【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)

本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回归预测,应用LogisticRegression实现逻辑回归预测,应用DecisionTreeClassifier实现决策树分类,应用RandomForestClassifie实现随机森林算法,应用Kmeans实现聚类任务。
全套笔记和代码自取移步gitee仓库: gitee仓库获取完整文档和代码
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
共 7 章,44 子模块
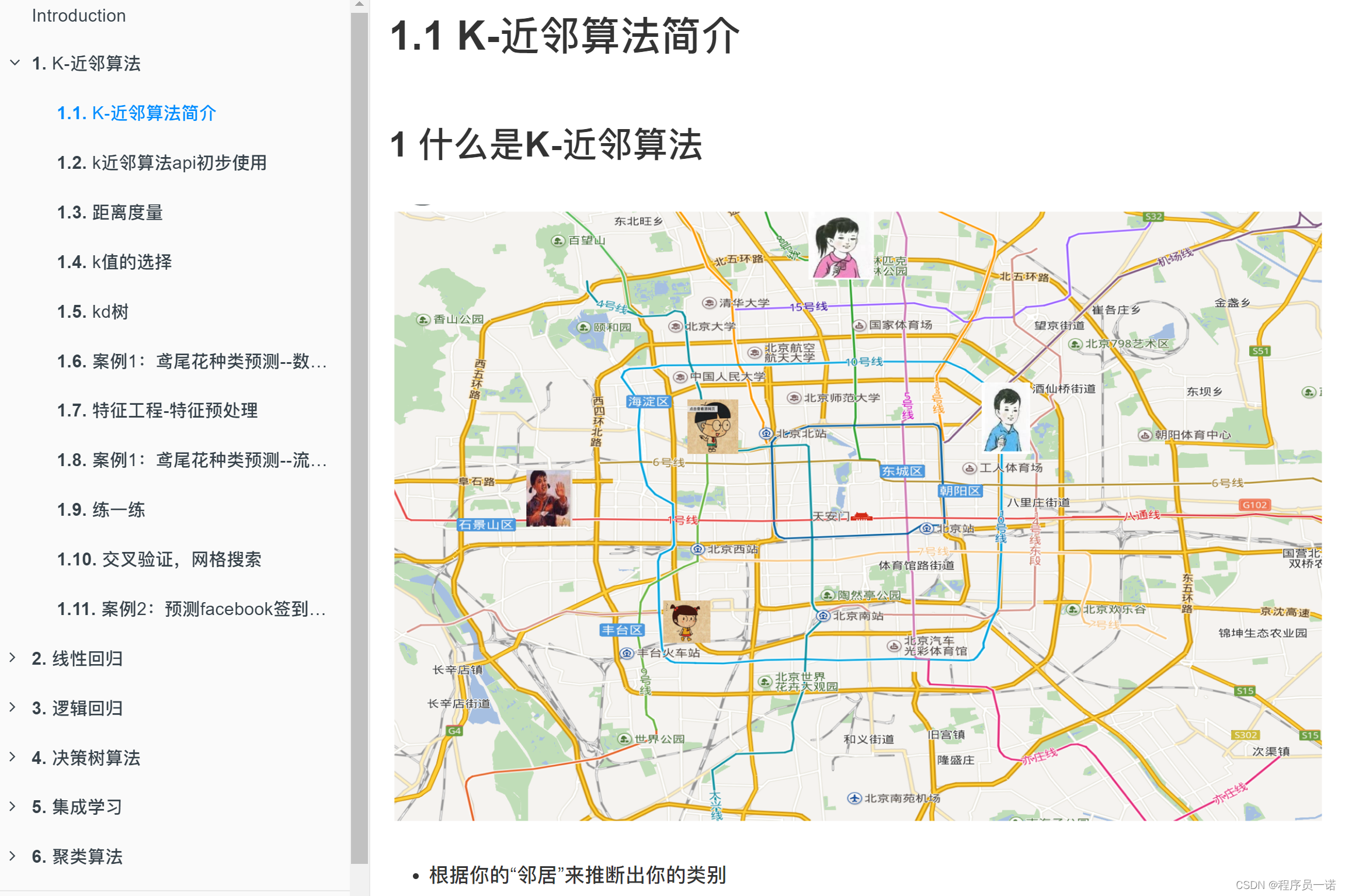
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.8 案例:鸢尾花种类预测—流程实现
1 再识K-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
-
n_neighbors:
- int,可选(默认= 5),k_neighbors查询默认使用的邻居数
-
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
-
快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,
- brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
- kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
-
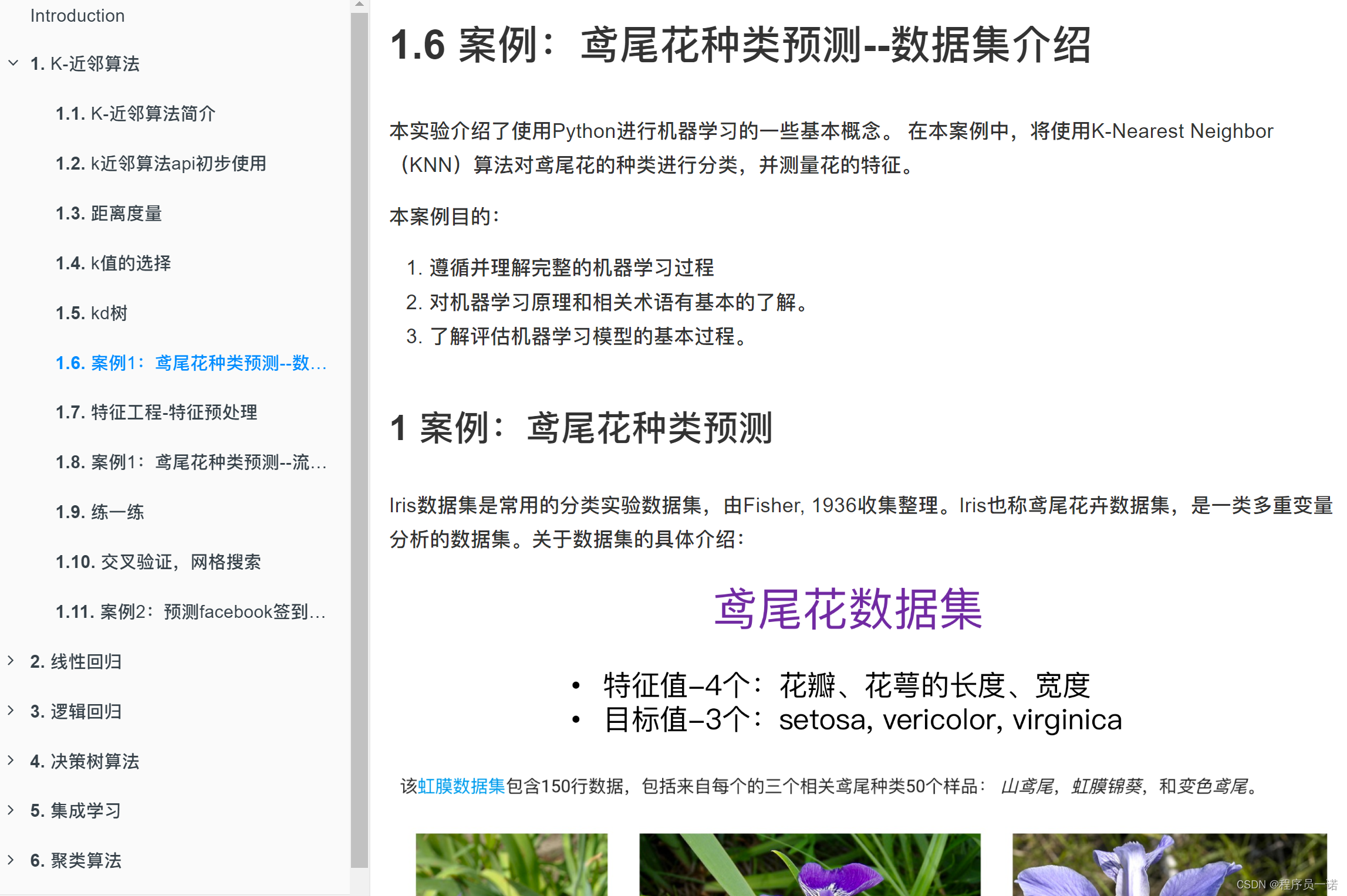
2 案例:鸢尾花种类预测
2.1 数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

2.2 步骤分析
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
2.3 代码过程
- 导入模块
python from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier
- 先从sklearn当中获取数据集,然后进行数据集的分割
```python
1.获取数据集
iris = load_iris()
2.数据基本处理
x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) ```
-
进行数据标准化
-
特征值的标准化
```python
3、特征工程:标准化
transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) ```
- 模型进行训练预测
```python
4、机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=9) estimator.fit(x_train, y_train)
5、模型评估
方法1:比对真实值和预测值
y_predict = estimator.predict(x_test) print("预测结果为:\n", y_predict) print("比对真实值和预测值:\n", y_predict == y_test)
方法2:直接计算准确率
score = estimator.score(x_test, y_test) print("准确率为:\n", score) ```
1.9 练一练
同学之间讨论刚才完成的机器学习代码,并且确保在自己的电脑是哪个运行成功
总结
-
在本案例中,具体完成内容有:
-
使用可视化加载和探索数据,以确定特征是否能将不同类别分开。
- 通过标准化数字特征并随机抽样到训练集和测试集来准备数据。
-
通过统计学,精确度度量进行构建和评估机器学习模型。
-
k近邻算法总结
-
优点:
- 简单有效
- 重新训练的代价低
-
适合类域交叉样本
- KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
-
适合大样本自动分类
- 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
