NLP 使用Word2vec实现文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客
🍦 参考文章:365天深度学习训练营
🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)
一、加载数据

import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
print(train_data)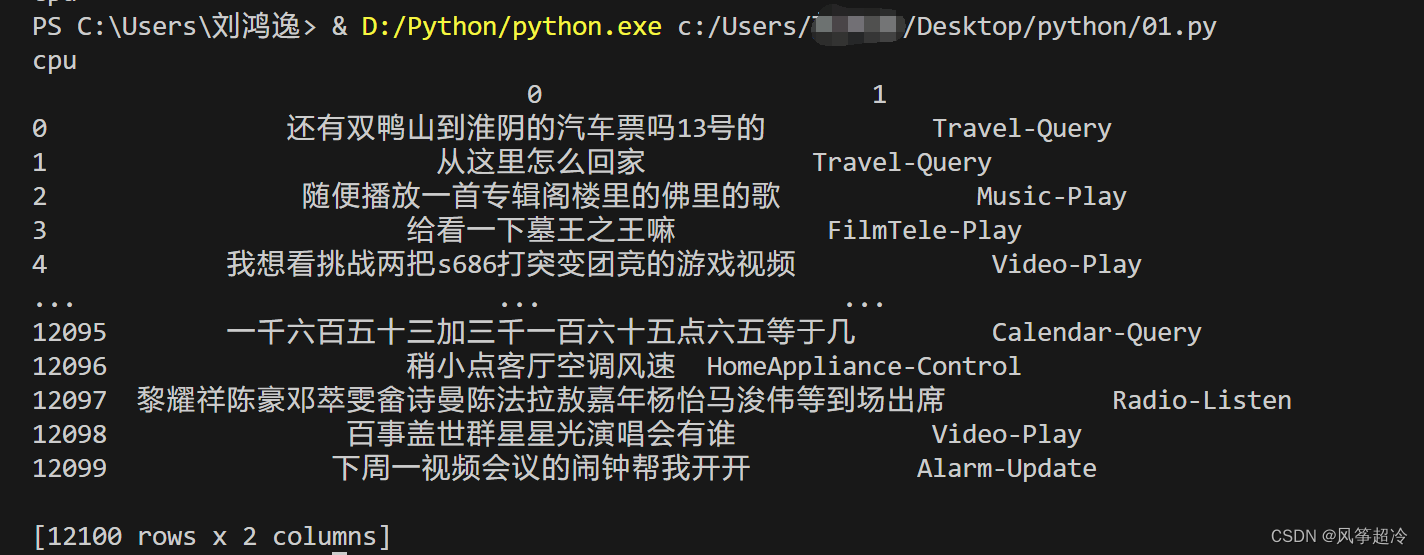
二、构造数据迭代器
# 构造数据集迭代器
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, yx = train_data[0].values[:]
#多类标签的one-hot展开
y = train_data[1].values[:]
print(x,"\n",y)yield x, y:使用 yield 关键字,将每次迭代得到的 (x, y) 元组作为迭代器的输出。yield 的作用类似于 return,但不同之处在于它会暂停函数的执行,并将结果发送给调用方,但函数的状态会被保留,以便下次调用时从上次离开的地方继续执行。

