【办公类-21-05】20240227单个word按“段落数”拆分多个Word(成果汇编 只有段落文字 1拆5)
作品展示
背景需求
前文对一套带有段落文字和表格的word进行13份拆分
【办公类-21-04】20240227单个word按“段落数”拆分多个Word(三级育婴师操作参考题目1拆13份)-CSDN博客文章浏览阅读293次,点赞8次,收藏3次。【办公类-21-04】20240227单个word按“段落数”拆分多个Word(三级育婴师操作参考题目1拆13份)https://blog.csdn.net/reasonsummer/article/details/136331041现在我随便找一份docx文件(全部都是段落文字,没有表格),
试试没表格干扰,是否直接读取段落就可以将加粗部分的文字另存多份
素材准备:
有几个加粗标题(不能是一级标题这种,一定清除格式,加粗)

错误的
# https://blog.csdn.net/lau_jw/article/details/114383781'''成果汇编word题目拆分成多个表格(根据标题(加粗)所在行数拆分-没有表格,只有段落文字)
作者:阿夏
时间:2024年2月27日
'''from docx import Document
from openpyxl import load_workbook
import glob
import re,osprint('----1、word数据清洗------')
a='成果汇编'path = r"C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题"
file=path + r'\{}.docx'.format(a) # 必须是docx
print(file)
# C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题\电子屏安全管理制度(样本)2.docx# 提取四个加粗标题所在的行数 # 参考https://www.shouxicto.com/article/96876.html
doc= Document(file)# 遍历每个段落并判断是否为空白行,如果有空白行,就删除
for paragraph in doc.paragraphs:if not paragraph.text.strip():# 如果是空白行则将其从文档中移除p = paragraph._elementp.getparent().remove(p) doc.save(path + r'\{}(去掉回车).docx'.format(a))print('----2、读取word里面标题加粗段落的行数------')filename=path + r'\{}(去掉回车).docx'.format(a)# 打开Word文档
doc = Document(filename)d=len(doc.paragraphs)
print(d)
# docx没有去掉空行前,一共有258段文字
# docx去掉空行后,一共有244段文字h=[]
s=[]
# 遍历文档中的段落
for i, paragraph in enumerate(doc.paragraphs):if paragraph.runs:# 检查段落中的所有运行对象for run in paragraph.runs:if run.bold:# 如果运行对象的文字为加粗,则打印段落索引# print("段落", i, "的文字被加粗了")h.append(i)# 提取每一份的加粗标题t=doc.paragraphs[i].text # print(t)s.append(t)
s=list(set(s))
s.sort()
# print(s)
# ['3.1.1 运用发育诊断法对2岁婴儿的以不同步子行走能力进行测试', '3.1.2 为2岁婴儿编制规范、适宜的个别化游戏活动计划(5分钟)', '3.1.3 设计生活中婴儿动手自理的活动(5分钟)', '3.1.4 六个月以内
# 的婴儿的精细动作的日常练习活动设计(5分钟)', '3.1.5 列举两种感统练习器械,并简述其活动功能(5分钟)', '3.2.1 请阐述对婴儿语言发展水平的观察与记录方法(5分钟)', '3.2.2 如何制定婴幼儿个别化
# 语言培养计划(5分钟)', '3.2.3 设计一份记录表格,观察一个6个月左右的宝宝寻找不同声源的感知练习过程(5分钟)', '3.2.4 设计一个观察表,观察并调整婴儿在视动协调方面的练习(5分钟)', '3.2.5 设
# 计一个观察表,记录孩子可能发生的行为(5分钟)', '3.3.1 如何对待任性的孩子(5分钟)', '3.3.2 如何对待爱哭的孩子(5
# print(len(s))
# 13h=list(set(h))
h.sort()
j=h[1:]
j.append(d)print(h)
print(len(h))
print(j)
print(len(j))
# # 去掉空行前
# # [1, 25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238]
# # 13
# # [25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238, 258]
# # 13
# # 去掉空行后
# # [1, 23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224]
# # 13
# # [23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224, 244]print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格# bg=[2,1,0,1,1,1,1,1,1,1,0,0,0]# # 第一张表是原来的段落数,所以就是0
# bg.insert(0,0)
# # print(bg)# # 数字累加
# o = []
# sum = 0
# for num in bg:
# sum += num
# o.append(sum)
# print(o)
# # [0, 2, 3, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
# # # # 没有空行的内容print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格imagePath1=path+r'\{}拆分'.format(a)
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建# for x in range(len(s)):# 获取第一页的段落和表格
# a=int(j[x]+o[x])
for x in range(len(s)):doc = Document(filename)first_page_paragraphs = []first_page_tables = []for element in doc.element.body:if element.tag.endswith(('}p', '}tbl')):if element.getparent().index(element) >int(j[x]) :# if element.getparent().index(element) >int(j[x]+o[x]) :if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)if element.getparent().index(element)<int(h[x]):# if element.getparent().index(element)<int(h[x]+o[x]):if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)# print(int(j[x]+o[x]))# print(int(h[x]+o[x]))# 删除第一页的段落和表格for paragraph in first_page_paragraphs:p = paragraph.getparent()p.remove(paragraph)for table in first_page_tables:t = table.getparent()t.remove(table)# # 保存修改后的文档为新文件# doc.save(path+r'01.docx')doc.save(imagePath1+r'\{} {}.docx'.format('%02d'%x,s[x]))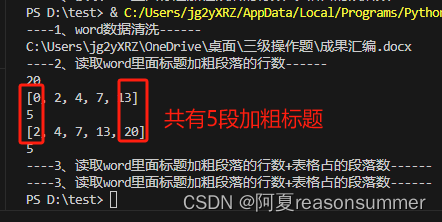