-
缺点:
-
惰性学习
- KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
-
类别评分不是规格化
- 不像一些通过概率评分的分类
-
输出可解释性不强
- 例如决策树的输出可解释性就较强
-
对不均衡的样本不擅长
- 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
-
计算量较大
- 目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
-
1.10 交叉验证,网格搜索
1 什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
1.1 分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

1.2 为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
2 什么是网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3 交叉验证,网格搜索(模型选择与调优)API:
-
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
-
对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
-
结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
4 鸢尾花案例增加K值调优
- 使用GridSearchCV构建估计器
```python
1、获取数据集
iris = load_iris()
2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
3、特征工程:标准化
实例化一个转换器类
transfer = StandardScaler()
调用fit_transform
x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test)
4、KNN预估器流程
4.1 实例化预估器类
estimator = KNeighborsClassifier()
4.2 模型选择与调优——网格搜索和交叉验证
准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
4.3 fit数据进行训练
estimator.fit(x_train, y_train)
5、评估模型效果
方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test) print("比对预测结果和真实值:\n", y_predict == y_test)
方法b:直接计算准确率
score = estimator.score(x_test, y_test) print("直接计算准确率:\n", score) ```
- 然后进行评估查看最终选择的结果和交叉验证的结果
python print("在交叉验证中验证的最好结果:\n", estimator.best_score_) print("最好的参数模型:\n", estimator.best_estimator_) print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
- 最终结果
python 比对预测结果和真实值: [ True True True True True True True False True True True True True True True True True True False True True True True True True True True True True True True True True True True True True True] 直接计算准确率: 0.947368421053 在交叉验证中验证的最好结果: 0.973214285714 最好的参数模型: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') 每次交叉验证后的准确率结果: {'mean_fit_time': array([ 