三、构建词典
from gensim.models.word2vec import Word2Vec
import numpy as np# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(vector_size=100, #是指特征向量的维度,默认为100。min_count=3) #可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5。w2v.build_vocab(x)
w2v.train(x, total_examples=w2v.corpus_count, epochs=20)Word2Vec可以直接训练模型,一步到位。这里分了三步
-
Word2Vec(vector_size=100, min_count=3): 创建了一个Word2Vec对象,设置了词向量的维度为100,同时设置了词频最小值为3,即只有在训练语料中出现次数不少于3次的词才会被考虑。 -
w2v.build_vocab(x): 使用 build_vocab 方法根据输入的文本数据 x 构建词典。build_vocab 方法会统计输入文本中每个词汇出现的次数,并按照词频从高到低的顺序将词汇加入词典中。 -
w2v.train(x, total_examples=w2v.corpus_count, epochs=20): 训练Word2Vec模型,其中:
x是训练数据。total_examples=w2v.corpus_count:total_examples 参数指定了训练时使用的文本数量,这里使用的是 w2v.corpus_count 属性,表示输入文本的数量epochs=20指定了训练的轮数,每轮对整个数据集进行一次训练。
# 将文本转化为向量
def average_vec(text):vec = np.zeros(100).reshape((1, 100))for word in text:try:vec += w2v.wv[word].reshape((1, 100))except KeyError:continuereturn vec# 将词向量保存为 Ndarray
x_vec = np.concatenate([average_vec(z) for z in x])# 保存 Word2Vec 模型及词向量
w2v.save('w2v_model.pkl')这段代码逐步完成了将文本转化为词向量的过程,并保存了Word2Vec模型及词向量。
-
average_vec(text): 这个函数接受一个文本列表作为输入,并返回一个平均词向量。它首先创建了一个形状为(1, 100)的全零NumPy数组vec,用于存储文本的词向量的累加和。然后,它遍历文本中的每个词,尝试从已经训练好的Word2Vec模型中获取词向量,如果词在模型中存在,则将其词向量加到vec中。如果词不在模型中(KeyError异常),则跳过该词。最后,返回词向量的平均值。 -
x_vec = np.concatenate([average_vec(z) for z in x]): 这一行代码使用列表推导式,对数据集中的每个文本z调用average_vec函数,得到文本的词向量表示。然后,使用np.concatenate函数将这些词向量连接成一个大的NumPy数组x_vec。这个数组的形状是(样本数, 100),其中样本数是数据集中文本的数量。 -
w2v.save('w2v_model.pkl'): 这一行代码保存了训练好的Word2Vec模型及词向量。w2v.save()方法将整个Word2Vec模型保存到文件中。
train_iter = coustom_data_iter(x_vec, y)
print(len(x),len(x_vec))-
train_iter = coustom_data_iter(x_vec, y): 这行代码创建了一个名为train_iter的迭代器,用于迭代训练数据。它调用了一个名为coustom_data_iter的函数,该函数接受两个参数x_vec和y,分别表示训练样本的特征和标签。在这个上下文中,x_vec是一个NumPy数组,包含了训练样本的特征向量表示,y是一个数组,包含了训练样本的标签。该迭代器将用于训练模型。 -
print(len(x),len(x_vec)): 这行代码打印了训练数据的长度,即x的长度和x_vec的长度。在这里,len(x)表示训练样本的数量,len(x_vec)表示每个样本的特征向量的长度(通常表示特征的维度)。这行代码的目的是用于验证数据的准备是否正确,以及特征向量的维度是否与预期一致。
![]()
label_name = list(set(train_data[1].values[:]))
print(label_name)
四、生成数据批次和迭代器
text_pipeline = lambda x: average_vec(x)
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline("你在干嘛"))
print(label_pipeline("Travel-Query"))-
text_pipeline = lambda x: average_vec(x): 这一行定义了一个名为text_pipeline的匿名函数(lambda函数),它接受一个参数x(文本数据)。在函数体内部,它调用了前面定义的average_vec函数,将文本数据x转换为词向量的平均值。 -
label_pipeline = lambda x: label_name.index(x): 这一行定义了另一个匿名函数label_pipeline,它接受一个参数x,该参数表示标签数据。在函数体内部,它调用了index方法来查找标签在label_name列表中的索引,并返回该索引值。 -
print(text_pipeline("你在干嘛")): 这行代码调用了text_pipeline函数,将字符串 "你在干嘛" 作为参数传递给函数。函数会将这个文本转换为词向量的平均值,并打印出来。 -
print(label_pipeline("Travel-Query")): 这行代码调用了label_pipeline函数,将字符串 "Travel-Query" 作为参数传递给函数。函数会在label_name列表中查找 "Travel-Query" 的索引,并打印出来。

