拿捏循环链表
目录:
一:单链表(不带头单向不循环)与循环链表(带头双向循环)区别
二:循环链表初始化
三:循环链表头插
四:循环链表尾插
五:循环链表头删
六:循环链表尾删
七:循环链表查找
八:循环链表指定pos 位置的删除
九:循环链表指定pos 位置之前的插入
十:循环链表销毁
十一:结语
1:单链表(不带头单向不循环)与循环链表(带头双向循环)区别
1)结构上
循环链表多了给 前驱指针 pre
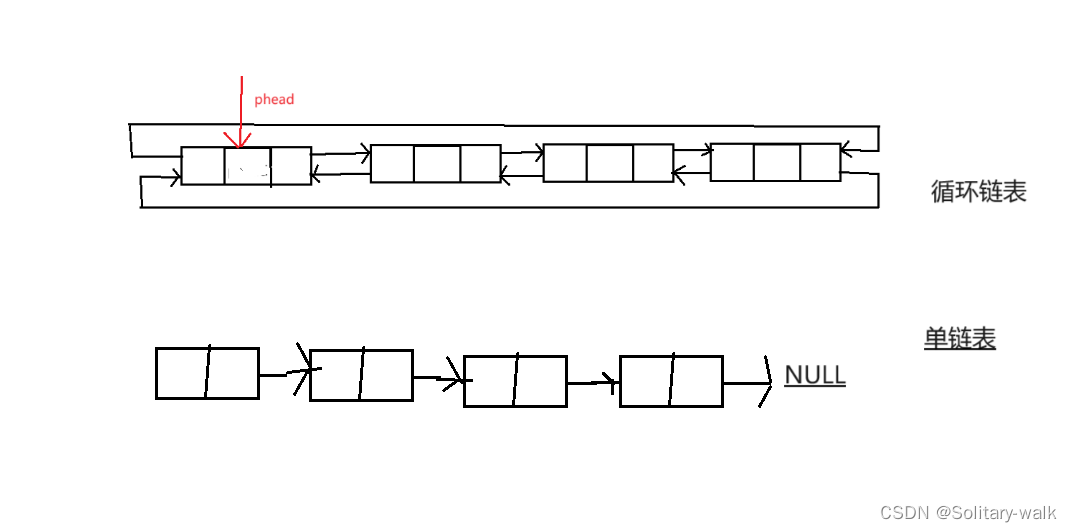
2)链表增删查改
有了pre这个指针,效率大大提升
2:循环链表初始化
讲到初始化,这里主要就是对哨兵位 (暂时称为:phead)进行设置
注意:哨兵位只是占一个位置,并不存储任何有效的数据
循环链表初始状态是空的:phead 自己成环

对应代码:
phead -> next = phead ;
phead -> pre = phead ;
那么问题就来了,在设计这个初始化函数的时候用一级指针还是二级指针

想必,前期看过我的单链表的博客,自然会说二级指针呀:
因为是对phead 这个指针进行改变所以是传二级指针。没毛病!不知道大家在做OJ题的时候,我们也涉及到对一级指针的改变,但是我们也可以返回这个一级指针,即可实现
ListNode* ListNodeInit()
{/*哨兵位:val 没有实际意义(自行赋值)初始化的目的就是对哨兵位进行设置因为整个接口都是用一级指针,若是初始化用二级指针有点不顺眼此函数返回哨兵位地址即可实现对哨兵位的初始化*/ListNode* phead = NULL;ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");return NULL;}phead = newnode;phead->val = -1;phead->pre = phead->next = phead;//够成环return phead;
}3:循环链表头插
头插:即在哨兵位的后面进行头插(若是链表为空,此时的头插也即是尾插)
头插分析:显然我们只需改变指针走向即可
注意指针先后问题
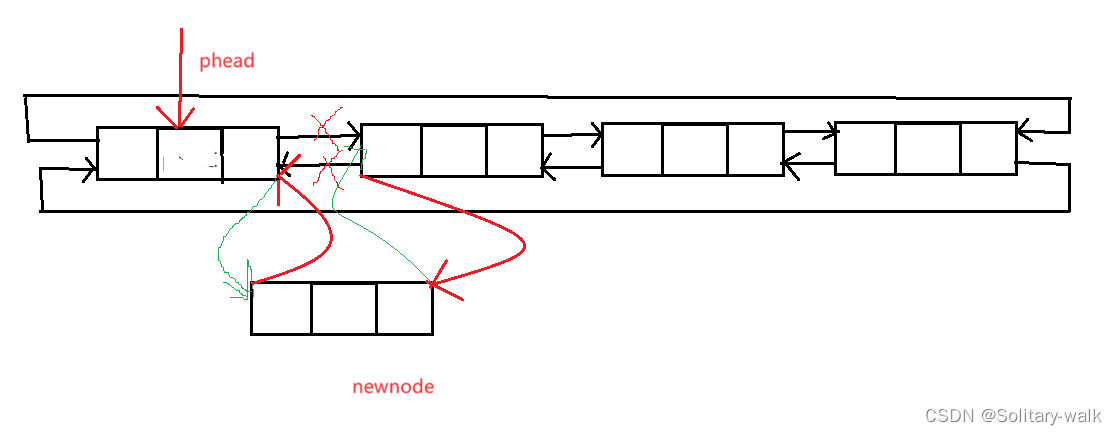
各位老铁康康这样的代码是否之正确:
phead-> next = newnode;
newnode-> next = phead-> next;
newnode-> pre = phead;
newnode->next-> pre = newnode;

