解密 ARMS 持续剖析:如何用一个全新视角洞察应用的性能瓶颈?
作者:饶子昊、杨龙
应用复杂度提升,根因定位困难重重
随着软件技术发展迭代,很多企业软件系统也逐步从单体应用向云原生微服务架构演进,一方面让应用实现高并发、易扩展、开发敏捷度高等效果,但另外一方面也让软件应用链路变得越来越长,依赖的各种外部技术越来越多,一些线上问题排查起来变得困难重重。
尽管经过过去十几年的发展,分布式系统与之对应的可观测技术快速演进,在一定程度上解决了很多问题,但有一些问题定位起来仍然很吃力,如下图是几个非常有代表性的线上常见问题:

图 1 CPU 持续性出现波峰
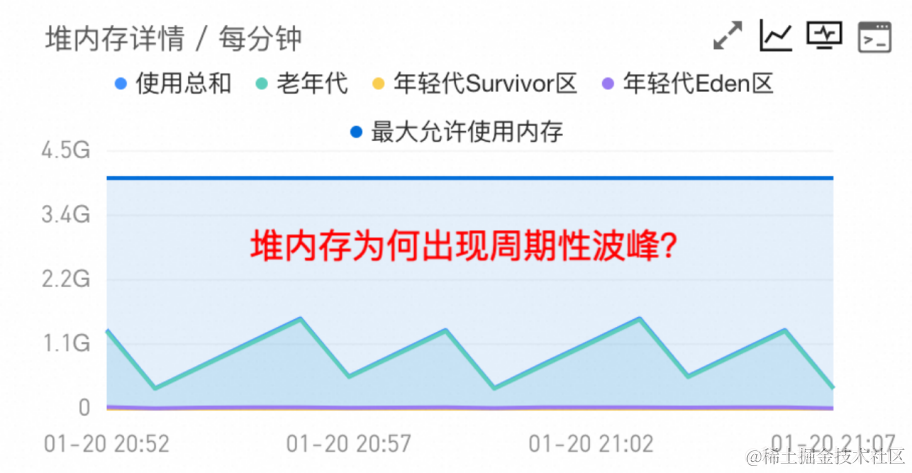
图 2 堆内存空间用在了哪里
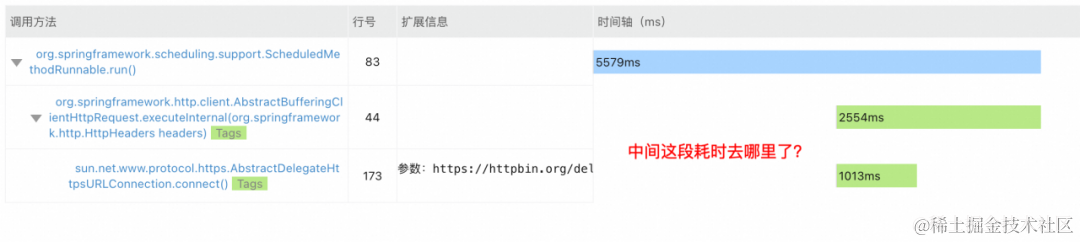
图 3 Trace调用链无法定位到耗时根因
针对上述问题,该如何进行根因定位?
对于一些问题排查经验比较资深,各种排查工具接触比较多的朋友可能会分别针对上述问题想到如下排查定位方法:
-
针对 CPU 波峰诊断,使用 CPU 热点火焰图工具进行问题排查;
-
针对内存问题可通过内存快照来进行内存使用诊断;
-
针对慢调用链诊断过程中出现耗时缺失问题,可以使用 Arthas 提供的 trace 命令进行方法耗时诊断。
上述方案确实有时候可以解决一部分问题,但有过相关问题排查经验的朋友一定也清楚,其分别有各自的使用门槛和局限性,比如:
-
针对测试环境难以复现的线上问题,CPU 热点火焰图工具也无能为力;
-
内存快照不仅对线上应用运行稳定可能有影响,而且需要有比较强的相关工具使用分析经验才可能诊断得出问题来;
-
Arthas 的 trace 命令在慢调用链不是稳定复现难以跟踪情况下问题排查就变得很困难,另外,针对跨多应用,多台机器的调用请求定位过程也非常困难等。
持续剖析,一个全新应用洞察视角
那有没有一种比较简单又高效的强大诊断技术能帮助我们解决上述问题呢?答案就是本文接下来要介绍的持续剖析技术。
持续剖析是什么?
持续剖析(Continuous Profiling)是通过动态实时采集应用程序 CPU/内存等资源申请的堆栈信息,来帮助监测和定位应用程序的性能瓶颈。通过上述介绍,大家对持续剖析的概念是不是还是比较模糊?如果说之前很多朋友没听说过持续剖析,那 JDK 提供的 jstack 打印线程方法栈,定位现程状态这个工具可能有很多朋友在过往排查应用问题的时候或多或少都可能接触过:

图 4 jstack 工具
持续剖析其实思想跟 jstack 类似,它也是以一定频率或者阈值抓取应用线程执行的 CPU、内存等资源申请使用方法栈信息,然后通过一些可视化技术将相关信息呈现出来,让我们能比较直观地洞察到应用相关资源使用情况。说到这里,可能性能分析工具使用比较多的朋友会联想到火焰图:

图 5 火焰图工具
平时在压测过程中,通过手动开启或关闭使用的一次性性能诊断工具如 Arthas CPU 热点火焰图生成工具其实是一类即时剖析技术,它无论从采集数据的方法与数据呈现形式,跟将介绍的持续剖析技术基本无二。相比于持续剖析,最核心的区别在于它是即时而非“持续”的。
有过火焰图使用经验的朋友,大家回忆一下,日常我们使用 CPU 热点火焰图工具一般都是在压测场景,通过一些工具在压测过程中抓取应用一段时间的火焰图做压测性能分析。而持续剖析不仅仅是解决压测场景的性能观测,更重要的是它通过一些技术优化能以低开销的方式,伴随着应用整个运行生命周期,持续地剖析应用的各种资源使用情况,然后通过火焰图或者其他可视化方式为我们呈现出相比可观测技术,更底层更深入的可观测效果。
持续剖析实现原理
说完持续剖析基本概念,大家一定对持续剖析的实现原理有所好奇,接下来简单介绍一些相关实现原理。我们知道 Tracing 通过对关键执行路径上方法埋点采集调用中的信息,来还原调用中参数/返回值/异常/耗时等信息,但业务应用难以穷举所有埋点,另外埋点太多开销也会很大,因此难以完全覆盖全面才会出现上文介绍的图 3 Tracing 监控盲区问题。而持续剖析的实现其实是在更底层对一些资源申请相关 JDK 库关键位置进行埋点或者依赖于操作系统特定事件来实现信息采集,不仅可以实现低开销而且所采集的信息具有更强的洞察力效果。
比如 CPU 热点剖析,其大致思路,通过操作系统底层的系统调用获得 CPU 上执行线程的信息,然后以一定频率(比如 10ms)采集一个线程对应的方法栈信息,1s 中就可以采集 100 个线程方法栈信息,类似下图 6一样,最后将这些方法栈做一些处理,最后再利用一些可视化技术比如火焰图展示出来,就是 CPU 热点剖析结果了。当然上述只是简单说了一些实现原理,不同的剖析引擎以及所需要剖析的对象在技术实现上一般也有些许差异。
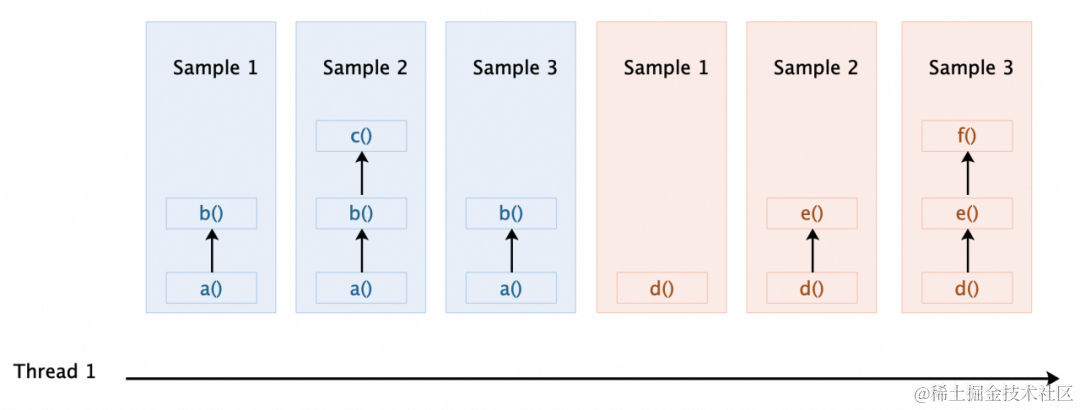
图 6 持续剖析数据采集原理
除了常见的 CPU 热点火焰图剖析,其实对计算机中的各种系统资源的使用和申请,都可通过持续剖析技术提供对应的剖析结果来帮助分析相关资源的申请和实现原理简介(注意,不同的剖析实现技术可能会有差异):
| 功能域 | 剖析类型 | 实现原理简介 |
|---|---|---|
| CPU | CPU耗时 | 以一定频率记录线程在Runnable状态下的方法栈 |
| 内存 | 堆内存分配大小 | 记录线程每个触发堆内存分配阈值时的内存分配大小以及触发时刻的方法栈 |
| 直接内存分配大小 | 记录线程每个触发直接内存分配阈值时的直接内存分配大小以及触发时刻的方法栈 | |
| 堆存活对象分配大小 | 记录线程每个触发堆内存中分配阈值时且尚未被垃圾回收的对象大小以及触发时刻的方法栈 | |
| 耗时 | 墙钟 | 以一定频率记录线程在任意状态下的方法栈 |
| 锁等待耗时 | 线程等待锁资源耗时达到阈值后记录相关耗时及线程对应方法栈 | |
| IO | Socket I/O读写耗时 | 线程等待读写Socket I/O 资源耗时达到阈值后记录相关耗时及线程对应方法栈 |
| Socket I/O读写数据量 | 线程等待读写Socket I/O 数据量达到阈值后记录相关数据量及线程对应方法栈 |
持续剖析可视化技术
之前说了很多关于持续剖析的内容,也提到了火焰图,在持续剖析采集后的数据可视化方面,应用最为广泛的技术之一便是火焰图(Flame Graph)那火焰图又有哪些奥妙之处呢?
什么是火焰图?
火焰图是一种可视化程序性能分析工具,它可以帮助开发人员追踪程序的函数调用以及调用所占用的时间,并且展示出这些信息。其核心思想是将程序的函数调用方法栈转化为一个矩形的 “火焰” 形图像,每个矩形的宽度表示该函数对应资源使用占比,高度表示函数整体的调用深度。通过比较不同时间点的火焰图,可以快速诊断程序的性能瓶颈所在,从而针对性地进行优化。
广义上的火焰图画法分为 2 种,分别是函数方法栈栈底元素在底部,栈顶元素在顶部的狭义火焰图,如下左图所示,以及方法栈栈底元素在顶部,栈顶元素在底部的冰柱状火焰图,如下右图所示。

