强化学习_06_pytorch-PPO实践(Hopper-v4)
一、PPO优化
PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1)
针对之前的PPO做了主要以下优化:
batch_normalize: 在mini_batch函数中进行adv的normalize, 加速模型对adv的学习policyNet采用beta分布(0~1): 同时增加MaxMinScale 将beta分布产出值转换到action的分布空间- 收集多个
episode的数据,依次计算adv,后合并到一个dataloader中进行遍历:加速模型收敛
1.1 PPO2 代码
详细可见 Github: PPO2.py
class PPO2:"""PPO2算法, 采用截断方式"""def __init__(self,state_dim: int,actor_hidden_layers_dim: typ.List,critic_hidden_layers_dim: typ.List,action_dim: int,actor_lr: float,critic_lr: float,gamma: float,PPO_kwargs: typ.Dict,device: torch.device,reward_func: typ.Optional[typ.Callable]=None):dist_type = PPO_kwargs.get('dist_type', 'beta')self.dist_type = dist_typeself.actor = policyNet(state_dim, actor_hidden_layers_dim, action_dim, dist_type=dist_type).to(device)self.critic = valueNet(state_dim, critic_hidden_layers_dim).to(device)self.actor_lr = actor_lrself.critic_lr = critic_lrself.actor_opt = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_opt = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gammaself.lmbda = PPO_kwargs['lmbda']self.k_epochs = PPO_kwargs['k_epochs'] # 一条序列的数据用来训练的轮次self.eps = PPO_kwargs['eps'] # PPO中截断范围的参数self.sgd_batch_size = PPO_kwargs.get('sgd_batch_size', 512)self.minibatch_size = PPO_kwargs.get('minibatch_size', 128)self.action_bound = PPO_kwargs.get('action_bound', 1.0)self.action_low = -1 * self.action_bound self.action_high = self.action_boundif 'action_space' in PPO_kwargs:self.action_low = self.action_space.lowself.action_high = self.action_space.highself.count = 0 self.device = deviceself.reward_func = reward_funcself.min_batch_collate_func = partial(mini_batch, mini_batch_size=self.minibatch_size)def _action_fix(self, act):if self.dist_type == 'beta':# beta 0-1 -> low ~ highreturn act * (self.action_high - self.action_low) + self.action_lowreturn act def _action_return(self, act):if self.dist_type == 'beta':# low ~ high -> 0-1 act_out = (act - self.action_low) / (self.action_high - self.action_low)return act_out * 1 + 0return act def policy(self, state):state = torch.FloatTensor(np.array([state])).to(self.device)action_dist = self.actor.get_dist(state, self.action_bound)action = action_dist.sample()action = self._action_fix(action)return action.cpu().detach().numpy()[0]def _one_deque_pp(self, samples: deque):state, action, reward, next_state, done = zip(*samples)state = torch.FloatTensor(np.stack(state)).to(self.device)action = torch.FloatTensor(np.stack(action)).to(self.device)reward = torch.tensor(np.stack(reward)).view(-1, 1).to(self.device)if self.reward_func is not None:reward = self.reward_func(reward)next_state = torch.FloatTensor(np.stack(next_state)).to(self.device)done = torch.FloatTensor(np.stack(done)).view(-1, 1).to(self.device)old_v = self.critic(state)td_target = reward + self.gamma * self.critic(next_state) * (1 - done)td_delta = td_target - old_vadvantage = compute_advantage(self.gamma, self.lmbda, td_delta, done).to(self.device)# recomputetd_target = advantage + old_vaction_dists = self.actor.get_dist(state, self.action_bound)old_log_probs = action_dists.log_prob(self._action_return(action))return state, action, old_log_probs, advantage, td_targetdef data_prepare(self, samples_list: List[deque]):state_pt_list = []action_pt_list = []old_log_probs_pt_list = []advantage_pt_list = []td_target_pt_list = []for sample in samples_list:state_i, action_i, old_log_probs_i, advantage_i, td_target_i = self._one_deque_pp(sample)state_pt_list.append(state_i)action_pt_list.append(action_i)old_log_probs_pt_list.append(old_log_probs_i)advantage_pt_list.append(advantage_i)td_target_pt_list.append(td_target_i)state = torch.concat(state_pt_list) action = torch.concat(action_pt_list) old_log_probs = torch.concat(old_log_probs_pt_list) advantage = torch.concat(advantage_pt_list) td_target = torch.concat(td_target_pt_list)return state, action, old_log_probs, advantage, td_targetdef