此代码结合画图,来看, 显然这样是不对的,因为newnode-> next = phead-> next;这句代码让newnode 这个节点自己成环了,所以又怎么可能头插进去呢?
实质性原因是:当我们头插进来newnode 时,应该先执行
newnode-> next = phead->next; //注意指针先后问题
phead->next->pre = newnode; //让原来头结点的 pre 指向newndoe
newnode-> pre = phead;
phead-> next = newnode;
ListNode* newnode = BuyNode(x);newnode->next = phead->next;newnode->pre = phead;phead->next->pre = newnode;//原来第一个节点pre与新的头结点连接phead->next = newnode;//新的头结点对于以上问题还可以这样解决:定义一个 next指针来保留一下原来的头结点
4:循环链表尾插
尾差之前我们需要先思考一个问题:对于单链表(不循环,不带头,单向)而言,每次尾插之前都需要遍历链表,来找尾结点
但是对于循环链表而言我们就不需要:找尾结点直接一步到位 phead-> pre
真的是没有对比就没有伤害,所以在这块,咱循环链表还是比较好搞滴
尾插分析:
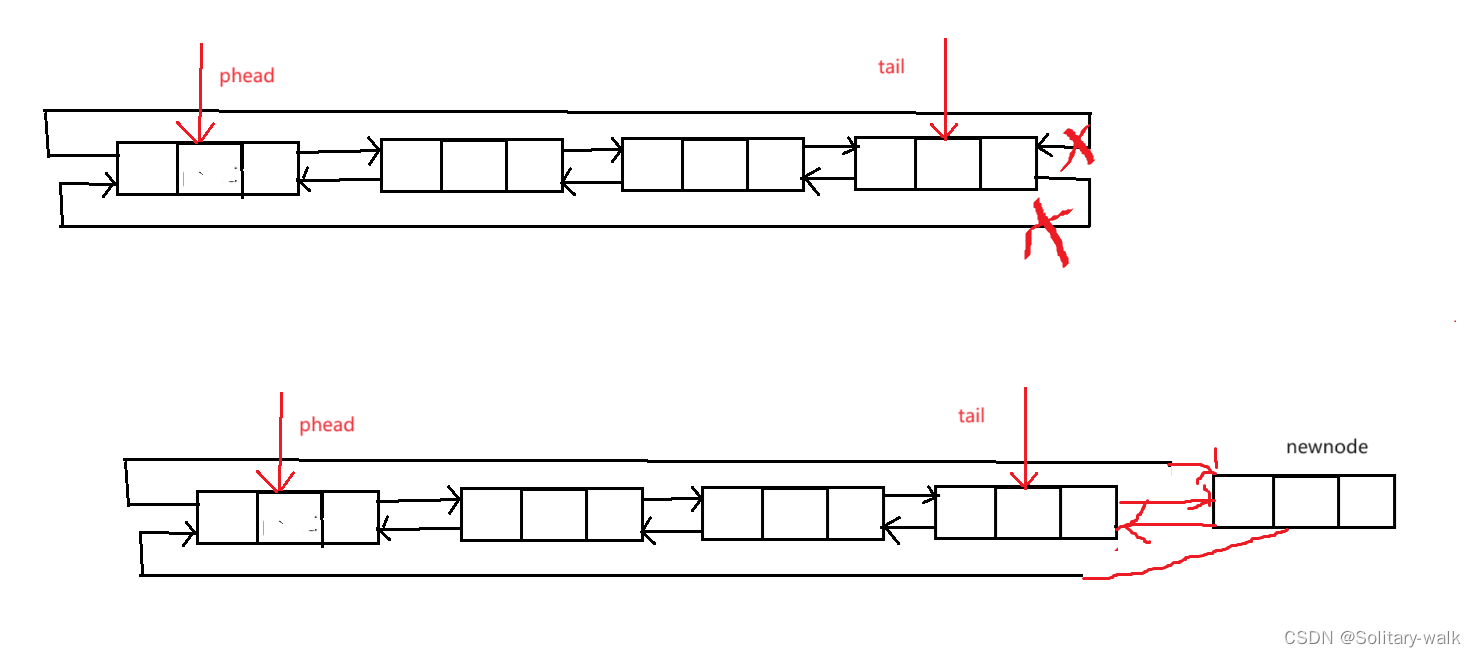
这里只需改变指针走向即可
代码:
void ListNodePushBack(ListNode* phead,DataType x)
{assert(phead);/*1:找尾结点 phead->pre2:指针连接 */ListNode* newnode = BuyNode(x);newnode->next = phead;newnode->pre = phead->pre;phead->pre->next = newnode;//原来尾结点与newnode进行连接phead->pre = newnode;//新的尾结点}5:循环链表头删
依然如此,按照“国际惯例”:找头结点 phead -> next
删除之前先保留一下 第二个节点
当把链表所以节点删除后(除哨兵位),会自动保存一个循环链表
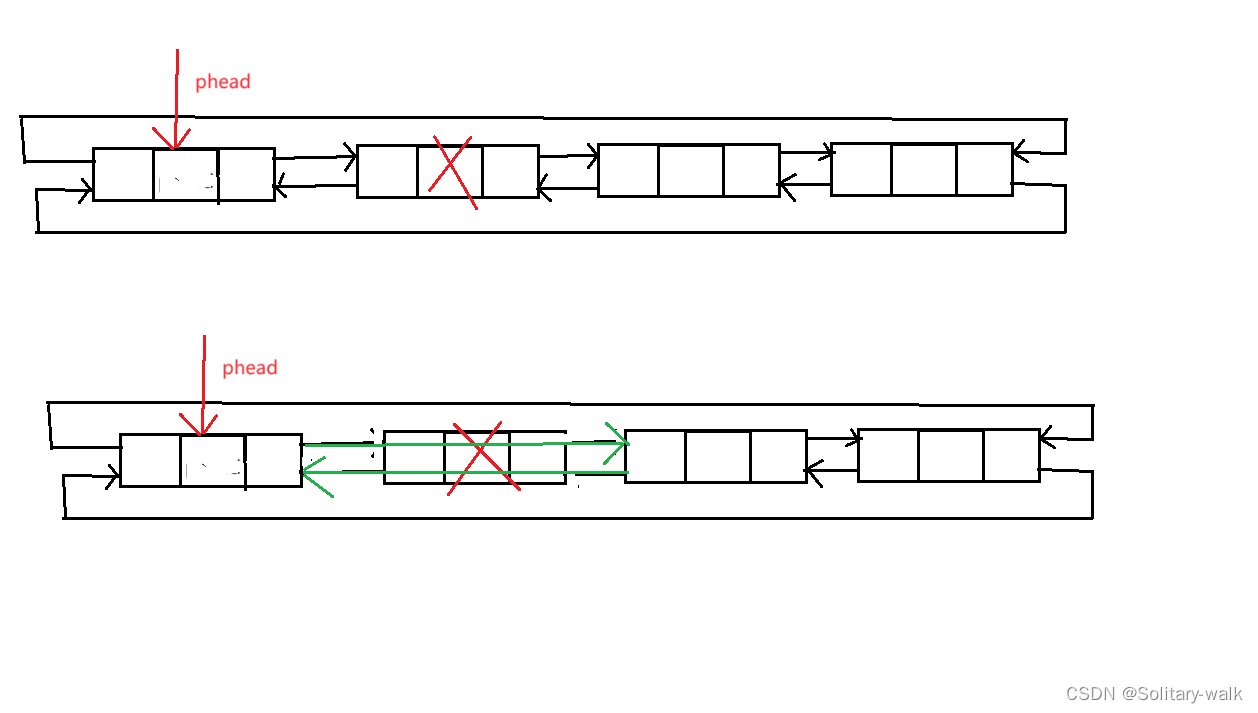
代码见下:
void ListNodePopFront(ListNode* phead)
{assert(phead->next != phead);//不相等说明不为空ListNode* newFirst = phead->next->next;newFirst->pre = phead;phead->next = newFirst;//成为新的头结点//以下写法也对,但可读性差phead->next = phead->next->next;phead->next->pre = phead;}6:循环链表尾删
既然谈到尾删,咱这里不得不提一嘴,单链表的尾删
单链表尾删逻辑:
1:链表不为空
2:只有一个节点:传二级指针
3:多个节点:传一级指针
4:找尾结点: 条件 tail -> next != NULL;
咱就是说,是不是事很多。
相比较之下,循环链表就比较友好:找啥尾结点,直接一步到位 phead-> pre
直接改变指针走向即可。
老问题:保留一下尾结点的前一个节点 tailPre
void ListNodePopBack(ListNode* phead)
{assert(phead);/*空链表: 1:找尾结点 phead->pre2:成环: 改变新的尾结点与phead 直接的链接*/assert(phead->next != phead);//不相等说明链表不为空,为空不能删除ListNode* tail = phead->pre;ListNode* tailPre = tail->pre;phead->pre = tailPre;//新的尾结点tailPre->next = phead;free(tail);
}7:循环链表查找
此函数可以实现2个功能:一个是查找;另一个是修改
逻辑:按值查找,若是存在,直接返回当前节点,否则返回 NULL
注意是从 第一个节点开始 而不是从哨兵位 开始
ListNode* Find(ListNode* phead, DataType x) //指定数据查找
{/*从第一个节点开始查找: phead->next依次遍历,若是存在返回节点否则返回NULL*/assert(phead);ListNode* cur = phead->next;while (cur != phead ) //phead 是哨兵位{if (x == cur->val){return cur;}cur = cur->next;}return NULL;//没有找到
}8:循环链表指定pos 位置的删除
这个接口的逻辑其实说白了与尾删没啥不同
注意:pos 这个节点是查找函数返回的
void ListNodeErase(ListNode* pos)//指定位置删除 pos是查找函数返回的
{assert(pos);ListNode* posPre = pos->pre;ListNode* posNext = pos->next;posPre->next = posNext;posNext->pre = posPre;free(pos);
}9:循环链表指定pos 位置之前的插入
void ListNodeInsert(ListNode* pos, DataType x)//指定位置之前插入
{/*1:找到pos 前一个节点 pos->pre2:注意避免节点找不到3:改变指针连接: posPre,newnode,pos*/assert(pos);//为空直接不玩了ListNode* newnode = BuyNode(x);ListNode* posPre = pos->pre;posPre->next = newnode;newnode->pre = posPre;newnode->next = pos;pos->pre = newnode;}10:循环链表销毁
这里的销毁就是一个节点一个节点进行删除
注意:包括哨兵位在内
void ListNodeDestroy(ListNode* phead)
{/*注意哨兵位也需要删除一个节点一个节点删除*/assert(phead);ListNode* cur = phead->next;while (cur != phead){ListNode* next = cur->next;free(cur);cur = next;}free(phead);
}各位老铁们,别走开,接下来的问题你值得一看,或许哪天自己面试会遇到类似问题呢?
前段时间看到过样一个问题:
有个求职者去面试:在他的简历上写着自己是比较熟练数据结构这个模块的。
面试官问了这样一个问题:你能否在10分钟之内,搞一个链表出来?
听到这,求职者心里多多少少是有点担忧“搞,是没有问题,但是这个时间能否在宽裕点……”
进过这种协商,时间定在15分钟
对于这个问题的答卷:很显然,这个求职者没有拿到100分

