Doris——荔枝微课统一实时数仓建设实践
目录
一、业务介绍
二、早期架构及痛点
2.1 早期架构
2.2 架构痛点
三、技术选型
四、新的架构及方案
五、搭建经验
5.1 数据建模
5.2 数据开发
5.3 库表设计
5.4 数据管理
5.4.1 监控告警
5.4.2 数据备份与恢复
六、收益总结
七、未来规划
原文大佬这篇Doris腾讯云实时数仓的实战文章整体写的很深入,这里直接摘抄下来用作学习和知识沉淀。
前言
腾讯云数据仓库Doris助力荔枝微课构建了规范的、计算统一的实时数仓平台。目前腾讯云数据仓库Doris已经支撑了荔枝微课内部90%以上的业务场景,整体可达到毫秒级的查询响应,数据时效性完成T+1到分钟级的提升,开发效率更是实现了50%的增长,满足了各业务场景需求,实现将本提效。
一、业务介绍
荔枝微课是一个免费使用的在线教育平台,拥有海量直播视频、录播视频、音频等数据内容。大数据平台旨在集成各种数据源的数据,整合形成数据资产,为业务提供用户全链路生命周期、实时指标分析、标签圈选等分析服务。
二、早期架构及痛点

2.1 早期架构
早期架构选用的是Hadoop生态圈组件,以spark批计算引擎为核心构建了离线数仓架构,基于flink计算引擎进行实时处理。从源端采集到的业务数据和日志数据将分为实时和离线两条链路:在实时部分,业务库数据通过Binlog的方式接入,日志数据使用Flume-Kafka-Sink进行实时采集,利用flink将数据计算写入到kafka和mysql中。在实时数仓内部,遵守数据分层的理论以实现最大程度的数据复用。
在离线部分,利用sqoop和datax对全量和增量业务库中的数据进行定时同步,日志数据通过flume和日志服务进行采集。当不同数据源进入到离线数仓后,首先使用hive on spark进行定时调度处理,接着根据维度建模将数仓分为ods,dwd,dws,ads层,每层数据存储在HDFS和对象存储COS上,最终利用Presto 进行数据即席查询,并通过 Metabase 提供交互式分析服务。同时为了保障数据的一致性,我们会通过离线数据对实时数据进行定期覆盖。
2.2 架构痛点
基于Hadoop的早期架构可以满足我们的初步需求,而面对较为复杂的分析诉求则显得心有余而力不足。再加上近年来,荔枝微课用户体量不断上升,数据量呈指数级上升,为了更好地为业务赋能,提高用户使用体验,业务侧对数据的实时性、可用性、响应速度也提出了更高的要求。在这样的背景下,早期架构暴露的问题也越发明显:
- 组件繁多,维护复杂,运维难度非常高
- 数据处理链路过长,导致查询延迟变高
- 当有新的数据需求时,牵一发而动全身,所需开发周期比较长
- 数据时效性低,只可满足T+1的数据需求,从而也导致数据分析效率低下
三、技术选型
通过对数据规模及早期架构存在的问题进行评估,我们决定引入一款实时数仓来搭建新的数据平台,同时希望新的olap引擎可以具备以下能力:
- 支持Join操作,可满足不同业务用户灵活多变的分析需求
- 支持高并发查询,可满足日常业务的报表分析需求
- 性能强悍,可以在海量数据场景下实现快速响应
- 运维简单,缩减运维人力的投入和成本的支持,实现降本提效
