Flink——芒果TV的实时数仓建设实践
目录
一、芒果TV实时数仓建设历程
1.1 阶段一:Storm/Flink Java+Spark SQL
1.2 阶段二:Flink SQL+Spark SQL
1.3 阶段三:Flink SQL+StarRocks
二、自研Flink实时计算调度平台介绍
2.1 现有痛点
2.2 平台架构设计
三、Flink SQL实时数仓分层实践
四、Flink SQL实时数仓生产过程遇到的问题
4.1 多表关联
4.2 复杂的表处理
4.3 State过大
4.4 Checkpoint 不能顺利完成
五、StarRocks选型背景及问题
六、基于Flink SQL+StarRocks实时分析数仓
6.1 明细模型
6.2 主键模型
6.3 聚合模型
6.4 物化视图
七、未来展望
7.1 湖仓一体
7.2 低代码
原文大佬的这篇实时数仓建设案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。
一、芒果TV实时数仓建设历程
芒果TV实时数仓的建设分为三个阶段,14-19 年为第一阶段,技术选型采用 Storm/Flink Java+Spark SQL。20-22 年上半年为第二阶段,技术选型采用 Flink SQL+Spark SQL 。22 年下半年-至今为第三阶段,技术选型采用 Flink SQL+ StarRocks。每一次升级都是在原有基础上进行迭代,以求更全面的功能,更快的速度,能更好的满足业务方的需求。
1.1 阶段一:Storm/Flink Java+Spark SQL
芒果 TV 的实时数据处理很早就开始了,最开始用的是 Storm,到了 18 年时,Flink 横空出世。Flink 的 State状态与流处理的优势让人眼前一亮,所以改用了 Flink 来搭建实时数仓,但当时主要以满足业务方需求为主,进行烟囱式的开发,基本流程是接上游kafka的数据,使用flink java进行相关业务逻辑处理后,将数据输出至对象存储中。然后使用spark sql对数据进行统计等二次加工处理后,再交付客户使用。此阶段优点是利用了Flink的长处,让数据从源头到终端更实时化了,满足了业务方对数据的时效性与业务需求,缺点是一个需求就开发一个功能,没有进行实时数仓的建设和沉淀。
1.2 阶段二:Flink SQL+Spark SQL
基于上一阶段的技术积累与发现的问题,提出了建设实时数仓的新方案。此时Flink sql功能已经初步完善,能满足搭建数仓各方面的需求,SQL 化相较 Flink Java 也能降低开发、维护等各方面成本,于是选择 Flink SQL 来搭建实时数仓。此阶段对实时数仓进行了分层架构设计,这个后面有详细讲解。
基本流程是接上游 Kafka 数据进行格式化后输出至 Kafka,下层接到 Kafka 数据进行字段处理、垃圾数据过滤等操作后输出至 Kafka,最后一层接 Kafka 数据进行维度扩展,然后将数据写至对象存储中。再由 Spark SQL 读取对象存储中的数据进行统计等处理后,交付客户使用。
