python从入门到精通(十六):python爬虫的BeautifulSoup4
python爬虫的BeautifulSoup4
- BeautifulSoup4
- 导入模块
- 解析文件
- 创建对象
- python解析器
- beautifulsoup对象的种类
- Tag获取整个标签
- 获取标签里的属性和属性值
- Navigablestring 获取标签里的内容
- BeautifulSoup获取整个文档
- Comment输出的内容不包含注释符号
- BeautifulSoup文档遍历
- BeautifulSoup文档搜索
BeautifulSoup4
导入模块
from bs4 import BeautifulSoup
解析文件
如果是本地文件,直接以写入权限打开,并用bs解析
with open('index.html', 'r', encoding='utf-8') as f:html = f.read()
如果是网页文件,则需要先用爬虫爬取,然后解析
response = requests.get(url=url, headers=headers)
html = response.text
创建对象
解析的第一步,是构建一个BeautifulSoup对象,基本用法:
response = requests.get(url=url, headers=headers)
html = response.text
soup = beautifulsoup(html,'html.parser') #处理html的解析器
python解析器
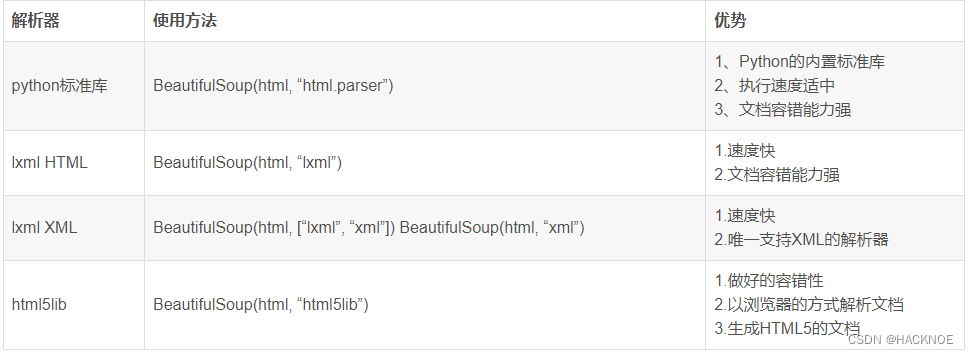
soup = beautifulsoup(html,'html.parser')
soup = beautifulsoup(html,'lxml')
soup = beautifulsoup(html,'xml')
beautifulsoup对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag获取整个标签
tag中最重要的属性:name和attributes
from bs4 import BeautifulSoup
# 逐一解析数据 把html使用html.parser进行解析
bs = BeautifulSoup(html,"html.parser")
print(bs.a) # 返回找到的第一个a标签,返回时的整个标签 Tag
print(bs.title)
<title>百度一下你就知道<title>
获取标签里的属性和属性值
bs = BeautifulSoup(html,"html.parser")
print(soup.head.name) # name 返回标签的名字#head
print(bs.a.attrs) # 返回找到的第一个title标签的属性和属性值,字典形式
{'href': 'https://accounts.douban.com/passport/login?source=movie', 'class': ['nav-login'], 'rel': ['nofollow']}
print(bs.a.attrs['href']) #查看某个属性的值
'https://accounts.douban.com/passport/login?source=movie'# 获取p标签的属性
bs.a.attrs(返回字典) or soup.p.attrs['class'](class返回列表,其余属性返回字符串)
bs.a.['class'](class返回列表,其余属性返回字符串)
bs.a.get('class')(class返回列表,其余属性返回字符串)
Navigablestring 获取标签里的内容
bs = BeautifulSoup(html,"html.parser")
print(bs.title.string) # 返回找到的第一个title标签的内容 字符串
百度一下你就知道
bs.title.string
bs.title.text
bs.title.get.text()
BeautifulSoup获取整个文档
bs = BeautifulSoup(html,"html.parser")
print(bs) # 返回整个文档的内容
Comment输出的内容不包含注释符号
soup = BeautifulSoup('<p class="t1"><!-- <div class="env">env的信息内容</div> --></p>', 'html.parser')
print(soup.p.string)
#如果标签内部的内容是注释,例如:<!-- -->;那么该NavigableSring对象会转换成Comment对象,并且会把注释符号去掉。
<div class="env">env的信息内容</div>
BeautifulSoup文档遍历
contens:获取所有子节点(仅仅获取子标签)
bs = BeautifulSoup(html,"html.parser")
print(bs.a.contens) # 返回a中的所有contens 列表形式 可以用列表遍历
print(bs.a.contens[2])
children:获取所有子节点(仅仅获取儿子),返回列表生成器,用于遍历
or child in soup.body.children:print(child)
descendants:获取所有子孙节点(获取全部子孙后代),返回列表生成器,用于遍历
for child in soup.body.descendants:print(child)
parent:返回某节点的直接父节点(仅仅获取父亲)
p = soup.p
print(p.parent.name)
#body
parents:返回某节点的所有父辈及以上辈的节点(父亲的父亲的父亲…都获取)
content = soup.head.title.string
for parent in content.parents:print(parent.name)