- 统一数仓构建,简化繁琐的大数据技术栈
- 社区活跃,在使用过程中遇到问题,可迅速与社区取得联系
基于以上要求,我们快速定位了Doris 和 ClickHouse 这两款开源 OLAP 引擎 ,这两款引擎都是当下使用较为广泛、口碑不错的产品。在调研中发现,ClickHouse在宽表查询时有着非常出色的性能表现,写入速度快,对于大量的数据更新非常使用;但对于join场景,通常需要额外的调优才能有较好的表现。在大多数业务场景中都需要基于明细数据进行大数据量的join,对比而言,Doris的多表Join能力强悍,高并发能力优异,完全可以满足我们日常的业务报表分析需求。除此之外,Doris可以同时支持实时数据服务、交互数据分析和离线数据处理多种场景,并且支持 Multi Catalog(Multi Catalog:多源数据目录功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力),可以实现统一的数据门户,这几个特点都是我们核心考虑的几个能力。
同时,我们也了解到腾讯数据仓库这款产品,作为一款支持在线业务和多维分析的实时数仓产品,腾讯云数据仓库 Doris 100% 兼容开源 Apache Doris,整体架构简洁易用,极简运维,弹性伸缩,功能完备,一站式的分析解决方案,满足各种业务数据分析场景,能够助力企业快速构建云上数据分析平台。
在多源数据加工方面, Flink有着优秀的表现满足我们的实时数据加工诉求,我们选择了腾讯云大数据 EMR-Flink。腾讯云EMR是一款基于云原生技术和泛 Hadoop生态开源技术的安全、低成本、高可靠的开源大数据平台,提供了非常丰富的组件选项。而作为云原生大数据产品,腾讯云数据仓库Doris与EMR这两款产品之间能够无缝集成和联动。
基于以上优势,最终选择与腾讯云大数据合作,采用腾讯云数据仓库 Doris+EMR来搭建新的实时数仓架构体系。
四、新的架构及方案
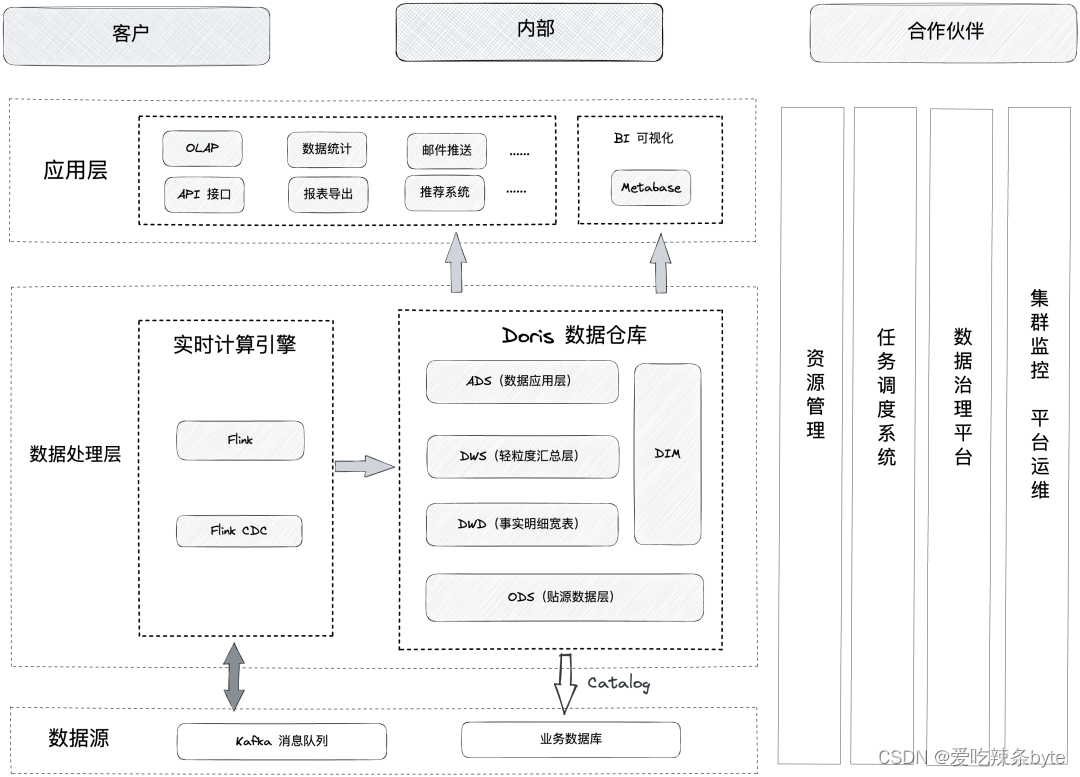
在新的架构中采取腾讯云数据仓库 Doris 和腾讯云EMR-Flink 来构建实时数仓,多种数据源的数据经过Flink CDC或Flink加工处理后,入库到kafka和Doris中,最终由Doris提供统一的查询服务。在数据同步上, 一般通过Flink CDC 将 RDS 数据实时同步到 Doris,通过 Flink 将 Kafka 的日志数据加工处理到 Doris,重要的指标数据一般由flink计算,再经过kafka分层处理写入到Doris中。
- 在存储媒介上,主要使用腾讯云数据仓库 Doris 进行流批数据的统一存储。
- 架构收益:成功构建了规范的、计算统一的实时数仓平台,腾讯云数据仓库 Doris的Multi Catalog功能助力我们统一了不同数据源出口,实现联邦后查询。同时利用外部表插入的方式进行快速同步和修复,真正实现了统一数据门户。
- 数据实时性有效提升,通过Flink+Doris架构,实时性从早期T+1缩短为分钟级别延迟。
