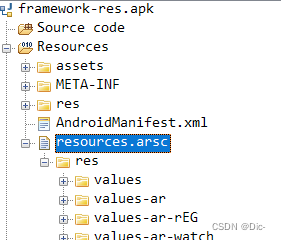
【笔记】Android 常用编译模块和输出产物路径
模块&产物路径 具体编译到软件的路径要看编译规则的分区,代码中模块编译输出的产物基本对应。 Android 代码模块 编译产物路径设备adb路径Comment 模块device/mediatek/system/common/ 资源overlay/telephony/frameworks/base/core 文件举例res/res/values-m…...

部署私有知识库项目FastGPT
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。 项目文档: [快速了解 FastGpt | FastGptFastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即…...

【2024-02-02】华为秋招笔试三道编程题解
恭喜发现宝藏!搜索公众号【TechGuide】回复公司名,解锁更多新鲜好文和互联网大厂的笔经面经。 作者TechGuide【全网同名】 订阅专栏: 【专享版】2024最新大厂笔试真题解析,错过必后悔的宝藏资源! 第一题:找…...
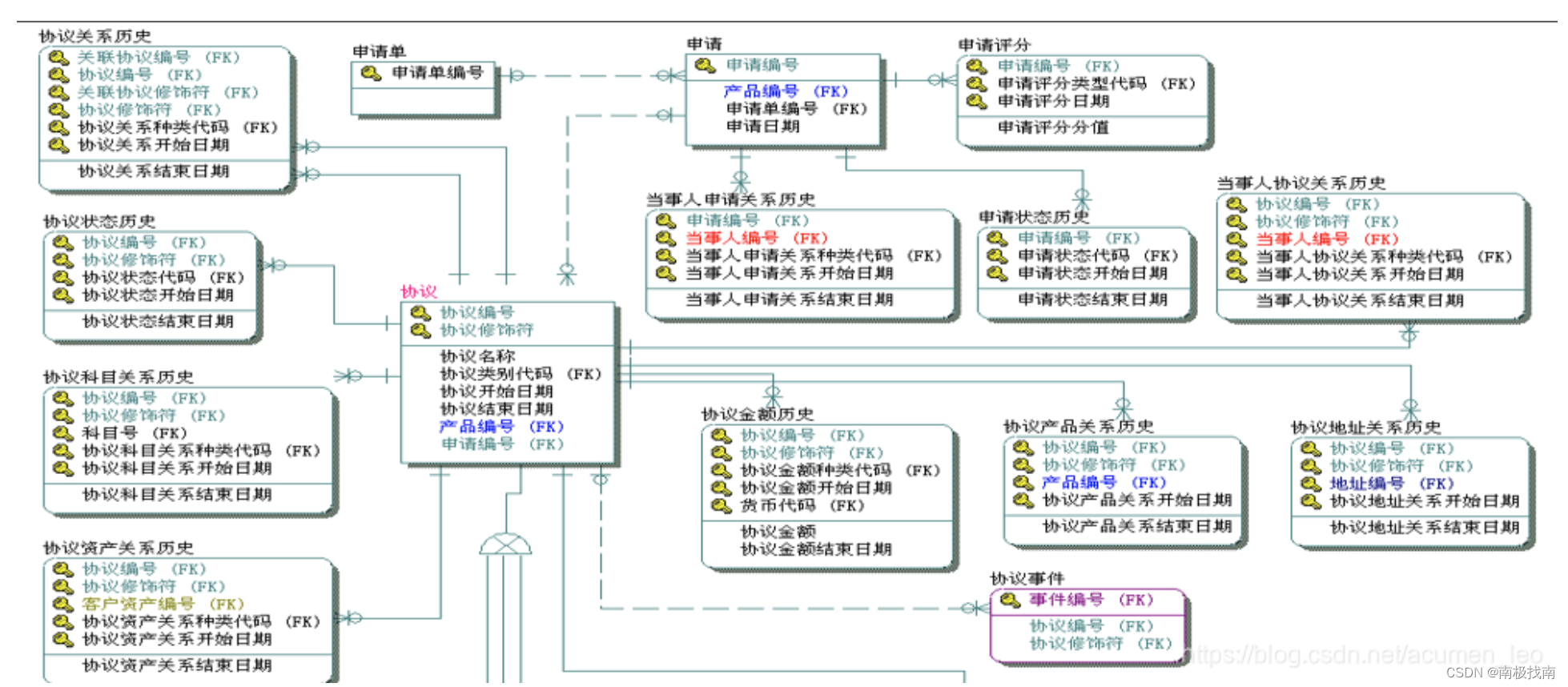
银行数据仓库体系实践(8)--主数据模型设计
主数据区域中保留了数据仓库的所有基础数据及历史数据,是数据仓库中最重要的数据区域之一,那主数据区域中主要分为近源模型区和整合(主题)模型区。上一节讲到了模型的设计流程如下图所示。那近源模型层的设计在第2.3和3这两个步骤…...

