C++并发编程 -2.线程间共享数据
本章就以在C++中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。
一. 锁分类和使用
按照用途分为互斥、递归、读写、自旋、条件变量。本章节着重介绍前四种,条件变量后续章节单独介绍。
由于锁无法进行拷贝和转移,通常与包装器进行连用。例如:lock_guard、unique_lock。
| 包装器 | lock_guard | unique_lock | shared_lock |
| 含义 | 作用域内自动获取互斥锁,并在作用域结束时释放锁,以确保资源的安全访问。 | 管理互斥锁的获取和释放,更加灵活,可以指定解锁加锁的时间点 | 允许多个线程同时共享一个互斥锁,以提高并发性能.例如多读一写的场景 |
| 属性 | 不可移动、赋值、拷贝。必须通过构造函数初始化和析构函数销毁 | 能拷贝、赋值、移动,也可通过构造函数初始化和析构函数销毁 | 能拷贝、赋值、移动 |
| 灵活性 | 差 ,不可指定加锁解锁时间点 | 灵活,可随意更改加锁解锁时间点。还可以锁超时、不锁定、条件变量 | 灵活,可随意更改加锁解锁时间点。还可以锁超时、不锁定、条件变量 |
| 性能 | 强 | 差 | 并发,强 |
| 传入参数 | 三者都支持 adopt_lock_t:表示对象在构造的时已经被锁定,会在析构时解锁互斥量,同样用于获取锁之后将锁的所有权转移给包装器对象.
| ||
1.互斥锁
互斥锁(Mutex)是一种用于多线程编程的同步机制,用于保护共享资源的访问。它确保在任何给定时刻只有一个线程可以访问被保护的资源,从而避免数据竞争和不一致的结果。
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>
#include <algorithm>using namespace std;mutex coutMutex;void function(int i)
{thread::id threadId = this_thread::get_id();{lock_guard<mutex> lock(coutMutex);cout<<"my thread id:"<<threadId<<" i:"<<i<<endl;}//锁自动释放使用权
}int main()
{vector<thread> threads;for(int i = 0; i < 30; i++){threads.push_back(thread(function, i));}for_each(threads.begin(), threads.end(), [](thread &t){t.join();});
}
当一个线程获得了互斥锁后,其他线程将被阻塞,直到该线程释放锁。这样可以确保在任何时刻只有一个线程可以执行临界区(对共享资源的访问代码段),从而避免了多个线程同时修改共享资源而导致的问题。
2.递归锁
递归锁(Recursive Lock)是一种特殊类型的互斥锁,它允许同一个线程多次获取锁而不会导致死锁。在多线程环境中,递归锁可以避免同一个线程在递归调用中对同一个资源进行重复加锁而导致的死锁情况。
递归锁内部维护了一个锁计数器,当一个线程第一次获取递归锁时,计数器加1,并且线程可以继续执行临界区代码。当同一个线程再次获取递归锁时,计数器再次加1,而不会被阻塞。只有当线程释放了与获取次数相匹配的锁时,计数器才会递减。只有当计数器为0时,其他线程才能获取该锁。
递归锁的使用场景通常是在一个函数或方法中需要递归调用自身,并且在每次递归调用中需要对共享资源进行加锁保护。递归锁允许同一个线程在递归调用中多次获取锁,确保了对共享资源的安全访问。
#include <iostream>
#include <mutex>std::recursive_mutex myMutex;void foo(int val) {std::lock_guard<std::recursive_mutex> lock(myMutex);// 访问共享资源std::cout << "Value: " << val << std::endl;// 可以递归地再次锁定同一个 mutexif (val > 0) {foo(val - 1);}
}int main() {foo(3);return 0;
} 
3.读写锁
shared_mutex是一种多线程同步机制,用于实现读写锁。它允许多个线程同时访问共享资源,但在写操作期间会独占资源,以确保数据的一致性和完整性。
shared_mutex提供了两种操作:共享访问和独占访问。
在共享访问模式下,多个线程可以同时读取共享资源,而不会互相干扰。这对于读取频繁、写入较少的场景非常有用,可以提高并发性能。
而在独占访问模式下,只有一个线程可以获得对共享资源的写权限,其他线程必须等待写操作完成后才能继续执行。这样可以保证在写操作期间,不会有其他线程读取或写入资源,从而确保数据的一致性。
#include <iostream>
#include <thread>
#include <shared_mutex>
#include <mutex>std::shared_mutex mutex;
int sharedData = 0;void readerThread() {while (true) {std::shared_lock<std::shared_mutex> lock(mutex); // 共享锁定std::cout <<"this thread id:"<<std::this_thread::get_id()<< " Reader Thread: " << sharedData << std::endl;std::this_thread::sleep_for(std::chrono::milliseconds(500));}
}void writerThread() {while (true) {std::unique_lock<std::shared_mutex> lock(mutex); // 独占锁定sharedData++;std::cout << "Writer Thread: " << sharedData << std::endl;std::this_thread::sleep_for(std::chrono::milliseconds(1000));}
}int main() {std::thread reader1(readerThread);std::thread reader2(readerThread);std::thread writer(writerThread);reader1.join();reader2.join();writer.join();while(1)std::this_thread::sleep_for(std::chrono::milliseconds(2000));return 0;
}4.自旋锁
自旋锁是一种基本的同步机制,用于保护共享资源,它使用忙等待的方式来实现线程的同步。当一个线程尝试获取自旋锁时,如果锁已经被其他线程占用,那么该线程会一直在一个循环中自旋等待,直到锁被释放。
优点:1)线程占用锁的时间非常短,短到不值得进行线程上下文切换的开销。
2)不会导致线程阻塞,避免了线程切换的开销。
缺点:自旋等待期间,线程会一直占用CPU资源,如果自旋等待时间过长,会浪费CPU资源
适用场景:
1)线程占用锁的时间非常短,短到不值得进行线程上下文切换的开销。
2)锁的占用时间较短,大部分情况下能够立即获取到锁。
class spinlock_mutex
{spinlock_mutex():spinMutex(ATOMIC_FLAG_INIT){}void lock(){while(spinMutex.test_and_set(std::memory_order_acquire)); //读之前保证变量最新}void unlock(){spinMutex.clear(std::memory_order_release); //写之前保证变量最新}private:std::atomic_flag spinMutex;
};在后续第七章节会结合内存序列进行详细介绍。
二. 死锁的原因
线程1先锁定mutex1,线程2先锁定mutex2.都需要等待对方释放锁权限,造成死锁.如下:
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <chrono>std::mutex mutex1;
std::mutex mutex2;void threadFunction1() {std::unique_lock<std::mutex> lock1(mutex1);std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 延迟一下,以确保线程2也能获取锁std::cout << "Thread 1: Trying to lock mutex2..." << std::endl;std::unique_lock<std::mutex> lock2(mutex2); // 尝试获取mutex2std::cout << "Thread 1: Got both locks!" << std::endl;
}void threadFunction2() {std::unique_lock<std::mutex> lock2(mutex2);std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 延迟一下,以确保线程1也能获取锁std::cout << "Thread 2: Trying to lock mutex1..." << std::endl;std::unique_lock<std::mutex> lock1(mutex1); // 尝试获取mutex1std::cout << "Thread 2: Got both locks!" << std::endl;
}int main() {std::thread t1(threadFunction1);std::thread t2(threadFunction2);t1.join();t2.join();return 0;
}三. 如何避免死锁
1.使用固定顺序加锁解锁
基于第二节造成死锁的原因,可以在需要加锁的期间按照相同顺序加锁解锁,如下改动:
void threadFunction1() {std::unique_lock<std::mutex> lock1(mutex1);std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 延迟一下,以确保线程2也能获取锁std::cout << "Thread 1: Locked mutex1, trying to lock mutex2..." << std::endl;std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 增加延迟,增加死锁的可能性{std::unique_lock<std::mutex> lock2(mutex2); // 尝试获取mutex2std::cout << "Thread 1: Got both locks!" << std::endl;}
}void threadFunction2() {std::unique_lock<std::mutex> lock1(mutex1);std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 延迟一下,以确保线程1也能获取锁std::cout << "Thread 2: Locked mutex1, trying to lock mutex2..." << std::endl;std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 增加延迟,增加死锁的可能性{std::unique_lock<std::mutex> lock2(mutex2); // 尝试获取mutex2std::cout << "Thread 2: Got both locks!" << std::endl;}
}适用场景:适用于需要对多个互斥锁进行加锁且对性能要求不高的场景,并且需要确保以相同的顺序对这些锁进行加锁。
优点:实现相对简单,不需要复杂的算法和数据结构。只需要定义好资源的顺序即可。
缺点:固定顺序加锁解锁可能会降低系统的灵活性,由于多个线程都按照顺序等待锁的占用释放,可能会对系统的性能产生一定的影响。
2.使用超时锁
超时锁(Timeout Lock)是一种在多线程编程中常用的技术,用于在一段时间内尝试获取锁,如果超过指定的时间仍未成功获取锁,则放弃获取锁并执行相应的处理逻辑。
#include <iostream>
#include <mutex>
#include <condition_variable>
#include <chrono>std::mutex mtx;
std::condition_variable cv;
