spark超大数据批量写入redis
利用spark的分布式优势,一次性批量将7000多万的数据写入到redis中。
# 配置spark接口
import os
import findspark
from pyspark import SparkConf
from pyspark.sql import SparkSession
os.environ["JAVA_HOME"] = "/usr/local/jdk1.8.0_192"
findspark.init("/usr/local/hadoop/spark-2.4.4-bin-hadoop2.6/")
# 设置配置信息
conf = SparkConf()
conf.set("spark.driver.memory", "16g")
conf.set("spark.executor.memory", "16g")
conf.set("spark.driver.maxResultSize","3g")
conf.set("spark.executor.maxResultSize", "3g")
conf.set("spark.ui.showConsoleProgress","false") # 取消进度条显示
spark = SparkSession.builder.appName("local_redis_spark").master("local[*]").enableHiveSupport().config(conf=conf).getOrCreate()
spark.sparkContext.setLogLevel("ERROR") # 提升日志级别
import redis
# 初始化一个全局函数来获取Redis连接池
def get_redis_connection_pool():# 配置redis参数host='127.0.0.1' # 替换为redis的服务地址即可port=6379password='123456' # 密码db=1 # db库如果不设置 默认为0max_connections=10 # 设置最大连接数redis_pool = redis.ConnectionPool(host=host, port=port, db=db, password=password, max_connections=max_connections) return redis_pool# 清空旧数据
with redis.Redis(connection_pool=get_redis_connection_pool()) as r:r.flushdb() # 清空当前库的所有数据 而flushall()则情况所有库数据
%%time
# 并行处理函数serv_id
def servid_pfun(sdf_data):# 定义redis写入函数 以连接池的方式获取链接 及时释放def write_to_redis(data_dict):with redis.Redis(connection_pool=get_redis_connection_pool()) as r:r.mset(data_dict)# 构建一个空字典 批量写入dat = {}for rw in sdf_data:dat[rw.serv_id] = str((rw.r_inst_id, rw.avg_value))# 批量写入write_to_redis(dat)# 并行处理函数one_id
def oneid_pfun(sdf_data):# 定义redis写入函数 以连接池的方式获取链接 及时释放def write_to_redis(data_dict):with redis.Redis(connection_pool=get_redis_connection_pool()) as r:r.mset(data_dict)# 构建一个空字典 批量写入dat = {}for rw in sdf_data:dat[rw.r_inst_id] = str((rw.offer_list,rw.filter_prod_offer_inst_list,rw.fuka_serv_offer_list,rw.filter_list,rw.new_serv_id))# 批量写入write_to_redis(dat)# 加载缓存数据
oneid_sdf = spark.sql("""select * from database.table1""")servid_sdf = spark.sql("""select * from database.table2""")# 设置分区数 如果批量写入的内存大小以及最大链接数有限制
# servid_num_parts = 50000
# oneid_num_parts = 10000 # 使用repartition方法进行重新分区
# servid_sdf_part = servid_sdf.repartition(servid_num_parts)
# oneid_sdf_part = oneid_sdf.repartition(oneid_num_parts)# 分批写入redis
servid_sdf.foreachPartition(servid_pfun)
print(f"servid字典缓存成功")
oneid_sdf.foreachPartition(oneid_pfun)
print(f"oneid字典缓存成功")
# 关闭spark
spark.stop()
print(f"redis缓存插入成功")
执行时间可能跟资源环境有关,测试整个过程大概只需要5分钟左右,非常快速。
相关文章:

spark超大数据批量写入redis
利用spark的分布式优势,一次性批量将7000多万的数据写入到redis中。 # 配置spark接口 import os import findspark from pyspark import SparkConf from pyspark.sql import SparkSession os.environ["JAVA_HOME"] "/usr/local/jdk1.8.0_192"…...

C# Socket的使用
C# 中的 System.Net.Sockets.Socket 类是 .NET Framework 提供的核心类,用于处理网络套接字编程。Socket 类是用于网络编程的基础类,它位于 System.Net.Sockets 命名空间中。 使用 Socket 类,可以创建客户端和服务器应用程序来进行基于TCP、…...

Spring Cloud + Vue前后端分离-第17章 生产打包与发布
源代码在GitHub - 629y/course: Spring Cloud Vue前后端分离-在线课程 Spring Cloud Vue前后端分离-第17章 生产打包与发布 17-1 注册中心配置中心Nacos 注册中心 Nacos 快速开始 | Nacos 本节内容:使用nacos作注册中心配置中心,不用eureka Nacos…...