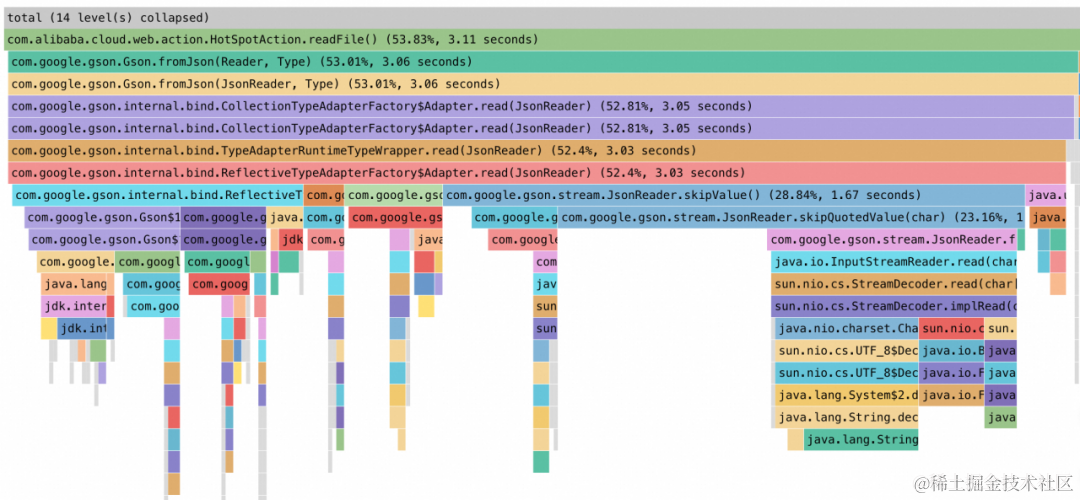
图 7 各种类型火焰图
如何使用火焰图?
火焰图作为性能分析的可视化技术,只有理解它该如何读才能基于其做性能分析。比如对于一张 CPU 热点火焰图,对于这个问题经常听到的一个说法就是看看火焰图中是否有较宽的栈顶,这个说法背后的原因是什么呢?
其实是因为,火焰图所绘制的内容就是计算机中方法执行的方法栈。而计算机中函数的调用上下文是基于一个叫做栈 [ 1] 的数据结构去存储,栈数据结构的特点是元素先进后出,因此栈底就是初始调用函数,依次向上就是一层层的被调用子函数。当最后一个子函数也就是栈顶执行结束以后才会依次从上往下出栈,因此栈顶较宽,就表示该子函数执行时间长,其下方的父函数也会因为其一直执行无法即时出栈而导致最终整体耗时很长。
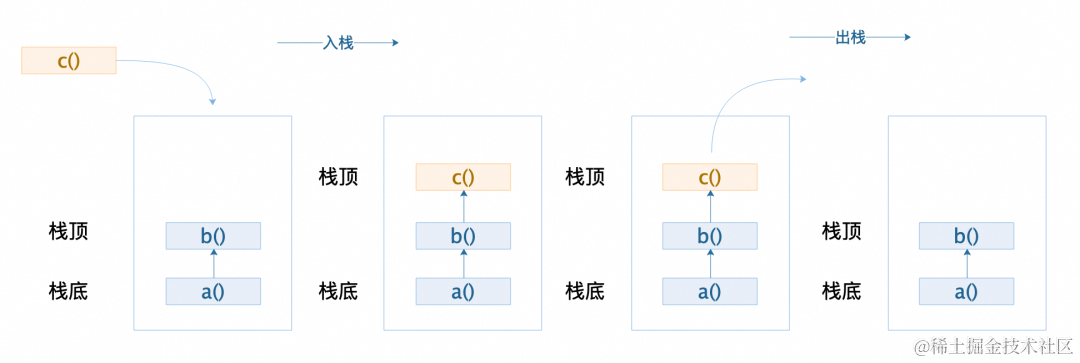
图 8 栈数据结构
因此分析火焰图的方法步骤如下:
-
判断火焰图对应的类型,找到其中的栈顶方向;
-
如果火焰图总资源占用高,就继续检查火焰图的栈顶是否有较宽的部分;
-
如果存在较宽的栈顶,沿着栈顶依次往栈底方向搜索,找到第一个包名为所分析应用自身所定义的方法行,然后重点排查该方法是否存在优化空间。
以下为一张资源占用高的火焰图,具体分析火焰图中的性能瓶颈步骤如下:
-
由下图形状可发现为一张栈底在上,栈顶在下的冰柱状火焰图,因此需要从下往上分析。
-
分析下方的栈顶,可以发现右侧较宽的栈顶为右侧的方法:java.util.LinkedList.node(int)。
-
