Hive调优——合并小文件
目录
一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量
3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐)
3.2.2 方式二:concatenate
3.2.3 方式三:使用hive的archive归档
3.2.4 方式四:hadoop getmerge
一、小文件产生的原因
- 数据源本身就包含大量的小文件,例如api,kafka消息管道等。
- 动态分区插入数据的时候,会产生大量的小文件,从而导致map数量剧增;;
- reduce 数量越多,小文件也越多,小文件数量=ReduceTask数量*分区数;
- hive中的小文件是向 hive 表中导入数据时产生;
向 hive 中导入数据的几种方式:
(1)直接向表中插入数据
insert into table t_order2 values (1,'zhangsan',88),(2,'lisi',61);这种方式每次插入时都会产生一个小文件,多次插入少量数据就会出现多个小文件,故这种方式生产环境基本不使用;
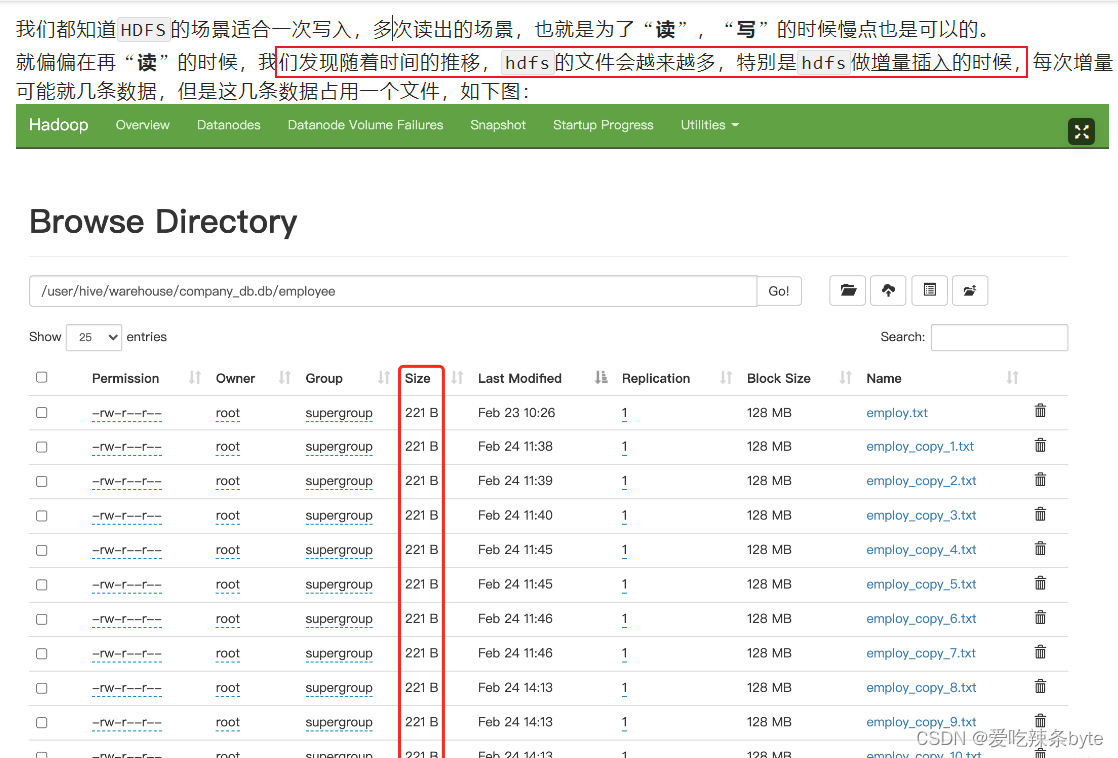
(2)通过load方式加载数据
-- 导入文件
load data local inpath "/opt/module/hive_data/t_order.txt" overwrite into table t_order;
-- 导入文件夹
load data local inpath "/opt/module/hive_data/t_order" overwrite into table t_order;使用 load方式可以导入文件或文件夹,当导入一个文件时,hive表就有一个文件,当导入文件夹时,hive表的文件数量为文件夹下所有文件的数量;
(3)通过查询方式加载数据
insert overwrite t_order select oid,uid from t_order2这种方式是生产环境中经常用的,也是最容易产生小文件的方式。insert 导入数据时会启动MR任务,MR-reduce的个数与输出文件个数一致。
因此,hdfs的文件数量= reduceTask数量* 分区数,有些fetch本地抓取任务(例如:简单的 select * from tableA)仅有map阶段,那此时文件个数 = mapTask数量*分区数
二、小文件的危害
小文件通常是指文件大小要比HDFS块大小(一般是128M)还要小很多的文件。
-
NameNode在内存中维护整个文件系统的元数据镜像、其中每个HDFS文件元数据信息(位置、大小、分块等)对象约占150字节,如果小文件过多会占用大量内存,会直接影响NameNode性能。相对的,HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立pipeline连接。
- 从 Hive 角度看,一个小文件会开启一个 MapTask,一个 MapTask开一个 JVM 去执行,这些任务的启动及初始化,会浪费大量的资源,严重影响性能。
三、小文件的解决方案
小文件的解决思路主要有两个方向:1.小文件的预防;2.已存在的小文件合并
3.1 小文件的预防
通过调整参数进行合并,在 hive 中执行 insert overwrite tableA select xx from tableB 之前设置如下合并参数,即可自动合并小文件。
3.1.1 减少Map数量
在Map前进行输入合并,从而减少mapper任务的数量。
- 设置map输入时的合并参数:
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split切片作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认#每个Map最大的输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256*1000*100; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100*100*100; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100*100*100; -- 100M- 设置map端输出时和reduce端输出时的合并参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M- 启用压缩(小文件合并后,也可以选择启用压缩)
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
3.1.2 减少Reduce的数量
#reduce的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#通过设置reduce的数量,利用distribute by使得数据均衡的进入每个reduce。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;#第二种是设置每个reduceTask的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=512*1000*1000; -- 默认是1G,这里为设置为5G#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;insert overwrite table A partition(dt)
