从头开始构建和训练 Transformer(上)
1、导 读
2017 年,Google 研究团队发表了一篇名为《Attention Is All You Need》的论文,提出了 Transformer 架构,是机器学习,特别是深度学习和自然语言处理领域的范式转变。
Transformer 具有并行处理功能,可以实现更高效、可扩展的模型,从而更容易在大型数据集上训练它们。它还在情感分析和文本生成任务等多项 NLP 任务中表现出了卓越的性能。
在本笔记本中,我们将探索 Transformer 架构及其所有组件。我将使用 PyTorch 构建所有必要的结构和块,并且我将在 PyTorch 上使用从头开始编Transformer。
# 导入库# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torch.utils.tensorboard import SummaryWriter # Math
import math # HuggingFace 库
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers .models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers.pre_tokenizers import Whitespace # Pathlib
from pathlib import Path # Typing
from Typing import Any # 循环中进度条的库
from tqdm import tqdm # 导入警告库
import warnings2、Transformer 架构
在编码之前,我们先看一下Transformer的架构。
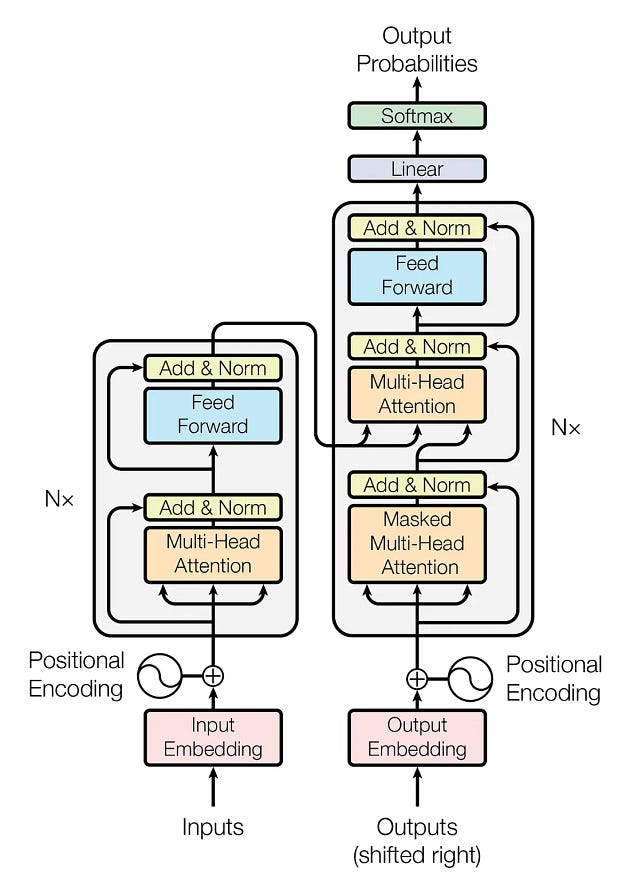
Transformer 架构有两个主要模块:编码器和解码器。让我们进一步看看它们。
编码器:它具有多头注意力机制和全连接的前馈网络。两个子层周围还有残差连接,以及每个子层输出的层归一化。模型中的所有子层和嵌入层都会产生维度 𝑑_𝑚𝑜𝑑𝑒𝑙=512 的输出。
解码器:解码器遵循类似的结构,但它插入了第三个子层,该子层对编码器块的输出执行多头关注。解码器块中的自注意子层也进行了修改,以避免位置关注后续位置。这种掩蔽确保位置 𝑖 的预测仅取决于小于𝑖 的位置处的已知输出。
编码器和解码块都重复 𝑁 次。在原始论文中,他们定义了𝑁 = 6,我们将在本笔记本中定义类似的值。
3、输入嵌入
当我们观察上面的 Transformer 架构图像时,我们可以看到嵌入代表了两个块的第一步。
下面的类InputEmbedding负责将输入文本转换为d_model维度的数值向量。为了防止我们的输入嵌入变得非常小,我们通过将它们乘以 √𝑑_𝑚𝑜𝑑𝑒𝑙 来对其进行标准化。
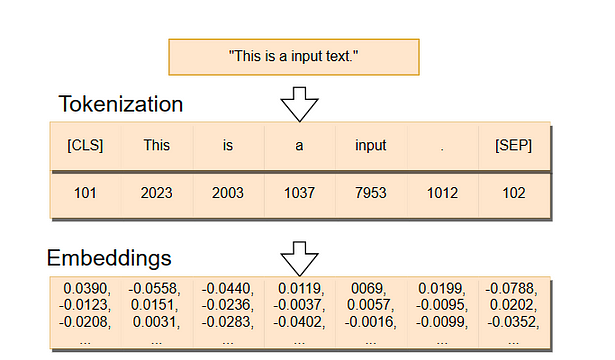
在下图中,我们可以看到嵌入是如何创建的。首先,我们有一个被分成标记的句子——我们稍后将探讨标记是什么——。然后,令牌 ID(识别号)被转换为嵌入,即高维向量。
class InputEmbeddings(nn.Module):def __init__(self, d_model: int, vocab_size: int):super().__init__()self.d_model = d_model # Dimension of vectors (512)self.vocab_size = vocab_size # Size of the vocabularyself.embedding = nn.Embedding(vocab_size, d_model) # PyTorch layer that converts integer indices to dense embeddingsdef forward(self, x):return self.embedding(x) * math.sqrt(self.d_model) # Normalizing the variance of the embeddings4、位置编码
在原始论文中,作者将位置编码添加到编码器和解码器块底部的输入嵌入中,以便模型可以获得有关序列中标记的相对或绝对位置的一些信息。位置编码与嵌入具有相同的维度𝑑_模型,因此可以将两个向量相加,并且我们可以将来自单词嵌入的语义内容和来自位置编码的位置信息结合起来。
下面我们将创建一个尺寸为 的PositionalEncoding位置编码矩阵。我们首先用0填充它。然后,我们将正弦函数应用于位置编码矩阵的偶数索引,而余弦函数应用于奇数索引。pe(seq_len, d_model)
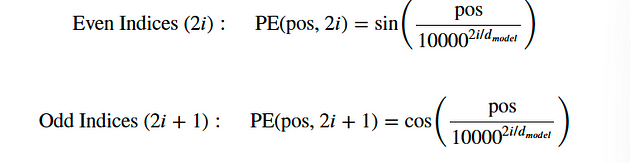
我们应用正弦和余弦函数,因为它允许模型根据序列中其他单词的位置来确定单词的位置,因为对于任何固定偏移量𝑃𝐸ₚₒₛ ₊ ₖ可以表示为𝑃𝐸ₚₒₛ 的线性函数。发生这种情况是由于正弦和余弦函数的特性,其中输入的变化会导致输出发生可预测的变化。
class PositionalEncoding(nn.Module):def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:super().__init__()self.d_model = d_model # Dimensionality of the modelself.seq_len = seq_len # Maximum sequence lengthself.dropout = nn.Dropout(dropout) # Dropout layer to prevent overfitting# Creating a positional encoding matrix of shape (seq_len, d_model) filled with zerospe = torch.zeros(seq_len, d_model) # Creating a tensor representing positions (0 to seq_len - 1)position = torch.arange(0, seq_len, dtype = torch.float).unsqueeze(1) # Transforming 'position' into a 2D tensor['seq_len, 1']# Creating the division term for the positional encoding formuladiv_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))# Apply sine to even indices in pepe[:, 0::2] = torch.sin(position * div_term)# Apply cosine to odd indices in pepe[:, 1::2] = torch.cos(position * div_term)# Adding an extra dimension at the beginning of pe matrix for batch handlingpe = pe.unsqueeze(0)# Registering 'pe' as buffer. Buffer is a tensor not considered as a model parameterself.register_buffer('pe', pe) def forward(self,x):# Addind positional encoding to the input tensor Xx = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)return self.dropout(x) # Dropout for regularization5、层归一化
