Windows11(非WSL)安装Installing llama-cpp-python with GPU Support
直接安装,只支持CPU。想支持GPU,麻烦一些。
1. 安装CUDA Toolkit (NVIDIA CUDA Toolkit (available at https://developer.nvidia.com/cuda-downloads)
2. 安装如下物件:
- git
- python
- cmake
- Visual Studio Community (make sure you install this with the following settings)
- Desktop development with C++
- development
- Linux embedded development with C++
3. Clone git repository recursively to get llama.cpp submodule as well
git clone --recursive -j8 https://github.com/abetlen/llama-cpp-python.git
4. Open up a command Prompt and set the following environment variables.
set FORCE_CMAKE=1
set CMAKE_ARGS=-DLLAMA_CUBLAS=ON
5. 复制文件从Cuda到VS:**
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3\extras\visual_studio_integration\MSBuildExtensions下面有四个文件,全部copy。
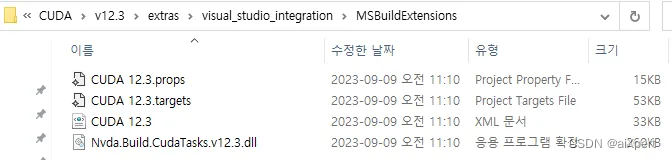
然后复制到:
C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\BuildCustomizations下面。
6. Compiling and installing
cd\llama-cpp-python
python -m pip install -e .
7. 检查成果:
>>> from llama_cpp import Llama
>>> llm = Llama(model_path="llama-2-7b-chat.Q8_0.gguf",n_gpu_layers=-1)
结果:
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 1 CUDA devices:Device 0: NVIDIA GeForce RTX 4090, compute capability 6.1, VMM: yes
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from llama-2-7b-chat.Q8_0.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 10: general.file_type u32 = 7
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q8_0: 226 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 6.67 GiB (8.50 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
显卡终于在列,可以玩儿了。

相关文章:
Windows11(非WSL)安装Installing llama-cpp-python with GPU Support
直接安装,只支持CPU。想支持GPU,麻烦一些。 1. 安装CUDA Toolkit (NVIDIA CUDA Toolkit (available at https://developer.nvidia.com/cuda-downloads) 2. 安装如下物件: gitpythoncmakeVisual Studio Community (make sure you install t…...

