【数仓】基本概念、知识普及、核心技术
一、数仓基本概念
-
数仓的定义:
- 数据仓库(Data Warehouse,简称DW或DWH)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。简言之,它是一个大型存储库,用于存储来自不同源的结构化和非结构化数据,并为分析目的提供数据。
-
数仓的特点:
- 面向主题:数据仓库中的数据是按照一定的主题域进行组织的,这些主题通常与企业的业务过程或分析需求相关。
- 集成性:数据仓库中的数据是从各个不同的数据源中抽取、转换和加载(ETL)而来的,确保数据的一致性和准确性。
- 稳定性:一旦数据进入数据仓库,通常就不会再进行修改或删除,而是作为历史数据被保留,用于分析目的。
- 时变性:数据仓库中的数据会随着时间的推移而发生变化,通常包括添加新数据和更新现有数据。
-
数仓与数据库的区别:
- 目标不同:数据库主要用于事务处理,如记录系统的日常操作;而数据仓库主要用于分析和决策支持。
- 数据组织不同:数据库通常按照应用程序的需求组织数据;数据仓库则按照主题和分析需求组织数据。
- 数据稳定性不同:数据库中的数据经常发生变化,包括增加、删除和修改;而数据仓库中的数据相对稳定,主要用于查询和分析。
-
数仓的架构:
- 数据仓库通常包括多个层次,如数据源层、ETL层、数据仓库层和数据应用层。每个层次都有其特定的功能和作用。
-
数仓的应用:
- 数据仓库广泛应用于企业决策支持系统(DSS)、在线分析处理(OLAP)和数据挖掘等领域。它可以帮助企业更好地了解其业务运营情况,发现潜在的问题和机会,并做出更明智的决策。
-
数仓的发展趋势:
- 随着大数据和人工智能技术的不断发展,数据仓库正在向更智能化、更灵活和更高效的方向发展。例如,实时数据仓库可以处理和分析实时数据流,为企业提供更及时的决策支持。
-
数据建模:
- 数据建模是数仓设计的核心环节,它决定了数据仓库中数据的组织方式。常见的数据建模方法有星型模型(Star Schema)和雪花模型(Snowflake Schema)。了解这些模型的特点和适用场景,有助于设计出高效、易用的数据仓库。
-
数据抽取、转换和加载(ETL):
- ETL是数仓建设中的关键过程,涉及从数据源抽取数据、对数据进行清洗、转换和加载到数据仓库中。了解ETL的原理、工具和技术,以及如何进行性能优化,对于数仓开发至关重要。
-
数据质量管理:
- 数据质量是数仓的生命线。了解如何定义和评估数据质量,以及如何进行数据清洗、校验和标准化,对于确保数仓数据的准确性和一致性非常重要。
-
数据安全与隐私:
- 随着数据泄露和隐私保护意识的提高,数据安全和隐私保护在数仓建设中越来越重要。了解如何对数据进行加密、访问控制、审计和匿名化处理,有助于确保数仓数据的安全性和合规性。
-
元数据管理:
- 元数据是关于数据的数据,描述了数据仓库中数据的结构、来源、含义和关系等信息。了解如何进行元数据收集、存储、查询和维护,有助于更好地管理和利用数仓中的数据。
-
数据仓库的性能优化:
- 数据仓库的性能直接影响到分析查询的速度和效率。了解如何进行数据分区、索引设计、查询优化和并行处理等性能优化技术,对于提高数仓的性能至关重要。
-
数据仓库与数据湖:
- 数据湖是一个相对于数据仓库而言的新概念,它强调数据的原始性和灵活性。了解数据湖的特点、适用场景以及与数据仓库的关系,有助于更全面地理解数据存储和分析的解决方案。
-
实时数据仓库:
- 随着实时分析需求的增加,实时数据仓库逐渐成为关注的焦点。了解实时数据仓库的架构、技术和挑战,有助于满足企业对实时数据分析的需求。
-
数据仓库的维护和升级:
- 数据仓库是一个持续发展的过程,需要定期进行维护和升级。了解如何进行数据备份、恢复、版本控制和迁移等操作,有助于确保数仓的稳定性和可持续性。
二、数仓架构由哪些部分组成?
数仓,即数据仓库(Data Warehouse),是一个大型、集中式的存储和处理数据的系统,通常用于支持企业或组织的决策分析处理。数仓的主要目标是提供决策支持,它整合来自不同业务系统的数据,并进行清洗、转换和加载,以提供一致、准确、及时的数据视图。
数仓通常由以下几个部分组成:
- 数据源层(Source Layer):这是数仓的起点,包括企业内部各个业务系统的数据库、外部数据源(如第三方数据提供商)以及实时数据流(如日志数据、传感器数据等)。
- ETL层(Extract, Transform, Load):ETL过程负责从数据源中提取数据,进行必要的转换和清洗,然后加载到数据仓库中。这一层通常包括数据清洗、数据转换、数据聚合等操作,以确保数据的质量和一致性。
- 数据仓库层(Data Warehouse Layer):这是数仓的核心部分,存储经过ETL处理后的数据。数据仓库层通常包括星型模型(Star Schema)或雪花模型(Snowflake Schema)等数据结构,以支持高效的数据查询和分析。
