中文文本分类(pytorch 实现)
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)train.csv 链接:https://pan.baidu.com/s/1Vnyvo5T5eSuzb0VwTsznqA?pwd=fqok 提取码:fqok import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])1.构建词典:
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text, in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])调用vocab(词汇表)对一个中文句子进行索引转换,这个句子被分词后得到的词汇列表会被转换成它们在词汇表中的索引。
print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))
生成一个标签列表,用于查看在数据集中所有可能的标签类型。
label_name = list(set(train_data[1].values[:]))
print(label_name)创建了两个lambda函数,一个用于将文本转换成词汇索引,另一个用于将标签文本转换成它们在label_name列表中的索引。
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))2.生成数据批次和迭代器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)collate_batch函数用于处理数据加载器中的批次。它接收一个批次的数据,处理它,并返回适合模型训练的数据格式。
在这个函数内部,它遍历批次中的每个文本和标签对,将标签添加到label_list,将文本通过text_pipeline函数处理后转换为tensor,并添加到text_list。
offsets列表用于存储每个文本的长度,这对于后续的文本处理非常有用,尤其是当你需要知道每个文本在拼接的大tensor中的起始位置时。
text_list用torch.cat进行拼接,形成一个连续的tensor。
offsets列表的最后一个元素不包括,然后使用cumsum函数在第0维计算累积和,这为每个序列提供了一个累计的偏移量。
3.搭建模型与初始化
from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)num_class = len(label_name) # 类别数,根据label_name的长度确定
vocab_size = len(vocab) # 词汇表的大小,根据vocab的长度确定
em_size = 64 # 嵌入向量的维度设置为64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device) # 创建模型实例并移动到计算设备4.模型训练及评估函数
train 和 evaluate分别用于训练和评估文本分类模型。
训练函数 train 的工作流程如下:
将模型设置为训练模式。
初始化总准确率、训练损失和总计数变量。
记录训练开始的时间。
遍历数据加载器,对每个批次:
进行预测。
清零优化器的梯度。
计算损失(使用一个损失函数,例如交叉熵)。
反向传播计算梯度。
通过梯度裁剪防止梯度爆炸。
执行一步优化器更新模型权重。
更新总准确率和总损失。
每隔一定间隔,打印训练进度和统计信息。
评估函数 evaluate 的工作流程如下:
将模型设置为评估模式。
初始化总准确率和总损失。
不计算梯度(为了节省内存和计算资源)。
遍历数据加载器,对每个批次:
进行预测。
计算损失。
更新总准确率和总损失。
返回整体的准确率和平均损失。
代码实现:
import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_count5.模型训练
设置训练的轮数、学习率和批次大小。
定义交叉熵损失函数、随机梯度下降优化器和学习率调度器。
将训练数据转换为一个map样式的数据集,并将其分成训练集和验证集。
创建训练和验证的数据加载器。
开始训练循环,每个epoch都会训练模型并在验证集上评估模型的准确率和损失。
如果验证准确率没有提高,则按计划降低学习率。
打印每个epoch结束时的统计信息,包括时间、准确率、损失和学习率。
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)运行结果:
| epoch 1 | 50/ 152 batches | accuracy 0.423 | loss 0.03079
| epoch 1 | 100/ 152 batches | accuracy 0.700 | loss 0.01912
| epoch 1 | 150/ 152 batches | accuracy 0.776 | loss 0.01347
---------------------------------------------------------------------
| end of epoch 1 | time: 1.53s | valid accuracy 0.777 | valid loss 2420.000 | lr 5.000000
| epoch 2 | 50/ 152 batches | accuracy 0.812 | loss 0.01056
| epoch 2 | 100/ 152 batches | accuracy 0.843 | loss 0.00871
| epoch 2 | 150/ 152 batches | accuracy 0.844 | loss 0.00846
---------------------------------------------------------------------
| end of epoch 2 | time: 1.45s | valid accuracy 0.842 | valid loss 2420.000 | lr 5.000000
| epoch 3 | 50/ 152 batches | accuracy 0.883 | loss 0.00653
| epoch 3 | 100/ 152 batches | accuracy 0.879 | loss 0.00634
| epoch 3 | 150/ 152 batches | accuracy 0.883 | loss 0.00627
---------------------------------------------------------------------
| end of epoch 3 | time: 1.44s | valid accuracy 0.865 | valid loss 2420.000 | lr 5.000000
| epoch 4 | 50/ 152 batches | accuracy 0.912 | loss 0.00498
| epoch 4 | 100/ 152 batches | accuracy 0.906 | loss 0.00495
| epoch 4 | 150/ 152 batches | accuracy 0.915 | loss 0.00461
---------------------------------------------------------------------
| end of epoch 4 | time: 1.50s | valid accuracy 0.876 | valid loss 2420.000 | lr 5.000000
| epoch 5 | 50/ 152 batches | accuracy 0.935 | loss 0.00386
| epoch 5 | 100/ 152 batches | accuracy 0.934 | loss 0.00390
| epoch 5 | 150/ 152 batches | accuracy 0.932 | loss 0.00362
---------------------------------------------------------------------
| end of epoch 5 | time: 1.59s | valid accuracy 0.881 | valid loss 2420.000 | lr 5.000000
| epoch 6 | 50/ 152 batches | accuracy 0.947 | loss 0.00313
| epoch 6 | 100/ 152 batches | accuracy 0.949 | loss 0.00307
| epoch 6 | 150/ 152 batches | accuracy 0.949 | loss 0.00286
---------------------------------------------------------------------
| end of epoch 6 | time: 1.68s | valid accuracy 0.891 | valid loss 2420.000 | lr 5.000000
| epoch 7 | 50/ 152 batches | accuracy 0.960 | loss 0.00243
| epoch 7 | 100/ 152 batches | accuracy 0.963 | loss 0.00224
| epoch 7 | 150/ 152 batches | accuracy 0.959 | loss 0.00252
---------------------------------------------------------------------
| end of epoch 7 | time: 1.53s | valid accuracy 0.892 | valid loss 2420.000 | lr 5.000000
| epoch 8 | 50/ 152 batches | accuracy 0.972 | loss 0.00186
| epoch 8 | 100/ 152 batches | accuracy 0.974 | loss 0.00184
| epoch 8 | 150/ 152 batches | accuracy 0.967 | loss 0.00201
---------------------------------------------------------------------
| end of epoch 8 | time: 1.43s | valid accuracy 0.895 | valid loss 2420.000 | lr 5.000000
| epoch 9 | 50/ 152 batches | accuracy 0.981 | loss 0.00138
| epoch 9 | 100/ 152 batches | accuracy 0.977 | loss 0.00165
| epoch 9 | 150/ 152 batches | accuracy 0.980 | loss 0.00147
---------------------------------------------------------------------
| end of epoch 9 | time: 1.48s | valid accuracy 0.900 | valid loss 2420.000 | lr 5.000000
| epoch 10 | 50/ 152 batches | accuracy 0.987 | loss 0.00117
| epoch 10 | 100/ 152 batches | accuracy 0.985 | loss 0.00121
| epoch 10 | 150/ 152 batches | accuracy 0.984 | loss 0.00121
---------------------------------------------------------------------
| end of epoch 10 | time: 1.45s | valid accuracy 0.902 | valid loss 2420.000 | lr 5.000000
---------------------------------------------------------------------6.模型评估
test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))7.模型测试
def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])8.全部代码(部分修改):
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])9.代码改进及优化
9.1优化器: 尝试不同的优化算法,如Adam、RMSprop替换原来的SGD优化器部分
9.1.1使用Adam优化器:
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=LR)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])相关文章:
)
中文文本分类(pytorch 实现)
import torch import torch.nn as nn import torchvision from torchvision import transforms, datasets import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统 device torch.device("cuda" if torch.cuda.i…...