rtt设备io框架面向对象学习-脉冲编码器设备
目录 1.脉冲编码器设备基类2.脉冲编码器设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 1.脉冲编码器设备基类 此层处于设备驱动框架层。也是抽象类。 在/ components / drivers / include / drivers 下的pulse_encoder.h定义…...
)
华为OD机试真题- 攀登者2-2024年OD统一考试(C卷)
题目描述: 攀登者喜欢寻找各种地图,并且尝试攀登到最高的山峰。地图表示为一维数组,数组的索引代表水平位置,数组的高度代表相对海拔高度。其中数组元素0代表地面。例如[0,1,4,3,1,0,0,1,2,3,1,2,1,0], 代表如下图所示的地图,地图中有两个山脉位置分别为 1,2,3,4,5和8,9,1…...
19.Qt 组合框的实现和应用
目录 前言: 技能: 内容: 1. 界面 2.槽 3.样式表 参考: 前言: 学习QCombox控件的使用 技能: 简单实现组合框效果 内容: 1. 界面 在ui编辑界面找到input widget里面的comboBoxÿ…...
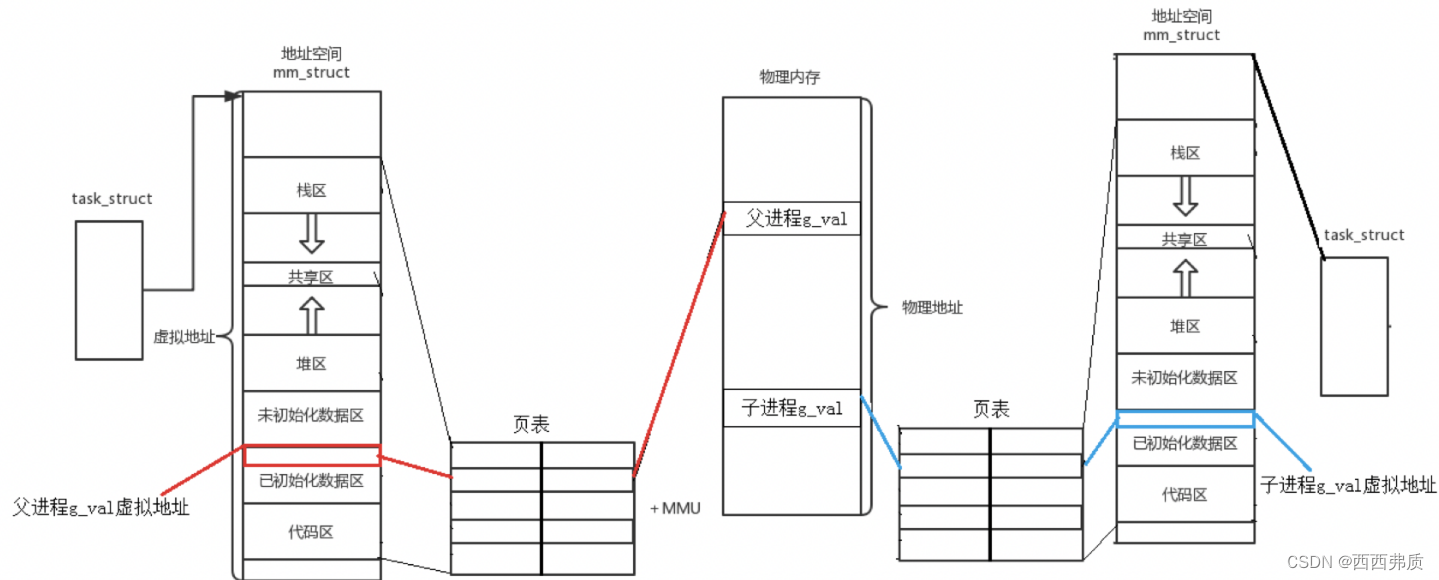
【Linux】进程地址空间的理解
进程地址空间的理解 一,什么是程序地址空间二,页表和虚拟地址空间三,为什么要有进程地址空间 一,什么是程序地址空间 在我们写程序时,都会有这样下面的内存结构,来存放变量和代码等数据。 一个进程要执行…...
【Jvm】类加载机制(Class Loading Mechanism)原理及应用场景
文章目录 Jvm基本组成一.什么是JVM类的加载二.类的生命周期阶段1:加载阶段2:验证阶段3:准备阶段4:解析阶段5:初始化 三.类初始化时机四.类加载器1.引导类加载器(Bootstrap Class Loader)2.拓展类…...
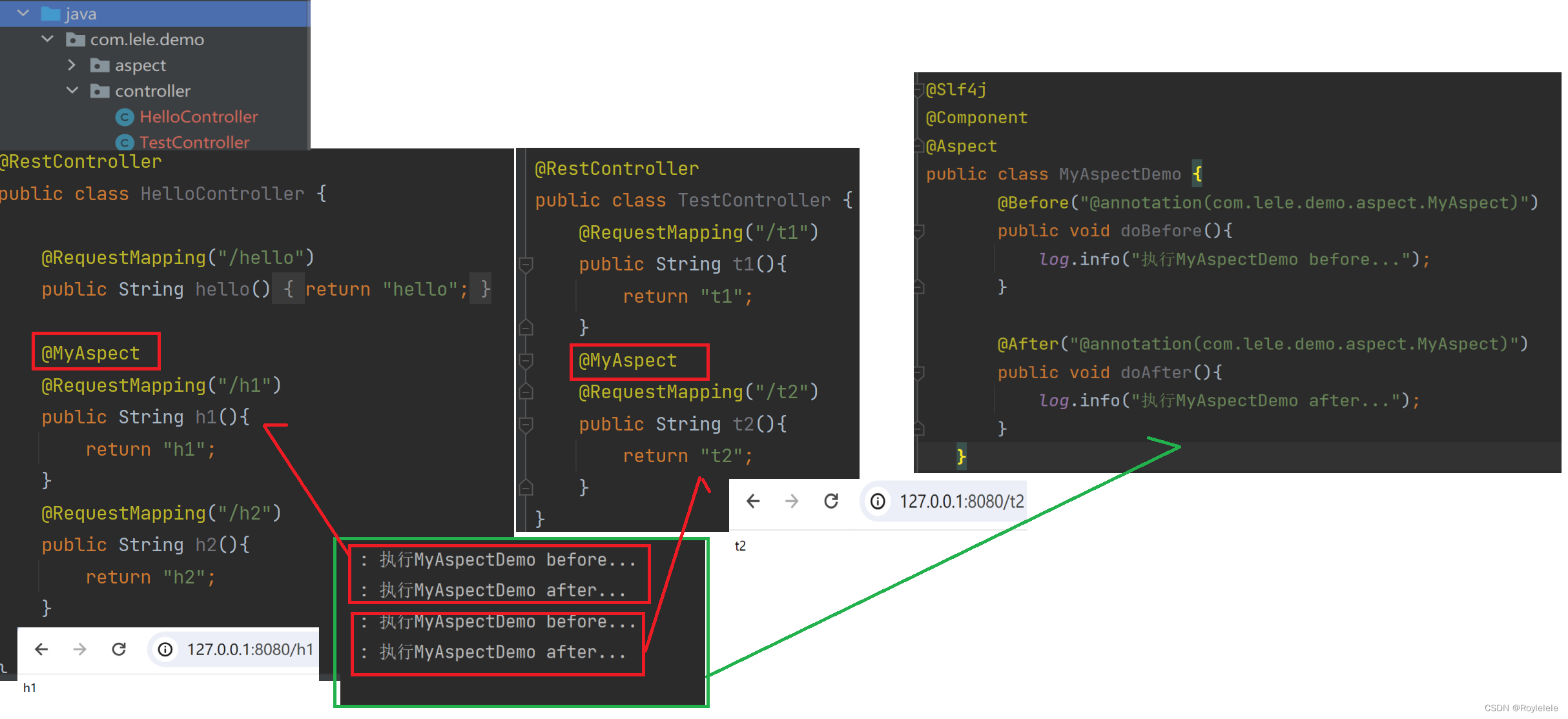
Spring AOP的实现方式
AOP基本概念 Spring框架的两大核心:IoC和AOP AOP:Aspect Oriented Programming(面向切面编程) AOP是一种思想,是对某一类事情的集中处理 面向切面编程:切面就是指某一类特定的问题,所以AOP可…...
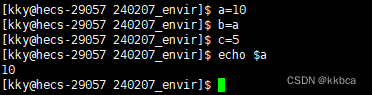
Linux------环境变量
目录 前言 一、环境变量 二、添加PATH环境变量 三、HOME环境变量 四、查看所有环境变量 1.指令获取 2.代码获取 2.1 getenv 2.2main函数的第三个参数 2.3 全局变量environ 五、环境变量存放地点 六、添加自命名环境变量 七、系统环境变量具有全局属性 八、环境变…...