0.00114751, 0.00027037, 0.00024462]), 'std_fit_time': array([ 1.13901511e-03, 1.25300249e-05, 1.11011951e-05]), 'mean_score_time': array([ 0.00085751, 0.00048693, 0.00045625]), 'std_score_time': array([ 3.52785082e-04, 2.87650037e-05, 5.29673344e-06]), 'param_n_neighbors': masked_array(data = [1 3 5], mask = [False False False], fill_value = ?) , 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([ 0.97368421, 0.97368421, 0.97368421]), 'split1_test_score': array([ 0.97297297, 0.97297297, 0.97297297]), 'split2_test_score': array([ 0.94594595, 0.89189189, 0.97297297]), 'mean_test_score': array([ 0.96428571, 0.94642857, 0.97321429]), 'std_test_score': array([ 0.01288472, 0.03830641, 0.00033675]), 'rank_test_score': array([2, 3, 1], dtype=int32), 'split0_train_score': array([ 1. , 0.95945946, 0.97297297]), 'split1_train_score': array([ 1. , 0.96 , 0.97333333]), 'split2_train_score': array([ 1. , 0.96, 0.96]), 'mean_train_score': array([ 1. , 0.95981982, 0.96876877]), 'std_train_score': array([ 0. , 0.00025481, 0.0062022 ])}
1.11 案例2:预测facebook签到位置
1 数据集介绍

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
python train.csv,test.csv row_id:登记事件的ID xy:坐标 准确性:定位准确性 时间:时间戳 place_id:业务的ID,这是您预测的目标
官网:https://www.kaggle.com/navoshta/grid-knn/data
2 步骤分析
-
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
-
1 缩小数据集范围 DataFrame.query()
-
2 选取有用的时间特征
-
3 将签到位置少于n个用户的删除
-
分割数据集
-
标准化处理
-
k-近邻预测
3 代码过程
- 1.获取数据集
```python
1、获取数据集
facebook = pd.read_csv("./data/FBlocation/train.csv") ```
- 2.基本数据处理
```python
2.基本数据处理
2.1 缩小数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s") time = pd.DatetimeIndex(time) facebook_data["day"] = time.day facebook_data["hour"] = time.hour facebook_data["weekday"] = time.weekday
2.3 去掉签到较少的地方
place_count = facebook_data.groupby("place_id").count() place_count = place_count[place_count["row_id"]>3] facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]] y = facebook_data["place_id"]
