AI大模型与小模型之间的“脱胎”与“反哺”(第一篇)
一、AI小模型脱胎于AI大模型,而AI小模型群又可以反哺AI大模型
AI大模型(如GPT、BERT等)通常拥有大量的参数和训练数据,能够生成或理解复杂的文本内容。这些大模型在训练完成后,可以通过剪枝、微调等方式转化为小模型,以适应不同的应用场景,比如嵌入式设备、移动应用或者对计算资源有限制的环境。
另一方面,AI小模型群在各自的领域中通过持续学习和优化,可以积累丰富的经验和知识。这些小模型在实际应用过程中产生的新数据、反馈信息以及改进策略,又可以被用于进一步迭代和升级AI大模型。这种“反哺”机制体现在:
1. 数据收集:AI小模型在与用户交互过程中生成的新数据,可以作为大模型训练的补充,帮助大模型更好地理解和适应现实世界的复杂性和多样性。
2. 知识迁移:AI小模型针对特定场景的专业化知识和技能,经过整合和提炼后,可以为大模型提供更具体和深入的知识输入。
3. 模型优化:从小模型获取到的有效算法改进、架构调整等经验,有助于提升大模型的学习效率和性能表现。
因此,AI大模型和小模型之间形成了一个相互促进、共同发展的生态循环系统。
此图片来源于网络
二、“脱胎”与“反哺”
元学习(Meta Learning)和迁移学习(Transfer Learning)是机器学习中两种不同的学习策略,它们都旨在利用已有的知识来帮助新任务的学习,但其核心思想与应用场景有所不同:
**元学习**:
1. 目标:元学习的目标在于“学习如何学习”,即训练模型掌握快速适应新任务的能力。它强调的是在多个相关的小规模任务上进行训练,从而学习到一种能够快速收敛、泛化到未见过的任务上的学习算法或初始化权重。
2. 方法:元学习通常采用“任务采样”的方式,在每次迭代过程中从一系列任务分布中抽样出小批量任务来进行训练,通过这种过程学习一个通用的初始化参数或者优化器,使得在面对新的目标任务时只需要少量样本就能快速调整和适应。
**迁移学习**:
1. 目标:迁移学习主要是将从一个或多个源任务中学到的知识应用到目标任务中,以改善目标模型的性能。它的重点在于重用预训练模型中的特征表示或其他相关信息,而不是从零开始训练一个新的模型。
2. 方法:迁移学习经常表现为使用在大型数据集(如ImageNet)上预先训练好的深度神经网络模型,将其顶层(通常是分类层)替换成针对新任务的结构,并根据目标数据集对部分或全部模型参数进行微调。迁移学习可以显著减少对新任务所需的大规模标注数据依赖。
总结起来,两者的主要区别在于:
- 元学习关注于学习到适用于任何任务的高效学习策略,解决的是如何更快地学习新任务的问题。
- 迁移学习关注于将从一个任务中学到的知识直接应用于另一个任务,尤其在有相关性的情况下,更侧重于复用已经学到的有用特征表示。