bool isLocked = false;bool tryLockFor(int milliseconds) {std::unique_lock<std::mutex> lock(mtx);auto timeout = std::chrono::system_clock::now() + std::chrono::milliseconds(milliseconds);while (isLocked) {if (cv.wait_until(lock, timeout) == std::cv_status::timeout) {return false; // 超时未获取到锁}}isLocked = true;return true; // 成功获取到锁
}void unlock() {std::lock_guard<std::mutex> lock(mtx);isLocked = false;cv.notify_one();
}int main() {std::cout << "Trying to acquire lock..." << std::endl;if (tryLockFor(2000)) {std::cout << "Have already locked, write data" << std::endl;unlock();} else {std::cout << "Failed to acquire lock within the timeout." << std::endl;}return 0;
}
适用并发访问共享数据结构:多个线程同时访问共享的数据结构(如链表、队列等)时,超时锁可以避免数据结构的破坏和不一致。
3.使用锁的层级结构
在一个复杂的多线程程序中,可能存在多个共享资源,每个资源都需要使用一个独立的锁进行保护。当多个线程需要同时访问多个资源时,为了避免死锁,需要按照一定的顺序获取这些锁。锁的层级结构可以通过定义锁的获取和释放顺序来实现。
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <stack>
#include <chrono>
#include <condition_variable>
#include <mutex>
#include <stdexcept>
#include <climits>
#include <chrono>class hierarchical_mutex
{std::mutex internal_mutex;unsigned long const hierarchy_value;unsigned long previous_hierarchy_value;static thread_local unsigned long this_thread_hierarchy_value;void check_for_hierarchy_violation(){if(this_thread_hierarchy_value <= hierarchy_value){throw std::logic_error("mutex hierarchy violated");}}void update_hierarchy_value(int value){previous_hierarchy_value=this_thread_hierarchy_value;this_thread_hierarchy_value=hierarchy_value;std::cout<<"update_hierarchy_value "<<"previous_hierarchy_value "<<previous_hierarchy_value<<std::endl;std::cout<<"update_hierarchy_value "<<"this_thread_hierarchy_value "<<this_thread_hierarchy_value<<std::endl;std::cout<<"value:"<<value<<std::endl;}
public:explicit hierarchical_mutex(unsigned long value):hierarchy_value(value),previous_hierarchy_value(0){}void lock(int value){std::cout<<"lock:"<<value<<std::endl;check_for_hierarchy_violation();internal_mutex.lock();update_hierarchy_value(value);}void unlock(int value){std::cout<<"unlock:"<<value<<std::endl;this_thread_hierarchy_value=previous_hierarchy_value;internal_mutex.unlock();}bool try_lock(int value){check_for_hierarchy_violation();if(!internal_mutex.try_lock()) //锁被占用,返回falsereturn false;update_hierarchy_value(value);return true;}
};/*函数声明为thread_local,使得每个线程都有其拷贝的副本,线程中的该变量独立互不影响*/
thread_local unsigned longhierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX); //最大值hierarchical_mutex m1(42);
hierarchical_mutex m2(2000);void thread_function1() {// 线程1尝试获取 m1(层级值为42)锁m1.lock(1);std::cout << "Thread 1 acquired m1 lock." << std::endl;// 在持有 m1 锁的情况下,线程1尝试获取 m2(层级值为2000)锁m2.lock(1);std::cout << "Thread 1 acquired m2 lock." << std::endl;// 这里可以执行一些线程1的工作// 释放锁时必须按相反的顺序释放m2.unlock(1);m1.unlock(1);
}void thread_function2() {// 线程2尝试获取 m2(层级值为2000)锁m2.lock(2);std::cout << "Thread 2 acquired m2 lock." << std::endl;// 在持有 m2 锁的情况下,线程2尝试获取 m1(层级值为42)锁,这将导致层级违规m1.lock(2); // 这里将引发 std::logic_error 异常std::cout << "Thread 2 acquired m1 lock." << std::endl;// 这里可以执行一些线程2的工作// 释放锁时必须按相反的顺序释放m1.unlock(2);m2.unlock(2);
}int main() {std::thread t1(thread_function1);std::thread t2(thread_function2);t1.join();t2.join();return 0;
}运行结果:
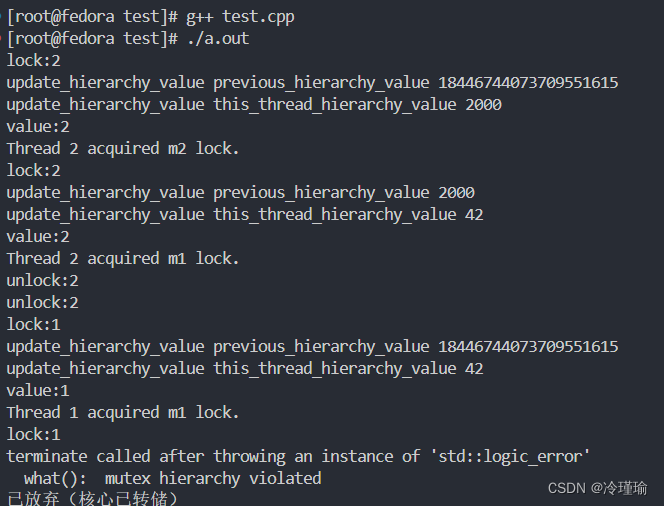
分析:
- 线程1运行 m1.lock(1);进行低层次枷锁,同时线程2运行 m2.lock(2);进行高层次加锁。
- 此时线程1运行到m2.lock(1);,准备进行低层次加锁
- 发现之前已经被加过锁了,锁是高层次锁。因此抛出异常。 通过这种方式避免嵌套锁导致死锁的发生
4.转移锁的所有权
转移锁的所有权是指将一个互斥锁(mutex)从一个线程转移到另一个线程,使得新的线程可以继续使用该锁。
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <stack>
#include <chrono>
#include <condition_variable>
#include <mutex>std::mutex some_mutex;void prepare_data(){std::cout<<"prepare_data"<<std::endl;}
void do_something(){std::cout<<"do_something"<<std::endl;}std::unique_lock<std::mutex> get_lock()
{extern std::mutex some_mutex;std::unique_lock<std::mutex> lk(some_mutex);prepare_data();return lk; // 1
}void process_data()
{std::unique_lock<std::mutex> lk(get_lock()); // 2do_something();
}int main()
{std::unique_lock<std::mutex> main_lock(get_lock()); // 获取互斥量所有权std::cout << "Main thread is doing something..." << std::endl;// 在进入 process_data 函数之前释放互斥量的所有权main_lock.unlock();// 在 process_data 函数中获取互斥量的所有权process_data();// 在 process_data 函数返回后重新获取互斥量的所有权main_lock.lock();return 0;
}优点:
减少锁的竞争:当一个线程完成了对共享资源的操作后,可以将锁的所有权转移到下一个需要访问共享资源的线程,避免了其他线程之间的锁竞争,提高了并发性能。
减少上下文切换:转移锁的所有权可以避免线程在释放锁后重新竞争锁的过程,从而减少了不必要的上下文切换,提高了系统的响应性能。
缺点:转移锁的所有权需要额外的代码来管理锁的状态和转移过程,增加了代码的复杂性和维护成本。
四. 粗锁和细锁适用差别
锁的粒度是指在并发编程中,锁定共享资源的范围大小,锁的粒度对程序性能有着重要的影响。
较粗粒度的锁会锁定较大范围的共享资源,这意味着在并发访问时,只有一个线程能够访问该资源,其他线程需要等待。这种情况下,锁的争用会增加,可能导致线程间的竞争和等待时间增加,从而降低程序的性能。相反,较细粒度的锁会锁定较小范围的共享资源,这意味着并发访问时,多个线程可以同时访问不同的资源,减少了锁的争用。这种情况下,线程间的竞争和等待时间减少,从而提高了程序的性能。
通常情况下,应该尽量使用细粒度的锁,以最大程度地减少锁的争用,提高并发性能。但是,过细的锁粒度也可能导致锁的开销增加,因此需要在实际应用中进行权衡和测试,找到合适的锁粒度
以下展示适用一种粗锁提升性能的场景:
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>std::mutex mtx; // 全局互斥量
int counter = 0;void increment() {auto start = std::chrono::high_resolution_clock::now(); // 记录开始时间for (int i = 0; i < 1000000; ++i) {mtx.lock(); // 细粒度锁counter++;mtx.unlock(); // 细粒度锁}auto end = std::chrono::high_resolution_clock::now(); // 记录结束时间auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); // 计算运行时间std::cout << "Increment thread duration: " << duration.count() << " milliseconds" << std::endl;
}void decrement() {auto start = std::chrono::high_resolution_clock::now(); // 记录开始时间mtx.lock(); // 粗粒度锁for (int i = 0; i < 1000000; ++i) {counter--;}mtx.unlock(); // 粗粒度锁auto end = std::chrono::high_resolution_clock::now(); // 记录结束时间auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); // 计算运行时间std::cout << "Decrement thread duration: " << duration.count() << " milliseconds" << std::endl;
}int main() {std::thread t1(increment);std::thread t2(decrement);t1.join();t2.join();std::cout << "Counter: " << counter << std::endl;return 0;
}测量多次结果:

