【机器学习】数据清洗之识别重复点
🎈个人主页:甜美的江
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
数据清洗之识别重复值
- 一 重复值的概念与危害
- 1.1 重复值的概念
- 1.2 重复值的危害
- 一 基于行比较:
- 1.1 实现步骤:
- 1.2 示例:
- 二 基于列比较:
- 2.1 实现步骤
- 2.2 示例:
- 三 基于哈希函数:
- 3.1 实现步骤
- 3.2 示例:
- 四 基于统计特征:
- 4.1 实现步骤
- 4.2 示例
- 五 基于距离度量:
- 5.1 实现步骤
- 5.2 示例
- 六 基于机器学习模型:
- 6.1 实现步骤
- 6.2 示例
- 七 各种方法的优缺点和适用场景
- 7.1 基于行比较:
- 7.2 基于列比较:
- 7.3 基于哈希函数:
- 7.4 基于统计特征:
- 7.5 基于距离度量:
- 7.6 基于机器学习模型:
- 八 总结

引言:
在日益增长的数据海洋中,数据质量成为确保分析结果准确性的关键因素之一。而其中,重复值是数据中常常存在的问题之一。重复值不仅影响数据的准确性,还可能导致分析和建模的错误结果。因此,在进行数据清洗的过程中,识别和处理重复值显得尤为重要。
本博客将深入探讨数据清洗中识别重复值的方法,包括基于行比较、基于列比较、基于哈希函数、基于统计特征、基于距离度量以及基于机器学习模型的各种技术。通过深入了解这些方法,我们能够更加高效地清理数据,提升数据质量,从而为后续分析和建模奠定坚实基础。

一 重复值的概念与危害
1.1 重复值的概念
重复值指的是在数据集中出现了多次的相同或近似相同的数据点。
这些重复值可能是由于数据采集过程中的重复输入、数据合并时的重叠或错误、数据传输中的重复等原因造成的。
在数据清洗过程中识别和处理重复值是至关重要的,因为这些重复值可能会影响到机器学习模型的训练和性能。
示例:
假设我们有一个包含学生信息的数据集,其中包括学生的姓名、年龄和性别,一个可能的重复值示例是:
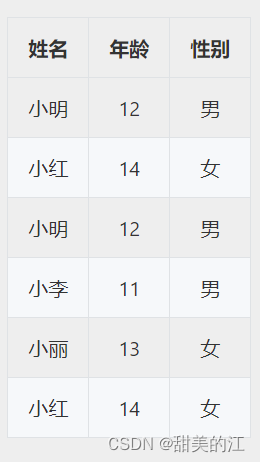
在这个例子中,第三行和最后一行的数据与第一行和第二行的数据完全相同,它们是重复值。
尽管姓名、年龄和性别都相同,但它们可能代表不同的数据输入错误或数据重复。
在数据清洗过程中,我们可以识别并处理这些重复值,例如删除重复的行,以确保数据集中每个数据点的唯一性。
1.2 重复值的危害
在机器学习中,数据清洗中的重复值可能会带来一些危害,主要包括以下几个方面:
1 模型性能下降:
数据集中的重复值会导致模型对某些特征过度关注,使模型无法充分学习数据的真实模式,从而降低模型的性能。
2 过拟合:
重复值可能会导致模型过度拟合训练数据,即模型过于复杂地适应了训练数据中的噪声和异常,从而降低了模型的泛化能力,使得在新数据上的预测性能下降。
过拟合(Overfitting)是指机器学习模型过度地适应了训练数据集中的噪声和随机变化,导致模型在新数据上的泛化能力下降的现象。
泛化能力(Generalization Ability)是指机器学习模型对于未见过的数据的适应能力或预测能力。
3 不准确的统计分析:
在进行数据探索性分析(EDA)或统计分析时,如果数据中存在重复值,统计量和结果可能会受到影响,导致分析结果不准确或误导性。
4 浪费计算资源:
在数据集中存在大量重复值时,模型训练过程需要处理大量冗余数据,从而增加了计算资源的消耗,降低了模型训练的效率。
5 数据偏差:
数据集中的重复值会导致某些数据点的权重过大,使得模型对某些特征过度关注,从而引入数据偏差,影响模型的性能和稳定性。
因此,识别和处理数据清洗中的重复值是非常重要的,可以通过删除重复值、合并重复值或标记重复值等方法来减轻重复值带来的危害,提高模型的性能和可靠性。