此阶段的优点是实现了数仓的分层架构设计,对各层数据定义了标准化,实现了各层数据解耦,避免了烟囱式的开发,解决了重复开发等问题,实时数仓逐步走向成熟。缺点是使用Spark SQL进行后续的统计与汇总时,不够灵活。需要提前设计好指标,面对客户多变的需求时,往往不能很及时的响应。
1.3 阶段三:Flink SQL+StarRocks
随着实时数仓的建设逐步加深,Spark SQL不够灵活,处理速度不够快的弊端越发突出。此时StarRocks进入了我们的视线,其MPP的架构,向量化引擎,多表Join等特性所展现出来在性能、易用性等方面的优势,都很好的弥补了 Spark SQL 在这块的不足。于是经调研后决定,在实时数仓中用 StarRocks 替换掉 Spark SQL 。在此阶段,前面用 Flink SQL 搭建的实时数仓分层构架并未改变,而下游用 Spark SQL 进行统计分析的相关功能,逐步替换成了用 StarRocks 来做。
之前使用Spark SQL先将数据进行统计与汇总后,将最终结果写入对象存储中,而现在是直接用 StarRocks 对明细数据进行汇总,展示到前端页面中。这么做的好处是能更快、更灵活的满足业务方的需求,减少了开发工作量,减少了测试、上线等时间。StarRocks 优秀的性能让即席查询速度并未变慢,功能更强大,更灵活,交付速度变更快了。
二、自研Flink实时计算调度平台介绍
2.1 现有痛点
- 原生任务命令复杂,调试麻烦,开发成本比较高;
- 连接器,UDF,Jar任务包等无法管理,调试复杂,经常遇到依赖冲突问题
- 无法做到统一的监控报警以及对资源上的权限管理
- sql开发任务复杂,没有一个好用的编辑器和代码管理及保存平台
- 基础表、维表、catalog没有记录和可视化的平台
- 多版本和跨云任务无法很好的管理
2.2 平台架构设计
实时Flink调度平台架构图:
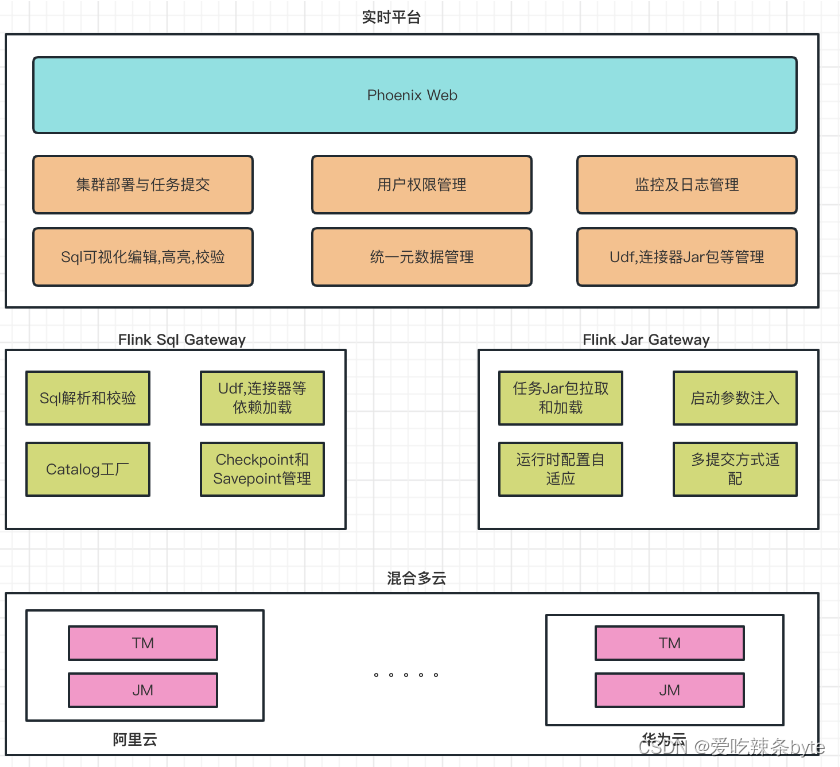
平台主要分为三个部分:
(1) Phoenix Web 模块主要负责面向用户。
-
集群部署与任务提交。
- 公司各内部业务权限管理
-
UDF,连接器等三方依赖 Jar 包管理。
-
多类型监控报警以及日志管理。
-
SQL 可视化编辑和校验以及多版本存储。
-
公司各内部业务权限管理。
(2) Flink SQL Gateway 和 Flink Jar Gateway 都是基于开源版本修改定制后的服务,支持SQL符合业务场景的解析和校验,以及Jar任务的提交,支持本地模式。Yarn-per-job 模式和 Application 模式,也支持自动的保存点Savepoint。
-
进行 SQL 的解析和校验。
-
加载SQL和Jar任务所需要的三方依赖。
-
SQL 任务连接 Catalog 存储进行关联和映射。
-
Checkpoint 和 Savepoint 的自动管理和恢复。
-
Jar 类型任务启动参数的注入。
-
运行时配置的自适应。
-
多类型的提交方式适配。
(3) 混合多云模块主要负责启动任务的分发和云之间的信息管理。
三、Flink SQL实时数仓分层实践
使用Flink SQL 搭建实时数仓时,首要问题是数仓分层架构如何解决,业界内有许多优秀的经验可以参考,同时也基于我们的情况,最终采用了如下数仓架构:

ODS层:原始日志层,在该层将上游 Binlog 日志、用户行为日志、外部数据等数据源同步至数仓,对多种数据源,多种格式的数据通过统一UDF函数解析,格式化,最终输出格式化JSON数据
DW层:数据明细层,在该层主要进行错误数据过滤,字段转义,统一字段名等处理,输出的数据已能满足日常基础分析的使用。
DM层:数据模型层,在该层进行扩维,补充相关的公共信息。再按业务进行分域,输出的数据
具有更丰富的维度,可以满足高级分析的数据使用需求。
ST 层:数据应用层,按业务,功能等维度进行汇总,交由给前端页面进行展现,输出的数据可交付 Web、App、小程序等功能使用。
四、Flink SQL实时数仓生产过程遇到的问题
在搭建实时数仓时,遇到了不少的问题,下面挑几个典型的问题讲解一下解决思路:
4.1 多表关联
在使用 Flink SQL 搭建实时数仓初期,涉及多表关联时,有些维表的数据在 Hive 里,有些维表又在 MySQL 中,甚至还有些维表数据在其它 OLAP 中,该选择何种关联方式,需要综合考虑性能 ,功能等方面,总结出如下规则:
- 流表关联维表(小数据量),使用Lookup Join, 维表数据量在十万以下时,可使用hive表做维表,因为离线数仓中的维表数据大部分都在 Hive 中,这样的话就可以直接复用,省去数据导入导出的额外工作,并且性能方面没有瓶颈,维表小时更新后,Flink SQL 也能读到最新数据。
- 流表关联维表(大数据量),使用Lookup Join,维表数据量在十万-千万以下时,可用Mysql做维表,此时用 Hive 维表已不能满足性能需求。可将数据导出至 MySQL 中,利用缓存机制,也能很好的满足要求。
- 流表关联流表,使用 Interval Join,通过两个流表的时间字段来控制关联范围,这种关联方式是目前用的比较多的,使用方式要跟离线比较接近。
4.2 复杂的表处理
4.3 State过大
在两个流表进行关联或进行汇总统计时,Flink的机制是会将数据缓存在State中,这就会导致State过大,导致GC频繁,进而任务失败。针对这种情况,在研究了 Flink 的内存机制后,得出的解决方案如下:
- 缩短时间范围,根据业务需求,适当减少关联时两条流的时间范围。
- 调整 Managed Memory 大小,可以调整 Managed Memory 占比,适当的缩小其它内存的使用。
- 设置State的TTL来避免缓存过多的数据
4.4 Checkpoint 不能顺利完成
任务中频繁出现 Checkpoint expired before completing异常,在实际生产环境中,发现有任务频繁的报这个错误,这个错误指Checkpoint不能顺序完成,因为Flink的Checkpoint有Barrier机制来保证数据的Exactly-once 精确一次性语义。如果一批数据处理不完,Checkpoint就完成不了。导致这个错误原因有多种,不同的问题也有不同的解答,接下来列举一下各场景与解决方案:
- Checkpoint 的超时时长设置的太短,导致 Checkpoint 还没完成就被报了超时,这个问题比较常见。解决方案就是设置长一点,我们一般根据任务类型,会设置 6 秒-2 分钟不等。
- 任务有被压,因为一个任务内有多个操作,其中一个操作耗时长影响了整个任务的执行,这个问题比较常见。解决方案是可以从WebUI上找到执行缓慢的Task
-
内存不足,我们在生产环境中一般使用 rocksdb statebackend,默认会保留全量 Checkpoint。而这种情况下,在遇到有关联、分组统计等使用了 heap statebackend 的任务中,计算的中间结果会缓存到 State中,State的内存默认是总内存的 40%,在这种计算中会不太够,从而导致频率的 GC,也影响了 Checkpoint 的执行。解决方案如下:
调大 TaskManager的内存,TaskManager 的内存调大后,其它内存区域也会相应调大。
调大 Managed Memory 的内存占比,就是设置 taskmanager.memory.managed.fraction 这个参数,可根据实际情况来,实际生产中最高可调到 90%。这种方法只调大了 ManagedMemory 一块,如果内存资源并不是很充裕时,可以用这种方式。
- 改用增量Checkpoint,根据实际情况调整State的TTL时间,并开启增量Checkpoint,甚至都不用调内存大小,也能解决问题。
五、StarRocks选型背景及问题
在之前的框架中我们是以Flink流式处理引擎完成原始日志的清洗,数据的打宽与轻度聚合,再落地到分布式文件系统或对象存储,通过离线Spark SQL五分钟级别的调度批处理,结果会通过Presto等引擎去查询,这样的架构在生产环境中渐渐显露出很多问题:
- 存在重复计算的问题,原始数据会在不同的任务中反复清洗,有的需要多个原始数据的关联也会反复的清洗,大量浪费了计算资源,代码和数据流可重用性很差。
-
为了满足离线批处理历史累计值和当前 5 分钟窗口的计算指标,在流量高峰期和当日指标累计到晚上时很可能在 5 分钟之内无法完成指标的计算,有很大的超时风险,业务会反馈实时指标的延迟。
-
由于离线Spark 批处理在多维组合分析并且又要求实时性情况下,略显乏力。业务的在线化,催生出很多实时的场景,另一方面运营的精细化和分析的平民化也催生出多维的分析需求,这些场景下需要粒度特别细,维度特别丰富的地层数据,这两部分的叠加起来就催生出了实时多维分析的场景。这时候我们需要不断的增加维度组合,增加结果字段,增加计算资源来满足以上场景,但是还是略显乏力。
-
在数据时效性日益增加的今天,很多场景下数据的时效性提出了秒级毫秒级的要求,之前5分钟级别的方式不能满足业务需求。
-
在之前的实时任务中经常需要在Flink内存中做流和流的Join,由于上游多个数据流的数据到达时间不一致,很难设计合适的window去在计算引擎里面打宽数据,采用Flink Interval Join时多个流的时间间隔太久,状态数据会非常庞大,启用mapState之类的状态计算又过于定制
-
在线上有大型活动或者大型节目时,实时数据量暴增,实时的大批量写入的情况下,写入延迟大,写入效率不高,数据积压。
-
对于 Flink 清洗或者计算的结果可能需要多个存储介质中,对于明细数据我们可能会存储在分布式文件系统或者对象存储,这时候是 Flink+HDFS,对于业务更新流数据,可能是 Flink CDC+hbase(cassandra或者其他 key-value 数据库),对于 Flink 产生回撤流数据可能是 Flink+MySQL(redis),对于风控类数据或者传统的精细化的看版可能是 Flink+ elasticsearch,对于大批量日志数据指标分析可能是Flink+clickhouse,难以统一,资源大量损耗,维护成本同样高。
总体分析,早期架构以下问题:
- 数据源多样,维护成本比较高
- 性能不足,写入延迟大,大促的场景会有数据积压,交互式查询体验较差
- 各个数据源割裂,无法关联查询,形成众多的数据孤岛,从开发的角度,每个引擎都需要投入相应的学习开发成本,程序复杂度比较高。
- 实时性要求高,并且开发效率快,代码或者数据可重复利用性强。
- 实时任务开发没有同一套标准,各自为战。
六、基于Flink SQL+StarRocks实时分析数仓
基于已经搭建完毕的 Flink SQL 的数仓分层体系,且由 StarRocks2.5X 版本升级到 StarRocks3.0X 存算分离版本并已大规模投入在生产环境中。
实时和离线湖仓一体的架构图:

6.1 明细模型
在大数据生产环境中最常见的日志数据,特点是数据量大,多维度的灵活复杂计算,计算指标多,实时性强,秒级别的高性能查询,简单稳定实时流写入,大表的Join,高基数字符列去重
使用Flink SQL+StarRocks 都能满足,首先实时平台上使用Flink SQL快速对实时流日志数据进行清洗,打宽,同时StarRocks提供 Flink-Connector-StarRocks连接器开箱即用,并且支持Exactly-once精准一次性语义和事务支持,底层通过Stream Load低延迟快速导入。
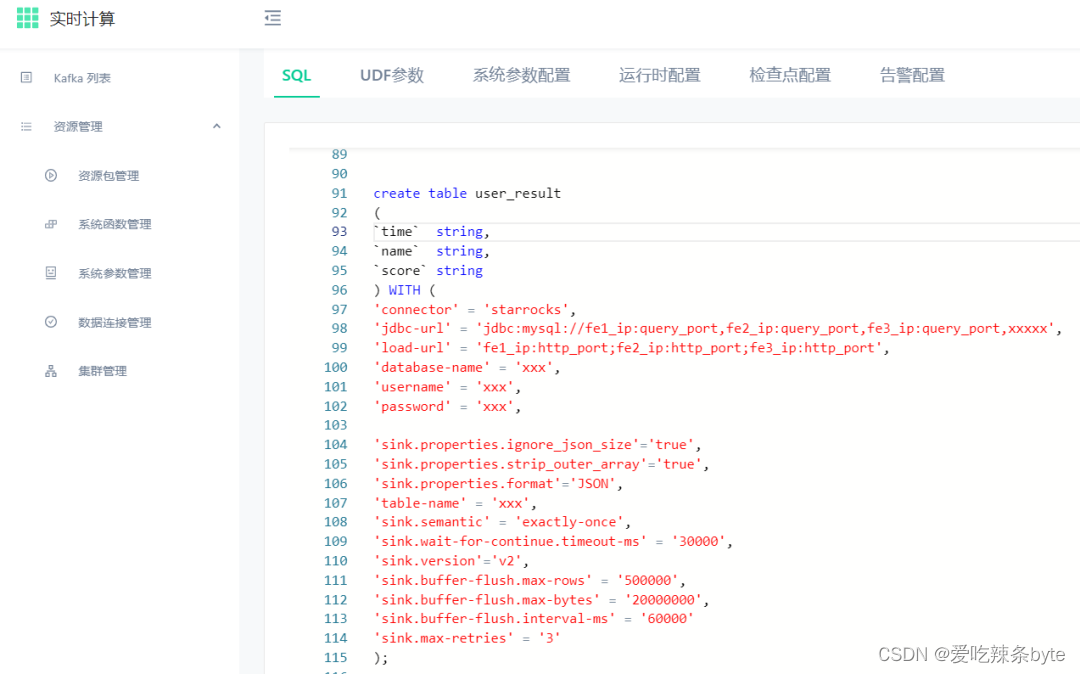
通过高效简单地Flink SQL建表模式,批量百万级写入,速度快,同时针对生产环境中单表十亿级别以上的数据,在计算多维度用户访问次数,和用户去重数据,能达到秒级别。
6.2 主键模型
对于数仓中的数据变更方式:
- 方式一:某些OLAP数据仓库数据仓库提供 Merge on Read模型的更新功能,完成数据变更,例如(clickhouse)。
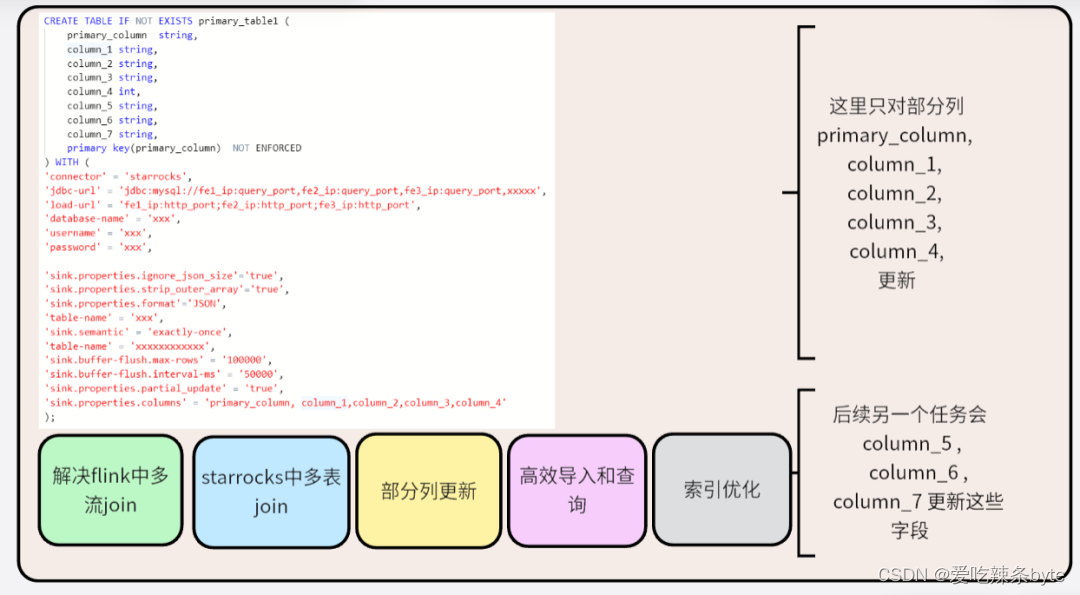
Merge on Read 模式在写入时简单高效,但读取时会消耗大量的资源在版本合并上,同时由于 merge 算子的存在,使得谓词无法下推、索引无法使用,严重的影响了查询的性能。 StarRocks 提供了基于 Delete and Insert 模式的主键模型,避免了因为版本合并导致的算子无法下推的问题。主键模型适合需要对数据进行实时更新的场景,可以更好的解决行级别的更新操作,支撑百万级别的 TPS,适合MySQL 或其他业务库同步到StarRocks 的场景。
-
方式二:简单来说就是创建新分区表,删除旧的分区表数据,然后批量刷写过去。
在新的分区中插入修改后的数据,通过分区交换完成数据变更。通过批量刷写的方式会要重新建表,删除分区数据,刷写数据过程繁杂,还可能导致出错。
而且通过Flink CDC和StarRocks完美结合可以实现业务库到OLAP数据仓库端到端的全量+增量的实时同步,一个任务可以搞定批量和实时的全部问题,并且高效稳定,同时主键模型也可以解决Flink中回撤流输出的问题,支持按条件更新,支持按列更新,这些都是传统OLAP数据库很多不兼具的优点。
6.3 聚合模型
在实时数仓中还有一种场景,我们不太关心原始的明细数据,多为汇总类查询,比如 SUM、MAX、MIN 等类型的查询,旧数据更新不频繁,只会追加新的数据,这个时候可以考虑使用聚合模型。建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
针对聚合指标,之前是放在Flink中统计,状态数据会存在内存中,会导致状态数据持续增长,斌并且消耗大量资源,将Flink的单纯统计修改为Flink SQL + StarRocks聚合模型,Flink这里只需要明细数据进行清洗并导入到 StarRocks,效率非常高且稳定。
实际生产环境中,聚合模型主要用来统计用户观看时长,点击量,订单统计等。