五. 构建线程安全的栈
1.异常发生在接口处
有时候我们可以将对共享数据的访问和修改聚合到一个函数,在函数内加锁保证数据的安全性。但是对于读取类型的操作,即使读取函数是线程安全的,但是返回值抛给外边使用,存在不安全性。比如一个栈对象,我们要保证其在多线程访问的时候是安全的,可以在判断栈是否为空,判断操作内部我们可以加锁,但是判断结束后返回值就不在加锁了,就会存在线程安全问题。
比如我定义了如下栈, 对于多线程访问时判断栈是否为空,此后两个线程同时出栈,可能会造成崩溃,因为两个线程运行顺序可能如下:

template<typename T>
class threadsafe_stack1
{
private:std::stack<T> data;mutable std::mutex m;
public:threadsafe_stack1() {}threadsafe_stack1(const threadsafe_stack1& other){std::lock_guard<std::mutex> lock(other.m);data = other.data;}threadsafe_stack1& operator=(const threadsafe_stack1&) = delete;void push(T new_value){std::lock_guard<std::mutex> lock(m);data.push(std::move(new_value));}T pop(){std::lock_guard<std::mutex> lock(m);auto element = data.top();data.pop();return element;}bool empty() const{std::lock_guard<std::mutex> lock(m);return data.empty();}
};线程1和线程2先后判断栈都不为空,之后执行出栈操作,可能会造成崩溃。
void test_threadsafe_stack1() {threadsafe_stack1<int> safe_stack;safe_stack.push(1);std::thread t1([&safe_stack]() {if (!safe_stack.empty()) {std::this_thread::sleep_for(std::chrono::seconds(1));safe_stack.pop();}});std::thread t2([&safe_stack]() {if (!safe_stack.empty()) {std::this_thread::sleep_for(std::chrono::seconds(1));safe_stack.pop();}});t1.join();t2.join();
}针对可能造成栈区异常,可以适当抛出异常来提醒。例如定义一个空栈函数,代码优化如下:
struct empty_stack : std::exception
{const char* what() const throw();
};
T pop()
{std::lock_guard<std::mutex> lock(m);if (data.empty()) throw empty_stack();auto element = data.top();data.pop();return element;
}2.异常发生在栈分配
但是现在仍然还有可能存在问题,假设有一个stack<vector<int>>,vector是一个动态容器,当你拷贝一个vetcor,标准库会从堆上分配很多内存来完成这次拷贝。当这个系统处在重度负荷,或有严重的资源限制的情况下,这种内存分配就会失败,所以vector的拷贝构造函数可能会抛出一个std::bad_alloc异常。当vector中存有大量元素时,这种情况发生的可能性更大。当pop()函数返回“弹出值”时(也就是从栈中将这个值移除),会有一个潜在的问题:这个值被返回到调用函数的时候,栈才被改变;但当拷贝数据的时候,调用函数抛出一个异常会怎么样? 如果事情真的发生了,要弹出的数据将会丢失;它的确从栈上移出了,但是拷贝失败了!
3.避免竞争方法
3.1 传入引用使得操作原子化
void pop(T& value){std::lock_guard<std::mutex> lock(m);if(data.empty()) throw empty_stack();value=data.top();data.pop();}既然要传入引用, 大部分情况下需要临时构造出一个堆中类型的实例,用于接收目标值。从时间和资源的角度上来看都不划算
3.2 返回弹出元素的指针
std::shared_ptr<T> pop()
{std::lock_guard<std::mutex> lock(m);if(data.empty()) throw empty_stack();std::shared_ptr<T> const res(std::make_shared<T>(data.top()));data.pop();return res;
} 直接pop出智能指针类型,这样在pop函数内部减少了数据的拷贝,防止内存溢出,其实这做法确实是相比之前直接pop固定类型的值更节省内存,运行效率也好很多。
六. 保护共享数据的初始化过程
1.早期局部静态的问题
当一个函数中定义一个局部静态变量,那么这个局部静态变量只会初始化一次,就是在这个函数第一次调用的时候,以后无论调用几次这个函数,函数内的局部静态变量都不再初始化。
那我们可以利用局部静态变量这一特点实现单例. 在C++11 以前存在多线程不安全的情况,编译器可能会初始化多个静态变量。但是C++11推出以后,各厂商优化编译器,能保证线程安全。所以为了保证运行安全请确保使用C++11以上的标准。
2.延迟初始化
下述示例中,延时系统资源初始化过程,存在这样一个问题:在多线程情况下,可能同时满足if(!resource_ptr)条件导致数据多次重复初始化,为了解决这一问题,使用 双重检查锁定模式。
std::shared_ptr<some_resource> resource_ptr;
void foo()
{if(!resource_ptr){resource_ptr.reset(new some_resource); // 1}resource_ptr->do_something();
}
3.双重检查锁定模式
在下述锁中,先判断资源是否被初始化,如果为被初始化,则通过2步骤加锁,使得别的线程无法进行资源初始化,然后再次进行判断,防止等锁期间资源进行被初始化。
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;void foo()
{if(!resource_ptr){std::lock_guard<std::mutex> lock(resource_mutex); // 2 if(!resource_ptr){resource_ptr.reset(new some_resource); // 3}}resource_ptr->do_something();
}但是双重锁定也存在潜在问题:
在双重锁定模式中,一个线程可能在第一个条件判断中检查到 resource_ptr 为null,并认为资源尚未初始化。然后,在另一个线程中,资源被成功初始化(操作③),但这个修改可能仅存在于初始化线程的缓存中,尚未同步到主内存。 因此,第一个线程可能无法看到这个修改,仍然认为资源没有初始化, 调用 do_something() 的问题:如果第一个线程继续调用 do_something()(操作④),它可能会使用一个尚未初始化的资源,这会导致不正确的结果。 这是因为第一个线程无法正确看到第二个线程对 some_resource 实例的修改。
4.使用once_flag+call_once确保初数据竞争
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag;void initialize_resource()
{resource_ptr.reset(new some_resource);
}void foo()
{std::call_once(resource_flag, initialize_resource);resource_ptr->do_something();
} 引入了一个std::once_flag对象resource_flag,用于标记资源是否已经被初始化。initialize_resource函数用于实际初始化资源。在foo函数中,使用std::call_once来保证initialize_resource函数只会被调用一次。这样就可以避免多个线程同时初始化资源的问题,从而实现线程安全。
5.静态局部实例
相对于call_once,使用静态局部变量来保证第一次调用初始化,保证线程安全。
优点:直观+开销小+不依赖标准库+移植性强
#include <iostream>
#include <mutex>
#include <thread>class Singleton {
public:static Singleton& getInstance() {if (instance == nullptr) {std::lock_guard<std::mutex> lock(mutex); // 加锁if (instance == nullptr) {instance = new Singleton();}}return *instance;}private:Singleton() { std::cout << "Singleton" << std::endl; } // 构造函数私有化,确保不能直接实例化static Singleton* instance;static std::mutex mutex;
};Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mutex;int main() {std::thread t1([](){Singleton& s1 = Singleton::getInstance();std::cout << "Thread 1: " << &s1 << std::endl;});std::thread t2([](){Singleton& s2 = Singleton::getInstance();std::cout << "Thread 2: " << &s2 << std::endl;});t1.join();t2.join();return 0;
}静态局部实例和静态全局实例区别:
静态局部实例:静态局部变量是在函数内部声明的静态变量,它们的初始化只会在第一次进入包含它们的函数时进行,然后在程序的生命周期内保持其状态。这是因为编译器会生成代码来确保只在第一次进入函数时初始化它们,而后续调用不会再次初始化。
静态全局实例:静态全局变量是在全局作用域内声明的静态变量,它们的初始化在程序启动时进行,由C++运行时系统管理。在多线程环境中,如果多个线程同时访问静态全局变量,可能会导致竞争条件,从而导致多次初始化。
相关文章:
C++并发编程 -2.线程间共享数据
本章就以在C中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。 一. 锁分类和使用 按照用途分为互斥、递归、读写、自旋、条件变量。本章节着重介绍前四种,条件变量后续章节单独介绍。 由于锁无法进行拷贝…...
Kubernetes-资源清单
一、k8s中的资源 什么是资源清单 我们跟kubernetes集群进行交互的时候,我们需要给K8S集群传输数据,传输信息,K8S才能按照我们的要求来运行,这个传输的文件,基本上都会通过资源清单进行传递。资源清单是我们跟集群进行…...