- 数据集市层(Data Marts):数据集市是数据仓库的一个子集,通常针对特定的业务部门或业务场景。数据集市可以提供更加细粒度的数据视图,以满足特定用户的需求。
- 前端展示层(Front-End Layer):这一层负责将数据仓库中的数据以可视化或报表的形式展示给用户。前端展示层可以包括各种数据可视化工具、报表工具以及数据分析工具等。
除了以上几个主要部分,数仓还可能包括数据质量管理、数据安全与隐私保护、数据备份与恢复等辅助功能和组件。
总之,数仓是一个集成了多个数据源、经过ETL处理、以支持决策分析处理的大型数据系统。它由多个部分组成,每个部分都扮演着不同的角色,共同协作以实现数仓的目标。
三、数仓的技术方案有哪些?
数仓的技术方案有多种选择,具体取决于企业的技术栈、业务需求、数据量以及预算等因素。以下是一些常见的数仓技术方案:
- 传统关系型数据库:如Oracle、SQL Server、MySQL等。这些数据库适用于数据量相对较小、查询性能要求较高的场景。在关系型数据库中,数据通常以表格的形式存储,通过SQL语言进行查询和分析。
- 分布式数据库:如Hadoop、Spark等。这些数据库适用于处理海量数据、对查询性能要求不高的场景。分布式数据库将数据分散存储在多个节点上,通过并行处理来提高数据处理效率。
- 列式数据库:如Vertica、Apache Drill等。列式数据库将数据按列存储,适用于大数据量、高并发查询的场景。列式数据库通过减少数据扫描量来提高查询性能。
- 内存数据库:如Redis、Memcached等。内存数据库将数据存储在内存中,具有极高的读写性能,适用于需要快速响应的场景。但需要注意的是,内存数据库的数据持久性相对较差,需要配合其他存储方案使用。
- 云原生数仓:云原生数仓将数据存储在云端,用户无需关心底层基础设施的运维和管理。云原生数仓通常提供丰富的查询和分析功能,以及良好的扩展性和弹性。
- 实时数仓:如Apache Kafka、Apache Flink等。实时数仓能够处理实时数据流,提供近实时的数据分析和查询能力。实时数仓通常与消息队列、流处理框架等技术结合使用,实现数据的实时采集、处理和分析。
在选择数仓技术方案时,需要综合考虑企业的业务需求、数据量、预算以及技术团队的能力等因素。同时,随着技术的不断发展,新的数仓技术方案也会不断涌现,企业需要保持对新技术的学习和探索,以便更好地满足业务需求。
四、搭建一个离线数仓的关键步骤
搭建一个离线数仓的步骤及其可能用到的技术方案如下:
-
需求分析与规划
- 步骤内容:明确业务需求,确定数仓建设的目标,如报表生成、数据分析等。进行业务过程的梳理和选择,明确需要建模的业务范围。
- 技术方案:业务过程梳理可以使用流程图工具,如Visio等,来帮助理解和规划。
-
数据源分析
- 步骤内容:确定数据源的范围和格式,包括数据库、日志文件、API接口等。分析数据源的更新频率、数据量及质量。
- 技术方案:可以使用数据剖析工具,如Apache Atlas、Informatica Metadata Manager等,进行数据源的分析和管理。
-
数据采集与清洗
- 步骤内容:从数据源中提取数据,并进行清洗、转换和格式化,确保数据的准确性和一致性。
- 技术方案:数据采集可以使用工具如Apache Sqoop(用于Hadoop与结构化数据存储之间的数据传输)、Logstash(日志数据采集)等。数据清洗和转换可以使用Python、Java等编程语言,结合Pandas、Spark等数据处理库。
-
数据建模
- 步骤内容:根据业务需求,设计数据仓库的逻辑模型和物理模型,包括确定数据的存储结构、索引策略等。
- 技术方案:逻辑模型设计可以使用ER图工具,如ERwin、Toad Data Modeler等。物理模型设计则需要考虑数据库的具体实现,如使用分布式数据库HDFS、关系型数据库MySQL等。
-
ETL过程实现
- 步骤内容:根据设计好的数据模型,编写ETL任务,将清洗后的数据加载到数据仓库中。
- 技术方案:ETL工具可以选择Apache NiFi、Talend、Informatica等。这些工具都提供了丰富的功能,可以支持复杂的数据转换和处理需求。
-
数据存储与管理
- 步骤内容:在数据仓库中存储和管理数据,包括数据的备份、恢复、安全和性能监控等。
- 技术方案:数据存储可以选择HDFS、HBase等分布式存储系统,也可以选择关系型数据库如MySQL、Oracle等。数据管理可以使用数据库管理系统(DBMS)提供的工具,如MySQL Workbench、Oracle SQL Developer等。
-
数据分析与应用
- 步骤内容:利用前端工具对数据进行查询、分析和挖掘,满足业务需求。
- 技术方案:数据分析工具可以选择Tableau、Power BI等可视化分析工具,也可以使用编程语言如Python、R等结合数据分析库如NumPy、Pandas、Matplotlib等进行数据分析。
-
维护与优化
- 步骤内容:定期对数仓进行维护,包括性能优化、错误修复等。根据业务需求的变化,对数仓进行扩展或调整。