update(self, samples_list: List[deque]):state, action, old_log_probs, advantage, td_target = self.data_prepare(samples_list)if len(old_log_probs.shape) == 2:old_log_probs = old_log_probs.sum(dim=1)d_set = memDataset(state, action, old_log_probs, advantage, td_target)train_loader = DataLoader(d_set,batch_size=self.sgd_batch_size,shuffle=True,drop_last=True,collate_fn=self.min_batch_collate_func)for _ in range(self.k_epochs):for state_, action_, old_log_prob, adv, td_v in train_loader:action_dists = self.actor.get_dist(state_, self.action_bound)log_prob = action_dists.log_prob(self._action_return(action_))if len(log_prob.shape) == 2:log_prob = log_prob.sum(dim=1)# e(log(a/b))ratio = torch.exp(log_prob - old_log_prob.detach())surr1 = ratio * advsurr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advactor_loss = torch.mean(-torch.min(surr1, surr2)).float()critic_loss = torch.mean(F.mse_loss(self.critic(state_).float(), td_v.detach().float())).float()self.actor_opt.zero_grad()self.critic_opt.zero_grad()actor_loss.backward()critic_loss.backward()torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5) torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5) self.actor_opt.step()self.critic_opt.step()return Truedef save_model(self, file_path):if not os.path.exists(file_path):os.makedirs(file_path)act_f = os.path.join(file_path, 'PPO_actor.ckpt')critic_f = os.path.join(file_path, 'PPO_critic.ckpt')torch.save(self.actor.state_dict(), act_f)torch.save(self.critic.state_dict(), critic_f)def load_model(self, file_path):act_f = os.path.join(file_path, 'PPO_actor.ckpt')critic_f = os.path.join(file_path, 'PPO_critic.ckpt')self.actor.load_state_dict(torch.load(act_f, map_location='cpu'))self.critic.load_state_dict(torch.load(critic_f, map_location='cpu'))self.actor.to(self.device)self.critic.to(self.device)self.actor_opt = torch.optim.Adam(self.actor.parameters(), lr=self.actor_lr)self.critic_opt = torch.optim.Adam(self.critic.parameters(), lr=self.critic_lr)def train(self):self.training = Trueself.actor.train()self.critic.train()def eval(self):self.training = Falseself.actor.eval()self.critic.eval()
二、 Pytorch实践
2.1 智能体构建与训练
PPO2主要是收集多轮的结果序列进行训练,增加训练轮数,适当降低学习率,稍微增Actor和Critic的网络深度
详细可见 Github: test_ppo.Hopper_v4_ppo2_test
import os
from os.path import dirname
import sys
import gymnasium as gym
import torch
# 笔者的github-RL库
from RLAlgo.PPO import PPO
from RLAlgo.PPO2 import PPO2
from RLUtils import train_on_policy, random_play, play, Config, gym_env_descenv_name = 'Hopper-v4'
gym_env_desc(env_name)
print("gym.__version__ = ", gym.__version__ )
path_ = os.path.dirname(__file__)
env = gym.make(env_name, exclude_current_positions_from_observation=True,# healthy_reward=0
)
cfg = Config(env, # 环境参数save_path=os.path.join(path_, "test_models" ,'PPO_Hopper-v4_test2'), seed=42,# 网络参数actor_hidden_layers_dim=[256, 256, 256],critic_hidden_layers_dim=[256, 256, 256],# agent参数actor_lr=1.5e-4,critic_lr=5.5e-4,gamma=0.99,# 训练参数num_episode=12500,off_buffer_size=512,off_minimal_size=510,max_episode_steps=500,PPO_kwargs={'lmbda': 0.9,'eps': 0.25,'k_epochs': 4, 'sgd_batch_size': 128,'minibatch_size': 12, 'actor_bound': 1,'dist_type': 'beta'}
)
agent = PPO2(state_dim=cfg.state_dim,actor_hidden_layers_dim=cfg.actor_hidden_layers_dim,critic_hidden_layers_dim=cfg.critic_hidden_layers_dim,action_dim=cfg.action_dim,actor_lr=cfg.actor_lr,critic_lr=cfg.critic_lr,gamma=cfg.gamma,PPO_kwargs=cfg.PPO_kwargs,device=cfg.device,reward_func=None
)
agent.train()
train_on_policy(env, agent, cfg, wandb_flag=False, train_without_seed=True, test_ep_freq=1000, online_collect_nums=cfg.off_buffer_size,test_episode_count=5)
2.2 训练出的智能体观测
最后将训练的最好的网络拿出来进行观察
agent.load_model(cfg.save_path)
agent.eval()
env_ = gym.make(env_name, exclude_current_positions_from_observation=True,render_mode='human') # , render_mode='human'
play(env_, agent, cfg, episode_count=3, play_without_seed=True, render=True)