结果显示及调整

1、结果显示题目与数字顺序不符合
1、解决思路


2、内容多一行

 2、解决思路
2、解决思路
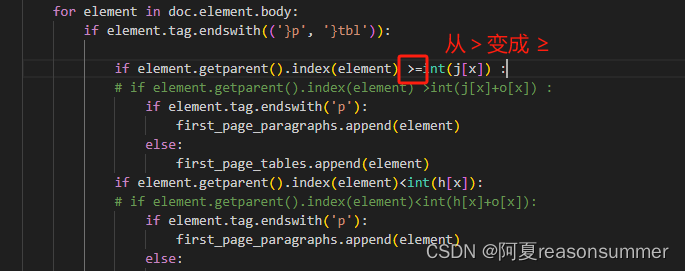

正确代码全部
# https://blog.csdn.net/lau_jw/article/details/114383781'''成果汇编word题目拆分成多个表格(根据标题(加粗)所在行数拆分-没有表格,只有段落文字)
作者:阿夏
时间:2024年2月27日
'''from docx import Document
from openpyxl import load_workbook
import glob
import re,osprint('----1、word数据清洗------')
a='成果汇编'path = r"C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题"
file=path + r'\{}.docx'.format(a) # 必须是docx
print(file)
# C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题\电子屏安全管理制度(样本)2.docx# 提取四个加粗标题所在的行数 # 参考https://www.shouxicto.com/article/96876.html
doc= Document(file)# 遍历每个段落并判断是否为空白行,如果有空白行,就删除
for paragraph in doc.paragraphs:if not paragraph.text.strip():# 如果是空白行则将其从文档中移除p = paragraph._elementp.getparent().remove(p) doc.save(path + r'\{}(去掉回车).docx'.format(a))print('----2、读取word里面标题加粗段落的行数------')filename=path + r'\{}(去掉回车).docx'.format(a)# 打开Word文档
doc = Document(filename)d=len(doc.paragraphs)
print(d)
# docx没有去掉空行前,一共有258段文字
# docx去掉空行后,一共有244段文字h=[]
s=[]
n=1
# 遍历文档中的段落
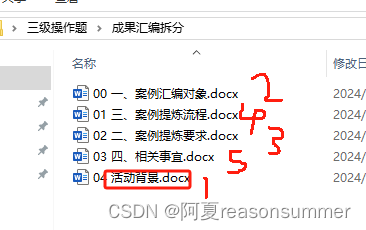
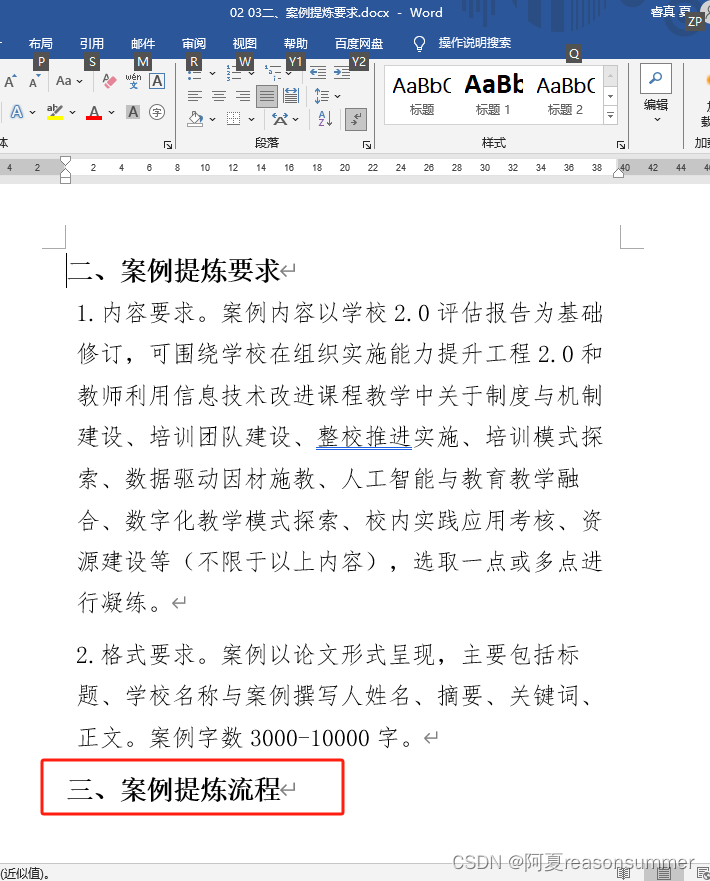
for i, paragraph in enumerate(doc.paragraphs):if paragraph.runs:# 检查段落中的所有运行对象for run in paragraph.runs:if run.bold:# 如果运行对象的文字为加粗,则打印段落索引# print("段落", i, "的文字被加粗了")h.append(i)# 提取每一份的加粗标题t=doc.paragraphs[i].text print(t)b=str('%02d'%n)+ts.append(b)# 没有按照顺序排列# ['一、案例汇编对象', '三、案例提炼流程', '二、案例提炼要求', '四、相关事宜', '活动背景']# 所以加了一个数字序号# ['01活动背景', '02一、案例汇编对象', '03二、案例提炼要求', '04三、案例提炼流程', '05四、相关事宜']n+=1
s=list(set(s))
s.sort()
print(s)
# ['3.1.1 运用发育诊断法对2岁婴儿的以不同步子行走能力进行测试', '3.1.2 为2岁婴儿编制规范、适宜的个别化游戏活动计划(5分钟)', '3.1.3 设计生活中婴儿动手自理的活动(5分钟)', '3.1.4 六个月以内
# 的婴儿的精细动作的日常练习活动设计(5分钟)', '3.1.5 列举两种感统练习器械,并简述其活动功能(5分钟)', '3.2.1 请阐述对婴儿语言发展水平的观察与记录方法(5分钟)', '3.2.2 如何制定婴幼儿个别化
# 语言培养计划(5分钟)', '3.2.3 设计一份记录表格,观察一个6个月左右的宝宝寻找不同声源的感知练习过程(5分钟)', '3.2.4 设计一个观察表,观察并调整婴儿在视动协调方面的练习(5分钟)', '3.2.5 设
# 计一个观察表,记录孩子可能发生的行为(5分钟)', '3.3.1 如何对待任性的孩子(5分钟)', '3.3.2 如何对待爱哭的孩子(5
# print(len(s))
# 13h=list(set(h))
h.sort()
j=h[1:]
j.append(d)print(h)
