自定义神经网络二之模型训练推理
文章目录
- 前言
- 模型概念
- 模型是什么?
- 模型参数有哪些
- 神经网络参数案例
- 为什么要生成模型
- 模型的大小
- 什么是大模型
- 模型的训练和推理
- 模型训练
- 训练概念
- 训练过程
- 训练过程中的一些概念
- 模型推理
- 推理概念
- 推理过程
- 总结
前言
自定义神经网络一之Tensor和神经网络
通过上一篇文章,我们大概了解了神经网络以及常见的神经网络结构和应用场景。但是在日常与算法同学打交道中,基本都是算法同学提供模型,工程化同学进行推理获取结果。
那么模型是什么,怎么产生的模型,模型训练和推理又是干嘛的呢?下面我们一一道来。
模型概念
模型是什么?
一个模型通常是一个构建好的并通过数据训练过的神经网络。它会保存学习到的特征和模式,用来对新的数据进行预测或者解决特定的问题。
通常,一个神经网络模型主要包含两部分:结构(Architecture) 和 权重(Weights)。
- 结构:这部分定义了模型的各个层及其连接方式。比如有多少层,每一层有多少个节点,每一层用的是什么类型的激活函数等等。这个结构是设计模型时预先定义好的。
- 权重:在模型的训练过程中,模型会学习到一些权重和偏置,这些都存储在权重中。这些权重和偏置就是模型从数据中学到的规律和知识,用来进行预测的。
模型参数有哪些
参考:深度学习之参数初始化
参数是模型所需要学习的一部分,通常被认为是模型的"知识"。这些参数处理输入数据,帮助模型做出预测。
以最常见的深度学习模型——神经网络为例,它的参数主要包括权重和偏置。
- 权重(Weights):权重决定了每一个输入特征对最终输出预测的影响程度。例如,在多层感知器(MLP)中,每一个输入节点和隐藏节点之间都有一个权重,该权重决定了输入值被乘以多少然后送入下一层节点。
- 偏置(Biases):偏置是用来调节神经元的激活阈值。可以看作是当所有的输入特征都为0时模型的预测值。如果没有偏置,神经元的输出就只是输入的加权和,当输入都是0时,输出也会是0。有了偏置之后,即使所有输入都是0,神经元还是有可能被激活。
- 公式: Y = W1 * X1 + W2 * X2 + b
- 两个输入节点(X1,X2),和一个输出节点(Y)
- W1和W2就是权重,分别定义了X1和X2对Y的贡献。
- b就是偏置
在神经网络中,我们使用张量来表示权重和偏置。每一层的权重可以用一个二维的张量来表示,其中行表示输入节点的数量,列表示输出节点的数量。偏置则是一个一维的张量,长度等于输出节点的数量。
神经网络参数案例
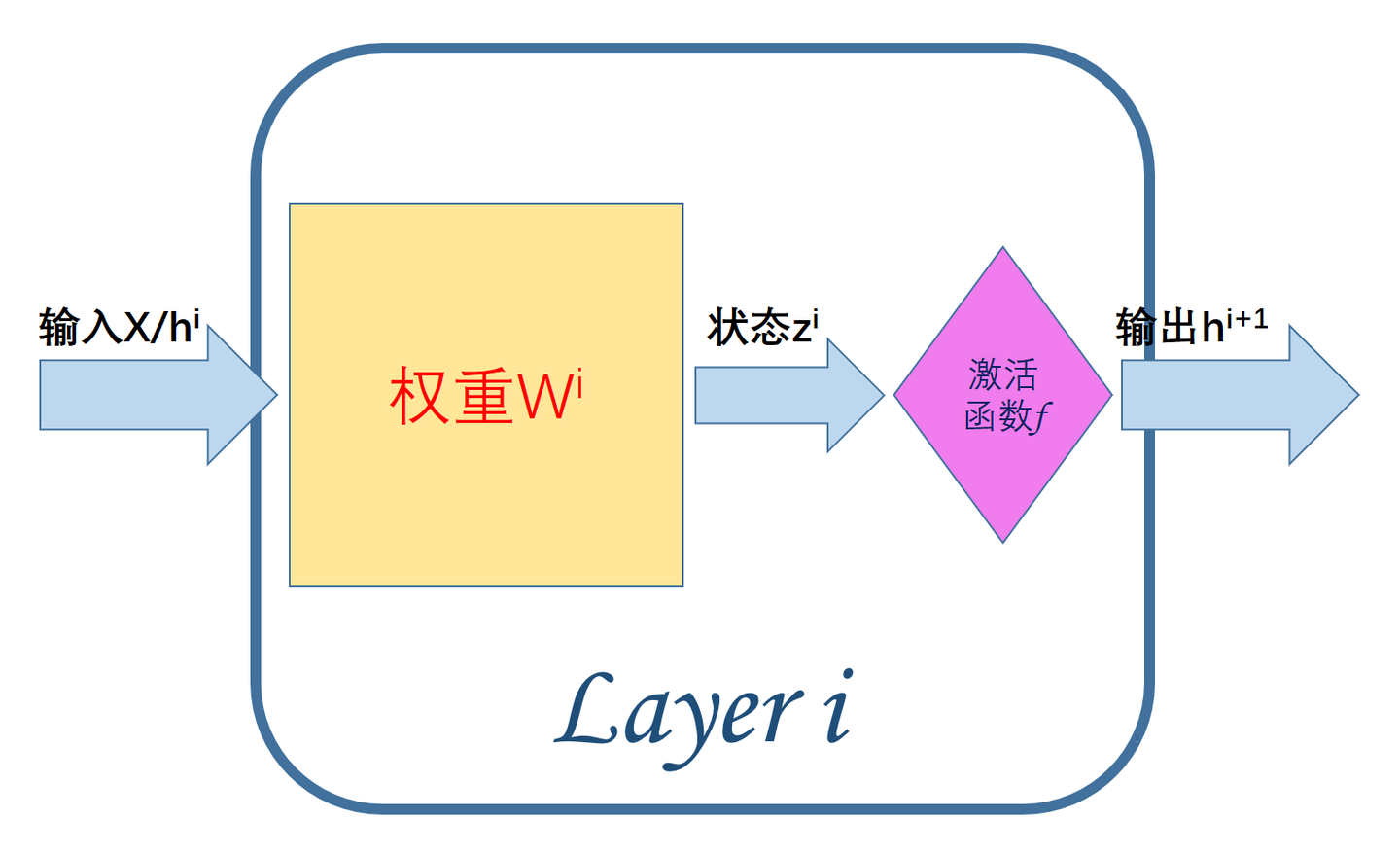
由图可知,每一个层内部的组成主要有:
输入X/hi:来自原始样本X的输入(i=0)或上一层(第i−1层)的输出hi。
权重W:网络模型训练的主体对象,第ii层的权重参数wi。
状态值z:作为每一层激活函数f的输入,处于网络层的内部,所以称之为状态值。
激活值h:状态值zi经过了激活函数f后的输出,也就是第i层的最终输出hi;
为什么要生成模型
训练结束之后,我们可以直接使用训练好的神经网络进行推理,但是这样的话不具备移植性,程序运行结束没有存档。
我们可以保存成模型的方式,然后通过解析模型去进行推理,这样的模型是具备移植性的。而且相当于保留了训练成果,可以继续在这个模型上进行进一步的训练。