当我们查看编码器和解码器块时,我们会看到几个称为Add & Norm的归一化层。
下面的类LayerNormalization对输入数据执行层归一化。在前向传播过程中,我们计算输入数据的平均值和标准差。然后,我们通过减去平均值并除以标准差加上一个称为epsilon的小数来标准化输入数据,以避免被零除。此过程会产生平均值为 0、标准差为 1 的标准化输出。
然后,我们将通过可学习参数缩放标准化输出alpha,并添加一个名为 的可学习参数bias。训练过程负责调整这些参数。最终结果是层归一化张量,它确保网络中各层的输入规模一致。
# Creating Layer Normalization
class LayerNormalization(nn.Module):def __init__(self, eps: float = 10**-6) -> None: # We define epsilon as 0.000001 to avoid division by zerosuper().__init__()self.eps = eps# We define alpha as a trainable parameter and initialize it with onesself.alpha = nn.Parameter(torch.ones(1)) # One-dimensional tensor that will be used to scale the input data# We define bias as a trainable parameter and initialize it with zerosself.bias = nn.Parameter(torch.zeros(1)) # One-dimensional tenso that will be added to the input datadef forward(self, x):mean = x.mean(dim = -1, keepdim = True) # Computing the mean of the input data. Keeping the number of dimensions unchangedstd = x.std(dim = -1, keepdim = True) # Computing the standard deviation of the input data. Keeping the number of dimensions unchanged# Returning the normalized inputreturn self.alpha * (x-mean) / (std + self.eps) + self.bias6、前馈网络
在全连接前馈网络中,我们应用两个线性变换,并在其间使用 ReLU 激活。我们可以用数学方式将该操作表示为:
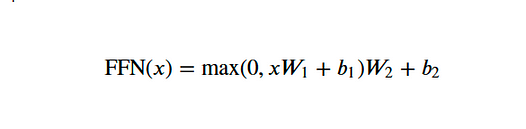
W1 和W2 是权重,而b1 和b2 是两个线性变换的偏差。
下面FeedForwardBlock,我们将定义两个线性变换 -self.linear_1和self.linear_2- 以及内层d_ff。输入数据将首先经过self.linear_1转换,将其维度从d_model增加到d_ff。
此操作的输出通过 ReLU 激活函数,该函数引入了非线性,因此网络可以学习更复杂的模式,并且该self.dropout层用于减轻过度拟合。最后的操作是self.linear_2转换为 dropout-modified 张量,将其转换回原始d_model维度。
# 创建前馈层
class FeedForwardBlock(nn.Module):def __init__(self, d_model: int, d_ff: int, dropout: float) -> None:super().__init__()# 第一次线性变换self.linear_1 = nn.Linear(d_model, d_ff) # W1 & b1self.dropout = nn.Dropout(dropout) # Dropout to prevent overfitting# 第二次线性变换self.linear_2 = nn.Linear(d_ff, d_model) # W2 & b2def forward(self, x):# (Batch, seq_len, d_model) --> (batch, seq_len, d_ff) -->(batch, seq_len, d_model)return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))7、多头注意力
多头注意力是 Transformer 最关键的组成部分。它负责帮助模型理解数据中的复杂关系和模式。
下图显示了多头注意力机制的工作原理。它不包括batch维度,因为它仅说明一个句子的过程。
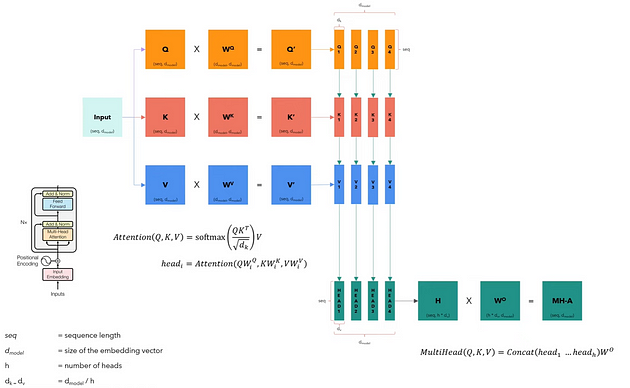
多头注意力模块接收分为查询、键和值的输入数据,并组织成矩阵𝑄、𝐾和𝑉。每个矩阵包含输入的不同方面,并且它们具有与输入相同的维度。
然后,我们通过各自的权重矩阵𝑊^Q、𝑊^K和𝑊^V来对每个矩阵进行线性变换。这些转换将产生新的矩阵𝑄′、𝐾′和𝑉′,它们将被分成与不同头ℎ相对应的更小的矩阵,从而允许模型并行处理来自不同表示子空间的信息。这种分割为每个头创建多组查询、键和值。
最后,我们将每个头连接成一个𝐻矩阵,然后由另一个权重矩阵𝑊𝑜进行转换以产生多头注意力输出,即保留输入维度的矩阵𝑀𝐻−𝐴 。