## 结果
title
head
html
[document]
next_sibling:获取该节点的下一个兄弟节点,结果通常是字符串或空白,因为空白或者换行也可以被视作一个节点。
previous_sibling:获取该节点的上一个兄弟节点。
print(soup.p.next_sibling)
# 实际该处为空白
print(soup.p.prev_sibling)
#None 没有前一个兄弟节点,返回 None
next_siblings:迭代获取该节点之前的全部兄弟节点。
next_siblings:迭代获取该节点之后的全部兄弟节点。
BeautifulSoup文档搜索
1.find()
查找第一个与字符串完全匹配的内容
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a") # 查找第一个的a标签
返回一个对象
a_list = bs.find('a')
a_list = bs.find('a', class_='xxx') # 注意class后的下划线
a_list = bs.find('a', title='xxx')
a_list = bs.find('a', id='xxx')
a_list = bs.find('a', id=compile(r'xxx'))
2.find_all()
字符串过滤,会查找所有与字符串完全匹配的内容
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find_all("a") # 查找所有的a标签
a_list = bs.find_all('a')
a_list = bs.find_all(['a','span']) #返回所有的a和span标签
a_list = bs.find_all('a', class_='xxx')
a_list = bs.find_all('a', id=compile(r'xxx'))
# 提取出前两个符合要求的
soup.find_all('a', limit=3)
3.find_parent
查找当前标签的父标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_parent('div') # 查找当前a标签的父div标签
4.find_next_sibling
查找当前标签的下一个兄弟标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_next_sibling('div') # 查找当前a标签的下一个div标签
5.find_previous_sibling
查找当前标签的前一个兄弟标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_previous_sibling('div') # 查找当前a标签的前一个div标签
2.search()
正则表达式搜索:使用search()方法来匹配内容
a_list = bs.find_all(re.compile("a"))
3.get_text()
获取标签内的文本内容
a_list = bs.find("a").get_text()
3.prettify()
格式化解析文本 自动为标签间添加换行符
soup = BeautifulSoup(ht, 'lxml')
soup.prettify()
3.自己写方法查询
def name_is_exists(tag):return tag.has_attr("name") # 查询标签中属性的名字为name的t_list = bs.find_all(name_is_exists)
for tag in t_list:print(tag)
4.kwargs 参数
t_list = bs.find_all(id="head") # 查找所有的id=head的标签
t_list = bs.find_all(class=True)
t_list = bs.find_all(herf="http://news.baidu.com")
5.text参数
t_list = bs.find_all(text="hao123") # 查找所有的id=head的标签
t_list = bs.find_all(text=["hao123","新闻","贴吧"])
for tag in t_list:print(tag)
t_list = bs.find_all(text = re.compile("\d")) # 应用正则表达式来查找包含特定文本的内容
6.limit参数
t_list = bs.find_all("a",limit=3) # 查找前三个a标签
7.css选择器
t_list = bs.select("a") # 查找所有的a标签
t_list = bs.select(".mnav") # 查找所有的类名为.mnav标签
t_list = bs.select("#u1") # 查找所有的id为#u1的标签
t_list = bs.select("a[class='bri']") # 查找属性为bri的标签
t_list = bs.select("head>title") # 查找head标签下的title标签
t list = bs.select(".mnav ~ .bri") # 查找.mnav的兄弟标签.bri的text
print(t_list[0].get_text())
相关文章:
python从入门到精通(十六):python爬虫的BeautifulSoup4
python爬虫的BeautifulSoup4 BeautifulSoup4导入模块解析文件创建对象python解析器beautifulsoup对象的种类Tag获取整个标签获取标签里的属性和属性值Navigablestring 获取标签里的内容BeautifulSoup获取整个文档Comment输出的内容不包含注释符号BeautifulSoup文档遍历Beautifu…...