select * from B
distribute by cast(rand()*10 as int);解释:如设置reduce数量为10,则使用cast(rand()*10 as int),生成0-10之间的随机整数,根据【随机整数 % 10】计算分区编号,这样数据就会均衡的分发到各reduce中,防止出现有的文件过大或过小3.2 已存在的小文件合并
对集群上已存在的小文件进行定时或实时的合并操作,定时操作可在访问低峰期操作,如凌晨2点,合并操作主要有以下几种方式:
3.2.1 方式一:insert overwrite (推荐)
执行流程总体如下:
(1)创建备份表(创建备份表时需和原表的表结构一致)
create table test.table_hive_back like test.table_hive ;(2)设置合并文件相关参数,并使用insert overwrite 语句读取原表,再插入备份表
- 设置合并文件相关参数
使用 hive的merger合并参数,在正式 insert overwrite 之前做一个合并,合并的时候注意设置好压缩,不然文件会比较大。
- 合并文件至备份表中,执行前保证没有数据写入原表
#如果有多级分区,将分区名放到partition中
insert overwrite table test.table_hive_back partition(batch_date)
select * from test.table_hive;
ps:insert overwrite table test.table_hive_back 备份表的时候,可以使用distribute by 命令设置合并后的batch_date分区下的文件数据量
insert overwrite table 目标表 [partition(hour=...)] select * from 目标表
distribute by cast( rand() * 具体最后落地生成多少个文件数 as int);
insert overwrite:会重写数据,先进行删除后插入(不用担心如果overwrite失败,数据没了,这里面是有事务保障的);
distribute by分区:能控制数据从map端发往到哪个reduceTask中,distribute by的分区规则:分区字段的hashcode值对reduce 个数取模后, 余数相同的数据会分发到同一个reduceTask中。
rand()函数:生成0-1的随机小数,控制最终输出多少个文件。
# 使用distribute by rand()将数据随机分配给reduce,这样可以使得每个reduce处理的数据大体一致。 避免出现有的文件特别大, 有的文件特别小,例如:控制dt分区目录下生成100个文件,那么hsql如下:
insert overwrite table A partition(dt)select * from B
distribute by cast(rand()*100 as int);#cast(rand()*100 as int) 可以生成0-100的随机整数如果合并之后的文件竟然还变大了,可能是 select from的原数据是被压缩的,但是insert overwrite目标表的时候,没有设置输出文件压缩功能,解决方案:
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
(3)确认表数据一致后,将原表修改名称为临时表tmp,将备份表修改名称为原表
- 先查看原表和备份表数据量,确保表数据一致
#查看原表和备份表数据量
set hive.compute.query.using.stats=false ;
set hive.fetch.task.conversion=none;
SELECT count(*) FROM test.table_hive;
SELECT count(*) FROM test.table_hive_back ;- 将原表修改名称为临时表tmp,将备份表修改名称为原表
alter table test.table_hive rename to test.table_hive_tmp;
alter table test.table_hive_back rename to test.table_hive ;(4)查看合并后的分区数和小文件数量
正常情况下:hdfs文件系统上的table_hive表的分区数量没有改变,但是每个分区的几个小文件已经合并为一个文件。
#统计合并后的分区数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive
#统计合并后的分区数下的文件数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive/batch_date=20210608例如:

(5)观察一段时间后再删除临时表
drop table test.table_hive_tmp ;
ps:注意修改hive表名的时候,对应表的存储路径会发生变化,如果有新的任务上传数据到具体路径,需要注意可能需要修改。
3.2.2 方式二:concatenate
对于orc文件,可以使用hive自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table test concatenate;#对于分区表
alter table test [partition(...)] concatenate
#例如:alter table test partition(dt='2021-05-07',hr='12') concatenate;注意:
- concatenate 命令只支持 rcfile和 orc文件类型。
- concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
- 当多次使用concatenate后文件数量不变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
3.2.3 方式三:使用hive的archive归档
每日定时脚本,对于已经产生小文件的hive表使用har归档,然后已归档的分区不能insert overwrite ,必须先unarchive
#用来控制归档是否可用
set hive.archive.enabled=true;#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;#控制需要归档文件的大小
set har.partfile.size=256000000;#对表的某个分区进行归档
alter table test_rownumber2 archive partition(dt='20230324');#对已归档的分区恢复为原文件
alter table test_rownumber2 unarchive partition(dt='20230324');
3.2.4 方式四:hadoop getmerge
对于txt格式的文件可以使用hadoop getmerge命令来合并小文件。使用 getmerge 命令先合并数据到本地,再通过put命令回传数据到hdfs。
- 将hdfs上分区为pdate=20220815,文件路径为 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* 下载到linux 本地进行合并文件,本地路径为:/home/hadoop/pdate/20220815
hadoop fs -getmerge /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* /home/hadoop/pdate/20220815;
- 将hdfs源分区数据删除
hadoop fs -rm /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
- 在hdfs上新建分区
hadoop fs -mkdir -p /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815
- 将本地合并后的文件回传到hdfs上
hadoop fs -put /home/hadoop/pdate/20220815 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
参考文章:
HIVE中小文件问题_hive小文件产生的原因-CSDN博客
Hive教程(09)- 彻底解决小文件的问题-阿里云开发者社区
0704-5.16.2-如何使用Hive合并小文件-腾讯云开发者社区-腾讯云
相关文章:
Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...
责任链模式)
设计模式(行为型模式)责任链模式
目录 一、简介二、责任链模式2.1、处理器接口2.2、具体处理器类2.3、使用 三、优点与缺点 一、简介 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,允许你将请求沿着处理者链进行传递,直到有一个处理者能够处理…...
HTTP和HTTPS区别!
http 是我们几乎天天都要打交道的东西,相关知识点有点多,所以也有不少面试必问的点,这里做了一些整理,帮且大家树立完整的 http 知识体系,对面试官说 so easy HTTP 的特点和缺点 特点:无连接、无状态、灵…...
)
麻将普通胡牌算法(带混)
最近在玩腾讯的麻将游戏,但是经常需要充值,于是就想自己实现一个简单的单机麻将游戏.第一个难点就是实现胡牌的判断.这里写一下心得. 术语 本文的胡牌是指手牌构成了3N2的牌型,即一对做将,剩下的牌均为刻子(3张一样的牌)或者顺子(3张连续的牌比如234饼). 下面就是一个14张牌…...