from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list= [], []for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.float32)text_list.append(processed_text)label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)return text_list.to(device),label_list.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)-
text_pipeline = lambda x: average_vec(x): 这行代码创建了一个名为text_pipeline的匿名函数,该函数接受一个参数x,表示文本数据。在这里,text_pipeline函数被定义为average_vec(x),即调用之前定义的average_vec函数,用来将文本转换为向量表示。 -
label_pipeline = lambda x: label_name.index(x): 这行代码创建了一个名为label_pipeline的匿名函数,该函数接受一个参数x,表示标签数据。在这里,label_pipeline函数被定义为label_name.index(x),即查找x在label_name列表中的索引,返回其索引值作为标签的表示。 -
collate_batch(batch): 这是一个自定义的函数,用于处理一个批次(batch)的数据。它接受一个批次的数据作为输入,并对数据进行处理,最后返回处理后的文本和标签列表。 -
在
collate_batch函数中:- 首先,创建了两个空列表
label_list和text_list,用于存储标签和文本数据。 - 然后,对批次中的每个样本进行遍历,提取样本的文本和标签。
- 对于标签部分,调用了
label_pipeline函数将标签转换为模型可接受的格式,并添加到label_list中。 - 对于文本部分,调用了
text_pipeline函数将文本转换为向量表示,并转换为 PyTorch 张量格式,并添加到text_list中。 - 最后,将
label_list转换为 PyTorch 整数张量格式,将text_list进行拼接并转换为 PyTorch 浮点数张量格式,并返回这两个张量。
- 首先,创建了两个空列表
-
dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch): 这行代码创建了一个 PyTorch 的数据加载器DataLoader,用于加载训练数据。其中参数说明如下:train_iter是之前定义的用于迭代训练数据的迭代器。batch_size=8指定了每个批次的样本数量为 8。shuffle=False表示不对数据进行洗牌,即不打乱样本的顺序。collate_fn=collate_batch指定了数据加载器在每个批次加载数据时调用的数据处理函数为collate_batch函数,用于处理每个批次的数据。
五、构建模型
from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, num_class):super(TextClassificationModel, self).__init__()self.fc = nn.Linear(100, num_class)def forward(self, text):return self.fc(text)num_class = len(label_name)
vocab_size = 100000
em_size = 12
model = TextClassificationModel(num_class).to(device)import timedef train(dataloader):model.train() # 切换为训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text,label) in enumerate(dataloader):predicted_label = model(text)optimizer.zero_grad() # grad属性归零loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 每一步自动更新# 记录acc与losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx,len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换为测试模式total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text,label) in enumerate(dataloader):predicted_label = model(text)loss = criterion(predicted_label, label) # 计算loss值# 记录测试数据total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count, train_loss/total_count六、训练模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 超参数
EPOCHS = 10 # epoch
LR = 5 # 学习率
BATCH_SIZE = 64 # batch size for trainingcriterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 构建数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| epoch {:1d} | time: {:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch,time.time() - epoch_start_time,val_acc,val_loss,lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为:{:5.4f}'.format(test_acc))| epoch 1 | 50/ 152 batches | train_acc 0.732 train_loss 0.02655
| epoch 1 | 100/ 152 batches | train_acc 0.822 train_loss 0.01889
| epoch 1 | 150/ 152 batches | train_acc 0.838 train_loss 0.01798
---------------------------------------------------------------------
| epoch 1 | time: 0.93s | valid_acc 0.812 valid_loss 0.019 | lr 5.000000
---------------------------------------------------------------------
| epoch 2 | 50/ 152 batches | train_acc 0.840 train_loss 0.01745
| epoch 2 | 100/ 152 batches | train_acc 0.843 train_loss 0.01807
| epoch 2 | 150/ 152 batches | train_acc 0.843 train_loss 0.01846
---------------------------------------------------------------------
| epoch 2 | time: 1.01s | valid_acc 0.854 valid_loss 0.020 | lr 5.000000