此图片来源于网络
三、小模型反哺大模型(108个想法)
利用众多行业AI小模型提升通用AI大模型能力的具体手段可以包括但不限于以下几种方法:
1. **知识蒸馏(Knowledge Distillation)**:
小型行业模型通常在各自领域有较高的准确性和专业性。通过知识蒸馏技术,将小型模型的预测结果或中间层特征“软标签”传递给大型模型学习,使得大模型能够模仿并吸收小模型的专业知识。
2. **多任务学习(Multi-Task Learning, MTL)**:
设计一个多任务学习框架,让大模型同时处理来自各个行业的小模型所对应的任务。大模型会共享底层特征提取部分,并为每个任务配备特定的输出层,从而学习到跨领域的通用和专用特征表示。
3. **元学习(Meta-Learning / Learning to Learn)**:
利用多个行业的小模型训练数据作为元训练集,训练一个能够快速适应新任务的大模型。大模型在不同任务之间进行迭代训练,学习如何快速调整自身的参数以应对新的、有限样本的任务。
4. **迁移学习与微调(Transfer Learning and Fine-tuning)**:
结合预训练的小型行业模型,将其底层权重或部分网络结构整合到大模型中,然后使用特定行业的数据对大模型进行微调,这样可以充分利用小模型在特定领域的学习成果。
5. **模型融合(Model Fusion or Ensemble)**:
将多个小型行业模型集成在一起形成混合系统,大模型可以通过分析和学习这些小模型在决策过程中的互补性和一致性,优化自身的表现。
6. **深度神经网络模块复用(Module Reuse in Deep Networks):
对于各行业中有相似功能或者问题结构的部分,从小模型中挑选出有效的神经网络模块加入到大模型中,实现跨行业的知识转移。
7. **联邦学习(Federated Learning)**:
在保护隐私的前提下,联合多个行业的小模型进行分布式训练,各自贡献模型更新信息,在云端构建统一的大模型,使大模型能够汇总多个行业特有的模式和规律。
8. **动态架构学习(Dynamic Architecture Learning)**:
根据不同行业任务的需求,动态地组合或调整预先训练好的小型模型组件,形成具有自适应能力的大模型。
9. **强化学习与元学习结合(Reinforcement Learning with Meta-Learning)**:
通过将强化学习应用于元学习框架中,让AI大模型在不同行业的小任务环境中学习如何调整其参数和行为策略,以适应新的、未知的任务环境。
10. **领域自适应(Domain Adaptation)**:
将多个行业小模型视为不同的源域,训练大模型学会从这些源域迁移到目标域的能力。大模型通过对不同行业数据的特征迁移和分布匹配,提高对新行业场景的理解和适应性。
11. **生成式对抗网络(Generative Adversarial Networks, GANs)**:
利用GANs或者变种技术生成各种行业的模拟数据,扩充大模型的训练集,使得大模型能够接触到更丰富的场景和案例,从而提升泛化能力。
12. **可解释性和因果推理(Interpretability and Causal Inference)**:
分析各个行业AI小模型的决策逻辑和因果关系,提炼出具有普适性的因果规律,并将其融入到AI大模型的设计和优化过程中,使其具备更强的跨行业推理和泛化能力。
13. **持续学习或终身学习(Continual Learning / Lifelong Learning)**:
让大模型以一种连续的方式不断学习并整合来自各行业的小模型的知识,同时设计相应的机制防止遗忘旧知识,确保大模型能随着时间和新任务的增加而持续进化和改进。
14. **联邦学习与联合建模(Federated Learning and Collaborative Modeling)**:
联邦学习允许AI大模型在不直接访问各行业小模型数据的情况下,通过分布式训练和信息交互来整合各个领域的知识。每个行业的本地模型在保护数据隐私的前提下,在本地进行训练,并将模型更新传输至中心服务器,大模型根据这些更新进行全局优化。
15. **多任务学习(Multi-Task Learning, MTL)**:
在一个统一的大模型架构中设计多个并行的任务头,每个任务头对应不同行业的特定需求。共享底层的表示层可以捕获跨行业的共同特征,同时利用各自的任务特定层来应对不同场景下的个性化要求。
16. **深度强化迁移学习(Deep Reinforcement Transfer Learning)**:
结合深度强化学习与迁移学习技术,让AI大模型从不同行业的RL任务中学习到通用策略,然后通过少量样本或环境交互就能快速适应新行业或新任务的需求。
17. **自监督学习(Self-Supervised Learning)**:
通过构建跨行业的自监督学习任务,如预测隐藏部分、重建输入数据或挖掘潜在结构等,使得大模型在无标注或少标注的数据环境下也能提取出有意义的行业共性特征。
18. **元决策森林(Meta Decision Forests)**:
利用元学习思想结合决策树或者随机森林等传统机器学习方法,形成一种能够快速适应新行业问题的元决策森林模型,它能够在面临新领域时迅速调整其内部结构以适应新的决策边界。
19. **神经架构搜索与元学习结合(Neural Architecture Search with Meta-Learning)**:
利用元学习来指导神经架构搜索过程,动态地发现和优化适合处理多行业任务的网络结构。通过这种方式训练出的大模型能够更好地捕获各行业间的共性特征,并在新领域快速适应。
20. **层级迁移学习(Hierarchical Transfer Learning)**:
根据不同行业的相似性和层次关系,设计多层次的迁移学习框架。底层共享通用特征表示,而上层针对特定行业进行细粒度的知识迁移,使得大模型在保留泛化能力的同时具备深入理解各行业特性的能力。
相关文章:
AI大模型与小模型之间的“脱胎”与“反哺”(第一篇)
一、AI小模型脱胎于AI大模型,而AI小模型群又可以反哺AI大模型 AI大模型(如GPT、BERT等)通常拥有大量的参数和训练数据,能够生成或理解复杂的文本内容。这些大模型在训练完成后,可以通过剪枝、微调等方式转化为小模型&…...
C#学习总结
1、访问权限 方法默认访问修饰符:private 类默认访问修饰符:internal 类的成员默认访问修饰符:private 2、UserControl的使用 首先添加用户控件 使用时一种是通过代码添加,一种是通过拖动组件到xaml中...