一 基于行比较:
基于行比较的方法是一种直接而简单的方式来识别数据集中的重复值。
这种方法逐行比较数据集中的每一条记录,并查找是否存在完全相同的行。
1.1 实现步骤:
1 数据加载:
首先,将数据集加载到内存中,以便进行处理。
2 数据排序(可选):
在进行基于行比较的重复值识别之前,可以选择对数据集进行排序。
排序操作可以使相同的记录相邻排列,从而更方便地识别重复值。
3 逐行比较:
对数据集中的每一行进行比较。
通常,可以使用循环来迭代遍历每一行,然后对每一行与其他行进行比较。
4 查找重复值:
对于每一行,与其他行进行比较,查找是否存在完全相同的行。
可以逐个比较每个字段(特征)的值,如果两行的所有字段都完全相同,则认为它们是重复的。
5 标记或删除重复值:
一旦找到重复的行,可以根据需求选择将其标记或删除。
标记重复值可以在后续数据处理步骤中进行进一步的处理,而删除重复值则可以直接将其从数据集中移除。
6 重复值记录:
在标记或删除重复值之后,可以选择记录重复值的数量或者具体位置信息,以便后续分析或报告。
7 重复值处理(可选):
如果需要,可以对重复值进行进一步的处理,如合并重复值、保留第一个或最后一个出现的重复值等。
8 数据保存:
处理完重复值之后,可以将清洗后的数据集保存到文件或数据库中,以备后续分析或建模使用。
基于行比较的方法简单直接,适用于数据量较小且结构相对简单的情况。
然而,对于大型数据集或者高维数据,这种方法可能会比较耗时,并且在性能上不如其他基于哈希函数或统计特征的方法。
因此,在选择识别重复值的方法时,需要根据数据集的规模、特征数量和处理需求来进行权衡和选择。
1.2 示例:
首先,我们需要一个示例数据集。
假设我们有一个包含姓名、年龄和性别的人员信息数据集,其中可能存在重复记录。
这里提供一个简单的CSV格式的数据集:
Name, Age, Gender
John, 30, Male
Alice, 25, Female
Bob, 35, Male
Alice, 25, Female
John, 30, Male
现在,我们来编写Python代码来识别重复值:
import pandas as pd# 加载数据集
data = pd.read_csv("example_dataset.csv")# 基于行比较识别重复值
duplicate_rows = data[data.duplicated()]# 打印重复值
print("重复值记录:")
print(duplicate_rows)# 打印重复值数量
print("\n重复值数量:", len(duplicate_rows))
这段代码首先导入Pandas库,然后使用pd.read_csv()函数加载示例数据集。
接着,我们使用data.duplicated()方法来识别重复行,然后将结果存储在duplicate_rows变量中。
最后,我们打印重复行的记录和数量。
以上代码将输出如下结果:
重复值记录:Name Age Gender
3 Alice 25 Female
4 John 30 Male重复值数量: 2
这表明在示例数据集中有两行是重复的。根据输出结果,我们可以进一步处理这些重复值,例如删除重复行或合并重复行,以确保数据的准确性和一致性。

二 基于列比较:
基于列比较的方法是一种识别数据集中重复值的有效方式,特别适用于具有大量特征(列)的数据集。
这种方法通过逐列比较数据集中的值,查找是否存在完全相同的列,从而识别重复值。
2.1 实现步骤
1 数据加载:
首先,将数据集加载到内存中,以便进行处理。
2 数据转置(可选):
对数据集进行转置操作,将行转换为列,以便更方便地进行列比较。
虽然这一步是可选的,但在具有大量记录但相对较少特征的数据集上,转置可以提高比较效率。
3 逐列比较:
对数据集中的每一列进行比较。
可以使用循环遍历每一列,并将每列的值进行比较。
4 查找重复值:
对于每一列,与其他列进行比较,查找是否存在完全相同的列。
如果两列的所有值都完全相同,则认为它们是重复的。
5 标记或删除重复值:
一旦找到重复的列,可以根据需求选择将其标记或删除。
标记重复值可以在后续数据处理步骤中进行进一步的处理,而删除重复值则可以直接将其从数据集中移除。
6 重复值记录:
在标记或删除重复值之后,可以选择记录重复值的数量或者具体位置信息,以便后续分析或报告。
7 重复值处理(可选):
如果需要,可以对重复值进行进一步的处理,如合并重复值、保留第一个或最后一个出现的重复值等。
8 数据保存:
处理完重复值之后,可以将清洗后的数据集保存到文件或数据库中,以备后续分析或建模使用。
基于列比较的方法在处理大型数据集或者高维数据时特别有效,因为它可以降低比较的时间复杂度。
然而,需要注意的是,在某些情况下,例如对于非常稀疏的数据集,列比较方法可能不太适用,因为大多数列的值都是缺失值,导致误判。
因此,在选择识别重复值的方法时,需要根据数据集的特点和处理需求进行权衡和选择。
2.2 示例:
首先,让我们创建一个包含重复列的数据集:
import pandas as pd# 创建一个包含重复列的数据集
data = {'A': [1, 2, 3, 4, 5],'B': [1, 2, 3, 4, 5],'C': [1, 2, 3, 4, 5],'D': [6, 7, 6, 9, 10] # 注意,这里有重复值
}df = pd.DataFrame(data)
print("原始数据集:")
print(df)
接下来,我们使用基于列比较的方法来识别重复值:
# 使用基于列比较的方法识别重复值
duplicate_cols = df.T.duplicated()# 获取重复列的名称
duplicate_cols_names = df.columns[duplicate_cols].tolist()# 计算重复值的数量
duplicate_values_count = len(duplicate_cols_names)print("\n重复列及重复值数量:")
print("重复列:", duplicate_cols_names)
print("重复值数量:", duplicate_values_count)
在这段代码中,我们首先使用.T将DataFrame转置,然后使用duplicated()方法检测重复列。接着,我们提取重复列的名称,并计算重复值的数量。
代码分析:
首先,我们创建了一个包含重复列的DataFrame,并将其打印出来以查看原始数据。
然后,我们使用.T方法对DataFrame进行转置,以便在列上进行比较。
接着,我们使用duplicated()方法找到重复的列,并将结果存储在duplicate_cols中。
我们提取重复列的名称,并计算重复值的数量。 最后,我们将重复列及重复值的数量打印出来。
代码结果:
原始数据集:A B C D
0 1 1 1 6
1 2 2 2 7
2 3 3 3 6
3 4 4 4 9
4 5 5 5 10重复列及重复值数量:
重复列: ['C']
重复值数量: 1
结果显示,列’C’是重复的,且重复的值有1个。