print(len(h))
print(j)
print(len(j))
# # 去掉空行前
# # [1, 25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238]
# # 13
# # [25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238, 258]
# # 13
# # 去掉空行后
# # [1, 23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224]
# # 13
# # [23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224, 244]print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格# bg=[2,1,0,1,1,1,1,1,1,1,0,0,0]# # 第一张表是原来的段落数,所以就是0
# bg.insert(0,0)
# # print(bg)# # 数字累加
# o = []
# sum = 0
# for num in bg:
# sum += num
# o.append(sum)
# print(o)
# # [0, 2, 3, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
# # # # 没有空行的内容print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格imagePath1=path+r'\{}拆分'.format(a)
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建# for x in range(len(s)):# 获取第一页的段落和表格
# a=int(j[x]+o[x])
for x in range(len(s)):doc = Document(filename)first_page_paragraphs = []first_page_tables = []for element in doc.element.body:if element.tag.endswith(('}p', '}tbl')):if element.getparent().index(element) >=int(j[x]) :# if element.getparent().index(element) >int(j[x]+o[x]) :if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)if element.getparent().index(element)<int(h[x]):# if element.getparent().index(element)<int(h[x]+o[x]):if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)# print(int(j[x]+o[x]))# print(int(h[x]+o[x]))# 删除第一页的段落和表格for paragraph in first_page_paragraphs:p = paragraph.getparent()p.remove(paragraph)for table in first_page_tables:t = table.getparent()t.remove(table)# # 保存修改后的文档为新文件# doc.save(path+r'01.docx')doc.save(imagePath1+r'\{}.docx'.format(s[x]))
相关文章:
【办公类-21-05】20240227单个word按“段落数”拆分多个Word(成果汇编 只有段落文字 1拆5)
作品展示 背景需求 前文对一套带有段落文字和表格的word进行13份拆分 【办公类-21-04】20240227单个word按“段落数”拆分多个Word(三级育婴师操作参考题目1拆13份)-CSDN博客文章浏览阅读293次,点赞8次,收藏3次。【办公类-21-04…...
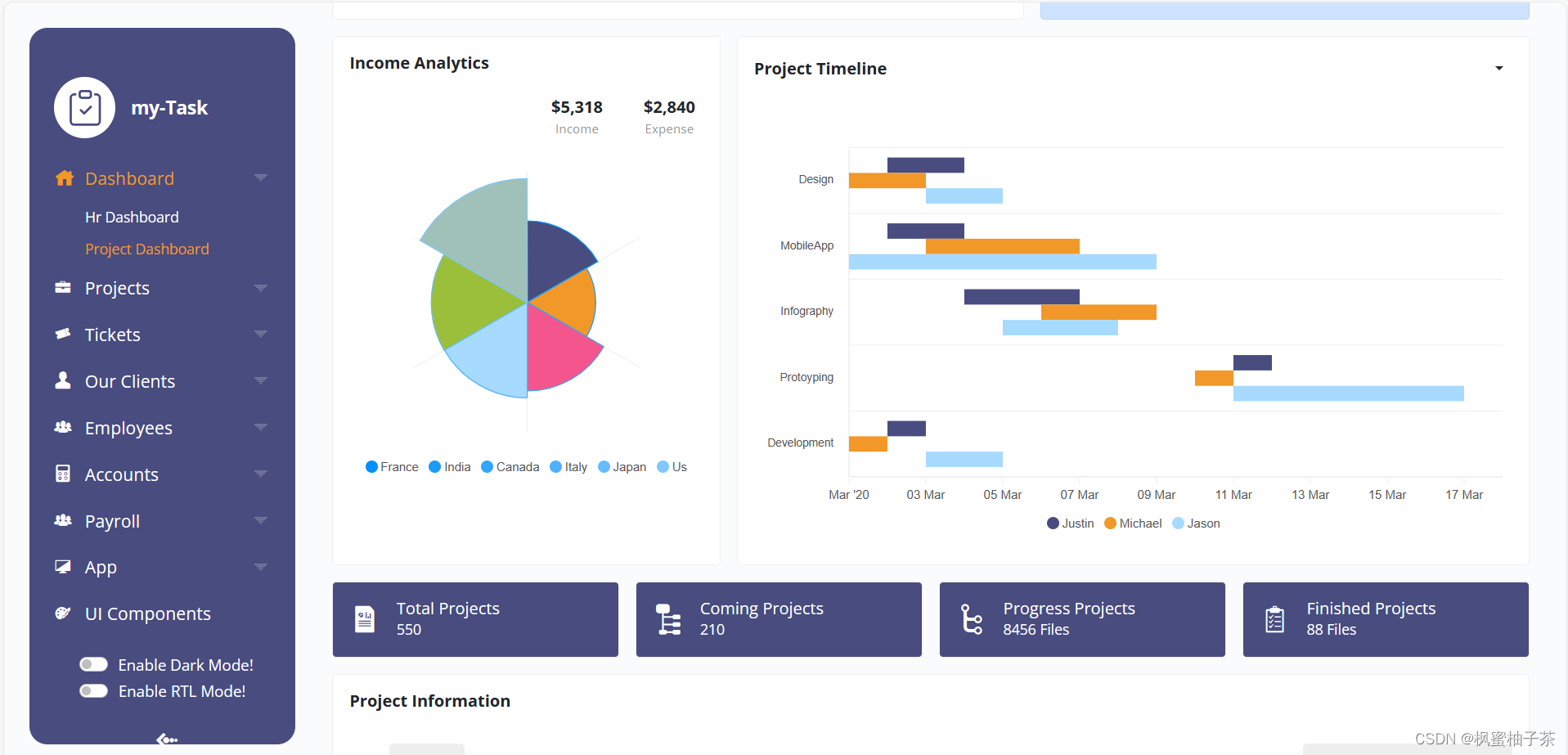
【前端素材】推荐优质后台管理系统网页my-Task平台模板(附源码)
一、需求分析 1、系统定义 后台管理系统是一种用于管理网站、应用程序或系统的工具,通常由管理员使用。后台管理系统是一种用于管理和控制网站、应用程序或系统的管理界面。它通常被设计用来让网站或应用程序的管理员或运营人员管理内容、用户、数据以及其他相关功…...