模型的保存通常包括两部分:
模型的结构和模型的权重。模型的结构保存了神经网络的架构(例如,各个层的类型,层的数量,每层的节点数等),而模型的权重保存了训练过程中学到的模型参数。
在Python的深度学习框架(如TensorFlow, PyTorch)中,“保存”模型通常意味着将模型的结构和权重序列化为二进制格式,并写入磁盘。对于TensorFlow和Keras,保存的模型通常是.h5或.ckpt(Checkpoint)格式的文件;对于PyTorch,保存的模型通常是.pt或.pth格式的文件。
模型的大小
参考:大模型(Large Model)常识综述(三)
这里要区分模型的磁盘大小和训练参数大小的区别。比如现在的大模型,训练参数可能是7b,13b,70b等,这里的b的单位是亿,比如7b代表70亿参数,这里的b代表10亿参数。
而模型的磁盘大小是指神经网络训练结束,保存为模型文件的大小。例如7b的llama2磁盘大小是3.8G, 13b的llama2磁盘大小是7.4G
我们自定义的神经网络,2层神经网络+每层一个神经元 + 每个神经元1个权重+偏置项 = 4个参数,保存模型大小为41k左右。
什么是大模型
**大模型是指具有大规模参数和复杂计算结构的机器学习模型。**这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
模型的训练和推理
机器学习模型的训练和推理是一个基于数据的反馈循环过程。
训练过程是模型学习数据的过程,而推理过程是使用已训练好的模型进行预测或分类的过程。
模型训练
训练概念
一个初始神经网络通过不断的优化自身参数,来让自己变得准确。这整个过程就称之为训练(Training)
训练过程
- 数据准备:选择和收集相应的数据集,对数据进行清洗、标注、特征提取等预处理操作,以便让数据适合模型的输入。
- 模型选择和定义:根据问题的需求,选择合适的模型架构,比如神经网络、决策树等,并定义模型的结构、参数和超参数。
- 模型初始化:对模型参数进行初始化操作,这样可以让模型开始训练时具有一定的初始能力。
- 前向传播:将数据输入模型,通过模型的每一层计算,从输入层到输出层的过程称为前向传播。在前向传播过程中,模型会依次计算每一层的输出,并在最后一层产生预测结果。
- 激活函数:每个神经元接收到输入后对其加权求和,然后传递给激活函数,根据激活函数的结果确定神经元的输出。
- 计算损失函数:将模型预测的结果与真实标签进行比较,计算模型的误差。常用的损失函数有平方损失、交叉熵损失等。
- 反向传播:根据损失函数的值,通过反向传播算法计算模型中各个参数的梯度。梯度是损失函数对参数的变化率,反向传播的目的是根据模型对样本的预测误差来调整模型参数,使得预测结果更加准确。
- 参数更新:利用优化算法(如梯度下降算法)根据梯度信息对模型参数进行更新。更新参数的过程会降低模型在当前任务上的训练误差。
- 重复迭代:通过重复执行前面的步骤,不断训练模型,直到模型的性能达到预期或收敛。
训练过程中的一些概念
正向传播: 输入信号从输入层经过各个隐藏层向输出层传播。在输出层得到实际的响应值,若实际值与期望值误差较大,就会转入误差反向传播阶段。
反向传播: 按照梯度下降的方法从输出层经过各个隐含层并逐层不断地调整各神经元的连接权值和阈值,反复迭代,直到网络输出的误差减少到可以接受的程度,或者进行到预先设定的学习次数。