力扣热题100_普通数组_56_合并区间
文章目录 题目链接解题思路解题代码 题目链接 56. 合并区间 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区…...
)
Springcloud OpenFeign 的实现(二)
Springcloud OpenFeign 的实现(一) 一、Feign request/response 压缩 您可以考虑为您的外部请求启用请求或响应GZIP压缩。您可以通过启用以下属性之一来完成此操作: feign.compression.request.enabledtrue feign.compression.response.en…...
[C++]智能指针用法
一、智能指针存在的意义 智能指针主要解决以下问题: (1)内存泄漏:内存手动释放,使用智能指针可以自动释放。 (2)共享所有权指针的传播和释放,比如多线程使用同一个对象时析构问题…...

六、行列式基本知识
目录 1、行列式的特性 2、行列式的计算方法: 2.1 通过行列式的定义去计算:对角法则。 2. 2 利用行列式的性质将行列式转化为上三角行列式: ①行列式的性质 : 性质一: 性质二: 性质三: 性质四:行列式之间的加法...
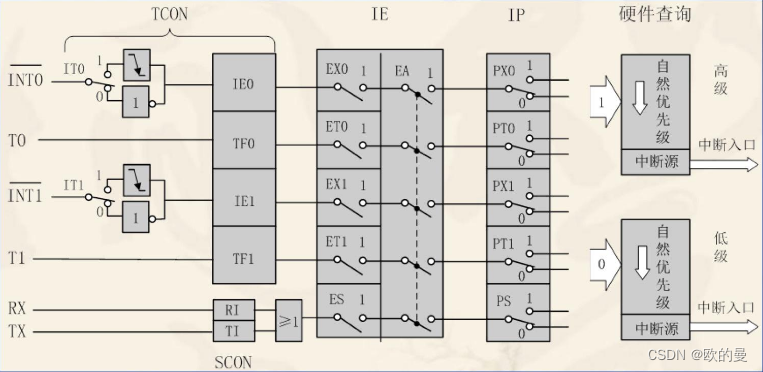
中断系统(详解与使用)
讲解 简介 中断是指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。 假设一个人在家看电视,这时候突然门铃响了,这个人此时就要停止看电视去开门,然后关上门后继续回来…...
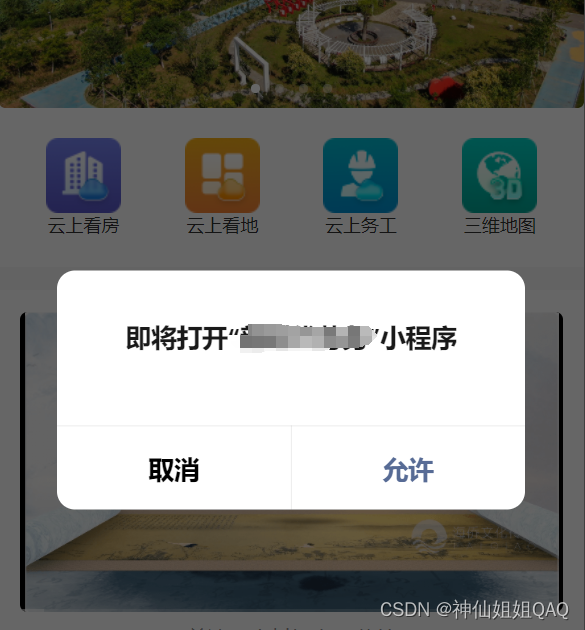