Linux高负载排查最佳实践
在Linux系统中,经常会因为负载过高导致各种性能问题。那么如何进行排查,其实是有迹可循,而且模式固定。 本次就来分享一下,CPU占用过高、磁盘IO占用过高的排查方法。 还是那句话,以最佳实践入手,真传一句话…...
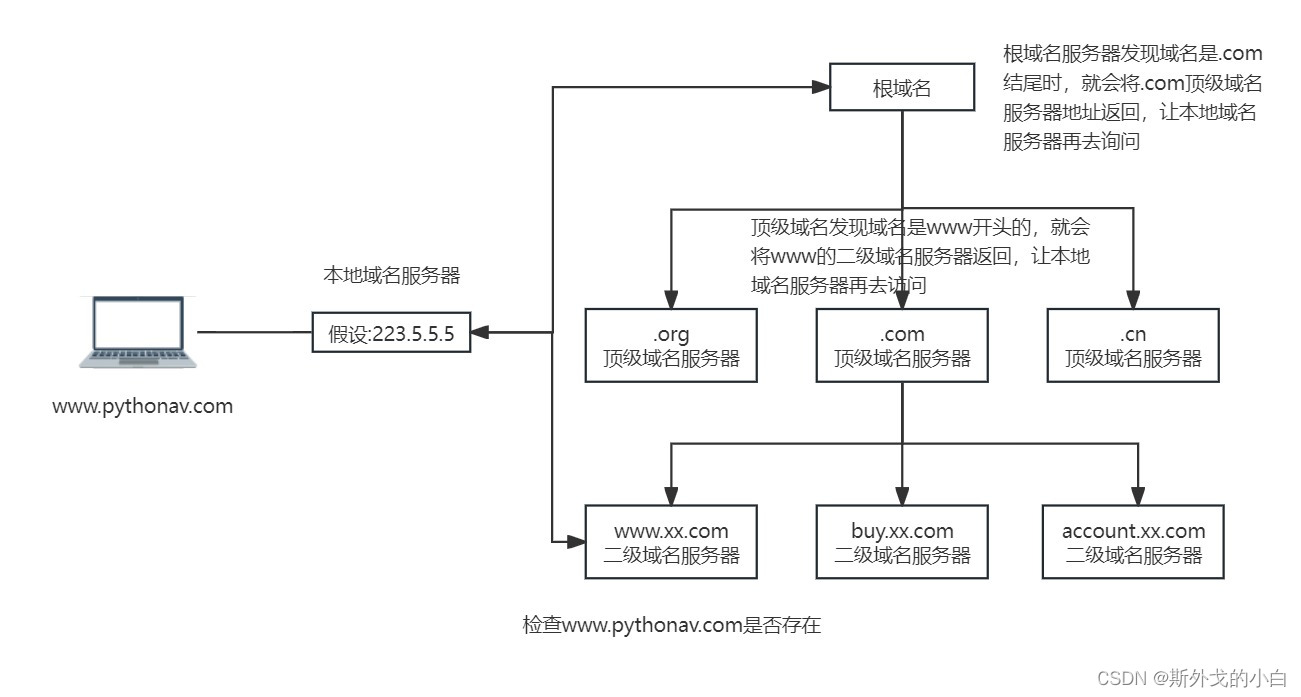
【python开发】网络编程(上)
这里写目录标题 一、必备基础(一)网络架构1、交换机2、路由器3、三层交换机4、小型企业基础网络架构5、家庭网络架构6、互联网 (二)网络核心词汇1、子网掩码和IP2、DHCP3、内网和公网IP4、云服务器5、端口6、域名 一、必备基础 &…...
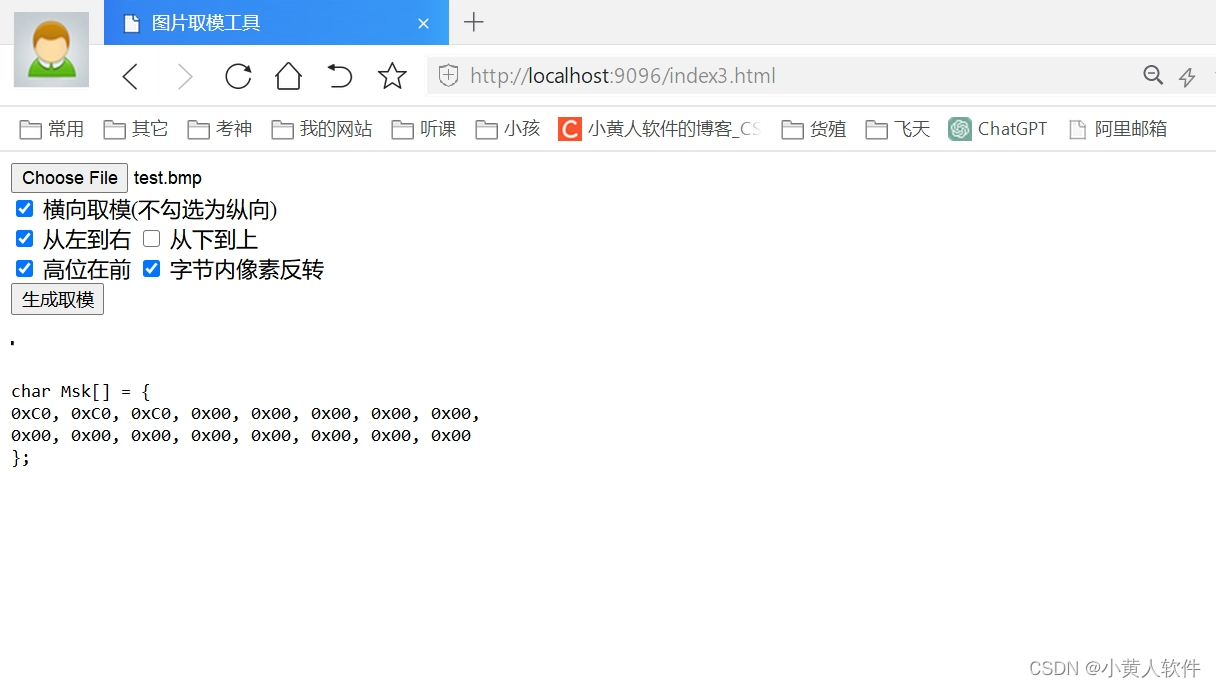
php源码 单色bmp图片取模工具 按任意方式取模 生成字节数组 自由编辑点阵
http://2.wjsou.com/BMP/index.html 想试试chatGPT4生成,还是要手工改 php 写一个网页界面上可以选择一张bmp图片,界面上就显示这张bmp图片, 点生成取模按钮,在图片下方会显示这张bmp图片的取模数据。 取模规则是按界面设置的&a…...
)
设计模式-命令模式(Command Pattern)
承接Qt/C软件开发项目,高质量交付,灵活沟通,长期维护支持。需求所寻,技术正适,共创完美,欢迎私信联系! 一、命令模式的说明 命令模式(Command Pattern)是一种行为设计模式…...

鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:位置设置)
设置组件的对齐方式、布局方向和显示位置。 说明: 从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 align align(value: Alignment) 设置容器元素绘制区域内的子元素的对齐方式。 卡片能力: 从API…...

ShardingJdbc实战-分库分表
文章目录 基本配置分库分表的分片策略一、inline 行表达时分片策略algorithm-expression行表达式完整案例和配置如下 二、根据实时间日期 - 按照标准规则分库分表标准分片 - Standard完整案例和配置如下 基本配置 逻辑表 逻辑表是指:水平拆分的数据库或者数据表的相…...
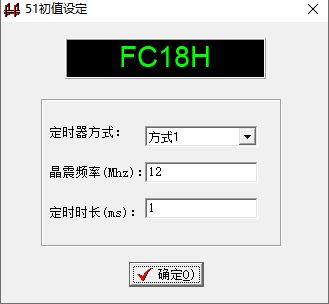
51单片机-(定时/计数器)
51单片机-(定时/计数器) 了解CPU时序、特殊功能寄存器和定时/计数器工作原理,以定时器0实现每次间隔一秒亮灯一秒的实验为例理解定时/计数器的编程实现。 1.CPU时序 1.1.四个周期 振荡周期:为单片机提供定时信号的振荡源的周期…...

midjourney提示词语法
更高级的提示可以包括一个或多个图像URL、多个文本短语和一个或更多个参数 Image Prompts 可以将图像URL添加到提示中,以影响最终结果的样式和内容。图像URL总是位于提示的前面。 https://docs.midjourney.com/image-prompts Text Prompt 要生成的图像的文本描述。…...

【鸿蒙 HarmonyOS 4.0】路由router
一、介绍 页面路由指在应用程序中实现不同页面之间的跳转和数据传递。HarmonyOS提供了Router模块,通过不同的url地址,可以方便地进行页面路由,轻松地访问不同的页面。 二、页面跳转 2.1、两种跳转模式: router.pushUrl()&…...
AT24C1024的模拟IIC驱动
AT24C1024是基于IIC的EEPROM,容量为1024/8128k bytes。它的引脚如下: 其中A1,A2为硬件地址引脚 WP为写保护引脚,一般我们需要读写,需要接低电平GND,接高的话则仅允许读 SDA和SCL则为IIC通信引脚 芯片通信采用IIC&…...

