大语言模型构建的主要四个阶段(各阶段使用的算法、数据、难点以及实践经验)
大语言模型构建通常包含以下四个主要阶段:预训练、有监督微调、奖励建模和强化学习,简要介绍各阶段使用的算法、数据、难点以及实践经验。
- 预训练
- 有监督微调阶段
- 奖励建模阶段
- 强化学习阶段
1. 预训练(Pre-training)
算法:
- 在预训练阶段,最常用的算法是基于Transformer架构的自注意力机制,如BERT、GPT系列、XLNet、RoBERTa等模型。这些模型通过无监督学习的方法,在大规模未标注文本数据上进行训练,学习语言的基本结构和模式。
数据:
- 使用数十亿乃至数百亿字节级别的大规模语料库,包括网页抓取数据、书籍、百科全书、论坛讨论等各类文本数据。
难点:
- 数据清洗和预处理:去除噪声数据,确保训练数据的质量和多样性。
- 计算资源需求:训练超大规模模型需要极其庞大的计算资源,包括GPU集群或TPU阵列。
- 学习效率和泛化能力:如何设计有效的预训练任务(如掩码语言模型、自回归语言模型等)以提高模型学习质量和泛化性能。
实践经验:
- BERT使用双向Transformer编码器结构,并引入了掩码语言模型(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP)任务进行预训练。
- GPT系列模型使用自回归Transformer解码器,通过预测下一个词语的方式进行预训练。
2. 有监督微调(Supervised Fine-tuning)
算法:
- 在预训练模型的基础上,针对特定的下游任务(如文本分类、问答、命名实体识别等),在带标签的小规模任务数据集上进行有监督微调。
数据:
- 微调阶段使用的数据集通常是有标注的任务特异性数据,如GLUE、SuperGLUE、SQuAD等任务数据集。
难点:
- 过拟合:由于预训练模型参数量庞大,如何在有限的标注数据上进行有效微调而不至于过拟合是一个挑战。
- 微调策略:如何选择合适的微调层、冻结部分层、调整学习率等因素以优化微调效果。
实践经验:
- 微调时通常会对预训练模型的顶部层进行训练,同时调整模型整体的学习率,以充分利用预训练阶段学到的通用知识。
3. 奖励建模(Reinforcement Learning)
算法:
- 在某些情况下,模型的训练可以通过强化学习方式进行,模型根据所采取的动作(生成文本等)得到环境反馈(奖励或惩罚),进而调整策略。
数据:
- 不再依赖于明确的标签,而是根据模型生成的文本内容与预期目标的匹配程度或其他相关指标给予奖励信号。
难点:
- 设计合理的奖励函数:确保奖励信号能够正确反映生成文本的质量和目标任务的要求。
- 稳定性与收敛性:强化学习过程可能较不稳定,需要精细调整训练策略以保证收敛到最优解。
实践经验:
- OpenAI的GPT-3在一些生成任务上采用了基于奖励的微调(RLHF,Reinforcement Learning with Human Feedback),通过人类评估员对模型生成结果的打分来调整模型策略。
4. 强化学习(Reinforcement Learning)
算法:
- 强化学习应用于语言模型时,通常涉及到自动生成任务,模型通过不断试错并根据外部环境的反馈(例如人类用户的评价或内置评估指标)调整自身行为。
数据:
- 可能是与环境交互产生的序列数据,或者是用户对模型生成结果的反馈数据。
难点:
- 采样效率:强化学习往往需要大量交互以学习最优策略,而在自然语言生成场景下,采样和反馈可能十分耗时和昂贵。
- 环境模拟:如果不能直接与真实世界交互,可能需要构建模拟环境来优化模型。
实践经验:
- 一些研究尝试将强化学习用于对话系统,通过与模拟用户交互,使模型学会更加流畅和有意义的对话策略。在实践中,通常会结合有监督学习和强化学习,以最大化模型性能。
总之,构建大语言模型是一个循序渐进的过程,从大规模预训练开始,逐步通过有监督微调、奖励建模和强化学习等手段,让模型适应更具体和复杂的任务需求。在这个过程中,如何优化算法、合理利用数据、克服难点以及总结最佳实践,都是推动模型性能持续提升的关键要素。
相关文章:
)
大语言模型构建的主要四个阶段(各阶段使用的算法、数据、难点以及实践经验)
大语言模型构建通常包含以下四个主要阶段:预训练、有监督微调、奖励建模和强化学习,简要介绍各阶段使用的算法、数据、难点以及实践经验。 预训练 需要利用包含数千亿甚至数万亿 单词的训练数据,并借助由数千块高性能 GPU 和高速网络组成的…...
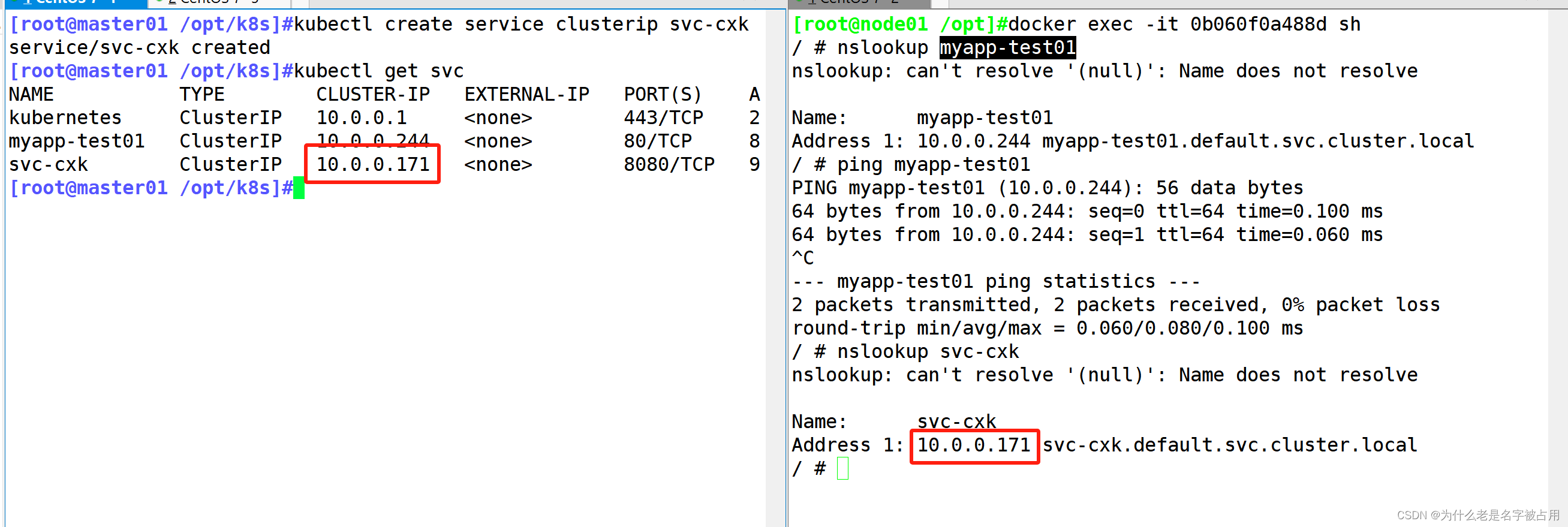
[云原生] 二进制安装K8S(中)部署网络插件和DNS
书接上文,我们继续部署剩余的插件 一、K8s的CNI网络插件模式 2.1 k8s的三种网络模式 K8S 中 Pod 网络通信: (1)Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享…...