相关文章:
强化学习_06_pytorch-PPO实践(Hopper-v4)
一、PPO优化 PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1) 针对之前的PPO做了主要以下优化: batch_normalize: 在mini_batch 函数中进行adv的normalize, 加速模型对adv的学习policyNet采用beta分布(0~1): 同时增加MaxMinScale …...
Scala Intellij编译错误:idea报错xxxx“is already defined as”
今天写scala代码时,Idea报了这样的错误,如下图所示: 一般情况下原因分两种: 第一是我们定义的类或对象重复多次出现,编译器无法确定使用哪个定义。 这通常是由于以下几个原因导致的: 重复定义:在同一个文件…...
面试笔记系列五之MySql+Mybaits基础知识点整理及常见面试题
myibatis执行过程 1读取MyBatis的配置文件。 mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。 2加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中…...

掌握Pillow:Python图像处理的艺术
掌握Pillow:Python图像处理的艺术 引言Python与图像处理的概述Pillow库基础导入Pillow库基本概念图像的打开、保存和显示 图像操作基础图像的剪裁图像的旋转和缩放色彩转换和滤镜应用文字和图形的绘制 高级图像处理图像的合成与蒙版操作像素级操作与图像增强复杂图形…...

React最常用的几个hook
React最常用的几个Hook包括:useState、useEffect、useRef以及useContext。 useState: 用于在函数组件中添加状态管理。它返回一个数组,第一个元素是当前状态的值,第二个元素是更新状态的函数。在使用时,可以通过解构赋…...

自然语言处理Gensim入门:建模与模型保存
文章目录 自然语言处理Gensim入门:建模与模型保存关于gensim基础知识1. 模块导入2. 内部变量定义3. 主函数入口 (if __name__ __main__:)4. 加载语料库映射5. 加载和预处理语料库6. 根据方法参数选择模型训练方式7. 保存模型和变换后的语料8.代码 自然语言处理Gens…...
无法自动打开终端的解决办法)
Windows 10中Visual Studio Code(VSCode)无法自动打开终端的解决办法
1.检查设置: 打开VSCode。点击左侧菜单栏的“文件”(File)。选择“首选项”(Preferences)。点击“设置”(Settings)。在搜索框中输入“shell”,然后点击“settings.json”进行编辑。…...