ABAP 笔记--内表结构不一致,无法更新数据库MODIFY和UPDATE
目录 ABAP 笔记内表结构不一致,无法更新数据库MODIFY和UPDATE ABAP 笔记 内表结构不一致,无法更新数据库 MODIFY和UPDATE 如果是使用MODIFY或者UPDATE...
机器学习-3降低损失(Reducing Loss)
机器学习-3降低损失(Reducing Loss) 学习内容来自:谷歌ai学习 https://developers.google.cn/machine-learning/crash-course/framing/check-your-understanding?hlzh-cn 本文作为学习记录1.降低损失:迭代方法 迭代学习 下图展示了机器学习算法用于训…...
-高精度-减-高精度)
蓝桥杯备战(AcWing算法基础课)-高精度-减-高精度
目录 前言 1 题目描述 2 分析 2.1 第一步 2.2 第二步 3 代码 前言 详细的代码里面有自己的理解注释 1 题目描述 给定两个正整数(不含前导 00),计算它们的差,计算结果可能为负数。 输入格式 共两行,每行包含一…...
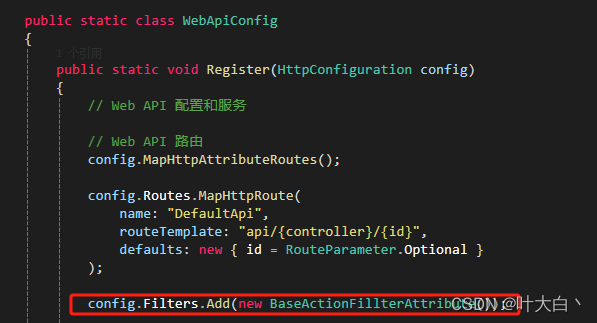
AspNet web api 和mvc 过滤器差异
最近在维护老项目。定义个拦截器记录接口日志。但是发现不生效 最后发现因为继承的 ApiController不是Controller 只能用 System.Web.Http下的拦截器生效。所以现在总结归纳一下 Web Api: System.Web.Http.Filters.ActionFilterAttribute 继承该类 Mvc: System.Web.Mvc.Ac…...
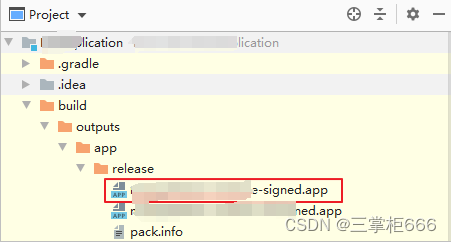
HarmonyOS应用/服务发布:打造多设备生态的关键一步
目前 前言HarmonyOS 应用/服务发布的重要性使用HarmonyOS 构建跨设备的应用生态前期准备工作简述发布流程生成签名文件配置签名信息编译构建.app文件上架.app文件到AGC结束语 前言 随着智能设备的快速普及和多样化,以及编程语言的迅猛发展,构建一个无缝…...
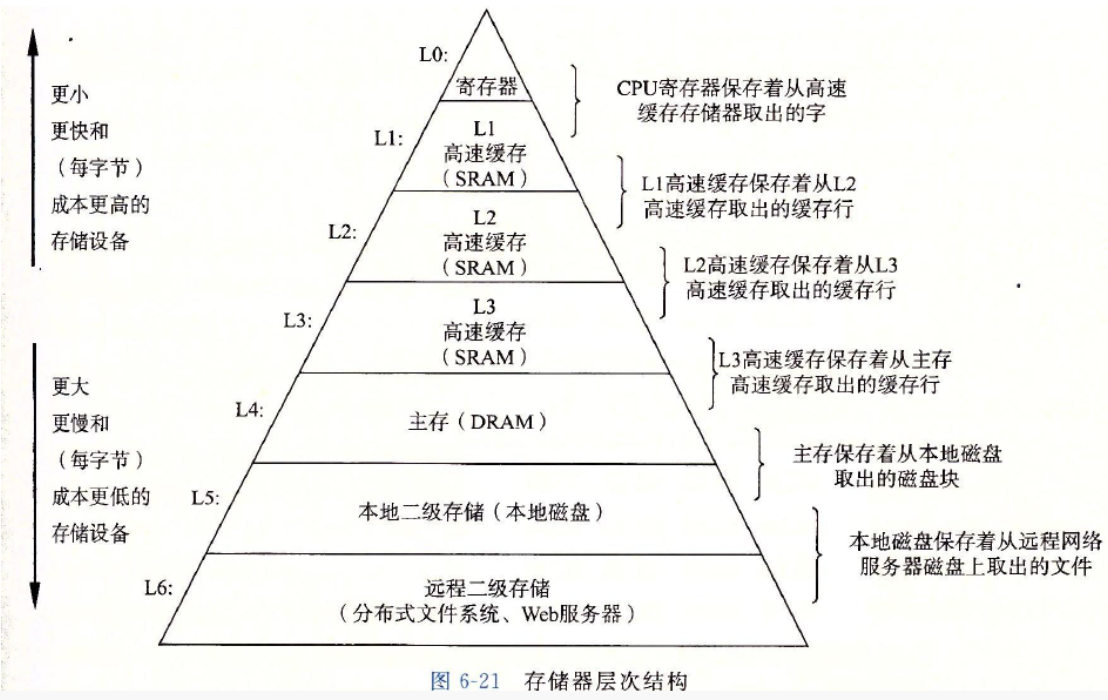