云端技术驾驭DAY13——Pod污点、容忍策略、Pod优先级与抢占、容器安全
往期回顾: 云端技术驾驭DAY01——云计算底层技术奥秘、云服务器磁盘技术、虚拟化管理、公有云概述 云端技术驾驭DAY02——华为云管理、云主机管理、跳板机配置、制作私有镜像模板 云端技术驾驭DAY03——云主机网站部署、web集群部署、Elasticsearch安装 云端技术驾驭…...
掌握Docker:让你的应用轻松部署和管理
文章目录 一、引言(为什么要学习docker?)1.1 环境不一致1.2 隔离性1.3 弹性伸缩1.4 学习成本 二、Docker介绍2.1 Docker的由来2.2 什么是Docker2.3 为什么要用Docker2.3.1 虚拟机2.3.2 Linux容器 2.4 Docker与传统虚拟机的区别2.5 Docker的思…...

5G-A,未来已来
目前,全国首个5G-A规模组网示范完成。这项由北京联通携手华为共同打造的示范项目,实现了北京市中心金融街、历史建筑长话大楼、大型综合性体育场北京工人体育场三个重点场景的连片覆盖。 实际路测结果显示,5G-A用户下行峰值速率达到10Gbps&am…...

智慧公厕让社区生活更美好
随着科技的迅猛发展,城市管理、城市服务均使用科技化的手段进行升级改造,社区生活更美好赋予全新的智慧效能,其中智慧公厕也成为了城市环卫设施的新宠。智慧公厕以物联网、互联网、大数据、云计算、5G通信、自动化控制等技术为核心࿰…...

Apache软件基金会的孵化标准和毕业标准
Apache软件基金会的孵化标准和毕业标准是一个项目成功的重要衡量指标。这些标准关注项目的多个方面,包括开放性、合作性、共建性、透明性、技术可行性、社区建设以及用户基础等。在孵化阶段,Apache软件基金会主要关注项目的开放性和合作性。首先…...
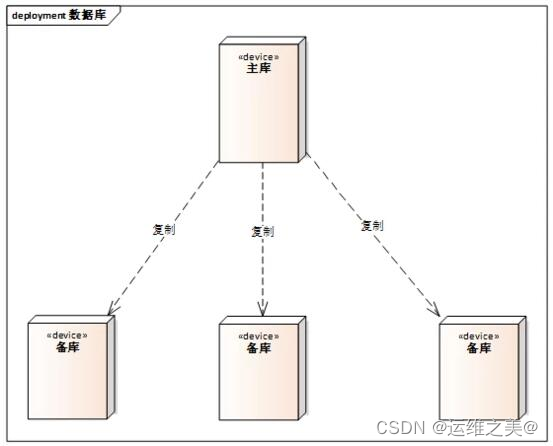
什么是高可用架构
一、什么是高可用 在运维中,经常听到高可用,那么什么是高可用架构呢?通俗点讲,高可用就是在服务故障,节点宕机的情况下,业务能够保证不中断,服务正常运行。 举个例子,支付宝&#…...

【Vuforia+Unity】AR04-地面、桌面平面识别功能(Ground Plane Target)
不论你是否曾有过相关经验,只要跟随本文的步骤,你就可以成功地创建你自己的AR应用。 官方教程Ground Plane in Unity | Vuforia Library 这个功能很棒,但是要求也很不友好,只能支持部分移动设备,具体清单如下: 01.Vuforia的地面识别功能仅支持的设备清单: Recommended…...