Codeforces Round 924(Div.2) A~E
A.Rectangle Cutting (模拟) 题意: 给出一个长方形,通过平行于原始矩形的一条边进行切割,将该矩形切割成两个边长为整数的矩形。询问是否能通过旋转和移动这两个矩形,得到新的矩形。 分析: 可以发现拼成的新长方形…...

django中实现观察者模式
在Django中实现观察者模式,你可以利用Django的信号(Signals)系统。Django的信号提供了一种发布/订阅模型,允许解耦应用程序组件之间的交互。一个组件可以发送一个信号,而其他组件可以监听这个信号并响应它。 下面是如…...

Elasticsearch中的动态DSL解决方案
目录 问题背景 解决方案 编写es的mapper 动态dsl编写 使用mapper获取动态dsl 远程调用restful api查询 问题背景 在大数据量的业务系统中,一般都会引入Elasticsearch来作为搜索引擎,而搜索的条件又是多种多样的。回顾下,如果是mysql等…...
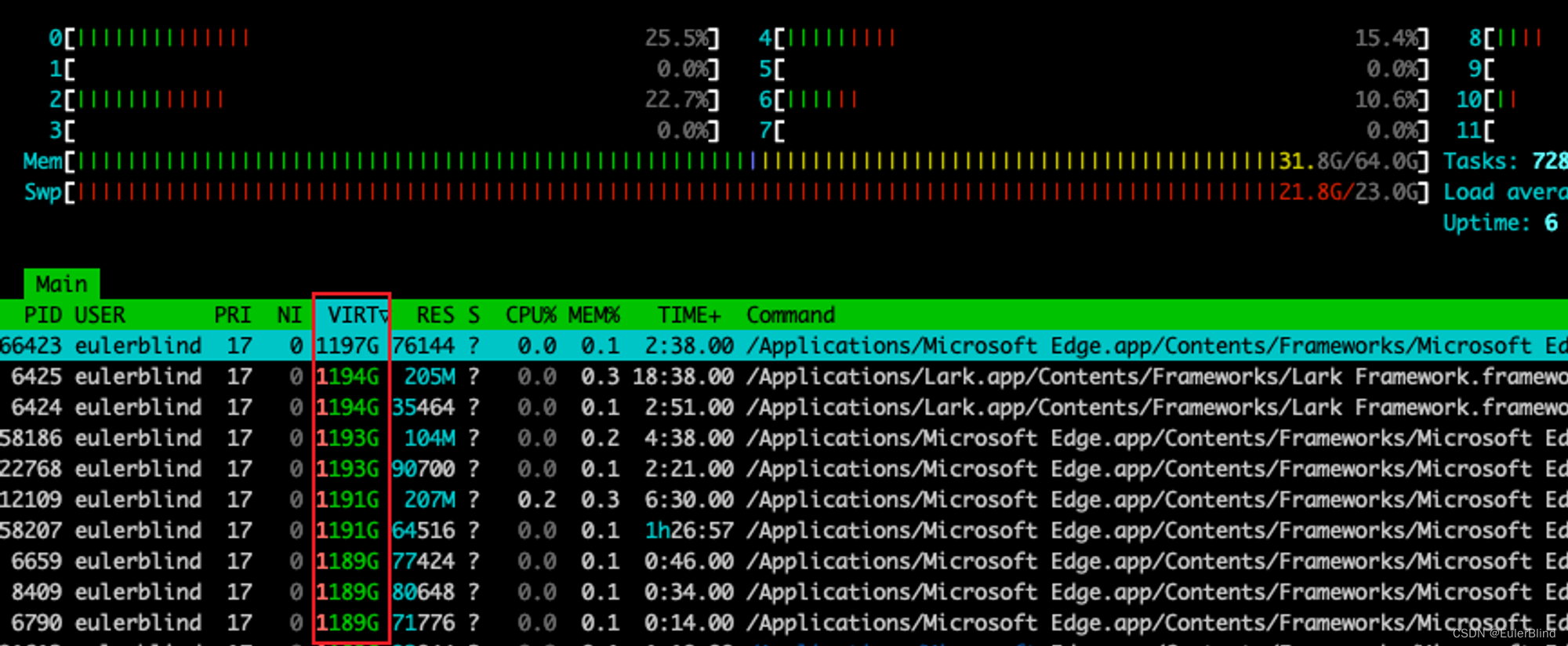
【操作系统】MacOS虚拟内存统计指标
目录 命令及其结果 参数解读 有趣的实验 在 macOS 系统中,虚拟内存统计指标提供了对系统内存使用情况和虚拟内存操作的重要洞察。通过分析这些指标,我们可以更好地了解系统的性能状况和内存管理情况。 命令及其结果 >>> vm_stat Mach Virtu…...