屏幕前的各位铁子们,假设你是那个求职者,你又会如何回答好这份答卷?
是的,要是我,我一定会用循环链表来搞呀(因为面试官有没有指定具体是8中链表的哪一种)
你仔细想想:循环链表效率多高呀
对于一个链表的基本操作无非不就是:
头删头插
尾删,尾插
任意位置的插入和删除
不知道你是否考虑过这样问题:
循环链表的尾插,头插其实就是任意位置插入的一个特例
尾删,头删其实就是任意位置的删除的一个特例
完整代码如下:
DList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"List.h"
void ListNodePrint(ListNode* phead)
{assert(phead);ListNode* cur = phead->next;printf("guard<==>");while (cur != phead){printf("%d<==>", cur->val);cur = cur->next;}printf("\n");
}
ListNode* ListNodeInit()
{/*哨兵位:val 没有实际意义(自行赋值)初始化的目的就是对哨兵位进行设置因为整个接口都是用一级指针,若是初始化用二级指针有点不顺眼此函数返回哨兵位地址即可实现对哨兵位的初始化*/ListNode* phead = NULL;ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");return NULL;}phead = newnode;phead->val = -1;phead->pre = phead->next = phead;//够成环return phead;
}ListNode* BuyNode(DataType x)
{ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");return NULL;}newnode->val = x;newnode->next = NULL;newnode->pre = NULL;return newnode;
}
void ListNodePushBack(ListNode* phead,DataType x)
{assert(phead);/*1:找尾结点 phead->pre2:指针连接 *///ListNode* newnode = BuyNode(x);//newnode->next = phead;//newnode->pre = phead->pre;//phead->pre->next = newnode;//原来尾结点与newnode进行连接//phead->pre = newnode;//新的尾结点ListNodeInsert(phead, x);//注意ListNodeInsert 这个函数功能是在pos 之前插入,所以要想实现尾插,需要传phead ,而不是phead->pre }
void ListNodePushFront(ListNode* phead, DataType x)
{/*注意phead不是头结点(第一个节点),phead 只是一个哨兵位,只占位置第一个节点:phead->next考虑指针先后问题,避免找不到第一个节点(链表不为空)*/assert(phead);//ListNode* newnode = BuyNode(x);//newnode->next = phead->next;//newnode->pre = phead;//phead->next = newnode;//新的头结点以上代码不对//ListNode* newnode = BuyNode(x);//newnode->next = phead->next;//newnode->pre = phead;//phead->next->pre = newnode;//原来第一个节点pre与新的头结点连接//phead->next = newnode;//新的头结点ListNodeInsert(phead->next, x);}void ListNodePopBack(ListNode* phead)
{assert(phead);/*空链表: 1:找尾结点 phead->pre2:成环: 改变新的尾结点与phead 直接的链接*/assert(phead->next != phead);//不相等说明链表不为空,为空不能删除ListNodeErase(phead->pre);//ListNode* tail = phead->pre;//ListNode* tailPre = tail->pre;//phead->pre = tailPre;//新的尾结点// tailPre->next = phead;//free(tail);
}
void ListNodePopFront(ListNode* phead)
{assert(phead->next != phead);//不相等说明不为空ListNodeErase(phead->next);//ListNode* newFirst = phead->next->next;//newFirst->pre = phead;//phead->next = newFirst;//成为新的头结点以下写法也对,但可读性差//phead->next = phead->next->next;//phead->next->pre = phead;}
ListNode* Find(ListNode* phead, DataType x) //指定数据查找
{/*从第一个节点开始查找: phead->next依次遍历,若是存在返回节点否则返回NULL*/assert(phead);ListNode* cur = phead->next;while (cur != phead ) //phead 是哨兵位{if (x == cur->val){return cur;}cur = cur->next;}return NULL;//没有找到
}void ListNodeInsert(ListNode* pos, DataType x)//指定位置之前插入
{/*1:找到pos 前一个节点 pos->pre2:注意避免节点找不到3:改变指针连接: posPre,newnode,pos*/assert(pos);//为空直接不玩了ListNode* newnode = BuyNode(x);ListNode* posPre = pos->pre;posPre->next = newnode;newnode->pre = posPre;newnode->next = pos;pos->pre = newnode;}void ListNodeErase(ListNode* pos)//指定位置删除 pos是查找函数返回的
{assert(pos);ListNode* posPre = pos->pre;ListNode* posNext = pos->next;posPre->next = posNext;posNext->pre = posPre;free(pos);
}
void ListNodeDestroy(ListNode* phead)
{/*注意哨兵位也需要删除一个节点一个节点删除*/assert(phead);ListNode* cur = phead->next;while (cur != phead){ListNode* next = cur->next;free(cur);cur = next;}free(phead);
}
DList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>typedef int DataType;
typedef struct DListNode
{DataType val;struct DListNode* next;struct DListNode* pre;//前驱指针}ListNode;
void ListNodePrint(ListNode*phead);
ListNode* ListNodeInit();void ListNodePushBack(ListNode* phead,DataType x);
void ListNodePushFront(ListNode* phead, DataType x);void ListNodePopBack(ListNode* phead);
void ListNodePopFront(ListNode* phead);ListNode* Find(ListNode* phead,DataType x); //指定数据查找(此函数可以实现2个功能:查找 + 修改)void ListNodeInsert(ListNode* pos, DataType x);//指定位置之前插入,pos是查找函数返回的void ListNodeErase(ListNode* pos);//指定位置删除void ListNodeDestroy(ListNode* phead);
/*
面试题目: 10分钟之内写一个链表
注意:头删,尾删 都只是 ListNodeErase 这个函数一个特例
头插,尾插,同理,是ListNodeInsert 一个特例
所以 可以借用
*/test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"List.h"void TestPush()
{ListNode* plist = ListNodeInit();//ListNodeInit(&plist);//ListNodePushBack(plist, 1);//ListNodePushBack(plist, 2);//ListNodePushBack(plist, 3);ListNodePushFront(plist, 1);ListNodePushFront(plist, 2);ListNodePushFront(plist, 3);ListNodePushFront(plist, 4);ListNodePushFront(plist, 5);ListNodePushFront(plist, 6);ListNodePushFront(plist, 7);ListNodePrint(plist);ListNodePushBack(plist, 0);ListNodePrint(plist);ListNodeDestroy(plist);}
void TestPop()
{//ListNode* plist = (ListNode*)malloc(sizeof(ListNode));//if (plist == NULL)// return;//plist->val = -1;//plist->next = plist;//plist->pre = plist;//等价于以下代码ListNode* plist = ListNodeInit();ListNodePushBack(plist, 1);ListNodePushBack(plist, 2);ListNodePushBack(plist, 3);ListNodePrint(plist);//ListNodePopFront(plist);//ListNodePrint(plist);//ListNodePopFront(plist);//ListNodePrint(plist);//ListNodePopFront(plist);//ListNodePrint(plist);ListNodePopBack(plist);ListNodePrint(plist);ListNodePopBack(plist);ListNodePrint(plist);ListNodePopBack(plist);ListNodePrint(plist);ListNodeDestroy(plist);}
void Test()
{ListNode* plist = ListNodeInit();ListNodePushBack(plist, 1);ListNodePushBack(plist, 2);ListNodePushBack(plist, 3);ListNode* pos = Find(plist, 3);if (pos != NULL){ListNodeInsert(pos, 10);ListNodePrint(plist);}else{printf("操作失败\n");}ListNodeDestroy(plist);}void Test1()
{ListNode* plist = ListNodeInit();ListNodePushBack(plist, 1);ListNodePushBack(plist, 2);ListNodePushBack(plist, 3);ListNode* pos = Find(plist, 3);if (pos != NULL){ListNodeErase(pos);ListNodePrint(plist);}else{printf("操作失败\n");}ListNodeDestroy(plist);}int main()
{TestPush();//TestPop();//Test();//Test1();return 0;
}11:结语
以上就是我今日要为大家share的内容。其实说白了,循环链表的结构看似复杂,实际操作起来,非常简单。(就是多了一个 pre这样的一个前驱指针)。希望各位老铁们能够从这篇博客中学到一些知识,同时欢迎大家随时指正,那咱话不多说,你懂滴!
相关文章:
拿捏循环链表
目录: 一:单链表(不带头单向不循环)与循环链表(带头双向循环)区别 二:循环链表初始化 三:循环链表头插 四:循环链表尾插 五:循环链表头删 六࿱…...
)
UMLChina公众号精选(20240207更新)
UMLChina服务 如何选择UMLChina服务 《软件方法》分步改进指南 做对《软件方法》强化自测题获得“软件方法建模师”称号 建模示范视频 [EA-029/石油钻井管理平台]35套UML/SysMLEA/StarUML的建模示范视频-全程字幕 UMLChina连EA经销商都不是,EA水平靠谱嘛?…...