【Git】解决‘每次初始化一个新仓库时,都需要执行git config --global --add safe.directory命令‘
问题 这个命令是用来将一个安全目录添加到全局的 Git 配置中。但每次克隆一个仓库或者新建一个仓库,并且对该仓库进行操作时,都需要执行该命令,十分麻烦! 这是因为,Git 近期进行了版本升级,添加了新的目录…...
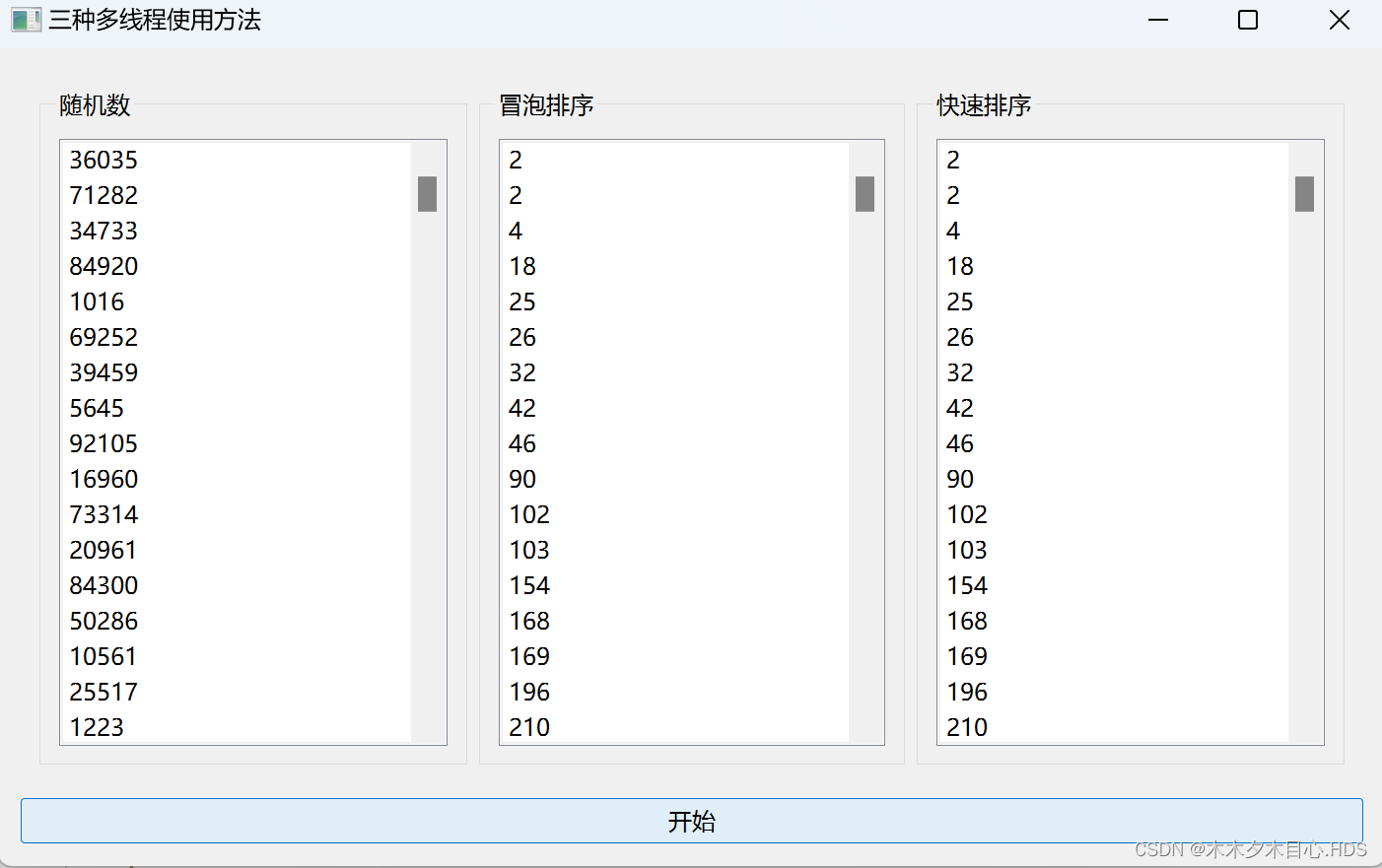
Qt的QThread、QRunnable和QThreadPool的使用
1.相关描述 随机生产1000个数字,然后进行冒泡排序与快速排序。随机生成类继承QThread类、冒泡排序使用moveToThread方法添加到一个线程中、快速排序类继承QRunnable类,添加到线程池中进行排序。 2.相关界面 3.相关代码 widget.cpp #include "widget…...
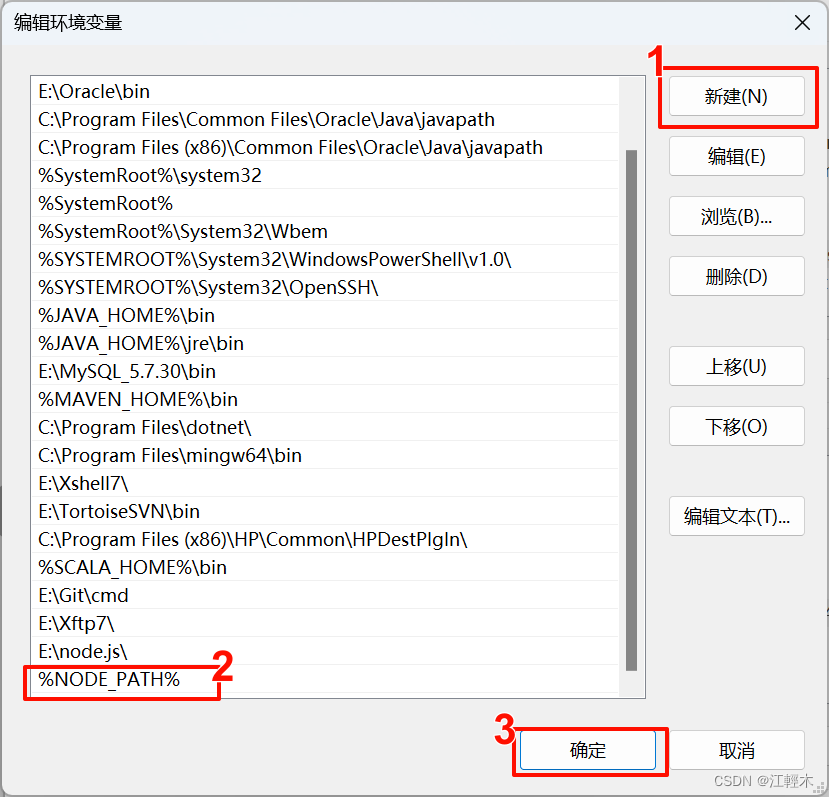
windows安装部署node.js并搭建Vue项目
一、官网下载安装包 官网地址:https://nodejs.org/zh-cn/download/ 二、安装程序 1、安装过程 如果有C/C编程的需求,勾选一下下图所示的部分,没有的话除了选择一下node.js安装路径,直接一路next 2、测试安装是否成功 【winR】…...