LeetCode:67.二进制求和
67. 二进制求和 - 力扣(LeetCode) 又是一道求和题,% / 在求和的用途了解了些, 目录 题目: 思路分析: 博主代码: 官方代码: 每日表情包: 题目: 思路分析…...

修改GI文件的权限
参考文档: How to check and fix file permissions on Grid Infrastructure environment (Doc ID 1931142.1) -- 验证二进制文件的权限 [gridnode19c01 ~]$ cluvfy comp software -n node19c01 -verbosePerforming following verification checks ...Software …...
OJ刷题:杨氏矩阵【建议收藏】
看见这个题目,很多人的第一反应是遍历整个数组查找数字,但是这种方法不仅效率低,而且远远不能满足题目要求。下面介绍一种高效的查找方法: 代码实现: #include <stdio.h>int Yang_Find_Num(int arr[][3], int …...
2024-02-13 Unity 编辑器开发之编辑器拓展4 —— EditorGUIUtility
文章目录 1 EditorGUIUtility 介绍2 加载资源2.1 Eidtor Default Resources2.2 不存在返回 null2.3 不存在则报错2.4 代码示例 3 搜索框查询、对象选中提示3.1 ShowObjectPicker3.2 PingObject3.3 代码示例 4 窗口事件传递、坐标转换4.1 CommandEvent4.2 GUIPoint 和 ScreenPoi…...

redis加锁实现方式
思考 是否有官方推荐(自己先思考如何实现,然后再参考其他人的实践,总结优缺点)通过哪些方式可以实现锁锁是否具有原子性锁请求失败了如何处理如果避免发生死锁如果避免发生资源抢占如果避免锁的误删 官方实现策略 安全性能&#…...

ClickHouse--08--SQL DDL 操作
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 SQL DDL 操作1 创建库2 查看数据库3 删除库4 创建表5 查看表6 查看表的定义7 查看表的字段8 删除表9 修改表9.1 添加列9.2 删除列9.3 清空列9.4 给列修改注释9.5 修…...
5种风格非常经典的免费wordpress主题
免费wordpress主题下载 高端大气上档次的wordpress主题,也可以是免费的,可以在线免费下载。 https://www.wpniu.com/themes/288.html wordpress免费主题 高端大气的wordpress免费主题,LOGO在顶部左侧,导航菜单在顶部右侧。 ht…...