# 创建多头注意力区块
class MultiHeadAttentionBlock(nn.Module):def __init__(self, d_model: int, h: int, dropout: float) -> None: # h = number of headssuper().__init__()self.d_model = d_modelself.h = h# 我们确保模型的维度可以被头的数量整除assert d_model % h == 0, 'd_model is not divisible by h'# d_k 是每个注意力的维度head 的键、查询和值向量self.d_k = d_model // h # d_k 公式,就像原始的“Attention Is All You Need”论文中一样# 定义权重矩阵self.w_q = nn.Linear(d_model, d_model) # W_qself.w_k = nn.Linear(d_model, d_model) # W_kself.w_v = nn.Linear(d_model, d_model) # W_vself.w_o = nn.Linear(d_model, d_model) # W_oself.dropout = nn.Dropout(dropout) # Dropout 层以避免过度拟合@staticmethoddef attention(query, key, value, mask, dropout: nn.Dropout):# mask => 当我们希望某些单词不与其他单词交互时,我们“隐藏”它们d_k = query.shape[-1] # 查询、键和值的最后一个维度# 我们按照上图中的公式计算 Attention(Q,K,V) attention_scores = (query @ key.transpose(-2,-1)) / math.sqrt(d_k) # @ = Matrix multiplication sign in PyTorch# 在应用 softmax 之前,我们应用掩码来隐藏单词之间的一些交互if mask is not None: # 如果定义了掩码.. .attention_scores.masked_fill_(mask == 0, -1e9) # 将 mask 等于 0 的每个值替换为 -1e9attention_scores = attention_scores.softmax(dim = -1) if dropout is not None: attention_scores = dropout(attention_scores) # 我们使用 dropout 来防止过拟合return (attention_scores @ value), attention_scores # 将输出矩阵乘以 V 矩阵,公式如下def forward(self, q, k, v, mask): query = self.w_q(q) # Q' matrixkey = self.w_k(k) # K' matrixvalue = self.w_v(v) # V' matrix# 将结果拆分为不同头的较小矩阵# 将嵌入(第三维)拆分为 h 个部分query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1,2) # Transpose => 将头部带到第二个维度key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1,2) # Transpose => 将头部带到第二个维度value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1,2) # Transpose => 将头部带到第二个维度# 获取输出和注意力分数x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)# 获取H矩阵x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)return self.w_o(x) # Multiply the H matrix by the weight matrix W_o, resulting in the MH-A matrix8、剩余连接
当我们查看 Transformer 的架构时,我们看到每个子层(包括自注意力和前馈块)在将其传递到Add & Norm层之前将其输出添加到输入。此方法将输出与Add & Norm层中的原始输入集成。这个过程称为跳跃连接,它允许 Transformer 通过为反向传播期间梯度流经提供捷径来更有效地训练深度网络。
下面的类ResidualConnection负责这个过程。
# 构建剩余连接
class ResidualConnection(nn.Module):def __init__(self, dropout: float) -> None:super().__init__()self.dropout = nn.Dropout(dropout) # 我们使用 dropout 层来防止过度拟合self.norm = LayerNormalization() # 我们使用归一化层def forward(self, x, sublayer):# 我们对输入进行归一化并将其添加到原始输入“x”。这将创建剩余连接过程。return x + self.dropout(sublayer(self.norm(x))) 9、编码器
我们现在将构建编码器。我们创建的EncoderBlock类由多头注意力层和前馈层以及残差连接组成。
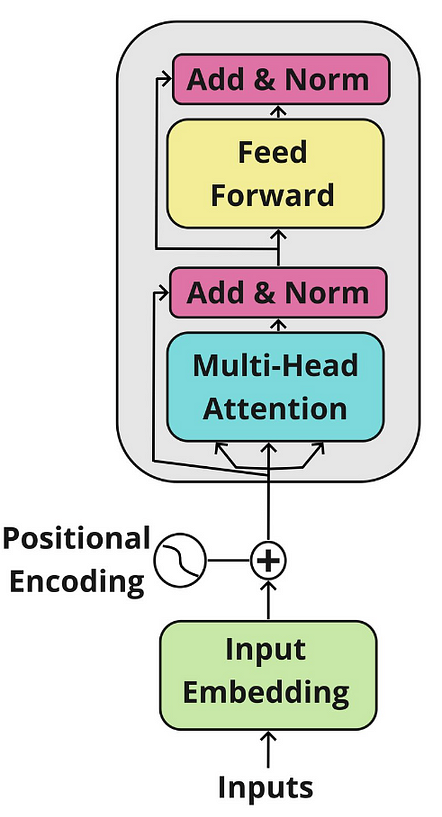
在原始论文中,编码器块重复六次。我们将Encoder类创建为多个 s 的集合EncoderBlock。在通过其所有块处理输入之后,我们还添加层归一化作为最后一步。
# 构建编码器模块
class EncoderBlock(nn.Module):# 该程序块接收多头注意程序块和前馈程序块,以及剩余连接的中断率def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:super().__init__()# 存储自我注意区块和前馈区块self.self_attention_block = self_attention_blockself.feed_forward_block = feed_forward_blockself.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)]) def forward(self, x, src_mask):# 将第一个残余连接应用于自我关注区块x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask)) # 三个 "x "分别对应查询、键和值输入以及源掩码# 将第二个残差连接应用于前馈区块x = self.residual_connections[1](x, self.feed_forward_block)return x # 建设编码器
# 一个编码器可以有多个编码器模块
class Encoder(nn.Module):# 编码器接收 "EncoderBlock "实例def __init__(self, layers: nn.ModuleList) -> None:super().__init__()self.layers = layers # 存储编码器块self.norm = LayerNormalization() # 编码器层输出标准化层def forward(self, x, mask):# 遍历存储在 self.layers 中的每个编码器块for layer in self.layers:x = layer(x, mask) # 对输入张量 "x "应用每个编码器块return self.norm(x) 10、解码器
类似地,Decoder 也由几个 DecoderBlock 组成,在原论文中重复了六次。主要区别在于它有一个额外的子层,该子层通过交叉注意组件执行多头注意,该交叉注意组件使用编码器的输出作为其键和值,同时使用解码器的输入作为查询。