代(Epoch): 使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练”。
批大小(Batch size): 使用训练集的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据”
迭代(Iteration): 使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练”(一次迭代)。每一次迭代得到的结果都会被作为下一次迭代的初始值。一个迭代=一个正向通过+一个反向通过。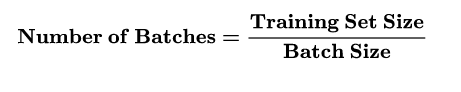
比如训练集有500个样本,batchsize = 10 ,那么训练完整个样本集:iteration=50,epoch=1.
模型推理
推理概念
你训练好了一个模型,在训练数据集中表现良好,但是我们的期望是它可以对以前没看过的图片进行识别。你重新拍一张图片扔进网络让网络做判断,这种图片就叫做现场数据(livedata),如果现场数据的区分准确率非常高,那么证明你的网络训练的是非常好的。这个过程,称为推理(Inference)。
推理过程
- 数据准备:与训练过程相似,对输入数据进行预处理和特征提取。
2. 模型加载:将训练好的模型加载到内存中,准备进行推理。
3. 前向传播:将处理后的数据输入模型,并通过前向传播计算得到输出结果。
4. 输出解释:针对输出结果进行解释和处理,根据具体的问题进行分类、回归、预测等。
5. 结果反馈:将输出结果反馈给用户或其他系统,完成推理过程。
需要注意的是,训练过程通常需要大量的数据和计算资源来完成,而推理过程相对较快,因为训练过程中大部分的计算已经在模型参数更新时完成了。
总结
本篇博客主要介绍了神经网络中模型的相关概念以及模型的训练和推理过程。整体来说更偏概念性,特别是训练和推理部分。后续我们会在自定义神经网络部分详细解释训练和推理在代码上的表示。
end
相关文章:
自定义神经网络二之模型训练推理
文章目录 前言模型概念模型是什么?模型参数有哪些神经网络参数案例 为什么要生成模型模型的大小什么是大模型 模型的训练和推理模型训练训练概念训练过程训练过程中的一些概念 模型推理推理概念推理过程 总结 前言 自定义神经网络一之Tensor和神经网络 通过上一篇…...
)
Java设计模式:单例模式之六种实现方式详解(二)
在Java中,单例模式是一种常见的设计模式,用于确保一个类只有一个实例,并提供一个全局访问点来获取该实例。单例模式在多种场景下都很有用,比如配置文件的读取、数据库连接池、线程池等。本文将详细介绍Java中实现单例模式的六种方…...
开创5G无线新应用:笙科电子5.8GHz 射频芯片
笙科电子(AMICCOM) 5.8GHz A5133射频芯片是一款专门设计用于在5.8GHz频率范围内(5725MHz - 5850MHz)进行射频信号处理的集成电路。这些集成电路通常包括各种功能模块,如射频前端、混合器、功率放大器、局部振荡器等,以支持无线通信系统的各种…...
使用 JMeter 生成测试数据对 MySQL 进行压力测试
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…...