东南亚手游市场攻略:出海前的关键准备与注意事项
随着全球游戏市场的日益繁荣,越来越多的手游企业开始将目光投向海外市场,其中东南亚地区因其庞大的用户基数和逐渐成熟的游戏市场环境,成为了不少企业的首选目标。然而,想要在东南亚市场取得成功,并非易事。本文Nox聚星…...
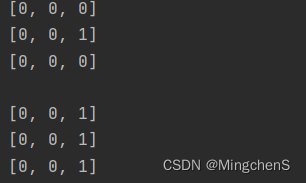
python二维数组初始化的一个极其隐蔽的bug(浅拷贝)
初始化一个三行三列的矩阵 m n 3初始化方式1 a [[0 for i in range(m)] for j in range(n)]初始化方式2 b [] row [0 for i in range(0,m)] for i in range(0,n):b.append(row)分别输出两个初始化的结果 for row in a:print(row) for row in b:print(row)当前的输出为…...
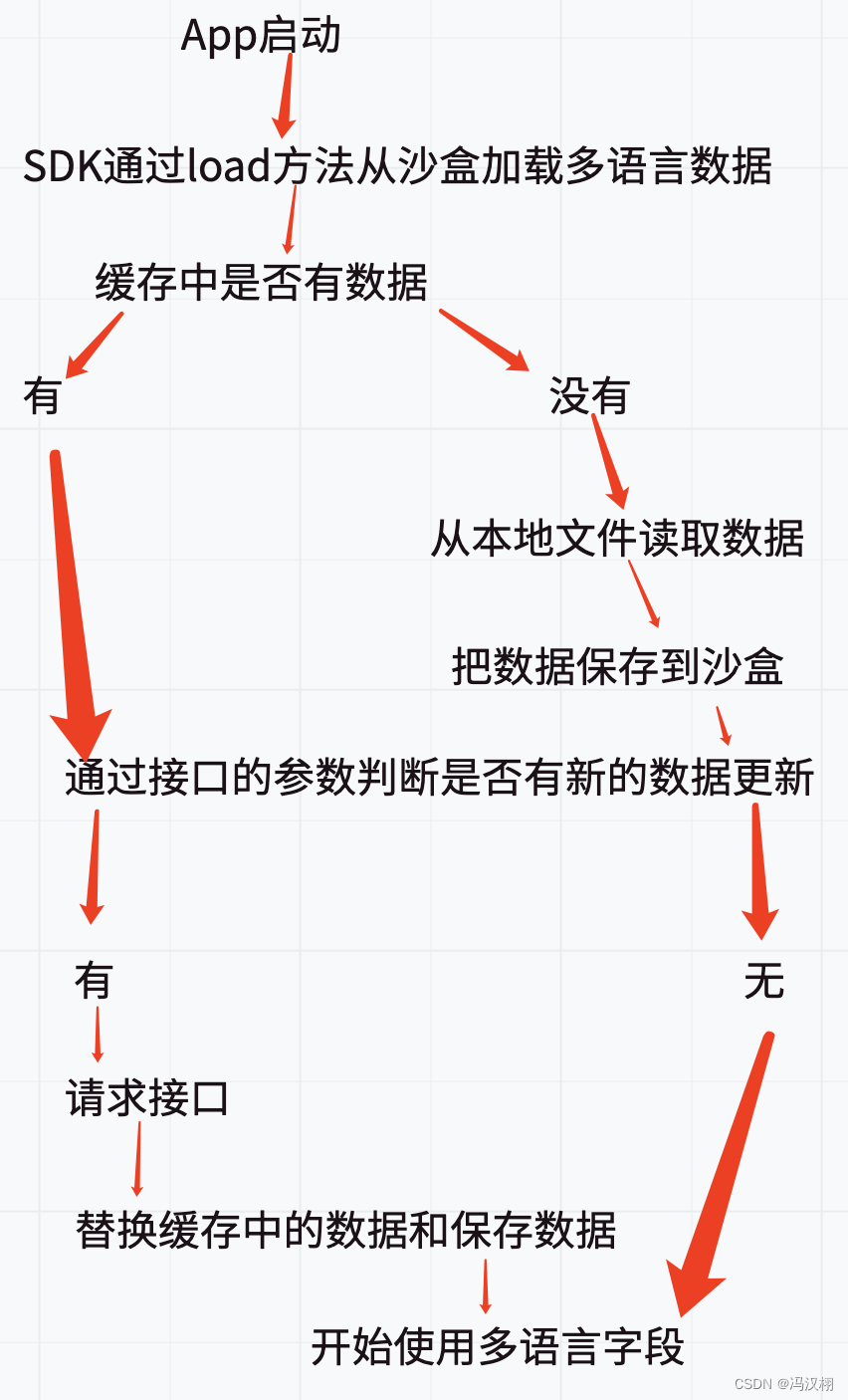
iOS 需求 多语言(国际化)App开发 源码
一直觉得自己写的不是技术,而是情怀,一个个的教程是自己这一路走来的痕迹。靠专业技能的成功是最具可复制性的,希望我的这条路能让你们少走弯路,希望我能帮你们抹去知识的蒙尘,希望我能帮你们理清知识的脉络࿰…...
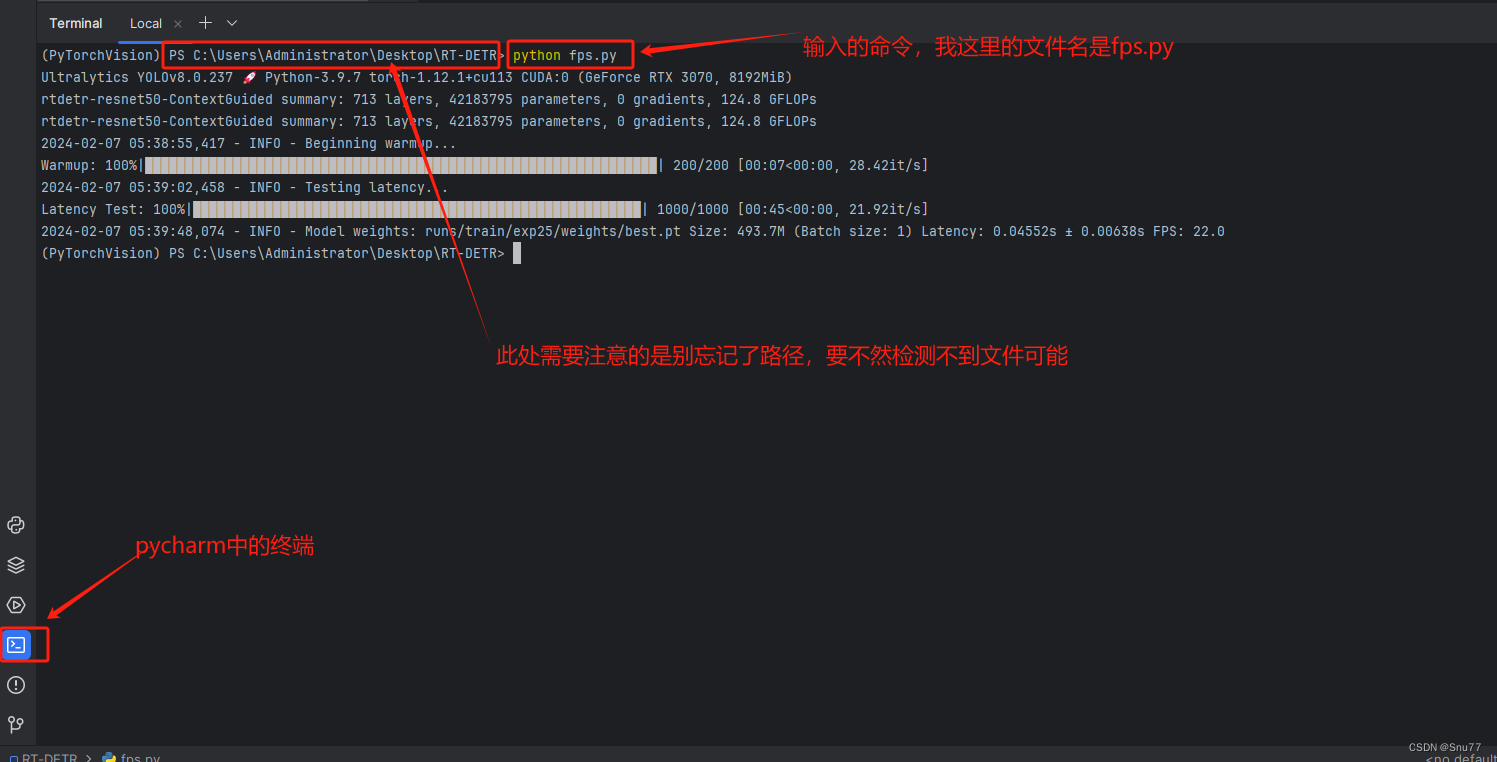
YOLOv8改进 | 利用训练好权重文件计算YOLOv8的FPS、推理每张图片的平均时间(科研必备)