6.4 物化视图
数据仓库环境中的应用程序经常基于多个大表执行复杂查询,通常涉及多表之间数十亿行数据的关联和聚合。要实现这种实时多表关联并查询结果的方式,在之前我们可能会把此项内容放在 Flink 实时数仓中去处理,分层处理关联,合并,统计等任务,最后输出结果层数据,处理此类查询通常会大量消耗系统资源和时间,造成极高的查询成本。
现在可以考虑使用Flink SQL+StarRocks 的新思路去处理这种大规模的分层计算问题,使得 Flink SQL 这里只需要处理一些简单清洗任务,把大量重复计算的逻辑下推到StarRocks去执行,多个实时流实时落地 ,在StarRocks可以建立多级物化视图的建模方式,StarRocks 的物化视图不仅支持内表和内表关联,也支持内表和外表关联。例如:数据分布在MySQL,Hudi,Hive 等都可以通过StarRocks 物化视图的方式查询加速,并设定定期刷新规则,从而避免手动调度关联任务。其中最大的一个特点时,当有新的查询对已构建了物化视图的基表进行查询时,系统自动判断是否可以复用物化视图中的预计算结果处理查询。如果可以复用,系统会直接从相关的物化视图读取预计算结果,以避免重复计算消耗系统资源和时间。查询的频率越高或查询语句越复杂,性能增益就会越很明显。
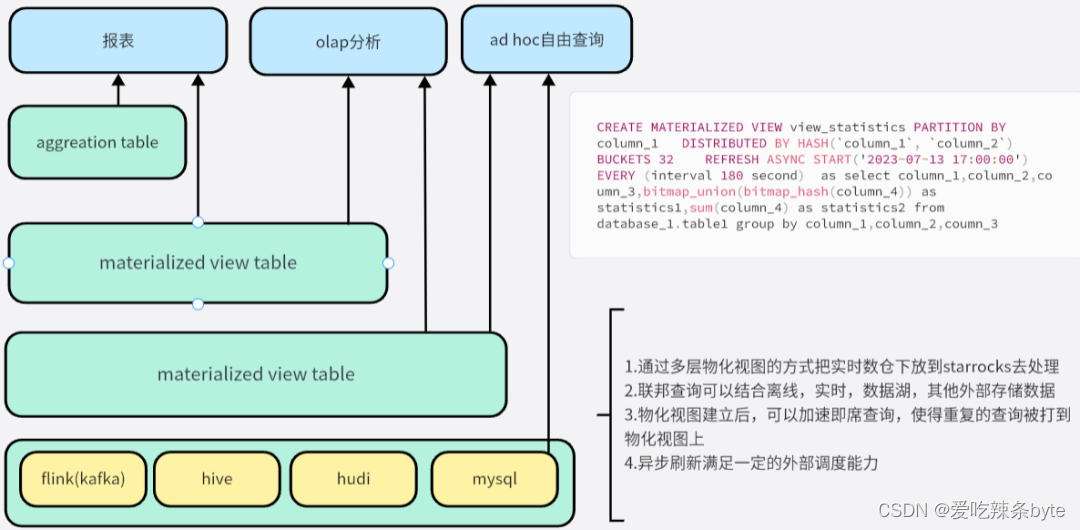
实时即未来,StarRocks 在逐渐实现这样的能力,StarRocks 和 Flink 结合去构建实时数据分析体系的联合解决方案,将在一定程度上颠覆既有的一些禁锢,形成实时数据分析新范式。
七、未来展望
7.1 湖仓一体
当前芒果 TV 已经实现了流批一体的数仓建设,而未来的重点是湖仓一体的建设。数据湖的特点在于可以存储各种类型和格式的原始数据,包括结构化数据、半结构化数据和非结构化数据。而数据仓库则是对数据进行结构化和整理,以满足特定的业务需求。
湖仓一体将数据仓库和数据湖的特点融合在一起,打造一个统一的数据中心,实现对数据的集中管理。湖仓一体的架构能够提供更好的安全性、成本效益和开放性,既能够存储和管理大量原始数据,又能够将数据整理成结构化的形式,为分析和查询提供便利。
通过建立湖仓一体,芒果 TV 能够向公司内部提供更丰富的数据服务,支持业务决策和创新,实现对数据的全面掌控和管理,包括数据的采集、存储、处理和分析。同时,湖仓一体还能够支持多种计算引擎和工具的使用,如 Flink、Spark、Hive 等,使得数据处理和分析更加灵活和高效。
7.2 低代码
现在的开发方式是在自研的平台上写 SQL 提交任务,这种方式在面对一些清洗场景时,大部分是重复工作,有较大的提升空间。低代码是时下比较热门的概念,其在降本增效方面的优势很大。我们的下一步的计划是逐步实现低代码,第一阶段是将实时平台与数据上报平台进行打通,通过读取上报平台里相关元数据,能够自动生成对应的数据清洗任务,解放生产力,提升工作效率与交付速度。
低代码的优势在于它能够将开发过程中的重复工作进行自动化和简化,减少了开发人员的编码工作量。通过可视化的方式,开发人员可以通过拖拽和配置来完成任务,而无需编写大量的代码。这不仅提高了开发效率,还降低了出错的风险。
总结而言,基于 Flink技术的特点,芒果 TV 在未来的数仓建设中将注重实现湖仓一体的架构,以实现对数据的全面管理和利用。同时,芒果 TV 计划逐步实现低代码的开发方式,以提高开发效率和交付速度。
参考文章:
芒果 TV 基于 Flink 的实时数仓建设实践
相关文章:
Flink——芒果TV的实时数仓建设实践
目录 一、芒果TV实时数仓建设历程 1.1 阶段一:Storm/Flink JavaSpark SQL 1.2 阶段二:Flink SQLSpark SQL 1.3 阶段三:Flink SQLStarRocks 二、自研Flink实时计算调度平台介绍 2.1 现有痛点 2.2 平台架构设计 三、Flink SQL实时数仓分…...