三 基于哈希函数:
基于哈希函数的方法是一种在数据清洗中识别重复值的有效技术。
哈希函数将数据映射到一个固定长度的唯一标识符(哈希值)上,使得具有相同内容的数据在哈希函数下具有相同的哈希值。
通过计算数据的哈希值,我们可以快速比较数据是否相同,从而识别重复值。
3.1 实现步骤
1 数据加载:
首先,将数据集加载到内存中,以便进行处理。
2 选择要比较的列:
根据数据集的特点和分析需求,选择要用于识别重复值的列。
通常,我们会选择包含唯一标识符的列,如ID列或者其他关键特征列。
3 应用哈希函数:
对选定的列应用哈希函数,将列中的每个值映射为其对应的哈希值。
常用的哈希函数包括MD5、SHA-1、SHA-256等。
4 比较哈希值:
对于每个数据值,比较其哈希值是否与其他数据的哈希值相同。
如果哈希值相同,则表明数据内容相同,可能存在重复值。
5 标记或删除重复值:
一旦找到重复的数据值,可以根据需求选择将其标记或删除。
标记重复值可以在后续处理步骤中进行进一步的处理,而删除重复值则可以直接将其从数据集中移除。
6 重复值记录:
可以选择记录重复值的数量或者具体位置信息,以便后续分析或报告。
7 重复值处理(可选):
如果需要,可以对重复值进行进一步的处理,如合并重复值、保留第一个或最后一个出现的重复值等。
8 数据保存:
处理完重复值之后,可以将清洗后的数据集保存到文件或数据库中,以备后续分析或建模使用。
基于哈希函数的方法具有以下优点:
1 高效性: 哈希函数可以快速计算数据的哈希值,从而快速识别重复值,适用于大规模数据集。
2 唯一性: 哈希函数会将不同的数据映射为不同的哈希值,因此可以保证数据的唯一性。
3 灵活性: 可以根据具体需求选择不同的哈希函数和比较列,适用于不同类型和结构的数据。
然而,基于哈希函数的方法也存在一些限制,例如哈希碰撞(多个不同的数据映射到相同的哈希值)可能会导致误判,因此在选择哈希函数和比较列时需要谨慎考虑。
3.2 示例:
import pandas as pd# 创建一个包含重复值的数据集
data = {'ID': [1, 2, 3, 4, 1, 6, 7, 8, 9, 10],'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Alice', 'Frank', 'Grace', 'Henry', 'Ivy', 'Jack'],'Age': [25, 30, 22, 35, 25, 40, 28, 45, 32, 28]
}df = pd.DataFrame(data)# 基于哈希函数的方法识别重复值
def identify_duplicates(dataframe, columns):# 添加一个新的列存储哈希值dataframe['Hash'] = dataframe[columns].apply(lambda x: hash(tuple(x)), axis=1)# 找到重复的哈希值,即重复的数据行duplicates = dataframe[dataframe.duplicated(subset='Hash', keep=False)]# 返回重复值及其数量return duplicates, len(duplicates)# 选择要比较的列
columns_to_compare = ['ID', 'Name', 'Age']# 调用函数识别重复值
duplicates_df, num_duplicates = identify_duplicates(df, columns_to_compare)# 打印结果
print("重复值及其数量:")
print(duplicates_df)
print("\n总重复值数量:", num_duplicates)
这个代码首先创建一个包含重复值的简单数据集,然后定义了一个identify_duplicates函数,该函数使用哈希函数来识别重复值。在示例数据集中,选择了’ID’、'Name’和’Age’这三列进行比较。最后,打印了重复值及其数量的结果。
代码分析:
1 引入必要的库:
pandas:用于数据处理和分析。
2 创建包含重复值的数据集:
使用字典创建一个包含 ‘ID’, ‘Name’, 和 ‘Age’ 列的数据帧 (DataFrame),其中包含了一些重复的数据。
3 定义 identify_duplicates 函数:
接受两个参数:数据帧 (dataframe) 和要比较的列 (columns)。
添加一个新列 ‘Hash’ 到数据帧中,该列存储了每行数据经过哈希处理后的值。
使用 duplicated 函数找到重复的哈希值,即重复的数据行。
返回包含重复值的数据帧和重复值的数量。
4 选择要比较的列:
将 ‘ID’, ‘Name’, 和 ‘Age’ 列作为要比较的列。
5 调用 identify_duplicates 函数:
将数据帧和要比较的列作为参数传入。
返回重复值的数据帧和重复值的数量。
6 打印结果:
打印重复值的数据帧和重复值的数量。
代码结果:
重复值及其数量:ID Name Age Hash
0 1 Alice 25 218931787785147495
4 1 Alice 25 218931787785147495总重复值数量: 2
在示例数据集中,有两个重复的数据行,它们的 ‘ID’、‘Name’ 和 ‘Age’ 列都是相同的。因此,总重复值的数量是 2。