vue在main.js中引入三方插件不生效的原因
有的时候需要比较复杂的功能,但是自己实现比较复杂的话,可以引入第三方插件.如果这个第三方插件需要全局都使用的话,可以在main.js中进行引入. 比如router elementplus之类的. import { createApp } from vue import ElementPlus from element-plus import element-plus/dist/…...

chatgpt搭建
chatgpt两步搭建大法 部署docker环境 下载docker curl -fsSL https://get.docker.com -o get-docker.sh安装docker sh get-docker.sh运行docker服务 systemctl start docker查看运行状态 systemctl status docker设置docker开机自启 systemctl enable docker部署chatgpt…...

vue基本理解
1、js闭包,作用?? 闭包是指在一个函数内部,可以访问外部函数的变量,即使外部函数已经执行完毕。闭包的作用有: 保护变量:闭包可以保护函数内部的变量,使其不受外部环境的影响。实现…...
NLP入门系列—Attention 机制
NLP入门系列—Attention 机制 Attention 正在被越来越广泛的得到应用。尤其是 [BERT]火爆了之后。 Attention 到底有什么特别之处?他的原理和本质是什么?Attention都有哪些类型?本文将详细讲解Attention的方方面面。 Attention 的本质是什…...

如何为Token-Flow开源生态贡献代码?从零开始的贡献者指南
Token-Flow正在逐步开源核心组件,目前已有三个仓库接受贡献。本文手把手教你成为贡献者。 一、哪些项目可以贡献? 项目仓库地址技术栈适合人群tf-client (Python SDK)github.com/token-flow/tf-client-pyPython初学者,文档/测试model-adapt…...
与解决方案)
避坑指南:Python调用摄像头常见问题(驱动、权限、多摄像头切换)与解决方案
Python摄像头开发避坑实战:从驱动调试到多设备管理的完整解决方案 当你兴奋地写完了Python摄像头调用代码,按下运行键时,屏幕上却跳出"无法打开视频设备"的错误提示——这种挫败感我太熟悉了。作为经历过无数次摄像头调试折磨的开发…...

终极Ventoy指南:从RAID阵列轻松启动多系统的完整解决方案
终极Ventoy指南:从RAID阵列轻松启动多系统的完整解决方案 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 你是否曾为从复杂的RAID存储阵列启动系统而烦恼?传统方法需要繁琐的BI…...

5步掌握B站高清视频下载:开源工具bilibili-downloader完整指南
5步掌握B站高清视频下载:开源工具bilibili-downloader完整指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为无法…...

新手零基础入门:在快马平台上运行你的第一个yolov8检测程序
今天想和大家分享一个特别适合机器学习新手的实践项目——用yolov8完成第一个目标检测程序。作为刚接触计算机视觉的小白,我最初被各种环境配置和术语搞得晕头转向,直到发现用InsCode(快马)平台可以跳过繁琐的步骤,直接体验模型效果。 为什么…...

Windows下Git 2.43.2安装全攻略:从下载到配置的避坑指南
Windows下Git 2.43.2安装全攻略:从下载到配置的避坑指南 对于Windows开发者而言,Git已经成为版本控制的标准工具。但许多新手在初次安装时,面对密密麻麻的选项和术语常常感到困惑。本文将带你一步步完成Git 2.43.2的安装过程,不仅…...

实战指南:基于快马平台生成trea国际版本地化价格展示组件代码
最近在开发一个国际电商项目时,遇到了一个很实际的需求:需要根据不同地区用户展示本地化格式的商品价格。这个看似简单的功能,其实涉及到货币转换、数字格式化、符号位置等多个细节。经过一番摸索,我总结出了一套比较完整的实现方…...

汇川伺服Modbus通讯踩坑实录:从“通信超时”到“数据错乱”的五个常见故障排查指南
汇川伺服Modbus通讯实战:五大典型故障排查与深度解析 调试现场的温度总是比办公室高几度,尤其是当你面对一台"沉默"的汇川伺服驱动器时。Modbus-RTU协议作为工业自动化领域的"普通话",理论上应该让不同设备间的对话变得…...
从《糖豆人》到《Among Us》:拆解Unity NetCode中NetworkTransform如何塑造不同的联机手感
从《糖豆人》到《Among Us》:NetworkTransform如何定义联机游戏的灵魂手感 当你在《糖豆人》的旋转平台上与对手挤作一团时,那种略带延迟的物理碰撞反馈;或是《Among Us》中看着队友角色突然"瞬移"到另一个房间的诡异同步——这些…...
)
别再用Keil MDK-ARM了?手把手教你用VSCode+GCC搭建STM32F103C8T6开发环境(附标准库模板)
逃离Keil:用VSCodeGCC打造高效STM32开发环境 在嵌入式开发领域,Keil MDK-ARM长期以来都是STM32开发的主流选择。但近年来,越来越多的开发者开始寻求更轻量、更现代化的替代方案。如果你也对Keil的笨重界面、高昂授权费用和有限的定制能力感到…...