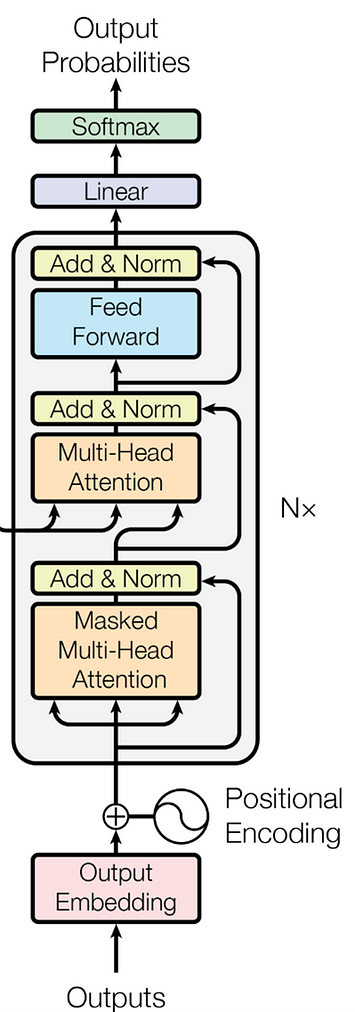
对于输出嵌入,我们可以使用InputEmbeddings与编码器相同的类。您还可以注意到,自注意力子层被屏蔽,这限制了模型访问序列中的未来元素。
我们将从构建类开始DecoderBlock,然后构建类Decoder,它将组装多个DecoderBlocks。
# 构建解码器模块
class DecoderBlock(nn.Module):# 解码器模块接收两个多头注意力模块。一个是自注意,另一个是交叉注意。def __init__(self, self_attention_block: MultiHeadAttentionBlock, cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:super().__init__()self.self_attention_block = self_attention_blockself.cross_attention_block = cross_attention_blockself.feed_forward_block = feed_forward_blockself.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)]) def forward(self, x, encoder_output, src_mask, tgt_mask):# 包含查询、关键字和值以及目标语言掩码的自关注块x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))# 交叉注意代码块使用两个 "encoder_ouput "来输入键和值,再加上源语言掩码。它还接收用于解码器查询的'x'。x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output, encoder_output, src_mask))# 带有残余连接的前馈区块x = self.residual_connections[2](x, self.feed_forward_block)return x# 构建解码器
# 一个解码器可以有多个解码块
class Decoder(nn.Module):# 解码器接收 "DecoderBlock "的实例def __init__(self, layers: nn.ModuleList) -> None:super().__init__()self.layers = layersself.norm = LayerNormalization() def forward(self, x, encoder_output, src_mask, tgt_mask):for layer in self.layers:x = layer(x, encoder_output, src_mask, tgt_mask)return self.norm(x)可以在解码器图像中看到,在运行一堆DecoderBlocks 后,我们有一个线性层和一个 Softmax 函数来输出概率。下面的类ProjectionLayer负责将模型的输出转换为词汇表上的概率分布,其中我们从可能的标记词汇表中选择每个输出标记。
# 建立线性层
class ProjectionLayer(nn.Module):def __init__(self, d_model: int, vocab_size: int) -> None: super().__init__()self.proj = nn.Linear(d_model, vocab_size) def forward(self, x):return torch.log_softmax(self.proj(x), dim = -1) 11、构建Transformer
现在可以通过将它们放在一起来构建 Transformer。
# 创建 Transformer 结构
class Transformer(nn.Module):def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbeddings, tgt_embed: InputEmbeddings, src_pos: PositionalEncoding, tgt_pos: PositionalEncoding, projection_layer: ProjectionLayer) -> None:super().__init__()self.encoder = encoderself.decoder = decoderself.src_embed = src_embedself.tgt_embed = tgt_embedself.src_pos = src_posself.tgt_pos = tgt_posself.projection_layer = projection_layer# Encoder def encode(self, src, src_mask):src = self.src_embed(src) # Applying source embeddings to the input source languagesrc = self.src_pos(src) # Applying source positional encoding to the source embeddingsreturn self.encoder(src, src_mask) # Returning the source embeddings plus a source mask to prevent attention to certain elements# Decoderdef decode(self, encoder_output, src_mask, tgt, tgt_mask):tgt = self.tgt_embed(tgt) # Applying target embeddings to the input target language (tgt)tgt = self.tgt_pos(tgt) # Applying target positional encoding to the target embeddingsreturn self.decoder(tgt, encoder_output, src_mask, tgt_mask)def project(self, x):return self.projection_layer(x)我们现在定义一个名为 的函数,在其中定义参数以及为机器翻译build_transformer任务建立一个完全可操作的 Transformer 模型所需的一切。
我们将设置与原始论文Attention Is All You Need中相同的参数,其中𝑑_𝑚𝑜𝑑𝑒𝑙 = 512、𝑁 = 6、ℎ = 8、dropout 率𝑃_𝑑𝑟𝑜𝑝 = 0.1和𝑑_𝑓𝑓= 2048 .
12、分词器
标记化是我们 Transformer 模型的关键预处理步骤。在此步骤中,我们将原始文本转换为模型可以处理的数字格式。
有多种代币化策略。我们将使用单词级标记化将句子中的每个单词转换为标记。