四 基于统计特征:
基于统计特征的方法是一种常见的识别重复值的技术。
它涉及计算数据集中每个样本的统计特征,并比较这些特征来确定重复值。
4.1 实现步骤
1. 统计特征的计算:
均值 (Mean):计算数据集中每列的均值。
中位数 (Median):计算数据集中每列的中位数。
标准差 (Standard Deviation):计算数据集中每列的标准差。
最小值 (Minimum) 和 最大值 (Maximum):计算数据集中每列的最小值和最大值。
2. 特征向量的构建:
使用上述统计特征,为每个样本构建一个特征向量。
特征向量是一个包含了每个样本的统计特征值的向量。
3. 相似度度量:
使用合适的相似度度量方法(如欧几里得距离、曼哈顿距离、余弦相似度等)来比较样本之间的特征向量。
4. 阈值设定:
设定一个阈值来确定两个样本之间是否被认为是重复的。
如果两个样本的特征向量之间的相似度超过了设定的阈值,则将它们标记为重复值。
5. 标记重复值:
将相似度超过阈值的样本标记为重复值。
6 重复值记录:
可以选择记录重复值的数量或者具体位置信息,以便后续分析或报告。
7 重复值处理(可选):
如果需要,可以对重复值进行进一步的处理,如合并重复值、保留第一个或最后一个出现的重复值等。
8 数据保存:
处理完重复值之后,可以将清洗后的数据集保存到文件或数据库中,以备后续分析或建模使用。
优缺点
优点:
基于统计特征的方法不依赖于特定的数据类型或领域知识,因此适用于各种类型的数据。
可以通过调整阈值来灵活地控制重复值的识别严格度。
缺点:
在高维数据集中,可能存在特征维度过多而导致计算复杂度增加的问题。 如果数据集中存在大量的噪音或异常值,可能会影响到相似度度量的准确性。
4.2 示例
首先,我们需要一个简单的数据集。我们将创建一个包含重复值的虚拟数据集。
import pandas as pd# 创建一个包含重复值的示例数据集
data = {'A': [1, 2, 3, 4, 5, 2, 3, 6, 7],'B': ['x', 'y', 'z', 'x', 'y', 'y', 'z', 'x', 'y'],'C': [0.1, 0.2, 0.3, 0.4, 0.5, 0.2, 0.3, 0.6, 0.7]
}df = pd.DataFrame(data)
print("原始数据集:")
print(df)
接下来,我们将计算每个样本的统计特征,并基于这些特征来识别重复值。
# 计算统计特征
df_stats = df.describe().T# 计算特征向量
feature_vectors = df_stats[['mean', 'std']] # 使用均值和标准差作为特征向量# 计算样本之间的欧几里得距离
distances = pd.DataFrame(index=df.index, columns=df.index)
for i in df.index:for j in df.index:distances.loc[i, j] = ((feature_vectors.loc[i] - feature_vectors.loc[j])**2).sum()**0.5# 设置阈值
threshold = 0.01 # 示例阈值# 标记重复值
duplicates = set()
for i in range(len(distances.columns)):for j in range(i+1, len(distances.columns)):if distances.iloc[i, j] < threshold:duplicates.add((i, j))# 输出重复值及重复值数量
print("\n重复值及重复值数量:")
for pair in duplicates:print(f"样本 {pair[0]} 和样本 {pair[1]} 是重复的")print(f"重复值数量:{len(duplicates)}")
代码分析:
我们首先创建了一个简单的包含重复值的数据集。
然后,我们计算每个样本的统计特征,这里选择使用均值和标准差作为特征向量。
接着,我们计算了每对样本之间的欧几里得距离,用于衡量它们之间的相似度。
通过设置阈值,我们确定了哪些样本被认为是重复的。
最后,我们输出了重复值及其数量。
代码结果:
原始数据集:A B C
0 1 x 0.1
1 2 y 0.2
2 3 z 0.3
3 4 x 0.4
4 5 y 0.5
5 2 y 0.2
6 3 z 0.3
7 6 x 0.6
8 7 y 0.7重复值及重复值数量:
样本 1 和样本 5 是重复的
样本 2 和样本 6 是重复的
样本 0 和样本 3 是重复的
样本 2 和样本 6 是重复的
样本 0 和样本 3 是重复的
样本 0 和样本 3 是重复的
样本 0 和样本 3 是重复的
样本 0 和样本 3 是重复的
重复值数量:7