- 极大地减少了运维成本,Doris架构简单,只有FE和BE两个进程,不依赖其他系统;另外集群扩缩容非常简单,可实现用户无感知扩容。
- 开发周期从周级别降至天级别,开发周期大幅缩短,开发效率相比之前提升了50%
五、搭建经验
5.1 数据建模
结合腾讯云数据仓库 Doris 的特性,我们对数据仓库进行了建模,建模方式与传统数仓类似:
(1)ods层:ods层日志数据选择duplicate模型的分区表,分区表方便进行设计修复,duplicate模型还可以减少非必要的compaction。ods层业务数据采用unique数据模型(业务库mysql单表数据通过flink cdc实时同步到doris,kafka日志数据经过flink清洗,通过doris的rountine load写入doris做为ods层),distribute by hash key根据具体的业务场景进行选择:
如果考虑机器资源,可选择均匀分布的key,让tablet数据能够均匀分布,使得查询时各BE资源能够充分利用,避免出现木桶效应。如果考虑大表Join性能,可以依据Colocate join特性进行创建,让Join查询更高效。
Doris1.2版本中unique模型开始支持写时合并Merge on Write,进一步提升了Unique模型的查询性能。
(2)DWD层:对于通过Flink将数据进行Join打宽处理分别写入Doris和kafka中的场景,选择使用unique数据模型。
对于高频查询的宽表,选择Doris的aggregate模型,使用replace_if_not_null字段类型,将多个事实单表进行插入,通过Doris的compaction机制可以有效减少flink状态TTL导致的历史数据没有及时更新的问题。
(3)DWS层和AD层:主要采用unique数据模型,dws层按天,月进行分区。除此之外,我们还会利用insert into语句进行5分钟的任务调度和 T+1的任务修复来进行数仓分层,便于需求的快速开发和实时数据修复(离线数据对实时数据进行覆盖,确保两条链路的数据一致性)。对于duplicate模型的数据表,我们会创建rollup的物化视图,通过命中物化视图查询,加快上层表的查询效率。
5.2 数据开发
在荔枝微课业务中,运营人员经常会有调整直播课程信息、修改专栏名称等操作,针对维度快速变化但宽表中维度列没有及时更新的场景,为了能更好地满足业务需求,我们利用 Doris Aggregate 模型 的 REPLACE_IF_NOT_NULL字段特性(聚合函数设置为REPLACE_IF_NOT_NULL即可实现部分列更新的支持)。当课程维度表数据发生变化时,需要查询上层维度(专栏和直播间),对维度表补全后再插入到 Doris 中;当上层维度(专栏和直播间)发生变化时,需要下钻到课程表维度表,补全对应的课程 ID 后再将数据插入到 Doris 中。通过这两种方式可以确保维度表中所有字段的实时更新。
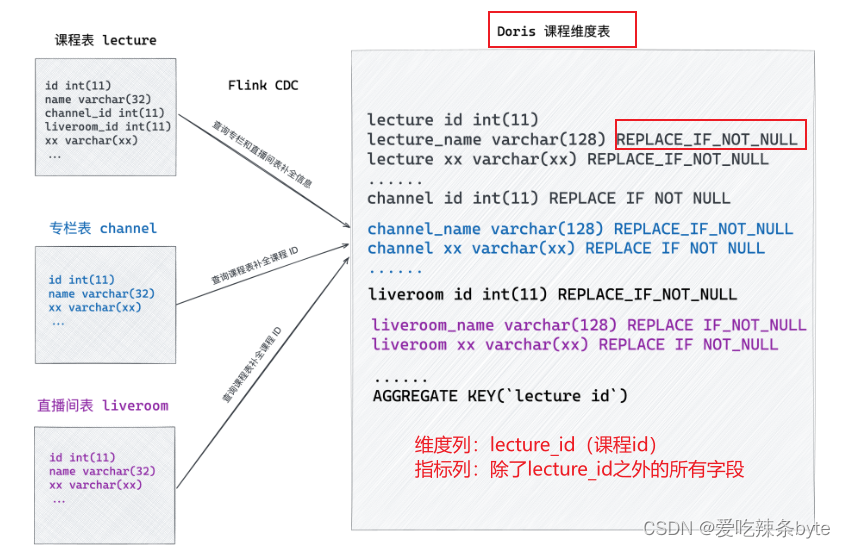
5.3 库表设计
在初期设计阶段,为了更好地利用腾讯云数据仓库 Doris 提供的Colocation Join功能,我们特别设计了事实表的主键,如下图示例:

上图中的业务库中课程表 A 和课程表 B 的关系是A.id=B.lecture_id,为了使用Colocation Join优化,我们会将B表的分桶列设置为lecture_id,即distributed by hash(lecture_id)。在数据量很大的情况下可能会导致数据倾斜,导致各个BE节点的Tablet大小不一致,在高并发查询时可能出现BE机器资源使用不均衡,从而影响查询稳定性,造成资源浪费。
基于以上问题,我们尝试进行调整,并对查询效率和机器资源的占用这两方面进行了评估权衡,最终决定在尽量不影响查询效率的前提下,尽可能提高资源利用率。
在资源利用上,我们在建表时利用colocate_with属性,在不同数量和类型的 Distributed Key 创建不同的 Group,实现机器资源能得以充分利用。
在查询效率上,根据业务场景和需求对前缀索引的字段顺序进行针对性调整,对于必选或高频的查询条件,将字段放在 UNIQUE KEY 前面,根据维度按照从高到低的顺序进行设计。其次我们利用物化视图对字段顺序进行调整,尽可能使用前缀索引进行查询,以加快数据查询 。除此之外,我们进行月、天分区,对明细数据进行分桶,通过合理库表的设计减少 FE元数据的压力。
5.4 数据管理
在数据管理方面,我们进行了以下操作:
5.4.1 监控告警
对于重要的单表,一般通过腾讯云数据仓库Doris来创建外部表,通过数据质量监控来对比业务库数据和Doris数据,进行数据质量稽查告警。
5.4.2 数据备份与恢复
我们会将Doris数据定期导入到HDFS进行备份,避免数据误删除或丢弃的情况发生。例如当因为某些原因导致Flink同步任务失败,无法从Checkpoint进行启动时,我们可以读取最新的数据进行同步,历史缺失数据通过外部表进行修复,使得同步任务快速恢复。
六、收益总结