计算机视觉所需要的数学基础
计算机视觉领域中使用的数学知识广泛而深入,以下是一些关键知识点及其在计算机视觉中的应用: 线性代数: - 矩阵运算:用于图像的表示和处理,如图像旋转、缩放、裁剪等。 - 向量空间:用于描述图像中的…...
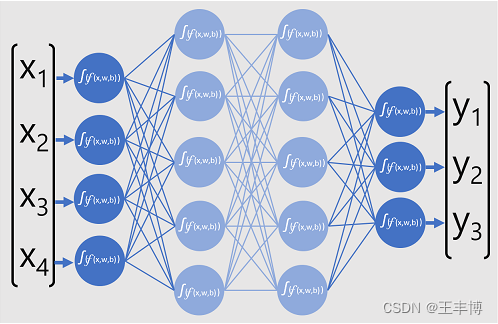
ChatGPT魔法1: 背后的原理
1. AI的三个阶段 1) 上世纪50~60年代,计算机刚刚产生 2) Machine learning 3) Deep learning, 有神经网络, 最有代表性的是ChatGPT, GPT(Generative Pre-Trained Transformer) 2. 深度神经网络 llya Suts…...

【c/c++】获取时间
在一些应用的编写中我们有时候需要用到时间,或者需要一个“锚点”来确定一些数的值。在c/c中有两个用来确定时间的函数:time/gettimeofday 一、time time_t time(time_t *timer);time 函数返回当前时间的时间戳(自 1970 年 1 月 1 日以来经…...
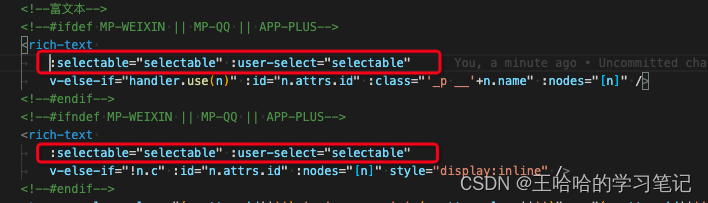
uniapp富文本文字长按选中(用于复制,兼容H5、APP、小程序三端)
方案:使用u-parse的selectable属性 <u-parse :selectable"true" :html"content"></u-parse> 注意:u-parse直接使用是不兼容小程序的,需要对u-parse进行改造: 1. 查看u-parse源码发现小程序走到以…...