一、本文介绍 本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有帮助,可以清晰帮你展示出模型速度性能的提升以及轻量…...
std::vector<cv::Mat>和unsigned char** in_pixels 互相转换
将std::vectorcv::Mat转换为unsigned char** in_pixels, std::vector<cv::Mat> matVector; // 假设已经有一个包含cv::Mat的vector// 创建一个二维数组,用于存储像素数据 unsigned char** in_pixels new unsigned char*[matVector.size()]; for …...
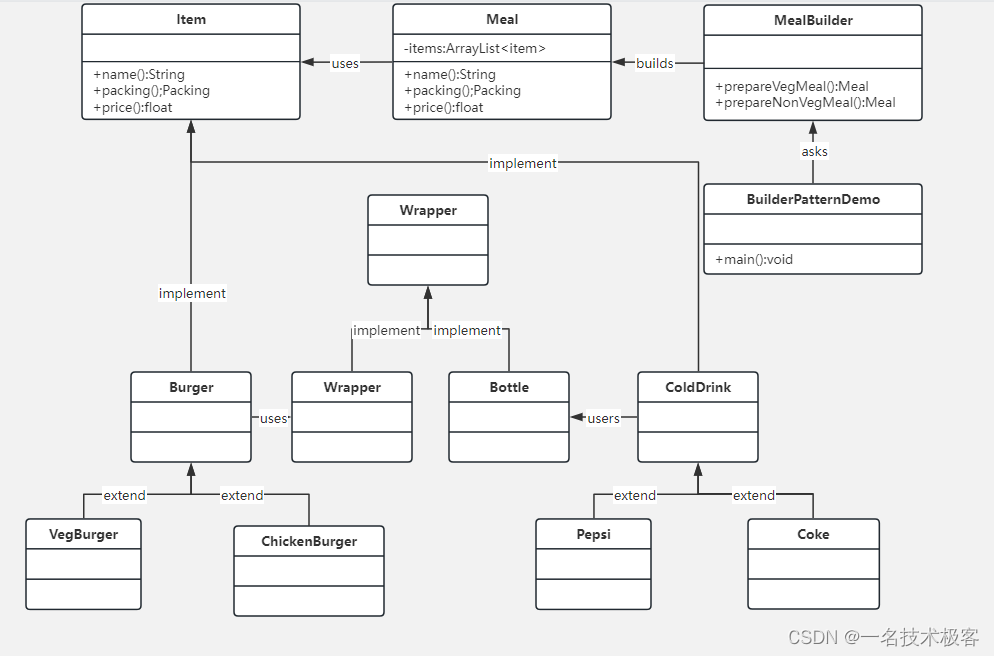
04-Java建造者模式 ( Builder Pattern )
建造者模式 摘要实现范例 建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象 一个Builder 类会一步一步构造最终的对象,该 Builder 类是独立于其他对象的 建造者模式属于创建型模式,它提供了一种创建对…...
使用PHPStudy搭建Cloudreve网盘服务
文章目录 1、前言2、本地网站搭建2.1 环境使用2.2 支持组件选择2.3 网页安装2.4 测试和使用2.5 问题解决 3、本地网页发布3.1 cpolar云端设置3.2 cpolar本地设置 4、公网访问测试5、结语 1、前言 自云存储概念兴起已经有段时间了,各互联网大厂也纷纷加入战局&#…...