在新架构中,我们从Hadoop生态完全的迁移到Flink +Doris上,在上层构建不同的数据应用,比如自主报表,自助数据提取,数据大屏,业务预警等,Doris通过应用层接口服务项目统一对外提供API查询,新架构的应用也为我们带来了许多收益,支撑了荔枝微课内部90%以上的业务场景,整体可达到毫秒级的查询响应。
(1)支持千万级甚至是亿级大表关联查询,可实现秒级甚至毫秒级响应。
(2)Doris统一了数据源出口,查询效率显著提升,支持多种数据的联邦查询,降低了多数据查询的复杂度以及数据链路处理成本。
(3)Doris架构简单,极大简化了大数据的架构体系,并高度兼容Mysql的语法,极大降低了开发人员接入成本。
七、未来规划
未来期待腾讯云数据仓库 Doris在实时数据处理场景的能力上有更进一步的提升,包括 Unique 模型上的部分列更新、单表物化视图上的计算增强、自动增量刷新的多表物化视图等,通过不断地迭代更新,使实时数仓的构建更加简单易用。
参考文章:
亿级大表毫秒关联,荔枝微课基于腾讯云数据仓库Doris的统一实时数仓建设实践
相关文章:
Doris——荔枝微课统一实时数仓建设实践
目录 一、业务介绍 二、早期架构及痛点 2.1 早期架构 2.2 架构痛点 三、技术选型 四、新的架构及方案 五、搭建经验 5.1 数据建模 5.2 数据开发 5.3 库表设计 5.4 数据管理 5.4.1 监控告警 5.4.2 数据备份与恢复 六、收益总结 七、未来规划 原文大佬这篇Doris腾…...
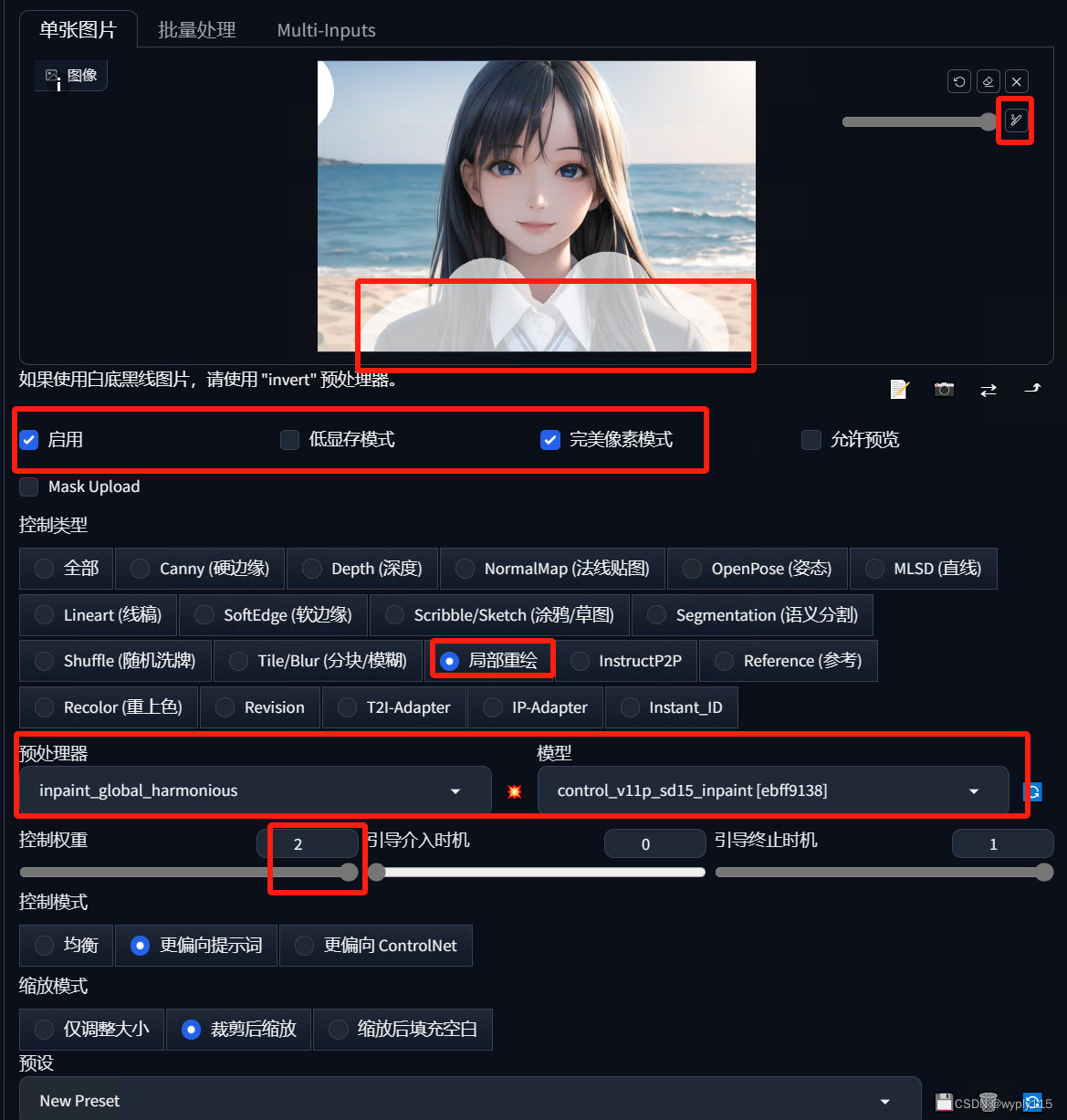
Stable Diffusion 绘画入门教程(webui)-ControlNet(Inpaint)
上篇文章介绍了语义分割Tile/Blur,这篇文章介绍下Inpaint(重绘) Inpaint类似于图生图的局部重绘,但是Inpain效果要更好一点,和原图融合会更加融洽,下面是案例,可以看下效果(左侧原图…...