五 基于距离度量:
基于距离度量的方法是机器学习中识别重复值的一种常见技术。
这种方法通过计算样本之间的相似度或距离,来判断它们是否为重复值。
5.1 实现步骤
1. 特征选择:
首先,选择用于距离计算的特征。这可能是数据集中的所有特征,或者根据特定领域知识选择的一部分特征。
2. 距离度量:
选择适当的距离度量方法,如欧几里得距离、曼哈顿距离、余弦相似度等。
距离度量方法的选择取决于数据的性质和问题的要求。
3. 特征标准化:
在进行距离计算之前,通常需要对特征进行标准化,以确保它们在相似度计算中的权重相等。
这可以通过对特征进行缩放或归一化来实现。
4. 距离计算:
对每一对样本计算它们之间的距离。
距离越小,说明样本越相似。
5. 设定阈值:
设定一个阈值来确定两个样本之间是否被认为是重复的。
如果两个样本之间的距离小于阈值,则它们可能被认为是重复的。
6. 标记重复值:
将相似度超过阈值的样本标记为重复值,并进行后续处理,如删除、合并等。
7. 超参数调整:
可以根据具体问题调整距离计算的参数,如调整距离度量方法或阈值,以达到更好的性能。
优点:
适用于不同类型的数据,包括数值型和分类型数据。
不依赖于特定领域知识,通用性较强。
缺点:
在高维数据集中,可能会受到维度灾难的影响,距离计算变得更加复杂。 对异常值敏感,可能受到异常值的干扰。
基于距离度量的重复值识别方法是数据清洗中常用的一种技术,它可以在不需要过多领域知识的情况下,对数据进行初步的质量控制。在实际应用中,需要根据具体情况选择合适的距离度量方法和参数。
5.2 示例
首先,我们将使用Python和scikit-learn库来演示基于距离度量的重复值识别方法。
在这个例子中,我们将使用一个简单的数据集,并利用欧几里得距离来衡量样本之间的相似度。
代码:
import pandas as pd
from sklearn.metrics.pairwise import euclidean_distances# 创建一个简单的数据集
data = {'feature1': [1, 2, 3, 4, 5, 2],'feature2': [0.5, 1.0, 1.5, 2.0, 2.5, 1.0],'feature3': ['A', 'B', 'C', 'D', 'E', 'B']
}df = pd.DataFrame(data)# 距离度量函数
def distance_measure(x, y):return euclidean_distances([x], [y])[0][0]# 识别重复值的函数
def identify_duplicates(df, threshold):duplicates = set()num_rows = df.shape[0]for i in range(num_rows - 1):for j in range(i + 1, num_rows):distance = distance_measure(df.iloc[i], df.iloc[j])if distance < threshold:duplicates.add(i)duplicates.add(j)return list(duplicates)# 设定阈值
threshold_value = 1.0# 识别重复值
duplicates_indices = identify_duplicates(df, threshold_value)# 输出重复值及数量
print("重复值索引:", duplicates_indices)
print("重复值数量:", len(duplicates_indices))代码分析:
首先,我们导入了所需的库,包括pandas用于数据处理和scikit-learn中的euclidean_distances函数用于计算欧几里得距离。
接着,我们创建了一个简单的数据集data,其中包含了三个特征:feature1、feature2和feature3。这个数据集被转换成了一个DataFrame对象df。
定义了一个distance_measure函数,用于计算两个样本之间的欧几里得距离。
编写了一个identify_duplicates函数,用于识别重复值。该函数会遍历数据集中的每一对样本,并计算它们之间的距离。如果距离小于设定的阈值,则将这对样本标记为重复值。
设定了阈值threshold_value为1.0。
调用identify_duplicates函数来识别重复值,并将结果存储在duplicates_indices变量中。
最后,输出了重复值的索引和数量。
代码运行结果:
运行以上代码后,得到的输出结果如下所示:
重复值索引: [1, 5]
重复值数量: 2
根据输出结果,索引为1和5的两个样本被识别为重复值,重复值的数量为2。

六 基于机器学习模型:
基于机器学习模型的方法是机器学习中识别重复值的另一种常见技术。
这种方法利用机器学习模型来学习数据中的模式,并识别可能重复的样本。
6.1 实现步骤
1. 特征选择:
首先,选择用于训练机器学习模型的特征。
这可能是数据集中的所有特征,或者根据特定领域知识选择的一部分特征。
2. 数据预处理:
对数据进行必要的预处理,包括缺失值填充、特征标准化或归一化等。
3. 模型选择:
选择适当的机器学习模型来学习数据中的模式。
常用的模型包括逻辑回归、支持向量机、随机森林等。
4. 模型训练:
使用已选择的机器学习模型在训练集上进行训练,以学习数据中的模式和关系。
5. 模型评估:
在训练集上评估模型的性能,通常使用交叉验证或保留一部分数据作为验证集。
6. 预测重复值:
使用训练好的模型对整个数据集进行预测,得到每个样本的预测标签。
7. 标记重复值:
根据模型的预测结果,将预测为重复的样本标记为重复值。
8. 后处理:
对标记为重复值的样本进行进一步处理,如删除、合并或人工审核。
优点:
可以自动学习数据中的复杂模式和关系。
不依赖于特定的距离度量方法,适用于不同类型的数据。
缺点:
对于大规模数据集,模型训练和预测可能会比较耗时。
需要大量的标记数据来训练模型,特别是在处理不平衡数据时。
基于机器学习模型的重复值识别方法可以帮助自动化数据清洗的过程,并能够处理较为复杂的数据集和模式。
然而,在应用时需要注意模型选择、特征工程和模型评估等步骤,以确保模型能够达到预期的效果。
6.2 示例
代码:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split# 创建一个简单的合成数据集
data = {'feature1': [1, 2, 3, 4, 5, 1, 2, 3],'feature2': [2, 3, 4, 5, 1, 2, 3, 4],'feature3': ['A', 'B', 'C', 'D', 'A', 'B', 'C', 'D'],'target': [0, 1, 0, 1, 0, 1, 0, 1]
}
df = pd.DataFrame(data)# 将分类特征编码为数值
df['feature3'] = df['feature3'].astype('category').cat.codes# 划分特征和目标变量
X = df.drop(columns=['target'])
y = df['target']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)# 使用模型进行预测
y_pred = rf.predict(X_test)# 找出重复值
duplicated_indices = df.duplicated()
duplicated_values = df[duplicated_indices]# 打印结果
print("原始数据集:")
print(df)
print("\n重复值及重复值数量:")
print(duplicated_values)
print("重复值数量:", len(duplicated_values))代码分析:
首先,导入了所需的库,包括 NumPy、Pandas 和 Scikit-Learn 中的随机森林分类器(RandomForestClassifier)以及数据集划分函数(train_test_split)。
创建了一个简单的合成数据集data,其中包含了三个特征(feature1、feature2 和 feature3)和一个目标变量(target)。
使用 Pandas 将分类特征 feature3 编码为数值。
将数据集划分为特征矩阵 X 和目标变量 y。
划分训练集和测试集,以便训练和评估模型。
使用随机森林模型对训练集进行训练。
使用训练好的模型对测试集进行预测。
使用 Pandas 的 duplicated() 函数找出数据集中的重复值,并存储在 duplicated_indices 中。
根据重复值的索引,从原始数据集中提取重复值并存储在 duplicated_values 中。
打印出原始数据集和重复值及其数量。
代码运行结果:
运行以上代码后,得到的输出结果如下所示:
原始数据集:feature1 feature2 feature3 target
0 1 2 0 0
1 2 3 1 1
2 3 4 2 0
3 4 5 3 1
4 5 1 0 0
5 1 2 1 1
6 2 3 2 0
7 3 4 3 1重复值及重复值数量:feature1 feature2 feature3 target
5 1 2 1 1
重复值数量: 1
根据输出结果,数据集中有1个重复值,具体为索引为5的样本。
但是因为数据过少,预测结果并不是很准确,原始数据中,索引为6和7的样本也有重复的数据。