【每日前端面经】2023-02-27
题目来源: 牛客 CSS盒模型 CSS中的盒子包括margin|border|padding|content四个部分,对于标准盒子模型(content-box)的widthcontent,但是对于IE盒子模型(border-box)的widthcontentborder2padding2 CSS选…...

springboot + easyRules 搭建规则引擎服务
依赖 <dependency><groupId>org.jeasy</groupId><artifactId>easy-rules-core</artifactId><version>4.0.0</version></dependency><dependency><groupId>org.jeasy</groupId><artifactId>easy-rules…...

Mac电脑配置环境变量
1.打开配置文件bash_profile open -e .bash_profile 2.如果没有创建过.bash_profile,则先需要创建 touch .bash_profile 3.输入你要配置的环境变量 #Setting PATH for Android ADB Tools export ANDROID_HOME/Users/xxx/android export PATH${PATH}:${ANDROID_HOME}…...
Windows系统x86机器安装(麒麟、统信)ARM系统详细教程
本次介绍在window系统x86机器上安装国产系统 arm 系统的详细教程。 注:ubuntu 的arm系统安装是一样的流程。 1.安装环境准备。 首先,你得有台电脑,配置别太差,至少4核8G内存,安装window10或者11都行(为啥…...

消息中间件篇之RabbitMQ-高可用机制
一、怎么保证高可用性 在生产环境下,使用集群来保证高可用性,一般我们采用普通集群、镜像集群、仲裁队列。 二、普通集群 普通集群,或者叫标准集群(classic cluster),具备下列特征: 1. 会在集…...
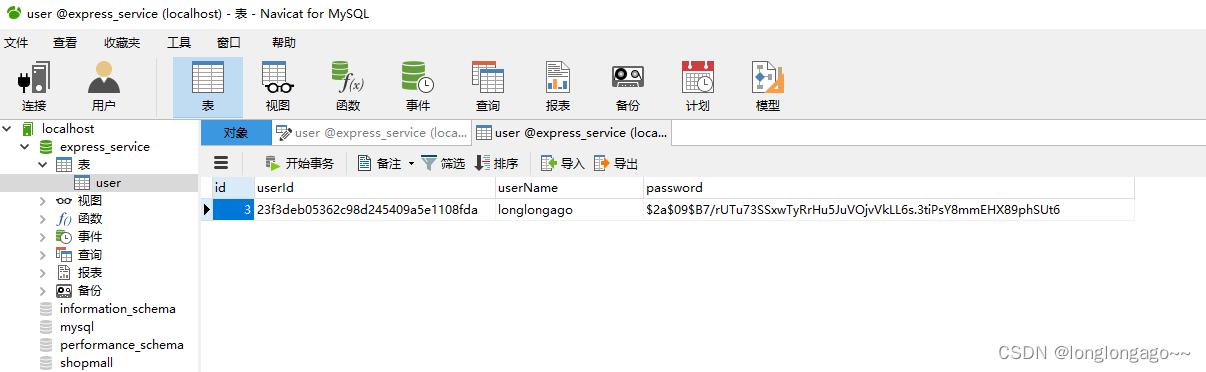
express+mysql+vue,从零搭建一个商城管理系统5--用户注册
提示:学习express,搭建管理系统 文章目录 前言一、新建user表二、安装bcryptjs、MD5、body-parser三、修改config/db.js四、新建config/bcrypt.js五、新建models文件夹和models/user.js五、index.js引入使用body-parser六、修改routes/user.js七、启动项…...

canvas水波纹效果,jquery鼠标水波纹插件
canvas水波纹效果,jquery鼠标水波纹插件 效果展示 jQuery水波纹效果,canvas水波纹插件 HTML代码片段 <div class"scroll04wrap"><h3>发展历程</h3><div class"scroll04"><p>不要回头,一…...