【数据结构】双向带头循环链表实现及总结
简单不先于复杂,而是在复杂之后。 文章目录 1. 双向带头循环链表的实现2. 顺序表和链表的区别 1. 双向带头循环链表的实现 List.h #pragma once #include <stdio.h> #include <assert.h> #include <stdlib.h> #include <stdbool.h>typede…...
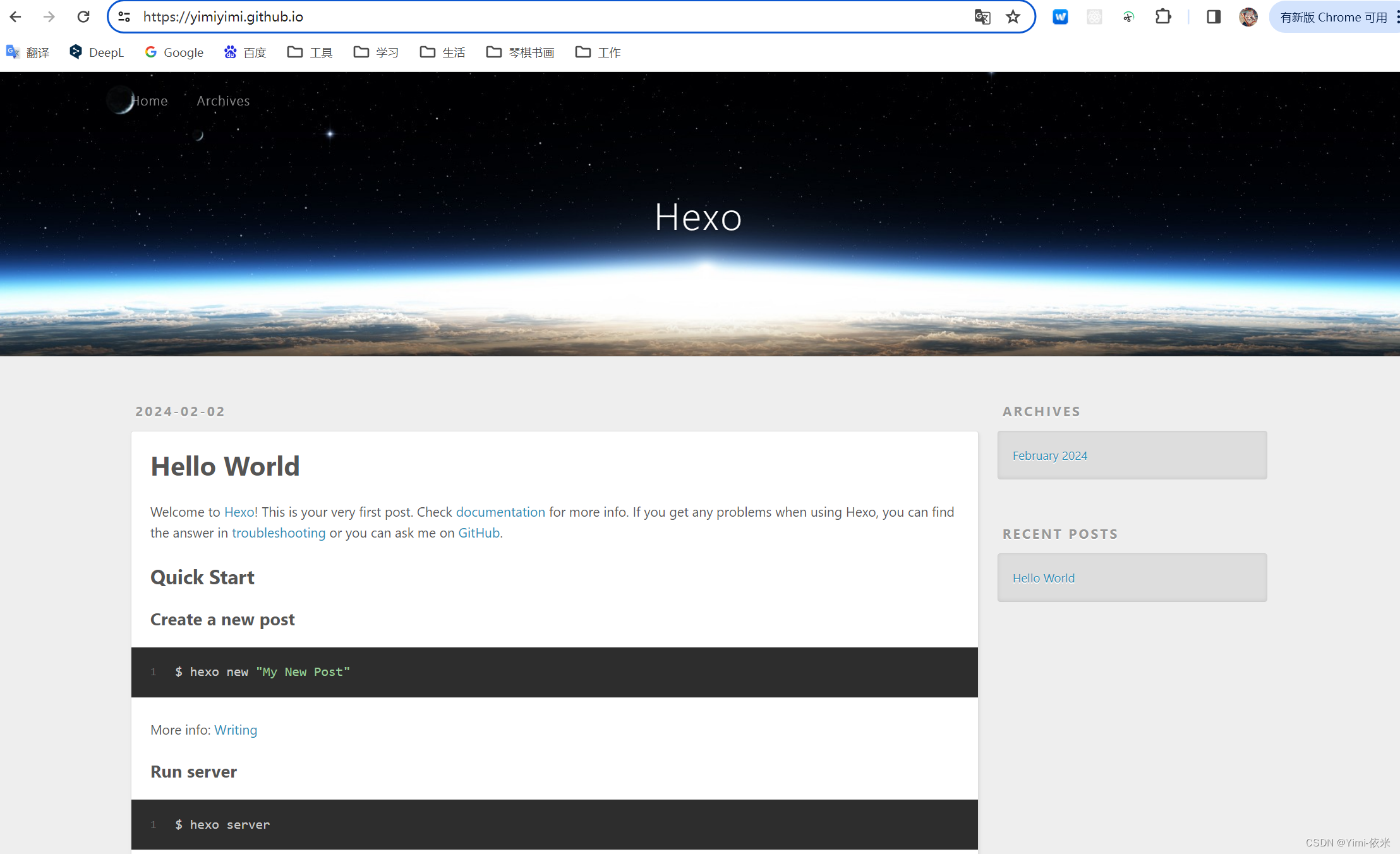
创建自己的Hexo博客
目录 一、Github新建仓库二、支持环境安装Git安装Node.js安装Hexo安装 三、博客本地运行本地hexo文件初始化本地启动Hexo服务 四、博客与Github绑定建立SSH密钥,并将公钥配置到github配置Hexo与Github的联系检查github链接访问hexo生成的博客 一、Github新建仓库 登…...
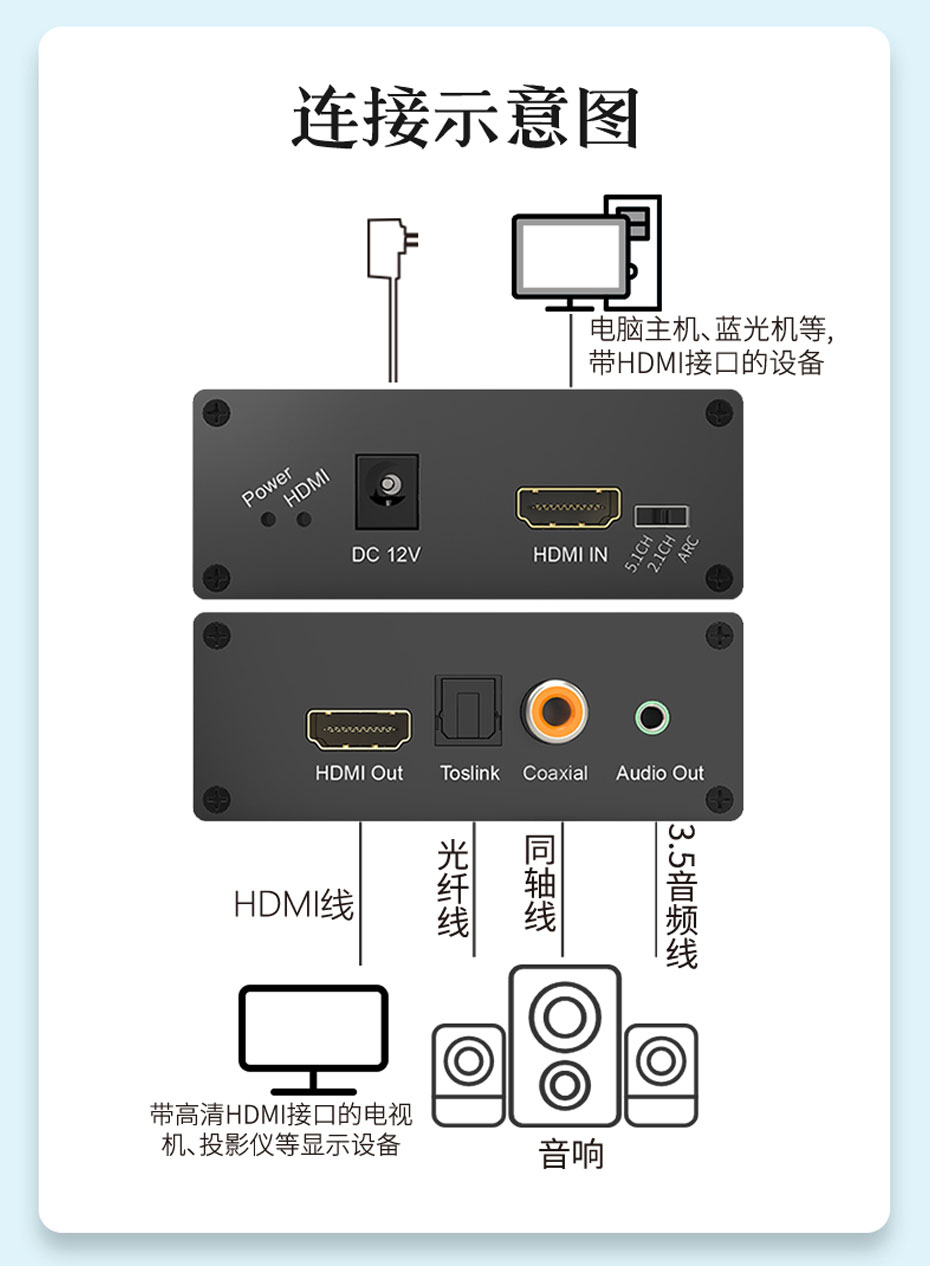
音箱、功放播放HDMI音频解决方案之HDMI音频分离器HHA
HDMI音频分离器HHA简介 HDMI音频分离器HHA具有一路HDMI信号输入,转换成一路HDMI信号、一路5.1光纤音频信号、一路5.1 SPDIF/同轴音频信号和一路模拟左右声道立体声信号输出,同时还支持EDID存储及兼容HDCP功能;分辨率最高支持1920*1080p&#…...
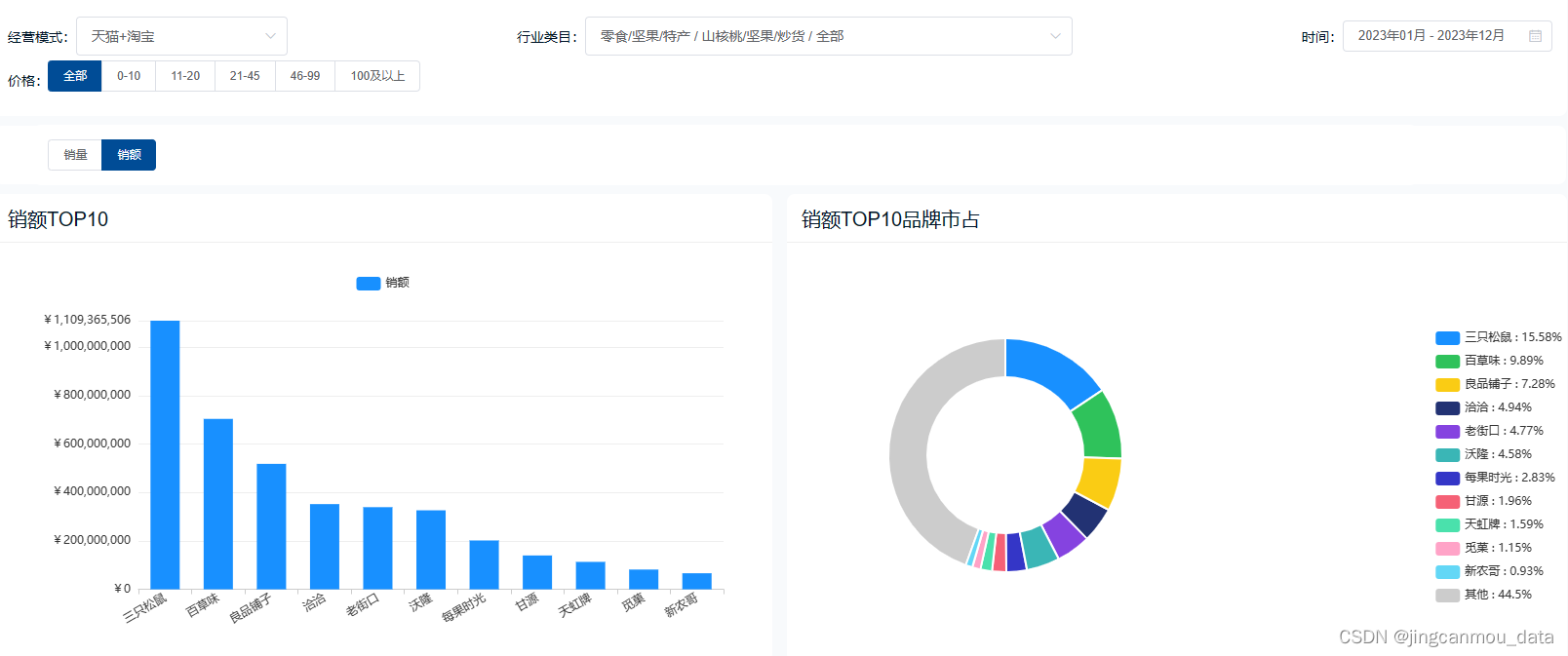
天猫数据分析:2023年坚果炒货市场年销额超71亿,混合坚果成多数消费者首选
近年来,随着人们生活水平和健康意识的提升,在休闲零食市场中,消费者们也越来越关注食品的营养价值,消费者这一消费偏好的转变也为坚果炒货食品行业带来了发展契机。 整体来看,坚果炒货市场的体量较大。根据鲸参谋电商…...
YouTrack 用户登录提示 JIRA 错误
就算输入正确的用户名和密码,我们也得到了下面的错误信息: youtrack Cannot retrieve JIRA user profile details. 解决办法 出现这个问题是因为 YouTrack 在当前的系统重有 JIRA 的导入关联。 需要把这个导入关联取消掉。 找到后台配置的导入关联&a…...