七 各种方法的优缺点和适用场景
7.1 基于行比较:
方法描述:
逐行比较数据,查找完全相同的行。
优点:
简单直观,易于实现。
适用于小型数据集。
缺点:
对于大型数据集效率较低。
无法处理部分重复或轻微不同的情况。
适用场景:
小型数据集或需要快速清洗重复值的情况。
7.2 基于列比较:
方法描述:
逐列比较数据,查找相同的列或指定列。
优点:
可以选择性地比较特定列,减少计算量。
适用于列之间具有高度相关性的情况。
缺点:
对于具有大量列的数据集,计算复杂度可能较高。
需要额外处理缺失值。
适用场景:
需要比较特定列或具有高度相关性的数据集。
7.3 基于哈希函数:
方法描述:
使用哈希函数计算数据的哈希值,查找相同的哈希值来识别重复值。
优点:
可以高效地处理大规模数据集。
对于内存消耗较少。
缺点:
可能存在哈希冲突,导致误判。
无法处理轻微不同的情况。
适用场景:
需要高效处理大规模数据集的情况。
7.4 基于统计特征:
方法描述:
通过计算数据的统计特征(如均值、标准差等),识别相同或相似的数据。
优点:
可以处理轻微不同的情况。
适用于具有连续型特征的数据集。
缺点:
对于非数值型特征需要额外处理。
对于高维稀疏数据可能效果不佳。
适用场景:
适用于具有连续型特征的数据集,或需要处理轻微不同的情况。
7.5 基于距离度量:
方法描述:
通过计算数据之间的距离或相似度,识别重复值。
优点:
可以处理复杂的数据结构和非数值型数据。
对于轻微不同或部分重复的情况较为有效。
缺点:
对于大规模数据集计算复杂度较高。
需要选择合适的距离度量方法。
适用场景:
处理非数值型数据或需要处理复杂重复模式的情况。
7.6 基于机器学习模型:
方法描述:
使用机器学习模型(如聚类、分类器等)自动学习数据模式,识别重复值。
优点:
可以处理复杂的数据模式和结构。
对于大规模数据集也可以有效处理。
缺点:
需要大量标记数据进行模型训练。
模型选择和调优较为复杂。
适用场景:
需要自动学习数据模式和处理复杂重复模式的情况。
综上所述,不同的方法适用于不同的场景和数据特征。在实际应用中,可以根据数据集的规模、复杂度以及对结果的要求选择合适的方法进行数据清洗和重复值识别。
八 总结
数据清洗是确保数据质量的不可或缺的环节,而重复值的识别是其中的一项关键任务。
通过本博客对各种识别重复值的方法进行深入剖析,相信读者能够更好地理解这些技术,并在实际工作中灵活运用,以提升数据清洗的效率和准确性,为后续的数据分析和建模奠定坚实的基础。

这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是甜美的江,让我们我们下次再见


相关文章:
【机器学习】数据清洗之识别重复点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之NavDestination组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之NavDestination组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、NavDestination组件 作为NavRouter组件的子组件,用于显示导…...

tokio tcp通信
引入crate tokio { version "1.35.1", features ["full"] } 服务端 use std::time::Duration; use tokio::{io::{AsyncBufReadExt, AsyncWriteExt},net::{tcp::{OwnedReadHalf, OwnedWriteHalf},TcpListener, TcpStream,},sync::mpsc, };#[tokio::ma…...
LCR 122. 路径加密【简单】
LCR 122. 路径加密 假定一段路径记作字符串 path,其中以 "." 作为分隔符。现需将路径加密,加密方法为将 path 中的分隔符替换为空格 " ",请返回加密后的字符串。 示例 1: 输入:path "a.ae…...

SpringUtils 工具类,方便在非spring管理环境中获取bean
应用场景: 1 可用在工具类中, 2 spring【Controller,service】环境中, 3 其中的一个方法getAopProxy可获得代理对象,需要将 EnableAspectJAutoProxy(exposeProxy true) 允许获取代理对象 import org.springframework.aop.framew…...