Zookeeper客户端命令、JAVA API、监听原理、写数据原理以及案例
1. Zookeeper节点信息 指定服务端,启动客户端命令: bin/zkCli.sh -server 服务端主机名:端口号 1)ls / 查看根节点下面的子节点 ls -s / 查看根节点下面的子节点以及根节点详细信息 其中,cZxid是创建节点的事务id,…...
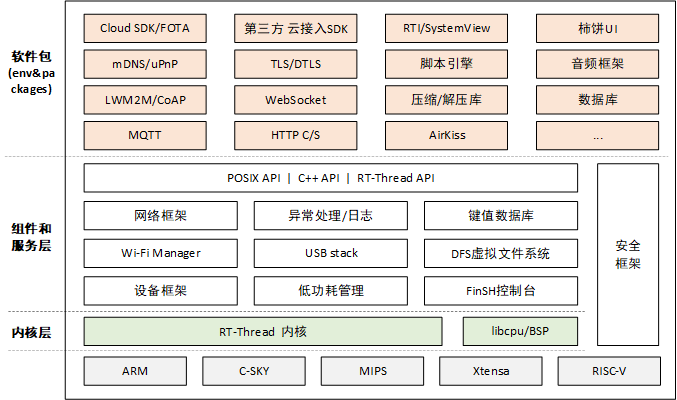
[嵌入式系统-34]:RT-Thread -19- 新手指南:RT-Thread标准版系统架构
目录 一、RT-Thread 简介 二、RT-Thread 概述 三、许可协议 四、RT-Thread 的架构 4.1 内核层: 4.2 组件与服务层: 4.3 RT-Thread 软件包: 一、RT-Thread 简介 作为一名 RTOS 的初学者,也许你对 RT-Thread 还比较陌生。然…...
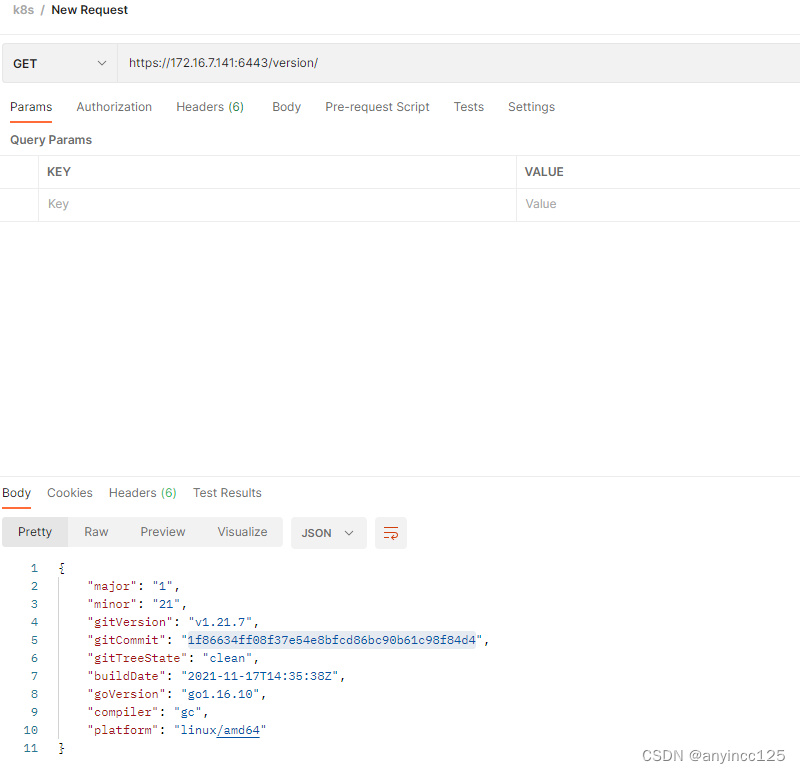
postman访问k8s api
第一种方式: kubectl -n kubesphere-system get sa kubesphere -oyaml apiVersion: v1 kind: ServiceAccount