对句子进行分词后,我们根据分词器训练期间训练语料库中存在的创建词汇将每个分词映射到唯一的整数 ID。每个整数代表词汇表中的一个特定单词。
除了训练语料库中的单词外,Transformer 还使用特殊标记来实现特定目的。我们将立即定义以下一些内容:
• [UNK]:该标记用于识别序列中的未知单词。
• [PAD]:填充标记以确保批次中的所有序列具有相同的长度,因此我们用此标记填充较短的句子。我们使用注意力掩码“告诉”模型在训练期间忽略填充的标记,因为它们对任务没有任何实际意义。
• [SOS]:这是一个用于表示句子开始的标记。
• [EOS]:这是一个用于表示句子结束的标记。
在build_tokenizer下面的函数中,我们确保标记器已准备好训练模型。它检查是否存在现有的分词器,如果不存在,则训练新的分词器。
def build_tokenizer(config, ds, lang):tokenizer_path = Path(config['tokenizer_file'].format(lang))if not Path.exists(tokenizer_path): tokenizer = Tokenizer(WordLevel(unk_token = '[UNK]')) # Initializing a new world-level tokenizertokenizer.pre_tokenizer = Whitespace() # We will split the text into tokens based on whitespacetrainer = WordLevelTrainer(special_tokens = ["[UNK]", "[PAD]", "[SOS]", "[EOS]"], min_frequency = 2) tokenizer.train_from_iterator(get_all_sentences(ds, lang), trainer = trainer)tokenizer.save(str(tokenizer_path)) # Saving trained tokenizer to the file path specified at the beginning of the functionelse:tokenizer = Tokenizer.from_file(str(tokenizer_path)) # If the tokenizer already exist, we load itreturn tokenizer # Returns the loaded tokenizer or the trained tokenizer相关文章:
从头开始构建和训练 Transformer(上)
1、导 读 2017 年,Google 研究团队发表了一篇名为《Attention Is All You Need》的论文,提出了 Transformer 架构,是机器学习,特别是深度学习和自然语言处理领域的范式转变。 Transformer 具有并行处理功能,可以实现…...
)
JVM-JVM内存结构(一)
程序计数器 Program Counter Register程序计数器(寄存器) 程序计数器在物理层上是通过寄存器实现的 作用:记住下一条jvm指令的执行地址特点 是线程私有的(每个线程都有属于自己的程序计数器)不会存在内存溢出 虚拟机栈 每个线程运行时所需要的内存称为虚拟机栈…...
)
React Emotion 如何优雅的使用样式(一)
简介 Emotion 是一个专为使用 JavaScript 编写 css 样式而设计的库。它提供了强大且可预测的样式组合,以及源映射、标签和测试实用程序等功能为开发人员提供了出色的体验,并且支持字符串和对象样式。 与框架无关的样式应用包 Emotion中提供了一个与框…...
)
1+X运维试题样卷A卷(初级)
云计算A卷 单选题(200分) 1.在OSI模型中,HTTP协议工作在第()层,交换机工作在第()层。(10分) (答案正确:10分) A、7/3 B、7/2 (正确答案) C、6/3 D、6/2 2.Linux有三个查看文件的命令,若希望在查看文件内容过程中可以用光标上下移动来查看文件内容,应使用命令。(10分…...