C# cass10 面积计算
运行环境Visual Studio 2022 c# cad2016 cass10 通过面积计算得到扩展数据,宗地面积 ,房屋占地面积,房屋使用面积 一、主要步骤 获取当前AutoCAD应用中的活动文档、数据库和编辑器对象。创建一个选择过滤器,限制用户只能选择&q…...

中间件-Nginx漏洞整改(限制IP访问隐藏nginx版本信息)
中间件-Nginx漏洞整改(限制IP访问&隐藏nginx版本信息) 一、限制IP访问1.1 配置Nginx的ACL1.2 重载Nginx配置1.3 验证结果 二、隐藏nginx版本信息2.1 打开Nginx配置文件2.2 隐藏Nginx版本信息2.3 保存并重新加载Nginx配置2.4 验证结果2.5 验证隐藏版本…...
Xcode与Swift开发小记
文章目录 引子Xcode工程结构核心概念Swift语法速记(TODO)小技巧单元测试中使用awaitSwiftUI中使用ListView中取数据 常见问题Xcode添加package时连接github超时Xcode无法修改快捷键,一闪而过 引子 鉴于React Native目前版本在iOS上开发遇到诸多问题,本以…...
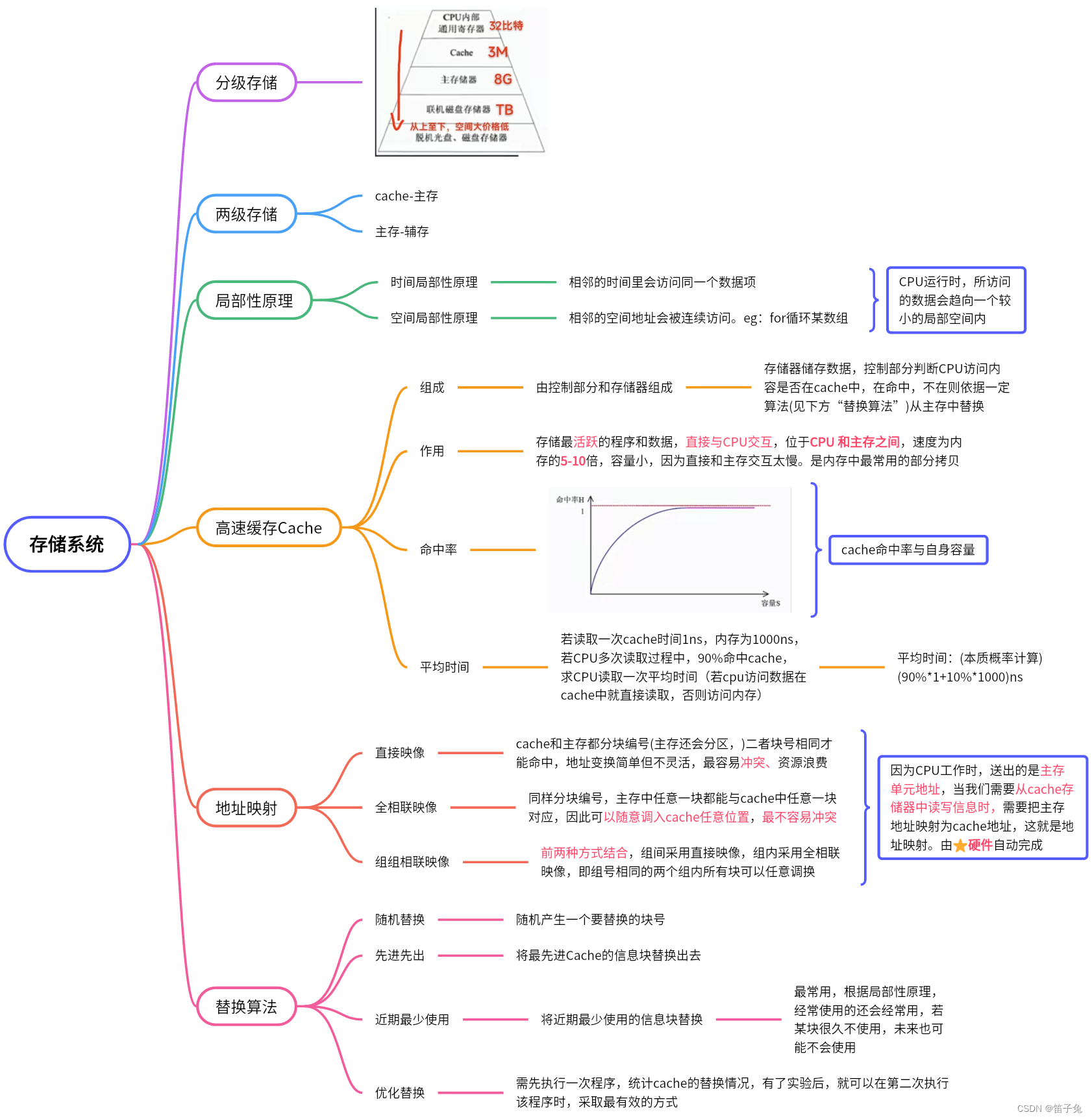
日更【系统架构设计师知识总结3】存储系统
【原创精华总结】自己一点点手打、总结的脑图,把散落在课本以及老师讲授的知识点合并汇总,反复提炼语言,形成知识框架。希望能给同样在学习的伙伴一点帮助!...
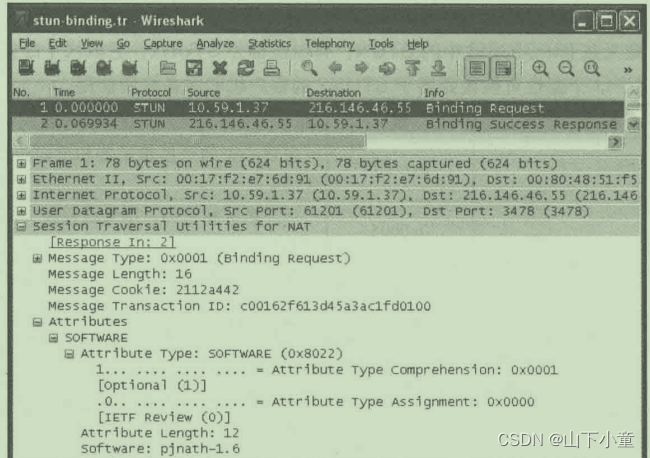
《TCP/IP详解 卷一》第7章 防火墙和NAT
7.1 引言 NAT通常改变源IP和源端口,不改变目的IP和目的端口。 7.2 防火墙 常用防火墙: 包过滤防火墙(packet-filter firewall) 代理防火墙(proxy firewall) 代理防火墙作用: 1. 通过代理服务…...