metadata:annotations:meta.helm.sh/release-name: ks-coremeta.helm.sh/release-namespace: kubesphere-systemcreationTimestamp: "2023-07-24T07…...
UE4c++ ConvertActorsToStaticMesh
UE4c ConvertActorsToStaticMesh ConvertActorsToStaticMesh UE4c ConvertActorsToStaticMesh创建Edior模块(最好是放Editor模块毕竟是编辑器代码)创建UBlueprintFunctionLibraryUTestFunctionLibrary.hUTestFunctionLibrary.cpp:.Build.cs 目标:为了大量…...
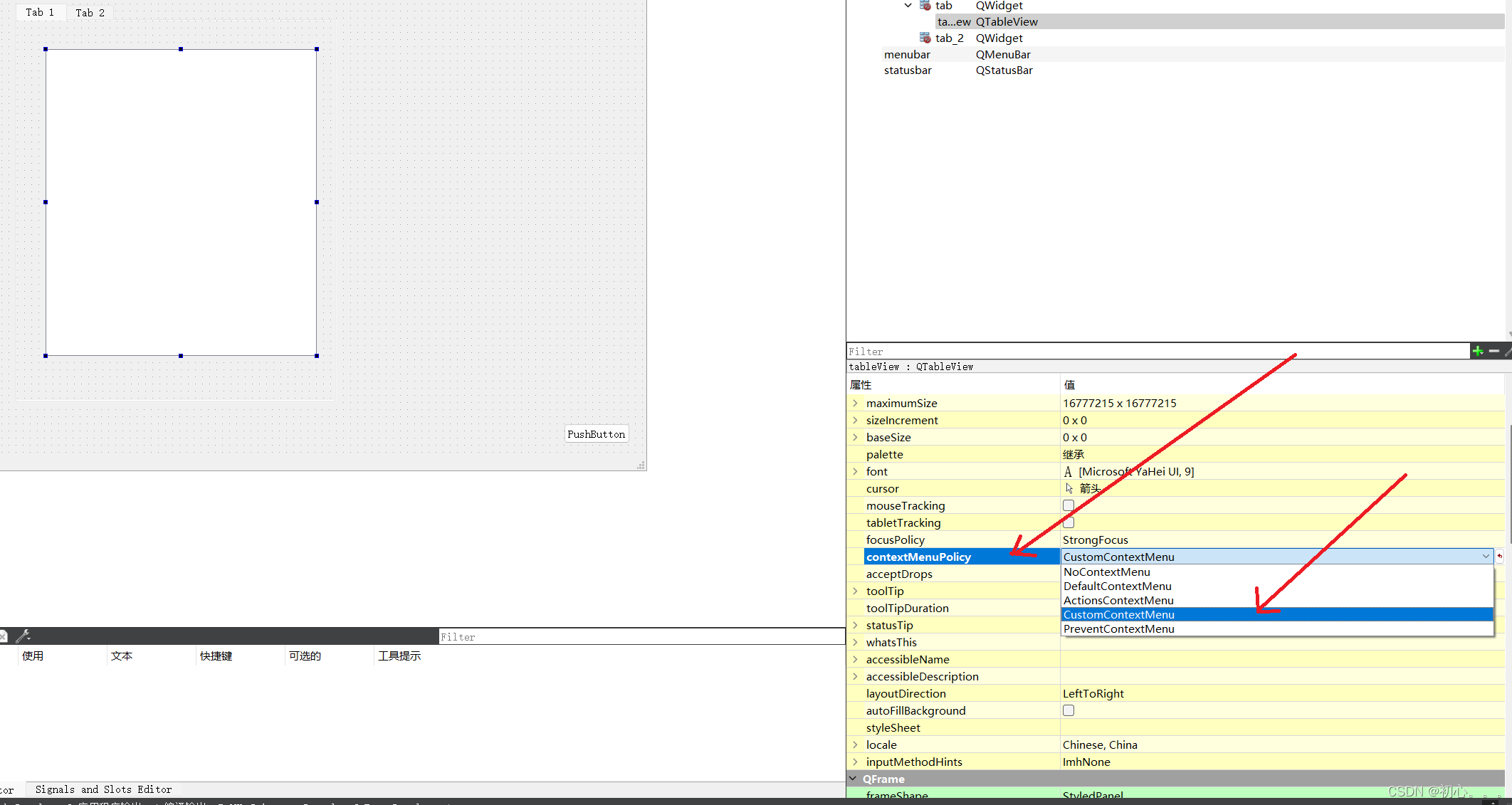
Qt中tableView控件的使用
tableView使用注意事项 tableView在使用时,从工具栏拖动到底层页面后,右键进行选择如下图所示: 此处需要注意的是,需要去修改属性,从UI上修改属性如下所示: 也可以通过代码修改属性: //将其设…...