uniapp开发微信小程序跳转到另一个小程序中
注意:一开始我的云上务工模块是单独的tabbar界面,但是小程序跳转好像不能直接点击tabbar进行,所以我将这里改成了点击首页中的按钮进行跳转 点击这里进行小程序跳转 目录 基础讲解 uniapp小程序跳转的两个方法 调用说明(半屏跳转…...
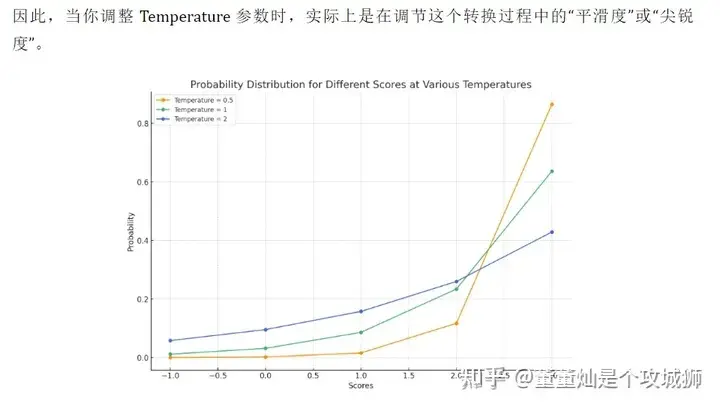
chatGPT 使用随想
一年前 chatGPT 刚出的时候,我就火速注册试用了。 因为自己就是 AI 行业的,所以想看看国际上最牛的 AI 到底发展到什么程度了. 自从一年前 chatGPT 火出圈之后,国际上的 AI 就一直被 OpenAI 这家公司引领潮流,一直到现在&#x…...
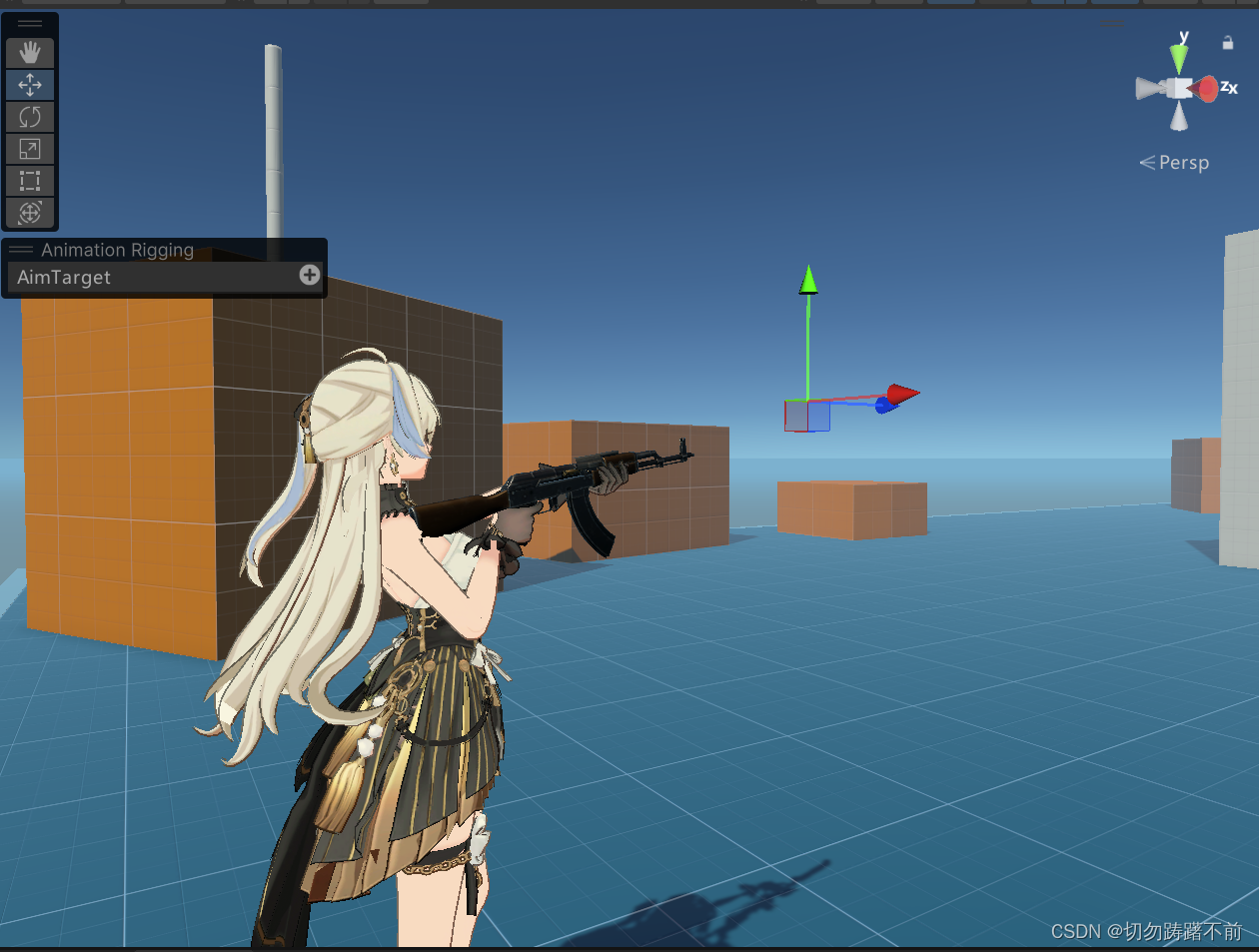
unity Aaimation Rigging使用多个约束导致部分约束失去作用
在应用多个约束时,在Hierarchy的顺序可能会影响最终的效果。例如先应用了Aim Constraint,然后再应用Two Bone Constraint,可能会导致Two Bone Constraint受到Aim Constraint的影响而失效。因此,在使用多个约束时,应该仔…...
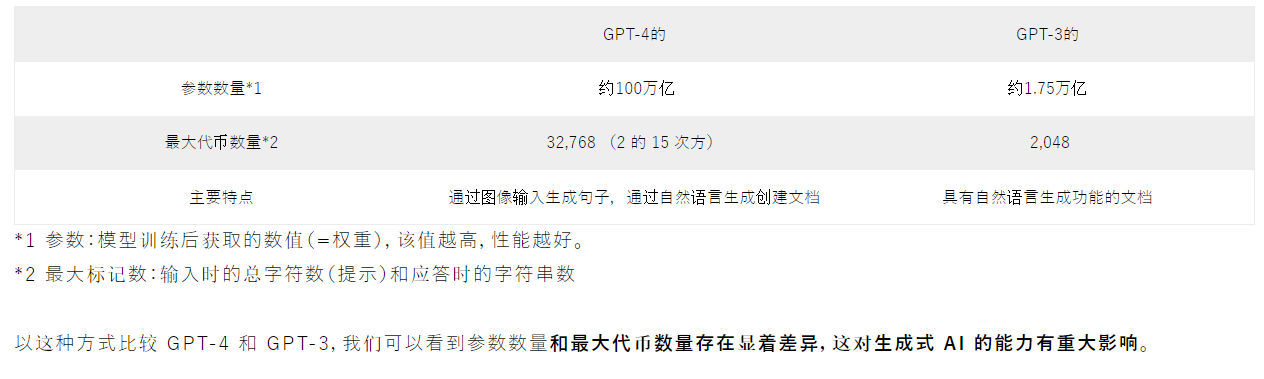
什么是ChatGPT
国外有篇文章解释了ChatGPT的开发技术是什么,GPT-3和GPT-4的区别,以及未来的可能性。 截至 2023 年,ChatGPT 等生成式 AI 服务正在全球引起关注,并且正在探索在广泛领域的应用。 您可能想知道 ChatGPT 是使用哪种开发技术制作的&a…...