卸载云服务器上的 MySQL 数据库
执行以下命令以停止 MySQL 服务: sudo service mysql stop执行以下命令以彻底卸载 MySQL: sudo apt-get remove --purge mysql-server mysql-client mysql-common sudo apt-get autoremove sudo apt-get autoclean 这将删除 MySQL 数据库服务器、客…...

AUTOSAR SPI详解
1.SPI通信 1)SPI通信脚 SCLO:串行时钟sclk。MTSR:主向从方向数据MTSR(主发送从接收)。MRST:从向主方向数据MRST(主接收从发送)。SLSO:从选择信号SLS,支持16路片选控制。 2) SPI状态机 2.SPI通信波形 在主…...

SpringBoot快速入门(黑马学习笔记)
需求 需求:基于SpringBoot的方式开发一个Web应用,浏览器发起请求/hello后,给浏览器返回字符串"Hello World~"。 开发步骤 第一步:创建SpringBoot工程项目 第二步:定义HelloController类,添加方…...
压力测试工具Jmeter的下载与使用
1、进入官网下载Jmeter https://jmeter.apache.org/ 国内镜像(下载的慢的话可以用国内镜像下载) https://mirrors.cloud.tencent.com/apache/jmeter/binaries/ 2、跳转到下载页面 3、根据不同系统下载相应版本的Jmeter压缩包,Linux系统下载…...
kubectl 陈述式资源管理方法
目录 陈述式资源管理方法 项目的生命周期 1.创建kubectl create命令 2.发布kubectl expose命令 service的4的基本类型 查看pod网络状态详细信息和 Service暴露的端口 查看关联后端的节点 编辑 查看 service 的描述信息 编辑在 node01 节点上操作,查看…...
从 iOS 设备恢复数据的 20 个iOS 数据恢复工具
作为 iPhone、iPad 或 iPod 用户,您可能普遍担心自己可能会丢失存储在珍贵 iOS 设备中的所有宝贵数据。数据丢失的原因多种多样,这里列出了一些常见原因: 1. iOS 软件更新 2. 恢复出厂设置 3. 越狱 4. 误操作删除数据 5. iOS 设备崩溃 …...
cpp基础学习笔记03:类型转换
static_cast 静态转换 用于类层次结构中基类和派生类之间指针或者引用的转换。up-casting (把派生类的指针或引用转换成基类的指针或者引用表示)是安全的;down-casting(把基类指针或引用转换成子类的指针或者引用)是不安全的。用于基本数据类型之间的转换ÿ…...