2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22) ```
- 特征工程--特征预处理(标准化)
```python
3.特征工程--特征预处理(标准化)
3.1 实例化一个转换器
transfer = StandardScaler()
3.2 调用fit_transform
x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) ```
- 机器学习--knn+cv
```python
4.机器学习--knn+cv
4.1 实例化一个估计器
estimator = KNeighborsClassifier()
4.2 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]} estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
4.3 模型训练
estimator.fit(x_train, y_train) ```
- 模型评估
```python
5.模型评估
5.1 基本评估方式
score = estimator.score(x_test, y_test) print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test) print("最后的预测值为:\n", y_predict) print("预测值和真实值的对比情况:\n", y_predict == y_test)
5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_) print("最好的参数模型:\n", estimator.best_estimator_) print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_) ```
未完待续, 同学们请等待下一期
全套笔记和代码自取移步gitee仓库: gitee仓库获取完整文档和代码
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
相关文章:
【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)
本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用࿰…...
Windows 自带的 Linux 子系统(WSL)安装与使用
WSL官网安装教程: https://learn.microsoft.com/zh-cn/windows/wsl/install Windows 自带的Linux子系统,比用VM什么的香太多了。可以自己看官方教程,也可以以下步骤完成。 如果中间遇到我没遇到的问题百度,可以在评论区评论&#…...

C语言--贪吃蛇
目录 1. 实现目标2. 需掌握的技术3. Win32 API介绍控制台程序控制台屏幕上的坐标COORDGetStdHandleGetConsoleCursorinfoCONSOLE_CURSOR_INFOSetConsoleCursorInfoSetConsoleCursorPositionGetAsyncKeyState 4. 贪吃蛇游戏设计与分析地图<locale.h>本地化类项setlocale函…...
原型设计工具Axure RP
Axure RP是一款专业的快速原型设计工具。Axure(发音:Ack-sure),代表美国Axure公司;RP则是Rapid Prototyping(快速原型)的缩写。 下载链接:https://www.axure.com/ 下载 可以免费试用…...

HeadFirst读书笔记
一、设计模式入门 1、使用模式最好的方式“把模式装进脑子里,然后在你的设计和已有的应用中,寻找何处可以使用它们”。以往是代码复用,现在是经验复用。 2、软件开发的一个不变的真理就是变化。 二、设计原则 1、找出应用中可能需要变化之…...

【C++】---内存管理new和delete详解
一、C/C内存分布 C/C内存被分为6个区域: (1) 内核空间:存放内核代码和环境变量。 (2)栈区:向下增长(存放非静态局部变量,函数参数,返回值等等) …...