由于该较宽栈顶是 JDK 中的库函数,并非为业务方法,因此,沿着栈顶方法:java.util.LinkedList.node(int),从下往上搜索,依次经过:java.util.LinkedList.get(int)->com.alibaba.cloud.pressure.memory.HotSpotAction.readFile(),而com.alibaba.cloud.pressure.memory.HotSpotAction.readFile() 是一个属于所分析应用的业务方法,即为第一个所分析应用自身所定义的方法行,其耗时为 3.89s,占到整张火焰图的 76.06%,因此其是该火焰图所采集时段内资源占用较高的最大瓶颈所在,因此可以根据相关方法名,对业务中相关方法的逻辑进行梳理,看是否存在优化空间。另外也可根据上述分析方法对图的左下角 java.net.SocketInputStream 相关方法一样进行分析,发现其属所分析应用第一个自身所定义的父方法全限定名为:com.alibaba.cloud.pressure.memory.HotSpotAction.invokeAPI,总占比位约为 23%。
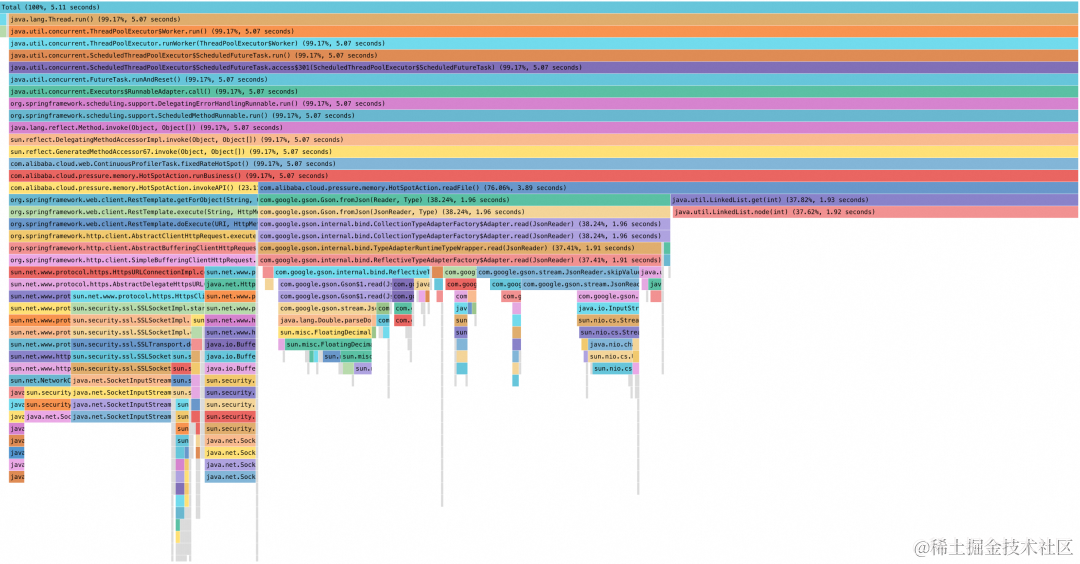
图 9 火焰图分析过程
开箱即用的 ARMS 持续剖析能力
经过上面的介绍,这个时候大家无论是对持续剖析概念、数据采集原理以及可视化技术应该都有了一定了解。然后,再介绍一下 ARMS 提供的开销即用持续剖析能力,如何帮助排查定位各类线上问题。
ARMS 提供一站式持续剖析产品能力,已经有接近 1w 应用实例在线上开启该功能进行持续数据采集与监控。