python dictionary 字典中的内置函数介绍及其示例
Python字典内置方法: 本文介绍了Python字典(dictionary)中的内置函数及其用法示例。字典是Python中非常常用的一种数据结构,它允许我们通过键(key)来快速查找、添加、修改或删除值(value&#…...
pdf转word文档怎么转?分享4种转换方法
pdf转word文档怎么转?在日常工作中,我们经常遇到需要将PDF文件转换为Word文档的情况。无论是为了编辑、修改还是为了重新排版,将PDF转为Word都显得尤为重要。那么,PDF转Word文档怎么转呢?今天,就为大家分享…...
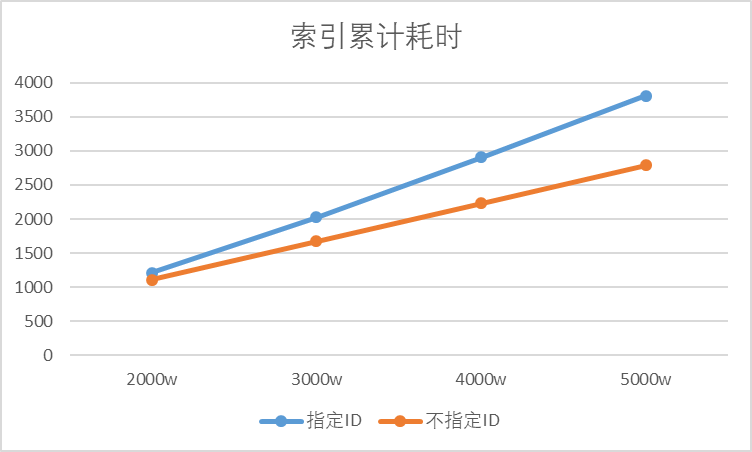
深度测试:指定DoC ID对ES写入性能的影响
在[[使用python批量写入ES索引数据]]中已经介绍了如何批量写入ES数据。基于该流程实际测试一下指定文档ID对ES性能的影响有多大。 一句话版 指定ID比不指定ID的性能下降了63%,且加剧趋势。 以下是测评验证的细节。 百万数据量 索引默认使用1分片和1副本。 指定…...

【JGit】 AddCommand 新增的文件不能添加到暂存区
执行git.add().addFilepattern(".").setUpdate(true).call() 。新增的文件不能添加到暂存区,为什么? 在 JGit 中,setUpdate(true) 方法用于在调用 AddCommand 的 addFilepattern() 方法时,将已跟踪文件标记为需要更新。…...
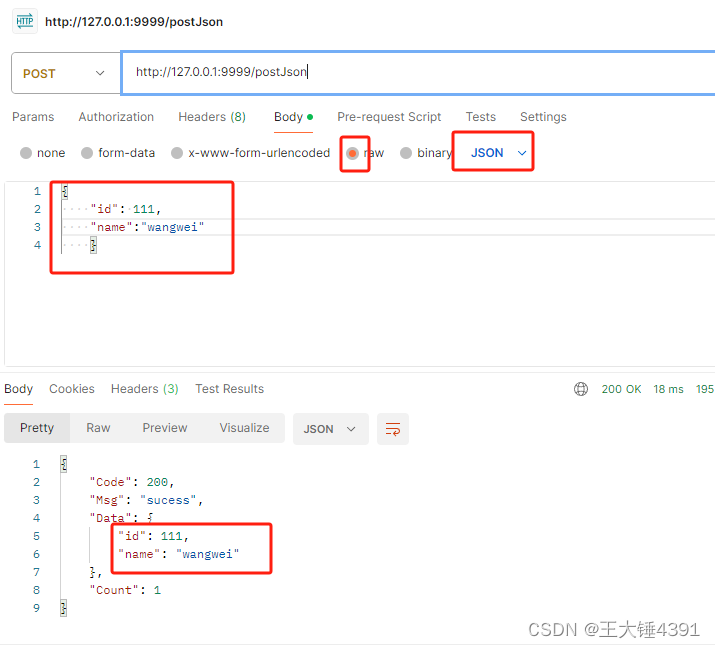
golang学习6,glang的web的restful接口传参
1.get传参 //get请求 返回json 接口传参r.GET("/getJson/:id", controller.GetUserInfo) 1.2.接收处理 package controllerimport "github.com/gin-gonic/gin"func GetUserInfo(c *gin.Context) {_ c.Param("id")ReturnSucess(c, 200, &quo…...