QT QDialog 中的按钮,如何按下后触发 accepted 消息?
QT 作为跨平台的系统,对话框并没有采用 Windows API 那种模式,通过返回 mrOK、mrCancel 等结果告诉调用方结果,而是采用了 accepted、rejected 等信号确定执行结果。下面介绍几种出发这些信号的方法。 1. 在按钮的 clicked 槽函数中触发 acc…...

seata分布式事务
文章目录 1、分布式事务1.1 事务的ACID原则原子性一致性隔离性持久性 1.2 分布式事务的问题示例代码准备环境1. seata_demo数据库2. 启动nacos seata-demo父工程pom.xml order-servicepom.xmlapplication.ymlOrderApplicationOrderControllerOrderServiceImplAccountClientStor…...

Python HttpServer 之 简单快速搭建本地服务器,并且使用 requests 测试访问下载服务器文件
Python HttpServer 之 搭建本地服务器,并且使用requests访问下载服务器文件测试 目录 Python HttpServer 之 搭建本地服务器,并且使用requests访问下载服务器文件测试...

【Python 实战】---- 实现批量给 pdf 插入 excel 动态生成的印章
1. 需求 想要能否实现批量自动为多个pdf加盖不同六格虚拟章(不改变pdf原有分辨率和文字可识别性);改在pdf首页上方空白位置,一般居中即可;如可由使用者自主选择靠页边距更好,以便部分首页上方有字的文件时人工可微调位置;从上而下,自左往右分别对应 excel 中各个字段;…...