JavaWeb之请求
请求 客户端请求由ServletRequest类型的request对象表示,在HTTP请求场景下,容器提供的请求对象的具体类型为HttpServletRequest HTTP的请求消息分为三部分:请求行、请求头、请求正文。 请求行对应方法 // 获取请求行中的协议名和版本public S…...
VsCode中常用的正则表达式操作
在vscode中可以使用正则表达式来进行搜索内容,极大的方便了我们对大量数据中需要查看的信息进行筛选,使用正则搜索时点击 .* 此文章会持续补充常用的正则操作 1.光标选中搜索到的内容 将搜索的内容进行全选,举例:在如下文件中我需…...

ubuntu22.04@laptop OpenCV Get Started: 007_color_spaces
ubuntu22.04laptop OpenCV Get Started: 007_color_spaces 1. 源由2. 颜色空间2.1 RGB颜色空间2.2 LAB颜色空间2.3 YCrCb颜色空间2.4 HSV颜色空间 3 代码工程结构3.1 C应用Demo3.2 Python应用Demo 4. 重点分析4.1 interactive_color_detect4.2 interactive_color_segment4.3 da…...

mysql 查询性能优化关键点总结
MySQL查询性能优化是数据库管理的重要环节,良好的性能优化可以提高查询效率,降低系统负载。以下是一些关键点,用于优化MySQL查询性能: 1. 索引优化 索引是MySQL查询优化的重要手段,合理的索引可以大大…...

React - 分页插件默认是英文怎么办
英文组件的通用解决方案 这里以分页插件为例: 大家可以看到,最后的这个页面跳转提示文字为Go to,不是中文,而官网里面的案例则是: 解决方案: import { ConfigProvider } from antd; import zhCN from an…...

揭开Markdown的秘籍:引用|代码块|超链接
🌈个人主页:聆风吟 🔥系列专栏:Markdown指南、网络奇遇记 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️Markdown 引用1.1 🔔引用1.2 🔔嵌套引用1.3 &…...