当我们浪费时我们在浪费什么
世界上的物质和能量不会增加也不会减少,为什么会存在浪费一说呢?是因为人类可以利用和支配的物质和能量是有限的,而且物质和能量的不同组织方式对于人类有着不同的价值。 人类对于世界的事物都有价值评估。例如一个玻璃杯摔碎了,…...
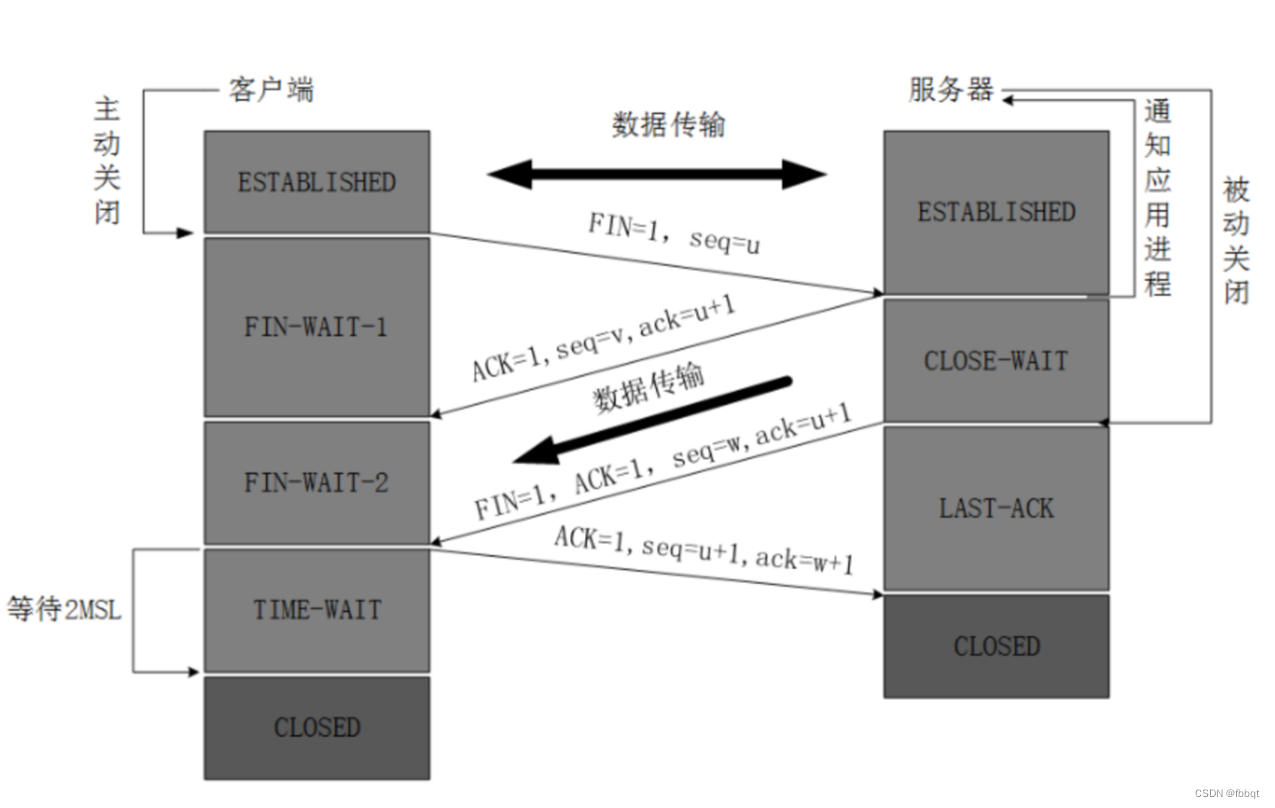
一文搞懂TCP三次握手与四次挥手
什么是TCP协议? TCP(Transmission control protocol)即传输控制协议,是一种面向连接、可靠的数据传输协议,它是为了在不可靠的互联网上提供可靠的端到端字节流而专门设计的一个传输协议。 面向连接:数据传…...
FairyGUI × Cocos Creator 3.7.3 引入报错解决
Cocos Creator 3.7.3引入fgui库 package.json添加这个依赖 "devDependencies": {"fairygui-cc": "latest"}执行npm