go-zero微服务入门教程
go-zero微服务入门教程 本教程主要模拟实现用户注册和用户信息查询两个接口。 准备工作 安装基础环境 安装etcd, mysql,redis,建议采用docker安装。 MySQL安装好之后,新建数据库dsms_admin,并新建表sys_user&#…...

蓝桥杯刷题--python-12
3768. 字符串删减 - AcWing题库 nint(input()) sinput() res0 i0 while(i<n): if s[i]x: ji1 while(j<n and s[j]x): j1 resmax(j-i-2,0) ij else: i1 print(res) 3777. 砖块 - AcWing题库 # https://www.a…...

LeetCode LCR 085.括号生成
正整数 n 代表生成括号的对数,请设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 示例 2: 输入&#x…...
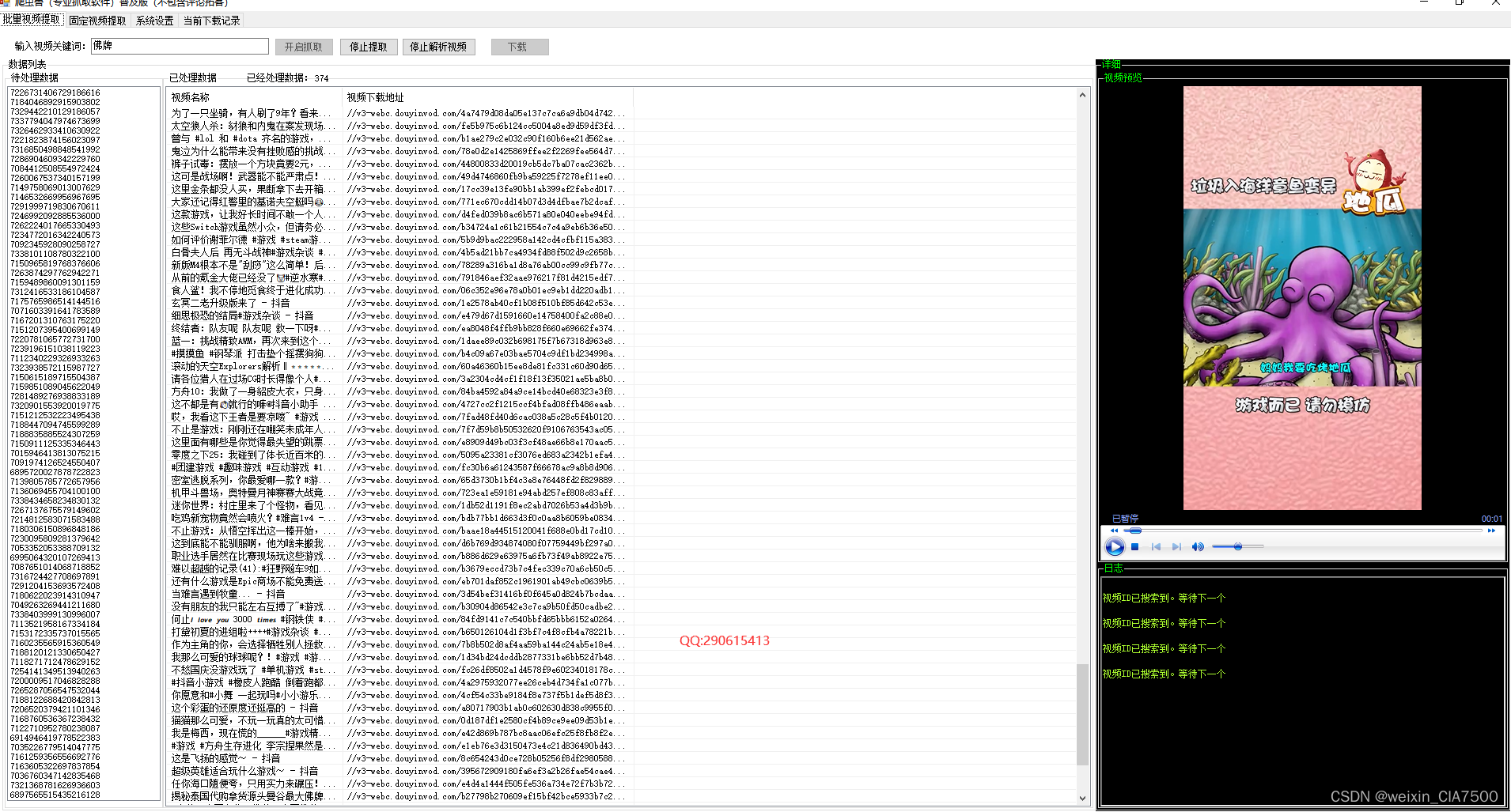
抖音视频评论数据提取软件|抖音数据抓取工具
一、开发背景: 在业务需求中,我们经常需要下载抖音视频。然而,在网上找到的视频通常只能通过逐个复制链接的方式进行抓取和下载,这种操作非常耗时。我们希望能够通过关键词自动批量抓取并选择性地下载抖音视频。因此,为…...