「数据结构」哈希表2:实现哈希表
🎇个人主页:Ice_Sugar_7 🎇所属专栏:Java数据结构 🎇欢迎点赞收藏加关注哦! 实现哈希表 🍉扩容🍉插入🍉获取value🍉源码 🍉扩容 在讲插入之前需要…...
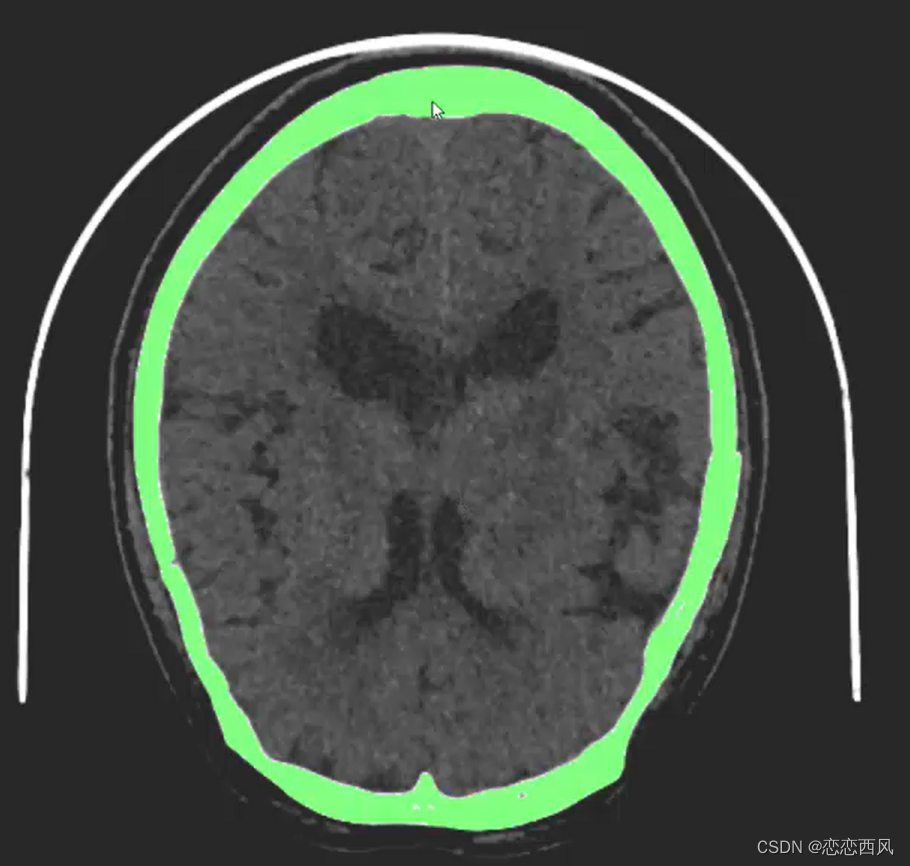
ITK 图像分割(一):阈值ThresholdImageFilter
效果: Video: 区域增加分割 1、itkThresholdImageFilter 该类的主要功能是通过设置低阈值、高阈值或介于高低阈值之间,则将图像值输出为用户指定的值。 如果图像值低于、高于或介于设置的阈值之间,该类就将图像值设置为用户指定的“外部”值…...

2023.2.6
#include<stdio.h> #include<string.h> //冒泡排序 void bubb(int arr[],int len) {for(int i1;i<len;i){for(int j0;j<len-i1;j){if(arr[j1]<arr[j]){int tarr[j];arr[j]arr[j1];arr[j1]t;}}} } //select排序 void select(int arr[],int len) {int min0;…...
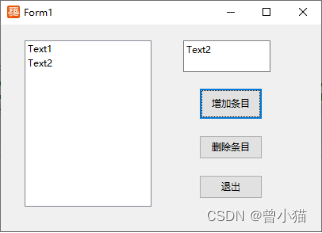
例39:使用List控件
建立一个EXE工程,在窗体上放一个文本框,一个列表框和三个按钮输入如下的代码: Sub Form1_Command1_BN_Clicked(hWndForm As hWnd, hWndControl As hWnd)List1.AddItem(Text1.Text)End SubSub Form1_Command2_BN_Clicked(hWndForm As hWnd, h…...

浏览器内核的主要功能模块介绍
浏览器内核是浏览器的核心部分,负责解析网页内容、渲染页面和处理用户交互。一个典型的浏览器内核主要包括以下几个功能模块: 1. **解析器(Parser)**: 解析器负责解析网页内容,包括HTML…...
如何流畅进入Github
前言 以下软件是免费的,放心用 一、进入右边的下载链接https://steampp.net/ 二、点击下载 三、点击接受并下载 四、随便选一个下载链接进行下载 五、软件安装好打开后,找到Github 六、点击全部启用 七、再点击左上角的一键加速 八、这个时候你再进Git…...

docker磁盘不足!已解决~
目录 🍟1.查看docker镜像目录 🧂2.停止docker服务 🥓3.创建新的目录 🌭4.迁移目录 🍿5.编辑迁移的目录 🥞6.重新加载docker 🍔7.检擦docker新目录 🍳8.删掉旧目录 1.查看doc…...