Rust结构体详解:定义、使用及方法
Rust 是一门强调安全性和性能的系统级编程语言,它引入了结构体(struct)作为一种自定义的数据类型,允许程序员以更加灵活的方式组织和操作数据。在本篇博客中,我们将深入探讨 Rust 结构体的定义、使用以及相关概念。 什…...
LeetCode、435. 无重叠区间【中等,贪心 区间问题】
文章目录 前言LeetCode、435. 无重叠区间【中等,贪心 区间问题】题目链接及分类思路贪心、区间问题 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技…...
 —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三))
【实战】一、Jest 前端自动化测试框架基础入门(三) —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三)
文章目录 一、Jest 前端自动化测试框架基础入门7.异步代码的测试方法8.Jest 中的钩子函数9.钩子函数的作用域 学习内容来源:Jest入门到TDD/BDD双实战_前端要学的测试课 相对原教程,我在学习开始时(2023.08)采用的是当前最新版本&a…...

信息学奥赛一本通1228:书架
1228:书架 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 18190 通过数: 10557 【题目描述】 John最近买了一个书架用来存放奶牛养殖书籍,但书架很快被存满了,只剩最顶层有空余。 John共有N�头奶牛(1≤N≤20,0001≤…...

红队打靶练习:GLASGOW SMILE: 1.1
目录 信息收集 1、arp 2、nmap 3、nikto 4、whatweb 目录探测 1、gobuster 2、dirsearch WEB web信息收集 /how_to.txt /joomla CMS利用 1、爆破后台 2、登录 3、反弹shell 提权 系统信息收集 rob用户登录 abner用户 penguin用户 get root flag 信息收集…...

网络安全的今年:量子、生成人工智能以及 LLM 和密码
尽管世界总是难以预测,但网络安全的几个强劲趋势表明未来几个月的发展充满希望和令人担忧。有一点是肯定的:2024 年将是非常重要且有趣的一年。 近年来,人工智能(AI)以令人难以置信的速度发展,其在网络安全…...

【FPGA】Verilog:奇偶校验位发生器 | 奇偶校验位校验器
目录 0x00 奇偶校验位发生器 0x01 奇偶校验位校验器 0x02 错误检测器和纠错器...

【心得】关于STM32中RTC的校准方法
最近看了一些关于RTC校准的帖子,发现很多人存在疑惑。正好最近我也在STM32中实现了RTC校准。发些心得。这些对老手来说有些罗索,但对新手有益处。 实现RTC 校准的核心之一是库文件Stm321f0x_bkp.c中的void BKP_SetRTCCalibrationValue (uint8_t Calibra…...

消息中间件面试篇
目录 消息中间件 RabbitMQ 消息不丢失 生产者确认机制 消息持久化 交换机持久化 队列持久化 消息持久化 消费者确认 消息重复消费 出现的场景 解决方案 每条消息设置一个唯一的标识id 幂等方案:【 分布式锁、数据库锁(悲观锁、乐观锁&#…...
)
【MySQL】-20 MySQL综合-6(MySQL创建数据表+MySQL修改数据表+MySQL删除数据表)
MySQL创建数据表MySQL修改数据表MySQL删除数据表 MySQL创建数据表基本语法在指定的数据库中创建表查看表结构 MySQL修改数据表基本语法添加字段修改字段数据类型删除字段修改字段名称修改表名 MySQL删除数据表基本语法删除表 MySQL创建数据表 在创建数据库之后,接下…...

linux查看当前连接的IP
linux下查询当前所有连接的ip_linux查看某个ip的连接-CSDN博客 netstat -ntu | grep tcp | awk {print $5} | cut -d: -f1 | sort | uniq -c | sort -nr...
洛谷_P1923 【深基9.例4】求第 k 小的数_python写法
哪位大佬可以出一下这个的题解?????话说蓝桥杯可以用numpy库吗?????? 这道题有一个很简单的思路就是排序完成之后再访问。 but有很大的问题&…...

【MySQL】学习约束和使用图形化界面创建表
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-iqtbME2KmWpQFQSt {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...
之四十八:pixman编译(Windows、Linux、MacOS环境下编译))
QGIS编译(跨平台编译)之四十八:pixman编译(Windows、Linux、MacOS环境下编译)
文章目录 一、pixman介绍二、pixman下载三、Linux下编译四、MacOS下编译五、Windows下编译一、pixman介绍 Pixman 是一个开源的图形库,它提供了底层像素操作功能,包括像素格式转换、图像合成、图像缩放、图像旋转等多种操作。Pixman 主要被用作 Cairo 图形库的后端,支持 Ca…...