【web】云导航项目部署及环境搭建(复杂)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、项目介绍1.1项目环境架构LNMP1.2项目代码说明 二、项目环境搭建2.1 Nginx安装2.2 php安装2.3 nginx配置和php配置2.3.1 修改nginx文件2.3.2 修改vim /etc/p…...

软件测试人员必会的linux命令
文件和目录操作: ● ls:列出目录中的文件和子目录。 ● cd:改变当前工作目录。 ● mkdir:创建新目录。 ● rm:删除文件或目录。 ● cp:复制文件或目录。 ● mv:移动或重命名文件或目录。 文本查看和编辑: ● cat:查看文件内容。 ● more或less:分页查看文件内…...

Mac使用K6工具压测WebSocket
commend空格 打开终端,安装k6 brew install k6验证是否安装成功 k6 version设置日志级别为debug export K6_LOG_LEVELdebug执行脚本(进入脚本所在文件夹下) k6 run --vus 100 --duration 10m --out csvresult.csv script.js 脚本解释&…...
小程序--vscode配置
要在vscode里开发微信小程序,需要安装以下两个插件: 安装后,即可使用vscode开发微信小程序。 注:若要实现鼠标悬浮提示,则需新建jsconfig.json文件,并进行配置,即可实现。 jsconfig.json内容如…...

linux僵尸进程
僵尸进程(Zombie Process)是指在一个进程终止时,其父进程尚未调用wait()或waitpid()函数来获取该进程的终止状态信息,导致进程的资源(如进程表中的记录)仍然保留在系统中的一种状态。 当一个进程结束时&am…...

【web | CTF】攻防世界 Web_php_unserialize
天命:这条反序列化题目也是比较特别,里面的漏洞知识点,在现在的php都被修复了 天命:而且这次反序列化的字符串数量跟其他题目不一样 <?php class Demo { // 初始化给变量内容,也就是当前文件,高亮显示…...
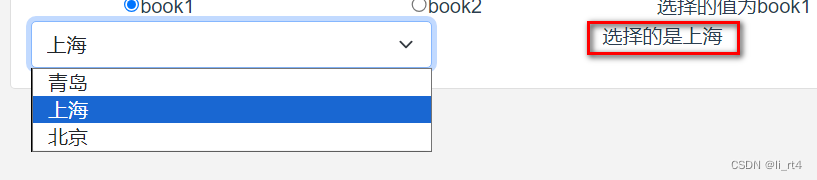
Vue3中的select 的option是多余的?
背景: 通过Vue3中填充一个下拉框,在打开页面时要指定默认选中,并在选项改变时把下拉框的选中值显示出来 问题: 填充通常的作法是设置 <option v-for"option in cities" :value"option.value" >&a…...

考研408深度分析+全年规划
408确实很难,他的难分两方面 一方面是408本身的复习难度,我们都知道,408的考察科目有四科,分别是数据结构,计算机组成原理,操作系统和计算机网络。大家回想一下自己在大学本科时候学习这些专业课的难度&am…...