LeetCode146: LRU缓存
题目描述 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存 int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则…...

【ArcGIS】基于DEM/LUCC等数据统计得到各集水区流域特征
基于DEM/LUCC等数据统计得到各集水区流域特征 提取不同集水区各类土地利用类型比例步骤1:划分集水区为独立面单元步骤2:批量掩膜提取得到各集水区土地利用类型比例步骤3:导入各集水区LUCC数据并统计得到各类型占比 提取坡度特征流域面坡度河道…...

vue3中安装并使用CSS预处理器Sass的方法介绍
文章目录 Sass是什么?为什么使用Sass?安装sass1、安装sass2、编写全局css变量/全局mixin3、vite引入并使用4、按需引入并使用 sass语法1、变量创建一个变量使用变量变量作用域 2、数学计算两个Sass有关于数学计算的“陷阱” 3、嵌套4、Imports sass中文官网 Sass是…...
)
过滤器(Filter)
过滤器(Filter) 1. 基本概念 过滤器(Filter)是拦截 Request 请求的对象:在用户的请求访问资源前处理 ServletRequest 和 ServletResponse 。 Filter 相关的接口有:Filter、FilterConfig、FilterChain 。…...
AMRT3D数字孪生引擎详解
AMRT 3D数字孪生引擎介绍 AMRT3D引擎是一款融合了眸瑞科技的AMRT格式与轻量化处理技术为基础,以降本增效为目标,支持多端发布的一站式纯国产自研的CS架构项目开发引擎。 引擎包括场景搭建、UI拼搭、零代码交互事件、光影特效组件、GIS/BIM组件、实时数据…...

Sqlite数据库详解
1.关于Sqlite SQLite 是一个进程内库,它实现了一个独立的、无服务器的、零配置的事务性 SQL 数据库引擎。 SQLite的代码属于公共领域,因此对 用于任何目的,商业或私人目的。 SQLite是世界上部署最广泛的数据库 应用程序比我们能做的要多 计数…...

基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统
wx供重浩:创享日记 对话框发送:225头盔 获取完整源码源文件已标注的数据集(1463张)源码各文件说明配置跑通说明文档 若需要一对一远程操作在你电脑跑通,有偿59yuan 效果展示 基于YOLOv8深度学习PyQT5的电动车头盔佩戴检…...
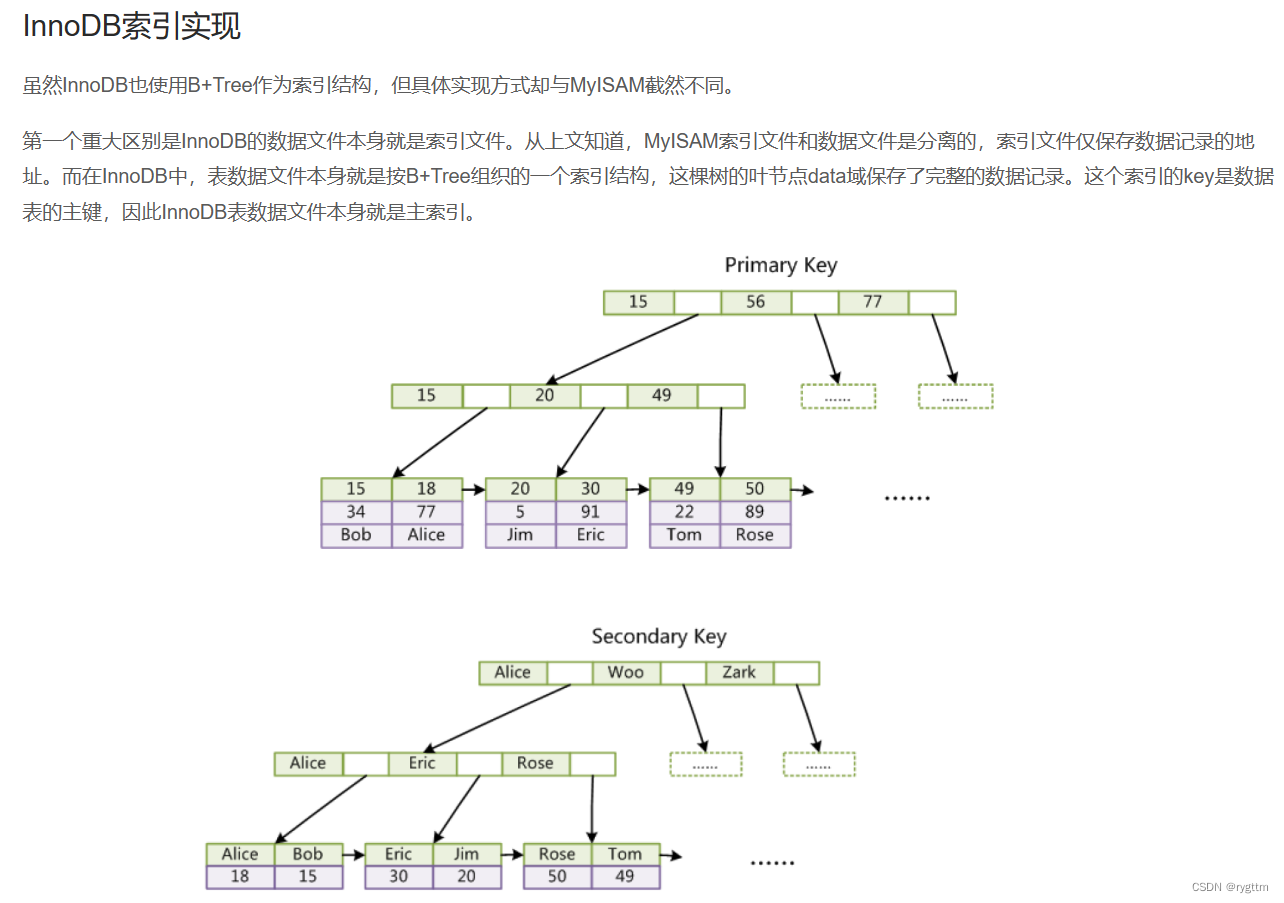
【数据结构】B树,B+树,B*树
文章目录 一、B树1.B树的定义2.B树的插入3.B树的中序遍历 二、B树和B*树1.B树的定义2.B树的插入3.B*树的定义4.B树系列总结 三、B树与B树的应用 一、B树 1.B树的定义 1. 在内存中搜索效率高的数据结构有AVL树,红黑树,哈希表等,但这是在内存…...