【计算机】本科考研还是就业?
其实现在很多计算机专业的学生考研,也是无奈的选择 技术发展日新月异,而在本科阶段,大家学着落后的技术,出来找工作自然会碰壁。而且现在用人单位的门槛越来越高,学历默认研究生起步,面试一般都是三轮起步…...
ChatGPT调教指南 | 咒语指南 | Prompts提示词教程(三)
在人工智能成为我们日常互动中无处不在的一部分的时代,与大型语言模型(llm)有效沟通的能力是无价的。“良好提示的26条原则”为优化与这些复杂系统的交互提供了全面的指导。本指南证明了人类和人工智能之间的微妙关系,强调清晰、专一和结构化的沟通方法。…...
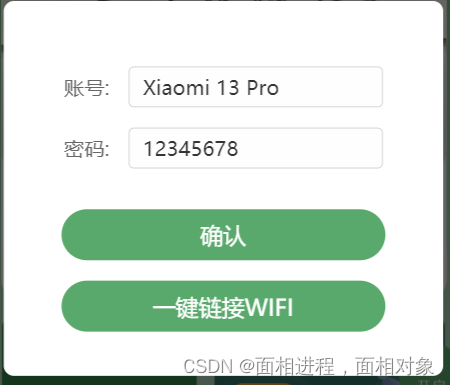
小程序一键链接WIFI
1.小程序一键链接WIFI connectWifi: function() {var that this;//检测手机型号wx.getSystemInfo({success: function(res) {var system ;if (res.platform android) system parseInt(res.system.substr(8));if (res.platform ios) system parseInt(res.system.substr(4…...