【算法笔记】ch01_01_0771 宝石与石头
笔记介绍: 本项目是datawhale发布的LeetCode 算法笔记(Leetcode-Notes)课程完成笔记,根据推荐题目循序渐进练习算法题目。主要用python进行书写相关代码,会介绍解题思路及跑通解法。 0771. 宝石与石头 题目大意 描…...

jQuery瀑布流画廊,瀑布流动态加载
jQuery瀑布流画廊,瀑布流动态加载 效果展示 手机布局 jQuery瀑布流动态加载 HTML代码片段 <!-- mediabanner --><div class"mediabanner"><img src"img/mediabanner.jpg" class"bg"/><div class"text&qu…...

惠普OMEN游戏本性能优化终极指南:如何用开源工具彻底释放硬件潜力
惠普OMEN游戏本性能优化终极指南:如何用开源工具彻底释放硬件潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软…...

边缘TTS实战:本地部署高质量语音合成与性能优化指南
1. 项目概述:当TTS遇见边缘计算最近在折腾一个需要实时语音合成的项目,发现了一个挺有意思的仓库:travisvn/openai-edge-tts。这名字一看就很有料,把“OpenAI”和“Edge-TTS”这两个词组合在一起,背后指向的是一个非常…...

三星48层3D V-NAND深度拆解:从电荷陷阱架构到存储密度革命
1. 初探三星48层3D V-NAND:一次深度拆解与工艺解析作为一名长期关注半导体存储技术的从业者,每次拿到业界巨头的新品进行物理层面的拆解分析,都像是一次充满惊喜的“寻宝”之旅。2016年初,当三星将其早在2015年8月就已预告的256Gb…...

Kali+MSF 安全攻防实操|Windows 渗透完整流程教程
入侵电脑,并没有我们想象的那么难,今天我们的文章主要是给一些基础比较薄弱的小伙伴们准备的,如果你从来没有利用msf进入过对方计算机,就赶紧找个风和日丽的下午,跟着博主一起来试试吧~ 01 什么是msf 演示环境 02 …...

深度强化学习在航天控制中的仿真到实物迁移挑战
1. 深度强化学习在航天控制领域的应用背景卫星近距离操作是航天任务中的一项关键技术挑战,涉及轨道交会、在轨服务、空间目标检测等多种场景。传统基于模型预测控制(MPC)的方法需要精确的环境动力学模型,而实际太空环境中存在诸多…...

Kubernetes配置管理神器Monokle:可视化IDE提升YAML开发效率
1. 项目概述:一个被低估的Kubernetes配置管理神器如果你和我一样,每天都在和成堆的YAML文件、复杂的Kubernetes资源关系以及让人头疼的配置漂移问题打交道,那你一定理解那种在终端、IDE和Dashboard之间反复横跳的疲惫感。几年前,当…...

WordPress集成Claude AI:构建智能内容创作技术栈的实践指南
1. 项目概述与核心价值最近在折腾个人博客和内容创作工具链,发现了一个挺有意思的GitHub项目:mvtandas/wordpress-claude-stack。这名字一看就很有料,直接把WordPress和Claude这两个看似不搭界的玩意儿给“堆”到了一起。作为一个常年混迹在内…...
:团雾识别+车流量统计全流程落地)
【YOLO26实战全攻略】20——智慧交通(二):团雾识别+车流量统计全流程落地
摘要:团雾作为高速公路"流动杀手",常导致能见度骤降、事故频发,而传统监测手段响应滞后、统计粗放;车流量数据则是交通管控的核心依据,但精细化分类统计一直是行业痛点。本文基于YOLO26的边缘友好特性,结合FAENet特征增强网络与ByteTrack跟踪算法,打造了一套&…...

权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区
更多请点击: https://intelliparadigm.com 第一章:权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区 在企业级部署 Gemini Workspace 时,大量团队遭遇“功能可登录但协作不可用”的隐性故障。根本原因并非 …...

构建个人知识管理系统:基于技能树与间隔重复的学习框架
1. 项目概述:构建个人专属的“人类技能树” 最近在折腾一个挺有意思的项目,我把它叫做“人类技能树”。这名字听起来有点科幻,但内核其实很朴素:我们每个人从小到大,从学校到职场,都在不断地学习各种技能&a…...