---------------------------------------------------------------------
| epoch 3 | 50/ 152 batches | train_acc 0.850 train_loss 0.01770
| epoch 3 | 100/ 152 batches | train_acc 0.850 train_loss 0.01675
| epoch 3 | 150/ 152 batches | train_acc 0.859 train_loss 0.01565
---------------------------------------------------------------------
| epoch 3 | time: 0.98s | valid_acc 0.836 valid_loss 0.023 | lr 5.000000
---------------------------------------------------------------------
| epoch 4 | 50/ 152 batches | train_acc 0.898 train_loss 0.00972
| epoch 4 | 100/ 152 batches | train_acc 0.892 train_loss 0.00936
| epoch 4 | 150/ 152 batches | train_acc 0.900 train_loss 0.00948
---------------------------------------------------------------------
| epoch 4 | time: 0.91s | valid_acc 0.879 valid_loss 0.011 | lr 0.500000
---------------------------------------------------------------------
| epoch 5 | 50/ 152 batches | train_acc 0.911 train_loss 0.00679
| epoch 5 | 100/ 152 batches | train_acc 0.899 train_loss 0.00786
| epoch 5 | 150/ 152 batches | train_acc 0.903 train_loss 0.00752
---------------------------------------------------------------------
| epoch 5 | time: 0.91s | valid_acc 0.879 valid_loss 0.010 | lr 0.500000
---------------------------------------------------------------------
| epoch 6 | 50/ 152 batches | train_acc 0.905 train_loss 0.00692
| epoch 6 | 100/ 152 batches | train_acc 0.915 train_loss 0.00595
| epoch 6 | 150/ 152 batches | train_acc 0.910 train_loss 0.00615
---------------------------------------------------------------------
| epoch 6 | time: 0.90s | valid_acc 0.880 valid_loss 0.010 | lr 0.050000
---------------------------------------------------------------------
| epoch 7 | 50/ 152 batches | train_acc 0.907 train_loss 0.00615
| epoch 7 | 100/ 152 batches | train_acc 0.911 train_loss 0.00602
| epoch 7 | 150/ 152 batches | train_acc 0.908 train_loss 0.00632
---------------------------------------------------------------------
| epoch 7 | time: 0.92s | valid_acc 0.881 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 8 | 50/ 152 batches | train_acc 0.903 train_loss 0.00656
| epoch 8 | 100/ 152 batches | train_acc 0.915 train_loss 0.00582
| epoch 8 | 150/ 152 batches | train_acc 0.912 train_loss 0.00578
---------------------------------------------------------------------
| epoch 8 | time: 0.93s | valid_acc 0.881 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 9 | 50/ 152 batches | train_acc 0.903 train_loss 0.00653
| epoch 9 | 100/ 152 batches | train_acc 0.913 train_loss 0.00595
| epoch 9 | 150/ 152 batches | train_acc 0.914 train_loss 0.00549
---------------------------------------------------------------------
| epoch 9 | time: 0.93s | valid_acc 0.877 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 10 | 50/ 152 batches | train_acc 0.911 train_loss 0.00565
| epoch 10 | 100/ 152 batches | train_acc 0.908 train_loss 0.00584
| epoch 10 | 150/ 152 batches | train_acc 0.909 train_loss 0.00604
---------------------------------------------------------------------
| epoch 10 | time: 0.91s | valid_acc 0.878 valid_loss 0.009 | lr 0.005000
---------------------------------------------------------------------
模型准确率为:0.8781七、测试指定数据
def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text), dtype=torch.float32)print(text.shape)output = model(text)return output.argmax(1).item()# ex_text_str = "随便播放一首专辑阁楼里的佛里的歌"
ex_text_str = "还有双鸭山到淮阴的汽车票吗13号的"model = model.to("cpu")print("该文本的类别是:%s" %label_name[predict(ex_text_str, text_pipeline)])
相关文章:
NLP 使用Word2vec实现文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/…...