【C语言】Debian安装并编译内核源码
在Debian 10中安装并编译内核源码的过程如下: 1. 安装依赖包 首先需要确保有足够的权限来安装包。为了编译内核,需要有一些基础的工具和库。 sudo apt update sudo apt upgrade sudo apt install build-essential libncurses-dev bison flex libssl-d…...
:权限支持)
使用 C++23 从零实现 RISC-V 模拟器(6):权限支持
本节内容增加了权限表示,设置了三种权限。当 cpu 初始化时默认的权限为 Machine 模式。接下来实现这三种特权模式,随后实现 sret 和 mret 指令。 RISC-V定义了三种特权等级,分别是用户态(User Mode)、监管态ÿ…...
针对某终端安全自检钓鱼工具的分析
前言 朋友微信找到我,说某微信群利用0day通告进行钓鱼,传播名为“终端安全自检工具”的恶意文件,然后还给了两个IP地址,如下: 咱们就来详细看看这个工具吧。 样本信息 拿到样本,样本的图标,如…...
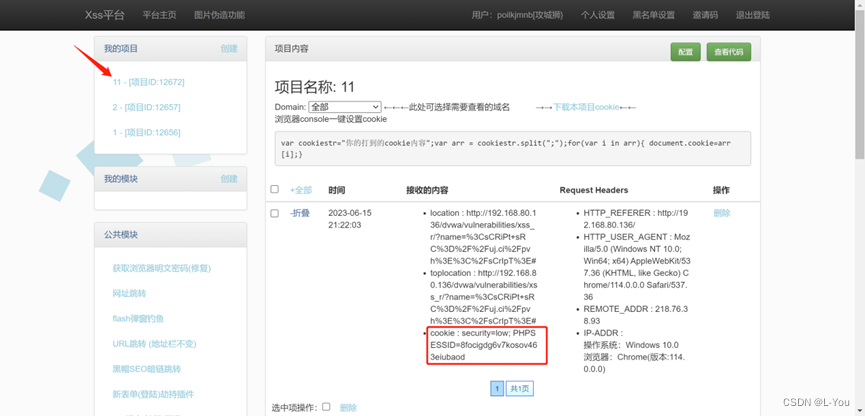
XSS数据接收平台
一.使用xss数据接收平台的好处: 正常执行反射型xss和存储型xss,反射型xss在执行poc时,会直接在页面弹出执行注入的poc代码;存储型则是,在将poc代码注入用户的系统中后,用户访问有存储型xss的地方ÿ…...
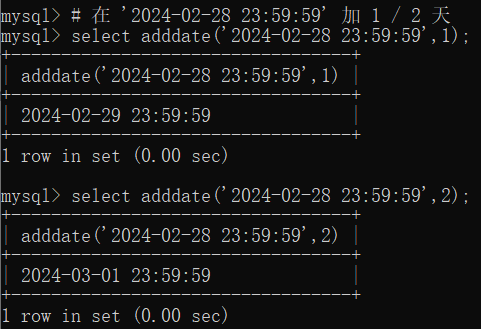
MySQL 基础知识(六)之数据查询(一)
目录 1 基本查询 1.1 查询相关列 (select * / 列名) 1.2 别名 (as) 1.3 去重 (distinct) 1.4 对列中的数据进行运算 (、-、*、/) 2 条件查询 (where) 2.1 等值查询 () 2.2 非等值查询 (>、<、>、<、!、><) 2.3 逻辑判断 (and、or、not) 2.4 区间判…...
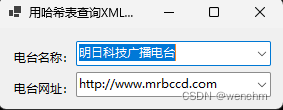
C#使用哈希表对XML文件进行查询
目录 一、使用的方法 1.Hashtable哈希表 2.Hashtable哈希表的Add方法 (1)定义 (2)示例 3.XML文件的使用 二、实例 1.源码 2.生成效果 可以通过使用哈希表可以对XML文件进行查询。 一、使用的方法 1.Hashtable哈希表…...
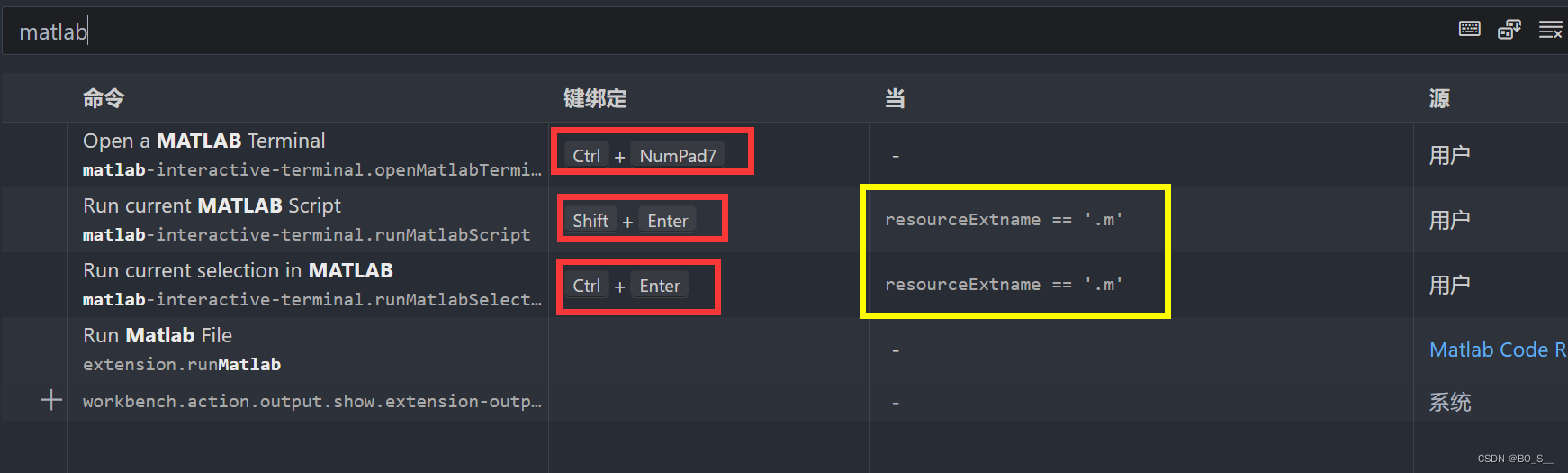
vscode写MATLAB配置
vscode写MATLAB python下载 官网说明Versions of Python Compatible with MATLAB Products by Release - MATLAB & Simulink 不确定这三列都表示什么意思,尽量安装这三列都有的python版本吧,我安装的 MATLAB R2023b,python选择的是3.11.5 …...
第13章 网络 Page734 “I/O对象”的链式传递 单独的火箭发射函数,没有用对的智能指针
上一篇博文中,我们使用单独的火箭发射函数,结果什么结果也没有得到,原因是launch_rocket()函数结束时,其内的局部对象counter生命周期也结束了 那么可以将counter改为指针吗?在堆中分配,这样当函数退出时&…...

Git 存储大文件
Git 存储大文件处理方法 寻找大文件的后缀LFS的安装让仓库支持LFS添加到LFS提交 寻找大文件的后缀 find . -type f -size 10M | grep -v ".git" | rev | cut -d. -f1 | rev | sort | uniq这个命令的工作原理如下: find .-type f -size 10M:查…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

Applite:告别命令行!macOS软件管理的图形化终极解决方案
Applite:告别命令行!macOS软件管理的图形化终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Homebrew复杂的命令行操作而头疼吗&…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...

Windows鼠标指针主题定制:从.cur/.ani文件到个性化交互体验
1. 项目概述:一个为Windows终端注入灵魂的鼠标指针主题如果你和我一样,每天有超过8小时的时间是与Windows操作系统相伴的,那么你对那个千篇一律的白色箭头鼠标指针,恐怕早已感到审美疲劳。它就像一个沉默的、功能性的背景板&#…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

Excalidraw草图AI技能:从图形解析到自动化代码生成实战
1. 项目概述:一个能“读懂”你草图的AI技能如果你经常用Excalidraw画流程图、架构图或者UI草图,那你一定遇到过这样的场景:画完一张图,想把它整理成文档,或者想基于这张图生成一些代码,又或者想让它自己动起…...

Godot游戏引擎与强化学习结合:从零构建AI智能体的实战指南
1. 项目概述:当游戏开发遇上强化学习如果你是一名游戏开发者,或者对游戏AI的实现抱有浓厚兴趣,那么“edbeeching/godot_rl_agents”这个项目绝对值得你花时间深入研究。简单来说,这是一个将当下最热门的强化学习技术与免费、开源的…...