结构体位域保存传感器数据
1、原理图分析: 8个74HC4052共用两个选通引脚,8个输入引脚,一共可以检测64个数字红外传感器。74HC4052的功能表如下,nY0表示所有Y0引脚。 S1 S0 Channel on 0 0 nY0 0 1 nY1 1 0 nY2 1 1 nY3 enum sensor_id{HS01 0, HS02, HS03, HS0…...

66-ES6:var,let,const,函数的声明方式,函数参数,剩余函数,延展操作符
1.JavaScript语言的执行流程 编译阶段:构建执行函数;执行阶段:代码依次执行 2.代码块:{ } 3.变量声明方式var 有声明提升,允许重复声明,声明函数级作用域 访问:声明后访问都是正常的&…...
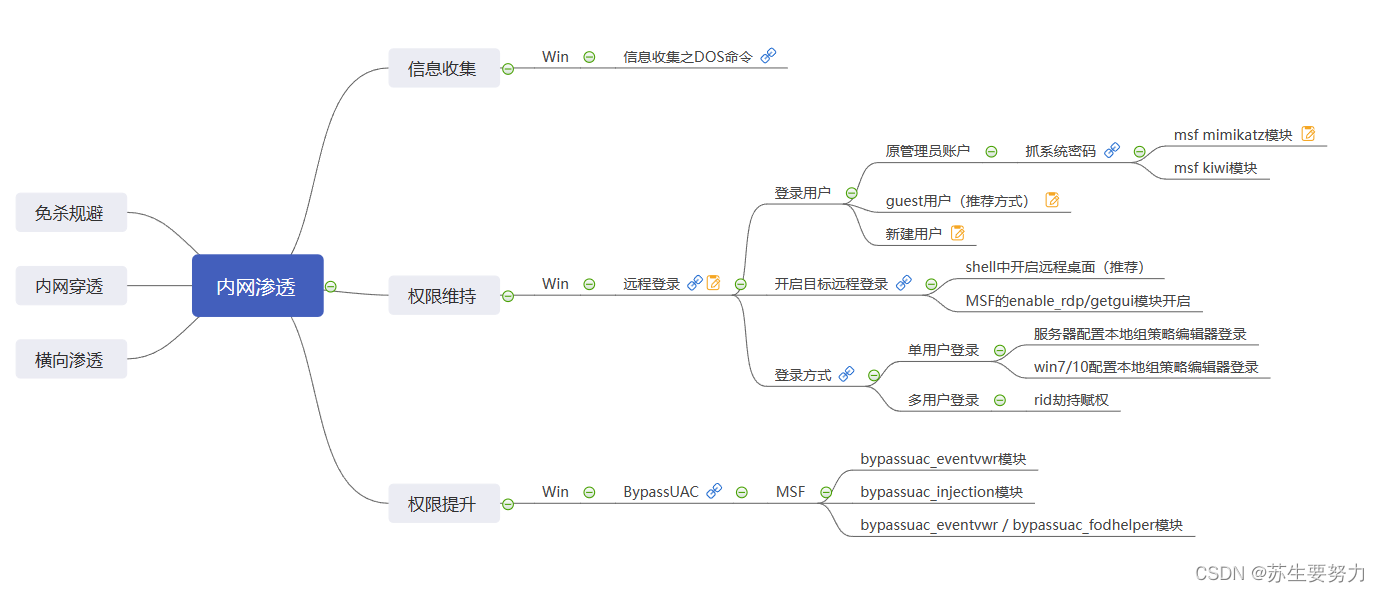
prime_series_level-1靶场详解
环境搭建 官网https://www.vulnhub.com/entry/prime-1,358/ 直接导入靶机 解题思路 arp-scan -l 确认靶机ip为192.168.236.136 也可以使用nmap扫网段 nmap -sn 192.168.236.0/24 使用nmap扫描靶机开放的端口 nmap -sS -T5 --min-rate 10000 192.168.236.136 -sC -p- …...
)
LeetCode刷题笔记之二叉树(三)
一、寻找特定节点 1. 404【左叶子之和】 题目: 给定二叉树的根节点 root ,返回所有左叶子之和。代码: class Solution {public int sumOfLeftLeaves(TreeNode root) {//左叶子不止是最左边的叶子,而是二叉树中每个节点的左叶子…...