i 报错解决 使用import引入fairygui-cc,就会有报错和警告,简单处理一下。 鼠标随便点一下也会出警告…...
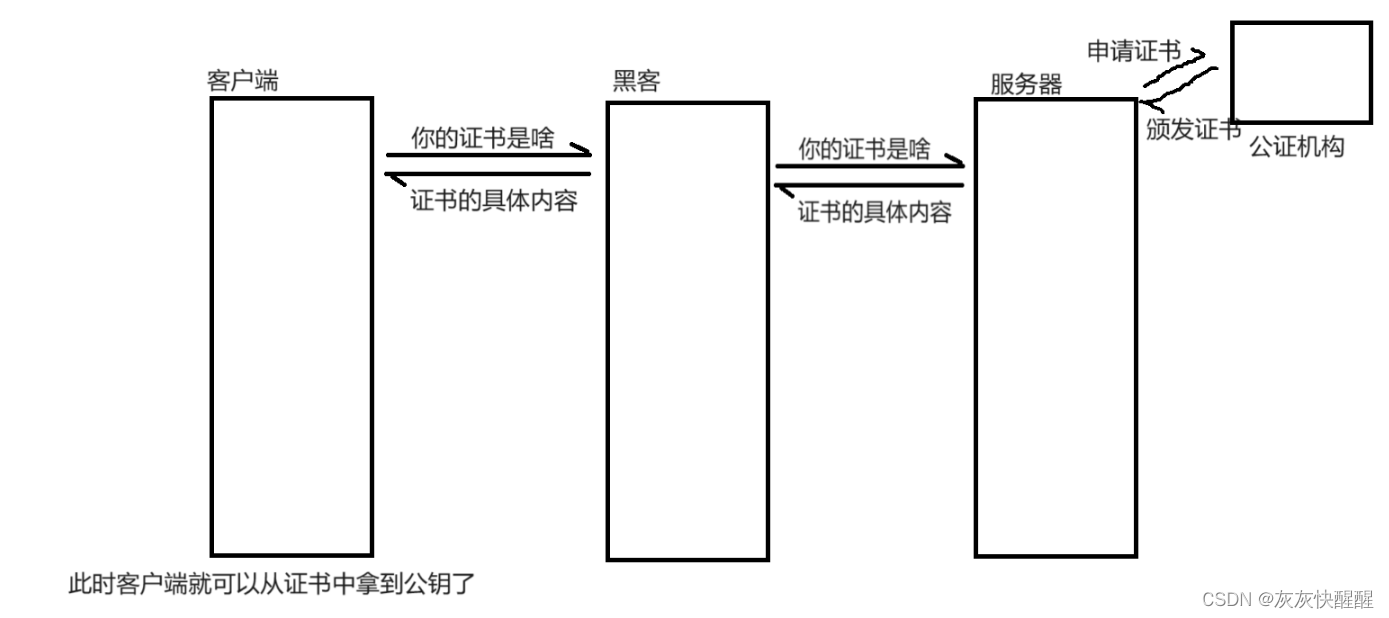
网络原理 - HTTP/HTTPS(5)
HTTPS HTTPS也是一个应用层协议.在HTTP协议的基础上引入了一个加密层. HTTP协议内容都是按照文本的方式明文传输的. 这就导致了在传输过程中出现了一些被篡改的情况. 臭名昭著的"运营商劫持" 下载一个天天动听. 未被劫持的效果,点击下载按钮,就会弹出天天动听的…...
设计模式——抽象工厂模式
定义: 抽象工厂模式(Abstract Factory Pattern)提供一个创建一系列或相互依赖对象的接口,而无须指定它们具体的类。 概述:一个工厂可以提供创建多种相关产品的接口,而无需像工厂方法一样,为每一个产品都提供一个具体…...