- 技术方案:可以使用数据库性能监控工具,如New Relic、Datadog等,进行性能监控和优化。对于错误修复和扩展调整,则需要根据具体情况选择适当的工具和技术。
五、数仓项目中用到的技术框架
在数仓项目中,用到的技术框架可以分为以下几类:
-
数据采集与传输:
- Flume:用于日志数据的采集、聚合和传输。
- Kafka:分布式流处理平台,用于实时数据的采集和传输。
- Sqoop:用于在Hadoop和结构化数据存储(如关系型数据库)之间传输数据。
- Logstash:用于日志数据的收集、解析和传输。
- DataX:用于大规模数据的离线同步和交换。
-
数据存储:
- HDFS(Hadoop Distributed File System):分布式文件系统,用于存储大规模数据。
- HBase:分布式、可扩展、列式存储的NoSQL数据库。
- Redis:内存中的数据结构存储系统,用作数据库、缓存和消息代理。
- MySQL:关系型数据库管理系统。
- MongoDB:面向文档的NoSQL数据库。
-
数据计算与处理:
- Hive:基于Hadoop的数据仓库工具,用于数据查询和分析。
- Spark:大数据处理框架,支持批处理和流处理。
- Flink:流处理和批处理的开源平台,用于实时数据分析。
- Storm:分布式实时计算系统,用于处理大规模数据流。
- Tez:Hadoop YARN的框架,用于优化Hadoop MapReduce计算。
-
数据查询与分析:
- Presto:分布式SQL查询引擎,用于大规模数据的实时查询。
- Kylin:开源的分布式分析引擎,提供Hadoop上的SQL查询和多维分析(OLAP)能力。
- Impala:用于查询存储在Hadoop集群中的大规模数据的SQL查询引擎。
- Druid:高性能、列式、分布式数据存储和查询引擎,适用于OLAP场景。
-
数据可视化:
- Echarts:开源的JavaScript可视化库。
- Superset:数据可视化和探索平台。
- QuickBI:商业智能和数据可视化工具。
- DataV:数据可视化大屏工具。
-
任务调度与资源管理:
- Azkaban:批处理工作流程调度器,用于运行Hadoop作业或其他脚本。
- Oozie:Hadoop作业的工作流调度系统。
- YARN(Yet Another Resource Negotiator):Hadoop的资源管理系统。
-
集群监控与管理:
- Zabbix:开源的分布式监控解决方案。
- Cloudera Manager或Ambari:用于管理Hadoop集群的工具。
-
元数据管理:
- Atlas:Apache Atlas提供元数据管理和治理功能,用于Hadoop生态系统。
这些技术框架在数仓项目中根据具体需求和场景进行选择和组合使用。请注意,这里列举的是一些常见的框架,并不意味着它们是唯一或最佳的选择。在实际项目中,可能还需要考虑其他因素,如技术团队的熟悉程度、与现有系统的兼容性等。
六、实时数仓和离线数仓有什么区别
实时数仓和离线数仓在多个方面存在明显的区别:
-
架构选择:离线数仓通常采用传统的大数据架构,以Hadoop为核心,结合HDFS作为存储层,使用MapReduce、Hive、Spark等作为计算层。而实时数仓则倾向于采用Kappa架构方式搭建,注重实时数据的处理和分析。
-
数据时效性:离线数仓处理的数据结果一般是T+1,即延迟一天。而实时数仓则强调数据的实时性,统计结果通常是分钟级别、秒级别,甚至毫秒级别,能够满足对实时性要求较高的业务场景。
-
数据处理方式:离线数仓主要处理历史数据和复杂的分析任务,数据一般批量处理,不强调实时性。而实时数仓则主要处理实时数据流,强调数据的实时采集、清洗、转换、加载等操作,形成面向实时的数据模型。
-
数据质量:离线数仓通常具有较高的数据质量和准确性,因为可以对数据进行充分的清洗和校验。而实时数仓由于强调实时性,可能在一定程度上牺牲数据质量,但随着技术的发展,实时数仓的数据质量和准确性也在逐渐提高。
-
数据吞吐量:离线数仓的吞吐量一般很高,因为可以批量处理数据。实时数仓在实时处理大量数据时,对数据吞吐量有较高要求,但随着实时技术的发展,其实时吞吐量也在不断提高。
-
数据存储:离线数仓一般将数据存储在HDFS、Hive中,而实时数仓则更倾向于将数据存储在Kafka、Hbase、Redis、ClickHouse等系统中,以满足实时处理和分析的需求。
-
应用场景:离线数仓更适合处理历史数据和复杂的分析任务,如报表生成、数据挖掘等。而实时数仓则更适用于实时监控、实时分析、实时决策等场景,如电商平台的实时交易分析、金融行业的实时风险监控等。
总之,实时数仓和离线数仓在架构、数据时效性、数据处理方式、数据质量、数据吞吐量、数据存储和应用场景等方面都存在明显的区别。企业在选择搭建数仓时,应根据自身的业务需求和场景来选择合适的数仓类型。
性和高效性。
相关文章:

【数仓】基本概念、知识普及、核心技术
一、数仓基本概念 数仓的定义: 数据仓库(Data Warehouse,简称DW或DWH)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。简言之,它是一个大型存储库,用于存储来…...

ky10-server docker 离线安装包、离线安装
离线安装脚本 # ---------------离线安装docker------------------- rpm -Uvh --force --nodeps *.rpm# 修改docker拉取源为国内 rm -rf /etc/docker mkdir -p /etc/docker touch /etc/docker/daemon.json cat >/etc/docker/daemon.json<<EOF{"registry-mirro…...

Linux的gdb调试
文章目录 一、编译有调试信息的目标文件二、启动gdb调试文件1、查看内容list/l:l 文件名:行号/函数名,l 行号/函数名2、打断点b:b文件名:行号/函数名,b 行号/函数名 与 查看断点info/i:info b3、删除断点d:…...

IO多路复用-select模型
IO多路复用(IO Multiplexing)是一种高效的网络编程模型,可以同时监控多个文件描述符(包括套接字等),并在有数据可读或可写时进行通知。其中,select模型是最常用和最早引入的一种IO多路复用模型。…...
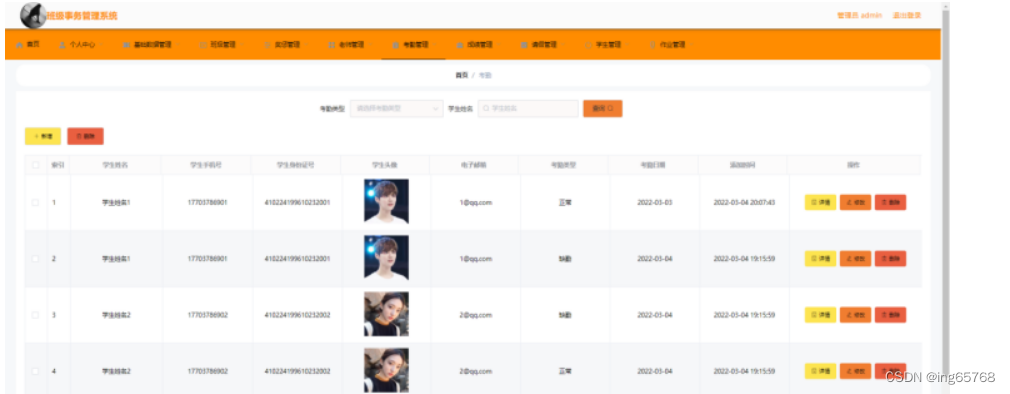
班级事务管理系统设计与实现
** 🍅点赞收藏关注 → 私信领取本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅** 一 、设计说明 1.1 选题…...