计算机网络-网络互联
文章目录 网络互联网络互联方法LAN-LAN:网桥及其互连原理使用网桥实现LAN-LAN使用交换机扩展局域网使用路由器连接局域网 LAN-WANWAN-WAN路由选择算法非自适应路由选择算法自适应路由选择算法广播路由选择算法:分层路由选择算法 网络互联 网络互联是指利…...

免费的ChatGPT网站( 7个 )
ChatGPT 是由 OpenAI 公司研发的一款大型语言模型,它可以实现智能聊天、文本生成、语言翻译等多种功能。以下是 ChatGPT 的详细介绍: 智能聊天:ChatGPT 可以与用户进行自然语言对话,回答用户的问题,提供相关的信息和建…...

Opencv3.2 ubuntu20.04安装过程
##1、更新源 sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main" sudo apt update##2、安装依赖库 sudo apt-get install build-essential sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavfor…...

OpenGL ES (OpenGL) Compute Shader 计算着色器是怎么用的?
OpenGL ES (OpenGL) Compute Shader 是怎么用的? Compute Shader 是 OpenGL ES(以及 OpenGL )中的一种 Shader 程序类型,用于在GPU上执行通用计算任务。与传统的顶点着色器和片段着色器不同,Compute Shader 被设计用于在 GPU 上执行各种通用计算任务,而不是仅仅处理图形…...

Python爬虫进阶:爬取在线电视剧信息与高级检索
简介: 本文将向你展示如何使用Python创建一个能够爬取在线电视剧信息的爬虫,并介绍如何实现更高级的检索功能。我们将使用requests和BeautifulSoup库来爬取数据,并使用pandas库来处理和存储检索结果。 目录 一、爬取在线电视剧信息 …...

Floor报错原理详解+sql唯一约束性
目录 floor报错原理 唯一性约束 主键约束: 创建约束的形式 删除约束 删除唯一性约束(UNIQUE Constraint) 在SQL Server中: 在MySQL中: 在PostgreSQL中: 删除主键约束: floor报错原理 …...
Arduino中安装ESP32网络抽风无法下载 暴力解决办法 python
不知道什么仙人设计的arduino连接网络部分,死活下不下来。(真的沙口,第一次看到这么抽风的下载口) 操作 给爷惹火了我踏马解析json选zip直接全部下下来 把这个大家的开发板管理地址下下来跟后面python放在同一目录下,…...