访问raw.githubusercontent.com失败问题的处理
1 问题 GitHub上的项目的有些资源是放在raw.githubusercontent.com上的,通常我们在安装某些软件的时候会从该地址下载资源,直接访问的话经常容易失败。 # 安装operator kubectl apply -f https://raw.githubusercontent.com/oceanbase/ob-operator/2.1…...

Elasticsearch的基本安装教程,Elasticsearch+SpringBoot实现简单的增删改查功能
Elasticsearch 是一个开源的分布式搜索和分析引擎,最初由 Elastic 公司开发。它是基于 Apache Lucene 的搜索引擎构建的,提供了强大的搜索和分析功能,并支持实时数据检索和分析。 Elasticsearch 被设计用来处理大规模的数据集,它具有以下几个主要特点: 分布式架构: Elast…...

【Git教程】(五)分支 —— 并行式开发,分支相关操作(创建、切换、删除)~
Git教程 分支 1️⃣ 并行式开发2️⃣ 修复旧版本中的 bug3️⃣ 分支4️⃣ 当前活跃分支5️⃣ 重置分支指针6️⃣ 删除分支7️⃣ 清理提交对象🌾 总结 对于版本提交为什么不能依次进行,以便形成一条直线型的提交历史记录,我们认为有 以下两个…...

Maven管理项目,本地仓库有对应的jar包,但还是报找不到
文章目录 业务场景错误提示分析过程解决办法 业务场景 settings.xml种配置了私服,但是有些依赖私服上没有,通过同事拷贝过来的。但是用maven打包时报红了。 错误提示 Idea Maven错误:was cached in the local repository, resolution will…...
)
手写JavaScript中的Promise.all方法(JS中Promise.all的执行过程)
简介: Promise.all是JavaScript中一种用于处理多个Promise对象的方法,该方法接收一个数组作为参数,并返回一个新的Promise对象。 这个新的对象会在所有Promise对象都成功解析后解析,解析的结果是一个数组,包含了所有P…...