Stable Diffusion生成式扩散模型代码实现原理
Stable Diffusion可以使用PyTorch或TensorFlow等深度学习框架来实现。这些框架提供了一系列的工具和函数,使得开发者可以更方便地构建、训练和部署深度学习模型。因此可以使用PyTorch或TensorFlow来实现Stable Diffusion模型。 安装PyTorch:确保您已经安…...
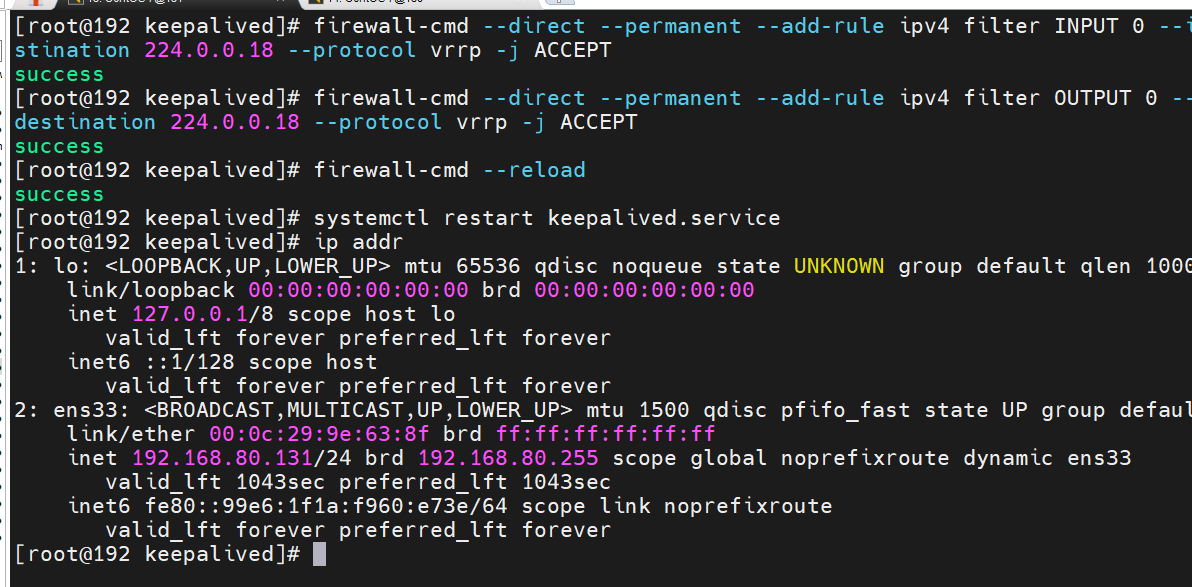
解决Keepalived “脑裂”(双VIP)问题
1. 检查广播情况 yum install tcpdump -y tcpdump -i ens33 vrrp -n master 192.168.80.130 与 backup: 192.168.80.131都在广播,正常情况下backup应该是不在广播的,所以可以判断存在防火墙屏蔽vrrp问题,需要设置VRRP过掉防火墙࿰…...