详解编译和链接!
目录 1. 翻译环境和运行环境 2. 翻译环境 2.1 预处理 2.2 编译 2.3 汇编 2.4 链接 3. 运行环境 4.完结散花 悟已往之不谏,知来者犹可追 创作不易,宝子们!如果这篇文章对你们…...
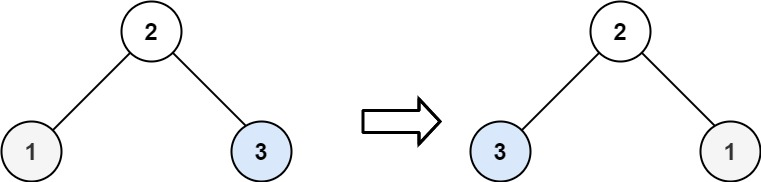
力扣226 翻转二叉树 Java版本
文章目录 题目描述解题思路代码 题目描述 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] 示例 2: 输入:root…...
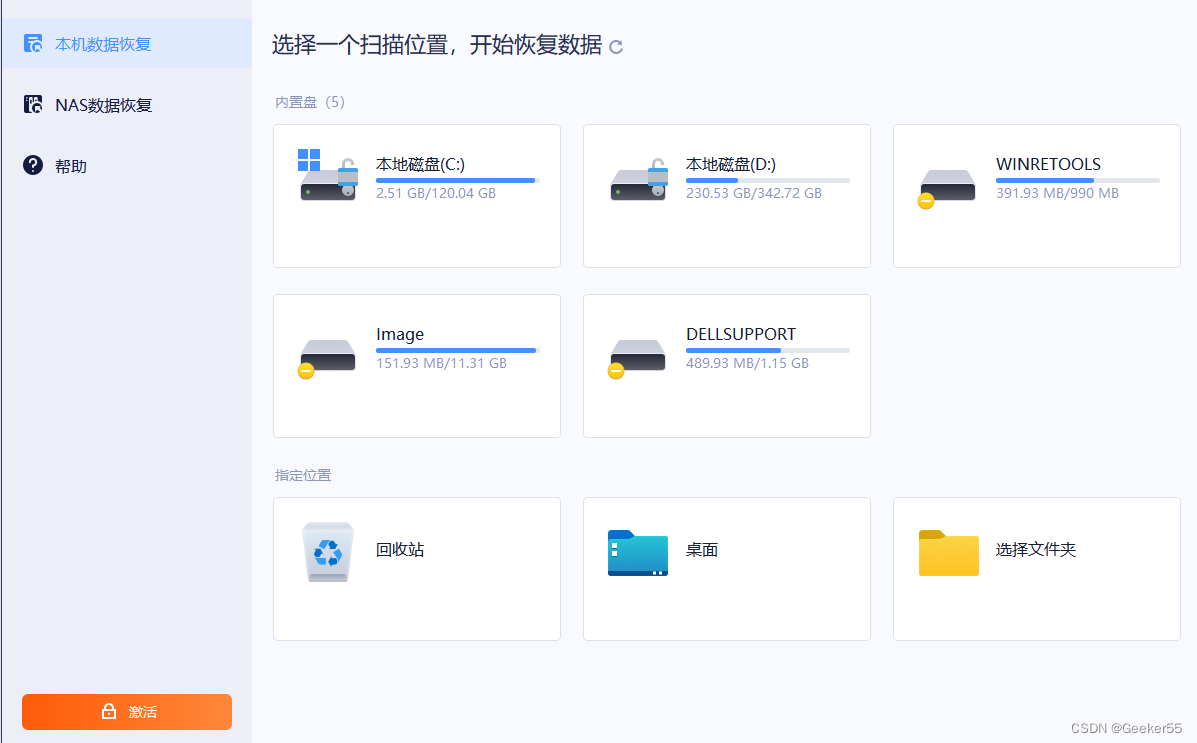
免费的数据恢复软件哪个好?这10个数据恢复软件可以试试
遇到电脑、硬盘或U盘等设备中数据丢失,不用着急,数据恢复软件来帮你。 在遇到数据丢失的问题时,很多朋友都会很着急也不知道该怎么办。作为数据恢复小白,我们可以选择使用数据恢复软件进行扫描恢复。现在市面上的数据恢复软件很多…...