IP设置教程
Win 7 固定Ip设定 https://jingyan.baidu.com/article/4b07be3cbc8e7348b380f31d.html Win 10 固定Ip设定 Win10 固定IP地址方法_win10设置固定ip地址怎么设置-CSDN博客 Win 11 固定Ip设定 https://jingyan.baidu.com/article/cb5d6105be5354415c2fe0d3.html TP-LINK…...
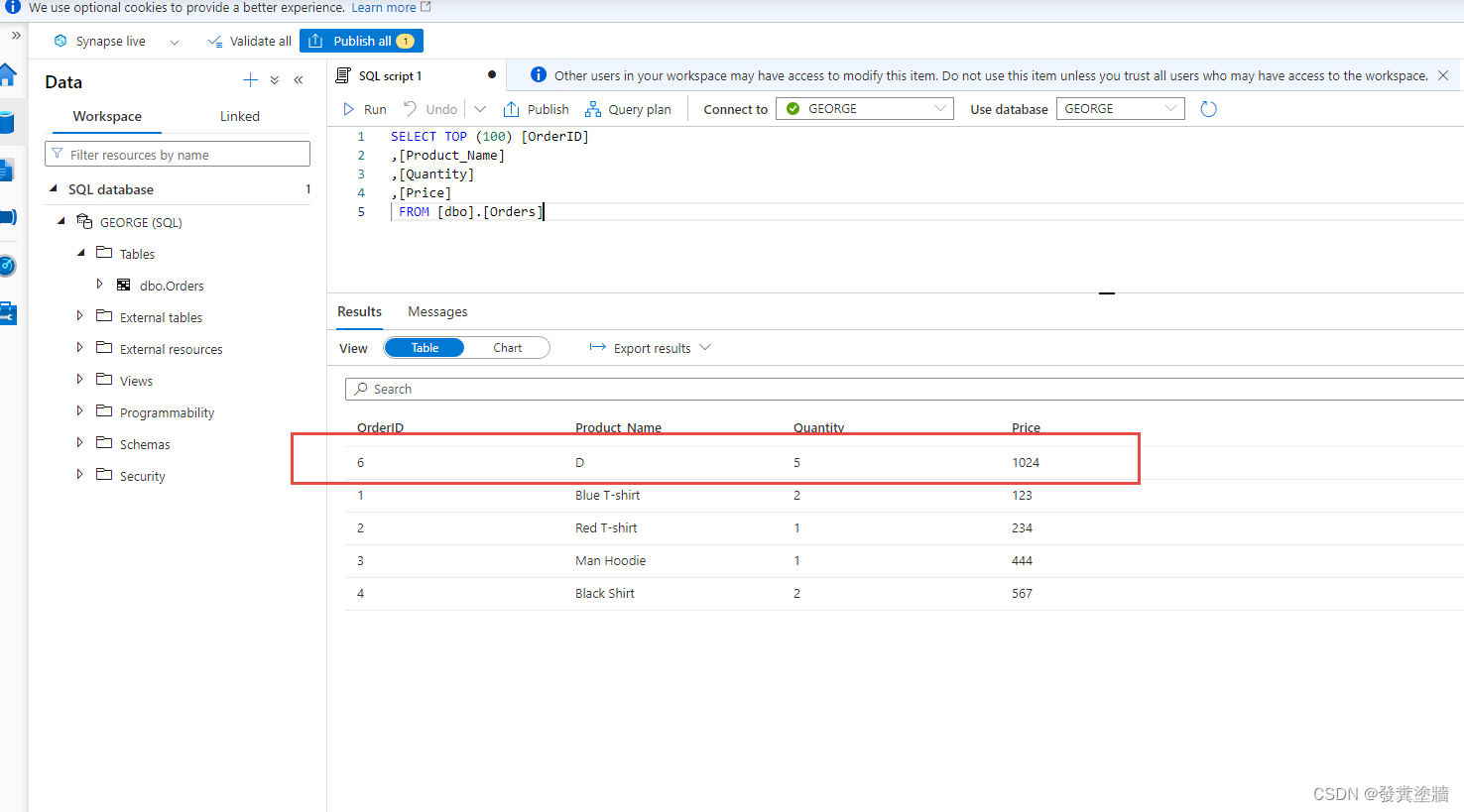
【Azure 架构师学习笔记】-Azure Synapse -- Link for SQL 实时数据加载
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Synapse】系列。 前言 Azure Synapse Link for SQL 可以提供从SQL Server或者Azure SQL中接近实时的数据加载。通过这个技术,使用SQL Server/Azure SQL中的新数据能够几乎实时地传送到Synapse(…...
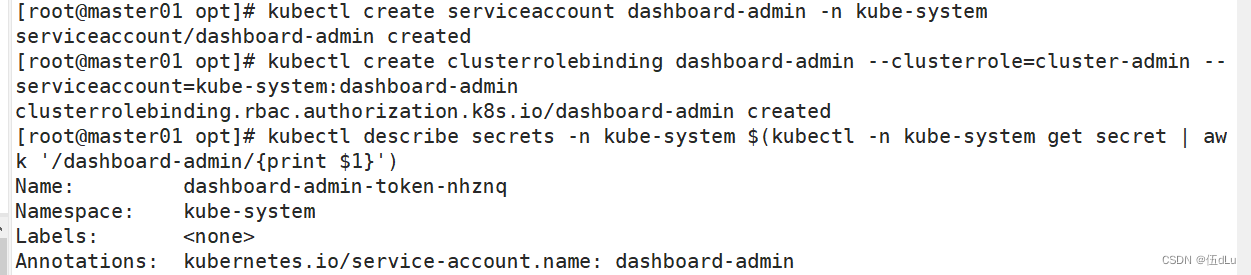
k8s(5)
目录 使用Kubeadm安装k8s集群: 初始化操作: 每台主从节点: 升级内核: 所有节点安装docker : 所有节点安装kubeadm,kubelet和kubectl: 修改了 kubeadm-config.yaml,将其传输给…...