H3C OSPF 外部路由引入实验
H3C OSPF 外部路由引入实验 实验拓扑 实验需求 按照图示配置 IP 地址R1,R2,R3 运行 OSPF 使内网互通,所有接口(公网接口除外)全部宣告进 Area 0;要求使用环回口作为 Router-id业务网段不允许出现协议报文…...

ARM简介
ARM:ARM是Advanced RISC Machine的缩写,意为高级精简指令集计算机。 英国ARM公司,2016年被软银创始人孙正义斥资320亿美元收购了。现在是软银旗下的芯片设计公司,总部位于英国剑桥,专注于设计芯片,卖芯片生…...

MySQL(基础篇)——事务
一.事务简介 事务是一组操作的集合,他是一个不可分割的单位,事务会把所有的操作作色一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 默认MySQL的事务是自动提交的,也就是说,…...

XGB-15:调参注意事项
参数调优是机器学习中的一门黑艺术,一个模型的最优参数可能取决于许多情境。因此,要为此提供全面的指南是不可能的。 了解偏差-方差权衡Bias-Variance Tradeoff 当能允许模型变得更加复杂(例如更深),模型具有更好的拟…...
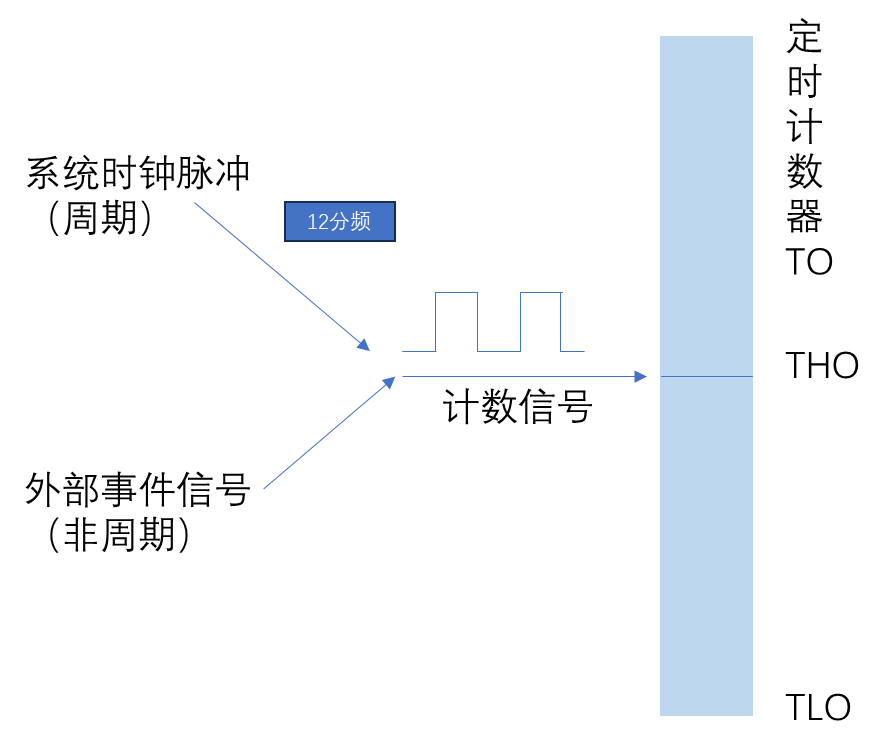
蓝桥杯_定时器的基本原理与应用
一 什么是定时器 定时器/计数器是一种能够对内部时钟信号或外部输入信号进行计数,当计数值达到设定要求时,向cpu提出中断处理请求,从而实现,定时或者计数功能的外设。 二 51单片机的定时/计数器 单片机外部晶振12MHZ,…...

【跨境电商须知】FP独立站的特点和痛点有哪些?
无论是做独立站,还是做亚马逊,都有各自的难点。自己做独立站若要在跨境行业长足发展,既要知道FP独立站有什么特点,要清楚FP独立站的痛点并一一克服。 一、FP独立站的特点 与依赖第三方平台相比,拥有自己的域名、服务器…...
)
js 精确计算(解决js四则运算精度缺失问题)
js的小数的运算,可能会得到一个不精确的结果,因为所有的运算都要转换成二进制去计算,然而,二进制无法精确表示1/10。 var a 0.1 0.2; console.log(a); //打印结果:0.30000000000000004因此需要使用以下方法实现精确…...

SpringBoot之统一事务管理配置
SpringBoot之自定义Jackson反序列化日期类型转换配置类 文章目录 SpringBoot之自定义Jackson反序列化日期类型转换配置类1. SpringBoot版本2. 统一事务管理配置类3. 主启动类加入开启事务的注解 统一事务管理配置 1. SpringBoot版本 <parent><groupId>org.springfr…...