【医学影像】LIDC-IDRI数据集的无痛制作
LIDC-IDRI数据集制作 0.下载0.0 链接汇总0.1 步骤 1.合成CT图reference 0.下载 0.0 链接汇总 LIDC-IDRI官方网址:https://www.cancerimagingarchive.net/nbia-search/?CollectionCriteriaLIDC-IDRINBIA Data Retriever 下载链接:https://wiki.canceri…...

MacOS开发环境搭建详解
搭建MacOS开发环境需要准备相应的软硬件,并遵循一系列步骤。以下是详细的步骤: 软硬件准备: MacOS电脑:确保你的电脑运行的是MacOS操作系统。Xcode软件:打开AppStore,搜索并安装Xcode。安装过程可能较长&…...

全量知识系统问题及SmartChat给出的答复 之2
Q6. 根据DDD的思想( 也就是借助 DDD的某个或某些实现),是否能按照这个想法给出程序设计和代码结构? 当使用领域驱动设计(DDD)的思想来设计程序和代码结构时,可以根据领域模型、领域服务、值对象、实体等概念来进行设计…...

嵌入式驱动学习第一周——vim的使用
前言 本篇博客学习使用vim,vim作为linux下的编辑器,学linux肯定是绕不开vim的,因为不确定对方环境中是否安装了编译器,但一定会有vim。 对于基本的使用只需要会打开文件,保存文件,编辑文件即可。 嵌入式驱动…...

loop_list单向循环列表
#include "loop_list.h" //创建单向循环链表 loop_p create_head() { loop_p L(loop_p)malloc(sizeof(loop_list)); if(LNULL) { printf("create fail\n"); return NULL; } L->len 0; L->nextL; retur…...