【服务器数据恢复】ext3文件系统下硬盘坏道掉线的数据恢复案例
服务器数据恢复环境: 一台IBM某型号服务器上有16块FC硬盘组建RAID阵列。上层linux操作系统,ext3文件系统,部署有oracle数据库。 服务器故障&检测: 服务器上跑的业务突然崩溃,管理员发现服务器上有2块磁盘的指示灯…...
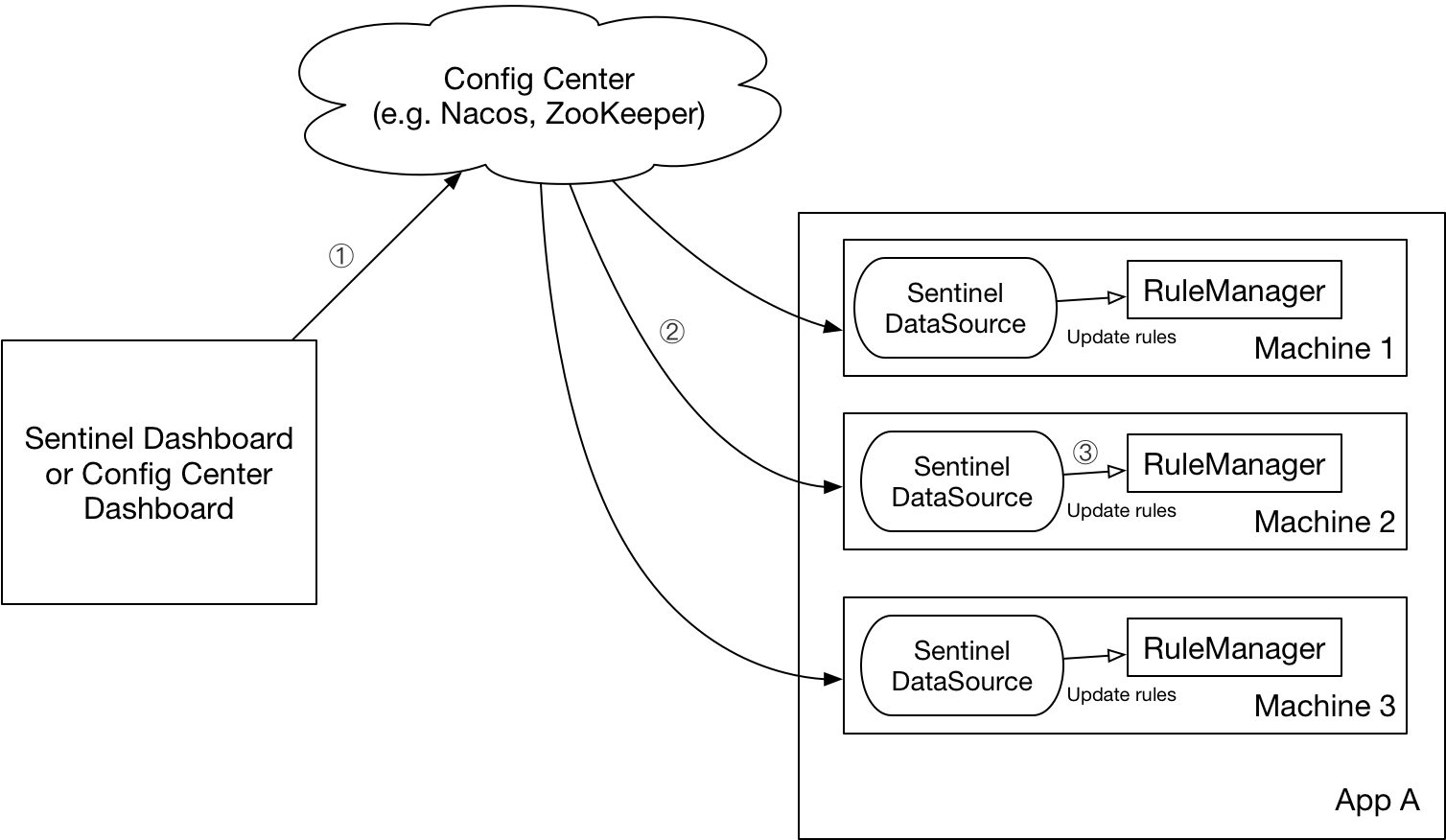
Sentinel 动态规则扩展
一、规则 Sentinel 的理念是开发者只需要关注资源的定义,当资源定义成功后可以动态增加各种流控降级规则。Sentinel 提供两种方式修改规则: 通过 API 直接修改 (loadRules)通过 DataSource 适配不同数据源修改 手动通过 API 修改比较直观,…...
UE5 UE4 自定义插件自动开启关联插件(plugin enable)
在我们自己编写UE4、UE5的插件时,常常需要开启相关联的插件进行功能编写。 例如:UE4/5 批量进行贴图Texture压缩、修改饱和度_ue4批量修改纹理大小-CSDN博客 而让插件使用者每次使用时,依次进行开启其他相关联插件确实有些麻烦。 如何只需要…...