IBM在闪存系统集成实时恶意软件I/O检测功能
IBM在其最新一代FlashCore Modules(FCMs)固件中集成了使用机器学习进行实时勒索软件和其他攻击检测的功能。这些FCMs是专用于IBM FlashSystem 5000和Storwize阵列的闪存驱动器,采用U.2外形尺寸及NVMe接口。现有的第三代FCMs分别提供4.8、9.6、…...

Java 转 C++ 系列:STL容器之vector
文章参考: 黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难 STL中的vector容器的一点总结 文章目录一、vector容器简介二、vector和数组的主要区别三、 vecotr容器中的使用3.1 构造函数3.2 vector赋值操作3.3 vector容量和大小3.4 vector插入和删除3.5 vect…...

Android Profiler 内存分析实战:从卡顿溯源到泄漏定位
1. Android Profiler内存分析器入门指南 第一次打开Android Studio的Profiler面板时,很多开发者都会被那些跳动的曲线和复杂的数据搞得一头雾水。记得我刚接触内存分析时,盯着那些上上下下的折线图看了半天,完全不知道从何下手。其实Android …...

LinkSwift:8大网盘直链解析工具的技术实现与用户体验革命
LinkSwift:8大网盘直链解析工具的技术实现与用户体验革命 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

GitHub Profile优化:软件测试工程师的吸引力法则与专业品牌构建
在数字化浪潮席卷全球的今天,GitHub早已超越了其作为代码托管平台的最初定位,演变为技术从业者展示专业能力、构建行业影响力的核心舞台。对于软件测试工程师而言,一个精心优化、内容充实的GitHub Profile不仅是技术实力的“数字自白书”&…...

实战指南:如何在Linux驱动开发中正确使用queue_work函数
实战指南:如何在Linux驱动开发中正确使用queue_work函数 在Linux内核开发中,异步任务处理是驱动工程师必须掌握的技能之一。想象一下,当你正在开发一个需要响应硬件中断的驱动程序,同时又不想让中断处理程序(ISR&#…...

终极指南:如何一键检测微信单向好友关系
终极指南:如何一键检测微信单向好友关系 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾怀疑…...
)
从CVE-2021-4034到CVE-2021-3156:手把手复现Linux两大本地提权漏洞(附修复方案)
从CVE-2021-4034到CVE-2021-3156:Linux本地提权漏洞深度实战指南 凌晨三点,安全团队的告警系统突然亮起红灯——又一台服务器被标记存在高危漏洞。作为运维负责人,你必须在最短时间内判断风险等级、验证漏洞真实性并制定修复方案。本文将带你…...

AI编程革命:Codex自动写脚本实战指南
告别重复造轮子:Codex写脚本的技术文章大纲理解Codex的基本能力Codex是基于GPT-3的AI模型,能够将自然语言转换为代码。 支持多种编程语言,包括Python、JavaScript、Go等。 适用于自动化脚本、数据处理、API调用等场景。识别适合自动化的重复任…...
)
齿轮箱零部件及其装配质检中的TVA技术突破(21)
前沿技术背景介绍:AI 智能体视觉检测系统(Transformer-based Vision Agent,缩写:TVA),是依托 Transformer 架构与“因式智能体”范式所构建的高精度智能体。它区别于传统机器视觉与早期 AI 视觉,…...

新的契约:人机协作的设计原则
一开始我觉得这个概念有点抽象,但读完后发现,它其实回答的是一个很现实的问题: 当 AI 不只是回答问题,而是开始自己规划、执行任务时,人和 AI 应该怎么分工? 这篇文章,我想从初学者角度&#…...