题目 1163: 排队买票
题目描述: 有M个小孩到公园玩,门票是1元。其中N个小孩带的钱为1元,K个小孩带的钱为2元。售票员没有零钱,问这些小孩共有多少种排队方法,使得售票员总能找得开零钱。注意:两个拿一元零钱的小孩,他们的位置互…...
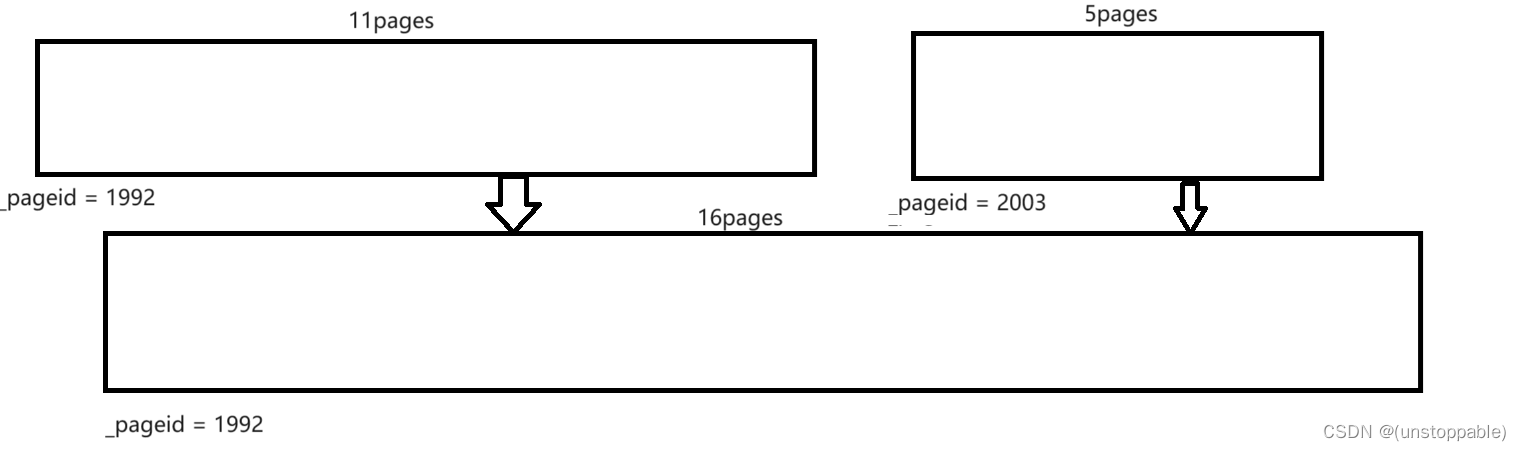
【lesson9】高并发内存池Page Cache层释放内存的实现
文章目录 Page Cache层释放内存的流程Page Cache层释放内存的实现 Page Cache层释放内存的流程 如果central cache释放回一个span,则依次寻找span的前后page id的没有在使用的空闲span,看是否可以合并,如果合并继续向前寻找。这样就可以将切…...