如何使用ui2/ui实现高效拖放操作:打造流畅的文件与数据传输体验
如何使用ui2/ui实现高效拖放操作:打造流畅的文件与数据传输体验 【免费下载链接】ui Platform-native GUI library for Go. 项目地址: https://gitcode.com/gh_mirrors/ui2/ui 在现代GUI应用开发中,拖放功能已成为提升用户体验的关键特性。本文将…...
)
Gazebo插件编译后报错‘No such file or directory’?手把手教你两种路径配置方法(附.bashrc修改)
Gazebo插件路径配置终极指南:从报错诊断到永久解决方案 当你满心欢喜地编译完Gazebo插件,却在运行世界文件时看到那个令人沮丧的"Failed to load plugin"错误时,那种感觉就像精心准备的晚餐被突然打翻。别担心,这几乎是…...
)
OSGEarth3动态图层加载实战:如何用代码‘拼装’你的专属地球(以world.tif为例)
OSGEarth3动态图层加载实战:如何用代码‘拼装’你的专属地球(以world.tif为例) 当我们需要在三维GIS应用或仿真系统中构建一个可交互的地球场景时,静态的earth文件虽然方便,但往往难以满足动态需求。想象一下这样的场景…...

百度网盘秒传脚本:告别文件链接失效,三步实现永久分享
百度网盘秒传脚本:告别文件链接失效,三步实现永久分享 【免费下载链接】rapid-upload-userscript-doc 秒传链接提取脚本 - 文档&教程 项目地址: https://gitcode.com/gh_mirrors/ra/rapid-upload-userscript-doc 你是否曾因百度网盘分享链接突…...

HTTrack网站镜像工具:从入门到精通的完整使用指南
HTTrack网站镜像工具:从入门到精通的完整使用指南 【免费下载链接】httrack HTTrack Website Copier, copy websites to your computer (Official repository) 项目地址: https://gitcode.com/gh_mirrors/ht/httrack HTTrack是一款强大的网站镜像工具和离线浏…...

3步快速掌握抖音批量下载助手:新手完全指南
3步快速掌握抖音批量下载助手:新手完全指南 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?面对心仪创作者的海量内容,一个个点击下载不…...

5 款 AI 写论文哪个好?2026 实测:真文献 + 实图表,虎贲等考 AI 成毕业论文首选
毕业季选 AI 写论文工具,最纠结的莫过于 “5 款 AI 写论文哪个好”—— 通用 AI 文献造假、轻量工具功能残缺、专项平台适配不足,能同时满足真实文献、可溯源数据、学术规范图表、全流程写作的工具少之又少。经过对 5 款主流 AI 论文工具的深度实测&…...
)
别再让OCV拖慢你的芯片!手把手教你用set_timing_derate优化时序(附CPPR实战)
芯片时序优化实战:用set_timing_derate与CPPR攻克OCV难题 在28nm以下工艺节点,芯片设计师们常会遇到一个令人头疼的现象——明明仿真时一切正常,流片后却因时序违例导致频率上不去。上周和某头部AI芯片公司的同事聊到这个问题,他们…...

从实验室到田间:FDR土壤水分传感器选型、部署与数据解读避坑指南
从实验室到田间:FDR土壤水分传感器选型、部署与数据解读避坑指南 清晨六点,当第一缕阳光穿透大棚薄膜时,山东寿光的番茄种植户老王发现自动灌溉系统又误启动了——这已经是本周第三次。他蹲下身拨开表层土壤,指尖传来的干燥触感与…...

爱毕业aibiye具备每日免费无限查重功能,集成AI改写工具,帮助用户轻松调整论文内容
核心工具对比速览 工具名称 查重速度 降重效果 特色功能 适用场景 aicheck 极快 重复率可降30% 专业术语保留 高重复率紧急处理 aibiye 中等 逻辑优化明显 学术表达增强 提升论文质量 askpaper 快 结构保持完整 多语言支持 外文论文降重 秒篇 极快 上下文…...