金三银四面试必问:Redis真的是单线程吗?
文章目录 01 Redis中的多线程1)redis-server:2)jemalloc_bg_thd3)bio_xxx: 02 I/O多线程03 Redis中的多进程04 结论▼延伸阅读 由面试题“Redis是否为单线程”引发的思考 作者:李乐 来源:IT阅读…...

notejs+nvm+angular+typescript.js环境 Hertzbeat 配置
D:\Program Files\nodejs\ D:\Users\Administrator\AppData\Roaming\nvm nvm命令提示 nvm arch:显示node是运行在32位还是64位。 nvm install <version> [arch] :安装node, version是特定版本也可以是最新稳定版本latest。 可选参…...
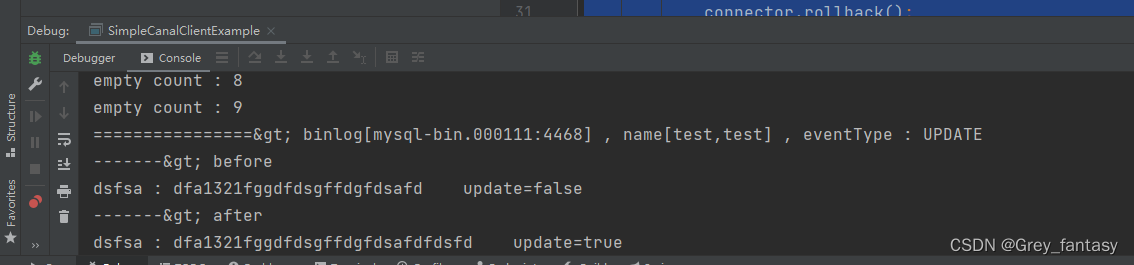
docker安装单机版canal和使用
说明:我安装的组件架构如下: 1、准备一台虚拟机,192.168.2.223,我安装的时候,docker只支持canal1.1.6版本,1.1.7无法使用docker安装.还有一点要补充,就是1.1.6好像不支持es8.0以上版本&#x…...

qt_xml文件
文章内容 简单介绍xml文件的增删改查写生成和读取xml文件的例子增删改查 Qt提供了QDomDocument类来操作XML文件。 增加节点: QDomElement root = doc.createElement("root"); doc.appendChild(root);QDomElement element = doc.createElement("element"…...

【DAY05 软考中级备考笔记】线性表,栈和队列,串数组矩阵和广义表
线性表,栈和队列,串数组矩阵和广义表 2月28日 – 天气:阴转晴 时隔好几天没有学习了,今天补上。明天发工资,开心😄 1. 线性表 1.1 线性表的结构 首先线性表的结构分为物理结构和逻辑结构 物理结构按照实…...
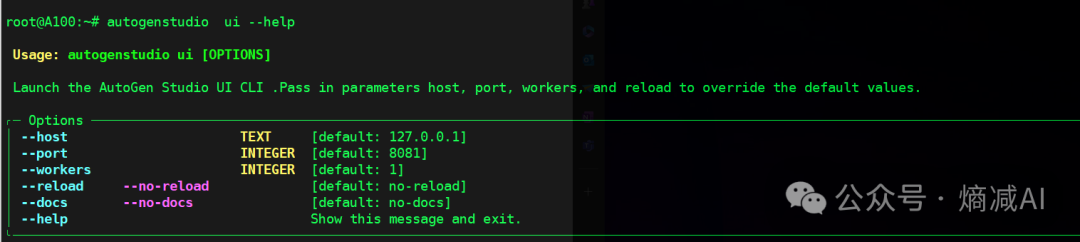
AutoGen Studio助力打造私人GPTs
微软最近在开源项目里的确挺能整活儿啊! 这次我介绍的是AutoGen Studio,我认为这个项目把AutoGen可用性又拔高了一个层次的项目 项目给自己的定义是交互式的多Agent workflow 项目地址:autogen/samples/apps/autogen-studio at main microsoft/autogen (github.com) 首先我…...
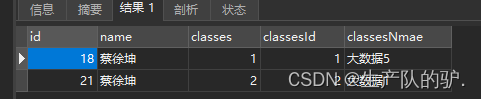
SpringBoot 自定义映射规则resultMap association一对一
介绍 例:学生表,班级表,希望在查询学生的时候一起返回该学生的班级,而一个实体类封装的是一个表,如需要多表查询就需要自定义映射。 表结构 班级表 学生表 SQL语句 SELECT a.id,a.name,a.classes,b.id classes…...

华东地区汽车相关夹具配套企业分布图,你了解多少?
1、华东地区 上海汽车整车厂众多,大多以设计研发为主,注重技术和造型,这与他们的整体风格息息相关。 作为与国际接轨的特大城市,中国的经济、交通、科技、工业、金融、贸易、会展和航运中心,聚集了大量的设计和研发人…...