Python爬虫实战第二例【二】
零.前言: 本文章借鉴:Python爬虫实战(五):根据关键字爬取某度图片批量下载到本地(附上完整源码)_python爬虫下载图片-CSDN博客 大佬的文章里面有API的获取,在这里我就不赘述了。 一…...
Eclipse是如何创建web project项目的?
前面几篇描述先后描述了tomcat的目录结构和访问机制,以及Eclipse的项目类型和怎么调用jar包,还有java的main函数等,这些是一些基础问题,基础高清出来才更容易搞清楚后面要说的东西,也就是需求带动学习,后面…...

5G手机信号突然变差?可能是RRC连接释放的锅,附排查思路
5G手机信号突然变差?可能是RRC连接释放的锅,附排查思路 你是否遇到过这样的场景:手机明明显示5G信号满格,但刷视频却频繁缓冲,游戏延迟飙升,甚至微信消息都发不出去?这种"假信号"问题…...

别再只盯着压差了!手把手教你从PSRR、噪声到环路补偿,全面评估一颗LDO芯片
从PSRR到环路稳定性:LDO芯片的深度评估指南 在电子系统设计中,低压差稳压器(LDO)的选择往往被简化为"压差越低越好"的单一标准。这种认知偏差导致许多工程师在电源设计上踩坑——噪声干扰、系统振荡、效率低下等问题频发。本文将打破常规认知框…...
)
保姆级教程:在Fedora/CentOS上用QEMU-KVM跑起ARM64虚拟机(附Debian镜像下载)
在Fedora/CentOS上构建高性能ARM64虚拟化环境的完整指南 对于需要在x86架构上开发和测试ARM64应用的工程师来说,搭建一个稳定高效的虚拟化环境是刚需。本文将带你从零开始,在Fedora或CentOS系统上配置完整的QEMU-KVM虚拟化栈,并针对ARM64架构…...
)
从随机数据到平滑曲线:用PCHIP算法在MATLAB中玩转数据插值(保姆级教程)
从随机数据到平滑曲线:用PCHIP算法在MATLAB中玩转数据插值(保姆级教程) 刚接触数据分析时,最让人头疼的莫过于拿到一组杂乱无章的实验数据,却要呈现出一条专业、平滑的曲线。记得我第一次处理传感器采集的振动数据时&a…...

020、多模态大模型微调:图文对齐与跨模态任务实战
020、多模态大模型微调:图文对齐与跨模态任务实战 昨天深夜调试一个跨模态检索任务,模型总是把“沙滩排球”的图片匹配到“羽毛球”的文本描述上。查看中间层激活值才发现,视觉编码器把沙滩的黄色特征提取得太强,完全盖过了排球本身的特征。这个坑让我重新思考多模态对齐的…...

Axure RP中文界面终极配置指南:3分钟实现专业汉化
Axure RP中文界面终极配置指南:3分钟实现专业汉化 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的英…...

Maxwell Simplorer Simulink 永磁同步电机矢量控制联合仿真
maxwell simplorer simulink 永磁同步电机矢量控制联合仿真,电机为分数槽绕组,使用pi控制SVPWM调制,修改文件路径后可使用,软件版本matlab 2017b, Maxwell electronics 2021b 共包含两个文件, Maxwell和Simplorer联合仿…...

告别蓝牙信标:用ESP32-S2的WiFi FTM功能,低成本实现米级精度室内定位原型
告别蓝牙信标:用ESP32-S2的WiFi FTM功能,低成本实现米级精度室内定位原型 在智能仓储、商场导航和工业自动化等场景中,室内定位技术正成为基础设施的关键部分。传统方案如蓝牙信标或UWB虽然成熟,但面临着硬件成本高、部署复杂和生…...

终极指南:如何用Meshroom开源工具将普通照片变成专业3D模型
终极指南:如何用Meshroom开源工具将普通照片变成专业3D模型 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 想将手机照片一键变成可旋转、可触摸的3D模型吗?Ƕ…...

别再手动敲AT指令了!用STM32CubeMX HAL库驱动ESP8266连接OneNET的保姆级教程
STM32CubeMX与HAL库驱动ESP8266连接OneNET的工程化实践 在物联网设备开发中,WiFi模块的集成往往是项目成败的关键节点。传统基于AT指令的手动调试方式不仅效率低下,还容易引入人为错误。本文将展示如何利用STM32CubeMX生成的HAL库代码,构建一…...