Java基础面试题-6day
I/O流基础知识总结 (1) io即输入输出流, 如何区分输入还是输入流 以内存为中介,当我们是将数据存储到内存即为输入,反之存储到外部存储器,即为输出 在Java中分输入输出流,根据数据处理又可以分…...
--RAC工作原理和相关组件)
【Oracle 集群】RAC知识图文详细教程(三)--RAC工作原理和相关组件
RAC 工作原理和相关组件 OracleRAC 是多个单实例在配置意义上的扩展,实现由两个或者多个节点(实例)使用一个共同的共享数据库(例如,一个数据库同时安装多个实例并打开)。在这种情况下,每一个单独…...

二级C语言笔试2
(总分100,考试时间90分钟) 一、选择题 下列各题A)、B)、C)、D)四个选项中,只有一个选项是正确的。 1. 下列叙述中正确的是( )。 A) 算法的效率只与问题的规模有关,而与数据的存储结构无关 B) 算法的时间复杂度是指执行算法所需要的计算工作量 …...
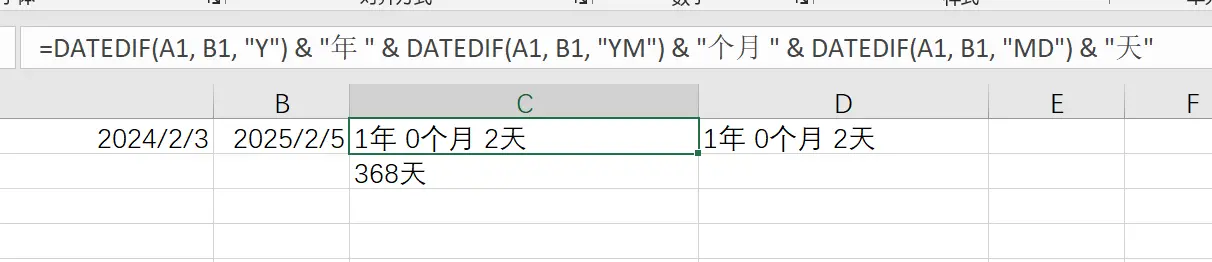
如何计算两个指定日期相差几年几月几日
一、题目要求 假定给出两个日期,让你计算两个日期之间相差多少年,多少月,多少天,应该如何操作呢? 本文提供网页、ChatGPT法、VBA法和Python法等四种不同的解法。 二、解决办法 1. 网页计算法 这种方法是利用网站给…...