法国实习面试——计算机相关专业词汇
法语 1.Spcialit - 专业 2.Systme - 系统 3.Embarqus - 嵌入式 4.Logicielle - 软件 5.Distribus - 分布式 6.lectronique - 电子 7.nergie lectrique - 电能 8.Automatisation - 自动化 9.Une exprience de stage - 实习经验 10.Automobiles - 汽车 11.tre charg…...

openCode 是什么?你电脑里常驻的 AI 开发搭档
凌晨一点,你正在改一个棘手的 Bug。 控制台里报错信息刷了一屏,你盯着那段陌生的代码——是上周同事写的,没注释,没文档。你下意识选中代码,复制,打开浏览器,粘贴到 ChatGPT 的对话框里。 等等。…...

AndroidCupsPrint:构建企业级Android打印服务架构的技术实践
AndroidCupsPrint:构建企业级Android打印服务架构的技术实践 【免费下载链接】AndroidCupsPrint Port of cups4j to Android. Allows wireless printing from any Android device to any CUPS-enabled print server or network printer. 项目地址: https://gitcod…...

同样是芯片,为什么有的板子CPU强、有的GPU猛、还有的专门带NPU?三者到底怎么分工?日常选型怎么避坑?
做嵌入式开发、玩工控板、折腾端侧AI的朋友,大概率都纠结过一个问题:同样是芯片,为什么有的板子CPU强、有的GPU猛、还有的专门带NPU?三者到底怎么分工?日常选型怎么避坑?一、通俗拆解:CPU / GPU…...

C# 环境:深入解析与应用
C# 环境:深入解析与应用 引言 C#(读作“C Sharp”)是一种由微软开发的高级编程语言,广泛应用于Windows平台的应用程序开发。自从2002年推出以来,C#已经成为了全球开发者喜爱的编程语言之一。本文将深入解析C#环境,包括其特点、应用场景以及开发环境搭建等。 C#环境概述…...
添加远程桌面控制功能)
libvncserver实战:给你的嵌入式Linux设备(如树莓派)添加远程桌面控制功能
libvncserver嵌入式实战:为树莓派等设备构建轻量级远程桌面方案 在工业控制、智能家居和边缘计算场景中,嵌入式设备的远程可视化操作需求日益增长。传统方案如SSH仅能提供命令行交互,而完整的桌面环境又过于臃肿。本文将展示如何利用libvncse…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...

ContextMenuManager:3步实现Windows右键菜单精准管理的开源解决方案
ContextMenuManager:3步实现Windows右键菜单精准管理的开源解决方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是操作系统中最频…...

UE材质背后的物理课:从菲涅尔到BRDF,理解PBR渲染的数学与视觉魔法
UE材质背后的物理课:从菲涅尔到BRDF,理解PBR渲染的数学与视觉魔法 当你在虚幻引擎中拖动粗糙度滑块时,是否思考过这个0到1的数值如何精确控制光线在虚拟表面的舞蹈?PBR渲染不是魔法,而是将自然界的光影规律翻译成计算机…...
)
告别上位机:用STM32的CAN总线直接对话Maxon EPOS4驱动器(附完整通信代码)
STM32直连Maxon EPOS4:CAN总线电机控制实战指南 在机器人关节控制、智能小车驱动等高精度运动控制场景中,Maxon EPOS4系列驱动器凭借其卓越性能成为工业级首选。但传统依赖PC上位机(如EPOS Studio)的调试方式,严重制约…...

VSCode + Modelsim 搭建Verilog开发环境:除了语法检查,还能这样玩?
VSCode与ModelSim深度集成:打造高效Verilog开发工作流 在数字电路设计领域,Verilog作为硬件描述语言的标准之一,其开发效率直接影响项目进度。传统开发模式中,工程师需要在多个工具间频繁切换——编辑器用于编码,Model…...