常见的几种Web安全问题测试简介
Web项目比较常见的安全问题 1.XSS(CrossSite Script)跨站脚本攻击 XSS(CrossSite Script)跨站脚本攻击。它指的是恶意攻击者往Web 页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web 里面的html 代码会被执行,从而达到恶意用户的特殊…...
linux信号机制[一]
目录 信号量 时序问题 原子性 什么是信号 信号如何产生 引入 信号的处理方法 常见信号 如何理解组合键变成信号呢? 如何理解信号被进程保存以及信号发送的本质? 为什么要有信号 信号怎么用? 样例代码 core文件有什么用呢&#…...

elementui 中el-date-picker 选择年后输出的是Wed Jan 01 2025 00:00:00 GMT+0800 (中国标准时间)
文章目录 问题分析 问题 在使用 el-date-picker 做只选择年份的控制器时,出现如下问题:el-date-picker选择年后输出的是Wed Jan 01 2025 00:00:00 GMT0800 (中国标准时间),输出了两次如下 分析 在 el-date-picker 中,我们使用…...
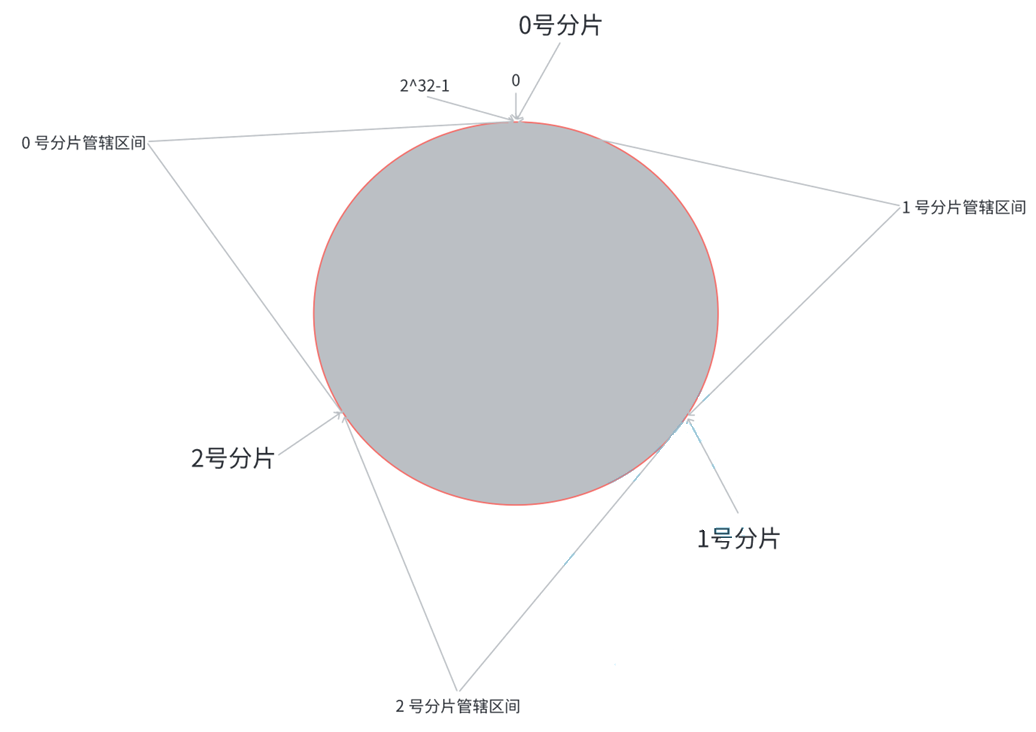
Redis 集群(Cluster)
集群概念 Redis 的哨兵模式,提高了系统的可用性,但是正在用来存储数据的还是 master 和 slave 节点,所有的数据都需要存储在单个 master 和 salve 节点中。 如果数据量很大,接近超出了 master / slave 所在机器的物理内存&#…...
)