再识C语言 DAY13 【递归函数(超详细)】
文章目录 前言一、函数递归什么是递归递归的两个重要条件练习一练习二 递归与迭代练习三练习四在练习三、四中出现的问题 如果您发现文章有错误请与我留言,感谢 前言 本文总结于此文章 一、函数递归 什么是递归 函数调用自身的编程技巧称为递归 (函数自…...

【Linux】权限管理
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《C》 《Linux》 《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 文章目录 一 、Linux中的用户1.1 Linux用户分类1.2 用户转换1.3 指令提权 二、Linux权限管…...

DENSO电装机器人软件授权序列号 wincaps3软件授权和软件安装包及软件手册
DENSO电装机器人软件授权序列号 wincaps3软件授权和软件安装包及软件手册 永久使用序列号 给机器人工程师的WinCaps3安装避坑指南 最近在调试DENSO机械臂的时候,发现不少同行在WinCaps3的安装和授权环节翻车。今天就结合自己的踩坑经验,聊聊怎么搞定这个…...
)
Tacview自定义模型全攻略:从3D建模到实战应用(附F-500案例文件)
Tacview自定义模型全攻略:从3D建模到实战应用(附F-500案例文件) 当你在Tacview中看到那些精准还原的飞行器轨迹时,有没有想过如何将自己的3D模型融入这个强大的分析工具?本文将带你从零开始,完整掌握Tacvie…...

Yii2的EVENT_BEFORE_ACTION的本质的庖丁解牛
yii\base\Controller::EVENT_BEFORE_ACTION 是 Yii2 框架中 AOP(面向切面编程) 的核心锚点,也是 MVC 流程中的“安检门”。 它的本质是:在具体的业务逻辑(Action)执行之前,提供的一个“拦截、验…...

用快马平台五分钟搭建countif函数交互演示原型,告别枯燥文档
最近在帮同事做Excel培训时,发现很多人对countif函数的使用总是一知半解。传统的文档说明太抽象,于是我尝试用InsCode(快马)平台快速搭建了一个交互式演示工具,效果出乎意料的好。整个过程只用了不到5分钟,完全不需要操心环境配置…...

如何用5步告别Mac菜单栏混乱?Ice帮你打造高效工作空间
如何用5步告别Mac菜单栏混乱?Ice帮你打造高效工作空间 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 你是否曾因Mac菜单栏上密密麻麻的图标而感到焦虑?随着工作时间的推移&a…...

intv_ai_mk11新手教程:3步完成提示词输入→参数调整→结果查看
intv_ai_mk11新手教程:3步完成提示词输入→参数调整→结果查看 1. 快速了解intv_ai_mk11 intv_ai_mk11是一个基于Llama架构的文本生成模型,特别适合日常的问答、内容改写和简短创作。它就像一位随时待命的文字助手,能帮你快速完成各种文字工…...

避坑指南:海康RGBD工业相机Python开发那些事儿——从环境配置到实时显示
避坑指南:海康RGBD工业相机Python开发全流程实战 第一次接触海康RGBD相机时,我被它强大的深度感知能力吸引,但随之而来的是一连串的环境配置和开发难题。记得那个深夜,我对着报错的OpenCV界面发呆,才意识到工业级设备的…...

别再死记硬背了!用sklearn的LogisticRegression搞定手写数字识别,附完整代码与参数调优心得
逻辑回归实战:从参数困惑到手写数字识别调优指南 当你第一次面对sklearn的LogisticRegression那十几个参数时,是否感到无从下手?特别是当官方文档用专业术语解释solver、C、max_iter时,大多数教程只会告诉你"照这样设置就行&…...

Path of Building PoE2:流放之路2终极角色规划器完整指南
Path of Building PoE2:流放之路2终极角色规划器完整指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 还在为《流放之路2》复杂的角色构建而头疼吗?每次天赋加点都犹豫不决&am…...

终极存储设备容量检测指南:3分钟识别假冒U盘和SD卡
终极存储设备容量检测指南:3分钟识别假冒U盘和SD卡 【免费下载链接】f3 F3 - Fight Flash Fraud 项目地址: https://gitcode.com/gh_mirrors/f3/f3 在数字时代,存储设备容量造假已成为普遍问题,许多用户购买的大容量U盘、SD卡和移动硬…...