图 10 ARMS 持续剖析产品能力
左测图是当前 ARMS 持续剖析能力的概览,从上往下依次是数据采集、数据处理以及数据可视化。具体功能层面,目前针对用户需求最为急迫的几个场景分别提供了对应解决方案,比如 CPU、堆内存分析,提供了 CPU、内存热点功能。针对慢调用链诊断问题,ARMS 提供了代码热点功能。ARMS 上的持续剖析是 ARMS 团队联合阿里云 Dragonwell 团队一起研发的持续剖析产品能力,相比于一般的剖析方案,它具有开销低、粒度细和方法栈完备等特点。
使用介绍
在 ARMS 产品文档已经提供对应子功能的最佳实践内容:
- 针对 CPU 利用率高问题诊断,可以参考《使用 CPU 热点诊断 CPU 消耗高问题 [ 2] 》进行问题诊断。
- 针对堆内存利用率高问题诊断,可以参考《使用内存热点诊断堆内存使用高的问题 [ 3] 》进行问题诊断。
- 针对调用链耗时根因诊断,可以参考《使用代码热点诊断慢调用链的问题 [ 4] 》进行问题诊断。
客户案例
相关功能自发布以后,较好地协助用户对一些线上困扰已久的疑难杂症进行诊断,获得很多用户的好评,例如:
- 用户 A,发现某个应用服务刚启动的时候,前几个请求会很慢,使用 Tracing 出现了监控盲区无法诊断耗时分布。最后,使用 ARMS 代码热点,帮助其诊断出相关慢调用链的耗时根源是 Sharding-JDBC 框架初始化耗时所致,帮助其终于搞清楚了一直困扰的现象根因。
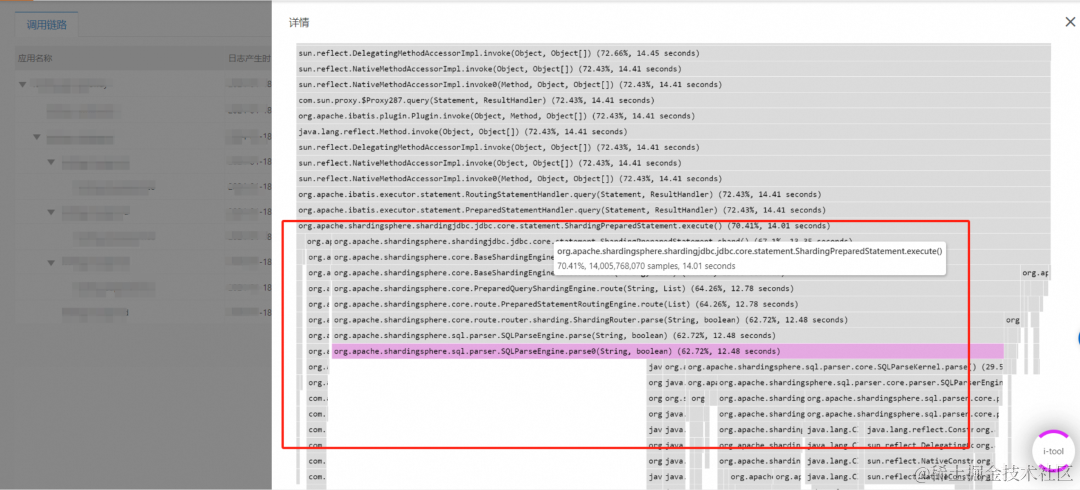
图 11 用户问题诊断案例 1
- 用户 B,压测过程中,应用的所有实例中总会出现有部分节点响应时长比其它节点慢很多,使用 Tracing 也看不出根因。最后,通过代码热点发现相关应用实例一压到某个压力情况下就会出现大量的时间消耗在写日志上,然后,根据相关信息,排查应用环境日志采集组件的资源使用率,发现其压测过程中占用了大量 CPU,导致应用实例写日志争抢不到资源而导致请求处理慢。