Lua协程-coroutine
lua也有协程这个机制,用以完成非抢占式的多任务处理。 协程与线程 协程和线程类似,有自己的堆栈、局部变量、指令指针等等。但同时也有不一致的地方,其中最重要的地方在于多线程程序可以同一时间运行多个线程,而协程同一时间只能…...
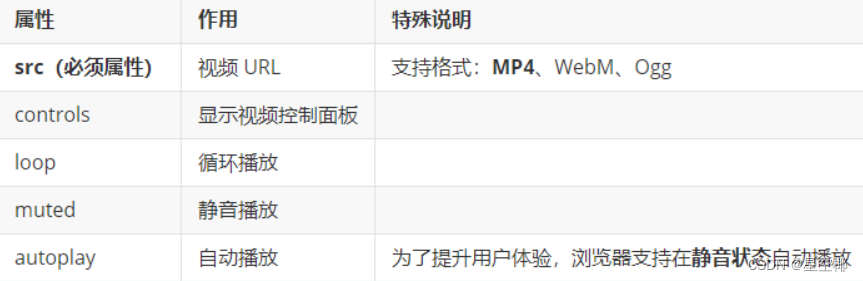
HTML5+CSS3+移动web——HTML 基础
目录 一、标签语法 HTML的基本框架 1. 标题标签 2. 段落标签 3. 换行和水平线 4. 文本格式化标签 5. 图像标签 6. 路径 相对路径 绝对路径 7. 超链接标签 8. 音频 9. 视频 10. 注释 二、标签结构 一、标签语法 HTML 超文本标记语言——HyperText Markup Langua…...