Linux基础命令—系统服务
基础知识 centos系统的开机流程 1)通电 2)BIOS硬件检查 3)MBR引导记录 mbr的引导程序 加载引导程序 让硬件加载操作系统内核 MBR在第一个磁盘第一个扇区 总大小512字节 mbr: 1.引导程序: 占用446字节用于引导硬件,加载引导程序 2.分区表: 总共占…...
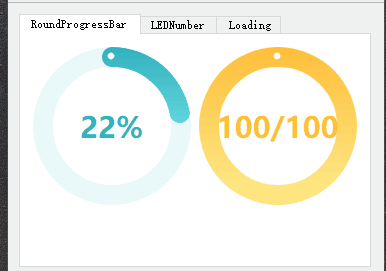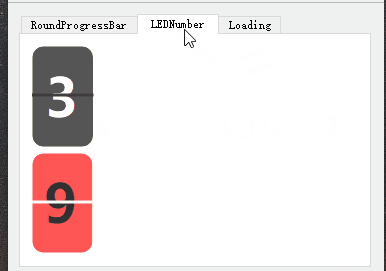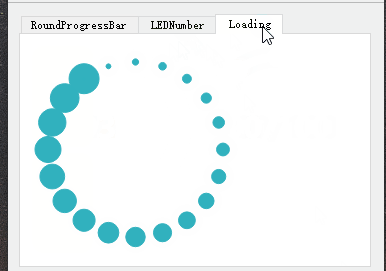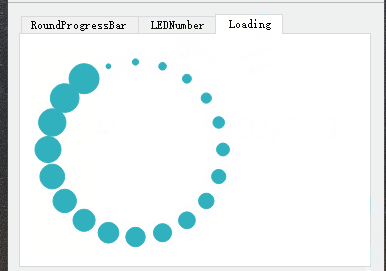
qt-动画圆圈等待-LED数字
qt-动画圆圈等待-LED数字 一、演示效果二、关键程序三、下载链接 一、演示效果 二、关键程序 #include "LedNumber.h" #include <QLabel>LEDNumber::LEDNumber(QWidget *parent) : QWidget(parent) {//设置默认宽高比setScale((float)0.6);//设置默认背景色se…...

SpringBoot3整合Swagger3,访问出现404错误问题(未解决)
秉承着能用就用新的的理念,在JDK、SpringBoot、SpringCloud版本的兼容性下,选择了Java17、SpringBoot3.0.2整合Swagger3。 代码编译一切正常,Swagger的Bean也能加载,到了最后访问前端页面swagger-ui的时候出现404。 根据网上资料…...

Django配置文件参数详解
Django是一个高级的Python Web框架,它遵循MVC设计模式,并内置了许多功能,如认证、URL路由、模板引擎、对象关系映射(ORM)等。为了定制Django项目的各种功能和行为,我们需要编辑其配置文件。Django的主要配置…...
Docker+Kafka+Kafka-ui安装与配置
前言 Docker、Kafka都是开发中常用到的组件。在自己的第三台电脑上去安装这些…所以写个博客记录一下安装过程。本文主要内容:Docker安装、kafka安装、kafka可视化配置。这次的电脑环境是Windows11,Intel处理器。 Docker安装 https://www.docker.com/p…...

单例模式的介绍
单例模式(Singleton)是一种创建型设计模式,它确保一个类只有一个实例,并提供全局访问点。其核心思想是通过限制类的实例化次数,防止多个实例同时存在,从而避免了多线程竞争和资源浪费,提高了代码…...

JavaSec 基础之 XXE
文章目录 XMLReaderSAXReaderSAXBuilderDocumentBuilderUnmarshaller**SAXParserFactory**XMLReaderFactoryDigester总结 XMLReader public String XMLReader(RequestBody String content) {try {XMLReader xmlReader XMLReaderFactory.createXMLReader();// 修复:…...
AI:137-基于深度学习的实时交通违法行为检测与记录
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…...