荒岛生存:以牙签为核心资源的生存策略与思考
设想一下,当你不幸流落荒岛,随身携带的唯一物品是一盒牙签,面对极端环境与匮乏资源,如何运用这一看似微不足道的工具进行生存,成为了一项严峻的挑战。本文旨在探讨如何最大限度地发挥牙签在荒岛生存中的作用࿰…...

云计算 2月26号 (进程管理和常用命令)
一、权限扩展 文件权限管理之: 隐藏权限防止root误删除 文件属性添加与查看 [rootlinux-server ~]# touch file1 file2 file3 1.查看文件属性 [rootlinux-server ~]# lsattr file1 file2 file3 ---------------- file1 ---------------- file2 ---------------- f…...

Pytorch中,dim形象化的确切意义是什么?
在Pytorch中涉及张量的操作都会涉及“dim”的设置,虽然也理解个大差不差,但是偶尔还是有点犯迷糊,究其原因还是没有形象化的理解。 首先,张量的维度排序是有固定顺序的,0,1,2,.....…...
跨域引起的两个接口的session_id不是同一个
来源场景: RequestMapping(“/captcha”)接口设置了SESSION_KEY,也能获取到,但是到了PostMapping(“/login”)接口就是空的,由于跨域导致的两个session_id不是同一个 /*** 系统用户 前端控制器*/ Controller CrossOrigin(origins…...
)
别再只盯着GPU了!手把手带你用Python模拟一个超简版NPU(附代码)
用Python模拟NPU核心原理:从矩阵乘法到存储计算一体化 在咖啡厅里打开笔记本电脑运行神经网络模型时,你是否注意过风扇突然狂转?这背后是传统处理器架构面对AI计算时的力不从心。NPU(神经网络处理器)的独特之处在于&am…...
预处理与避坑指南)
从‘黑大理石’到你的研究:VIIRS夜间灯光数据(VNP46)预处理与避坑指南
从‘黑大理石’到你的研究:VIIRS夜间灯光数据(VNP46)预处理与避坑指南 深夜打开NASA的"黑大理石"(Black Marble)夜间灯光数据集,仿佛在凝视地球的脉搏。这些来自Suomi NPP卫星VIIRS传感器的数据&…...

终极罗技PUBG鼠标宏指南:5步实现精准压枪射击
终极罗技PUBG鼠标宏指南:5步实现精准压枪射击 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 绝地求生(PUBG)…...

# Bun:下一代 JavaScript 运行时的性能革命与实战指南在 Node.js 逐
Bun:下一代 JavaScript 运行时的性能革命与实战指南 在 Node.js 逐渐成为前端生态标配的同时,Bun 正以一种前所未有的方式重新定义“运行时”的边界。它不仅是一个更快的 JS 引擎,更是一套集成开发体验、原生打包能力、甚至内置 HTTP 服务器的…...

Brook与智能家居集成:控制物联网设备网络
Brook与智能家居集成:控制物联网设备网络 智能家居设备已成为现代家庭的重要组成部分,但这些设备往往缺乏统一的网络管理方案,导致安全漏洞和控制复杂等问题。Brook作为一款跨平台可编程网络工具,能够为物联网设备提供灵活的网络…...

别再死记硬背了!用D触发器搭个8分频电路,手把手教你理解Verilog时序逻辑
从零构建8分频电路:用D触发器玩转Verilog时序逻辑 第一次接触数字电路设计时,我被各种触发器、寄存器绕得晕头转向。直到导师扔给我一块FPGA开发板:"别光看理论,先搭个分频电路试试"。那次实践让我恍然大悟——原来抽象…...

Qwen3-0.6B-FP8部署全攻略:环境配置+模型调用一步到位
Qwen3-0.6B-FP8部署全攻略:环境配置模型调用一步到位 想快速体验一个轻量级但能力不俗的大语言模型吗?Qwen3-0.6B-FP8镜像为你提供了一个开箱即用的解决方案。这个镜像基于通义千问最新的Qwen3-0.6B模型,通过vLLM进行高效部署,并…...
动态聚合策略与性能优化)
OpenLayers(六)动态聚合策略与性能优化
1. 动态聚合策略的核心逻辑 地图应用中点位聚合(Cluster)是解决海量数据展示的经典方案。但很多开发者容易忽略一个关键问题:固定聚合距离参数在不同缩放级别下的表现差异。我曾在智慧城市项目中遇到一个典型场景——当用户从省级视图缩放到街…...

告别复杂配置!用Wan2.2-I2V-A14B镜像,三步搞定图生视频,效果惊艳
告别复杂配置!用Wan2.2-I2V-A14B镜像,三步搞定图生视频,效果惊艳 1. 为什么选择Wan2.2-I2V-A14B镜像 1.1 专业级视频生成能力 Wan2.2-I2V-A14B是一款由通义万相开源的高效视频生成模型,拥有50亿参数的专业级视频生成能力。这个…...

RV1109与hi3861L SD卡槽WiFi驱动移植实战:内核适配与调试技巧
1. 从零开始的WiFi驱动移植挑战 最近在做一个智能家居网关项目,需要把海思hi3861L WiFi模块移植到瑞芯微RV1109平台上。刚开始接到这个任务时,我整个人都是懵的——两个不同架构的芯片,内核版本还差这么多(hi3861L驱动基于Linux 4…...