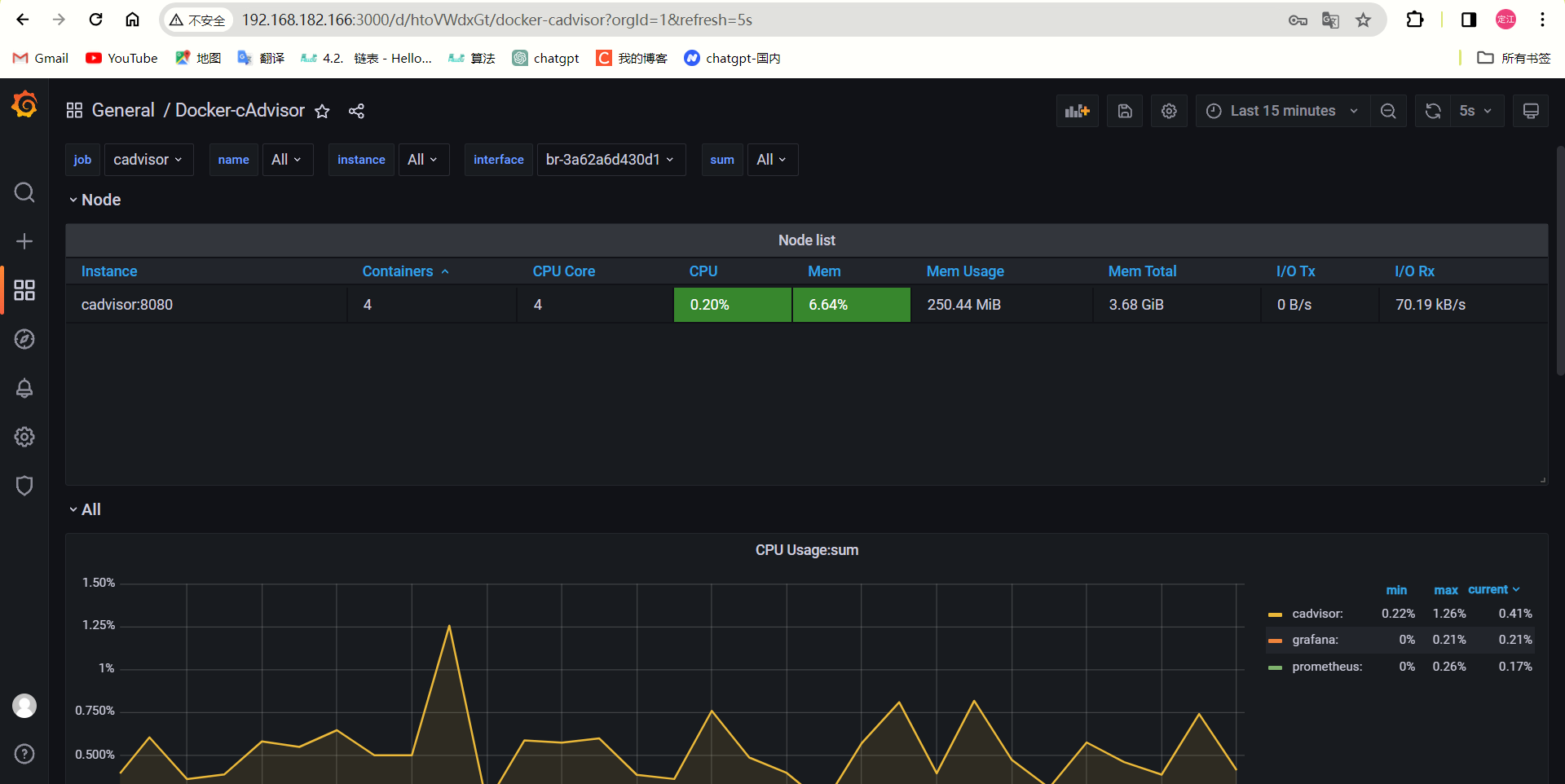
cAdvisor+Prometheus+Grafana 搞定Docker容器监控平台
cAdvisorPrometheusGrafana cAdvisorPrometheusGrafana 搞定Docker容器监控平台1、先给虚拟机上传cadvisor2、What is Prometheus?2.1、架构图 3、利用docker安装普罗米修斯4、安装grafana cAdvisorPrometheusGrafana 搞定Docker容器监控平台 1、先给虚拟机上传cadvisor cAd…...

java基础知识面试题
下面是关于java基础知识的一些常见面试题 equals 与区别 在Java中,""是一个比较操作符,用于比较两个变量的值是否相等。而"equals()"是Object类中定义的方法,用于比较两个对象是否相等。 具体区别如下: &…...