SpringBoot - 后端数据返回前端各个数据类型全局格式化
全局配置 import com.fasterxml.jackson.annotation.JsonInclude; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.SerializationFeature; import com.fasterxml.jackson.databind.module.SimpleModule; import com.fasterxml.j…...
实验室记账项目(java+Mysql+jdbc)
前言: 因为自己学习能力有限和特殊情况必须要找一个项目来做,但是上网搜的那些项目有两种(一种是技术太多,自己能力不够;一种是技术太少,项目太简单)导致都不适合本人,本人现有技术只…...
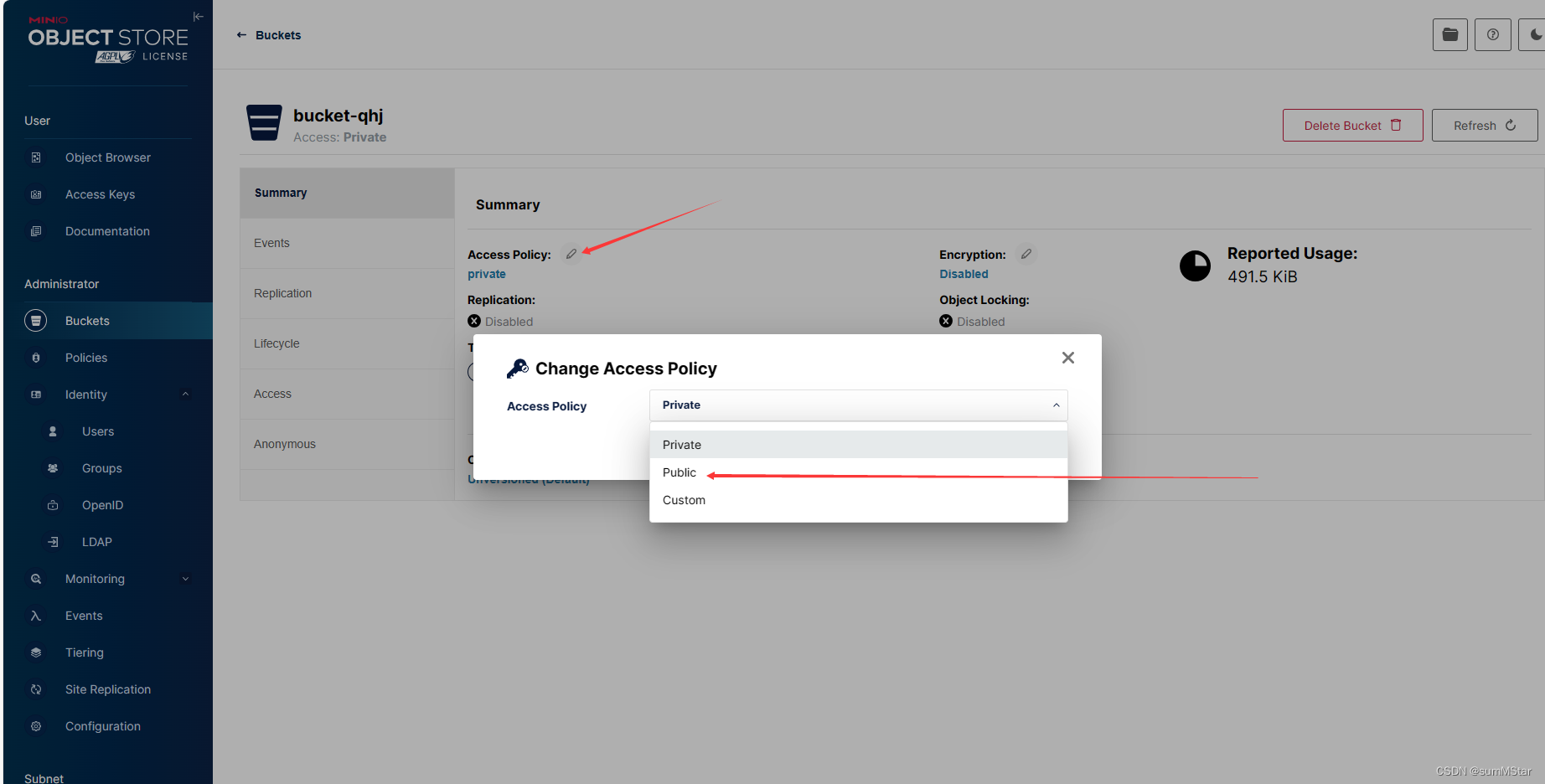