260.【华为OD机试真题】信道分配(贪心算法-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-信道分配二.解题思路三.题解代码Python题解代码…...
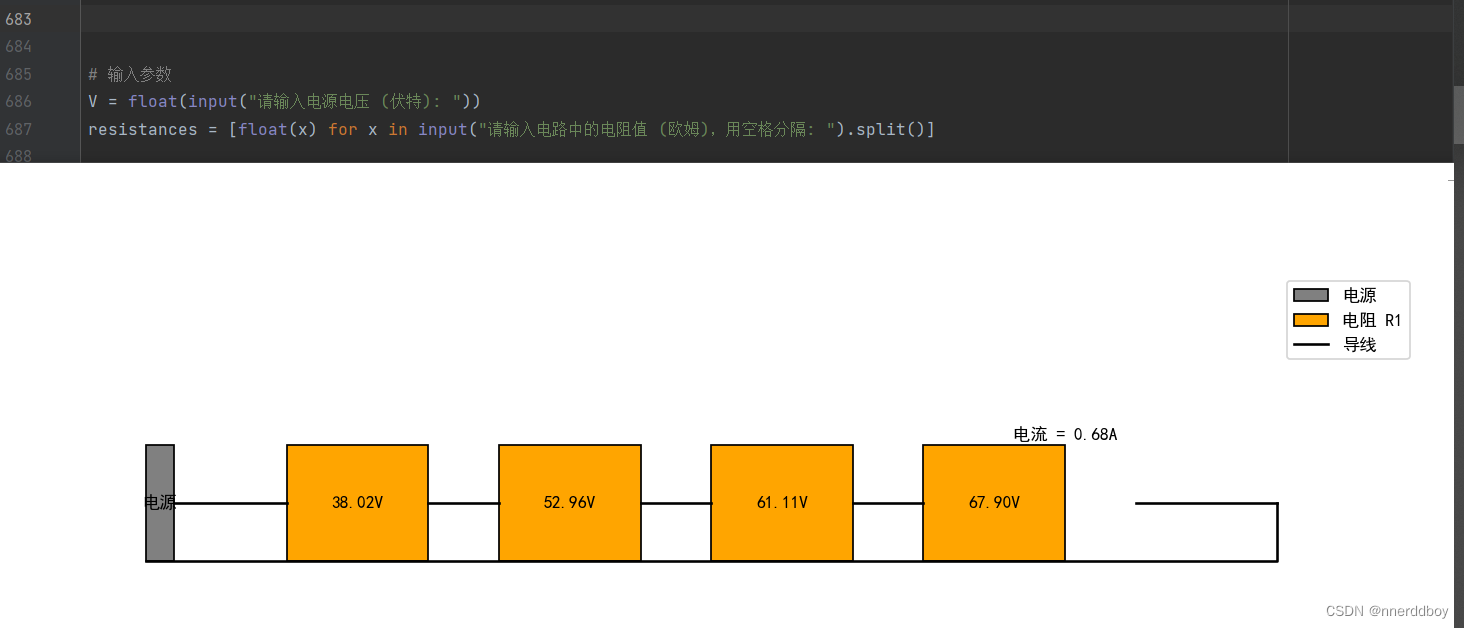
Python打发无聊时光:3.实现简单电路的仿真
看到这个标题肯定有人会问:好好的multisim、 proteus之类的专门电路仿真软件不用,非要写一个简陋的python程序来弄,是不是精神失常了。实际上,我也不知道为什么要这么干,前两篇文章是我实际项目中的一些探索࿰…...
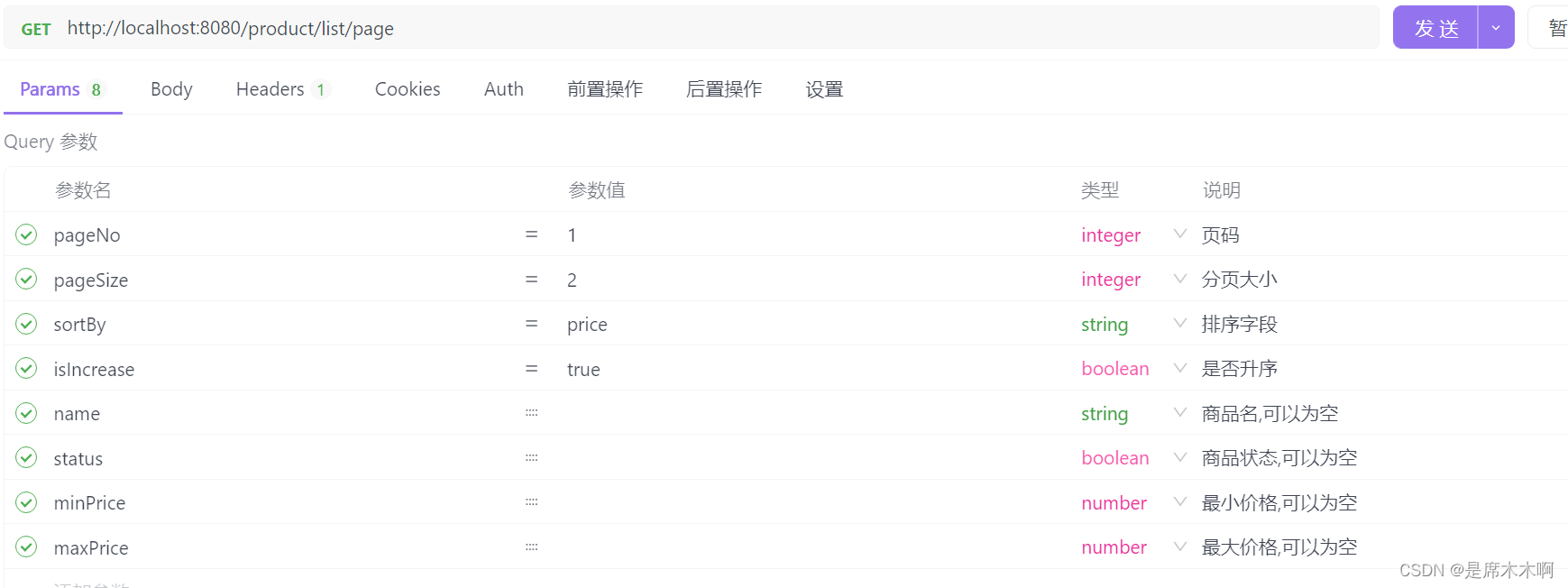
MyBatis-Plus:通用分页实体封装
分页查询实体:PageQuery package com.example.demo.demos.model.query;import com.baomidou.mybatisplus.core.metadata.OrderItem; import com.baomidou.mybatisplus.extension.plugins.pagination.Page; import lombok.Data; import org.springframework.util.St…...
、中台、Java SPI(Service Provider Interface))
MVC 、DDD(domain-driven design,软件主动学习业务)、中台、Java SPI(Service Provider Interface)
文章目录 引言I 单体架构DDD实现版本1.1 核心概念1.2 DDD四层架构规范1.3 案例1.4 请求转发流程II 领域服务调用2.1 菱形对称架构2.2 中台III Java SPI3.1 概念3.2 实现原理3.3 例子:本地SPI找服务see alsojava -cp<...