51单片机实验课二
实验任务一: 用C语言设计实现8个led灯左右移动显示效果。具体要求如下: 左移时,8个灯中的奇数位灯依次点亮; 右移时,8个灯中的偶数灯依次点亮; 如此循环往 #include <REGX52.H> void Delay(unsi…...

1-4 动手学深度学习v2-线性回归的简洁实现-笔记
通过使用深度学习框架来简洁地实现 线性回归模型 生成数据集 import numpy as np import torch from torch.utils import data # 从torch.utils中引入一些处理数据的模块 from d2l import torch as d2ltrue_w torch.tensor([2,-3.4]) true_b 4.2 features, labels d2l.syn…...

SQL如何实现数据表行转列、列转行?
SQL行转列、列转行可以帮助我们更方便地处理数据,生成需要的报表和结果集。本文将介绍在SQL中如何实现数据表地行转列、列转行操作,以及实际应用示例。 这里通过表下面三张表进行举例 SQL创建数据库和数据表 数据表示例数据分别如下: data_…...

【React】redux状态管理、react-redux状态管理高级封装模块化
【React】react组件传参、redux状态管理 一、redux全局状态管理1、redux概述2、redux的组成1.1 State-状态1.2 Action-事件1.3 Reducer1.4 Store 3、redux入门案例1.1 前期准备1.2 构建store1.2.1 在src下新建store文件夹1.2.2 在store文件夹下新建index.ts文件1.2.3 在index.t…...

HAProxy 和负载均衡概念简介
简介 HAProxy,全称高可用代理,是一款流行的开源软件 TCP/HTTP 负载均衡器和代理解决方案,可在 Linux、macOS 和 FreeBSD 上运行。它最常见的用途是通过将工作负载分布到多台服务器(例如 Web、应用程序、数据库)上来提…...

【go】ent操作之CRUD与联表查询
文章目录 1 CRUD1.1 创建1.1.1 单条创建1.1.2 批量创建 1.2 查找1.2.1 查询单条 / 条件准确查询1.2.2 查询单条 / 条件模糊查询1.2.3 查询单条 / In1.2.4 查询全部 1.3 更新1.4 删除 2 联表查询2.1 O2M(一对多查询)2.1.1 增加Edge2.1.2 查询方法2.1.2.1 …...

服务器性能监控管理方法及工具
服务器是组织数据中心的主干,无论是优化的用户体验,还是管理良好的资源,服务器都能为您完成所有工作,保持服务器随时可用和可访问对于面向业务的应用程序和服务以最佳水平运行至关重要。 理想的服务器性能需要主动监控物理和虚拟…...

AUTOSAR汽车电子嵌入式编程精讲300篇-基于FPGA和CAN协议2.0B的总线控制器研究与设计
目录 前言 研究现状分析 2 CAN总线协议 2.1 CAN总线基本概念 2.2 物理层...
)
14.1 Ajax与JSON应用(❤❤)
14.1 Ajax与JSON应用 1. Ajax1.1 简介1.2 Ajax使用流程1. 前端创建XMLHttpRequest对象2. 发送Ajax请求3. 处理服务器响应4. 代码2. JSON2.1 简介2.2 JS解析JSON3. Ajax与JSON开发3.1 后端:用Jackson实现JSON序列化输出3.2 前端Ajax处理JSON3.3 Ajax工具...
ffmpeg命令生成器
FFmpeg 快速入门:命令行详解、工具、教程、电子书 – 码中人的博客FFmpeg 是一个强大的命令行工具,可以用来处理音频、视频、字幕等多媒体文件。本文介绍了 FFmpeg 的基本用法、一些常用的命令行参数,以及常用的可视化工具。https://blog.mzh…...