华为数通方向HCIP-DataCom H12-821题库(单选题:441-460)
第441题 下面是一台路由输出的信息,关于这段信息描述正确的是 <R1>display bgp peerBGP local router ID : 2.2.2.2Local AS number : 100Total number of peers : 2 Peers in established state : 0Peer V AS MsgRcvd MsgSent OutQ Up/Down …...

【sass】 中使用 /deep/ 修改 elementUI 组件样式报错
element plus 想要覆盖组件的样式,想到了/deep/样式穿透,但样式一直不生效,代码如下: <style scoped lang"sass"> .main_wrapper{padding: 0 53pxposition: relativetop: -20px } >>> .el-tabs__item{h…...

UVM验证效率提升:利用仿真器保存恢复机制消除冗余配置周期
1. 验证环境中的冗余周期之痛:一个普遍存在的效率瓶颈在芯片验证领域,尤其是使用UVM(Universal Verification Methodology)构建的复杂验证环境中,我们常常会面临一个看似不起眼、实则消耗巨大的问题:冗余的…...

别再死记硬背公式了!用VisionMaster的N点标定,手把手教你搞定相机和机械手‘对齐’
视觉标定实战:用工具思维破解N点标定难题 在工业自动化领域,相机与机械手的协同工作就像两个语言不通的人试图完成精密舞蹈——标定就是为他们建立共同的坐标系词典。传统教材常将标定过程简化为数学公式的堆砌,导致许多工程师陷入"会推…...

从无人机云台到机械臂关节:聊聊FOC力矩控制在机器人里的那些实战坑
从无人机云台到机械臂关节:FOC力矩控制在机器人中的实战精要 当无人机云台在强风中依然保持画面稳定,当机械臂关节能够感知鸡蛋壳的脆弱并精准施力——这些看似简单的动作背后,都离不开一项关键技术:磁场定向控制(FOC&…...
)
用C++模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码)
用C模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码) 流感传播模型一直是计算机模拟和算法竞赛中的经典问题。这道来自信息学奥赛的题目不仅考察了递推算法的应用,更让我们得以一窥传染病传播的基本原理。本文将带你从零…...
)
STM32单片机引脚功能详解——从GPIO到AFIO的标准库配置指南(硬件总结四)
前言 在STM32的开发中,引脚是MCU与外部电路交互的物理桥梁。STM32F103C8T6这款经典的Cortex-M3单片机在LQFP48封装下仅有48个引脚,却能支持GPIO、ADC、USART、SPI、I2C、定时器、USB等多种外设功能——这得益于其灵活的多功能引脚复用机制。深入理解引脚…...

Layerdivider:5步完成AI智能图像分层,免费生成专业PSD文件
Layerdivider:5步完成AI智能图像分层,免费生成专业PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款革命…...

从MySQL到Neo4j:用你熟悉的SQL思维,快速上手CQL创建第一个知识图谱
从MySQL到Neo4j:用SQL思维快速构建知识图谱的实战指南 当你在MySQL中熟练编写JOIN查询时,是否想过这些表关系本质上就是一张网?图数据库将这种网状关系作为一等公民,而Neo4j正是这个领域的佼佼者。本文会带你用熟悉的SQL视角&…...

LeetCode 前K个高频元素题解
LeetCode 前K个高频元素题解 题目描述 给定一个数组,找到前 k 个高频元素。 示例: 输入:nums [1,1,1,2,2,3], k 2输出:[1,2] 解题思路 方法:堆 思路: 使用哈希表统计每个元素出现的次数。使用最小堆维护前…...

UE5 Niagara实战:手把手教你用自定义模块实现粒子间的实时位置同步
UE5 Niagara实战:用自定义模块构建粒子间的动态位置同步系统 在实时视觉效果开发中,粒子系统间的交互一直是提升场景动态表现力的关键。当两个发射器的粒子需要建立位置关联时——比如魔法飞弹追踪目标、萤火虫群集飞行或者流体颗粒间的引力作用——直接…...
)
618激战正酣!用易元AI备齐整个大促的千川全域推广素材(附1000套模板免费领)
618进入激战阶段后,千川全域推广已经不是“要不要投”的问题,而是素材能不能持续供给的问题。预算可以临时加,计划可以快速开,但素材如果准备不足,账户很快就会遇到消耗跑不动、ROI波动、爆款衰退、计划空转这些老问题…...