spring boot 整合 minio存储 【使用篇】
zi导入依赖 <!--minio--><dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.0.3</version></dependency> yml配置(默认配置) spring:# 配置文件上传大小限制s…...
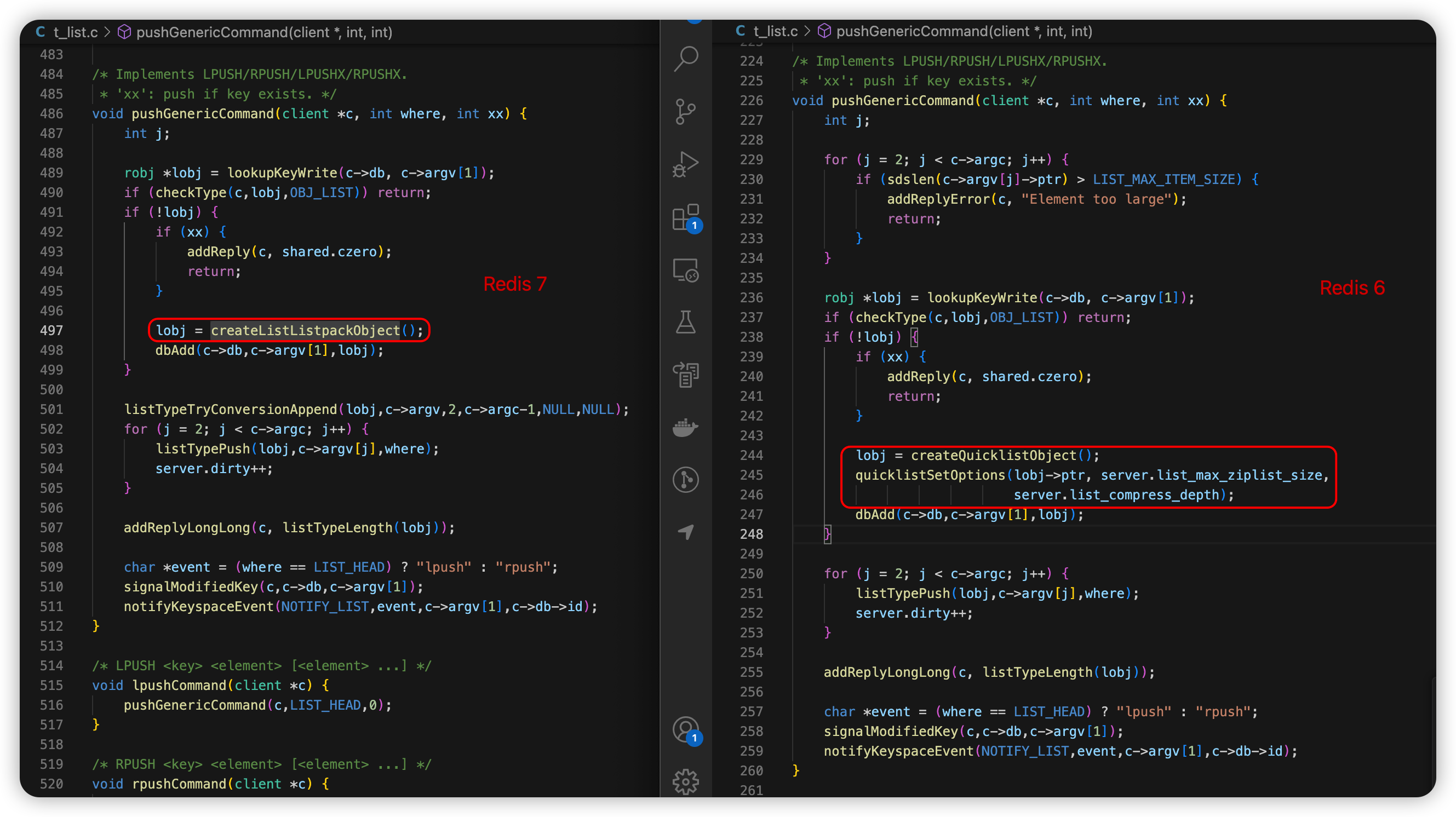
【Redis】深入理解 Redis 常用数据类型源码及底层实现(5.详解List数据结构)
本文是深入理解 Redis 常用数据类型源码及底层实现系列的第5篇~前4篇可移步( ̄∇ ̄)/ 【Redis】深入理解 Redis 常用数据类型源码及底层实现(1.结构与源码概述)-CSDN博客 【Redis】深入理解 Redis 常用数据类型源码及底…...