常用实验室器皿耐硝酸盐酸进口PFA材质容量瓶螺纹盖密封效果好
PFA容量瓶规格参考:10ml、25ml、50ml、100ml、250ml、500ml、1000ml。 别名可溶性聚四氟乙烯容量瓶、特氟龙容量瓶。常用于ICP-MS、ICP-OES等痕量分析以及同位素分析等实验,也可在地质、电子化学品、半导体分析测试、疾控中心、制药厂、环境检测中心等机…...
【kubernetes】二进制部署k8s集群之cni网络插件flannel和calico工作原理
k8s集群的三种接口 k8s集群有三大接口: CRI:容器进行时接口,连接容器引擎--docker、containerd、cri-o、podman CNI:容器网络接口,用于连接网络插件如:flannel、calico、cilium CSI:容器存储…...

Pycharm一直打不开,无任何报错
我windows安装了pycharm一直打不开(无论专业版还是社区版都打不开),无任何弹窗,无任何报错 最后解决问题: 查看环境变量PYCHARM_VM_OPTIONS 发现有一个环境变量PYCHARM_VM_OPTIONS 删除PYCHARM_VM_OPTIONS这个环境变量,pycharm终…...

用html编写的小广告板
用html编写的小广告板 相关代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</tit…...

hive中如何取交集并集和差集
交集 要获取两个表的交集,你可以使用INNER JOIN或者JOIN: SELECT * FROM table1 JOIN table2 ON table1.column_name table2.column_name;也可以使用 INTERSECT 关键字 SELECT * FROM table1 INTERSECT SELECT * FROM table2;并集 要获取两个表的并集…...

2024.2.26
今天又复习了一下熟悉的C语言 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> #include<windows.h>int main() {//数组初始化int n;scanf("%d", &n);int array[500];int i 0;for (i 0; i < n; i){scanf("%…...
【kubernetes】关于k8s集群的声明式管理资源
目录 一、声明式管理方法 二、资源配置清单管理 1、导出资源配置清单 2、修改资源配置清单并应用 2.1离线修改 2.2在线修改 三、通过资源配置清单创建资源对象 获取K8S资源配置清单文件模板? 关于配置清单常见的字段 方案一:手写yaml配置文件 …...
)
8.openEuler操作系统网络管理和防火墙(二)
openEuler OECA认证辅导,标红的文字为学习重点和考点。 如果需要做实验,建议安装麒麟信安、银河麒麟、统信等具有图形化的操作系统,其安装与openeuler基本一致。 3.通过IP命令配置网络 配置IP地址: 使用ip命令为接口配置地址,命令格式如下,其中 interface-name 为网卡名…...

1904_ARM Cortex M系列芯片特性小结
1904_ARM Cortex M系列芯片特性小结 全部学习汇总: g_arm_cores: ARM内核的学习笔记 (gitee.com) ARM Cortex M系列的MCU用过好几款了,也涉及到了不同的内核。不过,关于这些内核的基本的特性还是有些不了解。从ARM的官方网站上找来了一个对比…...