图 12 用户问题诊断案例 2
- 用户 C,线上应用运行过程中,发现堆内存使用量总是很大,通过内存热点,很快发现是应用使用的该版本微服务框架运行过程中将订阅的上游服务信息进行持久化处理导致大量堆内存占用,然后咨询相关框架服务提供方,最后,了解到可通过升级框架版本解决该问题。

图 13 用户问题诊断案例 3
开销情况
最后,大家可能会 ARMS 持续剖析开销非常关心,我们设计了如下压测场景对该功能开销进行测算,其模拟了一个从压测中心发起请求打入到业务入口应用,该应用会查询查询数据库并返回结果。

图 14 压测示意图
测试环境开启所有的持续剖析功能,采用的 K8s 容器运行环境来模拟一般企业应用运行环境。Pod limit 值为 4c8g,4g 堆内存年轻代占比设置为 1/2,压力极限为 6000 TPS。分别测试 500TPS 和极限压力的 80% 4800TPS 情况下的开销如下表所示。从表中可以看到,全部功能开启后 CPU 开销在 5% 左右,堆内内存开销不明显,堆外内存占用为 50MB 左右,流量小,或者仅开启部分持续剖析功能的情况下会更低。

图 15 压测结果
据了解,很多企业应用运行过程中的 CPU/内存等资源利用率都是比较低,通过少量资源消耗,为应用提供一个全新的观测视角,让应用在运行异常时有详细的根因定位数据还是非常有价值的!
如果您对文中提到的 ARMS 中的持续剖析功能感兴趣,欢迎加入 ARMS 持续剖析(Continuous Profiling)产品能力交流钉钉群讨论。(群号:22560019672)
直播推荐:
掌握 ARMS 持续剖析-轻松洞察应用性能瓶颈:https://developer.aliyun.com/live/253768
相关链接:
[1] 栈
https://baike.baidu.com/item/%E6%A0%88/12808149
[2] 使用 CPU 热点诊断 CPU 消耗高问题
https://help.aliyun.com/zh/arms/application-monitoring/user-guide/using-cpu-hotspots-to-diagnose-high-cpu-consumption
[3] 使用内存热点诊断堆内存使用高的问题
https://help.aliyun.com/zh/arms/application-monitoring/user-guide/using-memory-hotspots-to-diagnose-high-heap-memory-usage
[4] 使用代码热点诊断慢调用链的问题
https://help.aliyun.com/zh/arms/application-monitoring/user-guide/use-code-hotspots-to-diagnose-code-level-problems
相关文章:
解密 ARMS 持续剖析:如何用一个全新视角洞察应用的性能瓶颈?
作者:饶子昊、杨龙 应用复杂度提升,根因定位困难重重 随着软件技术发展迭代,很多企业软件系统也逐步从单体应用向云原生微服务架构演进,一方面让应用实现高并发、易扩展、开发敏捷度高等效果,但另外一方面也让软件应…...

【OJ比赛日历】春节快乐 #02.10-02.16 #9场
CompHub[1] 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号会推送最新的比赛消息,欢迎关注! 以下信息仅供参考,以比赛官网为准 目录 2024-02-10(周六) #4场比赛2024-02-11…...