Carla自动驾驶仿真八:两种查找CARLA地图坐标点的方法
文章目录 前言一、通过Spectator获取坐标二、通过道路ID获取坐标总结 前言 CARLA没有直接的方法给使用者查找地图坐标点来生成车辆,这里推荐两种实用的方法在特定的地方生成车辆。 一、通过Spectator获取坐标 1、Spectator(观察者)…...
 | PersistentStorage(持久化存储UI状态))
HarmonyOS | 状态管理(八) | PersistentStorage(持久化存储UI状态)
系列文章目录 1.HarmonyOS | 状态管理(一) | State装饰器 2.HarmonyOS | 状态管理(二) | Prop装饰器 3.HarmonyOS | 状态管理(三) | Link装饰器 4.HarmonyOS | 状态管理(四) | Provide和Consume装饰器 5.HarmonyOS | 状态管理(五) | Observed装饰器和ObjectLink装饰器 6.Harmo…...
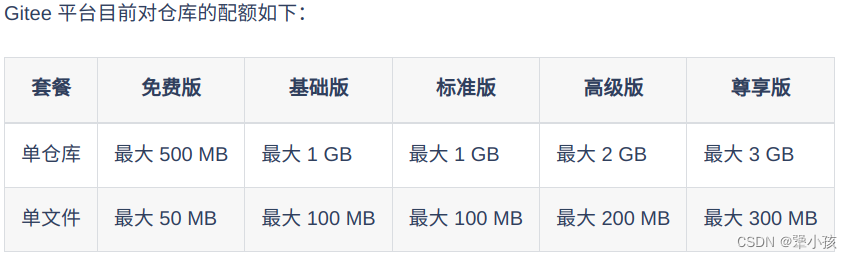
Git 突破 文件尺寸限制
前言 当Git本地存储里右超过50MB,却又确实需要上传的时候,就需要用到了不是 解决 本代码就是把大文件进行拆解成小文件,然后上传。 等到拉取下来的时候,可以直接再进行合并,合并成原文件 代码如下,仅供…...
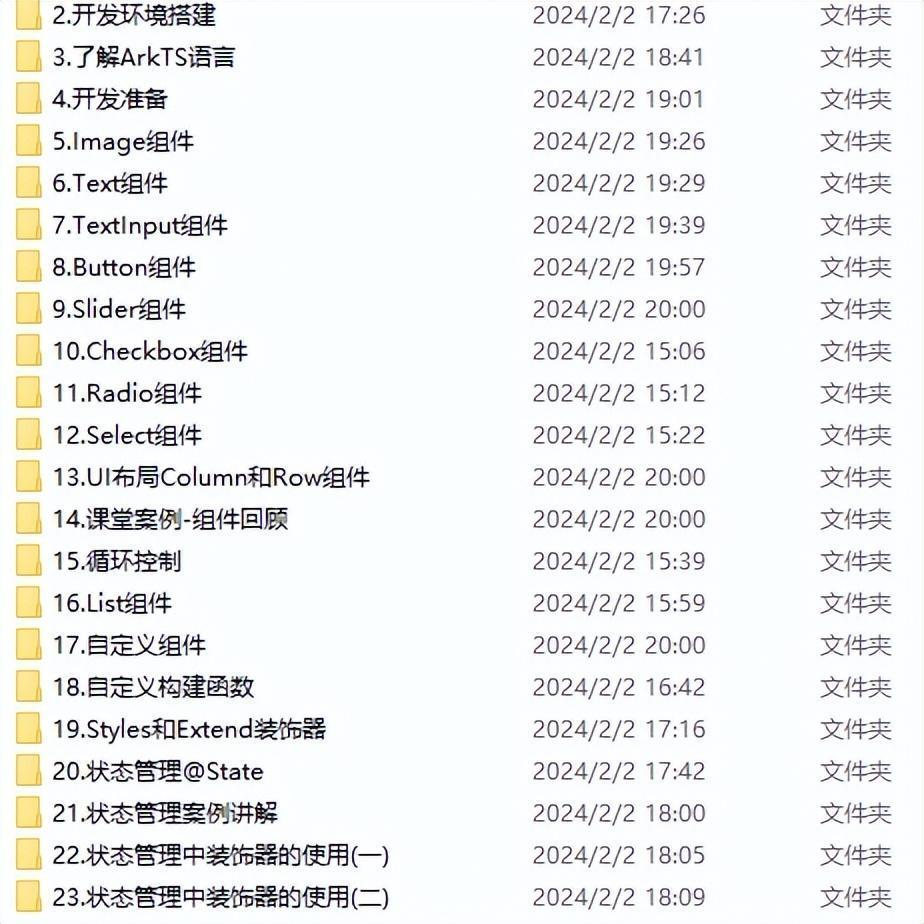