【Redis学习笔记03】Java客户端
1. 初识Jedis Jedis的官网地址:https://github.com/redis/jedis 1.1 快速入门 使用步骤: 注意:如果是云服务器用户使用redis需要先配置防火墙! 引入maven依赖 <dependencies><!-- 引入Jedis依赖 --><dependency&g…...
神经网络系列---激活函数
文章目录 激活函数Sigmoid 激活函数Tanh激活函数ReLU激活函数Leaky ReLU激活函数Parametric ReLU激活函数 (自适应Leaky ReLU激活函数)ELU激活函数SeLU激活函数Softmax 激活函数Swish 激活函数Maxout激活函数Softplus激活函数 激活函数 一般来说…...
python中continue的对比理解
# 使用while循环,输入1-10之间的数字,除7之外。 以下为代码对比: # 使用while循环,输入1-10之间的数字,除7之外。 # 第一种方式 num 0 while num < 10:num num 1if num 7:print("")else:print(num)…...

Amazon Generative AI | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…...
[服务器-数据库]MongoDBv7.0.4不支持ipv6访问
文章目录 MongoDBv7.0.4不支持ipv6访问错误描述问题分析错误原因解决方式 MongoDBv7.0.4不支持ipv6访问 错误描述 报错如下描述 Cannot connect to MongoDB.No suitable servers found: serverSelectionTimeoutMS expired: [failed to resolve 2408]问题分析 首先确定其是…...

【b站咸虾米】chapter5_uniapp-API_新课uniapp零基础入门到项目打包(微信小程序/H5/vue/安卓apk)全掌握
课程地址:【新课uniapp零基础入门到项目打包(微信小程序/H5/vue/安卓apk)全掌握】 https://www.bilibili.com/video/BV1mT411K7nW/?p12&share_sourcecopy_web&vd_sourceb1cb921b73fe3808550eaf2224d1c155 目录 5 API 5.1 页面和路…...

自学Python第十八天-自动化测试框架(二):DrissionPage、appium
自学Python第十八天-自动化测试框架(二):DrissionPage、appium DrissionPage环境和安装配置准备工作简单的使用示例控制浏览器收发数据包模式切换 浏览器模式创建浏览器对象访问页面加载模式none 模式技巧 获取页面信息页面交互查找元素ele()…...
云尚办公-0.3.0
5. controller层 import pers.beiluo.yunshangoffice.model.system.SysRole; import pers.beiluo.yunshangoffice.service.SysRoleService;import java.util.List;//RestController:1.该类是控制器;2.方法返回值会被写进响应报文的报文体,而…...

汇编英文全称
mov move mvn Mov Negative ldr LoaD Register str Store Register lsl Logic Shift Left lsr Logic Shift Right asr Arithmetic Shift Right 算数右移 ror Rotate right 循环右移…...
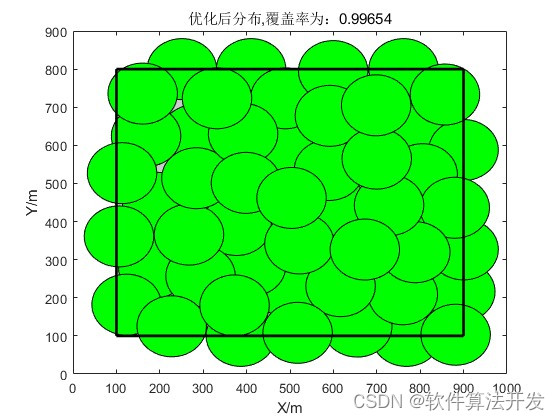
基于虚拟力优化的无线传感器网络覆盖率matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1 虚拟力优化算法 4.2 覆盖覆盖率计算 5.完整程序 1.程序功能描述 基于虚拟力优化的无线传感器网络覆盖率,仿真输出优化前后的网络覆盖率,覆盖率优化收敛迭代曲线…...