前端下载文件有哪些方式
前端下载文件有哪些方式 在前端,最常见和最常用的文件下载方式是: 使用 标签的 download 属性: 创建一个 标签,并设置其 href 属性为文件的 URL,然后使用 download 属性指定下载的文件名。 这种方式简单直接&…...
vscode预览github上的markdown效果
需要安装的插件有: Github Markdown Preview Markdown Checkboxes Markdown Emoji Markdown footnotes Markdown Preview Github Styling Markdown Preview Mermaid Support Markdown yaml Preamble ctrlshiftv结合双页功能...
)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)。 要使用PaddleNLP和BERT来识别垃圾邮件并做中文邮件内容分类,可以按照以下步骤进行操作: 安装PaddlePaddle和PaddleNLP:首先,确保在你的环境中已经安装了PaddlePaddle和…...
在bash或脚本中,如何并行执行命令或任务(命令行、parallel、make)
最近要批量解压归档文件和压缩包,所以就想能不能并行执行这些工作。因为tar自身不支持并行解压,但是像make却可以支持生成一些文件,所以我才有了这种想法。 方法有两种,第一种不用安装任何软件或工具,直接bash或其他 …...

拼音笔记笔记
一、翀的读音:chōng 声母:ch 韵母:ong 声调:一声 二、汉字释义: 向上直飞,相当于“冲”。 三、汉字结构:左右结构 四、部首:羽 五、相关词组: 翀举:谓成仙升…...

13. Threejs案例-绘制3D文字
13. Threejs案例-绘制3D文字 实现效果 知识点 FontLoader 一个用于加载 JSON 格式的字体的类。 返回 font,返回值是表示字体的 Shape 类型的数组。 其内部使用 FileLoader 来加载文件。 构造器 FontLoader( manager : LoadingManager ) 参数类型描述managerLo…...

clickhouse清理日志。
参考Clickhouse:日志表占用大量磁盘空间怎么办?_clickhouse store目录很大-CSDN博客t 清理脚本如下,清理动作需要时间比较长,10多分钟: alter table system.trace_log delete where event_date < 2024-01-01 alt…...

JS中实现继承
1.使用call实现继承(不推荐) function Animal(name) {this.name name;this.run function() {console.log(this.name, "跑");} } function Dog(name) {// 继承Animal.call(this, name);this.sleep function() {console.log(this.name, &quo…...

spring boot学习第九篇:操作mongo的集合和集合中的数据
1、安装好了Mongodb 参考:ubuntu安装mongod、配置用户访问、添删改查-CSDN博客 2、pom.xml文件内容如下: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns…...
momentJs推导日历组件
实现效果: 代码: 引入momentjs然后封装两个函数构建出基本数据结构 import moment from moment;// 某月有多少天 export const getEndDay (m) > m.daysInMonth();/*** description 获取本月空值数据* param { Date } year { } 年度* param { Number } month …...

Linux C/C++ 原始套接字:打造链路层ping实现
在C/C中,我们可以使用socket函数来创建套接字。我们需要指定地址族为AF_PACKET,协议为htons(ETH_P_ALL)来捕获所有传入和传出的数据包。 可以使用sendto和recvfrom函数来发送和接收数据包。我们需要构建一个合法的链路层数据包,在数据包的头…...

TCP 粘包/拆包
文章目录 概述粘包拆包发生场景解决TCP粘包和拆包问题的常见方法Netty对粘包和拆包问题的处理小结 概述 TCP的粘包和拆包问题往往出现在基于TCP协议的通讯中,比如RPC框架、Netty等 TCP 粘包/拆包 就是你基于 TCP 发送数据的时候,出现了多个字符串“粘”…...

【Spring Boot 3】应用启动执行特定逻辑
【Spring Boot 3】应用启动执行特定逻辑 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...
观察者模式)
设计模式(行为型模式)观察者模式
目录 一、简介二、观察者模式2.1、事件接口及其实现2.2、观察者接口及其实现2.3、主题接口及其实现2.4、使用 三、优点与缺点 一、简介 观察者模式(Observer Pattern)是一种行为设计模式,它定义了一种一对多的依赖关系,当一个对象…...

Windows 版Oracle 数据库(安装)详细过程
首先到官网上去下载oracle64位的安装程序 第一步:将两个datebase文件夹解压到同一目录中。 当下载完成后,它里面是两个文件夹 win64_11gR2_database_1of2, win64_11gR2_database_2of2,我们需要把其中的一个database文件夹整合在一起(复制一个database文件夹到另一…...
编程实例分享,计费系统一定要安装灯光控制吗?佳易王计时计费管理系统软件V18.0教程说明
编程实例分享,计费系统一定要安装灯光控制吗?佳易王计时计费管理系统软件V18.0教程说明 一、前言 以下教程以 佳易王计时计费软件V18.0为例说明 1、该软件既可以接灯控,也可以不接灯控,如果接灯控,则点击开始计时的时…...