HarmonyOS开发云工程与开发云函数
创建函数 您可直接在DevEco Studio创建函数、编写函数业务代码、为函数配置调用触发器。 1.右击“cloudfunctions”目录,选择“New > Cloud Function”。 2.输入函数名称后,点击“OK”。 函数名称仅支持小写英文字母、数字、中划线(-&a…...
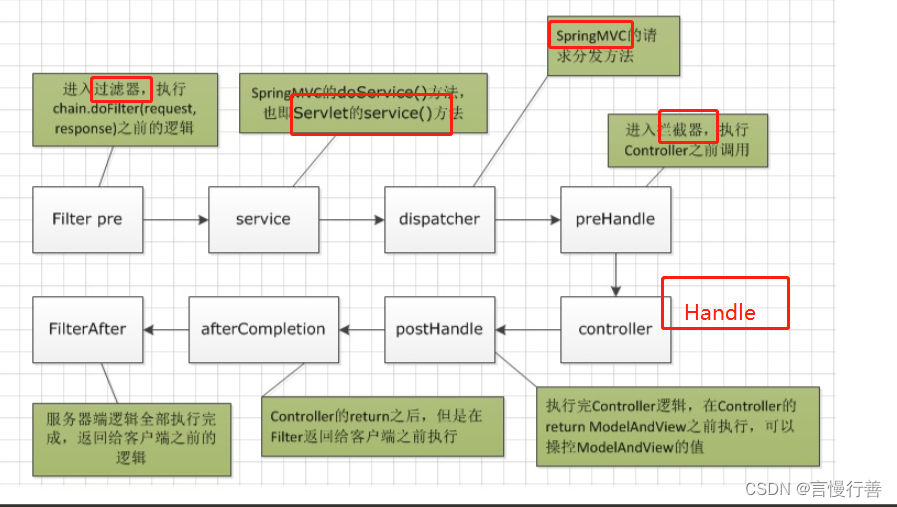
SpringMVC了解
1.springMVC概述 Spring MVC(Model-View-Controller)是基于 Java 的 Web 应用程序框架,用于开发 Web 应用程序。它通过将应用程序分为模型(Model)、视图(View)和控制器(Controller&a…...
路由的懒加载使用 路由的元信息(meta) 路由守卫函数 vant组件库的应用))
day44((VueJS)路由的懒加载使用 路由的元信息(meta) 路由守卫函数 vant组件库的应用)
一.路由懒加载的使用 使用原因 1.使用原因1) 使用一般写法(即直接填写组件的缺点)当使用这种写法,页面在初次加载会将所有路由配置表的添加的组件一次性全部加载,如果项目中组件代码量庞大,就需要很长时间…...
非线性优化资料整理
做课题看了一些非线性优化的资料,整理一下,以方便查看: 优化的中文博客 数值优化|笔记整理(8)——带约束优化:引入,梯度投影法 (附代码)QP求解器对比对于MPC的QP求解器 数值优化| 二次规划的…...