阿里云-系统盘-磁盘扩容
阿里云系统磁盘扩容 之前是测试环境磁盘用的默认的有 40G,后面升级到正式的 磁盘怕不够用打算升级到 100G, 系统镜像: Alibaba Cloud Linux 3.2104 LTS 64 位 磁盘 ESSD 40G 升级步骤: 扩容与创建快照 在阿里云后台首先去扩容…...

libmmd.dll修复
libmmd.dll 是与Intel Math Kernel Library (MKL) 相关的动态链接库文件,通常用于数学和科学计算。 最常出现的错误信息是: 程序无法启动,因为您的计算机缺少 libmmd.dll 。尝试重新安装程序来解决这个问题。 启动 libmmd.dll 发生错误。无法…...

大数据时代的明星助手:数据可视化引领新风潮
在大数据时代的浪潮中,数据可视化如一位巧夺天工的画师,为我们描绘出庞大而丰富的信息画卷,为我们提供了直观、清晰、高效的数据呈现方式。下面我就以可视化从业者的角度,来简单聊聊这个话题。 数据可视化首先在信息管理和理解方面…...

设计模式--享元模式和组合模式
享元模式 享元模式(Flyweight Pattern)又称为轻量模式,是对象池的一种实现。类似于线程池,线程池可以避免不停的创建和销毁多个对象,销毁性能。提供了减少对象数量从而改善应用所需的对象结构的方式。其宗旨是共享细粒…...
基于Java springmvc+mybatis酒店信息管理系统设计和实现
基于Java springmvcmybatis酒店信息管理系统设计和实现 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获…...