Java中List接口的常用方法
列举一些List接口的常用方法 List接口是Java集合框架中的一个核心接口,它定义了一个有序的集合(也称为序列)。List接口继承自Collection接口,因此它包含了Collection接口中定义的所有方法,同时还增加了一些特定的方法…...

mysql基础从头到尾快速梳理
MYSQL数据库学习 mysql的启动 net start mysql net stop mysql MYSQL客户端的连接 mysql -h 127.0.0.1 -p 3306 -u root -p SQL SQL通用语法 SQL语句可以单行或者多行书写,以分号结尾SQL语句可以使用空格/缩进来增强语句的可读性Mysql数据库的SQL语句不区分大…...

MySQL用心总结
大家好,好久不见,今天笔者用心一步步写一份mysql的基础操作指南,欢迎各位点赞收藏 -- 启动MySQL net start mysql-- 创建Windows服务 sc create mysql binPath mysqld_bin_path(注意:等号与值之间有空格) mysql -h 地址 -…...
电路设计(13)——生产线易拉罐自动计数装置的proteus仿真
1.设计要求 使用指定元件,用模电、数电等有关知识,设计并制作一个易拉罐饮料计数自动化的模拟装置。生产单位常采用红外自动计数装置,将装有饮料的易拉罐放在马达带动的传动带上,在传动带运动的过程中让每个易拉罐依次同一方向地穿…...
微服务-微服务Alibaba-Nacos 源码分析 (源码流程图)-2.0.1
客户端注册临时实例,GRPC处理 客户端服务发现 及订阅处理 客户端数据变换,数据推送,服务端集群服务数据同步...
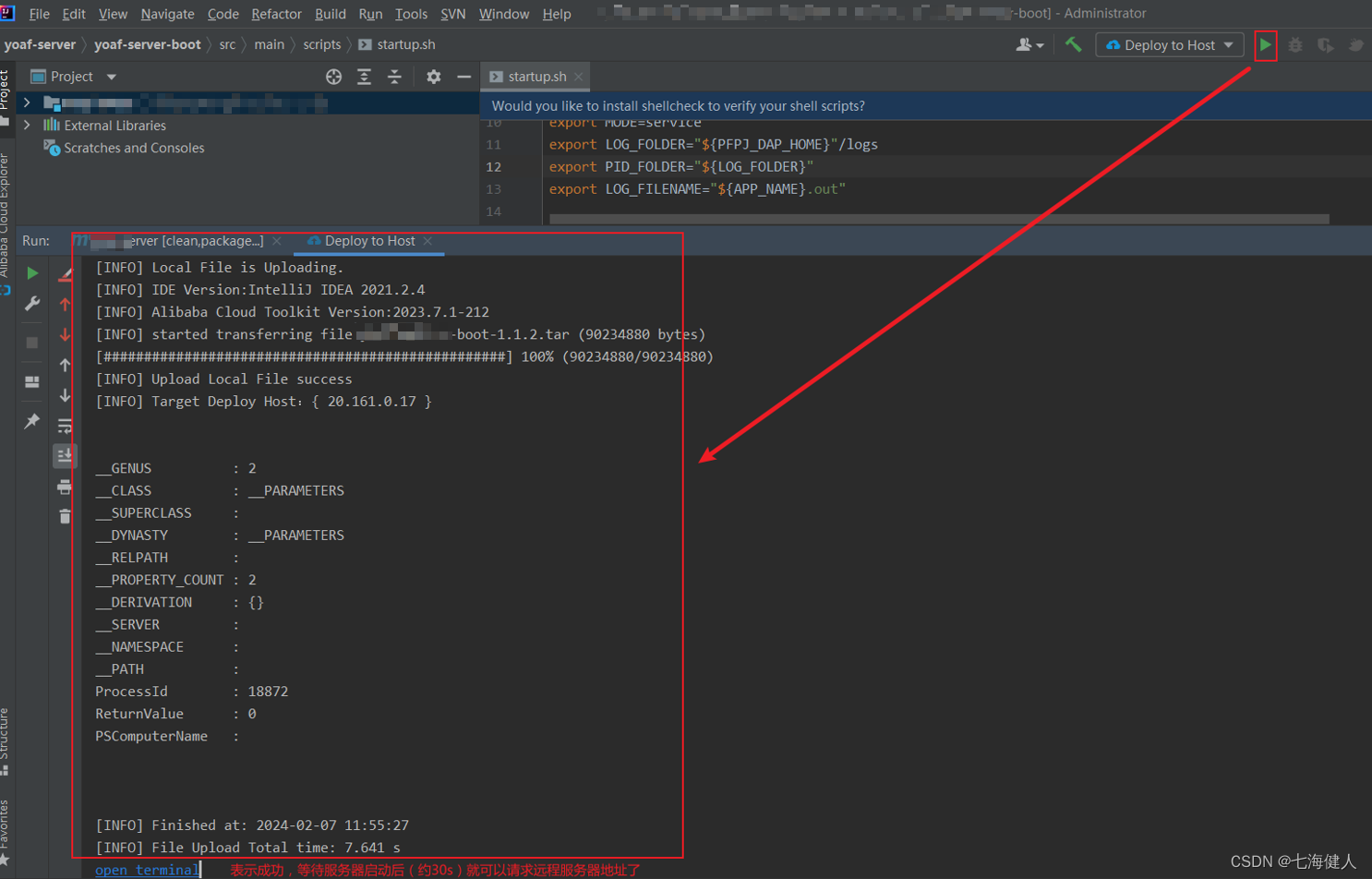
编码技巧——在项目中使用Alibaba Cloud Toolkit远程部署
背景 在新公司项目开发,当前项目为自建项目,意思是从开发到运维都需要自己负责,远程的服务器也是自己搭建的win操作系统; 之前在大厂工作时,一般提交代码之后,CICD流水线会自动的执行最新代码的拉取、构建打…...