热闹元宵进行中,如何利用VR全景展示民宿品牌形象?
错峰出游闹元宵,元宵节恰逢周末,而且还是春节假期返工之后的首个休息日,不少人都想通过短途度假来缓解“节后综合征”。两位数的特价机票、打折的各种酒店让你实现“旅行自由”,那么如何知道特价酒店服务好不好呢?先别…...

PPTXjs:零安装!在浏览器中完美预览PPTX文件的终极方案
PPTXjs:零安装!在浏览器中完美预览PPTX文件的终极方案 【免费下载链接】PPTXjs jquery plugin for convertation pptx to html 项目地址: https://gitcode.com/gh_mirrors/pp/PPTXjs 还在为无法在线查看PPTX文件而烦恼吗?PPTXjs为你带…...

FPGA实现UDP/IP协议栈,为什么我建议你从校验和与ARP缓存设计开始?
FPGA实现UDP/IP协议栈:从校验和与ARP缓存设计的核心陷阱突破 在FPGA上实现完整的UDP/IP协议栈时,许多开发者往往陷入一个误区——过早关注协议格式解析而忽视底层关键模块的健壮性设计。本文将聚焦两个最容易被低估却决定系统稳定性的核心组件࿱…...

立创EDA画STM32板子,这些“隐藏”设置能让你的PCB一次打样成功
立创EDA画STM32板子的7个高阶设置技巧 第一次用立创EDA画完STM32板子的那种成就感,往往会被打样回来后发现的问题冲淡——电源线发热、信号干扰、过孔断裂...这些问题大多源于一些容易被忽略的参数设置。作为用过上百次立创EDA的老手,我总结出这些实战经…...

Stata实操:用xtreg命令搞定面板数据,固定效应和随机效应到底怎么选?
Stata面板数据分析实战:从数据清洗到模型选择的完整指南 当面对一份包含多个实体(如公司、国家或个人)在不同时间点观测值的数据集时,面板数据分析方法成为揭示深层规律的有力工具。不同于单纯的横截面或时间序列数据,…...

Vue3-Marquee 架构深度解析:零依赖跑马灯组件的设计哲学与实践
Vue3-Marquee 架构深度解析:零依赖跑马灯组件的设计哲学与实践 【免费下载链接】vue3-marquee A simple marquee component with ZERO dependencies for Vue 3. 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-marquee 在 Vue 3 生态系统中,动…...

知网文献批量下载终极指南:3步实现高效学术研究自动化
知网文献批量下载终极指南:3步实现高效学术研究自动化 【免费下载链接】CNKI-download :frog: 知网(CNKI)文献下载及文献速览爬虫 (Web Scraper for Extracting Data) 项目地址: https://gitcode.com/gh_mirrors/cn/CNKI-download 还在为手动下载知网文献而…...

避坑指南:向老外要质粒/数据,为什么总石沉大海?这5个细节你可能没注意
科研材料索要实战手册:5个被忽视的关键细节决定成败 在跨国科研合作中,向国际同行索取质粒或实验数据,往往像在迷宫中寻找出口——明明按照常规路径操作,却总在某个转角碰壁。许多研究者都有过这样的经历:精心撰写的邮…...

Windows BAT脚本提权实战:从‘拒绝访问’到完美运行,我的踩坑记录与两种VBS方案详解
Windows BAT脚本提权实战:从权限不足到完美执行的深度解析 1. 当脚本遇到"拒绝访问":一个真实的权限困境 上周三凌晨2点,我正试图通过批处理脚本自动化部署一套本地测试环境。当脚本尝试修改C:\Windows\System32\drivers\etc\hosts…...

AssetRipper终极指南:5个技巧轻松提取Unity游戏资产
AssetRipper终极指南:5个技巧轻松提取Unity游戏资产 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipper是一款功能…...
)
MATLAB实战:用自适应UKF搞定单目视觉下的机器人位姿跟踪(附完整代码)
MATLAB实战:用自适应UKF实现单目视觉机器人位姿跟踪 在机器人定位与导航领域,位姿跟踪的精度直接影响着自主系统的决策质量。传统UKF(无迹卡尔曼滤波)在面对过程噪声统计特性未知的场景时,其性能往往大打折扣。本文将带…...