TC2526 低功耗原边反馈开关电源芯片
概述 TC2526 是一款低功耗原边反馈(PSR)开关电源芯片,其内部集成了大功率 BJT 管,适用于隔离型的高效低功耗便携式设备充电器应用。TC2526 采用独特具有恒流恒压功能的原边反馈控制技术,以及独特的轻载调频技术降低轻载…...

3步搞定Football Manager面部包管理:NewGAN-Manager完全指南
3步搞定Football Manager面部包管理:NewGAN-Manager完全指南 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 你是否厌倦了在Football M…...
)
【电脑自动化助手】 OpenClaw 一键部署教程(包含安装包)
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭借本地运行 零代码 自动执行任务的特点收获大量…...

DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南
DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer DriverStore Explorer(简称RAPR)…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

利用模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用模型广场为你的智能客服场景挑选合适模型 智能客服是当前许多应用接入大模型的核心场景之一。开发者需要根据业务对响应速度、…...

LeaguePrank终极指南:3分钟掌握英雄联盟个人信息自定义
LeaguePrank终极指南:3分钟掌握英雄联盟个人信息自定义 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否厌倦了英雄联盟中千篇一律的个人资料展示?想要在召唤师峡谷中展示独特的自我形象ÿ…...

华为擎云L420变身MCU开发主力机:VSCode + Cortex-Debug + 自编译工具链玩转雅特力AT32
华为擎云L420打造高效MCU开发环境:VSCodeCortex-Debug全流程实战 在嵌入式开发领域,效率工具的选择往往能决定项目的成败。当国产化浪潮席卷技术圈,越来越多的开发者开始尝试在纯国产硬件上构建完整的工作流。华为擎云L420作为一款基于ARM架构…...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...

Windows Cleaner终极指南:5大核心技术解析与实战优化方案
Windows Cleaner终极指南:5大核心技术解析与实战优化方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的…...