踩坑wow.js 和animate.css一起使用没有效果
踩坑wow.js 和animate.css一起使用没有效果 问题及解决方法一、电脑系统配置问题二、版本问题 问题及解决方法 一、电脑系统配置问题 在系统属性里面把窗口内的动画和元素勾选 二、版本问题 使用wow加animate4.4.1也就是最新本,打开网页没有任何动画效果 但是把…...

PTA天梯赛L2通关秘籍:从链表去重到彩虹瓶,这10道模拟题帮你避开所有坑
PTA天梯赛L2模拟题深度解析:从解题框架到实战技巧 在算法竞赛的世界里,PTA天梯赛作为国内最具影响力的程序设计赛事之一,其L2级别的题目往往成为选手晋级的关键门槛。而其中占比高达70%的模拟类题型,更是检验选手编程基本功和逻辑…...

ncmdump音乐解密工具:三分钟解锁网易云音乐NCM加密文件的终极方案
ncmdump音乐解密工具:三分钟解锁网易云音乐NCM加密文件的终极方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经遇到过这样的烦恼?在网易云音乐下载的歌曲只能在特定客户端播放,无法在…...

烽火HG5143D光猫折腾实录:用Fiddler抓包+U盘拷贝,一步步拿到超级密码
烽火HG5143D光猫深度探索:从抓包分析到权限获取实战指南 家里新装的烽火HG5143D光猫限制太多?想实现桥接模式却找不到入口?作为一名长期折腾家庭网络的技术爱好者,我最近就遇到了这个棘手问题。电信提供的这款光猫默认屏蔽了许多高…...

用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战
用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战 在核技术研究领域,精确模拟探测器响应是实验设计的关键环节。NaI(Tl)闪烁体探测器因其高探测效率和良好的能量分辨率,成为测量伽马射线的首选设备之一。本文将带你完成一个完整的MC…...
)
GitHub 国内访问太慢?2026 最新中国镜像站 + Git 换源指南(亲测有效,速度翻10倍)
🤵♂️ 个人主页:小李同学_LSH的主页 ✍🏻 作者简介:LLM学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

手把手复现AlexNet:用PyTorch 2.0+在单GPU上跑通2012年的‘深度’革命
手把手复现AlexNet:用PyTorch 2.0在单GPU上跑通2012年的‘深度’革命 2012年,AlexNet横空出世,以15.3%的Top-5错误率横扫ImageNet竞赛,将传统方法甩开近10个百分点。这个8层神经网络不仅证明了深度学习的潜力,更开创了…...

Scroll Reverser终极指南:如何为Mac触控板和鼠标分别设置滚动方向
Scroll Reverser终极指南:如何为Mac触控板和鼠标分别设置滚动方向 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在Mac上同时使用触控板和外接鼠标时&…...

零基础搞定PyTorch 2.8+RTX 4090D:开箱即用的深度学习环境配置
零基础搞定PyTorch 2.8RTX 4090D:开箱即用的深度学习环境配置 1. 为什么选择预构建的PyTorch镜像? 想象一下这个场景:你刚拿到一台配置RTX 4090D显卡的高性能服务器,准备开始深度学习项目。按照传统方式,你需要&…...

深入Shader变体:解决Unity CrossSection插件‘Maximum number of shader global keywords exceeded’报错
深入解析Unity Shader变体管理:从CrossSection插件报错到全局/本地关键字优化 当你在Unity项目中整合CrossSection剖切插件时,控制台突然弹出"Maximum number of shader global keywords exceeded"的红色警告,这绝非偶然。这个看似…...

神经网络催生低精度需求,4 位浮点数 FP4 格式大揭秘!
网站导航内容网站提供了多个分类导航,包括数学(涵盖信号处理、微分方程、概率等)、统计(包含专家证词、生物统计学、数据隐私等)、隐私(如 HIPAA、安全港、差分隐私、密码学)、写作(…...