【深度学习笔记】3_14 正向传播、反向传播和计算图
3.14 正向传播、反向传播和计算图 前面几节里我们使用了小批量随机梯度下降的优化算法来训练模型。在实现中,我们只提供了模型的正向传播(forward propagation)的计算,即对输入计算模型输出,然后通过autograd模块来调…...
Jenkins详解
目录 一、Jenkins CI/CD 1、 Jenkins CI/CD 流程图 2、介绍 Jenkins 1、Jenkins概念 2、Jenkins目的 3、特性 4、产品发布流程 3、安装Jenkins 1、安装JDK 2、安装tomcat 3.安装maven 4安装jenkins 5.启动tomcat,并页面访问 5.添加节点 一、Jenkins CI/…...

Java8 Stream API 详解:流式编程进行数据处理
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...

Arm DSTREAM调试接口设计与JTAG/SWD协议详解
1. Arm DSTREAM系统与调试接口设计指南1.1 调试接口技术基础1.1.1 JTAG协议架构解析JTAG(Joint Test Action Group)标准IEEE 1149.1定义了五线制调试接口:TCK:测试时钟,同步所有JTAG操作TMS:测试模式选择&a…...

嵌入式以太网模块WIZ5500应用指南:从SPI接口到物联网稳定连接
1. 项目概述:为什么你的物联网项目需要一个有线网络“锚点”无线网络(Wi-Fi)确实方便,但做过几个实际项目的朋友都知道,它的“方便”有时是建立在“不确定性”之上的。信号波动、信道拥堵、复杂的认证流程,…...

基于Docker Compose的容器化数据抓取平台OpenClaw部署与实战
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一些数据采集和自动化处理的工作流,发现一个挺有意思的项目:alexleach/openclaw-compose。光看名字,openclaw直译是“开放之爪”,compose则明确指向了 Doc…...

NumPy 使用指南
一、为什么选择 NumPy 而非 Python 列表Python 原生列表(list)虽能存储数组形式的数据,但存在显著性能缺陷:内存效率低:列表存储的是对象指针,即使存储简单数值(如 [0,1,2])…...
)
DeepSeek MMLU 86.7分是怎么炼成的?从提示工程、校准策略到知识蒸馏链路(内部训练日志首次公开)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MMLU 86.7分的里程碑意义与基准解读 MMLU 基准的本质与挑战 MMLU(Massive Multitask Language Understanding)是一项覆盖57个学科领域的综合性评测基准,涵…...

紧急通知:v8.1即将关闭旧版审美缓存——72小时内必须完成的3步风格校准清单
更多请点击: https://intelliparadigm.com 第一章:v8.1旧版审美缓存关停的技术动因与全局影响 核心架构演进压力 V8.1 引擎中长期运行的“审美缓存”(Aesthetic Cache)模块,本质上是一套基于 DOM 树节点样式偏好建模…...

Stardew Valley Mod开发:使用OpenClaw主题框架快速构建原生风格UI
1. 项目概述:一个为Stardew Valley Mod开发者量身打造的主题框架如果你是一位《星露谷物语》(Stardew Valley)的模组(Mod)开发者,或者正打算踏入这个充满创造力的社区,那么你很可能已经体会过&a…...

如何在IDEA中打造你的私人阅读空间:3个实用技巧提升编程效率与阅读体验
如何在IDEA中打造你的私人阅读空间:3个实用技巧提升编程效率与阅读体验 【免费下载链接】thief-book-idea IDEA插件版上班摸鱼看书神器 项目地址: https://gitcode.com/gh_mirrors/th/thief-book-idea 在快节奏的编程工作中,如何有效利用碎片化时…...

如何用baidupankey工具实现百度网盘提取码10秒智能查询
如何用baidupankey工具实现百度网盘提取码10秒智能查询 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要提取码的资源,都要在多个网站间来回搜索&a…...

Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 [特殊字符]️
Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 🛡️ 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin 想要确保你的…...