leetcode-找不同
389. 找不同 题解: 从题意我们可以知道,虽然 t 是由 s组成,但是 t中又随机添加了一个字符,也就是相当于 t 包含 s,我们使用字典,将 t 转换成字典对应关系t_map,然后遍历 s 中的字符,若存在&am…...
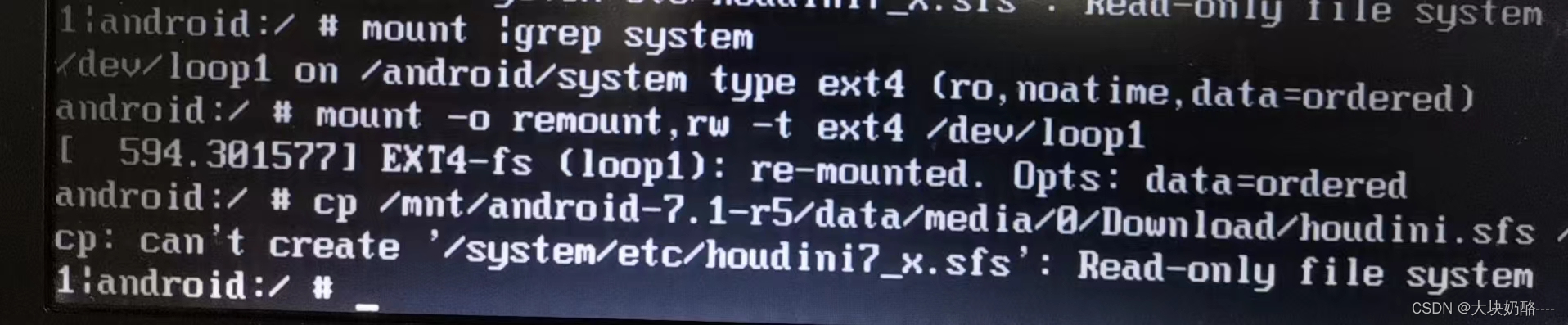
笔记本hp6930p安装Android-x86避坑日记
一、序言 农历癸卯年前大扫除,翻出老机hp6930p,闲来无事,便安装Android-x86玩玩,期间多次入坑,随手记之以避坑。 笔记本配置:T9600,4G内存,120G固态160G机械硬盘 二、Android-x86系统简介 官…...
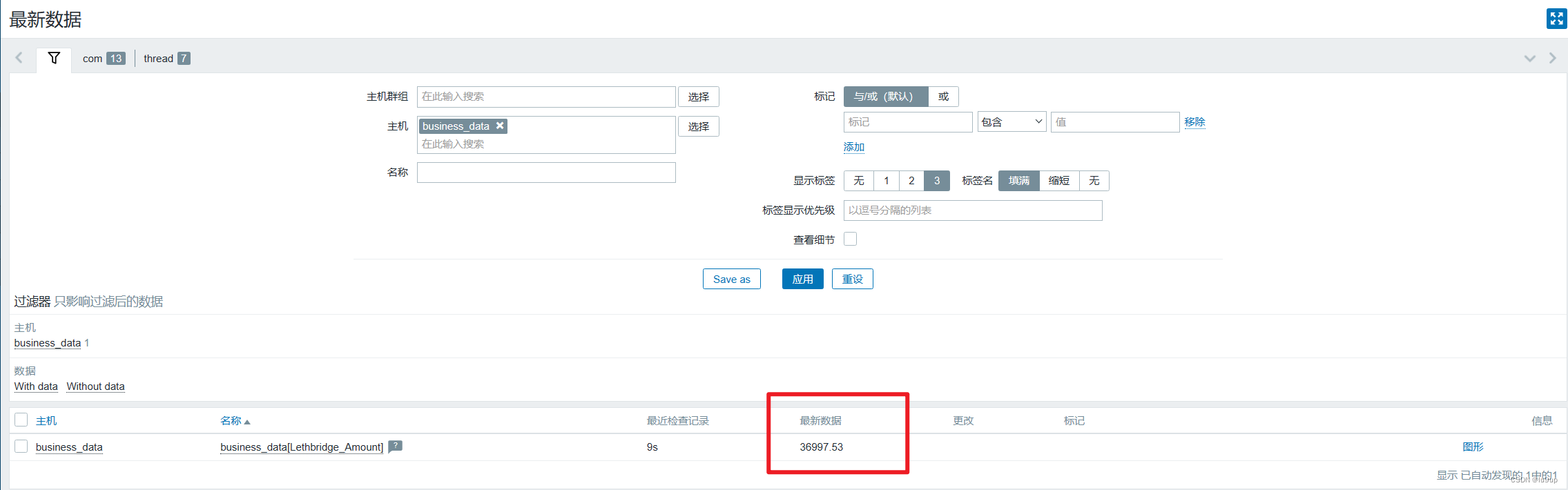
zabbix监控业务数据
前言 监控系统除了监控os和数据库性能相关的指标外,业务数据也是重点监控的对象。 一线驻场的运维同学应该深有体会,每天需要向甲方或者公司反馈现场的数据情况,正常情况下一天巡检两次,早上上班后和下午下班前各一次。监控项目…...
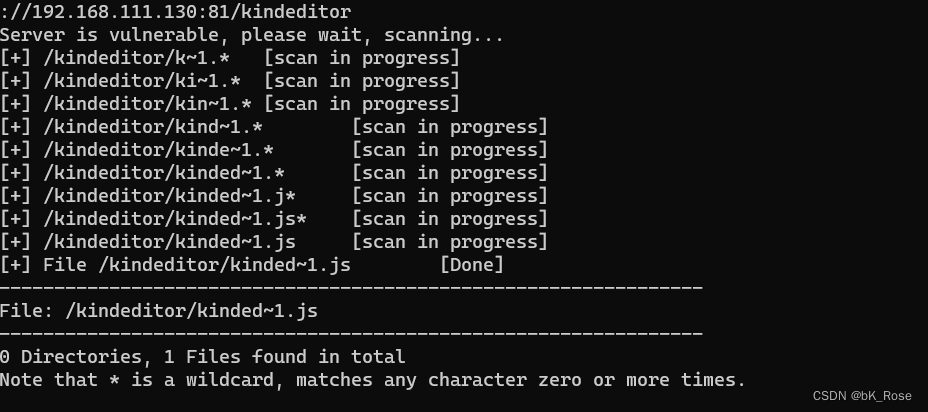
access数据库泄露与IIS短文件名利用
access数据库 Microsoft Office Access是微软把 数据库引擎 的图形用户界面和 软件开发工具 结合在一起的一个 数据库管理系统 它的数据库是没有库名的,都是表名。 (借用别的up的图)是不是感觉有点像excel access数据库的后缀是.mdb access数据库泄露漏洞 如果…...