深度学习如何入门?
深度学习是一个广泛且深入的领域,入门需要一些基础知识和学习资源。以下是一些推荐的步骤和资源: 数学基础:深度学习需要一些数学基础,包括线性代数、微积分、概率论和统计学。这些都是理解深度学习算法背后的原理的关键。 编程基…...
终面算法原题)
米哈游(原神)终面算法原题
恒大正式破产 准确来说,是中国恒大(恒大汽车、恒大物业已于 2024-01-30 复牌)。 恒大破产,注定成为历史的注目焦点。 作为首个宣布破产的房地产企业,恒大的破产规模也创历史新高。 房地产作为曾推动中国三分之一经济增…...

机器学习如何改变缺陷检测的格局?
机器学习在缺陷检测中扮演着重要的角色,它能够通过自动学习和识别各种缺陷的模式和特征,改变缺陷检测的格局。以下是机器学习在缺陷检测中的一些应用和优势: 自动化检测:机器学习技术可以自动化处理大量的数据,通过学…...

Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取
Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取 1. 项目背景与价值 对于中小企业而言,技术文档管理一直是个令人头疼的问题。工程师们经常需要从大量PDF、Word文档中提取关键信息,手动整理成结构化数据。这个过程…...

【学术干货免费领】200+学术海报模板免费领|科研展示零成本,高效出图不内耗 | 学术会议海报模板,适配国际国内各类学术场合 | 硕博研究生必需,全学科适配,助力科研成果高光出圈
重磅福利来袭!200学术海报模板,全程免费领取,零成本解锁科研展示新方式!适配以下各类科研相关人群:硕博研究生群体包括硕士研究生和博士研究生适用于不同研究阶段:从开题报告撰写到学位论文完成特别适合需要…...

StructBERT中文Large模型技术白皮书精读:结构化预训练策略深度解读
StructBERT中文Large模型技术白皮书精读:结构化预训练策略深度解读 1. 项目概述与核心价值 StructBERT是由阿里达摩院开发的中文预训练语言模型,它在经典BERT架构基础上引入了结构化预训练策略,显著提升了中文语言理解能力。这个模型特别针…...

如何通过FCEUX实现NES游戏的完美模拟?超实用指南
如何通过FCEUX实现NES游戏的完美模拟?超实用指南 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux 5个步骤3个技巧,让你快速掌握NES模拟器 核心价值:重温和探索经典游戏的最佳选择 …...

PWM技术原理与电机调速应用详解
PWM技术原理与电机调速应用详解1. PWM基础概念解析1.1 脉冲宽度调制定义PWM(Pulse Width Modulation)即脉冲宽度调制,是一种通过调节脉冲信号的宽度(占空比)来实现能量控制的电子电力技术。该技术在直流电机调速、开关电源、逆变器等电力电子领域有广泛应用。1.2 脉…...

提升开发效率与编码体验:开源字体LxgwWenKai跨平台配置全指南
提升开发效率与编码体验:开源字体LxgwWenKai跨平台配置全指南 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字形和TC旧字形…...

收藏!小白也能看懂的大模型如何改写工业效率?
收藏!小白也能看懂的大模型如何改写工业效率? 本文介绍了中控技术的TPT大模型在工业生产中的应用,它通过实时监控、自动计算最优参数和风险预警,帮助企业提升效率、降低成本。与互联网领域的AI应用不同,工业AI的价值更…...

Vivado初始化设计慢?可能是这3个隐藏设置惹的祸
Vivado初始化设计慢?可能是这3个隐藏设置惹的祸 当你在深夜赶项目进度,Vivado却卡在"Initializing Design"界面转圈超过15分钟,那种焦虑感堪比考试时笔没水。作为Xilinx FPGA开发的核心工具,Vivado的初始化速度直接影响…...

ClawdBot实战教程:零基础搭建个人AI助手的完整流程
ClawdBot实战教程:零基础搭建个人AI助手的完整流程 1. ClawdBot简介:你的本地AI助手 ClawdBot是一个可以在个人设备上运行的AI助手解决方案,基于vLLM提供后端模型能力。与常见的云端AI服务不同,它完全运行在本地环境中ÿ…...

基于模糊PID的水下航行器运动控制系统研究——Matlab 2016b及以上软件应用、课程报告...
基于模糊PID的水下航行器运动控制系统研究 1.适用软件Matlab 2016b及以上 2.课程报告6500字左右共16页 3.课程报告小报告仿真仿真视频 4.请结合以下图片水下航行器的运动控制一直是海洋工程领域的热门课题。面对复杂多变的洋流扰动和强非线性的水动力特性,传统PID控…...