【webpack】优化提升
webpack优化提升 安装webpack相关内容向下兼容游览器-babel/polyfill进一步优化babel/polyfill模块联邦-共享模块如何提升构建性能通用环境下1,webpack更新到最新版本2,将loader应用于最少数量的必要模块3,引导(每个额外的loader/…...
视频无损放大修复工具Topaz Video AI 新手入门教程
想要自学Topaz Video AI ?Topaz Video AI 如何使用?这里给大家带来了视频无损放大修复工具Topaz Video AI 新手入门教程,快来看看吧! 下载:Topaz Video AI for mac 导入您的文件 有两种方法可以将文件导入 Topaz Vid…...

PasteMD场景应用:微信聊天记录自动整理为会议纪要
PasteMD场景应用:微信聊天记录自动整理为会议纪要 1. 为什么你的会议纪要总是一团糟? 想象一下这个场景: 下午两点,项目组紧急拉了个微信群聊,大家七嘴八舌讨论了半小时,敲定了五个关键事项和三个责任人。…...
)
从零到上手:用COPY命令玩转人大金仓数据库的数据导入导出(附CSV处理技巧)
从零到上手:用COPY命令玩转人大金仓数据库的数据导入导出(附CSV处理技巧) 在数据驱动的时代,数据库的高效数据交换能力直接影响着业务敏捷性。对于人大金仓数据库用户而言,虽然传统的sys_dump和sys_restore在完整备份恢…...

rg -n 是什么意思?
关于 -n (Line number) 的原始英文说明在 rg --help 中,它是这样描述的:-n, --line-number Show line numbers. This is enabled by default when searching in a terminal.核心翻译: 显示行号。当在终端(terminal)中搜…...

终极Windows XP错误对话框组件:怀旧系统提示的优雅实现指南
终极Windows XP错误对话框组件:怀旧系统提示的优雅实现指南 【免费下载链接】winXP 🏁 Web based Windows XP desktop recreation. 项目地址: https://gitcode.com/gh_mirrors/wi/winXP 你是否怀念Windows XP那个经典的错误提示对话框࿱…...

NVIDIA vGPU许可服务器HA配置避坑指南:从环境准备到故障切换测试
NVIDIA vGPU许可服务器高可用配置实战:从零搭建到容灾验证 在虚拟化与AI计算融合的今天,NVIDIA vGPU技术已成为图形工作站、云游戏和机器学习平台的核心支撑。但许多团队在享受显卡虚拟化红利时,往往忽略了许可服务的高可用保障——当单点故障…...

别再手动改MTL文件了!一个Python脚本搞定ENVI打开Landsat 8/9 L2影像的报错问题
用Python自动化修复Landsat L2影像的ENVI兼容性问题 遥感数据处理中,Landsat 8/9的L2级别影像在ENVI软件中打开时经常遇到兼容性问题。传统的手动修改MTL文件方法不仅效率低下,还容易出错。本文将介绍一个Python自动化解决方案,帮助您彻底摆脱…...

福人板材靠谱供应商:企业采购决策核心要素解析
福人板材靠谱供应商:企业采购决策核心要素解析“选对福人板材靠谱供应商,比砍价更重要——企业采购决策的8个核心要素,少一个都可能踩坑”对于中小制造企业、装饰公司等采购方而言,福人板材作为行业知名的环保板材品牌,…...

M5Stack舵机驱动库:PCA9685硬件PWM控制与多平台移植
1. 项目概述M5Hat-8Servos 是专为 M5Stack 生态设计的硬件驱动库,用于控制 M5Stack 官方推出的HAT-8SERVO扩展模块。该模块基于PCA9685 16通道12位PWM LED与伺服驱动芯片,通过 IC 总线与主控(如 M5Stack Core2、M5Stamp C3、M5Paper 等&#…...

Bongo-Cat-Mver:实时键盘动画工具的创新应用与实践指南
Bongo-Cat-Mver:实时键盘动画工具的创新应用与实践指南 【免费下载链接】Bongo-Cat-Mver An Bongo Cat overlay written in C 项目地址: https://gitcode.com/gh_mirrors/bo/Bongo-Cat-Mver 在直播、教学和演示场景中,如何让观众清晰感知键盘操作…...
)
ESP32+LVGL实战:手把手教你搞定ST7789屏幕镜像显示(附完整代码)
ESP32LVGL实战:从寄存器到工程化配置,彻底解决ST7789屏幕镜像显示问题 当你用ESP32驱动ST7789屏幕时,是否遇到过图像上下左右颠倒的困扰?这个问题看似简单,但网上的零散教程往往只告诉你改某个寄存器值,却忽…...