JavaScript基础速成
由于学web时只学了后端,现在到了前后端联调的场景发现看不懂前端代码,于是开始恶补 看了下基础内容发现html和css比较好看懂,但JavaScript比较迷,大概知道组件id绑定事件 下面选取看菜鸟教程补充的JS知识 JS的作用 JS是在html…...

openGauss学习笔记-215 openGauss性能调优-确定性能调优范围-性能日志
文章目录 openGauss学习笔记-215 openGauss性能调优-确定性能调优范围-性能日志215.1 性能日志概述215.2 性能日志收集的配置参数 openGauss学习笔记-215 openGauss性能调优-确定性能调优范围-性能日志 215.1 性能日志概述 性能日志主要关注外部资源的访问性能问题。 性能日…...

Synthelix-Auto-Bot终极指南:10分钟掌握多钱包节点自动化管理
Synthelix-Auto-Bot终极指南:10分钟掌握多钱包节点自动化管理 【免费下载链接】Synthelix-Auto-Bot **Automated tool for managing Synthelix nodes across multiple wallets** 项目地址: https://gitcode.com/gh_mirrors/syn/Synthelix-Auto-Bot Synthelix…...

2026最权威的降重复率工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网AI检测系统会去对文本的语义连贯性展开多维分析,会对文本的句式结构进行多维…...
和线性矩阵不等式(LMI)问题的计算量)
别再怕凸优化!手把手教你估算二阶锥(SOC)和线性矩阵不等式(LMI)问题的计算量
凸优化实战指南:SOC与LMI问题计算量估算的工程化思维 在无线通信系统设计和信号处理算法开发中,工程师们经常需要面对各种优化问题。当论文中那些充满二阶锥(SOC)和线性矩阵不等式(LMI)的数学公式摆在面前…...

如何快速配置Windows三指拖动功能:ThreeFingerDragOnWindows完整指南
如何快速配置Windows三指拖动功能:ThreeFingerDragOnWindows完整指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/Thre…...

效率飙升:借鉴Cherry Studio思路,用快马平台自动化你的前端工作流
最近在尝试优化前端开发流程时,发现Cherry Studio的工作流理念特别值得借鉴——把重复性工作交给工具,让开发者专注创意和核心逻辑。刚好体验了InsCode(快马)平台的AI辅助开发功能,发现它能完美实现这种高效工作模式。下面分享我的实践心得&a…...

FASTDDS-Python 实战:从零构建分布式通信环境
1. 为什么选择Fast DDS-Python? 在物联网和机器人系统中,设备间的实时通信是个硬需求。想象一下,你正在开发一个智能仓储机器人系统,需要让多台机器人在复杂环境中协同工作。这时候,传统的HTTP请求-响应模式就显得力不…...

电商客服外包怎么选|避坑指南[特殊字符]2026 商家必看
做电商绕不开客服外包,但低价陷阱、转包兼职、大促掉链、响应超时、售后甩锅真的太坑了!今天整理一套不踩雷选型攻略,全是行业干货,新手也能直接抄作业👇 🚫先避坑:这些雷区千万别碰 超低价诱惑…...

Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题
Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题 1. 为什么需要智能面试助手 Java开发者求职路上,最头疼的莫过于海量面试题的整理和记忆。传统方式要么依赖网上零散的八股文合集,要么自己手动整理知识点,效率低下且难以…...
)
STC89C52抢答器DIY避坑指南:从万能板焊接调试到常见故障排查(蜂鸣器不响、按键失灵)
STC89C52抢答器DIY避坑指南:从万能板焊接调试到常见故障排查 在电子制作领域,抢答器是一个经典的单片机实践项目。不同于市面上现成的模块化套件,使用万能板手工焊接STC89C52抢答器不仅能深入理解电路原理,更能锻炼实际动手能力。…...

从ET1100迁移到AX58100:我的EtherCAT从站代码需要重写多少?
从ET1100迁移到AX58100:EtherCAT从站代码重构实战指南 当你的产品线需要从百兆升级到千兆EtherCAT网络,或者要支持时间敏感网络(TSN)功能时,从经典的ET1100切换到AX58100几乎是必然选择。但作为经历过完整迁移周期的开发者,我必须…...