Vue+Flask电商后台管理系统
在这个项目中,我们将结合Vue.js前端框架和python后端框架Flask,打造一个功能强大、易于使用的电商后台管理系统 项目演示视频: VueFlask项目 目录 前端环境(Vue.js): 后端环境(python-Flask&…...

SpringBoot保姆级入门文档
目录 1、SpringBoot的优点 2、和Spring、SpringMVC的对比 3、Xml 和 JavaConfig 1、SpringBoot的优点 2、和Spring、SpringMVC的对比 3、Xml 和 JavaConfig Spring 使用 Xml 作为容器配置文件,在 3.0 以后加入了 JavaConfig,使用 java 类做配置文件使…...

Springboot同一台服务器部署多个项目,导致redis混淆,如何根据不同项目区分
在Spring Boot应用中,如果在同一台服务器上部署了多个项目,并且每个项目都使用Redis作为缓存或存储,为了避免Redis数据混淆,你需要确保各个项目在访问Redis时使用不同的数据库索引号、键前缀或者连接配置。 以下是一些区分不同项目Redis数据的方法: 使用不同数据库索引:…...

【WinCC V7.5 实战:从零搭建污水处理监控系统】
1. 污水处理监控系统与WinCC V7.5的完美结合 污水处理是现代工业中不可或缺的一环,而监控系统则是确保处理过程稳定运行的关键。WinCC V7.5作为西门子经典的SCADA系统,在工业自动化领域有着广泛的应用。对于初学者来说,从零开始搭建一个完整的…...
)
HFSS实战:手把手教你仿真一个2.1GHz圆极化微带天线阵列(从单贴片到2x2阵)
HFSS实战:从单贴片到2x2阵列的圆极化微带天线仿真全流程 在射频工程领域,微带天线因其结构紧凑、成本低廉和易于集成的特点,成为无线通信系统的热门选择。特别是圆极化微带天线,能够有效减少极化失配带来的信号损失,在…...
)
农产品销售|基于springboot + vue农产品销售系统(源码+数据库+文档)
农产品销售系统 目录 基于springboot vue农产品销售系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产品销售系统 一、前言 博主介绍&#x…...

26HVV行动 初 中 高 级人员招聘
一、HW人员要求及详细介绍 原文地址:https://mp.weixin.qq.com/s/vzRwUhtWj8tfibZFS7YfoA HW介绍 HW(网络安全护网行动)是国家关键信息基础设施安全攻防演练行动,旨在通过实战化攻防对抗提升行业网络安全防护能力。 城市&…...

Redux DevTools 终极调试指南:从状态混乱到精准掌控的完整解决方案
Redux DevTools 终极调试指南:从状态混乱到精准掌控的完整解决方案 【免费下载链接】redux-devtools DevTools for Redux with hot reloading, action replay, and customizable UI 项目地址: https://gitcode.com/gh_mirrors/re/redux-devtools 你是否曾为R…...

《Hermes Agent 代码库安全漏洞分析与解决办法》
Hermes Agent 代码库安全漏洞分析与解决办法 Hermes Agent 作为跨平台自改进型 AI 智能体框架,涉及配置管理、多端通信、工具调用、容器部署等核心环节,以下从配置安全、部署安全、代码执行风险、数据隐私、网络通信、依赖管理、权限控制七大维度&#x…...

在 Linux 中查询最耗费 CPU 资源的前 10 个进程的常用脚本
方法一:使用 ps 命令(推荐,最通用)#!/bin/bash # 查看CPU占用最高的10个进程 ps aux --sort-%cpu | head -n 11 | tail -n 10或者更详细的版本:#!/bin/bash echo " CPU使用率最高的10个进程 " printf "…...

一文了解医疗废水处理行业!
相信大家都明白,在医院这类复杂的场所,排放的废水肯定也很复杂,其中是会包含各种有毒、有害的物理化学以及反射性的污染等,还存在空间性、急性等特征。接下来我们一文了解什么是医疗废水处理行业!其实医疗废水处理行业…...

2026年2款HR系统横评:红海云与用友谁更适合制造业?
制造业选HR系统,真正拉开差距的往往不是人事流程是否在线,而是倒班与综合工时能否稳、计件与绩效能否准、与MES和ERP数据能否顺畅闭环,以及集团多工厂规则差异能否统一管控。红海云与用友都覆盖主流HCM模块,但产品侧重点不同&…...

2026届学术党必备的六大降重复率方案解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 通过先进自然语言处理跟机器学习技术构建的人工智能论文工具,正一步步改变传统学…...