独立可托管的 listmonk:新闻通讯与邮件列表管理的高效工具
【导语:listmonk 作为一款独立且可自行托管的新闻通讯和邮件列表管理工具,以其速度快、功能丰富等特点受到关注。本文将介绍其安装方式、开发者相关信息及许可证等内容。】功能特性鲜明的 listmonklistmonk 是一款独立的、可自行托管的新闻通讯和邮件列表…...

STM32与ADS1256的SPI通信实战:从寄存器配置到串口数据可视化
1. 硬件准备与电路连接 第一次接触ADS1256这块24位ADC芯片时,我被它的精度吓到了——理论上能分辨出0.000000119V的电压变化!不过要让STM32和它正常对话,硬件连接是第一个门槛。我用的STM32F103C8T6最小系统板,和ADS1256模块之间…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

基于Taotoken统一API开发支持多模型切换的智能对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken统一API开发支持多模型切换的智能对话应用 应用场景类,场景是开发一个需要支持用户自由选择或系统自动切换…...

DIY蓝牙游戏手柄:基于Bluefruit EZ-Key的免编程硬件制作全攻略
1. 项目概述与设计思路几年前,我还在用有线手柄在电脑上打游戏,那根线总是缠来缠去,桌面也乱糟糟的。后来市面上无线手柄选择多了,但总感觉少了点自己动手的乐趣,功能也千篇一律。直到我开始接触像Adafruit Bluefruit …...

2026产品经理学数据分析对升职的价值
一、数据分析能力对产品经理升职的重要性数据分析能力已成为产品经理的核心竞争力之一。掌握数据分析技能可以帮助产品经理更精准地决策,提升产品成功率,从而在职业发展中占据优势。二、数据分析在产品经理工作中的具体应用通过数据分析优化产品功能迭代…...

Sophia优化器:二阶曲率感知如何加速大模型训练与调参
1. 项目概述:当优化器遇上“二阶”智慧最近在复现一些前沿的论文实验时,我又一次被优化器的选择给卡住了。AdamW虽然稳,但在某些超大规模模型或特定任务上,总觉得收敛速度不够快,调参又是个玄学。就在我对着损失曲线发…...