如何使用Android Sunflower构建可预测UI:掌握单向数据流的终极指南
如何使用Android Sunflower构建可预测UI:掌握单向数据流的终极指南 【免费下载链接】sunflower A gardening app illustrating Android development best practices with migrating a View-based app to Jetpack Compose. 项目地址: https://gitcode.com/gh_mirro…...

终极指南:Windows上无需模拟器安装安卓应用的完整教程
终极指南:Windows上无需模拟器安装安卓应用的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但厌倦了…...
)
从零到一:51单片机蓝牙遥控车实战指南(附避坑要点)
1. 项目背景与准备 作为一个非硬件专业的爱好者,我第一次接触51单片机时完全是一头雾水。记得当时因为特殊原因在家闲着,突发奇想做个蓝牙遥控车玩玩。没想到这个简单的想法,让我踩遍了新手能遇到的所有坑。现在回头看,其实用51单…...

【Perplexity学术研究黄金法则】:20年科研老炮亲授5大避坑指南与效率翻倍实战技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity学术研究黄金法则的底层逻辑 Perplexity(困惑度)并非单纯的语言模型评估指标,而是信息论中熵概念在序列建模中的直接映射——它量化了模型对真实语料分布的…...

嵌入式开发中的编程规范实践与行业标准解析
1. 编程规范的本质与价值在嵌入式汽车电子领域干了十五年,我见过太多因为代码不规范导致的惨痛教训。有一次,某车企的ECU控制模块在零下30度环境突然死机,排查三周后发现是未初始化的指针在低温环境下产生了非预期行为——这种问题本可以通过…...

终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址
终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

泛微OA ecology 9实战:手把手教你写一个能取表单数据的Java自定义接口
泛微OA Ecology 9深度开发:构建高效表单数据交互的Java接口实践 在当今企业数字化转型浪潮中,办公自动化系统(OA)作为核心支撑平台,其灵活性和扩展性直接影响着企业运营效率。泛微OA Ecology 9作为国内领先的协同办公平台,提供了丰…...

告别AT指令!用nRF52832的BLE NUS服务,5分钟搞定手机与开发板的双向通信
用nRF52832的BLE NUS服务实现高效蓝牙串口通信 在嵌入式开发中,设备与移动端的双向通信一直是个痛点。传统AT指令虽然简单,但效率低下、扩展性差,每次通信都需要复杂的握手流程。而基于nRF52832的BLE NUS(Nordic UART Service&…...

Llama-3中文优化实战:从模型选型到本地部署全解析
1. 项目概述:从Llama-3到中文Llama-3的进化之路 如果你在过去一年里关注过开源大模型,那么“Llama”这个名字对你来说一定不陌生。从Meta发布Llama-2开始,这个系列就成为了开源社区构建垂直领域模型的基石。今年4月,Meta又扔下了一…...

滑块验证码的轨迹反欺诈:从原理到QCaptcha企业级防护实战
摘要:本文深度剖析滑块验证码的反欺诈技术,从第一代纯位移校验到第三代复合验证的演进过程。重点讲解QCaptcha平台如何通过前端SDK内置轨迹采集后端票据校验实现企业级防护,并提供不同场景的配置建议和实测数据对比。一、黑产自动化攻击现状在…...