科技云报道:黑马Groq单挑英伟达,AI芯片要变天?
科技云报道原创。 近一周来,大模型领域重磅产品接连推出:OpenAI发布“文字生视频”大模型Sora;Meta发布视频预测大模型 V-JEPA;谷歌发布大模型 Gemini 1.5 Pro,更毫无预兆地发布了开源模型Gemma… 难怪网友们感叹&am…...
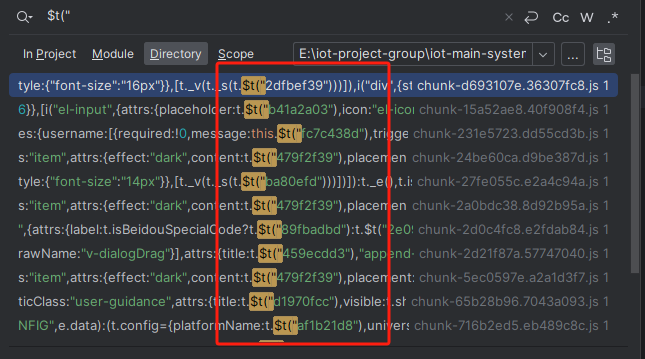
解决i18n国际化可读性问题,傻瓜式webpack中文支持国际化插件开发
先来看最后的效果 问题 用过国际化i18n的朋友都知道,天下苦国际化久矣,尤其是中文为母语的开发者,在面对代码中一堆的$t(abc.def)这种一点也不直观毫无可读性的代码,根本不知道自己写了啥 (如上图,你看得出…...
表达式)
【Django】执行查询—F()表达式
F() F()可以实现将模型字段值与同一模型中的另一字段做比较。举个例子看一下: class Entry(models.Model):...number_of_comments models.IntegerField(default0)number_of_pingbacks models.IntegerField(default0)...找到所有 number_of_pingbacks 大于 numbe…...

202112CSPT4磁盘文件操作
题意:有n个id号,m段空间,k个操作: 0 0 0:从L开始到R或遇到第一个其他非空id号为止,写入 i d id id号以及值 v a l val val;如果成功写入则输出写入成功的最右位置,否则输出-1 1 1 1:若 [ L , …...

从零构建AI辅助逆向分析环境:JADX-MCP与LLM的实战集成指南
1. 为什么需要AI辅助逆向分析? 逆向工程一直是安全研究员和开发者的重要技能,但面对日益复杂的Android应用,传统的手工分析方式效率低下。一个中等规模的APK反编译后可能产生数万行代码,人工阅读这些代码就像大海捞针。我曾经分析…...

FanControl终极指南:3步打造你的Windows风扇智能管家
FanControl终极指南:3步打造你的Windows风扇智能管家 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

架构演进:Logcat Reader如何重构Android日志调试领域
架构演进:Logcat Reader如何重构Android日志调试领域 【免费下载链接】LogcatReader A simple app for viewing logcat logs on an android device. 项目地址: https://gitcode.com/gh_mirrors/lo/LogcatReader Logcat Reader是一款专为Android开发者设计的开…...

突破下载瓶颈:XDM浏览器扩展的架构深度解析与技术实践
突破下载瓶颈:XDM浏览器扩展的架构深度解析与技术实践 【免费下载链接】xdm Powerfull download accelerator and video downloader 项目地址: https://gitcode.com/gh_mirrors/xd/xdm 在当今网络环境中,下载速度瓶颈和视频资源捕获已成为技术用户…...

深度学习图像分割终极指南:U-Net与ResNet-50的完美融合
深度学习图像分割终极指南:U-Net与ResNet-50的完美融合 【免费下载链接】pytorch-unet-resnet-50-encoder 项目地址: https://gitcode.com/gh_mirrors/py/pytorch-unet-resnet-50-encoder 还在为复杂的图像分割任务发愁吗?今天我要为你介绍一个基…...
工作原理系列(一))
AI智能体视觉检测系统(TVA)工作原理系列(一)
TVA初探——核心概念与应用场景解析作为企业初级技术人员,在接触AI智能体视觉检测系统(TVA)时,首先需要明确其核心定位、与传统机器视觉的区别,以及在工业场景中的实际应用价值。TVA全称为“Transformer-based Vision …...

通义千问1.5-1.8B-Chat-GPTQ-Int4 WebUI开发实战:Java八股文智能复习与面试模拟
通义千问1.5-1.8B-Chat-GPTQ-Int4 WebUI开发实战:Java八股文智能复习与面试模拟 1. 引言:当Java面试准备遇上AI助手 如果你正在准备Java面试,大概率对“八股文”这个词又爱又恨。爱的是,它确实划定了复习范围;恨的是…...

5分钟掌握Warframe自动演奏:ShawzinBot终极免费指南 [特殊字符]
5分钟掌握Warframe自动演奏:ShawzinBot终极免费指南 🎮 【免费下载链接】ShawzinBot Convert a MIDI input to a series of key presses for the Shawzin 项目地址: https://gitcode.com/gh_mirrors/sh/ShawzinBot 想让你的Warframe角色在游戏中演…...

3步解锁碧蓝航线全皮肤:Perseus原生库补丁终极指南
3步解锁碧蓝航线全皮肤:Perseus原生库补丁终极指南 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus Perseus是一个专为碧蓝航线(Azur Lane)设计的原生库补丁工具&#x…...

GLM-4-9B-Chat-1M作品实录:将300页英文技术标准翻译为中文并标注重点
GLM-4-9B-Chat-1M作品实录:将300页英文技术标准翻译为中文并标注重点 你有没有遇到过这样的难题?一份300多页的英文技术标准文档,密密麻麻的专业术语,不仅需要翻译成中文,还要从中找出关键条款、技术参数和风险点。传…...